OpenTSDB 入门
前言
网站主页 opentsdb
OpenTSDB is a distributed, scalable Time Series Database (TSDB) written on top of HBase
重点就是两个事情:实现架构;数据存储格式
架构实现
- OpenTSDB is primarily achieved by running one or more of the TSDs( Time Series Daemon). Each TSD is independent.
- store and retrieve time-series data
- There is no master, no shared state so you can run as many TSDs as required to handle any load you throw at it.
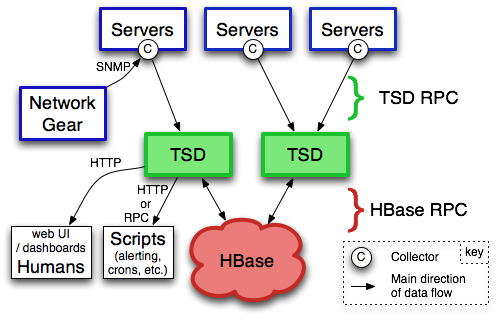
可以看到
- 底层是hbase 存储
- 中间是 Time Series Daemon (TSD)
- 周边是 运行在各个server 的collector,web ui,脚本等
数据结构
time series 最直观的数据格式是(t0,v0),(t1,v1),(t2,v2)...,当然作为一个系统考虑的要更多些,包括:
- A metric name.
- A UNIX timestamp
- A value, (64 bit integer or single-precision floating point value)
- A set of tags (key-value pairs) that describe the time series the point belongs to.
这种存储结构是后面一堆儿事儿(读取、写入、约束、原则、规范)的核心
mysql.bytes_received 1287333217 327810227706 schema=foo host=db1
mysql.bytes_sent 1287333217 6604859181710 schema=foo host=db1
mysql.bytes_received 1287333232 327812421706 schema=foo host=db1
mysql.bytes_sent 1287333232 6604901075387 schema=foo host=db1
mysql.bytes_received 1287333321 340899533915 schema=foo host=db2
mysql.bytes_sent 1287333321 5506469130707 schema=foo host=db2
名词解释
| 名词 | 指的是 | 数量 |
|---|---|---|
| metric | mysql.bytes_received/mysql.bytes_sent | 2个 |
