Goroutine 调度模型
前言
传统的C/C++ 等的并发实际上是基于操作系统的调度,即程序负责创建线程,操作系统负责调度。但它们存在编程模型难以理解、创建线程代价高等缺 点。
调度的本质Go 调度的本质是一个生产-消费流程,生产端是正在运行的 goroutine 执行 go func(){}() 语句生产出 goroutine 并塞到三级队列中去(包含P的runnext),消费端则是 Go 进程中的 m 在不断地执行调度循环。运行时(runtime)能够将goroutine多路复用到一个小的线程池中。这个观点非常新颖,这种熟悉加意外的效果其实就是你成长的时机。
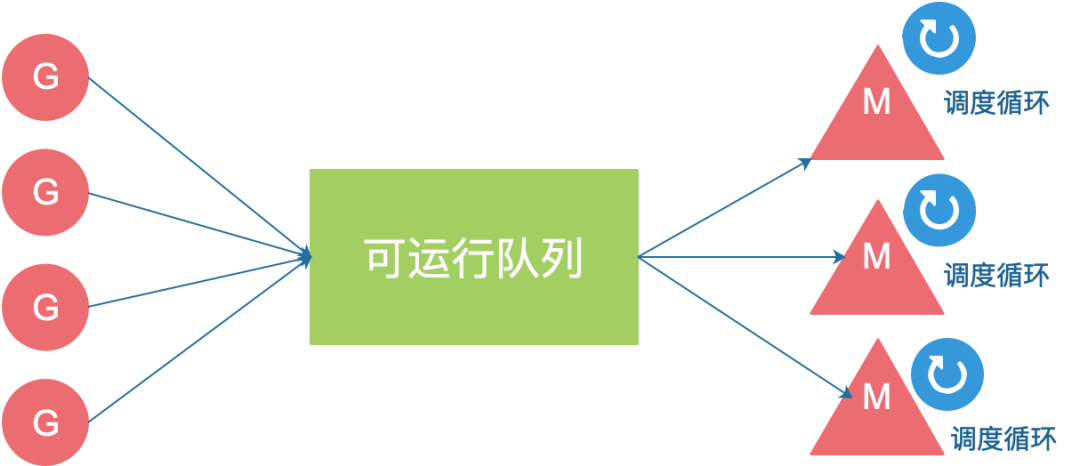
调度器的任务是给不同的工作线程 (worker thread) 分发可供运行的(ready-to-run)Goroutine。 go 在运行时提供了一套调度器,可以将 goroutine 分配到待执行队列中;内核线程从队列中获取并执行 goroutine,如果 goroutine 被阻塞,则会将其挂起,保留它的调用栈和上下文信息到内存中,并调度另一个 goroutine 到该线程执行;当 goroutine 恢复后,go 运行时会将其重新添加到待执行队列中;而这一切对于开发者来说是完全透明的。
万字长文深入浅出 Golang Runtime调度在计算机中是分配工作所需资源的方法,linux的调度为CPU找到可运行的线程,而Go的调度是为M(线程)找到P(内存、执行票据)和可运行的G。
为什么弄协程?
赵海平与张宏波谈编程语言为什么 Google 要去做 Golang 呢?是因为我们在这个过去的五到十年里面,就发现了实际上绝大多数的公司在写什么呢?在写分布式计算。特别常见的情况是我调你、你调它,它调它。团队大了之后拆分 engineering task 拆分完了之后,我就要 RPC 调用对吧?很多的 application 就变成了所谓的 IO intensive 的这种形式,20 年前的话,很多的软件都是在做大量的计算对吧,没有太多的 RPC 因为都在一个机器上进行。 IO多了,问题就来了,你的线程模型是什么?一个io一个线程不行,最后就发现了一定要用比如说 epoll 这种模型,要搞 user thread ,让其他的人都能够很快的去跳到这个模型上,所以他才把 goroutine (协程)这个概念变成了 first classcitizen ,所以其实人家的本意是在这里。
谈谈协程的历史与现状IO密集型一直是提高CPU利用率的难点,在抢占式调度中也有对应的解决方案:异步+回调,但原来整体的逻辑被拆分为好几个部分,让整个程序的可读性非常差。随着网络技术的发展和高并发要求,对IO型任务处理的低效逐渐受到重视,有没有一种技术把同步阻塞的简单易懂的优点和epoll多路复用的高性能结合起来呢?业界探索出来的方案就是语言运行时实现的协程。go中的协程被称为goroutine,协程对操作系统而言是透明的,也就是操作系统无法直接调度协程,因此必须有个中间层来接管goroutine。goroutine仍然是基于线程来实现的,因为线程才是CPU调度的基本单位,在go语言内部维护了一组数据结构和N个线程,协程的代码被放进队列中来由线程来实现调度执行,这就是著名的GMP模型。
The Go scheduler为什么Go 运行时需要一个用户态的调度器?
