LangGraph工作流编排
简介
在框架的早期,可以总结成两种主要方式:
- 提供更高层的组件与API的封装。比如简单的向量检索器是VectorIndexRetriever,但现在需要增加路由功能,就封装一个带有路由的RouterRetriever;简单的查询引擎是QueryEngine,但现在需要增加重排功能,就增加一个可以传入Reranker模块的参数。
- 提供链式或DAG(单向无环图)结构的可编排方法。最具代表性的是LangChain框架中的Chain(链)与LCEL(LangChain表达语言)特性;以及LlamaIndex在年初推出的Query Pipeline(查询管道)声明式API特性。它们都在一定程度上提供了编排能力。
尽管如此,这种受限的工作流编排仍然面临较大的局限性:
- 高层的组件或API封装缺乏足够的灵活性。体现在:
- 随着需求的复杂化,需要封装更多的高层组件,框架变得更臃肿。
- 高层组件的内部过于“黑盒”。比如很难对LangChain或LlamaIndex的ReActAgent组件构建的智能体的执行过程做更精细化的控制。
- 链式或DAG结构的流程无法支持循环,限制了使用场景。但在如今的很多AI工作流中,比如智能体的反思(Relfection)以及一些新的RAG范式(如C-RAG等)都需要循环的支持。
- 不够简洁与直观,也难以调试。基于这样一些原因,提供一种更强大的工作流定义与编排的支持,也成为了开发框架的发力重点,典型的就是之前介绍过的LangGraph以及LlamaIndex Workflows。 PS:一个workflow 引擎,两个关键字是workflow/step(task),三个关键字是workflow/step/context(全局的和step间的信息传递)。四个关键词就再带一个驱动机制:顺序驱动(按序执行,就没法循环了)、图驱动、事件驱动。
从顺序式为主的简单架构走向复杂的WorkFlow
编程语言大类上可以分为命令式编程和声明式编程,前者深入细节,各种 if else、各种 while/for,程序员掌控每个像素;后者把任务「描述」清楚,重点在业务流程翻译成所用的语言上,具体怎么实现甩给别人(大部分是系统自带)。由于这一波 LLMs 强大的理解、生成能力,关注细节的命令式编程似乎不再需要,而偏重流程或者说业务逻辑编排的 pipeline 能力的声明式编程,成了主流「编程」方式。
RAG 流程是指在 RAG 系统中,从输入查询到输出生成文本的整个工作流程。这个流程通常涉及多个模块和操作符的协同工作,包括但不限于检索器、生成器以及可能的预处理和后处理模块。RAG 流程的设计旨在使得 LLM(大语言模型)能够在生成文本时利用外部知识库或文档集,从而提高回答的准确性和相关性。推理阶段的RAG Flow分成四种主要的基础模式:顺序、条件、分支与循环。PS: 一个llm 业务有各种基本概念,prompt/llm/memory,整个工作流产出一个流式输出,处理链路上包含多个step,且step有复杂的关系(顺序、条件、分支与循环)。一个llm 业务开发的核心就是个性化各种原子能力 以及组合各种原子能力。
以一个RAG Agent 的工作流程为例
- 根据问题,路由器决定是从向量存储中检索上下文还是进行网页搜索。
- 如果路由器决定将问题定向到向量存储以进行检索,则从向量存储中检索匹配的文档;否则,使用 tavily-api 进行网页搜索。
- 文档评分器然后将文档评分为相关或不相关。
- 如果检索到的上下文被评为相关,则使用幻觉评分器检查是否存在幻觉。如果评分器决定响应缺乏幻觉,则将响应呈现给用户。
- 如果上下文被评为不相关,则进行网页搜索以检索内容。
- 检索后,文档评分器对从网页搜索生成的内容进行评分。如果发现相关,则使用 LLM 进行综合,然后呈现响应。
高级 RAG 检索策略之流程与模块化业界一个共识是RAG的演进:Naive RAG ==> Advanced RAG ==> Modular RAG。要落地Modular RAG,便是定义模块以及将模块串起来的Pipeline。比如LlamaIndex 的探索。PS: pipeline/add_modules/add_link
retriever = index.as_retriever()
p = QueryPipeline(verbose=True)
p.add_modules(
{
"input": InputComponent(),
"retriever": retriever,
"output": SimpleSummarize(),
}
)
p.add_link("input", "retriever")
p.add_link("input", "output", dest_key="query_str")
p.add_link("retriever", "output", dest_key="nodes")
完整的流水线
evaluator = RagasComponent()
p = QueryPipeline(verbose=True)
p.add_modules(
{
"input": InputComponent(),
"query_rewriter": query_rewriter,
"retriever": retriever,
"meta_replacer": meta_replacer,
"reranker": reranker,
"output": TreeSummarize(),
"evaluator": evaluator,
}
)
p.add_link("input", "query_rewriter")
p.add_link("input", "query_rewriter", src_key="input")
p.add_link("query_rewriter", "retriever")
p.add_link("retriever", "meta_replacer")
p.add_link("input", "reranker", dest_key="query_str")
p.add_link("input", "reranker", src_key="input", dest_key="query_str")
p.add_link("meta_replacer", "reranker", dest_key="nodes")
p.add_link("input", "output", dest_key="query_str")
p.add_link("input", "output", src_key="input", dest_key="query_str")
