程序猿视角看网络
简介
数据中心网络架构浅谈(三) 中提到:之所以写,是想提供一个非网工的,云计算从业人员的视角。本文也尝试从一个 程序猿的视角,来汇总网络方面的一些知识。
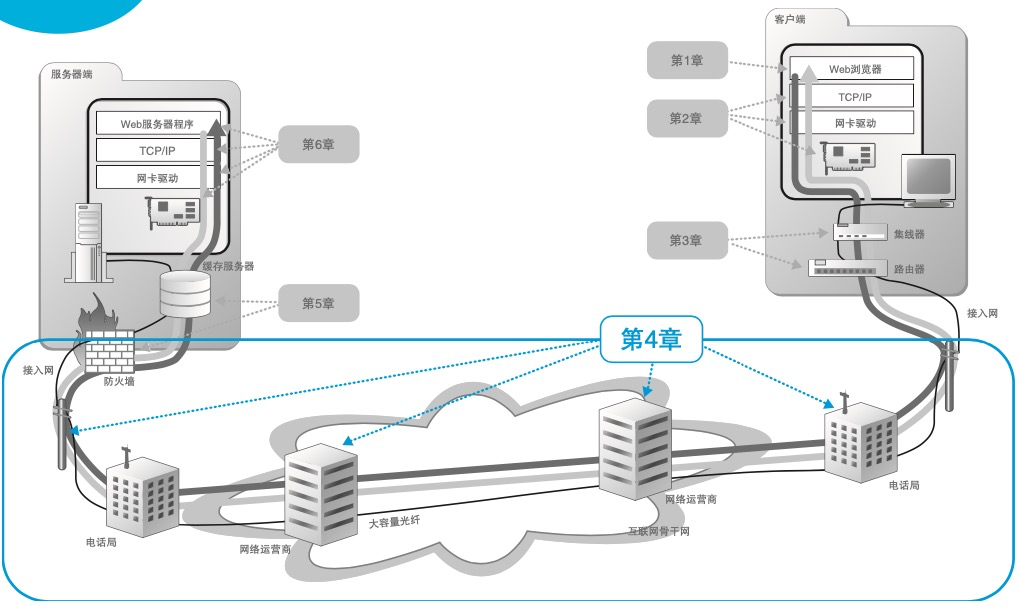
网络分块和分层
为什么要分层
2019.7.5补充:虽然全世界组成一张大的互联网,美国的网站你也能够访问的,但是这个网络不是一整个的。你们小区有一个网络,你们公司也有一个网络,联通、移动、电信运营商也各有各的网络,所以一个大网络是被分成个小的网络。network layer以下就是解决 “小网络”内的事儿。PS:就好像看地图是一片,但实际因为山川河流阻隔,都是一块一块的。去一个地方看似都能走,实际就几条路。
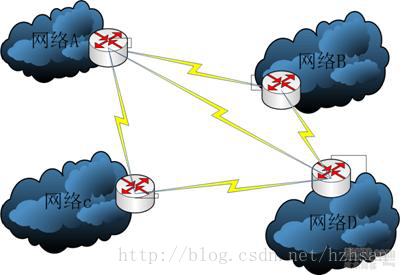
The Layers of the OSI Model Illustrated
为什么网络要分层?因为是个复杂点的程序都要分层。
- 应用程序包办一切。程序把应用层的数据,按某种编码转化为二进制数据,然后程序去操控网卡,把二进制数据发送到网络上。这期间,通信的连接方式、传输的可靠性、速度和效率的保证等等,都需要这个程序去实现。然后下次开发另外一个应用的时候,就把上面这些活,再干一遍。
- 应用程序、操作系统、网络设备等环节各自分工。应用程序只负责实现应用层的业务逻辑,操作系统负责连接的建立、处理网络拥塞和丢包乱序、优化网络读写速度等等,然后把数据交给网卡,后者和交换机等设备做好联动,负责二进制数据在物理线路上的传送和接收。
It conceptually divides computer network architecture into 7 layers in a logical progression. The lower layers deal with electrical signals, chunks of binary data, and routing of these data across networks. Higher levels cover network requests and responses, representation of data, and network protocols as seen from a user’s point of view.
