《深入拆解java 虚拟机》笔记
简介
从表到里学习JVM实现要了解JVM是如何实现的,首先必须要知道JVM到底是什么、不是什么,表面上应该提供怎样的功能。
虚拟机概论,推荐《Virtual Machines: Versatile Platforms for Systems and Processes》,帮助您了解“虚拟机”一词到底指代什么,有什么不同类型,大概有哪些实现方法,等等。读完这本书有助获得一个清晰的大局观。
为什么java 要在虚拟机里运行?
- java 作为高级语言,语法复杂,抽象程度高, 直接在硬件上运行难度大
- 可移植性
-
提供一个托管环境
- 帮我们处理一些代码冗长且容易出错的部分,比如垃圾回收
- 提供数据越界、动态类型检查等
-
就前两点来说,go runtime 也有同样的特性。go 也独立出一个 runtime 来支持如goroutine, channel, 以及Garbage collection,但Go语言程序是编译为机器代码来执行的。Analysis of the Go runtime scheduler
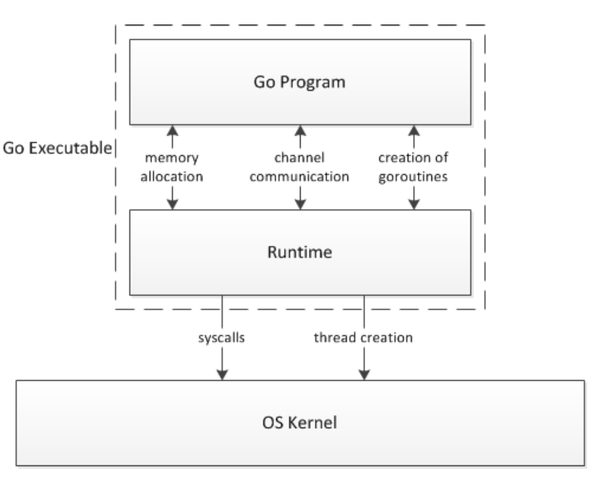
- java 运行时可以动态加载 磁盘或网络上的 class 文件运行,这是go runtime 所不支持的。
为什么jvm支持的指令序列称为字节码,因为其操作码被固定为一个字节。
java 代码是怎么运行的
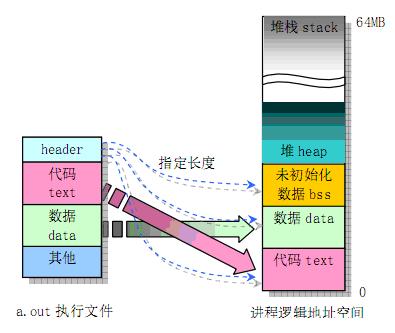
针对以下概念
- linux c 可执行文件格式(通常是elf)
- class 文件格式
- 进程 内存结构
可以肯定的是
- 为什么会有数据段。我们知道冯诺依曼体系将指令和数据存在一起。汇编指令,调用数据就那么几种方式:立即数,寄存器,和直接寻址,间址寻址。除了立即数,就必须是数据存在在一个地方,由指令根据地址去访问,这就是为什么要有数据段。可见,所谓指令和数据存在一起,直观上大部分更像是指令和地址存在一起。
- 指令访问 内存数据,内存地址 是 数据段地址 + 偏移 算出来的。
- jvm 进程 或者 其它linux 进程 都秉承同一个 进程内存结构,即主体是代码段 + 数据段(其它的如文字常量区 啥的也都一样)。数据段 分为 静态数据段 + 动态数据段。
- 动态数据段 分为 堆和栈,为什么要分开 参见《程序员的自我修养》小结
- 堆区 和 代码区 是所有线程共享的,栈区 是线程 独有的,或者说栈区 是thread safe的
class 文件 抽象了什么?
- 从机器码 到汇编码,操作码从0101变成了英文单词
- 然后是一个 大汇编文件 可以分别由几个小汇编文件组成,中间涉及到链接等
- 然后c 语言 ,将人从寄存器、操作码等机器细节中解脱出来。这个变换有点抖,欢迎大家补充。
- 我们说byte code可读性好很多,那么byte code构建于machine code之上,byte code相对于 machine code抽象了什么?a byte code is a virtualized machine code. Unlike machine code for a real processor, byte code is often for an idealized or virtual processor that doesn’t actually exist. Byte code is based on a CPU architecture like a register or stack machine but often uses general features common to any CPU or instructions and concepts that don’t exist on any CPU.
