总纲——如何学习分布式系统
简介
所谓分布式,指的是计算节点之间不共享内存,需要通过网络通信的方式交换数据。分布式的第一性原理就是:网络不可靠;机器不可靠。本文主要聊一下 分布式系统(尤其指分布式计算系统)的 基本组成和理论问题。
一个有意思的事情是现在已经不提倡使用Master-Slave 来指代这种主从关系了,毕竟 Slave 有奴隶的意思,在美国这种严禁种族歧视的国度,这种表述有点政治不正确了,所以目前大部分的系统都改成 Leader-Follower 了。
分布式的难点
分布式系统一致性为什么难做?因为没有全局时钟。每台服务器都有自己的本地时钟,跨服务器的本地时钟相比较是没有意义的。这就导致分布式系统时序成为了一个难题,一致性也就变得十分困难。关于全局时钟,工程架构上有什么最佳实践吗?
- 其一,经常使用单点串行化,保证时序。例如:MySQL以主节点操作时序为准,序列化为binlog后,同步到从节点执行。
- 其二,可以使用单点发号器,模拟全局时钟。所有操作执行前,到发号器上领取一个递增的时间戳,作为时序依据。单点发号器的时间戳比较,就变得有意义了。
- 其三,可以使用NTP协议尽量缩小服务器之间的差,但即使使用了NTP,仍然无法保证绝对时序。
《大数据经典论文解读》作为一个分布式的数据系统,它就需要满足三个特性,也就是可靠性、可扩展性和可维护性。
- 作为一个数据系统,我们需要可靠性。如果只记录一份数据,那么当硬件故障的时候就会遇到丢数据的问题,所以我们需要对数据做复制。而数据复制之后,以哪一份数据为准,又给我们带来了主从架构、多主架构以及无主架构的选择。然后,在最常见的主从架构里,我们根据复制过程,可以有同步复制和异步复制之分。同步复制的节点可以作为高可用切换的 Backup Master,而异步复制的节点只适合作为只读的 Shadow Master。
- 第二个重要的特性是可扩展性。在“大数据”的场景下,单个节点存不下所有数据,于是就有了数据分区。常见的分区方式有两种,第一种是通过区间进行分片,典型的代表就是 Bigtable,第二种是通过哈希进行分区,在大型分布式系统中常用的是一致性 Hash,典型的代表是 Cassandra。
- 最后一点就是整个系统的可维护性。我们需要考虑容错,在硬件出现故障的时候系统仍然能够运作。我们还需要考虑恢复,也就是当系统出现故障的时候,仍能快速恢复到可以使用的状态。而为了确保我们不会因为部分网络的中断导致作出错误的判断,我们就需要利用共识算法,来确保系统中能够对哪个节点正在正常服务作出判断。这也就引出了CAP 这个所谓的“不可能三角”。
而分布式系统的核心问题就是 CAP 这个不可能三角,我们需要在一致性、可用性和分区容错性之间做权衡和选择。因此,我们选择的主从架构、复制策略、分片策略,以及容错和恢复方案,都是根据我们实际的应用场景下对于 CAP 进行的权衡和选择。
单节点的存储引擎:然而,即使是上万台的分布式集群,最终还是要落到每一台单个服务器上完成数据的读写。那么在存储引擎上,关键的技术点主要包括三个部分。
