数据并行——ps
简介
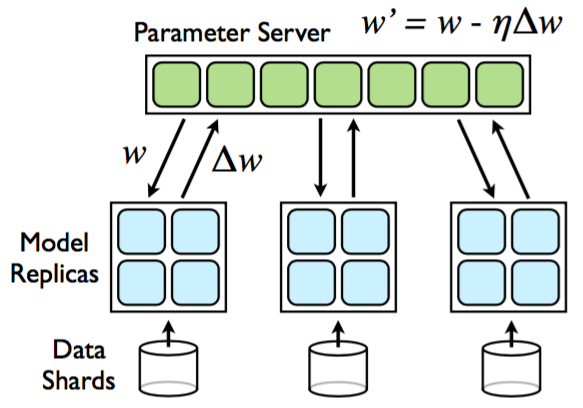
第一手的材料 就是李沐大神的 论文Scaling Distributed Machine Learning with the Parameter Server 巨大的模型其实就是巨大的参数。 Parameter Server分布式训练概述(上篇)
早期,ps 和worker 是独立部署的,分别维护,worker 启动后给他分配ps 运行。后来,一个job的ps 和 worker 同时部署,此时也称为伴生ps。
基本过程
机器学习参数服务器ps-lite (1) —– PostOffice如果做一个类比,参数服务器是机器学习领域的分布式内存数据库,其作用是存储模型和更新模型。
我们来看看机器学习的几个步骤,这些步骤不断循环往复。
- 准备数据:训练进程拿到权重 weight 和数据(data + label);
- 前向计算:训练进程使用数据进行前向计算,得到 loss = f(weight, data & label);
- 反向求导:通过对 loss 反向求导,得到导数 grad = b(loss, weight, data & label);
- 更新权重:weight -= grad * lr;
-
来到1,进行下一次迭代; 如果使用参数服务器训练,我们可以把如上步骤对应如下:
- 参数下发:参数服务器服务端 将 weight 发给 每个worker(或者worker自行拉取),worker就是参数服务器Client端;
- 并行计算:每个worker 分别完成自己的计算(包括前向计算和反向求导);
- grad 收集:参数服务器服务端 从每个 Worker 处得到 grad,完成归并(或者worker自行推送);
- 更新权重:参数服务器服务端 自行将 grad 应用到 weight 上;
- 来到1,进行下一次迭代;
为什么弄一个ps server
- 分布式训练是一种特殊的分布式计算,反向传播时涉及到梯度的汇总与计算,相对于一般的spark/mapreduce 就复杂了不少
- 单节点的内存容量支持的模型大小有限。(embedding 的特点使得worker 每次只需要pull 部分weight, 一些optimizer 算法 可能要花费两三倍 weight的空间)。
以往的分布式计算,比如mapreduce的原理,是将任务和数据分配到多个节点中做并行计算,来缩短任务的执行时间。对于分布式训练来说,同样是希望将训练任务部署到多个节点上并行计算,但是因为反向传播涉及到梯度的汇总和权重的更新,相比之前的分布式计算更加复杂。也有采用hadoop或者spark的分布式训练,用单个driver或者master节点来汇总梯度及更新权重,但是受限于单节点的内存容量,支持的模型大小有限。另外,集群中运行最慢的那个worker,会拖累整个训练的迭代速度。为了解决这些问题,Parameter Server做了新的设计。
两点设计使ps能够克服Master/Slave架构应用于大规模分布式训练时的困难:
- 所有参数不再存储于单一的master节点,而是由一群ps server节点负责存储、读写;
- 得益于推荐系统的特征是超级特征的特点,一个batch的训练数据所包含的feature数目是有限的,因此,我们没必要训练每个batch时都将整个模型(i.e., 上亿的embedding)在server/worker之间传来传去,而只传递当前batch所涵盖的有限几个参数就可以了。
几点设计
优化点:每个kv都是都是很小的值,如果对每个key都发送一次请求,那么服务器会不堪重负。为了解决这个问题,可以考虑利用机器学习算法中参数的数学特点(即参数一般为矩阵或者向量),将很多参数打包到一起进行更新。
异步
每个worker 互相不干扰,各自 pull 参数,然后计算梯度后,再通过 push 将梯度值回传给 server。server 再汇总所有 worker 的梯度结果后一起更新最终参数。这里的异步有2个方面
- optimizer 更新参数(学习率和梯度)
- 同步训练:每一轮迭代所有worker都要保持同步,每个worker只进行一次前向和后向计算,server收集所有worker的梯度求平均并更新参数,然后进行下一轮迭代。对于同步训练,每一次迭代的训练速度,取决于整个系统中最慢的worker和最慢的server。
- 异步训练,每个worker各自进行前后向计算,不需要等待其他worker,持续地进行迭代。而在server侧, 只要有worker push新的梯度过来,就会更新参数。
- 另一个问题是pull-计算-push 这个操作太频繁,通信有压力,拖慢计算。所以可以采取时效性不那么高的方法,就是不必每次都 pull 和 push,比如worker计算出第10次迭代的梯度之后,立即进行第11次迭代,而不需要pull新的权重过来,没有等待时间,效率较高;
重温经典之ps-lite源码解析(1):基础在纯异步的ASP模式中,每台worker在发送完自己的梯度后,不用等其他worker,就可以开始训练下一个batch的数据。由于无须同步,ASP的性能优势比较明显。但是,的确存在可能性,一个非常慢的worker基于老参数计算出过时梯度,传到server端会覆盖一些参数的最新进展。但是在实际场景下,由于推荐系统的特征空间是超级稀疏的,因此两个worker同时读写同一feature造成冲突的可能性还是较低的,因此纯异步ASP模式的应用还是比较普遍的。
浅谈工业界分布式训练(一)同步更新虽然可以保证Consistency,但由于各节点计算能力不均衡无法保证性能,而异步更新或者半同步更新并没有理论上的收敛性证明,Hogwild!算法证明了异步梯度下降在凸优化问题上按概率收敛,而深度学习问题一般面对的是非凸问题,所以无论异步和半同步算法都无收敛性的理论保障。所以只是根据经验,大部分算法在异步更新是可以收敛,求得最优或者次优解(其实现在无论是学术界和工业界,深度学习只要效果好就行)。当然目前比较好的方式针对针对SparseNet部分( 低IO pressure, 但高memory consumption),DenseNet部分 (高IO pressure,但低memory consumption)的特点,对sparsenet进行异步更新(因为Embedding Lookuptable的更新是稀疏的,每个worker更新不同的特征,冲突率较低),DenseNet采用同步更新/AllReduce的方式尽量逼近同步训练的效果。PS:为了防止模型不收敛,一般框架同步异步都会支持。hogwild 一般特指 parameter server 最常见的用法:完全无锁的异步训练。hogwild 这个术语本身在学术界用的更多,工程上用的比较少。
分布式
ps server 并不是只有一个master 来分发所有参数,而是存在一个 Server group,即多个 server 机器,每个机器只负责存一部分参数就行。这样就避免唯一 master 不停广播的通信代价问题。前面说了,server 存的是<key,value>,每个 server 上这个 key 的范围就是通多一致性哈希来分配的。这样设计有个好处,就是加入一个新节点,或者丢失删除一个节点后,参数可以通过环形只在相邻的节点上调整即可,避免节点频繁大规模的参数变动。
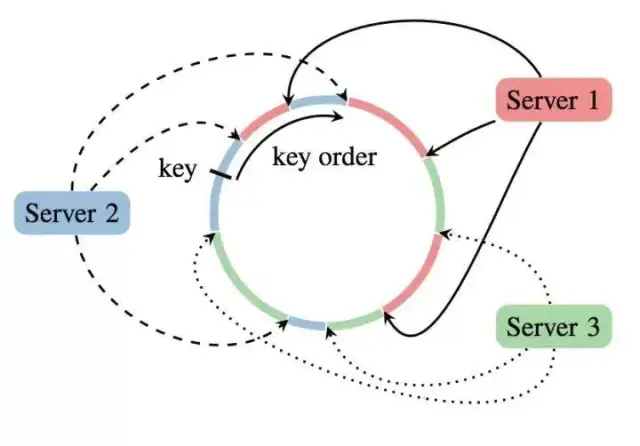
ElasticDL Parameter Server Design
- 可以存的更多。models could be large and overrun the memory space of a single PS instance. In such case, we need to partition the model and store different partitions in different PS instances.