- 线程调度成本高,比如context switch比如陷入内核执行,如创建一个 Goroutine 的栈内存消耗为 2 KB,而 thread 占用 1M 以上空间
- 操作系统在Go模型下不能做出好的调度决策。os 只能根据时间片做一些简单的调度。
- 协程的切换不需要陷入内核,协程的威力在于IO的处理,恰好这部分是线程的软肋
调度模型的演化
Go语言goroutine调度器概述(11) go调度就是创建一个操作系统线程执行schedule函数。N个线程会执行 N 个 schedule函数。
// 程序启动时的初始化代码
......
for i := 0; i < N; i++{ // 创建N个操作系统线程执行schedule函数
create_os_thread(schedule) // 创建一个操作系统线程执行schedule函数
}
//schedule函数实现调度逻辑
func schedule() {
for { // 调度循环
// 根据某种算法从M个goroutine中找出一个需要运行的goroutine
g = find_a_runnable_goroutine_from_M_goroutines()
run_g(g) // CPU运行该goroutine,直到需要调度其它goroutine才返回
save_status_of_g(g) // 保存goroutine的状态,主要是寄存器的值
}
}
GM模型
go1.1 之前都是该模型, 单线程调度器(0.x) 和多线程调度器(1.0),单线程调度器(0.x) 核心逻辑如下
static void scheduler(void) {
G* gp;
lock(&sched);
if(gosave(&m->sched)){ // 保存栈寄存器和程序计数器
lock(&sched);
gp = m->curg;
switch(gp->status){
case Grunnable:
case Grunning:
gp->status = Grunnable;
gput(gp);
break;
...
}
notewakeup(&gp->stopped);
}
gp = nextgandunlock(); // 获取下一个需要运行的 Goroutine 并解锁调度器
noteclear(&gp->stopped);
gp->status = Grunning;
m->curg = gp; // 修改全局线程 m 上要执行的 Goroutine;
g = gp;
gogo(&gp->sched); // 运行最新的 Goroutine
}
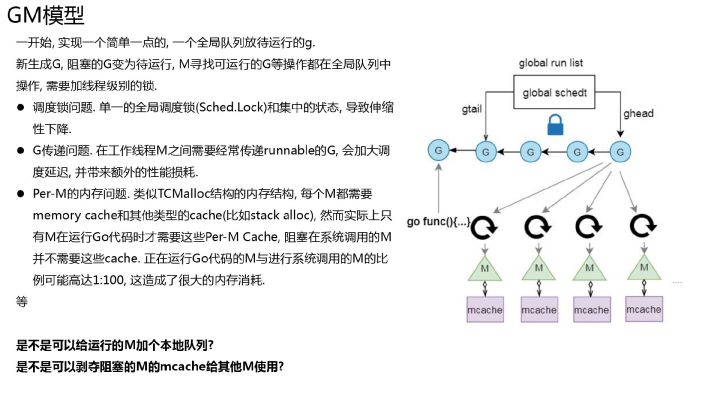
在这个阶段,goroutine 调度跟 java 的ThreadPool 是一样一样的,除了io操作会阻塞线程外,java Executor也可以视为一个用户态线程调度框架。runnable 表示运行逻辑 提交到queue,ThreadPool 维持多个线程 从queue 中取出runnable 并执行,只不过ThreadPool是执行runnable 直到完成runable。
调度器本身(schedule 方法),在正常流程下,是不会返回的,也就是不会结束主流程。schedule 会不断地运行调度流程,GoroutineA 完成了或时间到了,就开始寻找 GoroutineB,寻找到 B 了,就把已经完成的 A 的调度权交给 B,让 GoroutineB 开始被调度,一直继续下去。当然了,也有被正在阻塞(Blocked)的 G。假设 G 正在做一些系统、网络调用,那么就会导致 G 停滞。这时候 M(系统线程)就会被会重新放内核队列中,等待新的一轮唤醒。
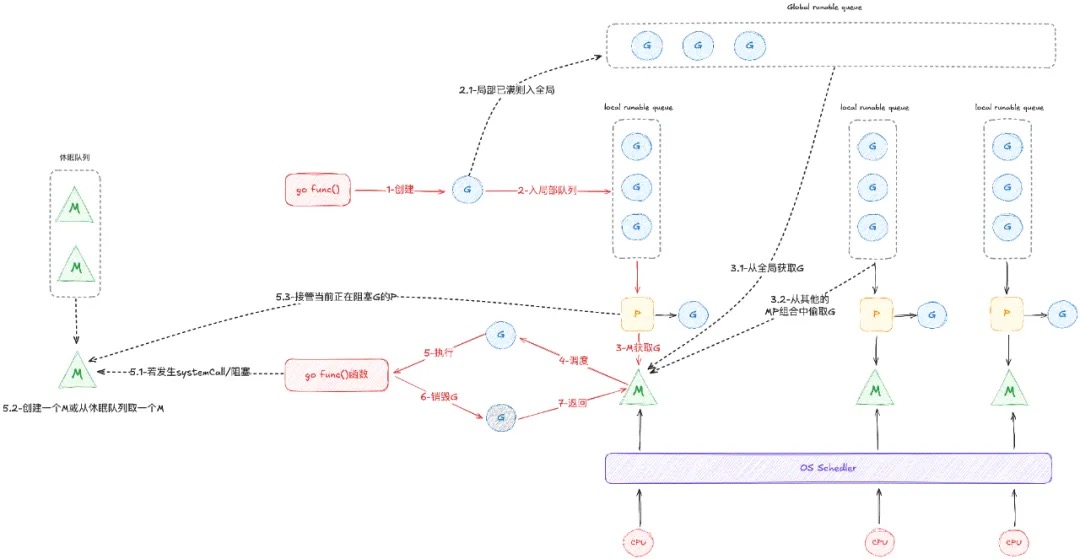
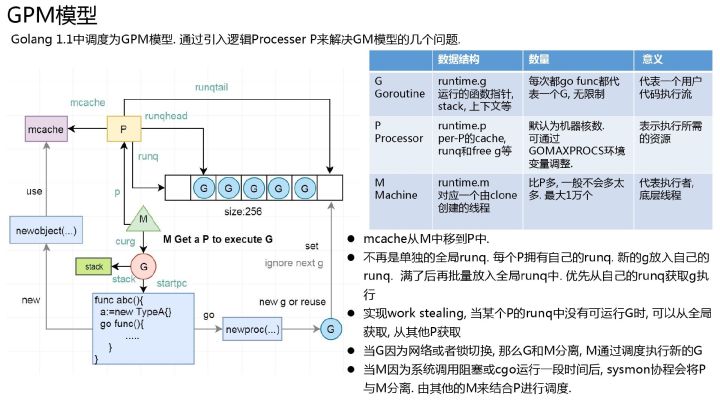
GPM模型
GMP模型和linux内核中cpu、runq有着非常高的相似度。
static void schedule(void) {
G *gp;
top:
if(runtime·gcwaiting) { // 如果当前运行时在等待垃圾回收,调用 runtime.gcstopm 函数;
gcstopm();
goto top;
}
gp = runqget(m->p); // 从本地运行队列中获取待执行的 Goroutine;
if(gp == nil)
gp = findrunnable(); // 从全局的运行队列中获取待执行的 Goroutine;
...