- 第一个是事务。在写入数据的时候,我们需要保障写入的数据是原子的、完整的。在传统的数据库领域,我们有 ACID 这样的事务特性,也就是原子性(Atomic)、一致性(Consistency)、隔离性(Isolation)以及持久性(Durability)。而在大数据领域,很多时候因为分布式的存在,我们常常会退化到一个叫做 BASE 的模型。BASE 代表着基本可用(Basically Available)、软状态(Soft State)以及最终一致性(Eventually Consistent)。不过无论是 ACID 还是 BASE,在单机上,我们都会使用预写日志(WAL)、快照(Snapshot)和检查点(Checkpoints)以及写时复制(Copy-on-Write)这些技术,来保障数据在单个节点的写入是原子的。而只要写入的数据记录是在单个分片上,我们就可以保障数据写入的事务性,所以我们很容易可以做到单行事务,或者是进一步的实体组(Entity Group)层面的事务。
- 第二个是底层的数据是如何写入和存储的。这个既要考虑到计算机硬件的特性,比如数据的顺序读写比随机读写快,在内存上读写比硬盘上快;也要考虑到我们在算法和数据结构中的时空复杂度,比如 Hash 表的时间复杂度是 O(1),B+ 树的时间复杂度是 O(logN)。这样,通过结合硬件性能、数据结构和算法特性,我们会看到分布式数据库最常使用的,其实是基于 LSM 树(Log-Structured Merge Tree)的 MemTable+SSTable 的解决方案。
- 第三个则是数据的序列化问题。出于存储空间和兼容性的考虑,我们会选用 Thrift 这样的二进制序列化方案。而为了在分析数据的时候尽量减少硬盘吞吐量,我们则要研究 Parquet 或者 ORCFile 这样的列存储格式。然后,为了在 CPU、网络和硬盘的使用上取得平衡,我们又会选择 Snappy 或者 LZO 这样的快速压缩算法。
分布式问题,往往脱胎于少量经典论文的算法证明;单节点的存储引擎,也是一个自计算机诞生起就被反复研究的问题,这两者其实往往是经典论文的再现。但是在上千个服务器上的计算引擎应该怎么做,则是一个巨大的工程实践问题,我们没有太多可以借鉴的经验。这也是为什么计算引擎的迭代和变化是最大的。不过随着 Dataflow 论文的发表,我们可以看到整个大数据的处理引擎,逐渐收敛成了一个统一的模型,大数据领域发展也算有了一个里程碑。
从哪里入手
有没有一个 知识体系/架构、描述方式,能将分布式的各类知识都汇总起来?当你碰到一个知识点,可以place it in context
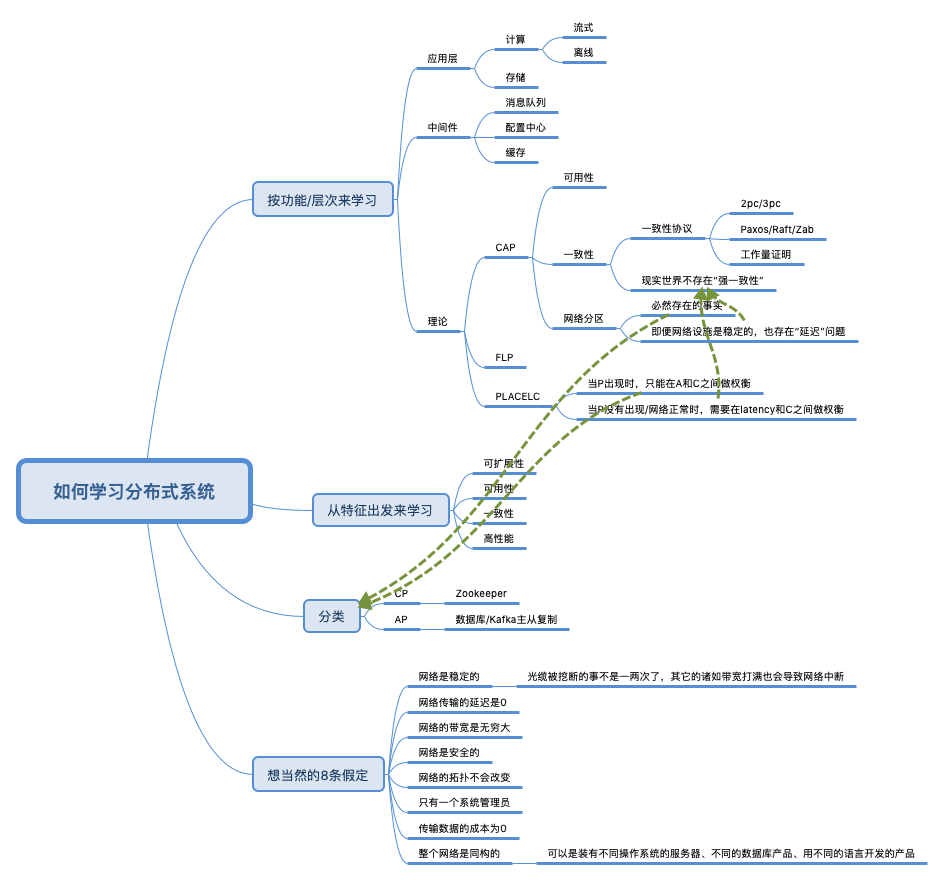
分布式学习最佳实践:从分布式系统的特征开始(附思维导图) 作者分享了“如何学习分布式系统”的探索历程, 深有体会。当一个知识点很复杂时,如何学习它,也是一门学问。
大咖文章
2018.11.25 补充 可能是讲分布式系统最到位的一篇文章回答了几个问题:
- “分布式系统”等于 SOA、ESB、微服务这些东西吗?