- 分担通信负担。distributes the model parameter communication from workers among PS instances.
存储两类数据
广告推荐中大规模分布式模型 ps server 上存储的参数格式是<key, value>对,支持set/get/update 以及自定义函数。每个 worker 读入一个 batch 数据后,会向 server 执行 pull 操作,获取当前计算需要的参数的最新的值。比如稀疏参数的获取,发现样本中,location 这一维特征有北京,上海,南京3个sign,那么则将这3个当做 key 去请求 server 获得当前的最新 embedding 向量。计算前向和梯度,也是需要 dense 模型参数的,所以也会 pull DNN 网络的参数。
Each PS node has a dictionary-based data structure to store its partition of model parameters.We consider two kinds of model parameters:
- non-embedding parameters,一般不大,不分区,存在一个ps 上,tf.Variable name 作为key,tf.Variable 作为value。可以使用
hash(p_name) % N选择存储的ps - embedding tables,Each embedding layer has an embedding table which maps a discrete ID i to an embedding vector vᵢ. Embedding tables could be huge, especially in some recommending and ranking models. Thus, we partition each embedding table and store every partition in an unique PS pod. For an embedding vector vᵢ, we select the (i mod N)-th parameter server to store it. To store an embedding vector, We use its corresponding embedding layer name and discrete ID as the key, and a 1-D numpy.ndarry as the value. PS:例如一个形状为 [m, n, l, k] 的 tensor 可以按切片的数量保存为 m 个形状为 [n, l, k] 的 KV 数据,key 为 tensor_name 和 m 维度序号组合的唯一命名。 针对大规模 Embedding 参数的定制处理
初始化:We use lazy initialization for model parameters in PS. PS does not have the model definition. Thus workers are responsible for initializing parameters and push the initialized parameters to corresponding PS pods. Each PS pod has a parameter initialization status, which is False after the PS pod launch.
- When a worker tries to get non-embedding parameters from the PS pod through a RPC call pull_variable, the PS pod tells the worker that the parameter initialization status is False in response. If the worker has already initialized non-embedding parameters, it sends non-embedding parameter values to the PS pod by a gRPC call push_model. When the PS pod receives non-embedding parameters in its first RPC service for push_model, it initializes non-embedding parameters and sets the parameter initialization status as True.PS: 这也是为什么 ps 挂了没事,worker 会push
- For an embedding vector, the corresponding PS pod will initialize it in the first pull_embedding_vector service that contains this embedding vector. The PS pod needs the embedding vector size and the initialization method for the initialization. The embedding vector size and the initialization method are in the model definition and workers can send them in push_model to PS pods together with non-embedding parameter values.
参数更新:
- A worker computes gradients in each training iteration, which contain gradients for non-embedding parameters and some embedding vectors if applicable. The worker partitions these gradients using their corresponding parameter names or discrete IDs for embedding vectors. Then the worker sends gradient partitions to their corresponding PS pods by RPC calls push_gradient.When a PS pod receives gradients in push_gradient, it uses a TensorFlow optimizer to apply gradients to non-embedding parameters.
- We have already implemented an OptimizeWrapper to sparsely update embedding vectors. OptimizeWrapper uses corresponding embedding vectors to form a temporary variable, applies gradients to this temporary variable, and writes results back to these embedding vectors. The PS pod can use this OptimizeWrapper directly to update embedding vectors.
