Kubernetes介绍
简介
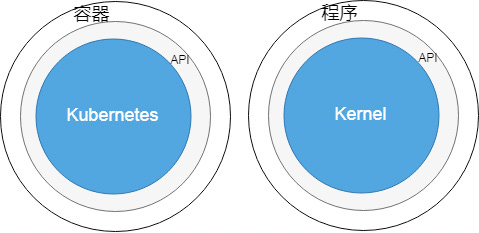
Kubernetes——集群操作系统
为什么我们需要基于kubernetes的云操作系统?现在,IaaS、PaaS 和 SaaS 在云原生技术普及的浪潮中已经名存实亡,比如容器运行在裸机上就已经拥有非常好的性能了,是否还需要 IaaS 这一层?PaaS、SaaS 本质都是容器,是否还需要区分?这三层架构实际上已经被击穿!
比较 Kubernetes 和单机操作系统,Kubernetes 相当于内核,它负责集群软 硬件资源管理,并对外提供统一的入口,用户可以通过这个入口来使用集群,和集 群沟通。
| 关在“笼子”里的程序 | 一般运行在操作系统上的程序 | |
|---|---|---|
| 为了让这个程序不依赖于操作系统自身的库文件, 我们需要制作容器镜像 |
||
| 程序分发 | 镜像仓库 | 应用商店 |
| 系统入口 | apiserver | 系统调用 |
2019.8.13:刘超《趣谈linux操作系统》最初使用汇编语言的前辈,在程序中需要指定使用的硬件资源,例如,指定使用哪个寄存器、放在内存的哪个位置、写入或者读取那个串口等等。对于这些资源的使用,需要程序员自己心里非常地清楚,要不然一旦 jump 错了位置,程序就无法运行。为了将程序员从对硬件的直接操作中解放出来,我们有了操作系统这一层,用来实现对于硬件资源的统一管理。某个程序使用哪个 CPU、哪部分内存、哪部分硬盘,都由操作系统自行分配和管理。其实操作系统最重要的事情,就是调度(当前任务需要多少资源,当前空闲多少资源,做一个适配)。因此,在内核态就产生这些模块:进程管理子系统、内存管理子系统、文件子系统、设备子系统网络子系统。这些模块通过统一的 API,也就是系统调用,对上提供服务。基于 API,用户态有很多的工具可以帮我们使用好 Linux 操作系统,比如用户管理、软件安装、软件运行、周期性进程、文件管理、网络管理和存储管理。但是到目前为止,我们能管理的还是少数几台机器。当我们面临数据中心成千上万台机器的时候,仍然非常“痛苦”。
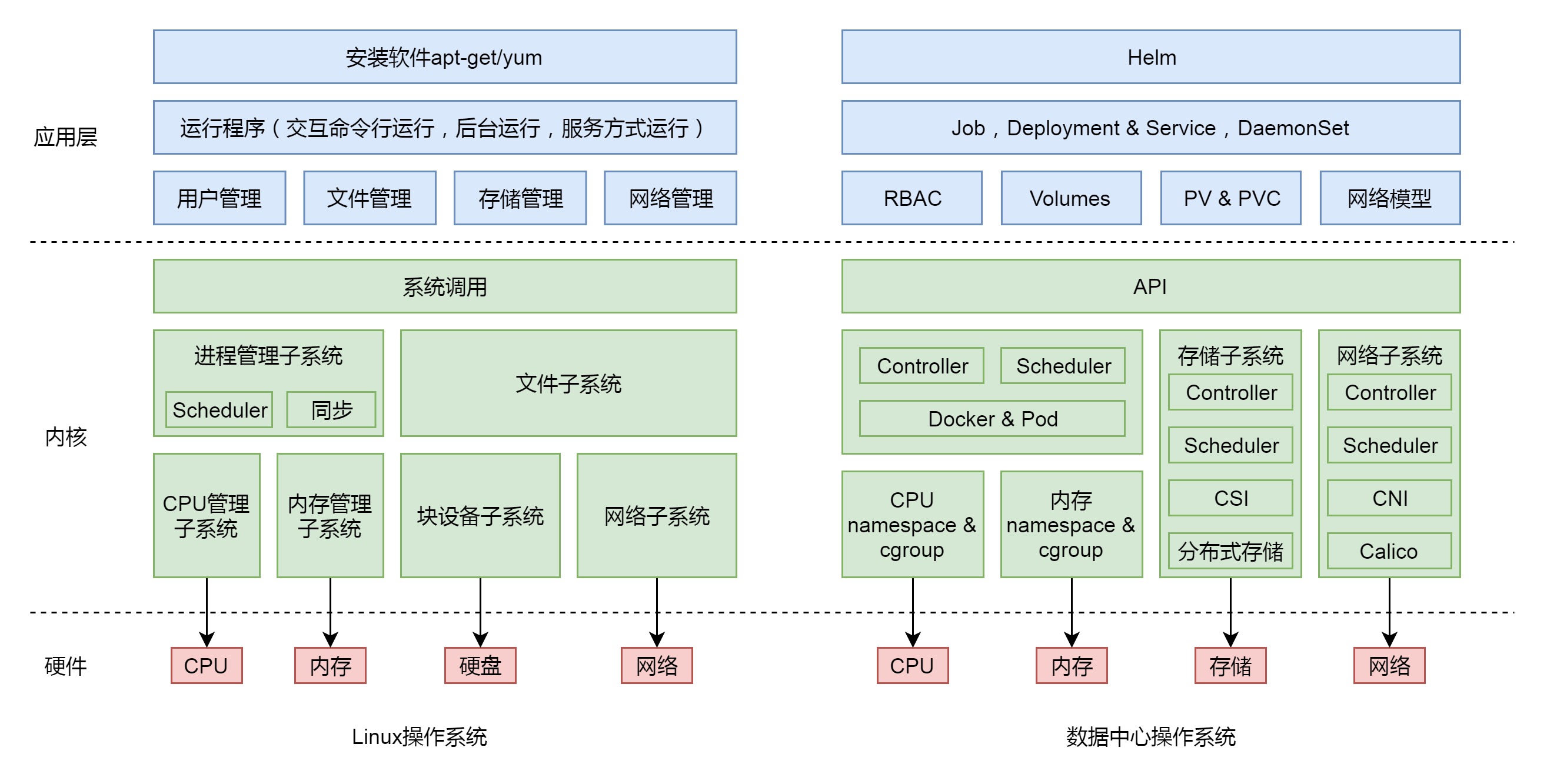