- “分布式系统”是各种中间件吗?中间件起到的是标准化的作用。中间件只是承载这些标准化想法的介质、工具,可以起到引导和约束的效果,以此起到大大降低系统复杂度和协作成本的作用。为了在软件系统的迭代过程中,避免将精力过多地花费在某个子功能下众多差异不大的选项中。
- 海市蜃楼般的“分布式系统”
我们先思考一下“软件”是什么。 软件的本质是一套代码,而代码只是一段文字,除了提供文字所表述的信息之外,本身无法“动”起来。但是,想让它“动”起来,使其能够完成一件我们指定的事情,前提是需要一个宿主来给予它生命。这个宿主就是计算机,它可以让代码变成一连串可执行的“动作”,然后通过数据这个“燃料”的触发,“动”起来。这个持续的活动过程,又被描述为一个运行中的“进程”。
- 分治
- 冗余,为了提高可靠性
- 再连接,如何将拆分后的各个节点再次连接起来,从模式上来说,主要是去中心化与中心化之分。前者完全消除了中心节点故障带来的全盘出错的风险,却带来了更高的节点间协作成本。后者通过中心节点的集中式管理大大降低了协作成本,但是一旦中心节点故障则全盘出错。
不要沉迷与具体的算法
distributed-systems-theory-for-the-distributed-systems-engineer 文中提到:
My response of old might have been “well, here’s the FLP paper, and here’s the Paxos paper, and here’s the Byzantine generals(拜占庭将军) paper…”, and I’d have prescribed(嘱咐、规定) a laundry list of primary source material which would have taken at least six months to get through if you rushed. But I’ve come to thinking that recommending a ton of theoretical papers is often precisely the wrong way to go about learning distributed systems theory (unless you are in a PhD program). Papers are usually deep, usually complex, and require both serious study, and usually significant experience to glean(捡拾) their important contributions and to place them in context. What good is requiring that level of expertise of engineers?
也就是说,具体学习某一个分布式算法用处有限。一个很难理解,一个是你很难 place them in contex(它们在解决分布式问题中的作用)。
分布式系统不可能三角——CAP
这可能是我看过最通俗也是最深刻的CAP理论 对CAP 进行了一些批判,有大牛对分布式系统问题进行了更系统的梳理。
2020.06.28补充:条分缕析分布式:到底什么是一致性?在历史上,CAP定理具有巨大的知名度,但它实际的影响力却没有想象的那么大。随着分布式理论的发展,我们逐渐认识到,CAP并不是一个「大一统」的理论,远不能涵盖分布式系统设计中方方面面的问题。相反,CAP引发了很多误解和理解上的混乱(细节不讨论了)。
下文来自 李运华 极客时间中的付费专栏《从0到1学架构》和韩健的《分布式协议和算法实战》。
Robert Greiner (http://robertgreiner.com/about/) 对CAP 的理解也经历了一个过程,他写了两篇文章来阐述CAP理论,第一篇被标记为outdated
| 第一版 | 第二版 | 韩健的《分布式协议和算法实战》 | |
|---|---|---|---|
| 地址 | http://robertgreiner.com/2014/06/cap-theorem-explained/ | http://robertgreiner.com/2014/08/cap-theorem-revisited/ | |
