linux vfs轮廓
简介
许式伟:怎么让很多的软件进程同时使用这些外置存储设备,而不会乱呢?直接基于物理的存储地址进行读写肯定是行不通的,过上几个月你自己可能都不记得什么数据写到哪里了。所以和内存管理不同,外部存储的管理,我们希望这些写到存储中的数据是“自描述”的某种数据格式,我们可以随时查看之前写了哪些内容,都什么时候写的。这就是文件系统的来源。
许式伟:存储它不应该只能保存一个文件,而是应该是多个。既然是多个,就需要组织这些文件。那么,怎么组织呢?操作系统的设计者们设计了文件系统这样的东西,来组织这些文件。虽然文件系统的种类有很多(比如:FAT32、NTFS、EXT3、EXT4 等等),但是它们有统一的抽象:文件系统是一颗树;节点要么是目录,要么是文件;文件必然是叶节点;根节点是目录,目录可以有子节点。
存储数据的介质可以是内存,也可以是硬盘,但这两种介质都只能提供数据存储能力,并没有数据组织的能力。比如,当我把一个文件存到内存或硬盘的某一个位置之后,如果我不记录这个位置,后面是无法再找到这个文件的。所以,在有了内存和硬盘这些存储介质之后,我们还需要一种机制,来记录各种文件和目录的存放位置,以及后期对它们的检索能力,而这种机制,就叫做文件系统。文件系统以文件和树形目录的抽象逻辑概念代替了硬盘和光盘等物理设备中的数据块的概念,用户使用文件系统来保存数据时,只需要知道文件路径而不必关心数据实际保存在硬盘的数据块地址。设备上存储空间的分配和释放由文件系统自动完成,用户只需要记住数据被存入哪个文件即可。
IO 栈
我们习惯了网络协议栈,但很少提io栈。请描述一下文件的 io 栈?
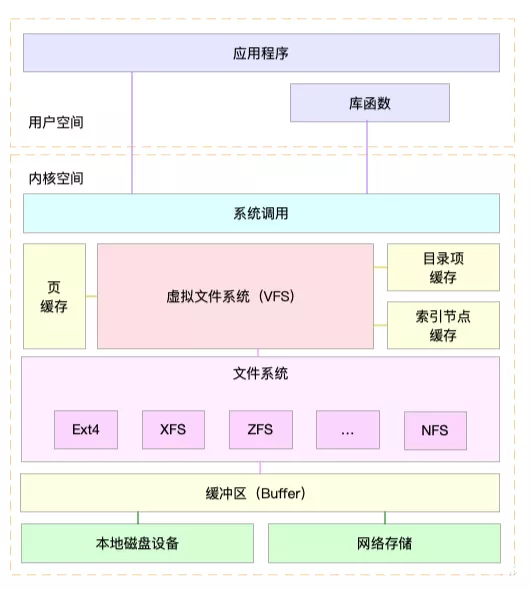
- IO 从用户态走系统调用进到内核,内核的路径:VFS → 文件系统 → 块层 → SCSI 层 。
- VFS ( Virtual File System 、Virtual FileSystem Switch )层是 Linux 针对文件概念封装的一层通用逻辑,它做的事情其实非常简单,就是把所有文件系统的共性的东西抽象出来,比如 file ,inode ,dentry 等结构体,针对这些结构体抽象出通用的 api 接口,然后具体的文件系统则只需要按照接口去实现这些接口即可,在 IO 下来的时候,VFS 层使用到文件所在的文件系统的对应接口。它的作用:为上层抽象统一的操作界面,在 IO 路径上切换不同的文件系统。
- 文件系统,对上抽象一个文件的概念,把数据按照策略存储到块设备上。文件系统管理的是一个线性的空间(分区,块设备),而用户看到的却是文件的概念,这一层的转化就是文件系统来做的。它负责把用户的数据按照自己制定的规则存储到块设备上。比如是按照 4K 切块存,还是按照 1M 切块存储,这些都是文件系统自己说了算。它这一层就是做了一层空间的映射转化,文件的虚拟空间到实际线性设备的映射。这层映射最关键的是 address_space 相关的接口来做。
- 块层,块层其实在真实的硬件之上又抽象了一层,屏蔽不同的硬件驱动,块设备看起来就是一个线性空间而已。块层主要还是 IO 调度策略的实现,尽可能收集批量 IO 聚合下发,让 IO 尽可能的顺序,合并 IO 请求减少 IO 次数等等;划重点:块层主要做的是 IO 调度策略的一些优化。比如最出名的电梯算法就是在这里。Linux 块层 IO 子系统
- SCSI 层,SCSI 层这个就不用多说了,这个就是硬件的驱动而已,本质就是个翻译器。SCSI 层里面按照细分又会细分多层出来。它是给你的磁盘做最后一道程序,SCSI 层负责和磁盘硬件做转换,IO 交给它就能顺利的到达磁盘硬件。
进程与文件系统
进程的文件位置等信息(当前目录等)是由 fs_struct 来描述的
//file:include/linux/fs_struct.h
struct fs_struct {
...