p.add_link("reranker", "output", dest_key="nodes")
p.add_link("input", "evaluator", src_key="input", dest_key="question")
p.add_link("input", "evaluator", src_key="ground_truth", dest_key="ground_truth")
p.add_link("reranker", "evaluator", dest_key="nodes")
p.add_link("output", "evaluator", dest_key="answer")
Runnable protocol
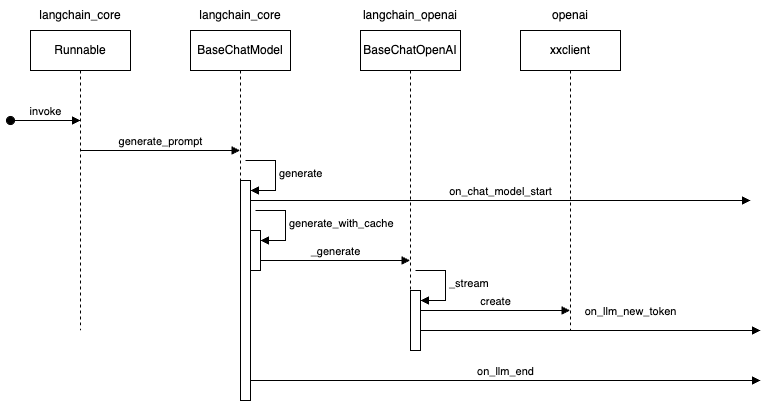
在 LangChain 0.1 之前,LangChain 总结提炼了LLM 开发必须的几个基础组件,比如Prompt/LLM等,对它们的功能范围、输入输出进行了界定,找到构造复杂系统的统一规律和可达路径,此时还相对碎一些,抽象粒度低,后来将Prompt/LLM 等都统一到Runnable 协议(就像Java里的一切皆Object),原子组件标准化,进而以此为基础提出了编排组件LCEL和LangGraph。 LangChain 0.1 几个包
- langchain-core 包含了核心抽象(如消息类型定义,输入输出管理等)和 LangChain 表达语言(LCEL)
- langchain-community 包含第三方集成,其易变特性与 langchain-core 形成对比。主要集成将被进一步拆分为独立软件包,以更好地组织依赖、测试和维护。
- langchain 负责流程的编排与组装,包含了实际运用的 Chain、Agent 和算法,为构建完整的 LLM 应用提供了支撑。。它相对开放,介于 langchain-core 和 langchain-community 之间。
在 LangChain 里只要实现了Runnable接口,并且有invoke方法,都可以成为链。实现了Runnable接口的类,可以拿上一个链的输出作为自己的输入。
类似runnable 协议的思路在业界有很多应用,比如KAG中文档入库的pipeline,其也是上层提了一个Runnable抽象,override了__rshift__方法
class DiseaseBuilderChain(BuilderChainABC):
def build(self, **kwargs):
source = PdfReader(output_type="Chunk", file_path=xx)
splitter = LengthSplitter(split_length=2000)
extractor = KAGExtractor()
vectorizer = BatchVectorizer()
sink = KGWriter()
return source >> splitter >> extractor >> vectorizer >> sink
LCEL
langchain入门3-LCEL核心源码速通LCEL实际上是langchain定义的一种DSL,可以方便的将一系列的节点按声明的顺序连接起来,实现固定流程的workflow编排。LCEL语法的核心思想是:一切皆为对象,一切皆为链。这意味着,LCEL语法中的每一个对象都实现了一个统一的接口:Runnable,它定义了一系列的调用方法(invoke, batch, stream, ainvoke, …)。这样,你可以用同样的方式调用不同类型的对象,无论它们是模型、函数、数据、配置、条件、逻辑等等。而且,你可以将多个对象链接起来,形成一个链式结构,这个结构本身也是一个对象,也可以被调用。这样,你可以将复杂的功能分解成简单的组件,然后用LCEL语法将它们组合起来,形成一个完整的应用。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
import os
os.environ["OPENAI_API_BASE"] = "http://xx:8000/v1"
os.environ["OPENAI_API_KEY"] = "EMPTY"
prompt = ChatPromptTemplate.from_template("tell me a short joke about {topic}")
output_parser = StrOutputParser()
model = ChatOpenAI(model="moonshot-v1-8k")
chain = prompt | model | output_parser
answer = chain.invoke({"topic": "ice cream"})
print(answer)
# 调用笑话对象,传入一个主题字符串,得到一个笑话字符串的流
chain.stream("dog")
chain = prompt | model | output_parser。我们可以看到这段代码中使用了运算符|,熟悉python的同学肯定知道,这里使用了python的magic method,也就是说它一定具有__or__函数。prompt | model就相当于prompt.__or__(model)。实际上,prompt实现了__ror__,这个magic method支持从右往左的or运算,dict|prompt,相当于prompt.__ror__(dict) 。
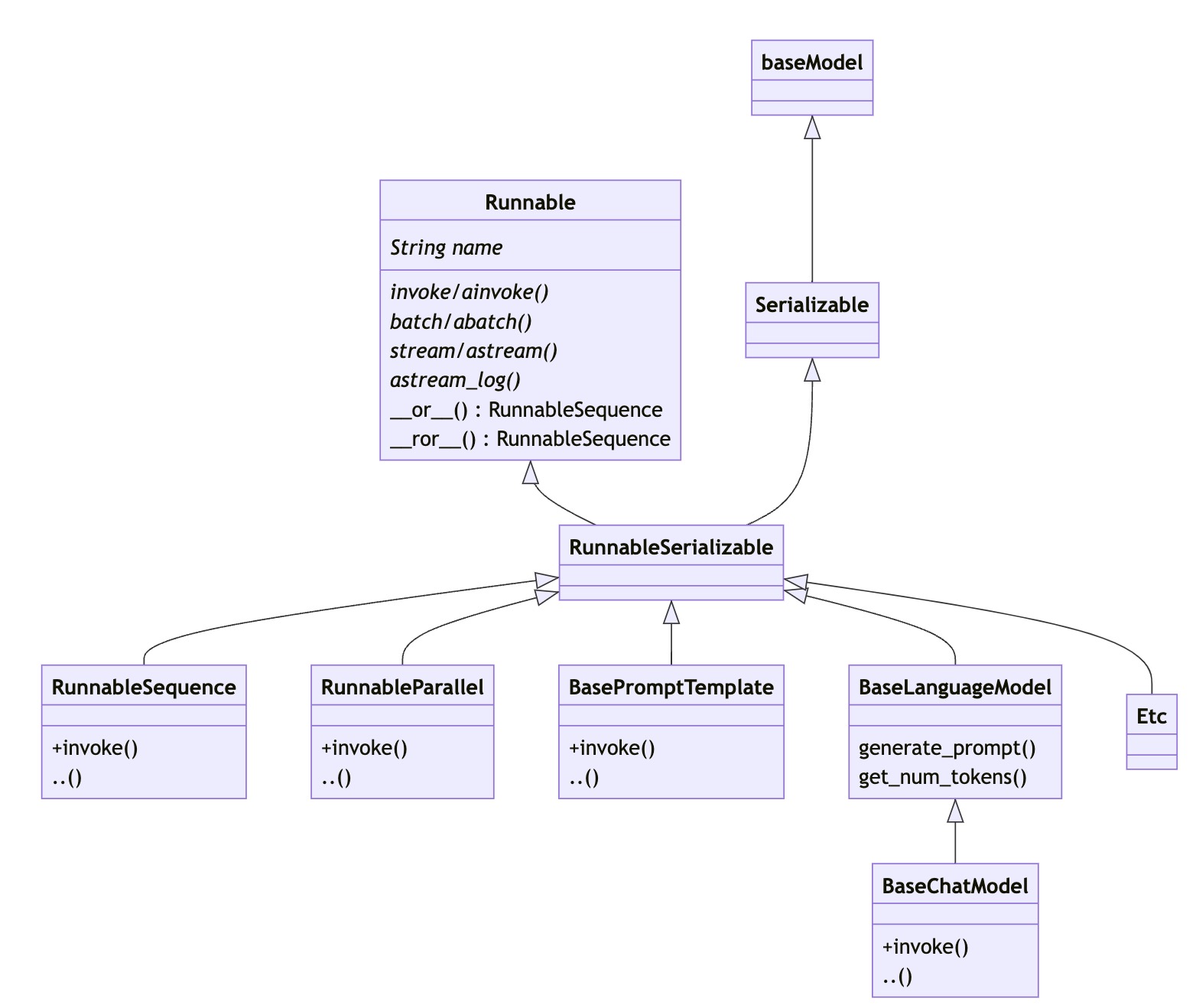
| Component | Input Type | Output Type |
|---|---|---|
| Prompt | Dictionary | PromptValue |
| ChatModel | Single string, list of chat messages or a PromptValue | ChatMessage |
| LLM | Single string, list of chat messages or a PromptValue | String |
| OutputParser | The output of an LLM or ChatModel | Depends on the parser |
| Retriever | Single string | List of Documents |