execute(gp); // 在当前线程 M 上运行 Goroutine
}
为什么引入Local Run Queue?它存在的意义在于实现工作窃取(work stealing)算法
- 在没有 P 的情况下,所有的 G 只能放在一个全局的队列中。对全局队列的操作均需要竞争同一把锁,mutex 需要保护所有与 goroutine 相关的操作(创建、完成、重排等), 导致伸缩性不好.
- GM 模型下一个协程派生的协程也会放入全局的队列, 大概率是被其他 m运行了, “父子协程” 被不同的m 运行,内存亲和性不好。
The Go scheduler就像linux 那样为每个cpu维护了一个 runqueue 结构
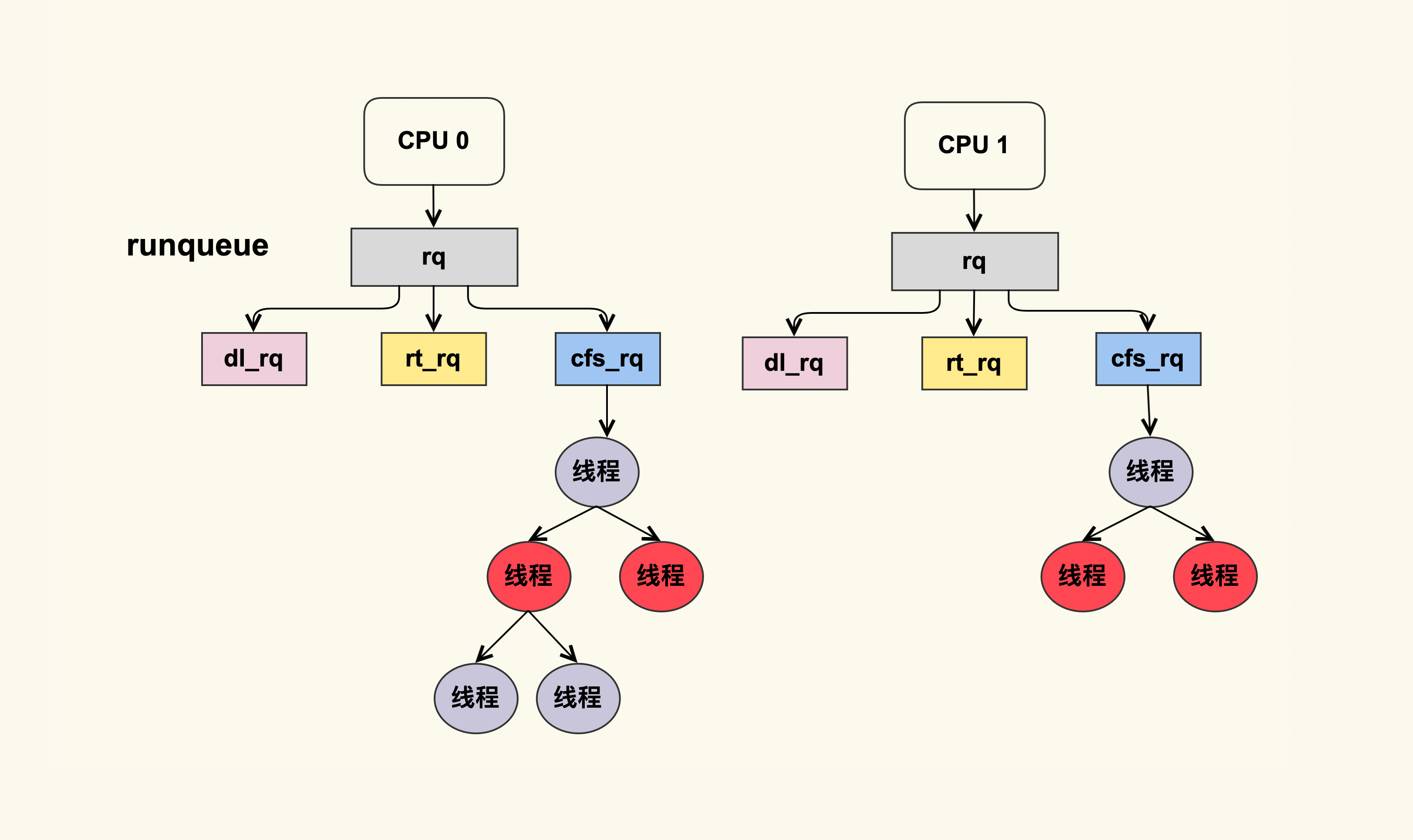
从Golang调度器的作者视角探究其设计之道如果是想实现本地队列、Work Stealing 算法,那为什么不直接在 M 上加runq呢,M 也照样可以实现类似的功能。为什么引入Processor 的概念?计算(M)存储(P)分离。把Local Run Queue及相关存储资源都挪到P 上去。
- 一般来讲,M 的数量都会多于 P。像在 Go 中,M 的数量最大限制是 10000,P 的默认数量的 CPU 核数。如果G 包含同步调用,会导致执行G 的M阻塞,进而导致 与M 绑定的所有runq 上的 G 无法执行。将M 和 runq 拆分,M 可以阻塞,M 阻塞后,runq 交由新的M 执行,M 数量会不断增加,如果本地队列挂载在 M 上,那就意味着本地队列也会随之增加,这显然是不合理的。对runq 及相关信息进行抽象 得到P,我们通过P把任务队列挂载到其它线程中。M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。
- GM 模型 一些内存资源(比如malloc cache等)是绑定在线程上面的,会导致线程数量和资源占用规模紧耦合。当线程数量多的时候,资源消耗也会比较大。
goroutine调度模型的四个抽象及其数据结构
Go 语言设计与实现-调度器goroutine调度模型4个重要结构,分别是M、G、P、Sched,前三个定义在runtime.h中,Sched定义在proc.c中。
P 的数量决定了系统内最大可并行的 G 的数量(前提:物理 CPU 核数 >= P 的数量)。P 的数量由用户设置的 GoMAXPROCS 决定,但是不论 GoMAXPROCS 设置为多大,P 的数量最大为 256。M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。
理解 M、P、G 三者的关系,可以通过经典的地鼠推车搬砖的模型来说明其三者关系:地鼠(Gopher)的工作任务是:工地上有若干砖头,地鼠借助小车把砖头运送到火种上去烧制。M 就可以看作图中的地鼠,P 就是小车,G 就是小车里装的砖。
Go的GMP模型真的“简单”GMP只是结构体,GMP和你写的业务代码一样,都是由系统线程运行。GMP是类似面相对象的封装,每个职责对应一个函数。
- 关于G展开两个关键问题:
- G和函数绑定过程。当通过go关键字运行一个函数时,从g的闲置队列获取一个g,并通过g.startpc属性绑定上待执行的函数fn。
- G切换上下文过程。goroutine的上下文信息,位于g的结构体 g.sched属性。g恢复上下文过程:触发调度时,找到可执行的g,把g的上下文g.sched通过汇编代码中的函数gogo恢复到对应的寄存器中。g保存上下文过程:当前g保存上下文(save/mcall),当前g切换到g0,g0执行schedule调度,找到新的可执行的g,新的g恢复上下文(gogo)。