PS:上图很有意思的一点是,将Kubernetes 的各项机制,根据内核态和用户态做了一个梳理。
2019.8.3:《阿里巴巴云原生实践15讲》读后感
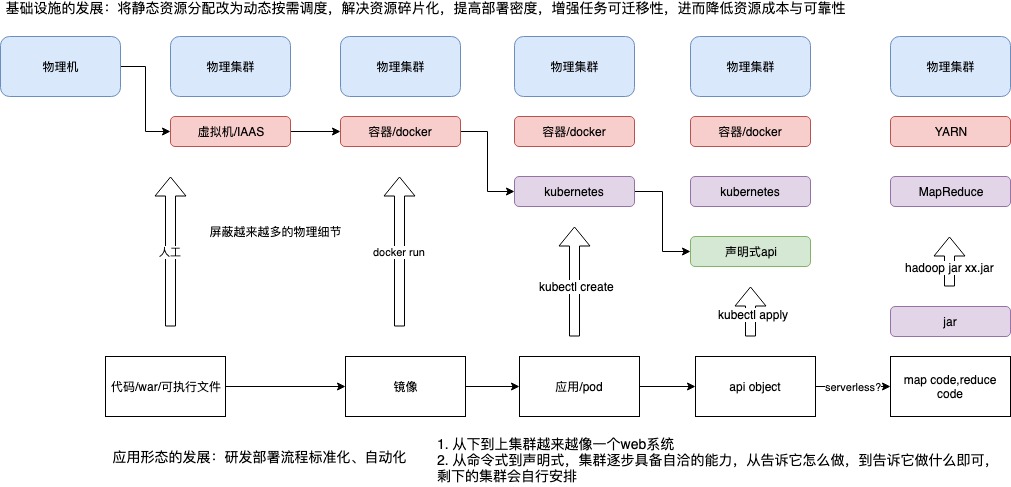
docker 让镜像和容器融合在一起,docker run 扣动扳机,实现镜像到 容器的转变。但docker run 仍然有太多要表述的,比如docker run的各种参数: 资源、网络、存储等,“一个容器一个服务”本身也不够反应应用的复杂性(或者 说还需要额外的信息 描述容器之间的关系,比如--link)。
我们学习linux的时候,知道linux 提供了一种抽象:一切皆文件。没有人会质疑基本单元为何是文件不是磁盘块?linux 还提供了一种抽象叫“进程”,没有人会好奇为何 linux 不让你直接操纵cpu 和 内存。一个复杂的系统,最终会在某个层面收敛起来,就好像一个web系统,搞到最后就是一系列object 的crud。类似的,如果我们要实现一个“集群操作系统”,容器的粒度未免太小。也就是说,镜像和容器之间仍然有鸿沟要去填平?kubernetes 叫pod,marathon叫Application,中文名统一叫“应用”。在这里,应用是一组容器的有机组 合,同时也包括了应用运行所需的网络、存储的需求的描述。而像这样一个“描述” 应用的 YAML 文件,放在 etcd 里存起来,然后通过控制器模型驱动整个基础设施的 状态不断地向用户声明的状态逼近,就是 Kubernetes 的核心工作原理了。“有了 Pod 和容 器设计模式,我们的应用基础设施才能够与应用(而不是容器)进行交互和响应的能力,实现了“云”与“应用”的直接对接。而有了声明式 API,我们的应用基础而设 施才能真正同下层资源、调度、编排、网络、存储等云的细节与逻辑解耦”。
关于声明式api,举一个调度例子, 假设一个服务有10个实例,要求两个实例不能在同一个机器上。在“命令式”的传统发布系统中,一般会指定每个实例所在的机器(就像指定数据放在哪个集群器、放在内存的哪个位置一样)而对于k8s,“两个实例不能在同一个机器上”就是一个配置而已, 由k8s相机将实例调度在不同的机器上。PS:笔者最近在团队管理上也有一些困惑, 其实,你直接告诉小伙伴怎么做并不是一个很好的方式,他们不自由,你也很心累。比较好的方式是做好目标管理,由他们自己不断去填平目标与现实的鸿沟。