| 理论定义 | Any distributed system cannot guaranty C, A, and P simultaneously. | In a distributed system (a collection of interconnected nodes that share data.), you can only have two out of the following three guarantees across a write/read pair: Consistency, Availability, and Partition Tolerance - one of them must be sacrificed. 在一个分布式系统(指互相连接并共享数据的节点的集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。 |
|
| 一致性 | all nodes see the same data at the same time | A read is guaranteed to return the most recent write for a given client 总能读到 最新写入的新值 | 客户端的每次读操作,不管访问哪个节点,要么读到的都是同一份最新的数据,要么读取失败 |
| 可用性 | Every request gets a response on success/failure | A non-failing node will return a reasonable response within a reasonable amount of time (no error or timeout) | 任何来自客户端的请求,不管访问哪个节点,都能得到响应数据,但不保证是同一份最新数据 |
| 分区容忍性 | System continues to work despite message loss or partial failure | The system will continue to function when network partitions occur | 当节点间出现任意数量的消息丢失或高延迟的时候,系统仍然可以继续提供服务 |
- 只要有网络交互就一定会有延迟和数据丢失,也就是说,分区容错性(P)是前提,不是你想不想的问题,而是始终会存在,于是只能在可用性和一致性两者间做出选择。当网络分区失效,也就是网络不可用的时候
- 如果选择了一致性,P(分区)会导致同步时间无限延长,系统就可能返回一个错误码或者干脆超时,即系统不可用。
- 如果选择了可用性,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。 在工程上,我们关注的往往是如何在保持相对一致性的前提下,提高系统的可用性。
- 大部分人对 CAP 理论有个误解,认为无论在什么情况下,分布式系统都只能在 C 和 A 中选择 1 个。 其实,在不存在网络分区的情况下,也就是分布式系统正常运行时(这也是系统在绝大部分时候所处的状态),就是说在不需要 P 时,C 和 A 能够同时保证。
- CAP理论的一致性是保证同样一个数据在所有不同服务器上的拷贝都是相同的,这是一种逻辑保证,而不是物理,因为光速限制,在不同服务器上这种复制是需要时间的,集群通过阻止客户端查看不同节点上还未同步的数据维持逻辑视图。
- 当跨分布式系统提供ACID时,这两个概念会混淆在一起,Google’s Spanner system能够提供分布式系统的ACID,其包含ACID+CAP设计,也就是两阶段提交 2PC+ 多副本同步机制(如 Paxos)
- 还是读写问题。多线程 提到,多线程本质是一个并发读写问题,数据库系统中,为了描述并发读写的安全程度,还提出了隔离性的概念。具体到cap 理论上,副本一致性本质是并发读写问题(A主机写入的数据,B主机多长时间可以读到,或者说B主机也在写同一个数据)。
服务发现技术选型那点事儿 Eureka通过“最大努力的复制(best effort replication)” 可以让整个模型变得简单与高可用,我们在进行 A -> B 的调用时,服务 A 只要读取一个 B 的地址,就可以进行 RESTful 请求,如果 B 的这个地址下线或不可达,则有 Hystrix 之类的机制让我们快速失败。PS:也就是不单纯局限于 CAP 来考虑系统的可用性
- 窃以为这里 CAP 理论研究的对象是:数据库、软件、网络,用数据库的一致性、软件的高可用和网络的可访问性来阐释:如何设计好的分布式系统。当今(2022年)的分布式系统已经远超数据库、软件和网络的概念,再以这三者为对象讨论:什么是好的分布式系统是否有点儿过时了?是否可以把这些概念做一下升级呢?