网络是七层、五层还是四层?TLS 虽然在 TCP 之上,按 TCP/IP 模型就要被归入应用层。但事实上,在 HTTPS 的场景下,HTTP 协议就是运行在 TLS 协议之上的,那么是不是把 HTTP 和 TLS 分到不同的层次更合适呢?正好在七层模型里,第五层和第六层,可以分别代表 TLS 的会话保持功能和数据加解密这种表示层的功能。
网络分层的好处是在于每一层都专心做好自己的事情就行了。而坏处也不是没有,比如在 Nginx 的日志里面,可能就有 connection reset by peer 这种报错。应用层只知道操作系统告诉它,“喂,你的连接被 reset 了”(收到RST)。但是为什么会被 reset 呢?应用层无法知道,只有操作系统知道,但是操作系统只是把事情处理掉,往内部 reset 计数器里加 1,但也不记录这次 reset 的前后上下文。我们做网络排查的第一个要点:把应用层的信息,“翻译”成传输层和网络层的信息。
- “应用层信息”,可能是以下这些:
- 应用层日志,包括成功日志、报错日志,等等;
- 应用层性能数据,比如 RPS(每秒请求数),transaction time(处理时间)等;
- 应用层载荷,比如 HTTP 请求和响应的 header、body 等。
- “传输层 / 网络层信息”,可能是以下种种:
- 传输层:TCP 序列号(Sequence Number)、确认号(Acknowledgement Number)、MSS(Maximum Segment Size)、接收窗口(Receive Window)、拥塞窗口(Congestion Window)、时延(Latency)、重复确认(DupAck)、选择性确认(Selective Ack)、重传(Retransmission)、丢包(Packet loss)等。
- 网络层:IP 的 TTL、MTU、跳数(hops)、路由表等。 可见,这两大类(应用 vs 网络)信息的视角和度量标准完全不同,所以几乎没办法直接挂钩。而这,也就造成了问题排查方面的两大鸿沟。
- 应用现象跟网络现象之间的鸿沟:你可能看得懂应用层的日志,但是不知道网络上具体发生了什么。
- 工具提示跟协议理解之间的鸿沟:你看得懂 Wireshark、tcpdump 这类工具的输出信息的含义,但就是无法真正地把它们跟你对协议的理解对应起来。 也就是说,你需要具备把两大鸿沟填平的能力,有了这个能力,你也就有了能把两大类信息(应用信息和网络信息)联通起来的“翻译”的能力。这正是网络排查的核心能力(把应用层问题锚定到网络层数据包)。PS: 比如同属一个时间段,一个ip,tcp包里包含的业务内容等。比如要了解系统调用 与TCP 标志位的状态转换关系。报文如果能关联pid就好了。
网络各层
| 层次 | 数据组织 | 概念 | 每一层除数据包不同之外,知道哪一层在哪些行为里也很重要 |
|---|---|---|---|
| Physical Layer | bit | ||
| Data Link Layer | frame | mac | 1. checks for physical transmission errors 2. packages bits into data “frames” 3. manages physical addressing schemes such as MAC addresses |
| Network Layer | package | ip | 承担了分组(Packet)转发和路由选择两大功能 1. 根据目的ip地址determine if the data has reached its final destination. 2. If the data has reached the final destination, this Layer 3 formats the data into packets delivered up to the Transport layer. Otherwise, the Network layer updates the destination address and pushes the frame back down to the lower layers. 3. adds the concept of routing above the Data Link layer 4. To support routing, the Network layer maintains logical addresses such as IP addresses for devices on the network. 5. manages the mapping between these logical addresses and physical addresses(ARP) |
| Transport Layer | error recovery, flow control, re-transmission. etc |
二层到四层都是在 Linux 内核里面处理的,是一个软件实现的功能逻辑层
《网络是怎样连接的》:IP 和Ethernet的分工,其中Ethernet的部分也可以替换成其他的东西,例如无线局域网、ADSL、FTTH 等,它们都可以替代以太网的角色帮助 IP 协议来传输网络包 要使用各种通信技术。像互联网这样庞大复杂的网络,在架构上需要保证 灵活性,这就是设计这种分工方式的原因。
TCP 和 UDP 可以同时绑定相同的端口吗?可以的。在数据链路层中,通过 MAC 地址来寻找局域网中的主机。在网际层中,通过 IP 地址来寻找网络中互连的主机或路由器。在传输层中,需要通过端口进行寻址,来识别同一计算机中同时通信的不同应用程序。所以,传输层的「端口号」的作用,是为了区分同一个主机上不同应用程序的数据包。传输层有两个传输协议分别是 TCP 和 UDP,在内核中是两个完全独立的软件模块。当主机收到数据包后,可以在 IP 包头的「协议号」字段知道该数据包是 TCP/UDP,所以可以根据这个信息确定送给哪个模块(TCP/UDP)处理,送给 TCP/UDP 模块的报文根据「端口号」确定送给哪个应用程序处理。因此, TCP/UDP 各自的端口号也相互独立,如 TCP 有一个 80 号端口,UDP 也可以有一个 80 号端口,二者并不冲突。
报文、帧、分组、段、数据包,这些术语是同一个东西吗?
- 报文(packet),是一种相对宽泛和通用的说法,基本上每一层都可以用。比如,在应用层,你可以说“HTTP 报文”;在传输层,你可以说“TCP 报文”;同样的,在网络层,当然就是“IP 报文”了。事实上,网络层也是“报文”一词被使用最多的场景了。数据包也是类似的,可以在很多场景下通用。我们再稍微考究一下语法。packet 这个词的后缀是 et。而在英文中,以 et 结尾的很多词表示某一个小小的东西。比如功能完备的一小段代码,叫 code snippet,一小段内嵌在 HTML 中的 Java 前端代码,叫 applet。自然的,packet 就是一个小的 pack(包裹)。
- 帧(frame)是二层也就是数据链路层的概念,代表了二层报文,它包含帧头、载荷、帧尾。注意,帧是有尾部的,而其他像 IP、TCP、HTTP 等层级的报文,都没有尾部。
- 分组是 IP 层报文,也就是狭义的 packet。
- 段特指 TCP segment,也就是 TCP 报文。既然 segment 是“部分”的意思,那这个“整体”又是什么呢?它就是在应用层交付给传输层的消息(message)。当 message 被交付给传输层时,如果这个 message 的原始尺寸,超出了传输层数据单元的限制(比如超出了 TCP 的 MSS),它就会被划分为多个 segment。这个过程就是分段(segmentation),也是 TCP 层的一个很重要的职责。
网络各层都有哪些排查工具呢?
