回头看Spring IOC
前言
为什么依赖注入只在 Java 技术栈中流行,在 go 和 cpp 没有大量使用?
深入浅出依赖注入及其在抖音直播中的应用面向对象设计带来的最直接的问题,就是对象间的依赖。对象 A 依赖于对象 B,那么对象 A 在初始化或者运行到某一点的时候,自己必须主动去创建对象 B 或者使用已经创建的对象 B。这个直接依赖会导致什么问题?
- 过渡暴露细节,A 只关心 B 提供的接口服务,并不关心 B 的内部实现细节,A 因为依赖而引入 B 类,间接的关心了 B 的实现细节
- 对象间强耦合,B 发生任何变化都会影响到 A,开发 A 和开发 B 的人可能不是一个人,B 把一个 A 需要用到的方法参数改了,B 的修改能编译通过,能继续用,但是 A 就跑不起来了
- A 是服务使用者,B 是提供一个具体服务的,假如 C 也能提供类似服务,但是 A 已经严重依赖于 B 了,想换成 C 非常之困难
学过面向对象的同学马上会知道可以使用接口来解决上面几个问题。如果早期实现类 B 的时候就定义了一个接口,B 和 C 都实现这个接口里的方法,这样从 B 切换到 C 是不是就只需很小的改动就可以完成。A 对 B 或 C 的依赖变成对抽象接口的依赖了,上面说的几个问题都解决了。但是目前还是得实例化 B 或者 C,因为 new 只能 new 对象,不能 new 一个接口,还不能说 A 彻底只依赖于接口了。从 B 切换到 C 还是需要修改代码,能做到更少的依赖吗?能做到 A 在运行的时候想切换 B 就 B,想切换 C 就 C,不用改任何代码甚至还能支持以后切换成 D 吗?通过反射可以简单实现上面的诉求。例如常用的接口NSClassFromString,通过字符串可以转换成同名的类。通过读取本地的配置文件,或者服务端下发的数据,通过 OC 的提供的反射接口得到对应的类,就可以做到运行时动态控制依赖对象的引入。
对象之间的耦合关系是无法避免的,也是必要的,这是协同工作的基础。功能越复杂的应用,对象之间的依赖关系一般也越复杂,经常会出现对象之间的多重依赖性关系。对象之间耦合度过高的系统,必然会出现牵一发而动全身的情形。耦合关系不仅会出现在对象与对象之间,也会出现在软件系统的各模块之间。如何降低系统之间、模块之间和对象之间的耦合度,是软件工程永远追求的目标之一。Michael Mattson IOC 理论提出的观点大体为:借助于“第三方”实现具有依赖关系的对象之间的解耦。全部对象的控制权全部上缴给“第三方”IOC 容器,所以,IOC 容器成了整个系统的关键核心,它起到了一种类似“粘合剂”的作用,把系统中的所有对象粘合在一起发挥作用,如果没有这个“粘合剂”,对象与对象之间会彼此失去联系,这就是有人把 IOC 容器比喻成“粘合剂”的由来。
控制反转(IoC )这里的控制是指:一个类除了自己的本职工作以外的逻辑。典型的如创建其依赖的对象的逻辑。将这些控制逻辑移出这个类中,就称为控制反转。那么这些逻辑由谁来实现呢?各种框架、工厂类、IoC (Inversion of Control)容器等等该上场了……依赖注入是控制反转( IoC)原则的一种具体实现方式,依赖注入的目的,是为了将「依赖对象的创建」与「依赖对象的使用」分离,通俗讲就是使用方不负责服务的创建。一个 DI 框架一般需要具备这些能力:
- 依赖关系的配置,被依赖的对象与其实现协议之间的映射关系
- 依赖对象生命周期的管理,注入对象的创建与销毁
- 依赖对象的获取,通过依赖对象绑定的协议,获取到对应的对象
- 依赖对象的注入,即被依赖的对象如何注入到使用者内
java的servlet就是一种组件,而负责运行servlet的比如tomcat这些,就是一种容器,tomcat和servlet就是一种控制反转,传统你要写一个http的服务器,你需要从main函数写起,你需要编写监听端口的代码,需要写处理逻辑的代码……,那经过ioc之后,你只需要写servlet,剩下的控制,交给tomcat等http服务器就好了,几乎所有的服务器端web服务器,都是这种理念的产物。di是ioc的一种,但是di并不是ioc的全部,spring是di的一种实现方式。在早些年,java没有static import,而且static方法,还放在一个不清不楚的方法区,而不是heap里面的时候用di可以让java代码更加易于维护的同时,也可以避开性能上的一些坑比如你把所有方法都放在方法区里,那方法区有多大啊?会不会爆掉啊?现在方法区已经被取消了,归入heap了,加上static import的引入,以及zgc等功能。其实你完全不需要spring和di,你的代码运行效率都不会低多少。
Spring 容器具象化一点就是 从xml、配置类、依赖jar 等处 通过 BeanDefinitionRegistry.registerBeanDefinition 向容器注入Bean信息,然后通过BeanFactory.getBean 应用在各个位置。
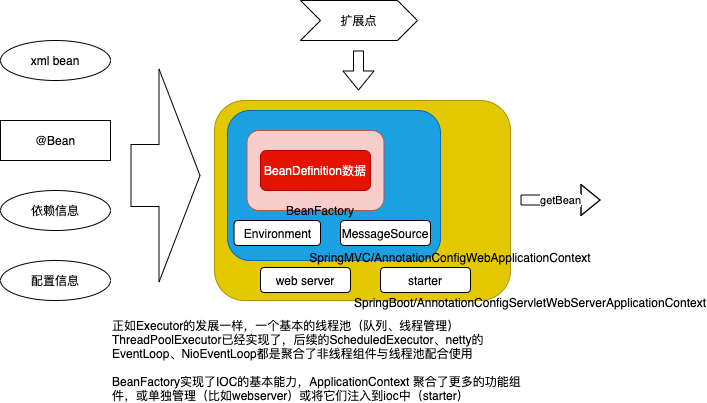
从谈元编程与表达能力中,笔者收获了对runtime的一个理解:当相应的行为在当前对象上没有被找到时,运行时会提供一个改变当前对象行为的入口(比如synchronized关键字,jvm 会针对性的做一些处理)。从这个视角看,Spring 也可以认为是 java 的一个runtime,通过标注@Autowire等,ApplicationContext 获取的bean 拥有 bean代码本身看不到的能力。