- 是否可以把 A 的部分升级为“容错”、P 的部分升级为“容灾”?之所以这样升级,因为,A 的软件部分升级为容错就能够涵盖:网络延迟、中断等情况,而不仅仅指狭义的可用,毕竟可用在不同的软件环境和设计下是不同的。这里软件环境指:系统内核模块或设别驱动、 I/O 等底层能力、基础框架、业务应用等,软件设计指:有/无状态服务、高/低并发、大/小数据量、内存/网络/磁盘 I/O 密集等针对性设计,这些环境和设计下对“高可用”的解释是不同的。P 升级为“容灾”可以涵盖超出“数据分区”的概念,同时,容灾还能够涵盖那些必须一致和可用的场景,当我在设计“部署架构”的时候,会考虑:南北分布、同一运营商分布、同城分布、同机房分布等,南北分布对应骨干网络灾备能力、同一运营商分布对应运营商服务灾备能力、同城分布对应城市灾备能力、同机房分布对应集群灾备能力,灾备能力基础上考虑访问速度、带宽成本等问题,已经超出了“容灾”的范围,可以因成本制约唯有并入广义的“可用性”。
- 容器技术把硬件标准化且隐去了,卖计算机到卖计算(当然还有存储),这一字之差使云计算的成本大幅降低。
解决分布式问题的武器——共识与事务
- 共识协议对于分布式系统之所以如此重要,在于其面向数据一致性与服务容错性这两大难题提供了近乎完美的解决方案。不过,任何技术皆非万能,一定是有其应用边界的,那么“共识”技术的作用域在哪里呢?参与“共识”的各方须是一系列副本(Replica),执行着相同的业务逻辑,趋近于相同的状态,故而互相可为容灾备份。
- 讲“共识”就要介绍 CAP,所谓 “C” 即 Consistency(一致性,可以理解为写成功的数据,总是能读得出来),“A” 即 Availability(可用性,可以理解为少部分节点故障,对外服务不受影响),“P” 即 Partition tolerance(分区容错性,可以理解为节点之间发生了网络分区,无法通信,也不影响系统响应的正确性)。这个性质是给工业界设置了底限,鱼和熊掌不可兼得,基于容忍网络分区的前提下,究竟选择 “C” 还是 “A”,这是个问题。
- 很多时候,我们要面临的挑战并非是能够在副本之间协调的,譬如一个操作可能会涉及不同的逻辑实体。那么业务系统对这样的操作应该持怎样的预期呢?这里所谓的“预期”,翻译一下,叫做 Serializability,可序列化。事实上,这个也是分布式系统的初始愿景 - 多台(成千上万台)计算机一起工作,在终端用户看来,这就像是一台(没座,关键词是一台)功能强大的超级计算机。就这样,继“共识”之后,分布式系统再有了“事务”这个武器,能够让终端用户的上述操作看起来是在一个独享的、不被干扰的环境下执行。