- 应用层的排查工具就太多了,比如HTTP 应用的排查工具。现在主流的浏览器是 Google 的 Chrome,它本身就内置了一个开发者工具。
- 传输层,可以测试连通性,也可以获取连接状况和统计信息
- 路径可达性测试,如果我们要测试 TCP 握手,我们有 telnet、nc 这两个常规工具。
- 查看当前连接状况,netstat 命令是一个经典命令了
- 查看当前连接的传输速率,有时候,你的网络跑得挺繁忙的,但你却不知道哪个连接占用了大量的带宽?你可以用 iftop。然后就能看到不同连接的传输速率,把祸害你带宽的连接给找到。
- 网络层,除了可以直接用 ping 这个非常简便的工具以外,traceroute、mtr、ip 等工具可以检测网络路径状况
- 查看网络路径状况,traceroute 和 mtr。
- 查看路由,比较老一点命令route,或者
netstat -r
- 数据链路层和物理层。这一层离应用层已经很远了,一般来说是专职的网络团队在负责。如果这一层有问题,就会直接体现在网络层表现上面,比如 IP 会有丢包和延迟等现象,然后会引发传输层异常(如丢包、乱序、重传等)。如果你想查看这两层的状况,可以用 ethtool 这个工具。它的原理,是网卡驱动会到内核中注册 ethtool 回调函数,然后我们用 ethtool 命令就可以查看这些信息了。
网路通信
本小节来自《Paas实现与运维管理》的笔记。
我们将网络世界的物理设备抽象为三种:计算节点,交换节点和路由节点
-
因为计算节点不能两两相连,所以我们需要一个交换节点,负责转发数据。在数据链路层范围内
- 计算节点在发送数据的时候,应用程序中不可能直接写目的主机的mac地址,所以我们需要一个虚拟地址,即ip地址。arp请求(广播)及arp缓存。
- 交换节点收到一个包,在转发这个包的时候,没有mac地址与端口的映射,会先广播,然后建立mac地址与串口的映射关系。
-
因为一个交换节点负责不了世界上的所有计算节点,(不然广播域也太大了),所以我们需要一个路由节点。
- 计算节点在发送数据时,通过ip+掩码来判断目的计算节点是否在一个子网内。当发现不在一个子网时,它会将数据包发送给子网内的路由节点(也就是网关)。
- 路由器根据路由表中的策略来接收和发送包。这就不能叫转发了,因为路由器会修改数据包。路由表中的rule可以静态设置,也可以动态学习。
修正自己以前的几个误区:
- 除了功能不同,交换节点和路由节点的另一个区别:交换节点并不修改package
- 实际上,计算节点通过交换节点向路由节点发送数据,交换节点转发包可以理解为透明。所以是:
计算节点 ==> 路由节点 ==> 计算节点实现跨网络传输 - 不仅计算节点有数据通信,路由节点也有数据通信
- 在一个网络数据包传输的过程中(跨网络+路由器),都是源/目标mac在变,源/目标ip都没变。
《趣谈网络协议》MAC 地址是一个局域网内才有效的地址。因而,MAC 地址只要过网关,就必定会改变,因为已经换了局域网。两者主要的区别在于 IP 地址是否改变。不改变 IP 地址的网关,我们称为转发网关;改变 IP 地址的网关,我们称为NAT 网关(IP段冲突场景)。在 IP 头里面,不会保存任何网关的 IP 地址。所谓的下一跳是,某个 IP 要将这个 IP 地址转换为 MAC 放入 MAC 头。NAT 网关经常见,大家每家都有家用路由器,家里的网段都是 192.168.1.x,所以你肯定访问不了你邻居家的这个私网的 IP 地址的。所以,当我们家里的包发出去的时候,都被家用路由器 NAT 成为了运营商的地址了。
网络发现
Computer networkNetwork是一组可以相互通信的Endpoints,网络提供connectivity and discoverability
尤其是对于discoverability,在网络的各个层次都有体现
- dns,有专门的dns服务器,在host组装数据包之前 根据dns 将域名转换为ip
- arp,在host 发出frame之前,根据arp 获取目的主机的mac地址
- 路由器之间的路由同步协议
- 边界路由器之间的路由同步协议,比如bgp
- 在oveylay 网络中,经常将 虚拟机/容器/网段在哪个主机上 等信息保存在zk/etc中。
解决了discoverability,数据包发向哪里都明确了,交换设备通过简单的复制,将数据包转发给目的设备,提供connectivity
网络路由
当网络设备收到一个数据包时,它根据数据包的目的IP地址查询路由表,如果有匹配的路由条目,就根据查询结果将数据包转发出去,如果没有任何匹配的路由条目,则将数据包丢弃,这个过程就是IP路由。除了路由器,三层交换机、防火墙、负载均衡设备甚至主机等设备都可以进行路由操作。每一个路由条目包含目的网段地址/子网掩码、路由协议、出接口、下一跳IP地址、路由优先级和度量值等信息。路由表直连路由、静态路由和动态路由三种方式获取,其中动态路由是通过动态路由协议从相邻网络设备动态学习到的路由条目。协议有OSPF,BGP ,RIP,RIPv2等。
天天讲路由,那 Linux 路由到底咋实现的网络包在发送的时候,需要从本机的多个网卡(eth0和lo)设备中选择一个合适的发送出去。网络包在接收的时候,也需要进行路由选择,如果是属于本设备的包就往上层送到网络层、传输层直到 socket 的接收缓存区中。如果不是本设备上的包,就选择合适的设备将其转发出去。
网络层发送的入口函数是 ip_queue_xmit, Linux 在 IP 层的接收入口 ip_rcv 执行后调用到 ip_rcv_finish。在这里展开路由选择。如果发现确实就是本设备的网络包,那么就通过 ip_local_deliver 送到更上层的 TCP 层 tcp_v4_rcv进行处理。如果路由后发现非本设备的网络包,那就进入到 ip_forward 进行转发,最后通过 ip_output 发送出去。
//file: net/ipv4/ip_output.c
int ip_queue_xmit(struct sk_buff *skb, struct flowi *fl){
// 路由选择过程
// 选择完后记录路由信息到 skb 上
rt = (struct rtable *)__sk_dst_check(sk, 0);
if (rt == NULL) {
// 没有缓存则查找路由项
rt = ip_route_output_ports(...);
sk_setup_caps(sk, &rt->dst);
}
skb_dst_set_noref(skb, &rt->dst);
...