struct path root, pwd;
};
//file:include/linux/path.h
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
};
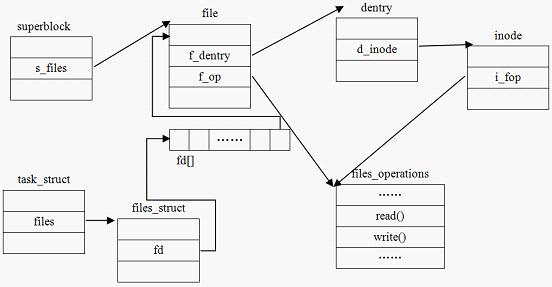
进程打开的文件信息:每个进程用一个 files_struct 结构来记录文件描述符的使用情况
//file:include/linux/fdtable.h
struct files_struct {
......
int next_fd; //下一个要分配的文件句柄号
struct fdtable __rcu *fdt; //fdtable
}
struct fdtable {
struct file __rcu **fd; //当前的文件数组
......
};
fdtable.fd数组的下标就是文件描述符,其中 0、1、2 三个描述符总是默认分配给标准输入、标准输出和标准错误。这就是你在shell 命令中经常看到的 2>&1的由来,在数组元素中记录了当前进程打开的每一个文件的指针。这个文件是 Linux 中抽象的文件,可能是真的磁盘上的文件,也可能是一个 socket。
vfs
文件系统的种类有很多,比如我们常见的基于硬盘的文件系统ext4,以及基于内存的文件系统sysfs。不同文件系统在内核里的实现各不相同,为了给使用者提供一套统一的接口,linux内核抽象出了vfs (virtual filesystem)层,即虚拟文件系统层,这样,当我们想要访问某个文件时,只用调用vfs的对应函数就好了,vfs会帮我们调用底层真实文件系统的对应函数,以此来获得文件数据。从文件 I/O 看 Linux 的虚拟文件系统
- 文件系统为应用程序提供了一个逻辑视图,具体是一棵倒立的树结构,方便用户管理众多文件。
- 内部实现:Linux 对超级块结构/superblock、目录结构/dentry,inode 结构以及数据块做了抽象,把这些结构加入了操作函数集合,形成了 VFS,即虚拟文件系统。只要软件模块能提供上述四大核心结构的操作函数集合,生成超级块结构,就可以形成一个文件系统实例,安装到 VFS 中。有了 VFS 层就可以向上为应用程序提供统一的接口,向下兼容不同的文件系统,让 Linux 能够同时安装不同的文件系统。
VFS 的基本概念
VFS 目的是为了屏蔽各种各样不同文件系统的相异操作形式,使得异构的文件系统可以在统一的形式下,以标准化的方法访问、操作。实现VFS 利用的主要思想是引入一个通用文件模型——该模型抽象出了文件系统的所有基本操作(该通用模型源于Unix风格的文件系统),比如读、写操作等。就必须要定义一组通用的数据结构,规范各个文件系统的实现,每种结构都对应一套回调函数集合,这是典型的面向对象的设计方法。这些数据结构包含描述文件系统信息的超级块、表示文件名称的目录结构、描述文件自身信息的索引节点结构、表示打开一个文件的实例结构。
- VFS 通过树状结构来管理文件系统,树状结构的任何一个节点都是“目录节点”
- 树状结构具有一个“根节点”
- VFS 通过“超级块”来了解一个具体文件系统的所有需要的信息。具体文件系统必须先向VFS注册,注册后,VFS就可以获得该文件系统的“超级块”。
- 具体文件系统可被安装到某个“目录节点”上,安装后,具体文件系统才可以被使用
- 用户对文件的操作,就是通过VFS 的接口,找到对应文件的“目录节点”,然后调用该“目录节点”对应的操作接口。
超级块、目录结构、文件索引节点,打开文件的实例,通过四大对象就可以描述抽象出一个文件系统了。而四大对象的对应的操作函数集合,又由具体的文件系统来实现,这两个一结合,一个文件系统的状态和行为都具备了。
安装文件系统
一个具体的文件系统必须先向vfs注册,才能被使用。通过register_filesystem() ,可以将一个“文件系统类型”结构 file_system_type注册到内核中一个全局的链表file_systems 上。文件系统注册的主要目的,就是让 VFS 创建该文件系统的“超级块”结构。