| Tool | Single string or dictionary, depending on the tool | Depends on the tool |
模块化抽象Runnable
我们使用的所有LCEL相关的组件都继承自RunnableSerializable,RunnableSequence 顾名思义就按顺序执行的Runnable,分为两部分Runnable和Serializable。其中Serializable是继承自Pydantic的BaseModel。(py+pedantic=Pydantic,是非常流行的参数验证框架)Serializable提供了,将Runnable序列化的能力。而Runnable,则是LCEL组件最重要的一个抽象类,它有几个重要的抽象方法。
class Runnable(Generic[Input, Output], ABC):
@abstractmethod
def invoke(self, input: Input, config: Optional[RunnableConfig] = None) -> Output:
Runnable所有接口都接收可选的配置参数,可用于配置执行、添加标签和元数据,以进行跟踪和调试。
- invoke/ainvoke: 单个输入转为输出。
- batch/abatch:批量转换。
- stream/astream: 单个流式处理,提供了对图(Graph)执行过程中各个节点产生的数据进行精细化控制的能力。PS: 如果没有这个,只能通过callbackhandler.on_llm_new_token 获取llm的吐字了
chunks = [] async for chunk in model.astream("你好。告诉我一些关于你自己的事情"): chunks.append(chunk) print(chunk.content, end="|", flush=True) -
stream_events:从输入流流式获取结果与中间步骤。 PS:尤其是对agent来讲,等final answer 太久了,但流式获取一个个token太细节了(哪怕这些token 都附带了它们属于哪些step的元信息),流式获取中间一个个event 更舒服些。langchain streaming
async for event in model.astream_events("hello", version="v1"): kind = event["event"] if kind == "on_chat_model_stream": ... if kind == "on_parser_stream": ...
有时我们希望 使用常量参数调用Runnable 调用链中的Runnable对象,这些常量参数不是序列中前一个Runnable 对象输出的一部分,也不是用户输入的一部分,我们可以使用Runnable.bind 方法来传递这些参数。
| 同时Runnbale也实现了两个重要的magic method ,就是前面说的用于支持管道操作符 | 的 __or__ 与__ror__。Runnable之间编排以后,会生成一个RunnableSequence。 |
class Runnable(Generic[Input, Output], ABC):
def __or__(
self,
other: Union[
Runnable[Any, Other],
Callable[[Any], Other],
Callable[[Iterator[Any]], Iterator[Other]],
Mapping[str, Union[Runnable[Any, Other], Callable[[Any], Other], Any]],
],
) -> RunnableSerializable[Input, Other]:
"""Compose this runnable with another object to create a RunnableSequence."""
return RunnableSequence(self, coerce_to_runnable(other))
def __ror__(
self,
other: Union[
Runnable[Other, Any],
Callable[[Other], Any],
Callable[[Iterator[Other]], Iterator[Any]],
Mapping[str, Union[Runnable[Other, Any], Callable[[Other], Any], Any]],
],
) -> RunnableSerializable[Other, Output]:
"""Compose this runnable with another object to create a RunnableSequence."""
return RunnableSequence(coerce_to_runnable(other), self)
Runnable 对象表示一个可调用的函数或操作单元,RunnableSequence 可以看成由lcel 构建的调用链的实际载体。如果我们运行最终编排好的Chain,例如chain.invoke({“topic”: “ice cream”}),实际上就是执行了RunnableSequence的invoke。那我们先来看看invoke函数。
# config对象,可以设置一些并发数、标签等等配置,默认情况下为空。
def invoke(self, input: Input, config: Optional[RunnableConfig] = None) -> Output:
from langchain_core.beta.runnables.context import config_with_context
# 根据上下文补充config
config = config_with_context(ensure_config(config), self.steps)
# 创建回调管理器,用于支持运行中产生的各种回调
callback_manager = get_callback_manager_for_config(config)
# 创建运行管理器,用于处理异常重试,结束等情况
run_manager = callback_manager.on_chain_start(
dumpd(self), input, name=config.get("run_name") or self.get_name()
)