//发送
ip_local_out(skb);
}
路由表(routing table)在内核源码中的另外一个叫法是转发信息库(Forwarding Information Base,FIB)。在源码中看到的 fib 开头的定义基本上就是和路由表相关的功能。所有的路由表都通过一个 hash - fib_table_hash 来组织和管理。它是放在网络命名空间 net 下的。这也就说明每个命名空间都有自己独立的路由表。
//file: include/net/ip_fib.h
struct fib_table {
struct hlist_node tb_hlist;
u32 tb_id;
int tb_default;
int tb_num_default;
unsigned long tb_data[0];
};
//file:include/net/net_namespace.h
struct net {
struct netns_ipv4 ipv4;
...
}
//file: include/net/netns/ipv4.h
struct netns_ipv4 {
// 所有路由表
struct hlist_head *fib_table_hash;
// netfilter
...
}
发送过程调用 ip_route_output_ports 来查找路由,接收过程调用 ip_route_input_slow 来查找。但其实这两个函数都又最终会调用到 fib_lookup 这个核心函数
//file: include/net/ip_fib.h
static inline int fib_lookup(struct net *net, const struct flowi4 *flp,
struct fib_result *res){
struct fib_table *table;
table = fib_get_table(net, RT_TABLE_LOCAL);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
table = fib_get_table(net, RT_TABLE_MAIN);
if (!fib_table_lookup(table, flp, res, FIB_LOOKUP_NOREF))
return 0;
return -ENETUNREACH;
}
这个函数就是依次到 local 和 main 表中进行匹配,匹配到后就返回,不会继续往下匹配。从上面可以看到 local 表的优先级要高于 main 表,如果 local 表中找到了规则,则路由过程就结束了。这也就是很多同学说为什么 ping 本机的时候在 eth0 上抓不到包的根本原因。所有命中 local 表的包都会被送往 loopback 设置,不会过 eth0。
网络通信中的IP 与MAC
路由表同时记录了目的计算机地址、下一跳地址和网络接口的关联信息。所谓下一跳地址就是:如果 IP 包从主机 A 发到主机 B,需要经过路由设备 X 的中转。那么 X 的 IP 地址就应该配置为主机 A 的下一跳地址。一旦A配置了下一跳地址,那么接下来,当 IP 包从网络层进入链路层封装成帧的时候,eth0 设备就会使用下一跳地址X_IP对应的 MAC 地址,作为该数据帧的目的 MAC 地址。网关/下一跳的 IP 地址不会出现在任何网络包头中(ip package的dest ip只用来记录最终地址)
| frame header | frame body | |||
| A mac | X mac | A ip | B ip | body |
-
如果要访问的目标IP跟自己是一个网段的(根据CIDR就可以判断出目标端IP和自己是否在一个网段内了),就不用经过网关了,先通过ARP协议获取目标端的MAC地址,源IP直接发送数据给目标端IP即可。此时网络层没有体现出作用。
frame header frame body A mac B mac A ip B ip body 如何是一个局域网的, you can just send a packet with any random IP address on it, and as long as the MAC address is right it’ll get there.