故障恢复:The model may contain one or more embedding layers with embedding tables as their parameters. If so, a minibatch of training data in a worker contains some embedding IDs, which correspond to a subset of embedding tables. The worker pulls all non-embedding parameters and only a subset of embedding tables from PS pods in the training. Thus, the PS pod can recover non-embedding parameters from workers but not embedding tables.
- For non-embedding parameters, the PS pod can recover them from workers in the same way as the parameter initialization by setting its parameter initialization status as False.
- For embedding tables, PS creates replicas to support fault-tolerance. For each PS pod PSᵢ, it can store M replicas of its embedding table partitions in M PS pods indexed from (i+1) mod N to (i+M) mod N. The relaunched PS pod can recover embedding tables from one of its replicas. PS: 一个ps 存了两份 replica,还周期性的同步呢。
Live replication of parameters between servers supports hot failover. Failover and selfrepair in turn support dynamic scaling by treating machine removal or addition as failure or repair respectively. PS:多副本 ==> 容错 ==> 弹性。每个参数会在PS集群中有三个副本,存储在不同的节点上来实现冗余。其中一个节点会被选为primary,来提供针对某个参数的服务。当这个节点失效时,另外两个副本中会被挑选出一个作为新的primary,来继续此参数的服务。因而,参数服务器也是需要调度的。
实现
一个大神的简单 c实现 Superjomn/SwiftSnails
ElasticDL——ps实现
ElasticDL Parameter Server Design
Message Definition
message Tensor {
enum DataType {
BOOL = 0;
INT16 = 1;
INT32 = 2;
INT64 = 3;
FP16 = 4;
FP32 = 5;
FP64 = 6;
}
string name = 1;
DataType data_type = 2;
repeated int64 dim = 3;
bytes content = 4;
repeated int64 indices = 5;
}
message EmbeddingTableInfo{
string name = 1;
repeated int64 dim = 2;
string initializer = 3;
}
message Model {
int64 version = 1;
# repeated 则表示数组
repeated Tensor variables = 2;
repeated EmbeddingTableInfo embedding_table_info = 3;
}
message PullVariableRequest{
int64 version = 1;
}
message PullVariableResponse{
bool model_init_status = 1;
Model model = 2;
}
message PushGradientRequest{
int32 model_version = 1;
repeated Tensor gradients = 2;
}
message PushGradientResponse{
bool accepted = 1;
int32 model_version = 2;
}
message PullEmbeddingVectorRequest{
string name = 1;
repeated int64 ids = 2;
}
message SynchronizeEmbeddingRequest {
int32 replica_index = 1;
}
message SynchronizeEmbeddingResponse {
repeated Tensor embedding_vectors = 1;
}
RPC Definition
service PServer{
# pull trainable tensorflow variables created by Keras layers
rpc pull_variable(PullVariableRequest) returns (PullVariableResponse);
# pull embedding vectors in ElasticDL embedding layers
# Do we need to create a new message `PullEmbeddingVectorRequest` rather than use `Tensor`?
rpc pull_embedding_vector(PullEmbeddingVectorRequest) returns (Tensor);
# push trainable tensorflow variables and meta info for ElasticDL embedding layers
rpc push_model(Model) returns (google.protobuf.Empty);
rpc push_gradient(PushGradientRequest) returns (PushGradientResponse);
# PS to recover embedding vectors after relaunch
rpc get_replica(SynchronizeEmbeddingRequest) returns (SynchronizeEmbeddingResponse);
# PS replica synchronization
rpc synchronize_embedding(SynchronizeEmbeddingRequest) returns (SynchronizeEmbeddingResponse);
}
Data Structure
class Tensor(object):
def __init__(self, name=None, value=None, indices=None):
self.name = name
self.value = value
self.indices = indices
@classmethod
def from_tensor_pb(cls, tensor_pb):
"""Create an ElasticDL Tensor object from tensor protocol buffer.
Return the created tensor object.
"""
pass
def to_tensor_pb(self):
pass
def to_tf_tensor(self):
pass
def to_ndarray(self):
pass
def serialize_to_pb(tensor, pb):
"""Serialize ElasticDL Tensor to tensor protocol buffer."""
pass
def deserialize_from_pb(pb, tensor):
"""Deserialize tensor protocol buffer to ElasticDL Tensor."""
pass
def tensor_pb_to_ndarray(tensor):
"""Deserialize tensor protocol buffer and return a numpy ndarray."""
pass
def tensor_pb_to_tf_tensor(tensor):
"""Deserialize tensor protocol buffer and return a TensorFlow tensor."""
pass
# In `Parameters`, interfaces `set_*_param` have two arguments, `value` and `name` (or `layer_name`).If `value` is a ElasticDL `Tensor` instance, `name` can be None.Otherwise `value` is a numpy ndarray, and `name` must be specified.
class Parameters(object):
def __init__(self):
# Parameter initialization status
self.parameter_init_status = False
# Non-embedding parameter dict, maps parameter name to tf.Variable instance
self.non_embedding_params = {}
# Embedding table dict, maps embedding layer name to `EmbeddingTable` instance
self.embedding_params = {}
@property
def non_embedding_params(self):
return self._non_embedding_params
def set_embedding_param(self, value, layer_name=None):
pass
def get_embedding_param(self, layer_name, ids):
return self._embedding_params.get(layer_name).get(ids)
def set_non_embedding_param(self, value, name=None):
pass
def init_non_embedding_param(self, value, name=None):
pass
def set_meta_info(self, layer_name, dim, initializer):
pass
class EmbeddingTable(object):
def __init__(self, dim, initializer):
# Embedding vector dict, maps ID to 1-D numpy.ndarray
self._embedding_vectors = {}
# the dimension of embedding vectors
self._dim = dim
# the initializer name for initializing embedding vectors
self._initializer = initializer
def get(self, ids):
values = []
for id in ids:
if id not self._embedding_vectors:
val = initialize_embedding_vector(self._dim, self._initializer)
else:
val = self._embedding_vectors.get(id)
values.append(val)
return np.concatenate(values).reshape(len(ids), -1)
def set(self, ids, values):
pass
Here is the pseudocode for a worker to pull variable from the PS. If the non-embedding variables are not initialized, the PS will tell the worker to initialize them and report to the PS.