容器解决了什么问题?
DI 容器要解决的问题是什么呢?它解决的是组件创建和组装的问题,但是为什么这是一个需要解决的问题呢?软件设计需要有一个分解的过程,所以,它必然还要面对一个组装的过程,也就是把分解出来的各个组件组装到一起,完成所需要的功能。
假设我们有一个文章服务(ArticleService)提供根据标题查询文章的功能。当然,数据是需要持久化的,所以,这里还有一个 ArticleRepository,用来与持久化数据打交道。
class ArticleService {
//提供根据标题查询文章的服务
Article findByTitle(final String title) {
...
}
}
在 ArticleService 处理业务的过程中,需要用到 ArticleRepository 辅助它完成功能,也就是说,ArticleService 要依赖于 ArticleRepository。这时你该怎么做呢?一个直接的做法就是在 ArticleService 中增加一个字段表示 ArticleRepository。
class ArticleService {
private ArticleRepository repository;
public Article findByTitle(final String title) {
// 做参数校验
return this.repository.findByTitle(title);
}
}
这个字段怎么初始化呢?程序员一般最直接的反应就是直接创建这个对象。
class ArticleService {
private ArticleRepository repository = new DBArticleRepository();
public Article findByTitle(final String title) {
// 做参数校验
return this.repository.findByTitle(title);
}
}
在真实的项目中,由于资源所限,我们一般不会在应用中任意打开数据库连接,而是会选择共享数据库连接。所以,DBArticleRepository 需要一个数据库连接(Connection)的参数。
class ArticlService {
private ArticleRepository repository;
public ArticlService(final Connection connection) {
this.repository = new DBArticleRepository(connection);
}
public Article findByTitle(final String title) {
// 做参数校验
return this.repository.findByTitle(title);
}
}
一旦开始准备测试,你就会发现,要让 ArticleService 跑起来,那就得让 ArticleRepository 也跑起来;要让 ArticleRepository 跑起来,那就得准备数据库连接。是不是觉得太麻烦?然后,真正开始写测试时,你才发现,要测试,你还要在数据库里准备各种数据。
问题出在哪儿呢?其实就在你创建对象的那一刻,问题就出现了。当我们创建一个对象时,就必须要有一个具体的实现类,对应到我们这里,就是那个 DBArticleRepository。虽然我们的 ArticleService 写得很干净,其他部分根本不依赖于 DBArticleRepository,只在构造函数里依赖了,但依赖就是依赖。与此同时,由于要构造 DBArticleRepository 的缘故,我们这里还引入了 Connection 这个类,这个类只与 DBArticleRepository 的构造有关系,与我们这个 ArticleService 的业务逻辑一点关系都没有。你看到了,只是因为引入了一个具体的实现,我们就需要把它周边配套的东西全部引入进来,而这一切与这个类本身的业务逻辑没有任何关系。这还只是最简单的场景,在真实的项目中,构建一个对象可能还会牵扯到更多的内容:
- 根据不同的参数,创建不同的实现类对象,你可能需要用到工厂模式。
- 为了了解方法的执行时间,需要给被依赖的对象加上监控。
- 依赖的对象来自于某个框架,你自己都不知道具体的实现类是什么。
既然直接构造存在这么多的问题,那么最简单的办法就是把创建的过程拿出去,只留下与字段关联的过程:
class ArticleService {
private ArticleRepository repository;
public ArticleService(final ArticleRepository repository) {
this.repository = repository;
}
public Article findByTitle(final String title) {
// 做参数校验
return this.repository.findByTitle(title);
}
}
现在,对象的创建已经分离了出去,但还是要要有一个地方完成这个工作,最简单的解决方案自然是,把所有的对象创建和组装在一个地方完成:
...