| data point | 每一个记录 | 6 个 |
| time series | metric 和 tag 的不同组合 | 4个 |
4个 time series 分别是,schema 都是 foo 可以忽略
- mysql.bytes_received + host=db1
- mysql.bytes_received + host=db2
- mysql.bytes_sent + host=db1
- mysql.bytes_sent + host=db2
基于这个基本结构
- 如何节省存储空间?opentsdb 有两张表,一张表存储数据本身,一张表存储 metric name、tag name、tag value 到一个unique id 的映射关系(uid 表)。metrics, tag name, tag value的编码长度都是3byte, 所以UID的数量上限为 2^24 个。
- 如果提高查询效率?参见存储结构小节
- 查询方式。或者说,基于tag的查询有什么花活儿?
tag
naming schema 命名规则
Tags allow you to separate similar data points from different sources or related entities, so you can easily ** graph them ** individually or in groups. tag 的最大作用是:方便各种条件的聚合查询。也就是,一个数据有多个维度,支持多个维度的聚合查询。the uniqueness comes from a combination of tag key/value pairs that allows for flexible queries with very fast aggregations.
大部分人的查询习惯,都是先看metric 总的数据,然后tagA 情况下的数据,然后tagA + tagB 情况下的数据,即 drill down。
tag 方式的副作用
- 假设 time series 有两个tag, 那么根据一个tag 去查询,则另一个tag的所有数据都会被匹配。这有时会带来一些不便。
A critical(重要的) aspect of any naming schema is to consider the cardinality(基数) of your time series. 任何命名规则(映射关系) 都必须考虑 命名的基数,比如月份,就是1~12. 比如,如果你将ip 地址作为 一个tag,则ip tag value 共有4 billion 中可能值 ,而 一个tag value 最多允许 16 million 中可能值。
OpenTSDB creates a new row per time series per hour
存储结构
hbase 存储结构