class PServer(elasticdl_pb2_grpc.PServerServicer):
...
def pull_variable(self, request):
res = PullModelResponse()
if self._need_initialize_model:
res.model_init_status = True
return res
res.model_init_status = False
res.model = self._get_model() # get model in this PS instance
return res
def push_model(self, request):
model = request.model
... # initialize model in this PS instance
pull和push是ps中的重要操作。
class Worker(object):
...
def pull_variable(self):
# for-loop should be implemented in multithread
for ps_index in range(self._ps_node_num):
req = PullModelRequest() # create request code keeps the same with current code
res = self._stub[ps_index].pull_variable() # pull variable from PS
if res.model_init_status:
# worker initializes its model here if needed
model = serialize_model_to_pb()
self._stub[ps_index].push_model(model) # get model in this worker
req = PullModelRequest() # create request code keeps the same with current code
res = self._stub[ps_index].pull_variable() # pull variable from PS
if res.model_init_status:
raise Error or try a pre-defined constant times
《用python实现深度学习框架》——ps实现
ps 架构的参数放在 ps 节点上,worker和ps直接通过 rpc 进行push/pull。《用python实现深度学习框架》给出的ps/worker 模型的grpc 通信api定义
service ParameterService{
# ps 接收从各个worker 发送过来的请求,拿到各个节点的梯度,并根据节点名称累加到相应的缓存中
# Push接口,各节点上传梯度
rpc Push(ParameterPushReq) returns (ParameterPushResq){}
# Pull接口,各节点下拉梯度
rpc Pull(ParameterPullReq) returns (ParameterPullResq){}
# 变量节点初始化接口
rpc VariableWeightsInit(VariableWeightsReqResp) returns(VariableWeightsReqResp){}
}
# ps server 实现
class ParameterService(xxx):
def Push(self,push_req...):
node_with_gradients,acc_no = self._deserialize_push_req(push_req)
if self.sync:
self._push_sync(node_with_gradients,acc_no)
else:
self._push_async(node_with_gradients,acc_no)
def _push_sync(self,node_with_gradients,acc_no):
if self.cond.accquire():
# 等待上一轮所有worker 等下拉完成
while self.cur_pull_num != self.worker_num:
self.cond.wait()
# 记录上传次数
self.cur_push_num +=1
# 把梯度更新到缓存
self._update_gradients_cache(node_with_gradients)
# 累计梯度数量
self.acc_no += acc_no
if self.cur_push_num >= self.worker_num:
self.cur_pull_num = 0
self.cond.notify_all()
self.cond.release()
else
self.cond.wait()
# main 实现
def train(worker_index):
...
if __name__ == '__main__':
# 解析参数
if role == 'ps':
server = ps.ParameterServiceServer(...)
server.serve()
else:
worker_index = args.worker_index