ArticleRepository repository = new DBArticleRepository(connection);
AriticleService service = new ArticleService(repository);
...
相比于业务逻辑,组装过程并没有什么复杂的部分。一般而言,纯粹是一个又一个对象的创建以及传参的过程,这部分的代码看上去会非常的无聊。虽然很无聊,但这一部分代码很重要,最好的解决方案就是有一个框架把它解决掉。在 Java 世界里,这种组装一堆对象的东西一般被称为“容器”,我们也用这个名字。
Container container = new Container();
container.bind(Connection.class).to(connection);
container.bind(ArticleReposistory.class).to(DBArticleRepository.class);
container.bind(ArticleService.class).to(ArticleService.class)
ArticleService service = container.getInstance(ArticleService.class);
一个容器就此诞生。因为它解决的是依赖的问题,把被依赖的对象像药水一样,注入到了目标对象中,所以,它得名“依赖注入”(Dependency Injection,简称 DI)。这个容器也就被称为 DI 容器了。在没有 DI 容器之前,那是怎样的一个蛮荒时代啊!有了 DI 容器之后呢?你的代码就只剩下关联的代码,对象的创建和组装都由 DI 容器完成了。甚至在不经意间,你有了一个还算不错的设计:至少你做到了面向接口编程,它的实现是可以替换的,它还是可测试的。
Inversion of control In software engineering, inversion of control (IoC) is a programming principle. IoC inverts the flow of control as compared to traditional control flow. In IoC, custom-written portions of a computer program receive the flow of control from a generic framework. A software architecture with this design inverts control as compared to traditional procedural programming: in traditional programming, the custom code that expresses the purpose of the program calls into reusable libraries to take care of generic tasks, but with inversion of control, it is the framework that calls into the custom, or task-specific, code. traditional control flow 是从开始到结束都是自己“写代码”,IoC 中control flow的发起是由一个framework 触发的。类只是干自己的活儿——“填代码”,然后ioc在需要的时候调用。
IOC设计模式的两个重要支持:
- 对象间依赖关系的建立和应用系统的运行状态没有很强的关联性,因此对象的依赖关系可以在启动时建立好,ioc容器(负责建立对象的依赖关系)不会对应用系统有很强的侵入性。
- 面向对象系统中,除了一部分对象是数据对象外,其他很大一部分是用来处理数据的,这些对象并不经常发生变化,在系统中以单件的形式起作用就可以满足应用的需求。
陈皓:控制反转(Inversion of Control,loC )是一种软件设计的方法,它的主要思想是把控制逻辑与业务逻辑分开(程序=控制逻辑+业务逻辑),不要在业务逻辑里写控制逻辑,因为这样会让控制逻辑依赖于业务逻辑,而是反过来,让业务逻辑依赖控制逻辑。 晓土:控制反转是在以解耦为目标驱动而产生的一种思想,终极目标就是通过IOC容器提供中间商/第三方的作用,让对象之间的依赖不靠对象自身控制。引入第三方平台后,对象的主动控制被剥夺,不再自主显式创建所要依赖的对象,而是被动的由第三方平台来控制,当执行到需要其他对象的时候,第三方平台会自动返回所需对象。PS:第三方平台一般直接负责创建所有对象了。在ioc的眼里各个对象之间都是独立的存在,他们之间的依赖关系也只是被写到注册表里面,运行的时候回去检查依赖所需,按需分配,把对象“粘合”到容器里面。
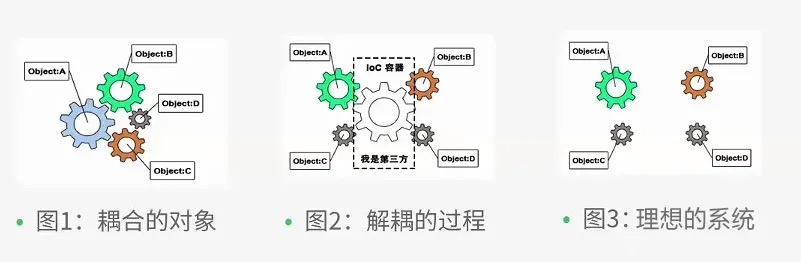
ioc 的接口定义
什么是ioc容器?BeanFactory是最简单的ioc容器,看了BeanFactory接口方法,也许会更直观(主要包括获取bean、查询bean的特性等方法)。BeanFactory收敛了所以上层的能力,具体包含核心的BeanDefinitionRegistry和BeanFactory,也就是bean的定义和生产bean的工厂。
interface BeanFactory{
FACTORY_BEAN_PREFIX
object getBean(String)
T getBean(String,Class<T>)
T getBean(Class<T>)
boolean containsBean(String)
boolean isSingleton(String)
boolean isPrototype(String)
boolean isTypeMatch(String,Class<T>)
class<?> getType(String)
String[] getAliases
}
BeanFactory
属于spring-beans包
The root interface for accessing a Spring bean container.This is the basic client view of a bean container;The point of this approach is that the BeanFactory is a central registry of application components, and centralizes configuration of application components (no more do individual objects need to read properties files,for example).