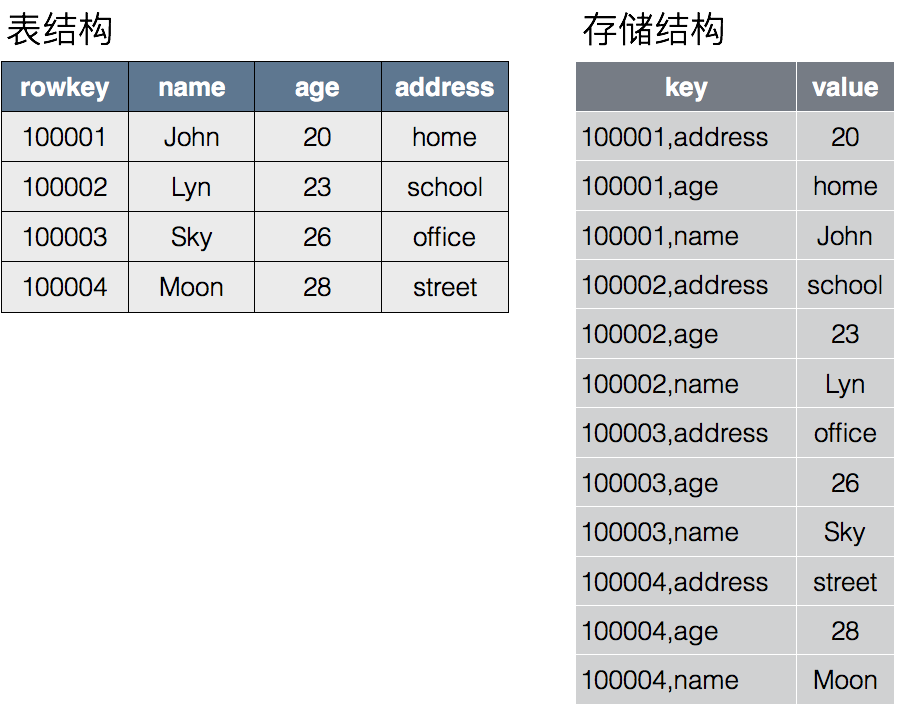
直观上,官网 例子 sys.cpu.user 在 hbase 的存储结构
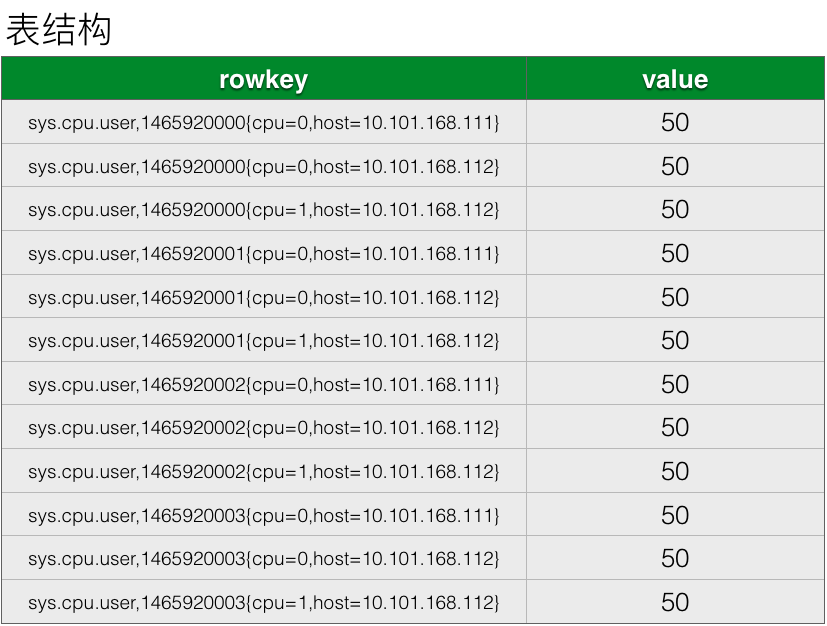
优化1,缩短row key
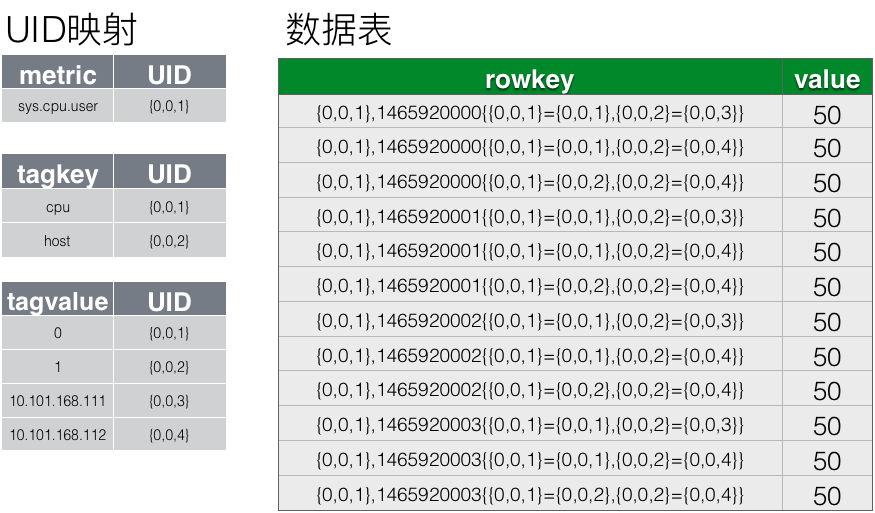
优化2,减少key value 个数。将多行(一个行一秒)合并为一行(1h 的数据 存在一行中),多行单列变为单行多列(每列列名是 相对 row key 中base 时间戳的偏移值)。
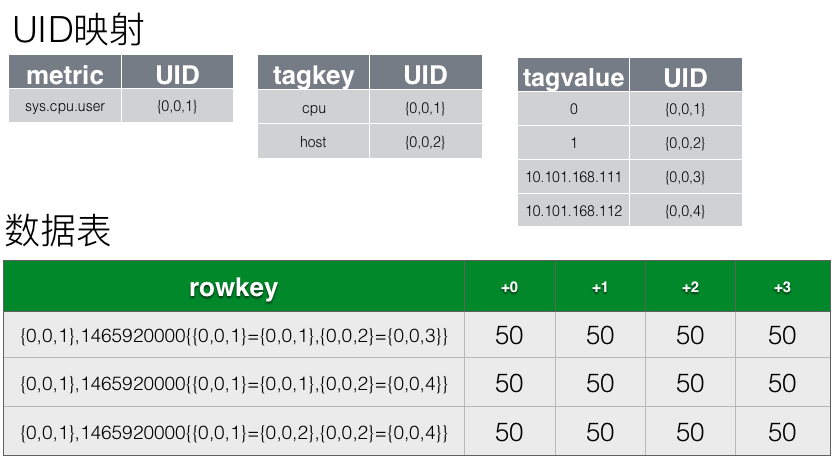
单行多列合并为单行单列

当某一个metric下数据点很多时,则该metric很容易造成写入热点。预分桶后的变化就是在rowkey前会拼上一个桶编号(bucket index)。可将某个热点metric的写压力分散到多个桶中,避免了写热点的产生。

查询
几个点
- OpenTSDB可以以毫秒分辨率存储数据,但为保持工具的向后兼容性,大多数查询将以秒为分辨率返回数据。 如果相同的时间点存储了多个数据值,这些数据值将被聚合并且作为一个正常的查询结果返回。
- Aggregation 聚合函数是将单个时间戳的两个或多个数据点的值合并成单个数据值的方法。
- Downsampling,返回秒级分辨率的数据时,通常数据量很大,可以在查询时使用向下采样以减少返回的数据点的数量。 下采样需要聚合函数和时间间隔。比如每秒1个,一共20s数据,interval=2s and Aggregation=avg。则查询结果返回10个数据,每一个是2s内数据的平均值。
图表操作
地址:http://ip:4242/
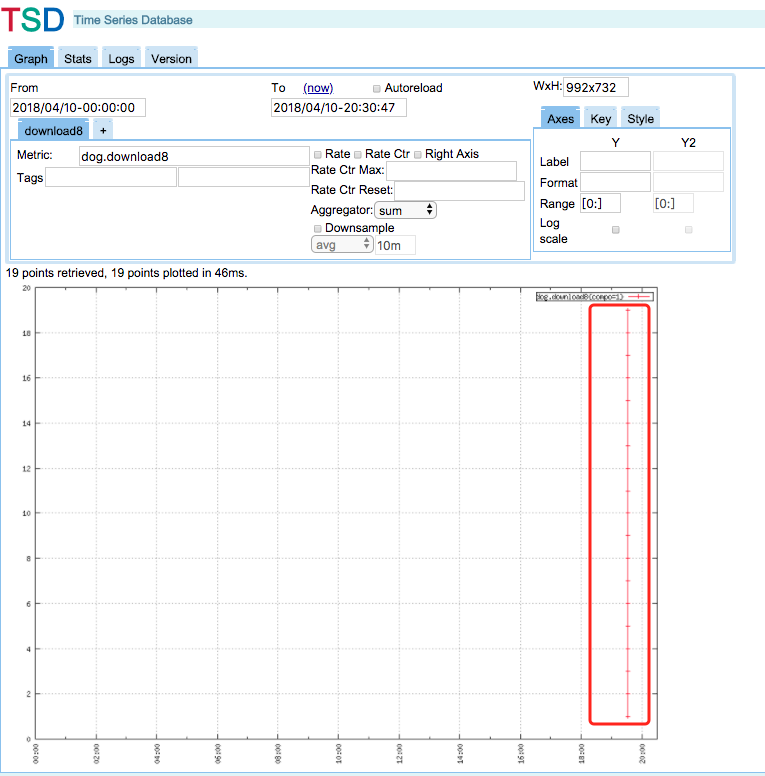
通过简单查询,即可得到数据。鼠标在折线图中选中一个区域,即可对该区域进行放大。
tips
- opentsdb 由java编写,启动方式类似hadoop、zookeeper 等 二进制脚本包裹的方式
- 第一次启动时候,运行指定脚本创建hbase表
- OpenTSDB can be configured via a file on the local system, via command line arguments or a combination or both.
- Querying or Reading Data
简单使用
opentsdb 本身提供cli、telnet和http api 等接口。此外还可以 直接操作 hbase 表,其本质 是copy了 opentsdb 的部分源码,写数据时,通过 opentsdb 代码 完成 input data ==> opentsdb data 的转换,然后由hbase client 写入 hbase。读取 亦然,相当于将 tsd 内嵌到 业务代码中。
java 封装 http api OpenTSDB的读写API
留下评论