grpo演进
简介(未完成)
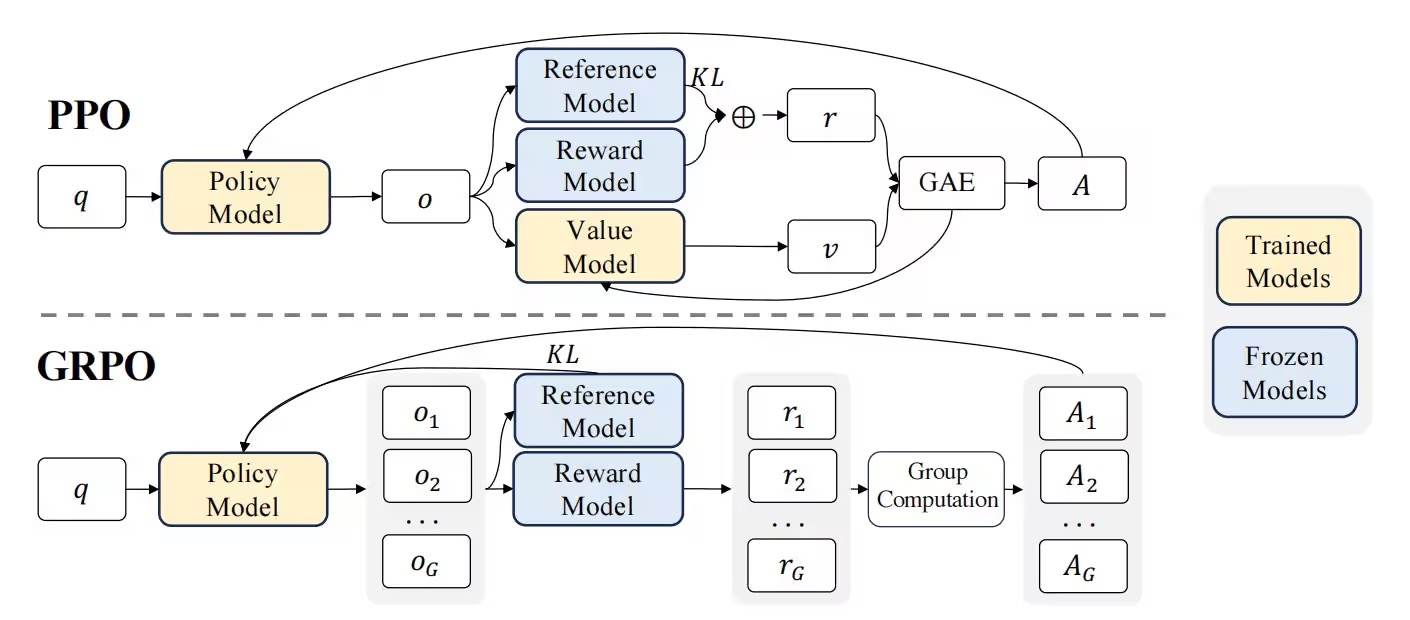
与ppo对比
| PPO | GRPO | |
|---|---|---|
| 价值网络的使用 | 依赖于一个与策略模型大小相当的价值网络(critic model)来估计优势函数(advantage function)。这个价值网络需要在每个时间步对状态进行评估,计算复杂度高,内存占用大。 | 完全摒弃了价值网络,通过组内相对奖励来估计优势函数。 |
| 奖励计算方式 | 使用广义优势估计(GAE)来计算优势函数,需要对每个动作的即时奖励和未来奖励的折扣总和进行估计。 | 通过采样一组动作并计算它们的奖励值,然后对这些奖励值进行归一化处理,得到相对优势。这种方法更直接,减少了对复杂奖励模型的依赖。 |
| 策略更新机制 | 通过裁剪概率比(clip operation)来限制策略更新的幅度,确保策略分布的变化在可控范围内。 | 引入了KL散度约束,直接在损失函数中加入KL散度项,从而更精细地控制策略更新的幅度。 |
| 计算效率 | 由于需要维护和更新价值网络,计算效率较低,尤其是在大规模语言模型中,训练过程可能变得非常缓慢。 | 通过避免价值网络的使用,显著提高了计算效率,降低了内存占用,更适合大规模语言模型的微调。 |
| 优势 | PPO通过裁剪概率比,能够有效防止策略更新过于剧烈,从而保持训练过程的稳定性。PPO在多种强化学习任务中表现出色,适用于多种类型的环境和任务。 | GRPO通过避免价值网络的使用,显著降低了计算和存储需求,提高了训练效率。通过组内相对奖励的计算,GRPO减少了策略更新的方差,确保了更稳定的学习过程。GRPO引入了KL散度约束,能够更精细地控制策略更新的幅度,保持策略分布的稳定性。 |
| 局限 | 在大规模语言模型中,PPO需要维护一个与策略模型大小相当的价值网络,导致显著的内存占用和计算代价。PPO的策略更新依赖于单个动作的奖励值,可能导致较高的方差,影响训练的稳定性。 | GRPO需要对每个状态采样一组动作,这在某些情况下可能会增加采样成本。GRPO在某些任务中可能不如PPO表现稳定,尤其是在奖励信号稀疏的情况下。 |
A concrete example of GRPO in action:
Query: “What is 2 + 3?”