-
如果访问的不是跟自己一个网段的,就会先发给网关(哪个网关由 The route table 确定),然后再由网关发送出去,网关就是路由器的一个网口,网关一般跟自己是在一个网段内的,通过ARP获得网关的mac地址,就可以发送出去了。
frame header frame body A mac gateway mac A ip B ip body -
主机/直接路由 强行指定下一跳地址
$ ip route ... 10.244.1.0/24 via 10.168.0.3 dev eth0目的 IP 地址属于 10.244.1.0/24 网段的 IP 包,应该经过本机的 eth0 设备发出去(即:dev eth0);并且,它下一跳地址(next-hop)是 10.168.0.3(即:via 10.168.0.3)。
在基于二层交换机的场景下,src mac 是可以不设置的,但是 dst mac 是一定要设置的,对于三层的网络通信是一定要 src mac 和 dst mac 都要设置正确,才可以完成数据包的正确处理。IP 包的 dest IP 一直不变,而每一跳链路上的 dest MAC 都可能变化。
传统网络架构
在传统的网络认知里,网络就是由带有一个或多个 NIC(Network Interface Controller,网络接口控制器,俗称网卡) 的一组 NC(Network Computer) 使用硬件介质和 switch(交换机)、Router(路由器)所组成的一个通信集合。
网络间通信——网关和路由器
网关,默认网关,自动网关,路由,网关与路由器的关系 路由器的每一个端口,都有独立的 MAC 地址。
- A 给 C 发数据包,怎么知道是否要通过路由器转发呢?子网。将源 IP 与目的 IP 分别同这个子网掩码进行与运算,相等则是在一个子网,不相等就是在不同子网。
- A 如何知道,哪个设备是路由器?在 A 上要设置默认网关。如果A发现数据包的目的主机不在本地网络中(同一个网段),就把数据包转发给它自己的网关。因为当前路由器集成了网关的功能,所以只使用路由器一种设备就可以了。
- 路由器如何知道C在哪里?路由表。路由器使用静态路由或动态路由来决定网络间的最短路径。
从A视角来看
- 首先我要知道我的 IP 以及对方的 IP
- 通过子网掩码判断我们是否在同一个子网
- 在同一个子网就通过 arp 获取对方 mac 地址直接扔出去
- 不在同一个子网就通过 arp 获取默认网关的 mac 地址直接扔出去 从交换机视角
- 我收到的数据包必须有目标 MAC 地址
- 通过 MAC 地址表查映射关系
- 查到了就按照映射关系从我的指定端口发出去
- 查不到就所有端口都发出去
路由器视角:
- 我收到的数据包必须有目标 IP 地址
- 通过路由表查映射关系
- 查到了就按照映射关系从我的指定端口发出去(不在任何一个子网范围,走其路由器的默认网关也是查到了)
- 查不到则返回一个路由不可达的数据包
涉及到的三张表分别是
- 交换机中有 MAC 地址表用于映射 MAC 地址和它的端口。MAC 地址表是通过以太网内各节点之间不断通过交换机通信,不断完善起来的。
- 路由器中有路由表用于映射 IP 地址(段)和它的端口。路由表是各种路由算法 + 人工配置逐步完善起来的。
- 电脑和路由器中都有 arp 缓存表用于缓存 IP 和 MAC 地址的映射关系。arp 缓存表是不断通过 arp 协议的请求逐步完善起来的。
TTL 是 IP 包(网络层)的一个属性,字面上就差不多是生命长度的意思,每一个三层设备都会把路过的 IP 包的 TTL 值减去 1。而 IP 包的归宿,无非以下几种:
- 网络包最终达到目的地;
- 进入路由黑洞并被丢弃;
- 因为网络设备问题被中途丢弃;
- 持续被路由转发并 TTL 减 1,直到 TTL 为 0 而被丢弃。 在RFC791中规定了 TTL 值为 8 位,所以取值范围是 0~255,不同的操作系统其初始 TTL 值不同,一般来说 Windows 是 128,Linux 是 64。因为 TTL 是从出发后就开始递减的,那么必然,网络上我们能抓到的包,它的当前 TTL 一定比出发时的值要小。TTL 从初始值到当前值的差值,就是经过的三层设备的数量。这个百度服务端大概率是 Linux 类系统,因为用 Linux 类系统的 TTL 64 减去 52,得到 12。这意味着这个回包在公网上经过了 12 跳的路由设备(三层设备)。
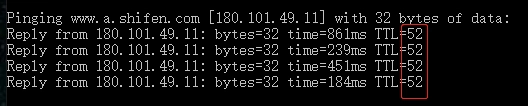
同样两个通信方之间的数据交互,其数据包在公网上容易出现路径不同的情况。就好比你每天开车上班,一般也有不止一条线路,无论走哪一条,只要能到公司就可以了。那么你和百度之间的路径,上午是 12 跳,下午变成 13 跳,或者 11 跳,也都属于正常。内网同一个连接中的报文,因为内网路径相对稳定,其 TTL 值一般不会变化。PS:如果有变,有可能是中间设备直接回包了。
网络层(IP协议)本身没有传输包的功能,包的实际传输是委托给数据链路层(以太网中的交换机)来实现的。
linux 的路由表
笔者的直观感受 一直是,路由是路由器做的事儿,既然如此,为了linux 中还有一个路由表?
普通的主机与路由器之间的根本区别在于:主机不会将一个报文从一个接口转发到另一个接口,而路由器可以转发报文。但是,一个普通路由算法可以被用在路由器上,同样也可以用在一台普通主机上。当一台主机可以用作路由器时,我们通常说这台主机嵌入了路由器的功能。这种具备嵌入路由器功能的主机平常不会转发报文,除非我们对它进行了配置,使它开启这种功能。
Linux路由分析提到: Linux默认情况下会丢掉不属于本机IP的数据包(类似的,网卡默认会丢弃mac地址不是本网卡的数据包,除非开启混杂模式)。将net.ipv4.ip_forward设置为1后,会开启路由功能,Linux会像路由器一样对不属于本机的IP数据包进行路由转发。linux 有路由表,是因为开启了路由功能。
root@ubuntu-1:/home/ops# ip route
default via 10.0.2.2 dev enp0s3
10.0.2.0/24 dev enp0s3 proto kernel scope link src 10.0.2.15
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
172.32.135.128/26 via 192.168.56.103 dev tunl0 proto bird onlink
blackhole 172.32.185.64/26 proto bird
172.32.185.70 dev calie34960bc671 scope link
172.32.185.71 dev cali6d5e7989019 scope link
172.32.243.0/26 via 192.168.56.102 dev tunl0 proto bird onlink
192.168.56.0/24 dev enp0s8 proto kernel scope link src 192.168.56.101
如何看待这个输出 route table explanation
proto,发现该路由的路由协议(即路由来源),一般是协议名,proto kernel 表示 The route was installed by the kernel during autoconfiguration.
scope,The scope of a route in Linux is an indicator of the distance to the destination network.