# !!关键内容!!
# 调用整个链
try:
# 顺序执行step,每一步的输出,将作为下一步的输入
for i, step in enumerate(self.steps):
input = step.invoke(
input,
# 为下一个step更新config
patch_config(
config, callbacks=run_manager.get_child(f"seq:step:{i+1}")
),
)
# finish the root run
except BaseException as e:
run_manager.on_chain_error(e)
raise
else:
run_manager.on_chain_end(input)
return cast(Output, input)
Runnable 还有很多增强/装饰方法,对underlying runnable 增加一些配置、逻辑得到一个新的Runnable,以openai为例,底层实质扩充了openai.ChatCompletion.create 前后逻辑或调用参数。
class Runnable(Generic[Input, Output], ABC):
def assign(self,**kwargs)-> RunnableSerializable[Any, Any]:
return self | RunnableAssign(RunnableParallel(kwargs))
# Bind kwargs to pass to the underlying runnable when running it.
def bind(self, **kwargs: Any) -> Runnable[Input, Output]:
return RunnableBinding(bound=self, kwargs=kwargs, config={})
# Bind config to pass to the underlying runnable when running it.
def with_config(self,config: Optional[RunnableConfig] = None,**kwargs: Any,) -> Runnable[Input, Output]:
return RunnableBinding(...)
# Bind a retry policy to the underlying runnable.
def with_retry(self,retry_if_exception_type,...) -> Runnable[Input, Output]:
return RunnableRetry(...)
# Bind a fallback policy to the underlying runnable.
def with_fallbacks(self,fallbacks,...)-> RunnableWithFallbacksT[Input, Output]:
return RunnableWithFallbacks(self,fallbacks,...)
RunnableConfig 是一个配置对象,用于自定义运行链(Chain)、工具(Tool)或任何可运行组件的行为。它允许我们控制执行过程中的各种参数和行为,可以确保配置信息与输入数据分离,不作为状态的一部分进行跟踪。
Runnable串联
def add_one(x: int) -> int:
return x + 1
def mul_two(x: int) -> int:
return x * 2
runnable_1 = RunnableLambda(add_one) # RunnableLambda 可以把一个Callable类转成Runnable类(python所有可调用对象都是Callable 类型),从而可以将你自定义的函数集成到chain中
runnable_2 = RunnableLambda(mul_two)
sequence = runnable_1 | runnable_2
sequence.invoke(1)
def mul_three(x: int) -> int:
return x * 3
sequence = runnable_1 | { # Runnable对象的列表或字典/this dict is coerced to a RunnableParallel
"mul_two": runnable_2,
"mul_three": runnable_3,
}
sequence.invoke(1) # 会输出一个dict {'mul_two':4, 'mul_three':6}
branch = RunnableBranch(
(lambda x: isinstance(x, str), lambda x: x.upper()),
(lambda x: isinstance(x, int), lambda x: x + 1),
(lambda x: isinstance(x, float), lambda x: x * 2),
lambda x: "goodbye",
)
branch.invoke("hello") # "HELLO"
branch.invoke(None) # "goodbye"
RunnableParallel 的使用可以有以下三种形式,三种形式等价:
{"context": retriever, "question": RunnablePassthrough()}
RunnableParallel({"context": retriever, "question": RunnablePassthrough()})
RunnableParallel(context=retriever, question=RunnablePassthrough())
在使用LCEL构建链时,原始用户输入可能不仅要传给第一个组件,还要传给后续组件,这时可以用RunnablePassthrough。RunnablePassthrough可以透传用户输入。
# 用户输入的问题,不止组件1的检索器要用,组件2也要用它来构建提示词,因此组件1使用RunnablePassthrough方法把原始输入透传给下一步。
chain = (
# 由于组件2 prompt的输入要求是字典类型,所以组件1把检索器和用户问题写成字典格式,并用组件2的变量作为键。
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| model
| StrOutputParser()
)
两个Runnable 对象之间(很多时候是第一个)需要一些数据处理、转换、透传的逻辑
- 在构建复杂的RunnableSequence时,我们可能需要将很多信息从上游传递到下游,此时可以用到RunnablePassthrough。此外,还可以使用RunnablePassthrough.assign 方法在透传上游数据的同时添加一些新的的数据。
- RunnableMap,底层是RunnableParallel,通常以一个dict 结构出现,value 是一个Runnable对象,lcel 会并行的调用 value部分的Runnable对象 并将其返回值填充dict,之后将填充后的dict 传递给RunnableSequence 的下一个Runnable对象。
目前Memory模块还是Beta版本,创建带Memory功能的Chain,并不能使用统一的LCEL语法。但是,LangChain提供了工具类RunnableWithMessageHistory,支持了为Chain追加History的能力,从某种程度上缓解了上述问题。不过需要指定Lambda函数get_session_history以区分不同的会话,并需要在调用时通过config参数指定具体的会话ID。
llm = xx
prompt = xx
chain = prompt | llm | output_parser
history = ChatMessageHistory()
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: history,
input_messages_key="question",
history_messages_key="chat_history",
)
LCEL提供了多种优势,例如一流的流支持、异步支持、优化的并行执行、支持重试和回退、访问中间结果、输入和输出模式以及无缝 LangSmith 跟踪集成。但因为语法上的问题,要实现 loop 和 condition 的情况就比较困难。于是LangChain社区推出了一个新的项目——LangGraph,期望基于LangChain构建支持循环和跨多链的计算图结构,以描述更复杂的,甚至具备自动化属性的AI工程应用逻辑,比如智能体应用。
LangGraph
langchain早期其实都内置有开箱即用的更简单的Agent开发组件。比如在先前LangChain中,创建一个会使用工具(Tools)的ReAct范式的Agent并不复杂:把定义好的tools交给大模型,然后让大模型自行规划与选择工具的使用,以完成输入任务。如下:
#准备tools,model,prompt
search = TavilySearchResults(max_results=2)
@tool
def email(topic: str) -> str:
return 'Email completed.'