- byte code 是被解释执行,c语言代码 是被编译为 machine code 执行的,所以直接对比并不完全恰当。解释执行相对编译执行的 一个不同就是:解释执行是有上下文的,堆、栈、常量区、方法区 都是 byte code的的上下文。而machine code 单看 每一个行 code,操作码、操作数等都必须是精确的。
jvm 进程有以下不同:
- jvm 将栈细分为面向 java方法的java 方法栈、C++ native 方法的本地方法栈 以及 存放各个线程 执行位置的 pc 寄存器
- 与elf 文件与 进程 内存结构 比较 简单的对应关系不同,class 文件 会被jvm加载 到 方法区中。也就是说,不准确的说,class 文件所有内容 会进入jvm 方法区。
所以,不要将jvm 内存区域 看的那么特别。比如对于堆区,jvm 中的垃圾回收,c/c++ 因为是手动回收,自然没有gc问题。但两者 都有内存碎片问题,只是jvm 在内存回收的同时顺带 做了碎片整理。c主要是 还是靠os 基于页的管理来部分解决(碎片只会在虚拟内存中产生,是不会映射到物理内存上的),部分追求性能的 可以采用程序内部的局部内存池。
数据类型
分为
- 基本类型
-
引用类型
- 类
- 解口
- 数组类
- 泛型参数
在jvm 中,类的唯一性是由类加载器一以及类的全名一同确定的。这就可以解释 class.getClassLoader() 可以返回classLoader
InputStream in = Thread.currentThread().getContextClassLoader().getResourceAsStream("xx.properties"); 每一个线程还会有一个上下文类加载器, 这属于双亲委派模型的补丁, 可以看下Java类加载器之线程上下文类加载器(ContextClassLoader)
方法的执行过程
java语言、编译器、虚拟机、机器指令 其实也是一个通过分层 拆解复杂度的过程。比如java 语言 里有重载,jvm 识别方法的关键在于类名、方法名以及方法描述符(由方法的参数类型以及返回类型所构成), 因此不准确的说,jvm中不存在重载这一概念。
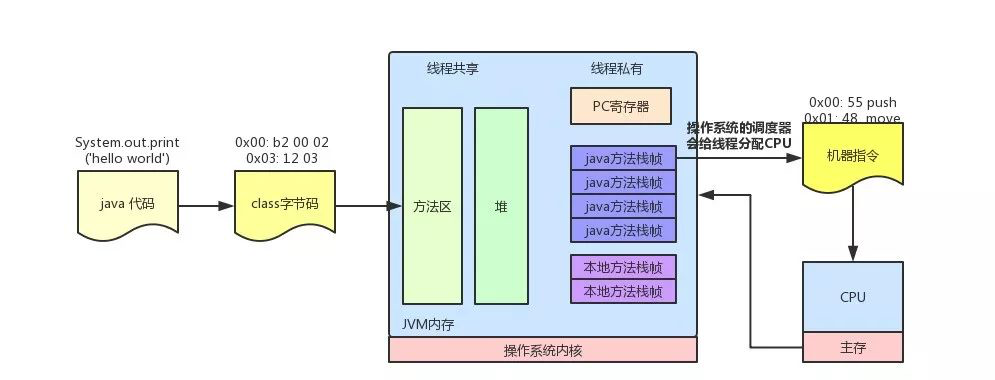
符号引用的转换
所谓“绑定” 就是讲 符号引用(编译器解阶段)绑定为 实际引用(jvm阶段)。
| 适用于 | 实际引用类型 | |
|---|---|---|
| 静态绑定 | 一般方法、重载 | 指向方法的指针 |
| 动态绑定 | 重写 | 一个方法表的索引 |
类加载阶段,会构造一个与该类相关联的方法表。
- 子类方法表中 包含 父类方法表中的所有方法
- 子类方法 在方法表中的索引值 与它所重写的父类方法的索引值 相同
一个class 文件 有多个组成,我以前只是知道 会将javap 中的字节码加载到 jvm方法区,其实是对常量池中的 符号引用 等还做了转换。 建议熟悉下 class 文件结构 实例分析JAVA CLASS的文件结构,虽然跟javap 的输出 顺序一致,但表示方式很不一样。
方法的执行
- 访问栈上的调用者,读取调用者的动态类型
- 读取该类型的方法表
- 读取方法表中某个索引值所对应的目标方法
很自然,为了加快 上述过程的速度,jvm 有两个优化手段:内联缓存和方法内联。
处理异常
- 栈帧(Stack Frame)是用于支持虚拟机进行方法调用和方法执行的数据结构
- 一个线程中的方法调用链可能会很长,很多方法都同时处于执行状态。对于执行引擎来讲,活动线程中,只有虚拟机栈顶的栈帧才是有效的,称为当前栈帧(Current Stack Frame),这个栈帧所关联的方法称为当前方法(Current Method)。执行引用所运行的所有字节码指令都只针对当前栈帧进行操作。
- java 编译器干了很多事,比如局部变量表、异常表都是在 编译阶段生成或确定的。
异常实例的构造十分昂贵,这是由于在构造异常实例时,java虚拟机便需要生成该异常的栈轨迹(stack trace)。该操作会逐一访问当前线程的java栈帧,并且记录下各种调试信息,包括栈帧所指向方法的名字、方法所在的类名、文件名,以及在代码中的第几行触发该异常。所以,不是异常对象占了多大地方,而是构造异常对象(主要指的是Stack Frame)非常麻烦。这个“昂贵”从代码层面就很难理解
当程序触发异常时,java 虚拟机会从上至下遍历异常表中的所有条目,如果匹配,则将控制流转移至该条目target 指针指向的字节码。若未找到,则会弹出当前方法对应的栈帧,在caller 方法中重复上述操作。最坏情况下,java 虚拟机需要遍历当前线程java栈上所有方法的异常表。
finally的处理,对当前jvm来说,是复制finally 代码块的内容 分别放在 try-catch 的后面。即实际是try - finally; catch finally
参见java 反射 学习下动态代理的本质。
留下评论