train(worker_index)
class Trainer(object):
def train_and_eval(self,train_x,train_y,test_x=None,test_y=None):
# 初始化权重变量
self._vaiable_weights_init()
# 开始模型训练
## 第一层循环,迭代epoches轮
for self.epoch in range(self.epoches):
## 模型训练
self.train(train_x,train_y)
## 模型评估
if self.eval_on_train:
...
def train(self,train_x,train_y):
# 遍历训练数据集
for i in range(len(list(train_x.values())[0])):
self.one_step(self._get_input_values(train_x,i),train_y[i])
if (i+1) % self.batch_size == 0:
self._optimizer_update()
# 执行一次前向传播和一次反向传播
def one_step(self, data_x,data_y,is_eval=False):
## 根据输入节点的名称,从输入数据dict中找到对应数据
for i in range(len(self.inputs)):
input_value = data_x.get(self.inputs[i].name)
self.inputs[i].set_value(np.mat(input_value).T)
## 标签赋值给标签节点
self.input_y.set_value(np.mat(data_y).T)
## 只有在训练阶段才执行优化器
if not is_eval:
self.optimizer.one_step()
@abc.abstractmethod
def _variable_weights_init(self):
raise NotImplementedError()
@abc.abstractmethod
def _optimizer_update(self):
raise NotImplementedError()
《用python实现深度学习框架》在分布式场景下,以ps 模式为例,只要定义一个 DistributedTrainer 实现_variable_weights_init 和 _optimizer_update 方法即可实现一个针对PS 架构的训练器。PS:allreduce 机制也大致类似,可以查看书中示例
class DistTrainerParameterServer(Trainer):
def __init__(self,*args,**kargs):
Trainer.__init__(self,*args,**kargs)
cluster_conf = kargs['cluster_conf']
ps_host = cluster_conf['ps'][0]
self.ps_client = ps.ParameterServiceClient(ps_host)
def _variable_weights_init(self):
var_weight_dict = dict()
for node in default_graph.nodes:
if isinstance(node,Variable) and node.trainable:
var_weight_dict[node.name] = node.value
# 把自己的weight 初始值发给ps
duplicated_var_weight_dict = self.ps_client.variable_weights_init(var_weights_dict)
# 使用ps返回的初始值,重新初始化本地参数
for var_name,weights in duplicated_var_weight_dict.items():
update_node_value_in_graph(var_name,weights)
print('[INIT] worker variable weights initialized')
def _optimizer_update(self):
# 把当前梯度上传到ps 上,此操作可能会block,直到所有节点都上传完成
acc_gradient = self.optimizer.acc_gradient
self.ps_client.push_gradients(acc_gradient,self.optimizer.acc_no)
# 从ps那里把所有节点的平均梯度都拉回来,此操作可能会block,直到所有节点都下拉完成
node_gradient_dict = self.ps_client.pull_gradients()
# 使用得到的平均梯度,利用优化器的优化算法,更新本地变量
self.optimizer.update(node_gradient_dict)
ps tensorflow实现
在TensorFlow 的实现中,Tensor对象及内部 TensorBuffer 对象本身始终保存在 CPU 内存上,TensorBuffer 内部指针指向的缓冲区有可能位于CPU 或GPU 内存,Tensor 的跨设备复制主要指 内部缓冲区的复制过程