tools = [search, email]
model = ChatOpenAI(model="gpt-4o")
prompt = hub.pull("hwchase17/openai-functions-agent")
#创建agent
agent = create_tool_calling_agent(model, tools, prompt)
#调用agent
agent_executor = AgentExecutor(agent=agent, tools=tools)
agent_executor.invoke({"input": "搜索明天的天气发送到mm@aa.com"})
那为什么还需要LangGraph?两个核心的原因是:
- 为了支持更复杂的LLM应用,特别是需要循环迭代的工作流,以及需要多智能体协作与交互的应用。比如Self-RAG
- 为了让AI智能体更加可控与可预测。尽管LLM已经足够强大,但完全依赖于其自行规划与决策行动的“黑盒”智能体仍然存在较大的不确定性,这会极大的限制其在生产环境,特别是企业环境中的应用。
彻底搞懂LangGraph:构建强大的Multi-Agent多智能体应用的LangChain新利器 相对于Chain.invoke()直接运行,Agent_executor的作用就是为了能够实现多次循环ReAct的动作,以最终完成任务。为什么需要将循环引入运行时呢?考虑一个增强的RAG应用:我们可以对语义检索出来的关联文档(上下文)进行评估:如果评估的文档质量很差,可以对检索的问题进行重写(Rewrite,比如把输入的问题结合对话历史用更精确的方式来表达),并把重写结果重新交给检索器,检索出新的关联文档,这样有助于获得更精确的结果。这里把Rewrite的问题重新交给检索器,就是一个典型的“循环”动作。而在目前LangChain的简单链中是无法支持的。其他一些典型的依赖“循环”的场景包括:代码生成时的自我纠正:当借助LLM自动生成软件代码时,根据代码执行的结果进行自我反省,并要求LLM重新生成代码;Web访问自动导航:每当进入下一界面时,需要借助多模态模型来决定下一步的动作(点击、滚动、输入等),直至完成导航。
那么,如果我们需要在循环中调用LLM能力,就需要借助于AgentExecutor,将Agent 置于一个循环执行环境(PS:所谓自主运行就是靠循环)。其调用的过程主要就是两个步骤:
- 通过大模型来决定采取什么行动,使用什么工具,或者向用户输出响应(如运行结束时);
- 执行1步骤中的行动,比如调用某个工具,并把结果继续交给大模型来决定,即返回步骤1; 这里的AgentExecute存在的问题是:过于黑盒,所有的决策过程隐藏在AgentExecutor背后,缺乏更精细的控制能力,在构建复杂Agent的时候受限。这些精细化的控制要求比如:
- 某个Agent要求首先强制调用某个Tool
- 在 Agent运行过程中增加人机交互步骤
- 能够灵活更换Prompt或者背后的LLM
- 多Agent(Multi-Agent)智能体构建的需求,即多个Agent协作完成任务的场景支持。 所以,让我们简单总结LangGraph诞生的动力:LangChain简单的链(Chain)不具备“循环”能力;而AgentExecutor调度的Agent运行又过于“黑盒”。因此需要一个具备更精细控制能力的框架来支持更复杂场景的LLM应用。
LangGraph的实现方式是把之前基于AgentExecutor的黑盒调用过程用一种新的形式来构建:状态图(StateGraph)。把基于LLM的任务(比如RAG、代码生成等)细节用Graph进行精确的定义(定义图的节点与边),最后基于这个图来编译生成应用;在任务运行过程中,维持一个中央状态对象(state),会根据节点的跳转不断更新,状态包含的属性可自行定义。
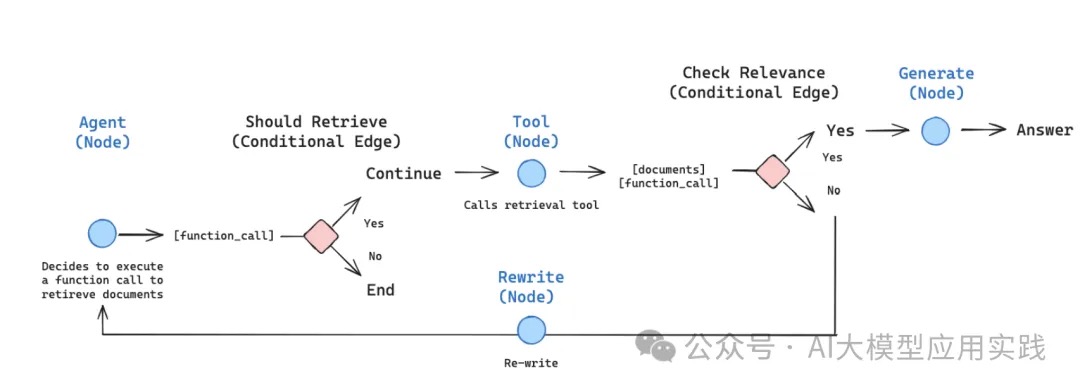
构建Agent
lcel示例
tools: Sequence[BaseTool] = xx
# A Runnable sequence representing an agent. It takes as input all the same input variables as the prompt passed in does. It returns as output either an AgentAction or AgentFinish.