Reasons Kubernetes is coolonce you have a working Kubernetes cluster you really can set up a production HTTP service (“run 5 of this application, set up a load balancer, give it this DNS name, done”) with just one configuration file. 对运维来说部署java application 和 部署mysql 是两个事情,但对于k8s 来说,就是一个事情。
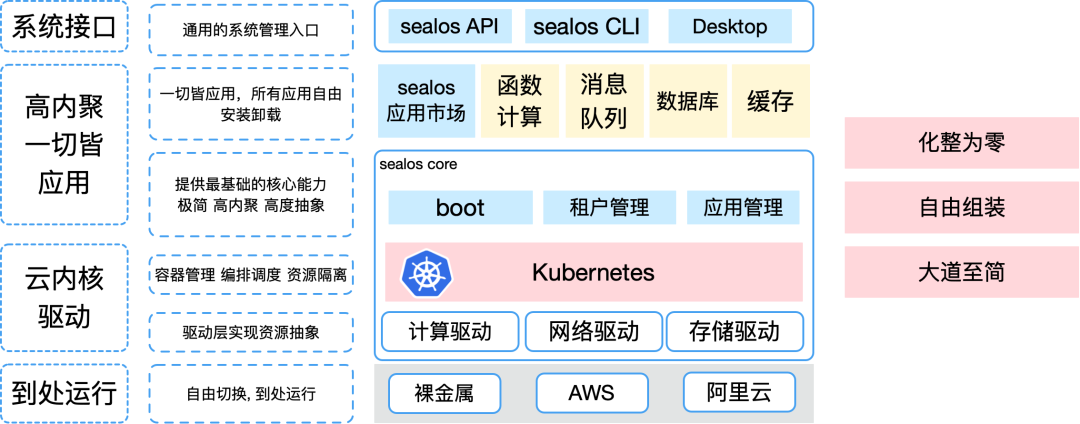
Kubernetes是以Container容器技术为核心的调度引擎,将传统云计算对应的基础资源,包含计算、存储、网络进行了彻底池化统一管理,同时将运行在技术架构之上的应用和服务也进行了抽象标准化,再通过调度快速实现应用与资源的匹配,即以应用为中心构建云原生操作系统能力。PS:CNI、CSI、device-plugin来配合进行这些资源的池化,池化 + 标准化 + 调度/匹配。
赢在API
一般orchestrator 包括但不限于以下功能:
- Organizational primitives,比如k8s的label
- Scheduling of containers to run on a ost
- Automated health checks to determine if a container is alive and ready to serve traffic and to relaunch it if necessary
- autoscaling
- upgrading strategies,from rolling updates to more sophisticated techniques such as A/B and canary deployments.