安装一个文件系统,必须指定一个目录作为安装点。一个设备可以同时被安装到多个目录上。 一个目录节点下可以同时安装多个设备。
“安装点”是已经存在的一个目录节点。例如把 /dev/sda1 安装到 /mnt/win 下,那么 /mnt/win 就是“安装点”。 可是文件系统要先安装后使用。因此,要使用 /mnt/win 这个“安装点”,必然要求它所在文件系统已也经被安装。 也就是说,安装一个文件系统,需要另外一个文件系统已经被安装。这是一个鸡生蛋,蛋生鸡的问题:最顶层的文件系统是如何被安装的?答案是,最顶层文件系统在内核初始化的时候被安装在“根安装点”上的,而根安装点不属于任何文件系统,它对应的 dentry 、inode 等结构是由内核在初始化阶段构造出来的。
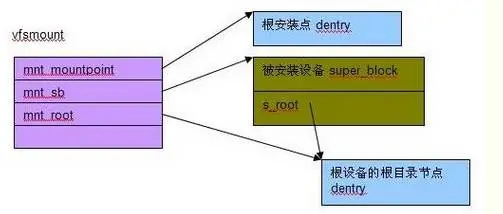
“安装”一个文件系统涉及“被安装设备”和“安装点”两个部分,安装的过程就是把“安装点”和“被安装设备”关联起来,这是通过一个“安装连接件”结构 vfsmount 来完成的。vfsmount 将“安装点”dentry 和“被安装设备”的根目录节点 dentry 关联起来。
所以,在安装文件系统时,内核的主要工作就是:
- 创建一个 vfsmount
- 为“被安装设备”创建一个 super_block,并由具体的文件系统来设置这个 super_block。
- 为被安装设备的根目录节点创建 dentry
- 为被安装设备的根目录节点创建 inode, 并由
super_operations->read_inode()来设置此 inode - 将 super_block 与“被安装设备“根目录节点 dentry 关联起来
- 将 vfsmount 与“被安装设备”的根目录节点 dentry 关联起来
Linux为什么不能像Windows那样自动mount?Unix-like的操作系统不支持自动mount原因是为了权限控制。POSIX权限的概念出现的很早,Unix、Linux都是支持POSIX权限的。那么对于一个新设备来说,操作系统不是很确定是不是所有用户都对这个设备有访问权限,这种情况下,如果自动mount,那么这个设备的内容就可能会被所有用户看到,这样会有安全的隐患。所以Unix和Linux才要求必须先mount,并且mount命令必须要用root权限,也就是说对于一个未知的设备,必须由root来决定是不是可用的。Linux可以配置自动mount,但这个配置的过程本身也需要root权限;Linux也允许用户通过编辑fstab来设置挂载点,但fstab编辑也需要root权限。
打开文件
例如要打开 /mnt/win/dir1/abc 这个文件,就是根据这个路径,找到‘abc’ 对应的 dentry ,进而得到 inode 的过程。
- 首先找到根文件系统的根目录节点 dentry 和 inode
- 由这个 inode 提供的操作接口 i_op->lookup(),找到下一层节点 ‘mnt’ 的 dentry 和 inode
- 由 ‘mnt’ 的 inode 找到 ‘win’ 的 dentry 和 inode
- 由于 ‘win’ 是个“安装点”,因此需要找到“被安装设备”/dev/sda1 根目录节点的 dentry 和 inode,只要找到 vfsmount B,就可以完成这个任务。
- 然后由
/dev/sda1根目录节点的 inode 负责找到下一层节点 ‘dir1’ 的 dentry 和 inode - 由于 dir1 是个“安装点”,因此需要借助 vfsmount C 找到
/dev/sda2的根目录节点 dentry 和 inode - 最后由这个 inode 负责找到 ‘abc’ 的 dentry 和 inode
