AQS1——论文学习
简介
论文地址:The java.util.concurrent synchronizer framework
译文系列 The j.u.c Synchronizer Framework翻译(一)背景与需求
introduction 部分
J2SE-1.5 introduces package java.util.concurrent, a collection of medium-level concurrency support classes(medium-level 的并发支持类) created via Java Community Process (JCP) Java Specification Request (JSR) 166.
Among these components are a set of synchronizers – abstract data type (ADT) classes that maintain an internal synchronization state (for example, representing whether a lock is locked or unlocked), operations to update and inspect that state, and at least one method that will cause a calling thread to block if the state requires it, resuming when some other thread changes the synchronization state to permit it. Examples include various forms of mutual exclusion locks, read-write locks, semaphores, barriers, futures, event indicators, and handoff queues.
abstract data type (ADT) classes 作者将同步器 描述为一个抽象的数据类型,包含几个要素
- an internal synchronization state
- operations to update and inspect that state
- at least one method that cause a calling thread to block if the state requires it, resuming when some other thread changes the synchronization state to permit it.
any synchronizer can be used to implement nearly any other.可以用一个同步器实现另一个同步器,就好像乘法可以换算为加法一样,但有几个问题
- doing so often entails enough complexity, overhead, and inflexibility to be at best a second-rate engineering option. 比较复杂,有性能瓶颈,是一个二流的实现方案。
- it is conceptually unattractive. If none of these constructs are intrinsically(本质的) more primitive than the others。 developers should not be compelled to arbitrarily choose one of them as a basis for building others. 所有同步器 都属于同一个抽象层次,以一个为基础实现另一个不科学。
因此,提出了一个AQS,自己(而不是借助于os锁)实现了同步器都会用到的 排队、唤醒、”阻塞“队列等特性
实现同步器要考虑的几个问题
为什么要同步?
线程同步出现的根本原因是访问公共资源需要多个操作,而这多个操作的执行过程不具备原子性,被任务调度器分开了,而其他线程会破坏共享资源,所以需要在临界区做线程的同步,这里我们先明确一个概念,就是临界区,它是指多个任务访问共享资源如内存或文件时候的指令,它是指令并不是受访问的资源。POSIX 定义了五种同步对象:互斥锁,条件变量,自旋锁,读写锁,信号量,这些对象在 JVM 中也都有对应的实现。
实现什么
同步器有两类(注意不是两个)方法:acquire和release,但java 没有定义类似interface Synchronizer 的接口,因此acquire 和 release 就衍生出诸多称谓:
- Lock.lock
- Semaphore.acquire
- CountDownLatch.await
- FutureTask.get 这次我第一次看到将Future 与 同步器串联起来
并且acquire 还有tryAcquire非阻塞版本、支持timeout版本、 Cancellability via interruption
同时,synchronizer 维护的state 还有 是否 exclusive的划分,即同时时刻是否允许多个线程通过
性能目标
-
公平性和aggregate throughput 的矛盾。
- 一个线程,占用了资源,但多久之后释放是不知道的,排队是公平的。对于连接池这类场景来说,公平性很重要。。但业务中若是大部分线程占用的时间短,少部分线程占用的时间长,则排队会影响线程通过的吞吐量
- 新的线程进来,总是先测试下state,不符合条件时才加入队列。此时,在高并发情况下,当state 可用时,实际上是新加入线程和队列头节点在竞争。按等待时间来说,这是不公平的,并且容易导致队列尾部的线程饥饿。
-
在cpu time requirements,memory traffic,thread scheduling 之间取得平衡.比如自旋锁,获取锁的速度倒是快,但是浪费cpu cycle,导致大量的memory contention,所以大部分时候不适用。
设计
synchronizer requires the coordination of three basic components:
- Atomically managing synchronization state
- Blocking and unblocking threads
- Maintaining queues
It might be possible to create a framework that allows each of these three pieces to vary independently。 同步器框架的核心决策是为这三个组件选择一个具体实现,同时在使用方式上又有大量选项可用 。这段话反映了一个很好的设计思路:
- 将同步器接口 acquire和release 具体为几个实际组件
- 组件之前可以各自抽象,彼此独立。(当然,AQS中没有这样做)
Concrete classes based on AbstractQueuedSynchronizer must define methods tryAcquire and tryRelease in terms of these exported state methods in order to control the acquire and release operations.