agent = (
RunnablePassthrough.assign(
agent_scratchpad=lambda x: format_log_to_str(x["intermediate_steps"]),
)
| prompt
| llm_with_stop
| JSONAgentOutputParser()
)
executor = AgentExecutor(agent=agent, tools=tools, callbacks=callbacks)
AgentExecutor初始化的时候,如果发现agent 是一个Runable,则会将其转为RunnableAgent。Agent输入输出比较明确
- 输入 prompt hwchase17/structured-chat-agent 和 intermediate_steps
- 输出 AgentAction 和 AgentFinish
class RunnableAgent(BaseSingleActionAgent): def plan( self, intermediate_steps: List[Tuple[AgentAction, str]], callbacks: Callbacks = None, **kwargs: Any, ) -> Union[AgentAction, AgentFinish]: ...AgentExecutor 循环执行Agent.plan,Agent.plan返回AgentAction,之后AgentExecutor 执行AgentAction.tool 得到observation, AgentExecutor 会将action和observation包装为 AgentStep 塞到临时变量intermediate_steps里,并在下次执行Agent.plan时塞给Agent.plan。AgentExecutor 驱动 Agent.plan 和 tool.run 一般相对固定,个性化逻辑主要是 Agent,主要体现在个性化 prompt 及tool description。
langgraph示例
langgraph正在成为构建Agent的推荐方式。
一个最基础的ReAct范式的Agent应用对应的Graph如下:
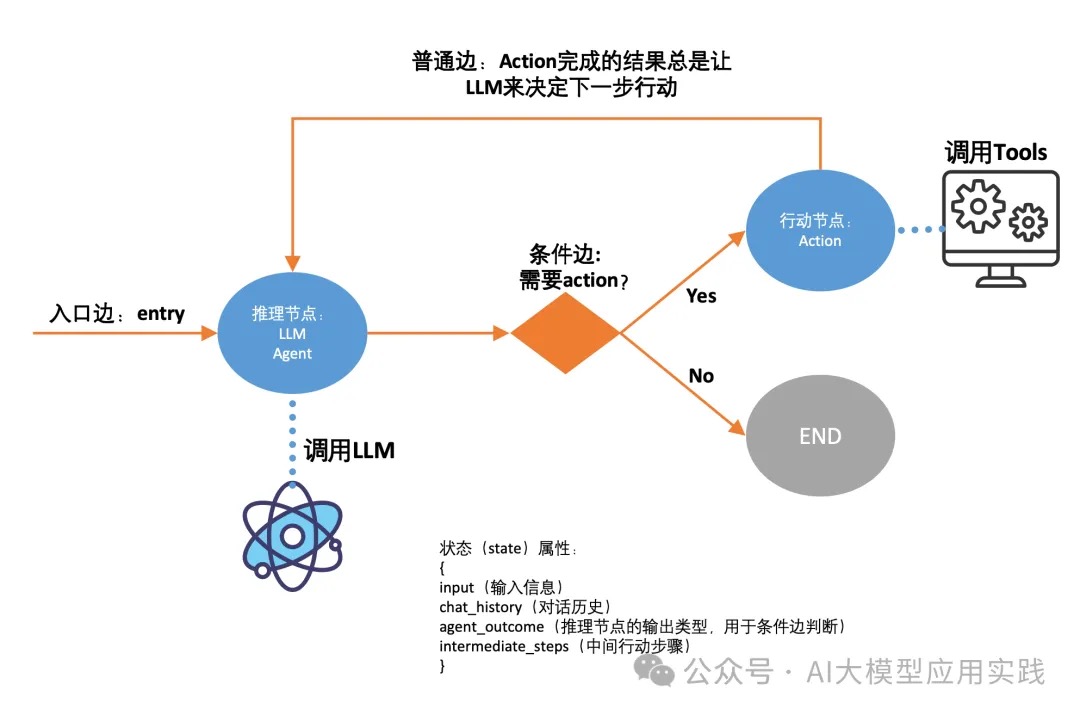
简单的实现代码如下(省略了部分细节):
# 定义一个Graph,传入state定义(参考上图state属性)
workflow = StateGraph(AgentState)
# 两个节点
#节点1: 推理节点,调用LLM决定action,省略了runreason细节
workflow.add_node("reason", run_reason)
#节点2: 行动节点,调用tools执行action,省略executetools细节
workflow.add_node("action", execute_tools)
#入口节点:总是从推理节点开始
workflow.set_entry_point("reason")
#条件边:根据推理节点的结果决定下一步
workflow.add_conditional_edges(
"reason",
should_continue, #条件判断函数(自定义,根据状态中的推理结果判断)
{
"continue": "action", #如果条件函数返回continue,进action节点
"end": END, #如果条件函数返回end,进END节点
},
)
#普通边:action结束后,总是返回reason
workflow.add_edge("action", "reason")
#编译成app
app = workflow.compile()
#可以调用app了,并使用流式输出
inputs = {"input": "you task description", "chat_history": []}
for s in app.stream(inputs):
print(list(s.values())[0])
print("----")
LangGraph原理
LangGraph的核心方法是:通过定义一个Graph图结构的流程来代表你需要创建的LLM应用工作流。Graph的特点决定了你的应用具备了极大的灵活性:
- 支持并行、条件分支、循环等各种细粒度工作流控制
- 灵活定义每个节点任务,每个节点都被设计为纯函数,可以是简单函数、LLM调用,或一次Agent交互
- 可持久的全局状态控制,工作流可随时暂停、启动或介入人工交互
三要素
LangGraph 三个核心要素
- StateGraph,LangGraph 在图的基础上增添了全局状态变量,是一组键值对的组合,可以被整个图中的各个节点访问与更新,从而实现有效的跨节点共享及透明的状态维护。它将该对象传递给每个节点。然后,节点会以键值对的形式,返回对状态属性的操作。这些操作可以是在状态上设置特定属性(例如,覆盖现有值)或者添加到现有属性。
- 在创建了StateGraph之后,我们需要向其中添加Nodes(节点)。添加节点是通过
graph.add_node(name, value)语法来完成的。其中,name参数是一个字符串,用于在添加边时引用这个节点。value参数应该可以是函数或runnable 接口,它们将在节点被调用时执行。其输入应为状态图的全局状态变量,在执行完毕之后也会输出一组键值对,字典中的键是State对象中要更新的属性。说白了,Nodes(节点)的责任是“执行”,在执行完毕之后会更新StateGraph的状态。PS: node 输入都是state,输出是对state的更新 - 节点通过边相互连接,形成了一个有向无环图(DAG),边有几种类型:
- Normal Edges:即确定的状态转移,这些边表示一个节点总是要在另一个节点之后被调用。
- Conditional Edges:输入是一个节点,输出是一个mapping,连接到所有可能的输出节点,同时附带一个判断函数(输入是StateGraph,输出是Literal),根据全局状态变量的当前值判断流转到哪一个输出节点上,以充分发挥大语言模型的思考能力。 PS: 在langgraph 较新的版本支持 langgraph.types.Command(动态路由)之后,一个node1 跳转到另一个node2 在node1 内部就可以定义了。
当我们使用这三个核心要素构建图之后,通过图对象的compile方法可以将图转换为一个 Runnable对象(Runnable也有Runnable.get_graph 转为Graph对象),之后就能使用与lcel完全相同的接口调用图对象。
class Graph:
def __init__(self) -> None:
self.nodes: dict[str, Runnable] = {}
self.edges = set[tuple[str, str]]()
self.branches: defaultdict[str, dict[str, Branch]] = defaultdict(dict)
self.support_multiple_edges = False
self.compiled = False
langgraph 代码的主要流程 构建node、edge,然后将其组为graph,自然 langchain 会提供很多现成封装,将各种组件封装为 node/edge。比如两个 为tool 提供了 ToolNode(将tool转为 node,因为node 一般入参是stateGraph,出餐是dict), tools_condition(是一个入参包含stateGraph 的函数,返回Literal)
web_search_tool = TavilySearchResults(k=3)
tools = [web_search_tool]
retrieve = ToolNode(tools)
...