一个文件每被打开一次,就对应着一个 file 结构。 我们知道,每个文件对应着一个 dentry 和 inode,每打开一个文件,只要找到对应的 dentry 和 inode 不就可以了么?为什么还要引入这个 file 结构?这是因为一个文件可以被同时打开多次,每次打开的方式也可以不一样。 而dentry 和 inode 只能描述一个物理的文件,无法描述“打开”这个概念。因此有必要引入 file 结构,来描述一个“被打开的文件”。每打开一个文件,就创建一个 file 结构。实际上,打开文件的过程正是建立file, dentry, inode 之间的关联的过程。
在遍历路径的过程中,会逐层地将各个路径组成部分解析成目录项对象,如果此目录项对象在目录项缓存中,则直接从缓存中获得;如果该目录项在缓存中不存在,则进行一次实际的读盘操作,从磁盘中读取该目录项所对应的索引节点。得到索引节点后,则建立索引节点与该目录项的联系。如此循环,直到最终找到目标文件对应的目录项,也就找到了索引节点,这样就建立了文件对象与实际的物理文件的关联。

文件对象所对应的文件操作函数 列表是通过索引结点的域i_fop得到的
rootfs
linux内核中根文件系统的初始化及init程序的运行当在a进程里创建一个b进程时,内核会以a进程结构体为模板,拷贝一个新的进程结构体,然后再根据b进程的要求,对这个结构体进行修改,最终修改后的结构体,就是b进程。之所以要以拷贝a进程结构体的方式创建b进程,是因为b进程中很多信息,要继承自a进程,比如,b进程所属的根目录以及当前目录,就是继承自a进程的。既然子进程是通过继承父进程数据的方式,来获取其所属的根目录以及当前目录的,那第一个init进程的根目录和当前目录是从哪里继承的呢?init进程的根目录和当前目录,其实是继承自内核里面的init_task。init_task是内核里定义的一个全局变量,其类型为struct task_struct结构体,也就是进程所使用的结构体。进程所有的初始信息,都被定义在了init_task指向的这个结构体里,我们可以把它看成是其他进程的模板。
每个文件系统实例都有自己独有的根目录,那这些文件系统实例,是如何组成一个统一的目录体系呢?其实就是通过挂载的方式,比如b文件系统实例的根目录,挂载到a文件系统实例的/mnt目录下,那以后我们在访问a文件系统实例的/mnt目录时,其实访问的就是b文件系统实例的根目录。根文件系统实例是在内核启动时创建的,也就是说,在那个时候,才会对init_task->init_fs里的root和pwd字段进行初始化。init_mount_tree -> vfs_kern_mount创建了一个根文件系统实例,该文件系统的类型是rootfs,它是一个基于内存的文件系统。在拿到这个文件系统实例mnt之后,我们就可以通过mnt->mnt_root字段,获取其对应的根目录。这个根目录被赋值到root.dentry字段里,然后root变量又通过set_fs_pwd和set_fs_root函数,被赋值为current指向的进程的当前目录和根目录。此时,init_task所属的根目录和当前目录,指向的就是rootfs文件系统实例的根目录。我们在有了这个目录体系之后,后面就会在这个目录树里寻找init程序,然后启动它,作为linux系统里的第一个进程。
为了提供一个目录体系,我们创建了一个rootfs文件系统实例,是一个基于内存的文件系统,它内部现在除了一个空的根目录之外,是没有任何其他文件或目录的,但为挂载真正的根文件系统提供了基础。rootfs并不是最终的真正的根文件系统,它只是在内核启动过程中,用于临时过渡的一个文件系统,我们真正的根文件系统一般是存储于硬盘的,类型一般是ext4。内核的逻辑继续往下执行,最终会尝试在各种地方寻找init程序,并把它作为第一个进程开始执行(比如systemd)。
rootfs是基于内存的文件系统,所有操作都在内存中完成;也没有实际的存储设备,所以不需要设备驱动程序的参与。基于以上原因,Linux在启动阶段使用rootfs文件系统。
参见https://www.kernel.org/doc/Documentation/filesystems/ramfs-rootfs-initramfs.txt
What is initramfs?