- 说“事务”也不得不提 ACID,这个可以更正式地解释什么叫符合业务“预期”的结果。所谓 “A” 即 Atomicity(原子性,可以理解为一个事务内的所有操作,要么全部成功,要么全部失败,不存在中间状态),“C” 即 Consistency(虽说与 CAP 的 “C” 是一个单词,含义却完全不同:这里的 “C” 可以理解为数据完整性的约束,保持系统的不变量/invariants,比如 A,B 两个账户总额2000元,则不管AB之间如何转账,2000就是这个invariants),“I” 即 Isolation(隔离性,可以理解为并发事务之间,各自内部的操作状态对对方是不可见的),“D” 即 Durability(持久化,可以理解为一旦写成功的数据,不会因为进程 failover 等异常而导致状态丢失)。
一个成熟的分布式事务的实现通常需要考虑三部分:1)最上层的是原子提交协议,主流的自然是鼎鼎大名的 2 PC - 两阶段提交协议;2)中间层是并发访问控制协议,用于提升事务的并发读写效率;3)最下面的是基于共识的复制协议,保证服务的可容错性。
![]()
上图即可清晰地解释共识与事务的关系,总结起来,“事务”要解决的问题,在“共识”之上:首先,“事务”的参与方,并非副本,而是不同业务逻辑的资源实体;其次,“事务”包括了一系列子操作,每个操作的作用方可以落在不同的资源实体。通俗一点讲,“共识”是同一个培训班出来的几个人,做的是同一件事情,互为容灾备份;“事务”则是来自五湖四海的一群人,各司其职,组合在一起,干一票大的。
硬件更新
以CPU为中心的传统架构的短板:
- 首先是慢。在分布式体系架构下,很多大型应用会分散在多个子系统中去部署,这就对各系统之间的延迟提出了很高的要求,此外,由于大数据应用的增长,数据中心内部数据的迁移流量也在增大,这对网络带宽又是一个挑战。CPU最开始时并不是为了搭载云操作系统而设计的,CPU的优势是单核性能强,在指令性计算任务处理时,性能优异,但对数据处理并不擅长,数据吞吐能力弱,一旦遇到分布式大数据系统就要消耗大量的资源用于数据搬运。
- 超大规模的复杂管理。既包含了云计算超大规模基础设施的硬件管理,也有云内部超大应用、复杂应用的管理。
- 在云产生的十几年时间里,已经应运而生了非常多的为了服务云环境而产生的软硬件,比如容器。
- 为了做好弹性,大部分云上 PaaS 软件要么已经完成了计算和存储的分离解耦,要么正在做。在弹性提升的同时,本来一件在本地物理机就可以做完的事情,现在不得不跨越虚拟机环境、跨越物理集机、跨越集群……一个云原生数据库集群可能拥有十几个计算节点和成百上千个存储节点。在这样的架构里面同时实现低延时和高吞吐是非常困难的。PolarDB 就使用了 RDMA 来改善网络的问题。但 RDMA 这样的软硬结合技术本身的规模化推广是有难度的,时至今日能用得上、用得好 RDMA 的数据库也不多。
三问阿里云:CIPU究竟是什么?阿里云基础产品首席架构师黄瑞瑞将云计算的发展分成分布式技术阶段、资源池化技术阶段和如今的 CIPU 阶段。
- 分布式架构严格来说还不是云,只是企业内部使用了相应的分布式架构去解决自身扩展性的问题。在未使用分布式技术前,企业通过不停地增加小型机或者数据库的方式应对计算任务的增加,并不具备可扩展性、且缺少性价比。分布式技术让企业不再需要专门采购一些专用的大型机或者定向购买小型机,解放了供应链的弹性。