- service discovery to determine which host a scheduled container ended upon,usually including DNS support.
The unit of scheduling in Kubernetes is a pod. Essentially, this is a tightly coupled set of one or more containers that are always collocated (that is, scheduled onto a node as a unit); they cannot be spread over nodes.
- The number of running instances of a pod—called replicas—can be declaratively stated and enforced through controllers.
- The logical organization of all resources, such as pods, deployments, or services, happens through labels. label 的作用不小啊
Kubernetes is highly extensible, from defining new workloads and resource types in general to customizing its user-facing parts, such as the CLI tool kubectl (pronounced cube cuddle).
Kubernetes 的核心是 API 而非容器容器并非 Kubernetes 最重要、最有价值的地方,Kubernetes 也并非仅仅是一个更广泛意义上的 Workload 调度器 —— 高效地调度不同类型的 Workload 只是 Kubernetes 提供的一种重要价值,但并不是它成功的原因。Kubernetes 的成功和价值在于,提供了一种标准的编程接口(API),可以用来编写和使用软件定义的基础设施服务。Kubernetes 是一个针对云服务(Cloud Services)的标准 API 框架。PS:没有标准化,云的发展
- Specification + Implementation 构成一个完整的 API 框架 —— 用于设计、实现和使用各种类型和规模的基础设施服务;
- 这些 API 都基于相同的核心结构和语义:typed resources watched and reconciled by controllers (资源按类型划分,控制器监听相应类型的资源,并将其实际 status 校准到 spec 里期望的状态)。