All 2.6 Linux kernels contain a gzipped “cpio” format archive, which is extracted into rootfs when the kernel boots up. After extracting, the kernel checks to see if rootfs contains a file “init”, and if so it executes it as PID1. If found, this init process is responsible for bringing the system the rest of the way up, including locating and mounting the real root device (if any). If rootfs does not contain an init program after the embedded cpio archive is extracted into it, the kernel will fall through to the older code to locate and mount a root partition, then exec some variant of /sbin/init out of that.
所以一个linux的启动过程经历了rootfs ==> 挂载initramfs ==> 挂载磁盘上的真正的fs。为什么还要使用initramfs呢?因为,现实中的根文件系统的挂载过程可能非常复杂,因为根文件系统并不一定存在于本地硬盘上,它可能是在一个网络节点上,甚至它还有可能被压缩被加密等等,如果想在内核里处理所有这些情况,是完全不现实的。所以,内核的当前状态是,提供了一个内置的挂载简单根文件系统的逻辑,而针对复杂的根文件系统挂载,则可以使用initramfs的方式,由用户自行处理。
存储之道 - 51CTO技术博客 中的《一个IO的传奇一生》
实现文件系统
基于FUSE
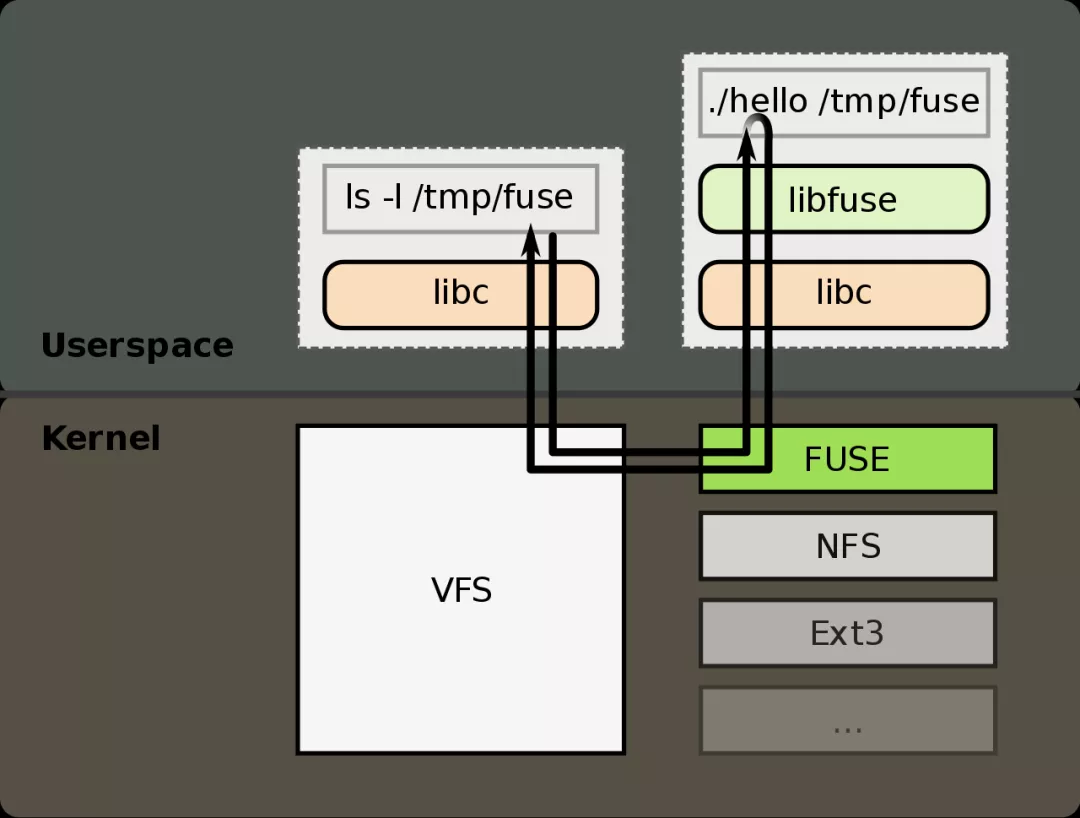
该图表达的意思有以下几个:
- 背景:一个用户态文件系统,挂载点为 /tmp/fuse ,用户二进制程序文件为 ./hello ;
- 当执行 ls -l /tmp/fuse 命令的时候,流程如下:
- IO 请求先进内核,经 vfs 传递给内核 FUSE 文件系统模块;
- 内核 FUSE 模块把请求发给到用户态,由 ./hello 程序接收并且处理。处理完成之后,响应原路返回; 内核 fuse.ko 用于承接 vfs 下来的 io 请求,然后封装成 FUSE 数据包,通过 /dev/fuse 这个管道传递到用户态。守护进程监听这个管道,看到有消息出来之后,立马读出来,然后利用 libfuse 库解析协议。PS: 听起来跟一个rpc 协议差不多
以实现一个 hellofs 为例。PS: 把实现文件系统整的跟web 开发一样
func main() {
var mountpoint string
flag.StringVar(&mountpoint, "mountpoint", "", "mount point(dir)?")