- M职责解析
- 绑定真正执行代码的系统线程
- 执行G的调度
- 执行被调度的G绑定的函数
- 维护P链表(可以从下一个P的队列找G)
- P职责解析
- 维护可执行G的队列(M从该队列找可执行的G);
- 堆内存缓存层(mcache)
- 维护g的闲置队列
G
Go语言goroutine调度器概述(11)系统线程对goroutine的调度与内核对系统线程的调度原理是一样的,实质都是通过保存和修改CPU寄存器的值来达到切换线程/goroutine的目的。为了实现对goroutine的调度,需要引入一个数据结构来保存CPU寄存器的值(具体的说就是栈指针、pc指针)以及goroutine的其它一些状态信息。调度器代码可以通过g对象来对goroutine进行调度,当goroutine被调离CPU时,调度器代码负责把CPU寄存器的值保存在g对象的成员变量之中,当goroutine被调度起来运行时,调度器代码又负责把g对象的成员变量所保存的寄存器的值恢复到CPU的寄存器。PS:函数不是并发执行体,所以函数切换只需要保留栈指针就可以了。
G是goroutine实现的核心结构,G维护了goroutine需要的栈、程序计数器、任务函数以及它所在的M等信息,可重用。一个协程代表了一个执行流,执行流有需要执行的函数(startpc),有函数的入参,有当前执行流的状态和进度(对应 CPU 的 PC 寄存器和 SP 寄存器),当然也需要有保存状态的地方(gobuf strcut),用于执行流恢复。 每个协程都拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。栈切换的核心就是栈指针 rsp 寄存器的切换,只要我们想办法把 rsp 切换了就相当于换了执行单元的上下文环境。
type g struct {
m *m // 当前 Goroutine 占用的线程,可能为空;
sched gobuf // 保存g的现场,goroutine切换时通过它来恢复
atomicstatus uint32 // Goroutine 的状态
goid int64 // Goroutine 的 ID,该字段对开发者不可见
// 与栈相关
stack stack // 描述了当前 Goroutine 的栈内存范围 [stack.lo, stack.hi)
stackguard0 uintptr // 用于调度器抢占式调度
// 与抢占相关
preempt bool // 抢占信号
preemptStop bool // 抢占时将状态修改成 `_Gpreempted`
preemptShrink bool // 在同步安全点收缩栈
// defer 和 panic 相关
_panic *_panic // 最内侧的 panic 结构体
_defer *_defer // 最内侧的延迟函数结构体
startpc uintptr // goroutine函数的指令地址
}
type stack struct{
lo uintptr // 栈低地址
hi uintptr // 栈高地址
}
type gobuf struct { // 让出cpu 时,将寄存器信息保留在这里。即将获得cpu时,将这里的信息加载到寄存器
sp uintptr // 栈指针(Stack Pointer)
pc uintptr // 程序计数器(Program Counter)
g guintptr // 持有 runtime.gobuf 的 Goroutine
ret sys.Uintreg // 系统调用的返回值
...