我们说 Kubernetes 的核心是其 API 框架,但并不是说这套 API 框架就是完美的。事实上,后一点(完美)并不(非常)重要,因为 Kubernetes 模型已经成为一个事实标准:开发者理解它、大量工具主动与它对接、主流厂商也都已经原生支持它。用户认可度、互操作性 经常比其他方面更能决定一个产品能否成功。随着 Kubernetes 资源模型越来越广泛的传播,现在已经能够 用一组 Kubernetes 资源来描述一整个软件定义计算环境。就像用 docker run 可以启动单个程序一样,用 kubectl apply -f 就能部署和运行一个分布式应用, 而无需关心是在私有云还是公有云以及具体哪家云厂商上,Kubernetes 的 API 框架已经屏蔽了这些细节。
设计理念
- 声明式 VS 命令式, 声明式优点很多,一个很重要的点是:在分布式系统中,任何组件都可能随时出现故障。当组件恢复时,需要弄清楚要做什么,使用命令式 API 时,处理起来就很棘手。但是使用声明式 API ,组件只需查看 API 服务器的当前状态,即可确定它需要执行的操作。
- 显式的 API, Kubernetes 是透明的,它没有隐藏的内部 API。换句话说 Kubernetes 系统内部用来交互的 API 和我们用来与 Kubernetes 交互的 API 相同。这样做的好处是,当 Kubernetes 默认的组件无法满足我们的需求时,我们可以利用已有的 API 实现我们自定义的特性。
- 无侵入性, 我们的应用达到镜像后, 不需要改动就可以遨游在 Kubernetes 集群中。 Kubernetes 以一种友好的方式将 Secret、Configuration等注入 Pod,减少了大家的工作量,而无需重写或者很大幅度改变原有的应用代码。
- 有状态的移植, 比如 PersistentVolumeClaim 和 PersistentVolume
整体结构
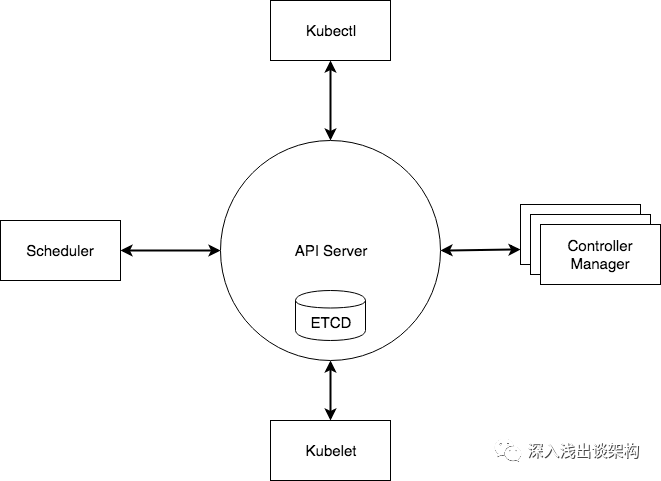
简版的
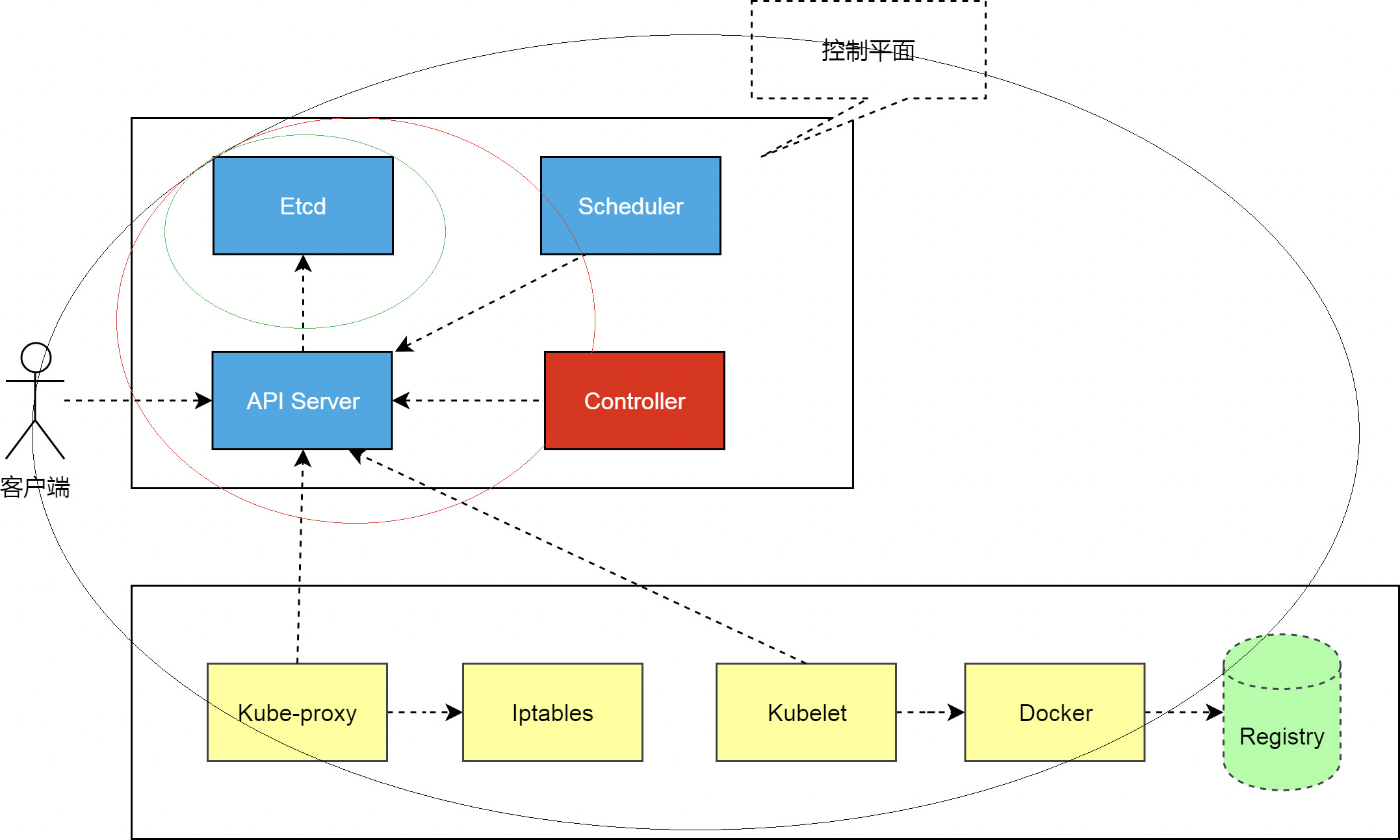
详细的
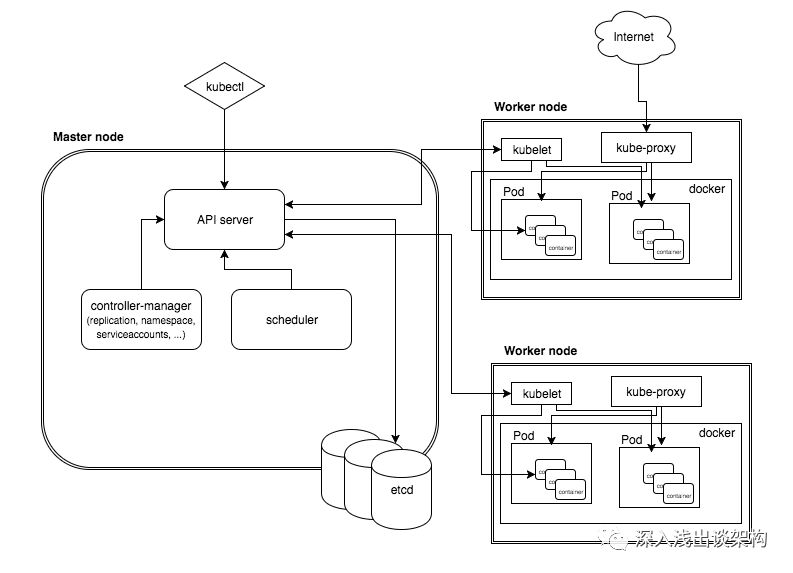
调整后的架构图
- etcd,各个组件通信都并不是互相调用 API 来完成的,而是把状态写入 ETCD(相当于写入一个消息),其他组件通过监听 ETCD 的状态的的变化(相当于订阅消息),然后做后续的处理,然后再一次把更新的数据写入 ETCD。