flag.Parse()
if mountpoint == "" {
log.Fatal("please input invalid mount point\n")
}
// 建立一个负责解析和封装 FUSE 请求监听通道对象;
c, err := fuse.Mount(mountpoint, fuse.FSName("helloworld"), fuse.Subtype("hellofs"))
if err != nil {
log.Fatal(err)
}
defer c.Close()
// 把 FS 结构体注册到 server,以便可以回调处理请求
err = fs.Serve(c, FS{})
if err != nil {
log.Fatal(err)
}
}
// hellofs 文件系统的主体
type FS struct{}
func (FS) Root() (fs.Node, error) {
return Dir{}, nil
}
// hellofs 文件系统中,Dir 是目录操作的主体
type Dir struct{}
func (Dir) Attr(ctx context.Context, a *fuse.Attr) error {
a.Inode = 20210601
a.Mode = os.ModeDir | 0555
return nil
}
// 当 ls 目录的时候,触发的是 ReadDirAll 调用,这里返回指定内容,表明只有一个 hello 的文件;
func (Dir) Lookup(ctx context.Context, name string) (fs.Node, error) {
// 只处理一个叫做 hello 的 entry 文件,其他的统统返回 not exist
if name == "hello" {
return File{}, nil
}
return nil, syscall.ENOENT
}
// 定义 Readdir 的行为,固定返回了一个 inode:2 name 叫做 hello 的文件。对应用户的行为一般是 ls 这个目录。
func (Dir) ReadDirAll(ctx context.Context) ([]fuse.Dirent, error) {
var dirDirs = []fuse.Dirent
return dirDirs, nil
}
// hellofs 文件系统中,File 结构体实现了文件系统中关于文件的调用实现
type File struct{}
const fileContent = "hello, world\n"
// 当 stat 这个文件的时候,返回 inode 为 2,mode 为 444
func (File) Attr(ctx context.Context, a *fuse.Attr) error {
a.Inode = 20210606
a.Mode = 0444
a.Size = uint64(len(fileContent))
return nil
}
// 当 cat 这个文件的时候,文件内容返回 hello,world
func (File) ReadAll(ctx context.Context) ([]byte, error) {
return []byte(fileContent), nil
}
FUSE 能做什么?FUSE 能够转运 vfs 下来的 io 请求到用户态,用户程序处理之后,经由 FUSE 框架回应给用户。从而就可以把文件系统的实现全部放到用户态实现了。但是请注意,文件系统要实现对具体的设备的操作的话必须要使用设备驱动提供的接口,而设备驱动位于内核空间,这时可以直接读写块设备文件,就相当于只把文件系统摘到用户态,用户直接管理块设备空间。实现了 FUSE 的用户态文件系统有非常多的例子,比如,GlusterFS,SSHFS,CephFS,Lustre,GmailFS,EncFS,S3FS等等
彭东《操作系统实战》
文件系统只是一个设备,文件系统一定要有储存设备,HD 机械硬盘、SSD 固态硬盘、U 盘、各种 TF 卡等都属于存储设备,这些设备上的文件储存格式都不相同,甚至同一个硬盘上不同的分区的储存格式也不同。这个储存格式就是相应文件系统在储存设备上组织储存文件的方式。不难发现让文件系统成为 Cosmos 内核中一部分,是个非常愚蠢的想法。因此:文件系统组件是独立的与内核分开的;第二,操作系统需要动态加载和删除不同的文件系统组件。
关于文件系统存放文件数据的格式,类 UNIX 系统和 Windows 系统都采用了相同的方案,那就是逻辑上认为一个文件就是一个可以动态增加、减少的线性字节数组。我们如何把这个逻辑上的文件数据字节数组,映射到具体的储存设备上呢?现在的机械硬盘、SSD 固态硬盘、TF 卡,它们都是以储存块为单位储存数据的,一个储存块的大小可以是 512、1024、2048、4096 字节,访问这些储存设备的最小单位也是一个储存块,不像内存设备可以最少访问一个字节。
现在 PC 机上的文件数量都已经上十万的数量级了,如果把十万个文件顺序地排列在一起,要找出其中一个文件,那是非常困难的,所以,需要一个叫文件目录或者叫文件夹的东西,我们习惯称其为目录。这样我们就可以用不同的目录来归纳不同的文件。可以看出,整个文件层次结构就像是一棵倒挂的树。
// 文件系统的超级块或者文件系统描述块
typedef struct s_RFSSUBLK