}
// 创建协程的函数
func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g {
...
// 从缓存中获取或创建g对象
newg := gfget(_p_)
if newg == nil {
newg = malg(_StackMin) // _StackMin=2KB,创建g对象并为其成员赋值
...
}
...
newg.startpc = fn.fn
...
return newg
}
结构体 g 的字段 atomicstatus 就存储了当前 Goroutine 的状态,可选值为
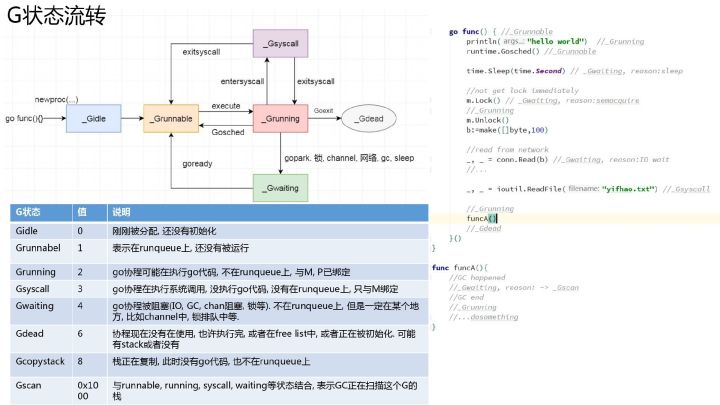
虽然 Goroutine 在运行时中定义的状态非常多而且复杂,但是我们可以将这些不同的状态聚合成最终的三种:等待中(比如正在执行系统调用或同步操作)、可运行、运行中(占用M),在运行期间我们会在这三种不同的状态来回切换。
其中 G 细分为以下几类:
- 主协程:用来执行用户main函数的协程;
- 主协程创建的协程:也是P调度的主要成员;
- 每个 M 都有一个 G0 协程,是 runtime 的一部分,跟 M 绑定,主要用来执行调度逻辑的代码,不能被抢占也不会被调度(普通 G 也可以执行 runtime_procPin 禁止抢占),G0 的栈是系统分配的,比普通的 G 栈(2KB)要大,不能扩容也不能缩容;,它会深度参与运行时的调度过程,包括 Goroutine 的创建、大内存分配和 CGO 函数的执行。
- sysmon:sysmon 是 runtime 的一部分,直接运行在 M 不需要 P,主要做一些检查工作:
- 执行 netpoll 操作,唤醒 io 就绪的 g
- 执行 retake 操作,对运行时间过长的 g 执行抢占操作
- 执行 gcTrigger 操作,探测是否需要发起新的 gc 轮次
- 检查死锁
- 检查计时器获取下一个要被触发的计时任务
M
M 是 Go 代码运行的真实载体,包括 Goroutine 调度器自身的逻辑也是在 M 中运行的。代码毕竟是没办法直接调用系统调用的,一般c 程序创建线程也使用glibc pthread_create 函数,通过汇编进入clone系统调用。在go中,c语言的运行时库glibc 没办法再用了。所以go像glibc一样,在用户态定义了自己的线程对象和线程创建的函数。
调度器最多可以创建 10000 个线程,但是其中大多数的线程都不会执行用户代码(可能陷入系统调用),最多只会有 GOMAXPROCS 个活跃线程能够正常运行。在默认情况下,运行时会将 GOMAXPROCS 设置成当前机器的核数。
M代表内核级线程,一个M就是一个线程,goroutine就是跑在M之上 ;M 结构体对象除了记录着工作线程的诸如栈的起止位置、当前正在执行的 Goroutine 以及是否空闲等等状态信息之外,还通过指针维持着与 P 结构体的实例对象之间的绑定关系。在绑定有效的 P 后,进入 schedule 循环,而 schedule 循环的机制大致是从 Global 队列、P 的 Local 队列以及 wait 队列中获取 G,切换到 G 的执行栈上并执行 G 的函数,调用 goexit 做清理工作并回到 M,如此反复,M 并不保留 G 状态,这是 G 可以跨 M 调度的基础。PS:语言层级要有对线程的描述,只不过java thread的类似信息是被jvm隐藏了。PS:m 的运行目标始终在 g0 和 g 之间进行切换——寻找任务(执行g0);执行任务(执行g)
// file: src/runtime/runtime2.go
type m struct {
g0 *g // 每个m都有一个对应的g0线程,用来执行调度代码,当需要执行用户代码的时候,g0会与用户goroutine发生协程栈切换
curg *g // 在当前线程上运行的用户 Goroutine
p puintptr // 隶属于哪个P
nextp puintptr // 当被唤醒时,首先拥有这个P
oldp puintptr // 执行系统调用之前的使用线程的处理器 oldp
...
// 没有 goroutine 需要运行时,工作线程睡眠在这个 park 上
park note
// tls作为线程的本地存储
tls [tlsSlots]uintptr
// 用于存储创建当前线程的堆栈信息
createstack [32]uintptr
mstartfn func() // 启动 m 的函数
}
在 Linux 系统中,fs 段可以用于存储线程的 TLS 数据,通常通过 fs 段寄存器来访问。m 结构体的 tls 字段通常会被设置为当前线程的 fs 段,Go 可以高效地管理和访问每个 goroutine 的特定数据。每个工作线程在刚刚被创建出来进入调度循环之前就利用线程本地存储机制为该工作线程实现了一个指向m结构体实例对象的私有全局变量,这样在之后的代码中就使用该全局变量来访问自己的m结构体对象以及与m相关联的p和g对象。
除了对线程的定义, 还需要实现创建线程的函数newm
// file: src/runtime/proc.go
func newm(fn func(), pp *p, id int64){
...