- api server,各个组件并不是直接访问 ETCD,而是访问一个代理,这个代理是通过标准的RESTFul API,重新封装了对 ETCD 接口调用,除此之外,这个代理还实现了一些附加功能,比如身份的认证、缓存等
- Controller Manager 是实现任务调度的
- Scheduler 是用来做资源调度的
如何看待k8s object
笔者最开始接触k8s 是想用k8s 接管公司的测试环境,所以一直以来对k8s的理解停留在 如何将一个项目运行在k8s上,之后向前是ci/cd,向后是监控报警等。一直以来有两个误区:
- 虽然知道k8s 支持crd,但只是认为crd 是增强服务发布能力的。以发布、运行服务为主来先入为主的理解k8s。
- k8s 是声明式的,所以crd 也应该是声明式的。
当然这个观点在 面向 K8s 设计误区 被认为是错误的。几个错误思维:
- 一切设计皆 YAML;
- 一切皆合一;
- 一切皆终态;
- 一切交互皆 cr。
这个印象在openkruise 推出ImagePullJob 之后产生了动摇,这个crd的作用是将 image 下发到指定个规则的node上。面对不可避免的故障,我们造了一个“上帝视角”的控制台 中chaosblade 的crd 则支持向某个进程注入一个故障。chaosblade 本身首先是一个故障注入平台,然后才是支持在k8s 平台上支持故障注入(物理机也是支持的)。
TKE qGPU 通过 CRD 管理集群 GPU 卡资源通过 GPU CRD 扫描物理 GPU 的信息,并在 qGPU 生命周期中更新使用到的物理 GPU 资源,从而解决在共享 GPU 场景下缺少可见性的问题。
另一个例子是自动扩缩容,其实并不复杂,直接api 变更replicas 即可。 但hpa 提供一个 平台化的能力来 做这件事(metric + 策略 + 控制器),是很值得思考的一个点。当 Kruise Rollout:灵活可插拔的渐进式发布框架 提到手动暂停 发布过程 都可以用k8s 来实现的时候,“一切交互”皆cr 就显而易见了。
Kubernetes 仍需进一步发展
Kubernetes何时才会消于无形却又无处不在?一项技术成熟的标志不仅仅在于它有多流行,还在于它有多不起眼并且易于使用。Kubernetes依然只是一个半成品,还远未达到像Linux内核及其周围操作系统组件在过去25年中所做到的那种“隐形”状态。
k8s 重新定义了上下游交付的标准。有了k8s 之前,公有云卖货是 xx 配置服务器xx 钱一年,交付的是虚拟机。有了k8s 之后,公有云交付的是k8s 集群,业务方 将自己的业务 部署到k8s,并根据 需要调用公有云接口 扩容或缩容 k8s 集群。