- Link-local address are supposed to be used for addressing nodes on a single link. Packets originating from or destined to a link-local address will not be forwarded by a router. 还有一种说法 valid only on this device
- Site,valid only within this site (IPv6)
- Host,A host address is something that will only exist within the host machine itself. For instance 127.0.0.1 is a host address commonly assigned to the loopback interface. The loopback interface has no external connectivity and so it’s scope is confined to within that of the host machine.
- A global address is what you might currently consider a “normal” address. Global which is visible on and routable across an external network.
数据中心网络架构
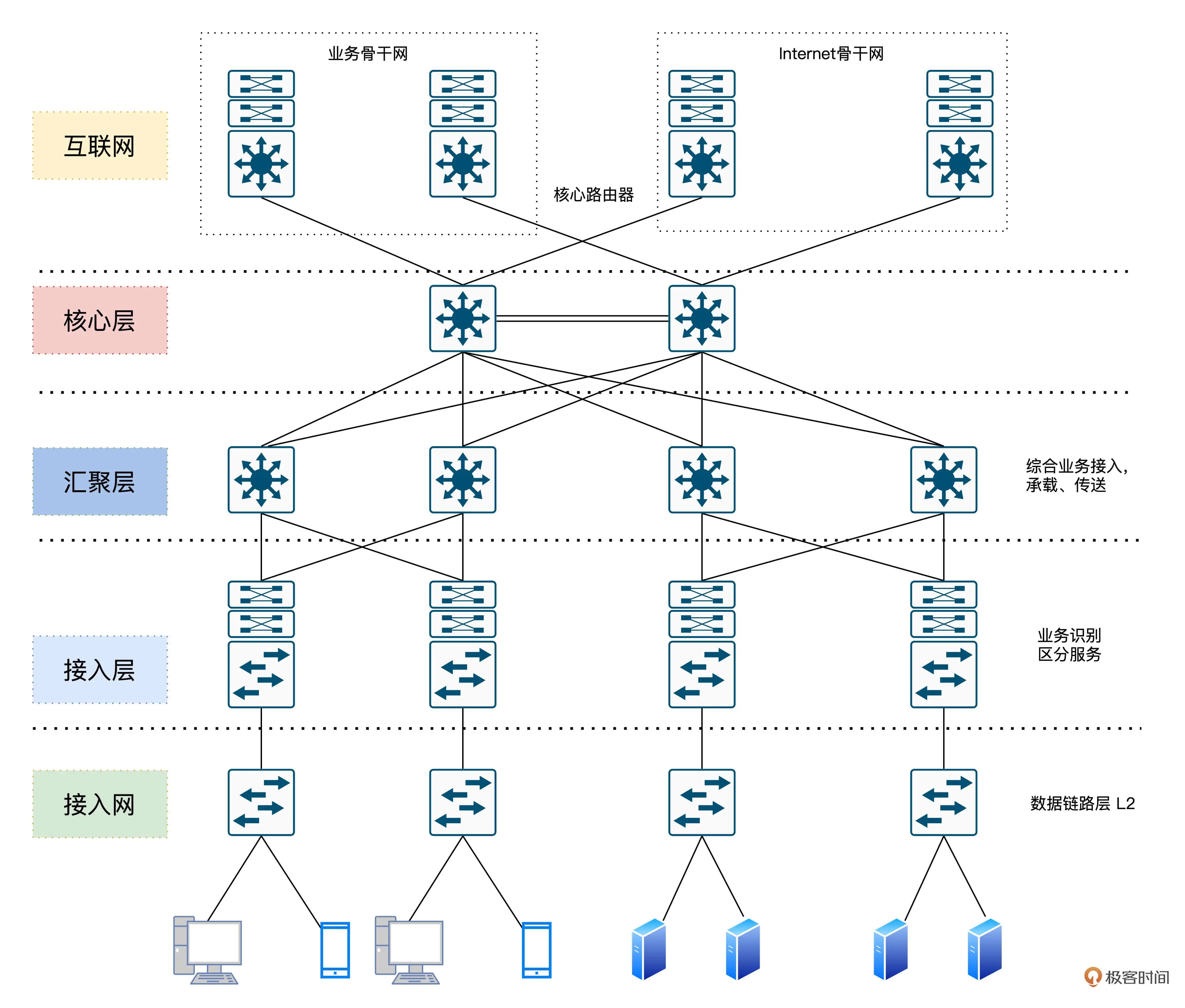
著名的通信设备厂商思科把这种架构叫做分级的互联网络模型(Hierarchical Inter-networking Model)。这种架构的优点是,可以把复杂的网络设计问题抽象为几个层面来解决,每个层面又聚焦于某些特定的功能。首先是核心层。交换层的核心交换机为进出数据中心的数据包提供高速转发的功能,为多个汇聚层提供连通性,同时也为整个网络提供灵活的 L3 路由网络。然后是汇聚层。汇聚交换机与接入交换机相连,提供防火墙、SSL 卸载、入侵检测、网络分析等其他服务。最后我们来看接入层。接入交换机通常位于机架的顶部,因此它们也被称为 ToR 交换机,并且它们与服务器物理连接。
基于这样的网络拓扑结构,The Google File System (二):如何应对网络瓶颈? 客户端写入文件时,先把所有数据传输给到网络里离自己最近的次副本 A,然后次副本 A 一边接收数据,一边把对应的数据传输给到离自己最近的另一个副本,也就是主副本。同样的,主副本可以如法炮制,把数据也同时传输给次副本 B。从而把所有的数据从客户端,传输到三个副本所在的 chunkserver 上。为什么客户端传输数据,是先给离自己最近的次副本 A,而不是先给主副本呢?两台服务器如果在同一个机架上,它们之间的网络传输只需要通过接入层的交换机即可。在这种情况下,除了两台服务器本身的网络带宽之外,它们只会占用所在的接入层交换机的带宽。但是,如果两台服务器不在一个机架,乃至不在一个 VLAN 的情况下,数据传输就要通过汇聚层交换机,甚至是核心交换机了。而如果大量的数据传输,都是在多个不同的 VLAN 之间进行的,那么汇聚层交换机乃至核心交换机的带宽,就会成为瓶颈。
整体结构
数据中心网络架构 也可以说是一种 网络硬件设备架构
- 数据中心网络架构、三层网络架构、大二层网络架构 是什么?