// 申请线程对象及默认的g0
mp := allocm(pp, fn, id)
// 创建线程
newm1(mp) // ==> newosproc
...
}
func newosproc(mp *m){
...
// 线程没有办法使用os 默认给进程分配的栈内存,linux中glibc库的做法是自己申请内存来当线程栈用。
// go 在linux 平台的做法是直接将g0 这个特殊的协程的栈(默认8KB)当做线程栈给clone 传递过去
stk := unsafe.Pointer(mp.g0.stack.hi)
// os线程是需要通过调用clone 系统调用来完成的,而且需要指定线程所使用的栈
clone(cloneFlags,stk, unsafe.Pointer(mp), unsafe.Pointer(mp.g0), unsafe.Pointer(abi.FuncPCABI0(mstart)))
// 汇编中mstart函数调用的是go源码中的mstart0
}
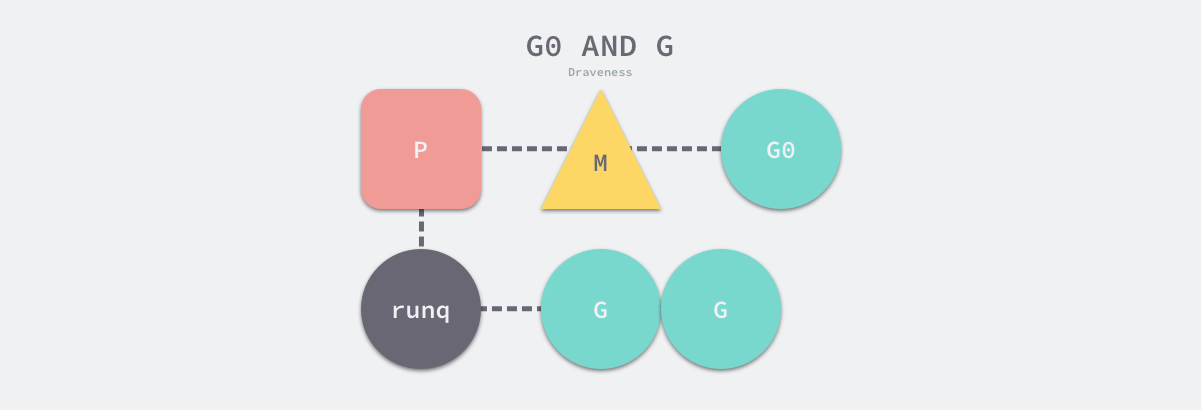
如果只有一个os thread,那么就只会有一个m结构体对象,问题就很简单,定义一个全局的m结构体变量就行了。可是我们有多个os thread和多个m需要一一对应,怎么办呢?线程本地存储其实就是线程私有的全局变量,每个工作线程在刚刚被创建出来进入调度循环之前就利用线程本地存储机制为该工作线程实现了一个指向m结构体实例对象的私有全局变量,这样在之后的代码中就使用该全局变量来访问自己的m结构体对象,进而访问与m相关联的p和g对象。
其中 M 细分为以下几类:
- 普通 M:用来与 P 绑定执行 G 中任务;
- m0:Go 程序是一个进程,进程都有一个主线程,m0 就是 Go 程序的主线程,通过一个与其绑定的 G0 来执行 runtime 启动加载代码;一个 Go 程序只有一个 m0;
- 运行 sysmon 的 M:主要用来运行 sysmon 协程。
P
P全称是Processor,处理器,表示调度的上下文,它可以被看做一个运行于线程 M 上的本地调度器,所以它维护了一个goroutine队列(环形链表),里面存储了所有需要它来执行的goroutine。M想要运行G,就得先获取P,然后从 P 的本地队列获取 G。通过处理器 P 的调度,每一个内核线程都能够执行多个 Goroutine,它能在 Goroutine 进行一些 I/O 操作时及时切换,提高线程的利用率。PS:linux内核为每个cpu 准备了一个rq
- 对 G 来说,P 相当于 CPU 核,G 只有绑定到 P (在 P 的 local runq 中)才能被调度。
- 对 M 来说,P 提供了相关的执行环境(Context),如内存分配状态(mcache),任务队列(G)等。
P 整个结构除去 本地 G 队列,后来发现任何想避免多线程锁开销的东西都可以往这里丢,一些性能追踪、内存分配(mcache)、统计、调试、GC 辅助的字段了。
struct P {
Lock;
uint32 status; // p 的状态 one of pidle/prunning/...
P* link; // 指向下一个处理器的指针,用于链式管理多个处理器
uint32 tick;
M* m; // 执行runq 的M,如果处理器处于闲置状态,则为 nil
MCache* mcache; // 用于分配微小对象和小对象的一个块的缓存空间,里面有各种不同等级的span
G** runq; // 运行的 Goroutine 组成的环形的运行队列
int32 runqhead; // 本地可运行的G队列的头部和尾部,达到无锁访问
int32 runqtail;
int32 runqsize;
runnext guintptr
G* gfree; // 存储已完成的 goroutine(状态为 Gdead)的结构体,供后续重用
...
gcw gcWork // 此处理器的 GC 工作缓冲区缓存,管理内存工作
wbBuf wbBuf // 此处理器的 GC 写入屏障缓冲区
gcStopTime int64 // 最近一次进入 GC 停止状态的时间戳
};
func schedinit(){ // 会将所有的 P 都初始化好
...