{
spinlock_t rsb_lock; //超级块在内存中使用的自旋锁
uint_t rsb_mgic; //文件系统标识
uint_t rsb_vec; //文件系统版本
uint_t rsb_flg; //标志
uint_t rsb_stus; //状态
size_t rsb_sz; //该数据结构本身的大小
size_t rsb_sblksz; //超级块大小
size_t rsb_dblksz; //文件系统逻辑储存块大小,我们这里用的是4KB
uint_t rsb_bmpbks; //位图的开始逻辑储存块
uint_t rsb_bmpbknr; //位图占用多少个逻辑储存块
uint_t rsb_fsysallblk; //文件系统有多少个逻辑储存块
rfsdir_t rsb_rootdir; //根目录,后面会看到这个数据结构的
}rfssublk_t;
// 目录
typedef struct s_RFSDIR
{
uint_t rdr_stus; //目录状态
uint_t rdr_type; //目录类型,可以是空类型、目录类型、文件类型、已删除的类型
uint_t rdr_blknr; //指向文件数据管理头的块号,不像内存可以用指针,只能按块访问
char_t rdr_name[DR_NM_MAX]; //名称数组,大小为DR_NM_MAX
}rfsdir_t;
// 文件,包含文件名、状态、类型、创建时间、访问时间、大小,更为重要的是要知道该文件使用了哪些逻辑储存块。
typedef struct s_fimgrhd
{
uint_t fmd_stus;//文件状态
uint_t fmd_type;//文件类型:可以是目录文件、普通文件、空文件、已删除的文件
uint_t fmd_flg;//文件标志
uint_t fmd_sfblk;//文件管理头自身所在的逻辑储存块
uint_t fmd_acss;//文件访问权限
uint_t fmd_newtime;//文件的创建时间,换算成秒
uint_t fmd_acstime;//文件的访问时间,换算成秒
uint_t fmd_fileallbk;//文件一共占用多少个逻辑储存块
uint_t fmd_filesz;//文件大小
uint_t fmd_fileifstbkoff;//文件数据在第一块逻辑储存块中的偏移
uint_t fmd_fileiendbkoff;//文件数据在最后一块逻辑储存块中的偏移
uint_t fmd_curfwritebk;//文件数据当前将要写入的逻辑储存块
uint_t fmd_curfinwbkoff;//文件数据当前将要写入的逻辑储存块中的偏移
filblks_t fmd_fleblk[FBLKS_MAX];//文件占用逻辑储存块的数组,一共32个filblks_t结构
uint_t fmd_linkpblk;//指向文件的上一个文件管理头的逻辑储存块
uint_t fmd_linknblk;//指向文件的下一个文件管理头的逻辑储存块
}fimgrhd_t;
// 基于上述结构的驱动程序
drvstus_t rfs_entry(driver_t* drvp,uint_t val,void* p){……}
drvstus_t rfs_exit(driver_t* drvp,uint_t val,void* p){……}
drvstus_t rfs_open(device_t* devp,void* iopack){……}
drvstus_t rfs_close(device_t* devp,void* iopack){……}
drvstus_t rfs_read(device_t* devp,void* iopack){……}
drvstus_t rfs_write(device_t* devp,void* iopack){……}
drvstus_t rfs_lseek(device_t* devp,void* iopack){……}
drvstus_t rfs_ioctrl(device_t* devp,void* iopack){……}
drvstus_t rfs_dev_start(device_t* devp,void* iopack){……}
drvstus_t rfs_dev_stop(device_t* devp,void* iopack){……}
drvstus_t rfs_set_powerstus(device_t* devp,void* iopack){……}
drvstus_t rfs_enum_dev(device_t* devp,void* iopack){……}
drvstus_t rfs_flush(device_t* devp,void* iopack){……}
drvstus_t rfs_shutdown(device_t* devp,void* iopack){……}
格式化操作并不是把设备上所有的空间都清零,而是在这个设备上重建了文件系统用于管理文件的那一整套数据结构。
Page Cache
请描述一下文件的 io 栈?page cache 是发生在文件系统层。通常我们确保数据落盘有两种方式:
- Writeback 回刷数据的方式:write 调用 + sync 调用;
- Direct IO 直刷数据的方式; 直接在用户路径上刷数据到磁盘,不走 PageCache 的逻辑,但并不是所有文件系统都会实现它。