Note that it is generally better to rely on Dependency Injection(“push” configuration) to configure application objects through setters or constructors, rather than use any form of “pull” configuration like a BeanFactory lookup. Spring’s Dependency Injection functionality is implemented using this BeanFactory interface and its subinterfaces.

- 作为一个BeanFactory,要能够getBean、createBean、autowireBean、根据各种Bean的信息检索list bean、支持父子关系,这些能力被分散在各个接口中
- AbstractBeanFactory 负责实现BeanFactory,同时留了一些抽象方法交给子类实现
- 如何对 BeanFactory 施加影响?BeanPostProcessor,Factory hook that allows for custom modification of new bean instances,e.g. checking for marker interfaces or wrapping them with proxies.
实际使用
AutowireCapableBeanFactory factory = new ...
xxBean xx = new xxBean();
factory.autowireBean(xxBean);
factory.initializeBean(xxBean, ...);
ApplicationContext

属于spring-context包
AbstractRefreshableApplicationContext 虽然实现了BeanFactory接口,但其实是组合了一个beanFactory,这是讨论BeanFactory 和 ApplicationContext 差异时最核心的一点。 也正因此,ApplicationContext is a complete superset of the BeanFactory.
public abstract class AbstractRefreshableApplicationContext extends AbstractApplicationContext {
private DefaultListableBeanFactory beanFactory;
public final ConfigurableListableBeanFactory getBeanFactory() {
synchronized (this.beanFactoryMonitor) {
if (this.beanFactory == null) {
throw new IllegalStateException("BeanFactory not initialized or already closed - " +
"call 'refresh' before accessing beans via the ApplicationContext");
}
return this.beanFactory;
}
}
}
In contrast to a plain BeanFactory, an ApplicationContext is supposed to detect special beans(BeanFactoryPostProcessor/BeanPostProcessor/ApplicationListener)defined in its internal bean factory
public abstract class AbstractApplicationContext{
public void refresh(){
...
prepareBeanFactory(beanFactory);
...
registerBeanPostProcessors(beanFactory);
...
}
protected void prepareBeanFactory(ConfigurableListableBeanFactory beanFactory) {
...
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));
...
}
}
beanFactory.addBeanPostProcessor(new ApplicationContextAwareProcessor(this));ApplicationContextAwareProcessor是一个BeanPostProcessor,其作用就是当发现 一个类实现了ApplicationContextAware等接口时,为该类注入ApplicationContext 成员。
public static void registerBeanPostProcessors(...){
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanPostProcessor.class, true, false);
...
for (String ppName : postProcessorNames) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
priorityOrderedPostProcessors.add(pp);
}
...
registerBeanPostProcessors(beanFactory,priorityOrderedPostProcessors);
}
BeanFactory VS ApplicationContext
ApplicationContexts can autodetect BeanPostProcessor beans in their bean definitions and apply them to any beans subsequently created.Plain bean factories allow for programmatic registration of post-processors,applying to all beans created through this factory.