}
func runqput(_p *p, gp *g, next bool){ // 将gp 添加到 P.runq中
// 尝试将gp 放到 runnext中,这个有优先执行权,然后将gp 或被gp从runnext 踢下来的G加入到当前P(运行队列)的尾部
}
runhead、runqtail、runq 以及 runnext 等字段表示P持有的运行队列,该运行队列是一个使用数组构成的环形链表,其中最多能够存储 256 个指向Goroutine 的指针,除了 runq 中能够存储待执行的 Goroutine 之外,runnext 指向的 Goroutine 会成为下一个被运行的 Goroutine。PS:go 因为协程执行的都非常快,也都是“自己人”,所以不需要过分考虑公平性,没必要像内核那样搞到红黑树那么复杂,直接用数组就可以了。
p 结构体中的状态 status 可选值
- _Pidle 处理器没有运行用户代码或者调度器,运行队列为空
- _Prunning 被线程 M 持有,并且正在执行用户代码或者调度器
- _Psyscall 没有执行用户代码,当前线程陷入系统调用
- _Pgcstop 被线程 M 持有,当前处理器由于垃圾回收被停止
- _Pdead 当前处理器已经不被使用
调度器最多可以创建10000个线程,但是最多只会有GOMAXPROCS(P的数量)个活跃线程能够正常运行。设置GOMAXPROCS的值只能限制P的最大数量,对M和G的数量没有任何约束。当M上运行的G进入系统调用导致M被阻塞时,运行时系统会把该M和与之关联的P分离开来,这时,如果该P的可运行G队列上还有未被运行的G,那么运行时系统就会找一个空闲的M,或者新建一个M与该P关联,满足这些G的运行需要。因此,M的数量很多时候都会比P多。
通过引入中间态 Processor来 优化传统线程模型,利用局部性原理和工作窃取机制实现高效的任务分配与负载均衡,结合动态关联策略减少阻塞影响:传统的线程模型可以理解为 GM 模型(这里的 G 引申为用户的并发任务),为了解决传统 GM 模型的切换开销大(内核态到用户态),并发开销大(线程为 MB 级别,并发数量受内存限制)的问题,Go 语言引入了 一层 Processor 来作为两者的中间态,Processor 的设计进一步细化了并发时分复用的调度粒度,从 MB 到 KB,实现轻量,将内核态用户态的互相切换完整放在用户态执行,实现用户级快速切换。当一个线程因为系统调用或其他原因阻塞时,GMP 不会让绑定的处理器(P)空闲(无M可用),而是将当前的 P 传递给另一个线程,以便新线程可以继续执行 P 上的 Goroutine。PS:最早有global queue,不过这个表述很有意思,不是一个简单的thread:core多对多就完事了。
Sched
调度器,所有 Goroutine 被调度的核心,存放了调度器持有的全局资源,以及访问这些资源需要的锁。
Go语言goroutine调度器概述(11)要实现对goroutine的调度,仅仅有g结构体对象是不够的,至少还需要一个存放所有(可运行)goroutine的容器,便于工作线程寻找需要被调度起来运行的goroutine,于是Go调度器又引入了schedt结构体,一方面用来保存调度器自身的状态信息,另一方面它还拥有一个用来保存goroutine的运行队列。因为每个Go程序只有一个调度器,所以在每个Go程序中schedt结构体只有一个实例对象,该实例对象在源代码中被定义成了一个共享的全局变量,这样每个工作线程都可以访问它以及它所拥有的goroutine运行队列,我们称这个运行队列为全局运行队列。
// src/runtime/runtime2.go
type schedt struct {
midle muintptr // 空闲的 M 列表
pidle puintptr // 空闲 p 链表
runq gQueue // 全局 runnable G 队列
runqsize int32
// defer 结构的池
deferlock mutex
deferpool [5]*_defer
gcwaiting uint32 // gc is waiting to run
}
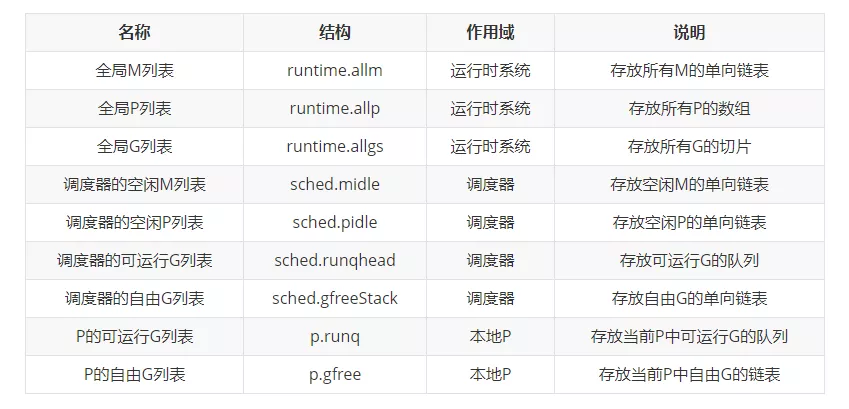
重要的全局变量,尤其是allgs/allm/allp。在程序初始化时,这些全变量都会被初始化为0值,指针会被初始化为nil指针,切片初始化为nil切片,int被初始化为数字0,结构体的所有成员变量按其本类型初始化为其类型的0值。所以程序刚启动时allgs,allm和allp都不包含任何g,m和p。
allgs []*g // 保存所有的g
allm *m // 所有的m构成的一个链表,包括下面的m0
allp []*p // 保存所有的p,len(allp) == gomaxprocs
ncpu int32 // 系统中cpu核的数量,程序启动时由runtime代码初始化
gomaxprocs int32 // p的最大值,默认等于ncpu,但可以通过GOMAXPROCS修改
sched schedt // 调度器结构体对象,记录了调度器的工作状态
m0 m // 代表进程的主线程
g0 g // m0的g0,也就是m0.g0 = &g0
其它容器
与函数的关系
20 世纪 60 年代高德纳(Donald Ervin Knuth)总结两种子过程(Subroutine):一种是我们常见的函数调用的方式,而另一种就是协程。和函数的区别是,函数调用时,调用者跟被调用者之间像是一种上下级的关系;而在协程中,调用者跟被调用者更像是互相协作的关系,比如一个是生产者,一个是消费者。