阻塞和恢复线程 参见Unsafe
队列
- The heart of the framework is maintenance of queues of blocked threads, which are restricted here to FIFO queues. 队列用来存储 blocked 线程,先进先出
- there is little controversy that the most appropriate choices for synchronization queues are non-blocking data structures. 同步队列的最佳选择是自身没有使用底层锁来构造的非阻塞数据结构,这样的locks有两种:MCS locks and CLH locks,因为后者对cancellation 和 timeout 的支持更好,因此选择了 CLH,并对其做了一些改动。
不管是业务层面的秒杀、还是数据库锁、还是操作系统锁,底层都是线程排队 线程排队
思维顺序
- 数据结构/容器层面,一般阻塞队列,锁其实可以变量的理解为一个长度为1的阻塞队列,put 成功就相当于获取到了锁
- 数据结构/容器层面,一般非阻塞队列/无锁队列 无锁队列
- 操作系统中的队列情况显式地提升到了应用层
- 并发/线程排队层面,CLH
- 并发/线程排队层面,AQS 对CLH 的改动
来龙去脉
Java AQS 核心数据结构-CLH 锁CLH 锁是对自旋锁的一种改良。自旋锁实现简单,同时避免了操作系统进程调度和线程上下文切换的开销,但他有两个缺点:
- 锁饥饿问题。在锁竞争激烈的情况下,可能存在一个线程一直被其他线程”插队“而一直获取不到锁的情况。
- 性能问题。在实际的多处理上运行的自旋锁在锁竞争激烈时性能较差。这是因为自旋锁锁状态中心化,在竞争激烈的情况下,锁状态变更会导致多个 CPU 的高速缓存的频繁同步,从而拖慢 CPU 效率。PS:cas 一写多读还好,多写多读时还不如抢不到锁就休眠。
因此自旋锁适用于锁竞争不激烈、锁持有时间短的场景。CLH 锁是对自旋锁的一种改进,有效的解决了以上的两个缺点。首先它将线程组织成一个队列,保证先请求的线程先获得锁,避免了饥饿问题。其次锁状态去中心化,让每个线程在不同的状态变量中自旋,这样当一个线程释放它的锁时,只能使其后续线程的高速缓存失效,缩小了影响范围,从而减少了 CPU 的开销。
另一个视角:如何实现一个高性能链表/队列,支持多个CPU并发crud节点?
- 第一反应,为链表准备一个mutex,先获取mutex,才能进行后续的crud。此时 mutex 成为性能热点,无法充分利用多核性能。