解读2018:我们处在一个什么样的技术浪潮当中?Kubernetes 还是太底层了,真正的云计算并不应该是向用户提供的 Kubernetes 集群。2014 年 AWS 推出 Lambda 服务,Serverless 开始成为热词。从理论上说,Serverless 可以做到 NoOps、自动扩容和按使用付费,也被视为云计算的未来。Serverless 是我们过去 25 年来在 SaaS 中走的最后一步,因为我们已经渐渐将越来越多的职责交给了服务提供商。——Joe Emison 《为什么 Serverless 比其他软件开发方法更具优势》
解读容器 2019:把“以应用为中心”进行到底云原生的本质是一系列最佳实践的结合;更详细的说,云原生为实践者指定了一条低心智负担的、能够以可扩展、可复制的方式最大化地利用云的能力、发挥云的价值的最佳路径。这种思想,以一言以蔽之,就是“以应用为中心”。正是因为以应用为中心,云原生技术体系才会无限强调让基础设施能更好的配合应用、以更高效方式为应用“输送”基础设施能力,而不是反其道而行之。而相应的, Kubernetes 、Docker、Operator 等在云原生生态中起到了关键作用的开源项目,就是让这种思想落地的技术手段。
- 微型虚拟机 (MicroVM),微型虚拟机与容器的区别在于它不与宿主机共用内核,拥有自己的微内核,提供了与虚拟机一样的硬件虚拟化安全性。虚拟机抽象了内存、CPU、网络、存储和其他计算资源,而微型虚拟机是围绕应用程序来对资源进行抽象,只抽象了必要的资源,所以更加高效。
- WebAssembly:虚拟机模拟了完整的计算机;容器模拟了完整的操作系统;WebAssembly 仅仅模拟了进程。容器大家都比较熟悉,它只模拟了完整操作系统的用户空间,不包含内核空间,也不包含硬件相关的抽象。但是对于微服务和 Serverless 而言,它仍然很重,我只需要启动一个进程,你却让我先启动一个完整的操作系统再启动进程。这时候 WebAssembly 的价值就体现出来了,你只需要启动一个进程,而我恰好就只启动了进程,没有操作系统,也没有硬件虚拟化,只有孤单的进程,只是这个进程被放入了 WebAssembly 的沙盒中。在 Kubernetes 上使用 WebAssembly: 从容器到 Wasm
- 认识 WebAssembly 与 Rust 实践 wsam 性能好(相对也于js来说,SIMD 和 多线程);很多语言写成的库可以转为wsam,js和wsam可以互操作 ==> 其它语言编写的库可以很好的去移植到 Web 中,和 JavaScript 的内容结合到一起使用,大多数 HTML/CSS/JavaScript 应用结合几个高性能的 WASM 模块(例如,绘图,模拟,图像/声音/视频处理,可视化,动画,压缩等等能够允许开发者像今天我们所用的 JS 库一样去重用流行的 WASM 库。
留下评论