- CPU 内存间的复制无需使用特殊函数,对于TensorBuffer 指向的缓冲区不做完整复制,只需复制指针并增加引用计数。
- CPU 与GPU 内存之间的数据复制 函数 需要不同GPU 设备的DeviceContext 子类重写。
Tensorflow使用gRPC 实现进程间通信,分布式模式中的每个进程具有一个 GrpcServer 实例(也包含客户端对象),包含GrpcMasterService 和 GrpcWorkerService 两个服务
| GrpcMasterService主要用于会话相关操作 | GrpcWorkerService 主要用于数据流图相关操作 | |
|---|---|---|
| 控制接口 | CreateSession,ExtendSession,… | GetStatus,RunGraph |
| 数据通信接口 | RecvTensor |
- 服务端均以异步模式实现,master 服务的客户端调用多为同步模式,worker 服务的客户端调用多为异步模式
- 对于同一进程内的 grpc 调用,均有可能直接访问本地对象
- RecvTensor 有一定特殊性,Tensor 的大小可能很大,自定义了消息传输与解析格式(没有用grpc 自带的),客户端调用的生命周期管理也有所不同
- 为进一步提高进程间数据通信性能,在保留gRPC 通信的同时,利用TensorFlow 的扩展机制,支持RDMA 特性的InfiniBand 协议栈,上层使用与grpc 接口一致,只需开启相关配置即可。
Paddle——ps实现
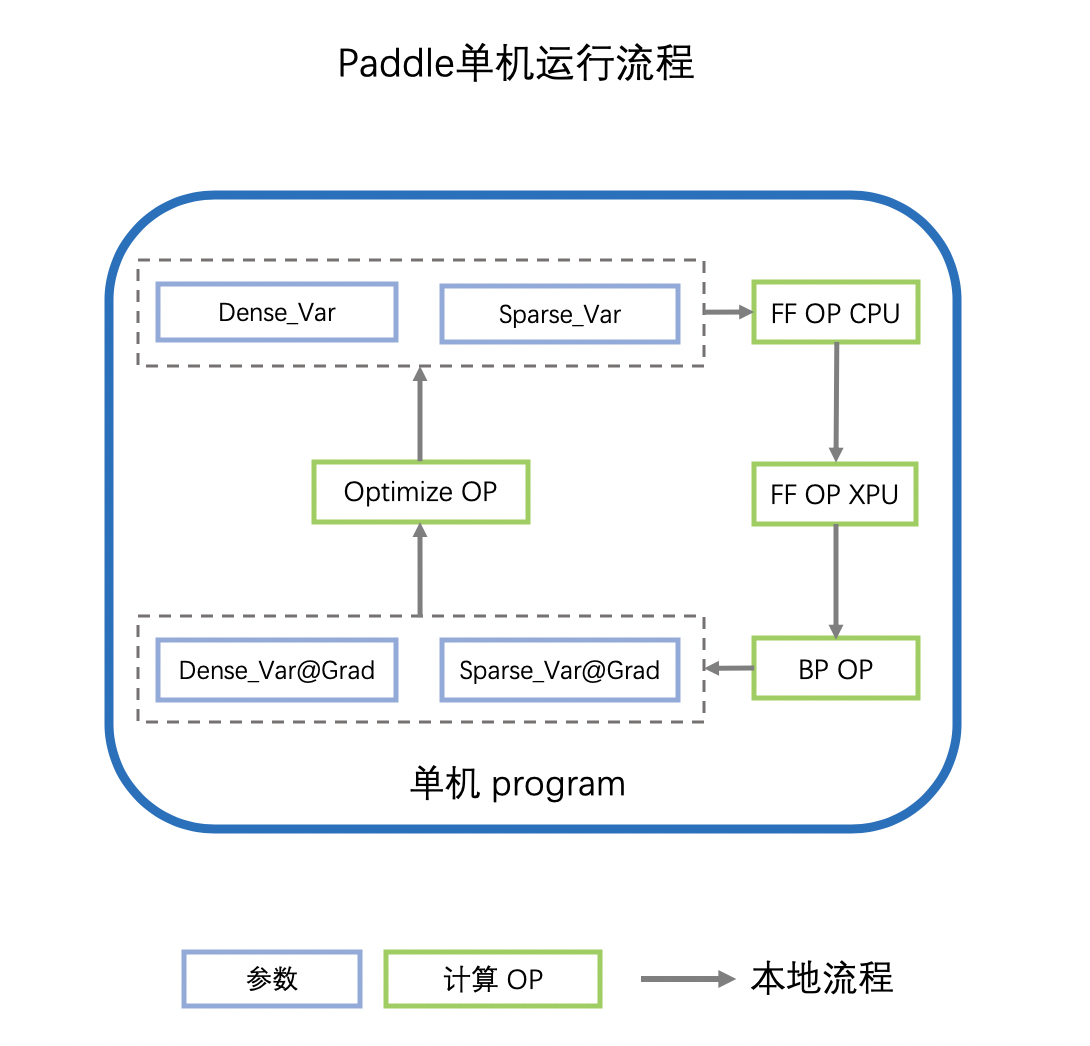
Paddle计算图拆分与优化 深度学习网络中有两个基本元素:Operator(比如加减/FC/Embedding查表) 和 Variable(分为稠密参数和稀疏参数) 单机的计算图执行流程:
- 计算图拿到参数的值(Var)之后,会首先执行前向OP(FF OP),OP可能会执行在不同的设备上,如CPU/GPU/Kunlun 或其他AI芯片,我们用XPU代指。
- 前向OP计算完成后,得到loss,会继续计算反向OP(BP OP),得到各个参数的梯度(Var_Grad)
- 指定SGD/Adam等优化器,利用参数的梯度(Var_Grad)更新原始参数(Var)
- 重复以上流程,迭代参数的更新,实现深度学习网络的训练
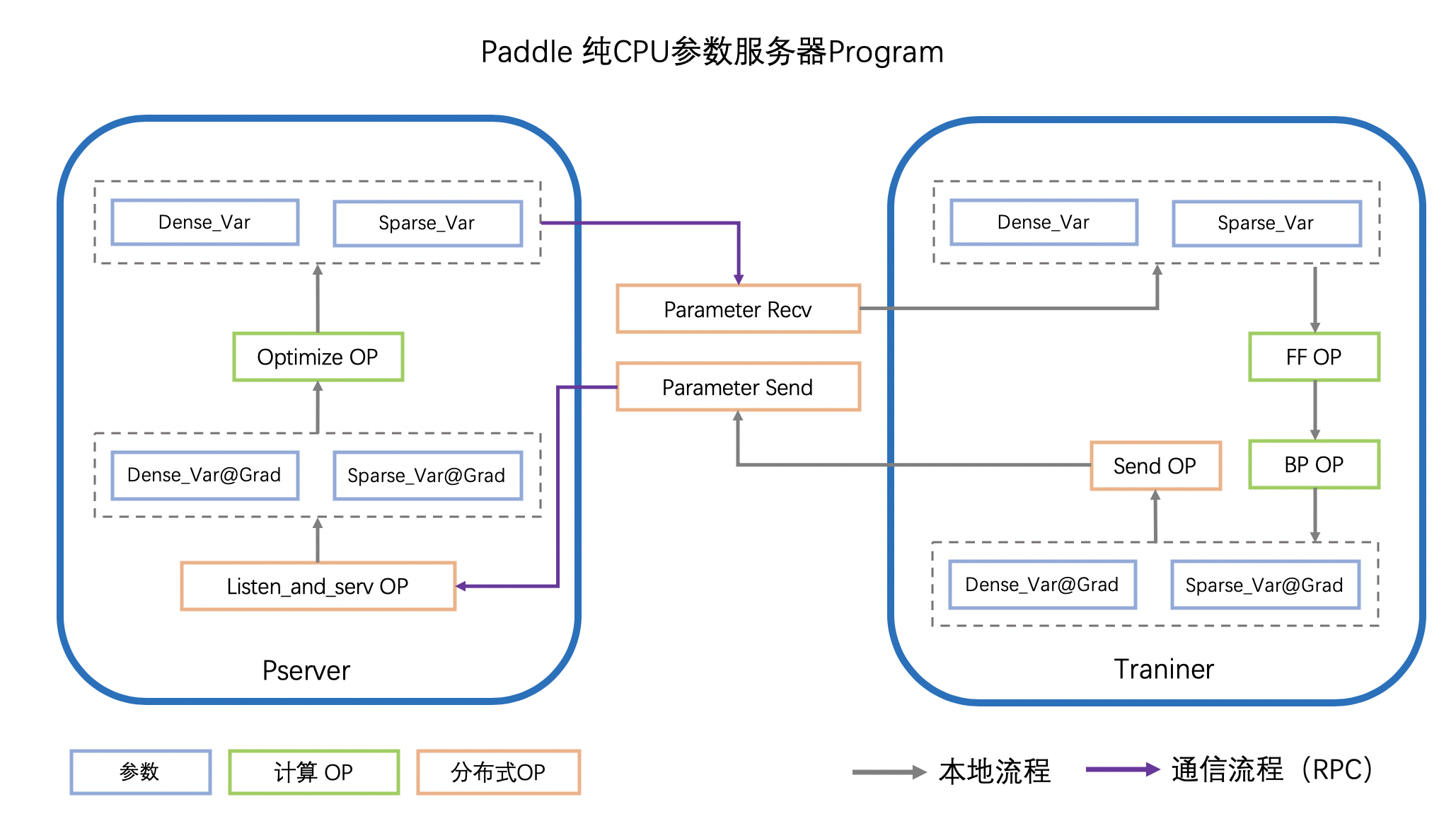
- Worker(Trainer)在计算得到参数的梯度(Var_Grad)后,会通过RPC发送给PServer
- PServer监听通信端口,将收到的不同参数分别通过不同的Oprimizer OP完成更新。 PS: 参数更新放在ps的问题是 添加新的优化算法必须修改 PS 的实现
- Worker在下一个迭代时,请求PServer上最新的参数
- 重复以上流程,迭代参数的更新,实现分布式参数服务器的训练
Paddle计算图拆分与优化参数服务器模式下,所有参数的全局真值都被分片保存在各个Pserver上,PServer执行Optimizer OP(另一种选择是 ps 只是汇总梯度,weight还是worker 更新的),执行参数的更新。以PS-CPU异步模式的计算图介绍PServer的计算图
进程内通信主要实现内存数据的跨设备复制(本地CPU和GPU内存之间、多个GPU内存之间), 进程间通信主要实现数据流和控制流基于网络协议的传输。Tensorflow 的运行时框架会根据应用代码中的集群和设备配置,在数据流图构建时自动插入通信操作,并在数据流图执行过程中动态调度这些操作。
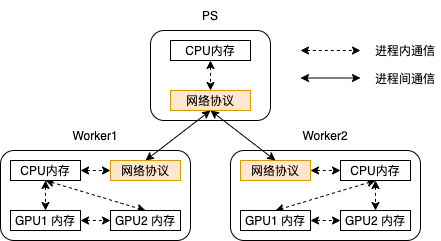
- 对于逻辑上具有数据传输语义,但物理上通信的源和目标位于同一设备、同一地址空间的进程内通信,只传输数据指针,不传输数据本身。
- 对于cpu 和gpu 内存间的设备通信,本质是跨设备内存的数据复制,尽量使用底层设备接口实现(比如DMA机制),而不是用面向应用层的API
- 涉及GPU的内存传输一般需要经过CPU 内存中转,除非使用支持RDMA 协议的高性能网络。
- 尽量做到 计算与通信过程重叠,很多通信函数采用异步模式及多线程并发执行
与allreduce 对比
机器学习参数服务器ps-lite (1) —– 历史溯源在参数服务器之前,大部分分布式机器学习算法是通过定期同步来实现的,比如集合通信的all-reduce,或者 map-reduce类系统的reduce步骤。当async sgd出现之后,就有人提出了参数服务器。
分布式常用的2种模式有ParameterServer 和 AllReduce/RingAllReduce。随着开源框架的火热迭代,再者 GPU 显存也越来越大,AllReduce 模式研究的更多一点。毕竟大多数研究的还是 dense 模型,就算上百层的网络,参数也大不到哪去。所以很多训练都是数据并行,每个节点可以存储完整的模型参数。但是像 CTR 这类用到大规模离散特征的,本质也是一个大规模离散模型,一般称为 sparse 模型。几百 G 的模型很常见,一个节点也不太可能放的下。这时候 parameter Server 模型更加适用一些。
embedding/稀疏场景优化