- 优化的第一反应: 分段 ==> 每个段一个锁 ==> 每个节点一个锁。背后的核心就是,要cud一个节点,必须先找到其前驱节点,其前驱节点上持有的锁就是保护 当前节点cud 操作的(细节很多,了解思路即可)。不操作同一个节点,就不会有竞争,按需竞争,在链表的任意节点处,最多只有一个cpu执行写操作,区域内一写多读,全局多写多读。 自旋锁是 得不到锁就一直自旋,多写多读时 cpu缓存频繁失效,效率也低。clh 则是得不到锁 不自旋了而是加入链表,这个链表 一方面承担容纳等待 线程容器的作用,一方面 把对全局锁的竞争转移到了前驱节点上。
传统CLH 队列
public class CLH {
private final ThreadLocal<Node> node = ThreadLocal.withInitial(Node:new);
private final AtomicReference<Node> tail = new AtomicReference<>(new Node());
private static class Node {
// 这个状态变量只会被持有该状态变量的线程写入,只会被队列中该线程的后驱节点对应的线程读,而且后者会轮询读取。因此,可见性问题不会影响锁的正确性。但要实现一个可以在多线程程序中正确执行的锁,还需要解决重排序问题。
private volatile boolean locked;
}
public void lock(){
Node node = this.node.get()
node.locked = true
Node pre = this.tail.getAndSet(node)
while (pre.locked);
}
public void unlock(){
final Node node = this.node.get();
node.locked = false
this.node.set(new Node())
}
}
The j.u.c Synchronizer Framework翻译(二)设计与实现
CLH队列实际上并不那么像队列,因为它的入队和出队操作都与它的用途(即用作锁)紧密相关。它是一个链表队列,通过两个字段head和tail来存取,这两个字段是可原子更新的,两者在初始化时都指向了一个空节点。
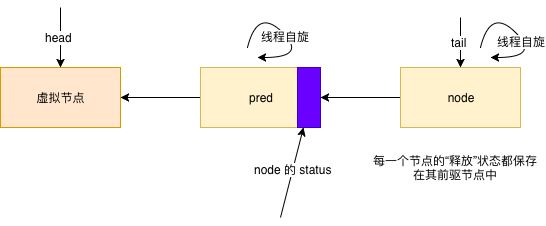
CLH 锁是一种隐式的链表队列,没有显式的维护前驱或后继指针。因为每个等待获取锁的线程只需要轮询前一个节点的状态就够了,而不需要遍历整个队列。在这种情况下,只需要使用一个局部变量保存前驱节点,而不需要显式的维护前驱或后继指针。