- 数据中心网络,本质上是一个局域网, 但机器很多,为了减少网络广播等考虑,通常会划分几个子网。
- 一个交换机最多也就几百个端口,再多的话,交换这么多数据太忙了,接那么多物理机 接口也挺麻烦的。所以,一个交换机是无法支撑一个数据中心网络架构的
- 交换机可以只是单纯的连接物理机,提供连通性,比如access switch(通常一个机架一个)。也可以是一个子网入口,或者一个词POD(Point Of Delivery)
- 互联网的发展,使得数据中心以南北流量(数据中心的主机与外网相互访问)为主转变为东西流量(数据中心内主机彼此访问)为主。比如hadoop 集群就只是内网彼此访问
- 虚拟化的流行 大大提高了单台服务器的利用率,单台服务器网络流量也随之提高
- 东西流量要求原来的 三层网络架构 的核心交换机(core switch)具备很高的性能,代价较高
- Fabric网络架构,fabric 一词的由来
- 虚拟网络 和 物理网络是紧密联系的。
- overlay网络,只要求物理网络提供连通性。只要hostA(192.168.0.0/16)和 hostB(172.16.0.0/16)连通,就可以提供一个10.10.0.0/16 网络来。物理网络上跑的 数据包 还都是 hostA和 hostB的。
二层网络与三层网络
二层网络结构和三层网络结构的对比在这里的二层、三层是按照逻辑拓扑结构进行的分类,并不是说ISO七层模型中的数据链路层和网络层,而是指数据中心网络架构,具体的说是核心层,汇聚层和接入层,这三层都部署的就是三层网络结构,二层网络结构没有汇聚层。数据中心网络架构浅谈(一)
- 二层交换机根据MAC地址表进行数据包的转发,有则转发,无则泛洪。即将数据包广播发送到所有端口,如果目的终端收到给出回应,那么交换机就可以将该MAC地址添加到地址表中。但频繁这样做,在大规模网络架构中会形成网络风暴,限制了二层网络的规模。
- 三层交换机工作原理文中提到了vlan场景下的三层交换过程。如果来一个非同一网段ip1,交换机可以通过查询过程建立ip1与port1 的映射关系,此后,去向ip1的包直接由port1转发。
其它:
为什么三层交换机无法替代路由器? - 萧骁的回答 - 知乎提高三层交换机与路由器的区别时提到:
- 三层交换机: 三层交换技术就是将路由技术与交换技术合二为一的技术。在对第一个数据流进行路由后,它将会产生一个MAC地址与IP地址的映射表,当同样的数据流再次通过时,将根据此表直接从二层通过而不是再次路由,从而消除了路由器进行路由选择而造成网络的延迟,提高了数据包转发的效率。三层交换技术就是二层交换技术+三层转发技术。它解决了局域网中网段划分之后,网段中子网必须依赖路由器进行管理的局面,解决了传统路由器低速、复杂所造成的网络瓶颈问题。三层交换机的路由功能通常比较简单,因为它所面对的主要是简单的局域网连接。
- 路由器,本质是维护ip与port的关系,其处理过程从不涉及mac。路由器的重点是向网络中广播和更新自己的路由信息。路由器一般由基于微处理器的软件路由引擎执行数据包交换,虽然也适用于局域网之间的连接,但更主要的是路由功能,更多的体现在不同类型网络之间的互联上。
- 三层交换机的最重要的目的是加快大型局域网内部的数据交换,所具有的路由功能也是为这目的服务的,能够做到一次路由,多次转发。对于数据包转发等规律性的过程由硬件高速实现,更适用于数据交换频繁的局域网中。
交换机,维基百科解释:是一个扩大网络的器材,能为子网络中提供更多的port,以便连接更多的电脑。
二层交换机、三层交换机和路由器的基本工作原理和三者之间的主要区别出于安全和管理方便的考虑,主要是为了减小广播风暴的危害,必须把大型局域网按功能或地域等因素化成一个个小的局域网,这就使得VLAN技术在网络中得到大量应用,而不同VLAN之间的通信都要经过路由器来完成转发,随着网间互访的不断增加。单纯使用路由器来实现网间访问,不但由于端口数量有限,而且路由速度较慢。从而限制了网络的规模和访问速度。基于这种情况三层交换机便应用而生。
所谓的二层设备、三层设备,都是这些设备上跑的程序不同而已。什么叫二层设备呀,就 是只把 MAC 头摘下来,看看到底是丢弃、转发,还是自己留着。那什么叫三层设备呢?就是把 MAC 头摘下来之后,再把 IP 头摘下来,看看到底是丢弃、转发,还是自己留着。
其它
NAT
为什么 IPv6 难以取代 IPv4网络地址转换(Network Address Translation、NAT)是一种在 IP 数据包通过路由器时修改网络地址的技术,可以将IP数据报文头中的IP地址转换为另一个IP地址,并通过转换端口号达到地址重用的目的。