可以说,BeanFactory 基本实现了一个bean container 需要的所有功能,但其一些特性要通过programmatic来支持,ApplicationContext在简单容器BeanFactory的基础上,增加了许多面向框架的特性。《Spring技术内幕》中参照XmlBeanFactory的实现,以编程方式使用DefaultListableBeanFactory,从中我们可以看到Ioc容器使用的一些基本过程。
ClassPathResource res = new ClassPathResource("beans.xml");
DefaultListableBeanFactory factory = new DefaultListableBeanFactory();
XmlBeanDefinitionReader reader = new XmlBeanDefinitionReader(factory);
reader.loadBeanDefinitions(res);
简单来说,reader.loadBeanDefinitions(res);将类信息从beans.xml 读取到DefaultListableBeanFactory及其父类的各种map中。然后factory.getBean时即可做出对应的反应。
ioc启动与停止
ioc/容器上下文生命周期(从这个视角也可以看下 ApplicationContext 与BeanFactory 的不同)
- 上下文启动准备阶段 prepareRefresh
- BeanFactory 创建阶段 obtainFreshBeanFactory
- BeanFactory 准备阶段 prepareBeanFactory
- BeanFactory 后置处理阶段 postProcessBeanFactory
- BeanFactory 注册BeanPostProcessor 阶段
- 初始化内建Bean: MessageSource
- 初始化内建Bean:Spring 事件广播器
- Spring 应用上下文刷新阶段
- Spring 事件上下文注册阶段
- BeanFactory 初始化完成阶段
- Spring 应用上下文刷新完成阶段
- Spring 应用上下文启动阶段
- Spring 应用上下文停止阶段
- Spring 应用上下文关闭阶段
一个容器的功能:构建和管理Bean, 分割在启动和getBean 两个部分,启动时候没有创建Bean 对象。所以BeanFactoryPostProcessor 工作在ioc 启动阶段,BeanPostProcessor 工作在getBean 阶段。
容器启动
AbstractApplicationContext.refresh(): Load or refresh the persistent representation of the configuration such as xml. ApplicationContext 支持的很多特性都可以在个启动方法里找到迹象。
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context. 加入了Bean依赖以及非Bean依赖(比如Environment)
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}catch (BeansException ex) {
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
其中obtainFreshBeanFactory ==> refreshBeanFactory
// AbstractRefreshableApplicationContext.java
protected final void refreshBeanFactory() throws BeansException {
if (hasBeanFactory()) {
destroyBeans();
closeBeanFactory();
}
try {
DefaultListableBeanFactory beanFactory = createBeanFactory();
beanFactory.setSerializationId(getId());
customizeBeanFactory(beanFactory);
loadBeanDefinitions(beanFactory);
synchronized (this.beanFactoryMonitor) {
this.beanFactory = beanFactory;
}
}
catch (IOException ex) {
throw new ApplicationContextException("I/O error parsing bean definition source for " + getDisplayName(), ex);
}
}
refreshBeanFactory 中beanFactory 的refresh 更纯粹一点:从xml、注解 等处构造BeanDefinitions 信息。ApplicationContext refresh 杂活比较多,还要管 Listeners、MessageSource、Event ,给beanFactory 塞一些特殊的类实例或逻辑。
停止逻辑
public void close() {
synchronized (this.startupShutdownMonitor) {
doClose();
// If we registered a JVM shutdown hook, we don't need it anymore now:We've already explicitly closed the context.
if (this.shutdownHook != null) {
try {
Runtime.getRuntime().removeShutdownHook(this.shutdownHook);
}catch (IllegalStateException ex) {
// ignore - VM is already shutting down
}
}
}
}
ioc 中的对象
| 来源 | Spring Bean对象 | 生命周期管理 | 配置元信息 是否lazyload/autowiring等 |
使用场景 |
|---|---|---|---|---|
| Spring BeanDefinition | 是 | 是 | 有 | 依赖查找、依赖注入 |
| 单体对象 | 是 | 否 | 无 | 依赖查找、依赖注入 |
| Resolvable Dependency | 否 | 否 | 有 | 依赖注入 |
bean在不同阶段的表现形式
| 表现形式 | 与jvm类比 | |
|---|---|---|
| 配置文件 @Configuration注释的class等 |
<bean class=""></bean> |
java代码 |
| ioc初始化 | BeanDefinition | class二进制 ==> 内存中的Class对象 |
| getBean | Object | 堆中的对象实例 |
@Configuration 含义 indicates that a class declares one or more @Bean methods and may be processed by the Spring container to generate bean definitions and service requests for those beans at runtime.