Step 1: LLM generates three answers.
1. “5”
2. “6”
3. “2 + 3 = 5”
Step 2: Each answer is scored.
1. “5” → 1 points (correct, no reasoning)
2. “6” → 0 points (incorrect)
3. “2 + 3 = 5” → 2 points (correct, w/ reasoning)
Step 3: Compute avg score for entire group.
Avg score = (1 + 0 + 2) / 3 = 1
Step 4: Compare each answer score to avg.
1. “5” → 0 (same as avg)
2. “6” → -1 (below avg)
3. “2 + 3 = 5” → 1 (above avg)
Step 5: Reinforce LLM to favor higher scores.
1. Favor responses like #3 (positive)
2. Maintain responses like #1 (neutral)
3. Avoid responses like #2 (negative)
This process is repeated, allowing the model to learn and improve over time.
Coding GRPO from Scratch: A Guide to Distributed Implementation with Qwen2.5-1.5B-Instruct
def correctness_reward(prompts, completions, answer, **kwargs):
"""
Assigns a reward based on the correctness of the model's answer.
Explanation:
1. Extracts the content from each completion.
2. Extracts the answer portion from each response using extract_answer_from_model_output.
3. Assigns rewards based on matching criteria:
- 2.0 points for an exact match
- 1.5 points for numeric equivalence (when values match but format differs)
- 0.0 points for incorrect answers
4. Tracks completion lengths for analysis.
"""
responses = [completion[0]['content'] for completion in completions]
extracted = [extract_answer_from_model_output(r) for r in responses]
rewards = []
for r, a in zip(extracted, answer):
if r == a: # Exact match case
rewards.append(2.0)
else:
# Try numeric equivalence
r_num = extract_single_number(str(r))
a_num = extract_single_number(str(a))
if r_num is not None and a_num is not None and r_num == a_num:
rewards.append(1.5)
else:
rewards.append(0.0)
# Log completion lengths
completion_lengths = [len(response.split()) for response in responses]
return rewards
def format_reward(completions, **kwargs):
"""
Assigns a reward for adhering to the desired XML format.
Explanation:
1. Extracts the content from each completion.
2. Evaluates format compliance by checking for required XML tags:
- 0.2 points for each tag present (<reasoning>, </reasoning>, <answer>, </answer>)
- Maximum score of 0.8 for perfect format compliance
3. Stores and returns the format compliance scores.
"""
responses = [completion[0]['content'] for completion in completions]
rewards = []
format_scores = []
for response in responses:
score = 0.0
if "<reasoning>" in response: score += 0.2
if "</reasoning>" in response: score += 0.2
if "<answer>" in response: score += 0.2
if "</answer>" in response: score += 0.2
rewards.append(score)
format_scores.append(score)
return rewards
HuggingFace GRPOTrainer继承自Trainer类,在Trainer类中封装了很多的训练逻辑
from datasets import load_dataset
from trl import GRPOTrainer
dataset = load_dataset("trl-lib/tldr", split="train")
trainer = GRPOTrainer(
model="Qwen/Qwen2-0.5B-Instruct",
reward_funcs="weqweasdas/RM-Gemma-2B",
train_dataset=dataset,
)
trainer.train()
留下评论