- 但是企业由于业务状态不同,对于计算算力的要求会有波峰和波谷。不同公司的不同 IT 部门开始引入相对应的虚拟化技术,实现分时复用,解决单个企业内集群资源利用率相对比较低的问题。分布式架构下一个时代就是公有云,从技术的维度去看就是资源池化的时代。资源池化的关键技术能力在于能否将云上的资源提供给对应的弹性。将云上的计算、存储、网络等技术的算力资源,通过不同的搭配方式,在云上搭建各种各样的应用。从技术的维度看,资源池化阶段,虚拟化技术再向前一步,将不同的物理资源变成虚拟化的资源,变成统一的池化管理。资源池化将计算的虚拟化资源、存储的虚拟化资源、网络的虚拟化资源放在一起管理,企业就不需要承担早期分布式阶段中自己管理基础资源、不需要自己管理虚拟化资源。云厂商们迎来了新的业务需求挑战:企业在进行上云时不仅仅注重技术问题,也更加关注经济问题。PS:比如你买机器只有2c4g 和 4c8g,但你的应用cpu和mem的耗费比可能是1:3 关系。
阿里云新一代云计算体系架构 CIPU 到底是啥?超全技术解读来了 软件优化终有尽,软硬兼修。我一直觉这些问题只要你的规模足够大,你服务的客户足够多,你最终一定都会遇到这些问题。因为我们规模走在前面,有可能我们先看到别人看不到的风景,所以我们先走到这一步。如果别人没看到这个风景,不一定觉得该这样做,但是对我们来讲最终一定是这样一个路径。我们看到了别人没有看到的风景,所以我知道做这件事情很有用,但是很多人其实不知道这个事情是不是有用。对于云的深刻理解,我们认为这也是另外一个门槛。这里的认知,在蒋林泉看来其实是由规模决定的。正是由于客户规模的激增、需求的暴涨,从而带来了一系列的新问题,而当传统的方式并不能解决它们之时,创新就成了必然选择。越是深刻理解客户,就越能感受到不足,从而下定决心去做难而正确的事情。艰难险阻,终成壁垒。
- 从2018到2022年,Intel CPU 提升了 2 倍,DDR 带宽提升了 2.4 倍,单网卡(包含网卡连接的以太交换网络)带宽提升了 4 倍,单 NVMe 带宽提升了 3.7 倍,整机 PCIe 带宽提升 6.7 倍,计算、网络、存储等基础设施层面发展的不同步,将对数据库和大数据等 PaaS 层的系统架构产生关键影响
- CPU擅长的领域是指令集处理,并不擅长并行计算和网络控制。这也是为什么和AI相关的计算,需要用GPU、和网络传输相关的应用需要网卡芯片的原因;大数据势必伴随着大量的数据搬运和迁移,带来的是高带宽的需求,而CPU没办法提供高带宽;现在的云计算的规模都太大了,动辄几十万上百万台服务器的规模,这就给整个系统的管理增加了极高的复杂度。而CPU作为一种通用芯片,很难兼顾复杂度、低延时和高性能。很多芯片公司都意识到了这个问题,并且给出了他们的解决方案。比如英特尔就提出了IPU、也就是基础设施处理器,而英伟达也推出了DPU、也就是数据处理器。不管是IPU、DPU,他们的本质都是类似的,都是对以CPU为核心的云计算架构的补充和扩展。它们能把CPU不擅长的工作接下来,转移到自己身上更高效的完成,这样就减轻了CPU的压力。