和函数的区别是,函数调用时,调用者跟被调用者之间像是一种上下级的关系;当我们使用函数的时候,简单地保持一个调用栈就行了。当 fun1 调用 fun2 的时候,就往栈里增加一个新的栈帧,用于保存 fun2 的本地变量、参数等信息;这个函数执行完毕的时候,fun2 的栈帧会被弹出(恢复栈顶指针 sp),并跳转到返回地址(调用 fun2 的下一条指令),继续执行调用者 fun1 的代码。
而在协程中,调用者跟被调用者更像是互相协作的关系,比如一个是生产者,一个是消费者。如果调用的是协程 coroutine1,该怎么处理协程的栈帧呢?因为协程并没有执行完,显然还不能把它简单地丢掉。这种情况下,程序可以从堆里申请一块内存,保存协程的活动记录,包括本地变量的值、程序计数器的值(当前执行位置)等等。这样,当下次再激活这个协程的时候,可以在栈帧和寄存器中恢复这些信息。
- Stackful Coroutine,每个协程,都有一个自己专享的协程栈(linux进程栈对应task_struct.mm_struct)。可以在协程栈的任意一级,暂停协程的运行。可以从一个线程脱离,附加到另一个线程上。PS: Go中的G 所表达的主要内容
- Stackless Coroutine,在主栈上运行协程的机制,会被绑定在创建它的线程上
G0
关于Go并发编程,你不得不知的“左膀右臂”——并发与通道!运行时系统中的每个M都会拥有一个特殊的G,一般称为M的g0(主要任务就是不断寻找可执行的 g)。M的g0不是由Go程序中的代码间接生成的,而是由Go运行时系统在初始化M时创建并分配给该M的(g0是随着线程 m 对象一起被创建出来的)。M的g0一般用于执行调度(提供栈来跑schedule函数)、垃圾回收、栈管理等方面的任务。M还会拥有一个专用于处理信号的G,称为gsignal。除了g0和gsignal之外,其他由M运行的G都可以视为用户级别的G,简称用户G,g0和gsignal可称为系统G。Go运行时系统会进行切换,以使每个M都可以交替运行用户G和它的g0。PS:g0 就是M 的代码逻辑 g1 -> g0 -> g2 -> g0 -> g3
聊聊 g0linux 执行调度任务:cpu 发生时间片中断,正在执行的线程 被剥离cpu,cpu 执行调度 程度寻找下一个线程并执行。 调度程度 的运行依托 栈、寄存器等上下文环境。对于go 来说,每一个线程/M 一直在执行一个 调度循环schedule()->execute()->gogo()->g2()->goexit()->goexit1()->mcall()->goexit0()->schedule() ,每个被调度的协程 有自己的栈 等 空间,那么先后执行的 两个协程之间 运行 schedule 这些逻辑时,也需要一些栈空间,这些都归属于g0。
Go: g0, Goroutine for SchedulingGo has to schedule and manage goroutines on each of the running threads. This role is delegated to a special goroutine, called g0, that is the first goroutine created for each OS thread. 以下图为例,在g7 被挂起后,运行g0,选择g2 来执行。
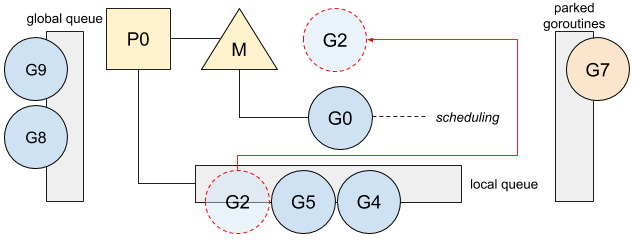
此外 g0 has a fix and larger stack. This allows Go to perform operations where a bigger stack is needed. 比如 Goroutine creation, Defer functions allocations, Garbage collector operations
除了每个M都拥有属于它自己的g0外,还存在一个runtime.g0。runtime.g0用于执行引导程序,它运行在Go程序拥有的第一个内核线程之中,这个线程也称为runtime.m0,runtime.m0的g0就是runtime.g0。
Go runtime还会用Background thread来运行一些相对特别的G(如 Network Poller、Timer)
补充
过去的语言(如C语言)只是提供标准的库,让你访问操作系统的线程管理功能,包括信号量、同步互斥什么的。Java语言增加了一些专门处理多线程的元素,比如synchronized关键字。go语言又更进一步,把操作系统的线程进行了封装,变成了轻量级的goroutine。
goroutine一些重要设计:
- 堆栈开始很小(只有 4K),但可按需自动增长;
- 坚决干掉了 “线程局部存储(TLS)” 特性的支持,让执行体更加精简。P内的 g 共用P的cache。
- 提供了同步、互斥和其他常规执行体间的通讯手段,包括大家非常喜欢的 channel;
- 提供了几乎所有重要的系统调用(尤其是 IO 请求)的包装。
Scheduling In Go : Part I - OS Scheduler Scheduling In Go : Part II - Go Scheduler Scheduling In Go : Part III - Concurrency
留下评论