Bean工厂的养料——BeanDefinition
在BeanFactory 可以getBean之前,必须要先初始化,从各种源(比如xml配置文件、@Bean)中加载bean信息。
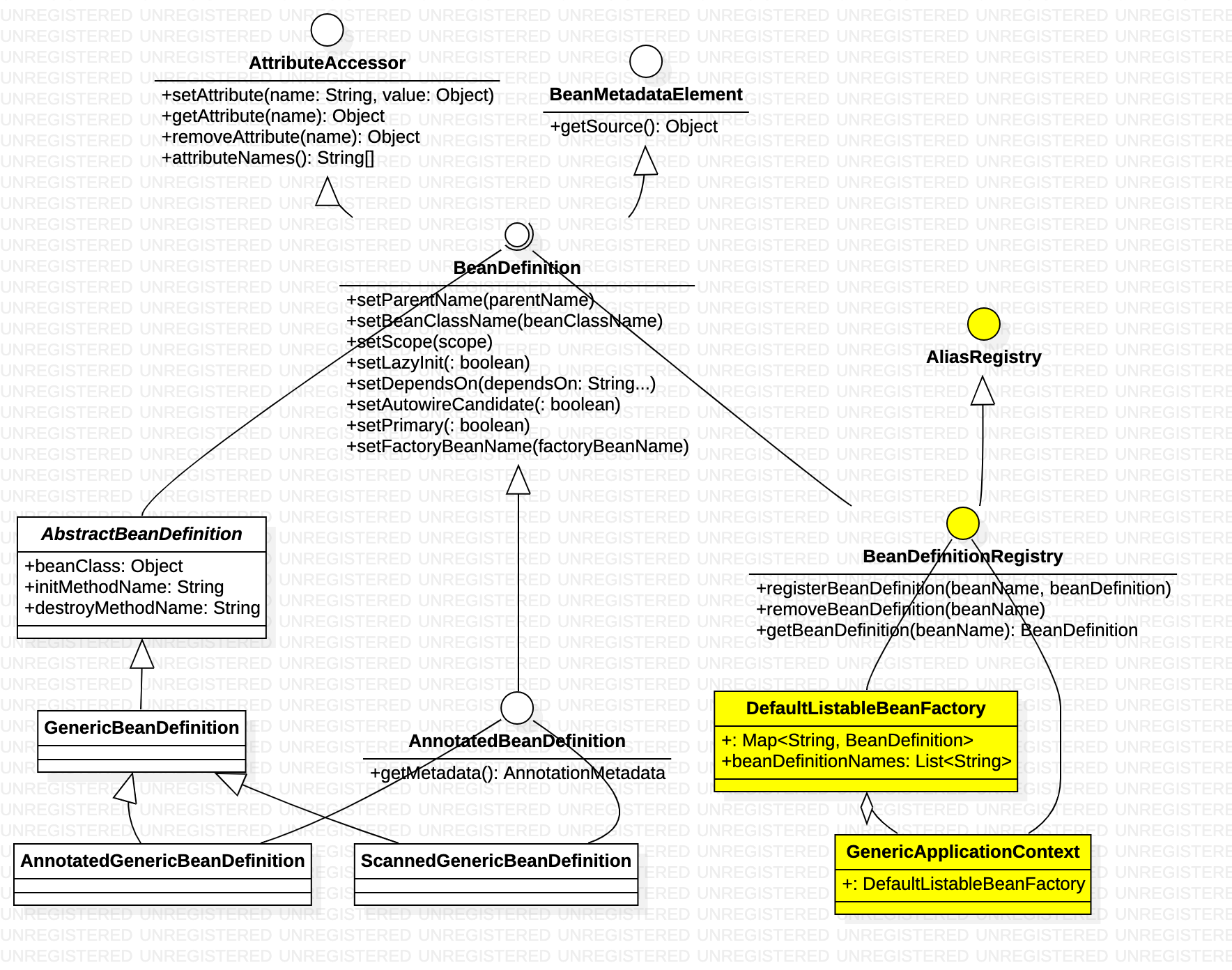
jvm 基于Class 对象将对象实例化,想new 一个对象,得先有Class 对象,或者使用classLoader 加载,或者动态生成。spring 容器类似,想getBean 对象bean 实例, 就是先register 对应的BeanDefinition,任何来源的bean 通过BeanDefinitionRegistry.registerBeanDefinition 都可以纳入到IOC 的管理。
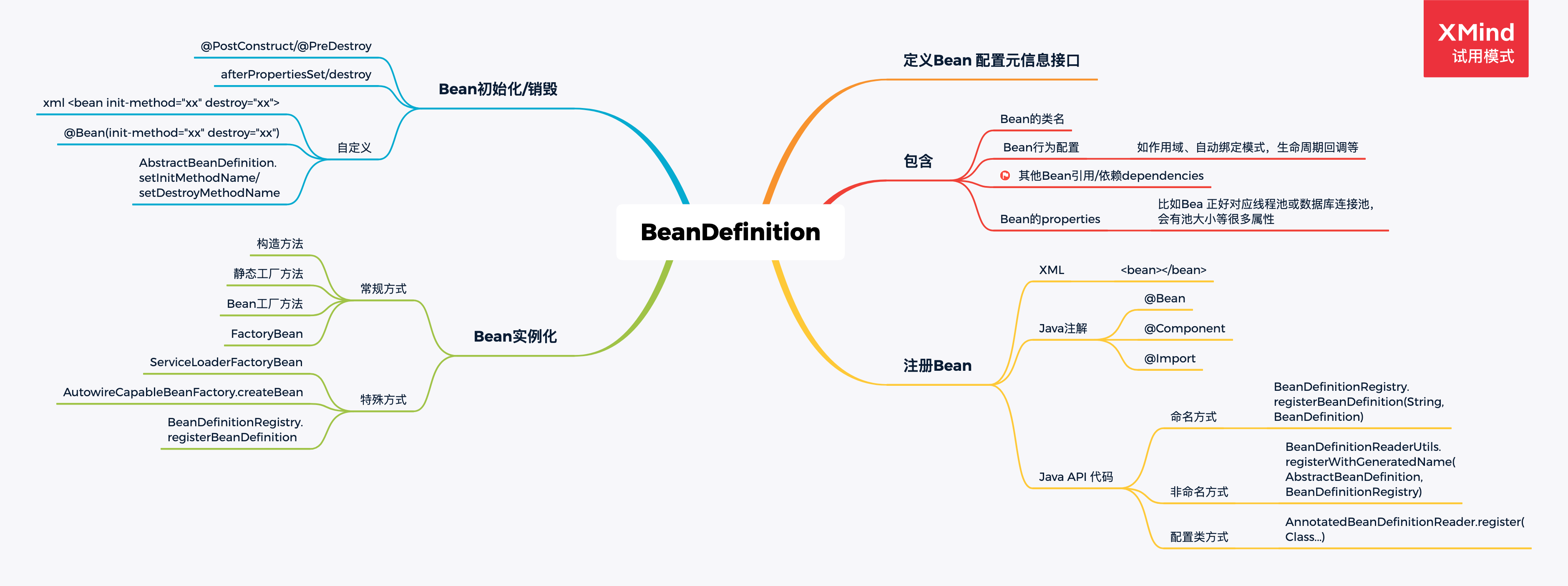
SpringBean 生命周期
- Spring Bean 元信息配置阶段
- Spring Bean 元信息解析阶段。面向资源的BeanDefinition 解析(BeanDefinitionReader和xml 解析器BeanDefinitionParser)和面向注解的BeanDefinition 解析(AnnotatedBeanDefinitionReader,比如@ComponentScan)
- Spring Bean 注册阶段。BeanDefinitionRegistry
- Spring BeanDefinition 合并阶段
- Spring Bean Class 加载阶段。每个BeanDefinition 对应一个Bean的class,必然会经过ClassLoader 的加载
- Spring Bean 实例化前阶段。InstantiationAwareBeanPostProcesssor.postProcessBeforeInstantiation,比如通过创建一个代理类的方式来创建一个实例来替换传统的实例方法。
- Spring Bean 实例化阶段
- Spring Bean 实例化后阶段。InstantiationAwareBeanPostProcesssor.postProcessAfterInstantiation,决定bean的属性值是否需要被设置
- Spring Bean 属性赋值前阶段。 InstantiationAwareBeanPostProcesssor.postProcessPropertyValues