一文梳理推荐系统中Embedding应用实践在自然语言中,非端到端很常见,因为学到一个好的的词向量表示,就能很好地挖掘出词之间的潜在关系,那么在其他语料训练集和自然语言任务中,也能很好地表征这些词的内在联系,预训练的方式得到的Embedding并不会对最终的任务和模型造成太大影响,但却能够「提高效率节省时间」,这也是预训练的一大好处。但是在推荐场景下,根据不同目标构造出的序列不同,那么训练得到的Embedding挖掘出的关联信息也不同。所以,「在推荐中要想用预训练的方式,必须保证Embedding的预训练和最终任务目标处于同一意义空间」,否则就会造成预训练得到Embedding的意义和最终目标完全不一致。比如做召回阶段的深度模型的目标是衡量两个商品之间的相似性,但是CTR做的是预测用户点击商品的概率,初始化一个不相关的 Embedding 会给模型带来更大的负担,更慢地收敛。
阿里开源自研工业级稀疏模型高性能训练框架 PAI-HybridBackend在PS架构下使用GPU设备训练的两个问题。
- 变化的硬件资源瓶颈。疏训练主要由Embedding阶段、特征交叉(feature interation)阶段和多层感知器(MLP)阶段组成,Embedding阶段在PS范式的训练下占据了至少50%以上的训练时间。经过分析发现,Embedding阶段的算子主要以访存密集型(memory access intensive)和通信密集型的算子(communication intensive)为主,主要需要的硬件资源是内存和网络的带宽,而后两个阶段的算子则是计算密集型的算子占主导,需要的资源是算力。这意味着在PS的范式训练下,任何一个阶段都有可能存在某一种硬件资源成为瓶颈而其他硬件资源被浪费的现象。GPU使用率(SM Util)在不同的训练阶段之间呈现脉冲式变化(pulse)
- 算子细碎化(fragmentation),生产实际中的模型往往拥有上百路的Embedding特征查询,每一路的特征查询在TensorFlow内都会调用数十个算子操作(operations)。TensorFlow的引擎在调度上千级别的大量的算子操作需要额外的CPU线程开销;对于GPU设备来说,过多的 CUDA kernel 提交到流处理器上(TensorFlow下每个GPU设备只有一个stream抽象)带来了GPU Stream Multiprocessor (SM)的调度开销,同时每个算子处理数据的并发度又不高,从而很难打满GPU的计算单元。
HybridBackend架构中参数放在 worker 上,不同的稀疏特征,比如说ID类型的特征,相对来讲会非常大,对于有些特征,它的特征的量非常少,比如说省份、性别这种类型的特征。不同的特征,它的同步方式是有区别的
- 稠密参数 replication 存放,每个 worker 都有副本,梯度更新时进行 allreduce;
- 稀疏参数 partition 存放,每个 worker 只有部分分片,梯度更新时进行 alltoall。
allreduce 和 alltoall 都会使用 nccl 进行同步通信,效率较高。hb 进行 alltoall 时,通信的是稀疏梯度,而不是完整的参数,通信量上和 ps 是一致的,但是通信效率会更高。
TensorFlow在推荐系统中的分布式训练优化实践在原生的TensorFlow中构建Embedding模块,用户需要首先创建一个足够装得下所有稀疏参数的Variable,然后在这个Variable上进行Embedding的学习。
user_col = tf.feature_column.categorical_column_with_identity(key='userId', num_buckets=30001)
user_emb_col = tf.feature_column.embedding_column(user_col, 10)
然而,使用Variable来进行Embedding训练存在很多弊端:
- Variable的大小必须提前设定好,对于百亿千亿的场景,该设定会带来巨大的空间浪费;
- 训练速度慢,无法针对稀疏模型进行定制优化。 我们首先解决了有无的问题,使用HashTable来替代Variable,将稀疏特征ID作为Key,Embedding向量作为Value。相比原生使用Variable进行Embedding的方式,具备以下的优势:
- HashTable的大小可以在训练过程中自动伸缩,避免了开辟冗余的存储空间,同时用户无需关注申请大小,从而降低了使用成本。
- 针对HashTable方案实施了一系列定制优化,训练速度相比Variable有了很大的提高,可以进行千亿规模模型的训练,扩展性较好。
核心流程大致可以分为以下几步:
- 稀疏特征ID(通常我们会提前完成统一编码的工作)进入Embedding模块,借助TensorFlow搭建的Send-Recv机制,这些稀疏特征ID被拉取到PS端,PS端上的Lookup等算子会实际从底层HashTable中查询并组装Embedding向量。
- 上述Embedding向量被Worker拉回进行后续训练,并通过反向传播计算出这部分参数的梯度,这些梯度进一步被位于PS端的优化器拉回。
- PS端的优化器首先调用Find算子,从HashTable获取到梯度对应的原始稀疏参数向量和相应的优化器参数,最终通过优化算法,完成对Embedding向量和优化器参数的更新计算,再通过Insert算子插入HashTable中。
系统架构
XDL