在文件系统这一层,当处理完了一些自己的逻辑之后,需要把数据写到块层去,无论是直刷还是回刷的方式,都是用到 address_space_operations 里面实现的方法:
struct address_space_operations {
// 回刷的方式,走 Page Cache
int (*write_begin)(struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned copied, struct page *page, void *fsdata);
// 回刷的方式,走 Page Cache
int (*writepage)(struct page *page, struct writeback_control *wbc);
int (*readpage)(struct file *, struct page *);
int (*writepages)(struct address_space *, struct writeback_control *);
int (*readpages)(struct file *filp, struct address_space *mapping, struct list_head *pages, unsigned nr_pages);
void (*readahead)(struct readahead_control *);
// 直刷的方式
ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov, loff_t offset, unsigned long nr_segs);
// ...
};
如果实现一个走 Page Cache 回刷功能的文件系统,那么至少要实现 .write_begin,.write_end,.write_page,.read_page 的接口。
触发脏数据回刷的方式有多种:
- 时间久了,比如超过 30 秒的,那必须赶紧刷,因为夜长梦多;
- 量足够大了,比如脏页超过 100M 了,那必须赶紧刷,因为量越大,掉电丢数据的损失越大;
- 有人调用了 Sync ,那必须赶紧刷;
刷这些脏数据,内核是作为任务交给了 kworker 的线程去做。简单来讲就是这是 kworker 会去挑选块设备对应的的一些脏“文件”,把这些对应的 page 内存刷到磁盘。回刷的实现是文件系统提供的 .write_page 或者 .write_pages 的接口。
挂载方式
如果将mount的过程理解为:inode被替代的过程。除了将设备mount到rootfs上,根据被替代方式的不同,mount的花样可多了。
bind mount
mount --bind olddir newdir
ln分为软链接和硬链接
硬链接只能连文件 你删除它源文件就被删了
软链接相当于windows的快捷方式,文件和目录都可以连,但是你删出它只是删除的这个快捷方式
在操作系统中ln -s和mount -bind也许使用起来没多少差别,但是ftp目录里貌似不能放软连接。把一个文件夹mount到另一个地方,等于在把它挂载到那个地方当成一个磁盘,进到两个文件夹中操作 都是等价的,删除一个文件也会在两边同时删除。
union mount
联合文件系统是一种 堆叠文件系统,通过不停地叠加文件实现对文件的修改。其中,增加操作通过在读写层增加新文件实现,删除操作一般通过添加额外的删除属性文件实现,比如删除a.file时读写层增加一个a.file.delete文件。修改只读层文件时,需要先复制一份儿文件到读写层,然后修改复制的文件。
参见Union mount,In computer operating systems, union mounting is a way of combining multiple directories into one that appears to contain their combined contents.
union mount的使用场景——读写只读文件系统,As an example application of union mounting, consider the need to update the information contained on a CD-ROM or DVD. While a CD-ROM is not writable, one can overlay the CD’s mount point with a writable directory in a union mount. Then, updating files in the union directory will cause them to end up in the writable directory, giving the illusion that the CD-ROM’s contents have been updated.
Union FileSystem的核心逻辑是Union Mount,它支持把一个目录A和另一个目录B union,提供一个虚拟的C目录(目录union的语义)。对于特定的权限设置策略,如果设置A目录可写,B目录只读。用户对目录C的读取就是A加上B的内容,而对C目录里文件写入和改写则会保存在目录A上。这样,就有了A在B上层的感觉。 DOCKER基础技术:AUFS
留下评论