当数据包从内部访问外部网络时,NAT 会为当前请求分配一个端口、覆写数据包中的源地址和端口并将地址和端口信息存储到本地的转换表中;当数据包从外部进入网络内部时,NAT 会根据数据包的 IP 地址和端口号查找到私有网络中对应的主机和端口号并覆写数据包中的目的地址和端口。
通过 NAT 这一中间层,我们不仅可保护私有的网络,还能缓解 IP 地址的短缺问题。不过 NAT 技术也并不是只有好处,它也带来了很多的问题,在 NAT 网络下的主机并不能与对端建立起真正的端到端连接,也不能参与部分因特网协议。
另一种表述:NAT在网络连接的过程中是常见的操作。举例,在路由器上就会对地址进行转换,具体是 snat (源地址转换) /dnat (目的地址转换) 就看处理连接的阶段,如果是数据包从外部进来,就会进行 dnat 操作,作用是将数据包的目的地址,转换成真正要访问的服务的地址,如通过 NodePort 访问应用,那肯定会将目的地址转换成要访问的 Pod 的 ip 地址;如果是数据包要从主机出去的时候,一般会进行 snat 的操作,因为要让数据包的源地址是路由可达的,而一般路由可达的地址应该是主机的物理网卡的地址,所以一般会 snat 成主机的物理网络地址。有 NAT,就会有反向 NAT,主要是完成 reply 包的处理。
隧道技术
为什么需要IP隧道?为了在TCP/IP网络中传输其他协议的数据包
Linux Networking/IPIP Encapsulation
隧道都是静态建立的,隧道一端有一个IP地址,另一端也有唯一的IP地址
PPP、PPTP和L2TP等协议或软件不是基于内核模块的,Linux系统内核实现的IP隧道技术主要有三种,都是不加密的。对于ip 连通的hostA 和 hostB来说(可以直接连通,或者hostA ==> routeA ==> routeB ==> hostB):
- ipip,点对点tunnel,hostA和hostB 均包含tunnel设备(负责解封包),在 IP 头部外面再包上一层 IP 头部
- gre,解封包在 routeA 和 route B 上完成,hostA 和host B 只需要配置路由即可。因而支持广播。
- sit
- 对于厂商来说,docker网络可能跨多个环境,统一acl等比较复杂
- 容器相较于虚拟机在一台主机上的密度大大增加
VPC
基于目前主流的隧道技术,虚拟私有网络/专有网络隔离了虚拟网络。每个VPC都有一个独立的隧道号,一个隧道号对应着一个虚拟化网络。PS:经常一个云厂商的一个账号下可以创建多个vpc
- 一个VPC内的ECS(Elastic Compute Service)实例之间的传输数据包都会加上隧道封装,带有唯一的隧道号标识,然后通过物理网络进行传输。
- 不同VPC内的ECS实例由于所在的隧道号不同,本身处于两个不同的路由平面,因此不同VPC内的ECS实例无法进行通信,天然地进行了隔离。
在云网络的语境中
- Underlay 底层网络是云网络的物理基础,它通常由一系列的物理网络设备,如路由器、交换机、光纤线缆等构成,是实实在在存在于数据中心或网络基础设施中的硬件连接部分。
- Overlay 覆盖网络是构建在 Underlay 底层网络之上的虚拟网络,它通过软件和虚拟化技术实现,对底层物理网络资源进行抽象和整合,从而创建出逻辑上独立、隔离的虚拟网络环境,类似于在已有的道路(Underlay 网络)基础上,通过规划不同的行车路线、设置特殊标识等方式构建出专属于某些车辆类型(不同虚拟网络)的虚拟交通网络。可以实现多租户之间的网络隔离,不同租户在云环境中虽然共用底层的物理网络设备,但通过 Overlay 网络能拥有各自独立、安全的虚拟网络空间,彼此的数据不会相互干扰。
云网络中很重要的一部分是基于物理网络构建出的虚拟网络层,也就是常说的 Overlay(覆盖网络)。通过如 VXLAN、NVGRE 等技术对网络流量进行封装等操作。另外云网络的构建不仅仅是简单地基于物理网络虚拟出一层网络这么简单。它还涉及到诸多关键技术和组件协同工作:
- 软件定义网络(SDN):将网络的控制平面与数据平面分离,通过软件层面的控制器对网络进行集中管控、灵活配置路由策略、分配带宽等
- 网络功能虚拟化(NFV):把原本依靠硬件实现的网络功能,像防火墙、负载均衡器等以软件化虚拟功能形式运行在通用服务器上,这也是云网络架构里重要的一环,和单纯在物理网络上虚拟网络层的概念不同。
留下评论