- 从芯片本身的功能来看,阿里云的云基础设施处理器CIPU可能和DPU或者IPU没有本质的区别,也就是对网络、计算、存储三大资源的卸载、加速和隔离。但它最大的特点,就是它采用了一种完全不同的数据中心体系结构。
- 在数据流动(移动)过程中,通过深度垂直软硬件协同设计,尽最大可能减少数据移动,以此提升计算效率。因此,CIPU 在计算机体系架构视角的主要工作是:优化云计算服务器之间和服务器内部的数据层级化 cache、内存和存储的访问效率。
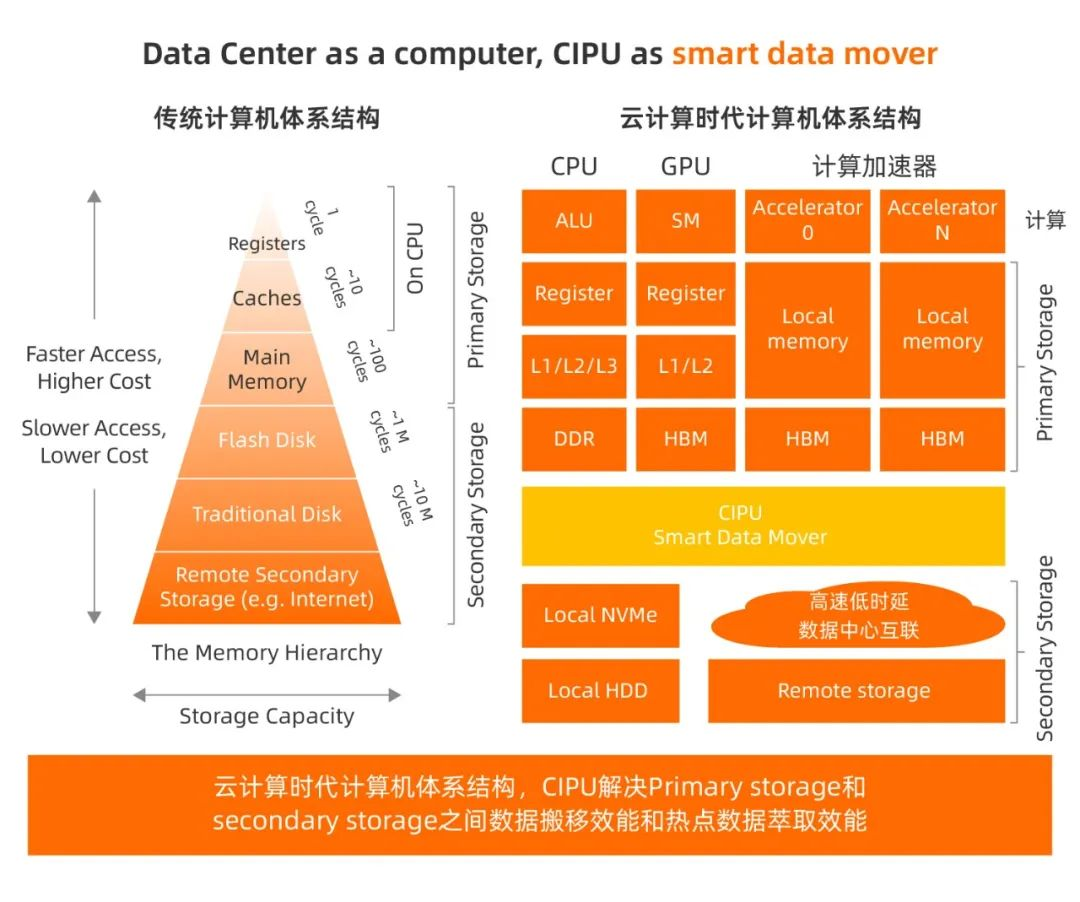
- CIPU 位于网络和存储必经之路,一方面把存储和计算进行了存算分离,能在芯片层面直接支持存储设备的硬件虚拟化。不需要CPU的介入,存储设备的性能也能大幅提升。CIPU还支持多个节点之间通过NVMe协议共享云盘块存储,更好的实现存储资源的池化。
Intel IPU,全名基础设施处理器(Infrastructure Processing Unit),是一种可编程网络设备,当前主要应用场景是大型云服务提供商。
- 在典型企业数据中心中,CPU总管一切任务。但在云上,要运行的任务不仅有业务程序,还有基础设施的支持程序。IPU所做的事,就是替代CPU承担运行基础设施软件的任务,从而让服务器CPU更好地聚焦在为云服务租户提供更大性能价值的任务上。具体而言,IPU主要处理网络虚拟化、存储虚拟化、网络存储管理以及安全等基础设施功能,此前,传统智能网卡SmartNIC主要做安全加速网络和存储基础设施,但仍受CPU来控制、管理、编程,更多用在通信服务等场景。而IPU是SmartNIC的进化,内置CPU核,不仅能实现安全地加速任务,而且可编程,能承担控制管理任务。
- 优化过的IPU具有加速功能,更擅长处理存储协议,压缩,解压缩,加密校验等事务,由于CPU不用管这些了,所以,云服务提供商可以把整个CPU都给用户。英特尔的IPU提供存储管理功能,而要管理的硬盘不在服务器内部,而是在通过网络连接的外部共享存储上,这里说的是所有硬盘都不在服务器上,甚至连系统启动盘也不在服务器内部,创建云主机的时候才在共享存储上创建个虚拟的NVMe固态盘。这种服务器上没有硬盘的架构被称作是Diskless架构,服务器架构得以简化,意味着成本降低,整个存储的管理无需CPU进行任何干预,意味着CPU开销的降低。
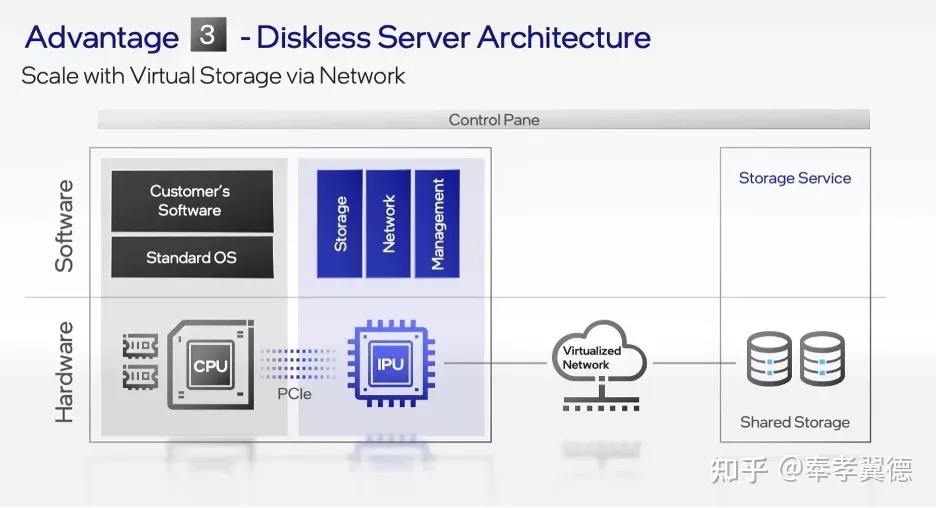
PS:有了CIPU/IPU,基于CIPU 和 CPU 两个核心的os 如何设计,os 以运行在CIPU 为主,执行进程时委托给CPU?就像cpu 调用gpu那样?
留下评论