CLH 锁作为自旋锁的改进,有以下几个优点:
- 性能优异,获取和释放锁开销小。CLH 的锁状态不再是单一的原子变量,而是分散在每个节点的状态中,降低了自旋锁在竞争激烈时频繁同步的开销。在释放锁的开销也因为不需要使用 CAS 指令而降低了。
- 公平锁。先入队的线程会先得到锁。
- 实现简单,易于理解。
- 扩展性强。下面会提到 AQS 如何扩展 CLH 锁实现了 j.u.c 包下各类丰富的同步器。 当然,它也有两个缺点:
- 因为有自旋操作,当锁持有时间长时会带来较大的 CPU 开销。
- 基本的 CLH 锁功能单一,不改造不能支持复杂的功能。
AQS 对 CLH 的变动
针对 CLH 的缺点,AQS 对 CLH 队列锁进行了一定的改造。针对第一个缺点,AQS 将自旋操作改为阻塞线程操作。针对第二个缺点,AQS 对 CLH 锁进行改造和扩展,AQS 中的对 CLH 锁数据结构的改进主要包括三方面:扩展每个节点的状态、显式的维护前驱节点和后继节点以及诸如出队节点显式设为 null 等辅助 GC 的优化。
- 因为 AQS 用阻塞等待替换了自旋操作,线程会阻塞等待锁的释放,不能主动感知到前驱节点状态变化的信息。AQS 中显式的维护前驱节点和后继节点,需要释放锁的节点会显式通知下一个节点解除阻塞。
- AQS 每个节点的状态
volatile int waitStatus,提供了该状态变量的原子读写操作- SIGNAL 表示该节点正常等待
- PROPAGATE 应将 releaseShared 传播到其他节点
- CONDITION 该节点位于条件队列,不能用于同步队列节点
- CANCELLED 由于超时、中断或其他原因,该节点被取消
从JUC lock - AQS - CLH queue /【死磕Java并发】—–J.U.C之AQS:CLH同步队列 可以看到,acquire 和 release 和一般的无锁队列 是一致的
-
入队,先创建Node,然后cas 竞争tail 指向 Node
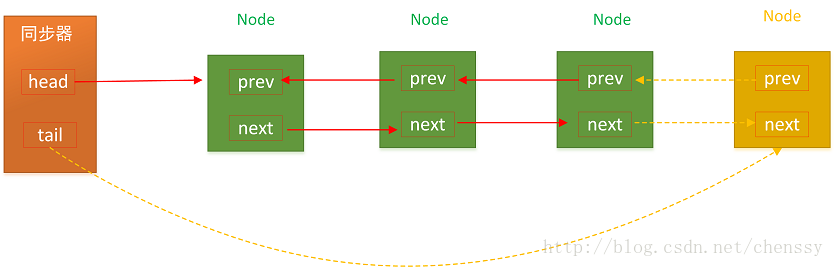
-
出队,cas 竞争head, 使得head 指向自己
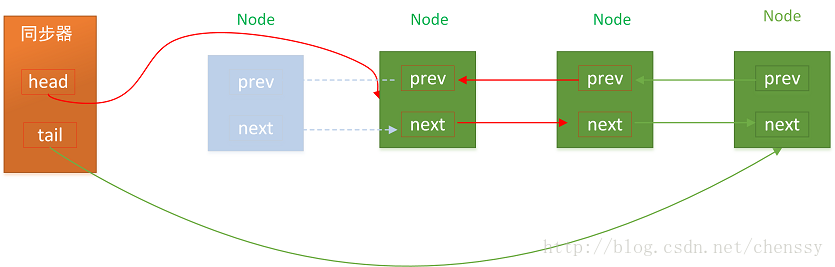
区别在于
- 入队后,设置前驱节点状态,告诉他:你释放锁的时候记得唤醒我,然后park 自己
- head 表示当前持有锁的节点,release操作 upark head 之后的线程
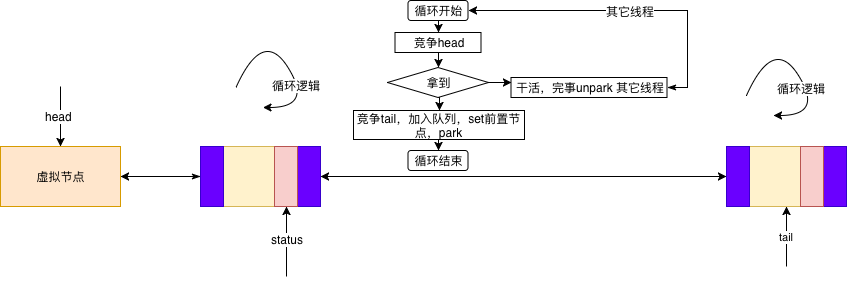
演化
晁岳攀:go Mutex 庖丁解牛看实现