XDL 包含 server和worker两类节点,既可以是物理节点,即server和worker分别部署在不同的物理机上,也可以是逻辑节点,即server和worker以进程的方式部署在同一台物理机上。后者是目前ps的主流做法,好处是减少了跨物理机之间的通信。
训练过程包括前向和后向计算。前向计算中,worker获取训练数据,给server发送特征ID请求,server查找对应的embedding向量并返回给worker,同时worker还要从server拉取最新的dense net,worker对embedding向量做pooling,例如求和或者平均,然后送入dense net进行计算。这部分还是worker的pull操作。后向计算,worker计算出sparse net和dense net的梯度之后发送给server,server收集到所有梯度之后,采用sgd/adagrad等各类优化算法对权重或参数做更新。这部分是worker的push操作。对于一些比较复杂的优化算法,例如,adagrad,adam等,训练过程需要累积梯度或者梯度平方项,这些累积项都存储在server中,server侧基于这些累积项和收集到的梯度,对模型权重做更新。PS: 对应的代码是哪块? 有助于分析一些框架与tf的关系
对于sparse net来说,因为特征规模庞大,所以需要较大的存储空间,又由于特征稀疏的特点,所以每一次只需要查找少量的embedding向量。所以sparse net具有存储大,但是I/O小的特点。dense net占用的存储空间较小,但是每一次训练需要拉取全部的参数,所以dense net对内存要求不大,但是对I/O要求很高。XDL采用不同的方式对两种网络进行管理。对于sparse net,使用hashmap做key-value存储,并且将所有的embedding向量均匀分布在各个server节点中,这对于缓解单个server节点的存储压力和通信都有帮助。dense net同样也均匀分割到所有server节点中。
在生产环境中容错是必不可少的,否则如果机器出现故障导致从头开始训练,会带来时间和资源的浪费。在训练过程中,server会保存模型的快照,可以理解为checkpoint。调度器会根据心跳来监控server的状态,如果检查到server出现异常,任务就会中断,等到server恢复正常后,调度器会通知server加载最近一次的快照继续训练。对于worker来说,训练过程中所有worker会把数据的读取状态上传到server中,如果worker失败之后恢复正常,worker会从server请求读取状态,在数据中断的地方继续训练,这样可以避免样本丢失,或者重复训练等问题。
tensornet
扩展tf
tf的分层结构(图-> 算子) 和 系统结构(master/worker 分别负责拆分和执行)都是分布式计算的常见设计(spark/flink也是类似),没啥问题,优化点一般在通信(同步异步、协议)、存储((sparse,存在独立ps 还是分布式)上。有两类
- 仅暴露给算子/在算子层以下优化。比如ps 、存储、协议等都在算子层以下
- 自定义算子。自定义算子了,还得确保能用上,一般会涉及到 自定义Model(包括Layer)、Optimizer 等,在自定义的 高层python api 上用到这些算子。除此之外,一些 c的一些逻辑 可能会直接暴露给python 层被使用,比如初始化底层的一些组件做一些准备工作(此时就是单纯的python 调用c,就不是自定义算子了)。
- python api 层扩展支持 EmbeddingVariable,主需要配套的c 支持
扩展的目的
- 支持大模型,主要是embedding 参数,基于tensorflow做扩展支持大模型的做法
- 训练加速,比如提高通信效率等
- 推荐场景在电商,视频,资讯等众多头部互联网公司的火爆导致推荐系统对AI硬件的消耗在互联网公司超过了传统NLP,CV,语音等应用的总和。
- 无量一开始采用的是基于参数服务器的架构。对tf 的改造有两个方向
- 把TensorFlow作为一个本地执行的lib,在外围开发,TensorFlow被复用来提供Python API以及完成基础算子的执行。而参数服务器,分布式通信等方面则是自己开发,没有复用TensorFlow。
- 基于TensorFlow底层进行改造,研发难度会比较大,而且很可能与社区版TensorFlow走向不同的方向,进而导致TensorFlow版本难以升级。
阿里巴巴开源大规模稀疏模型训练/预测引擎DeepRec在TensorFlow引擎上支持大规模稀疏特征,业界有多种实现方式
- 最常见的方式是借鉴了ParameterServer的架构实现,在TensorFlow之外独立实现了一套ParameterServer和相关的优化器,同时在TensorFlow内部通过bridge的方式桥接了两个模块。
- TensorFlow是一个基于Graph的静态图训练引擎,在其架构上有相应的分层,比如最上层的API层、中间的图优化层和最下层的算子层。
- 基于存储/计算解耦的设计原则在Graph层面引入EmbeddingVariable功能;
- 基于Graph的特点实现了通信的算子融合。
- TensorFlow 模型准实时更新上线的设计与实现 针对已有算子 重新实现(比如tensor保存在第三方kv),然后将graphdef 中已有算子替换为自己实现的对应算子。
有的时候,一些框架也不是在扩展tf,而是把 tf 当时一个库在用(用它的前向和反向)。扩展方式五花八门的,不像 k8s 有明确的csi/cri/cni 接口要遵守
留下评论