- Spring Bean Aware 接口回调阶段
- Spring Bean 初始化前阶段。BeanPostProcessor.postProcessBeforeInitialization
- Spring Bean 初始化阶段。@PostConstruction;InitializingBean.afterProperties;自定义初始化方法
- Spring Bean 初始化后阶段。BeanPostProcessor.postProcessAfterInitialization
- Spring Bean 初始化完成阶段
- Spring Bean 销毁前阶段
- Spring Bean 销毁阶段
- Spring Bean 垃圾收集
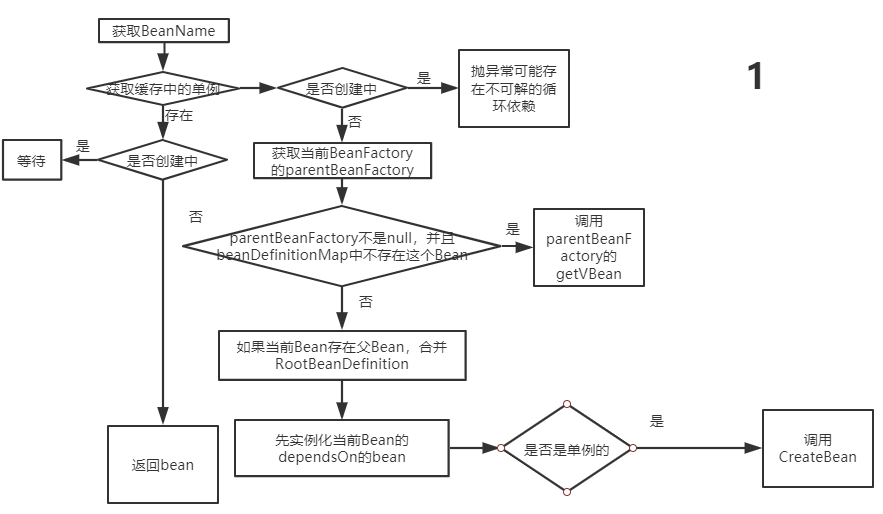
getBean
Spring的Bean生命周期,11 张高清流程图及代码,深度解析BeanFactory.getBean("beanid")得到bean的实例
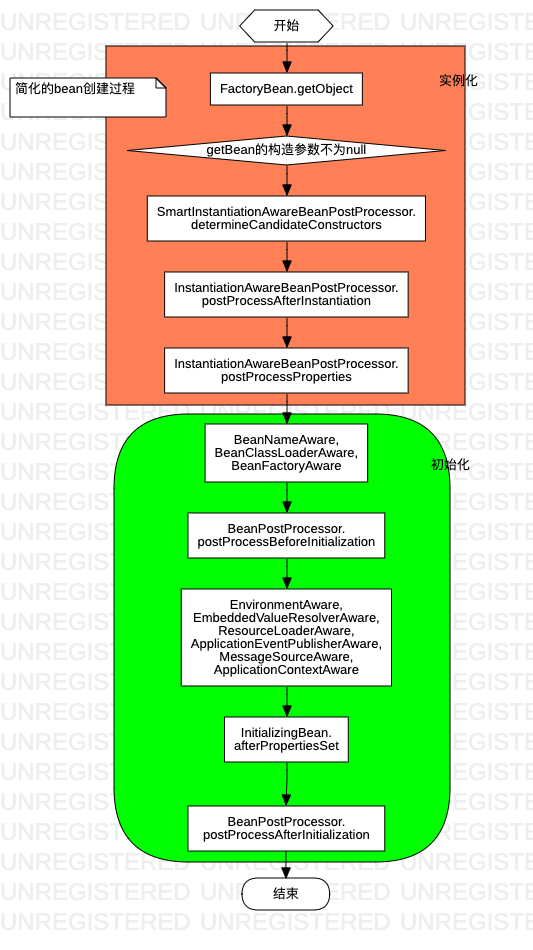
ioc在实例化bean的过程中,还夹了不少“私货”/“钩子”:
内建对象Environment
Interface representing the environment in which the current application is running.Models two key aspects of the application environment: profiles and properties. Environment代表着程序的运行环境,主要包含了两种信息,一种是profiles,用来描述哪些bean definitions 是可用的;一种是properties,用来描述系统的配置,其来源可能是配置文件、jvm属性文件、操作系统环境变量等。
并不是所有的Bean 都会被纳入到ioc管理,A profile is a named, logical group of bean definitions to be registered with the container only if the given profile is active. Beans may be assigned to a profile whether defined in XML or via annotations; see the spring-beans 3.1 schema or the @Profile annotation for syntax details.