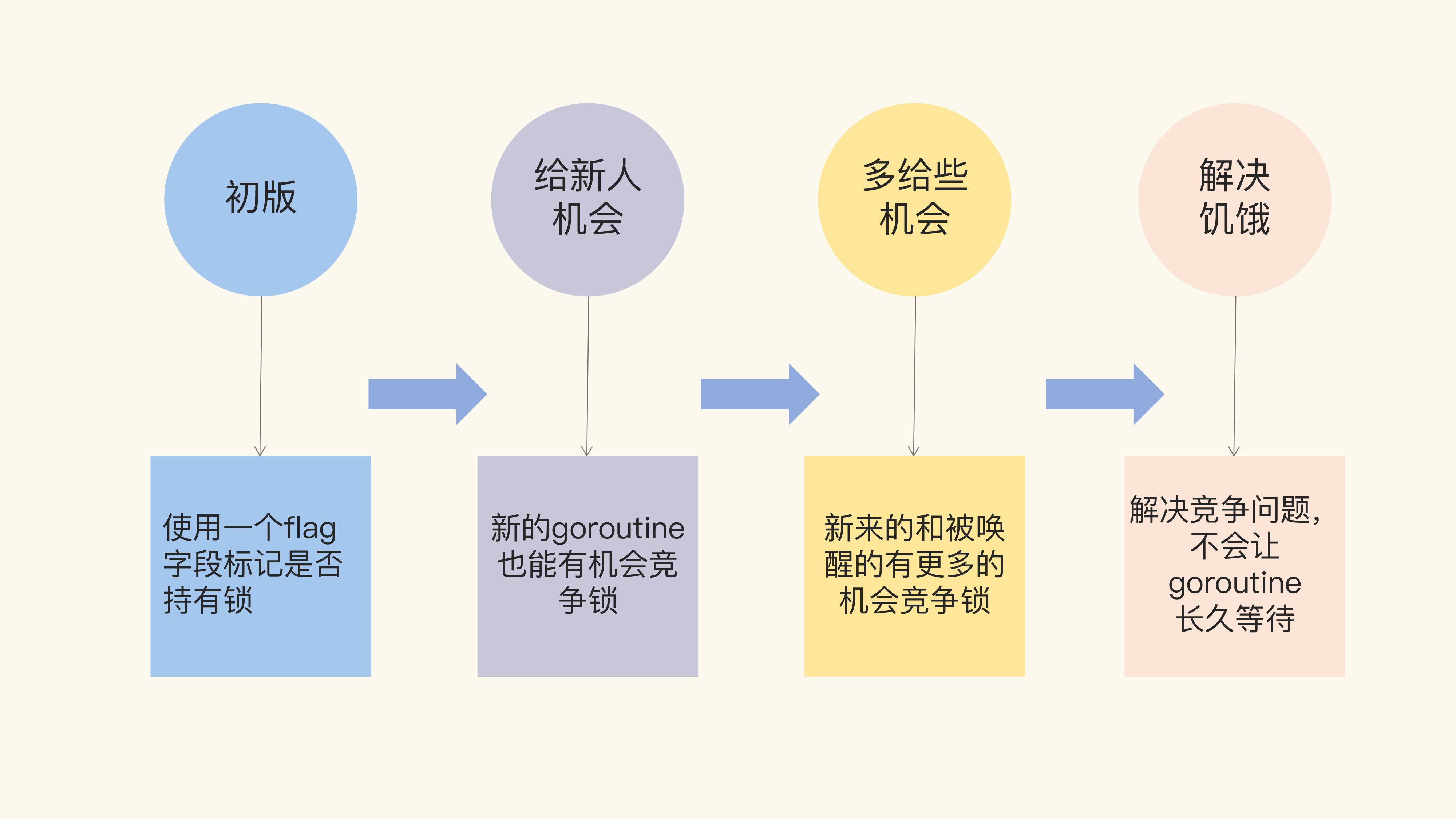
“初版”的 Mutex 使用一个 flag 来表示锁是否被持有,实现比较简单;后来照顾到新来的 goroutine,所以会让新的 goroutine 也尽可能地先获取到锁,这是第二个阶段,我把它叫作“给新人机会”;那么,接下来就是第三阶段“多给些机会”,照顾新来的和被唤醒的 goroutine;但是这样会带来饥饿问题,所以目前又加入了饥饿的解决方案,也就是第四阶段“解决饥饿”。
Mutex 绝不容忍一个 goroutine 被落下,永远没有机会获取锁。不抛弃不放弃是它的宗旨,而且它也尽可能地让等待较长的 goroutine 更有机会获取到锁。
Mutex 可能处于两种操作模式下:正常模式和饥饿模式
- 正常模式下,waiter 都是进入先入先出队列,被唤醒的 waiter 并不会直接持有锁,而是要和新来的 goroutine 进行竞争。新来的 goroutine 有先天的优势,它们正在 CPU 中运行,可能它们的数量还不少,所以,在高并发情况下,被唤醒的 waiter 可能比较悲剧地获取不到锁,这时,它会被插入到队列的前面。如果 waiter 获取不到锁的时间超过阈值 1 毫秒,那么,这个 Mutex 就进入到了饥饿模式。
- 在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会 spin,它会乖乖地加入到等待队列的尾部。
小结一下
- cpu 层面有内存屏障、cas、关中断 等指令,有l1/l2/l3 cache ,cpu 会对指令重排序
- 操作系统 提供 锁抽象,但aqs 这里没用。并且锁的实现 是否用到了cas 、内存屏障等指令待分析。
- 编译器会对 代码重排序
- 因为cpu、编译器等基本特性,所以线程安全的操作一个变量需要原子性、有序性和可见性
- jvm 提供 volatile(对应读写屏障指令)、cas 等cpu 级别的操作
- 因此,使用volatile、cas 等 可以在java 层面 线程安全操作一个变量,无锁化的
- 同步器的三大组件,状态、阻塞/恢复线程、队列,具备这个能力就可以实现一个同步器。如果可以无锁化的更改状态、操作队列,则可以实现一个无锁化的同步器。
聊聊原子变量、锁、内存屏障那点事 实际上无锁的代码仅仅是不需要显式的Mutex来完成,但是存在数据竞争(Data Races)的情况下也会涉及到同步(Synchronization)的问题。从某种意义上来讲,所谓的无锁,仅仅只是颗粒度特别小的“锁”罢了,从代码层面上逐渐降低级别到CPU的指令级别而已,总会在某个层级上付出等待的代价,除非逻辑上彼此完全无关。
留下评论