workflow.add_conditional_edges(
"agent",
# Assess agent decision
tools_condition,
{
# Translate the condition outputs to nodes in our graph
"tools": "retrieve",
END: END,
},
)
workflow.add_node("retrieve", retrieve)
from langgraph_core.tools import BaseTool
class BaseTool(RunnableSerializable[Union[str, Dict], Any]):
name: str
description: str
def invoke(self, input: Union[str, Dict],config: Optional[RunnableConfig] = None,**kwargs: Any,) -> Any:
...
return self.run(...)
class Tool(BaseTool):
description: str = ""
func: Optional[Callable[..., str]]
coroutine: Optional[Callable[..., Awaitable[str]]] = None
from langgraph.prebuilt import ToolNode
class ToolNode(RunnableCallable):
def __init__( self,tools: Sequence[BaseTool],*,name: str = "tools",tags: Optional[list[str]] = None,) -> None:
super().__init__(self._func, self._afunc, name=name, tags=tags, trace=False)
self.tools_by_name = {tool.name: tool for tool in tools}
def _func(self, input: Union[list[AnyMessage], dict[str, Any]], config: RunnableConfig) -> Any:
message = messages[-1]
def run_one(call: ToolCall):
output = self.tools_by_name[call["name"]].invoke(call["args"], config)
return ToolMessage(...output...)
with get_executor_for_config(config) as executor:
outputs = [*executor.map(run_one, message.tool_calls)]
return outputs 或者 {"messages": outputs}
def tools_condition(state: Union[list[AnyMessage], dict[str, Any]],) -> Literal["tools", "__end__"]:
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return "__end__"
langgraph 的灵感来自 Pregel 和 Apache Beam。暴露的接口借鉴了 NetworkX。PS: 限定了node 输入输出的dag。
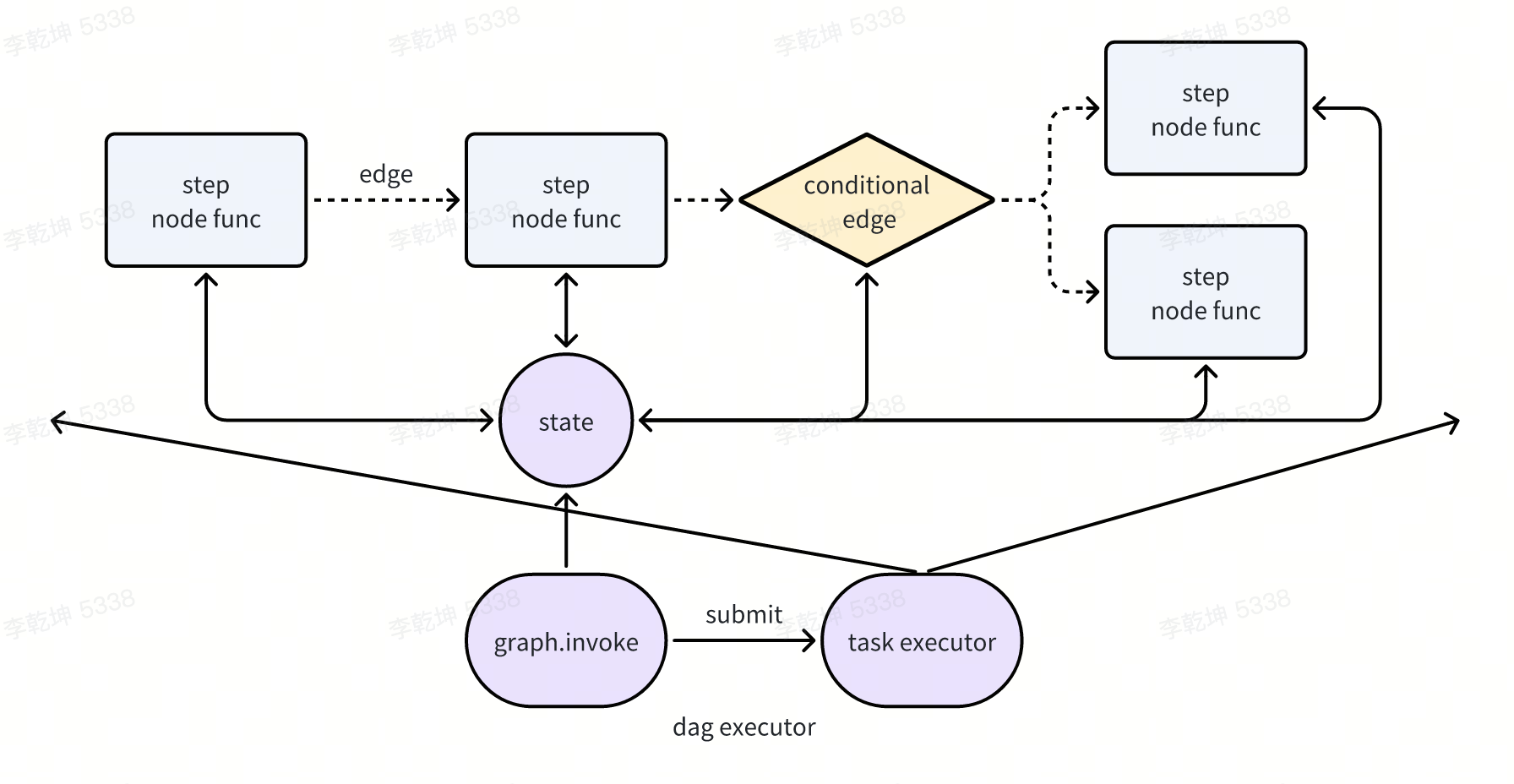
- CompiledGraph 类没正经干什么活儿,主要将点、边加入到了nodes/channels里,核心是父类Pregel在干活儿。触发 CompiledGraph.astream 实质是触发 Pregel.astream/stream。stream的输出是当前step的state的值。
- node 的输入是state,输出是对state的更新。所以langgraph 才提供了prebuilt 将 其它工具转为兼容node的形式。
- Pregel.stream 核心工作是按DAG依次提交node/task并执行,拿到某个node 结果后,更新state值,执行下一个node/conditional_edge。此时Pregel 与一个DAGExecutor 没什么两样。
runtime 和context
LangGraph Run
Input ---------> Graph ---------> Node ---------> Node ---------> Output
│
│
RunnableConfig
(runtime control plane)
LangGraph ≈ 一个“声明式 DAG + 动态运行时注入系统”
- 编译阶段,
graph = workflow.compile(), 这一步只是定义“结构与依赖关系”(DAG 拓扑、边、node 名称),它是一个 纯描述性的编排对象,没有携带任何运行时数据。compile 阶段没有 state,也没有 runtime;所有 node 仅仅是“函数定义引用”,不会执行;节点所需的所有数据,都要在 invoke 阶段注入。PS:control flow - invoke阶段,数据注入的唯一入口:
graph.invoke(input_state={"query": "AI policy"}, context=my_context, config=my_config,)。一个node 的运行需要很多数据,一些数据可以从state 传入(和写入),但类似db/redis client无法被序列化,于是又提出 context 负责承载长期依赖(连接、LLM、缓存、logger 等);所有 node 共用同一个 context;runtime 自动持有对 context 的引用。PS:data flowdef node_func(state, runtime, config) 1. 读写 state(流转数据) 2. 访问 runtime.context(DB/LLM等资源) - 节点函数(node_func)到底能有很多入参形式
def node_func(state)state 来自graph.invoke(input_state)def node_func(context:langgraph.types.RunContext)context 自动封装 (包含 state/runtime/config)def node_func(context, **state)context 自动封装,state 解包def node_func(state, runtime, config)三者分别由 runtime 注入, 语义最清晰、类型最安全、可并行, 最接近 runtime 底层逻辑。def node_func(state, runtime)runtime/context 部分注入def node_func()无注入 常用于起始节点或初始化任务def node_func(state, **kwargs), state + 其他参数(来自 invoke), 不建议