Properties play an important role in almost all applications,and may originate from a variety of sources: properties files, JVM system properties, system environment variables, JNDI, servlet context parameters, ad-hoc Properties objects,Maps, and so on. The role of the environment object with relation to properties is to provide the user with a convenient service interface for configuring property sources and resolving properties from them.

其它
Spring容器本质上就是一个存放了一个个描述不同对象属性和方法的定义单元,需要使用的时候就通过反射机制把对象创建好,再将描述的属性初始化。
Spring 元信息
- Spring Bean配置元信息 BeanDefinition
- Spring Bean属性元信息 PropertyValues
- Spring 容器配置元信息
- Spring 外部化配置元信息 PropertySource
- Spring Profile 元信息 @Profile
当大家第一次去看Spring Bean扫描的逻辑时,它的逻辑是很复杂的,如果让我们自己去实现一个,你可能会很简单的设计出来,根据指定的路径扫描所有的类,如果有@Component的注解时就存放到BeanDefinnitionMap中,那为什么Spring要设计得这么复杂呢,原因是现实场景中Bean定义有多种方法,比如嵌套定义Bean,再比如先扫描出一部分Bean,此时这些Bean中有定义@CompentScan,又可以加载其它的Bean,所以你看这么多你不曾考虑的场景叠加在一起,实现起来的复杂度自然就高了。
留下评论