LangGraph 完整执行生命周期
graph.compile()
↓
graph.ainvoke(input_state, context, config)
↓
Runtime(graph, context, config)
↓
state = copy.deepcopy(input_state)
↓
┌─────────────────────────────────────────────┐
│current_nodes = [graph.START] |
|while current_nodes: │
│ node = graph.get_node(name) │
│ snapshot = runtime.state_snapshot() │
│ result = await execute_node(node) │
│ runtime.merge_state(result) │
│ next_nodes = handle_result(result) │
│ current_nodes.extend(next_nodes) │
└─────────────────────────────────────────────┘
↓
return runtime.state # 最终输出
await graph.ainvoke(
input_state={"query": "AI policy"},
context=my_context,
config=my_config,
)
初始化阶段(Invoke / Runtime 构造)
async def ainvoke(graph, input_state, context, config):
# Step 1: 初始化 runtime
runtime = Runtime(
graph=graph,
context=context,
config=config,
)
# Step 2: 初始 state 拷贝
runtime.state = copy.deepcopy(input_state)
# Step 3: 调度入口
return await runtime.run()
Runtime 主调度循环
class Runtime:
async def run(self):
# 初始化节点队列
current_nodes = [self.graph.START]
visited = set()
while current_nodes:
node_name = current_nodes.pop(0)
node = self.graph.get_node(node_name)
# 获取当前节点的 state 快照
state_snapshot = self.state_snapshot()
# 执行节点函数
try:
result = await self.execute_node(node, state_snapshot)
except Exception as e:
# 广播错误事件,可用于 tracing
await self.handle_error(node, e)
raise e
# 结果可能是 dict 或 Command
next_nodes = await self.handle_result(node, result)
visited.add(node_name)
# 合并 state
self.merge_state(result)
# 推入下一个节点(可能多个)
for next_node in next_nodes:
if next_node not in visited:
current_nodes.append(next_node)
# 返回最终状态
return self.state
execute_node(节点执行阶段),每一步执行:
- 取当前 state
- 执行一个 node(函数)
- 得到 state_delta
- merge → 新 state
- 决定下一个 node
async def execute_node(self, node, state):
# 1️⃣ 分析函数签名
sig = inspect.signature(node.func)
# 2️⃣ 构造 RunContext(若需要)
if "context" in sig.parameters:
ctx = RunContext(state=state, runtime=self, config=self.config)
# 3️⃣ 动态调度调用
if {"state", "runtime", "config"} <= sig.parameters.keys():
output = await node.func(state, self, self.config)
elif "context" in sig.parameters:
output = await node.func(ctx)
elif "state" in sig.parameters:
output = await node.func(state)
else:
output = await node.func()
# 4️⃣ 输出类型检查
if not isinstance(output, (dict, Command, Return)):
raise TypeError(f"Invalid node output: {output}")
return output
结合Agent 设计
def node_func1(state, runtime, config):
# 读写 state(流转数据)
# 访问 runtime.context(DB/LLM等资源)
def node_func2(state, runtime, config):
# 读写 state(流转数据)
# 访问 runtime.context(DB/LLM等资源)
workflow = StateGraph(xxState)
workflow.add_node(node_func1)
workflow.add_node(node_func2)
graph = workflow.compile()
graph.ainvoke(input_state=args, context=xx)
我们一般不单独按上述代码过程式的使用langgraph,往往将其封装为一个Agent
class BaseAgent:
parameter1
parameter2
runnable
def __init__(self):
self.parameter1 = ...
self.parameter2 = ...
self.build_runnable()
def build_runnable(self):
workflow = StateGraph(xxState)
workflow.add_node(xx)
self.runnable = workflow.compile()
async def run(self, args):
await self.runnable.ainvoke(input_state=args, context=xx)
node_func 执行需要各种参数(依赖,数据依赖,资源依赖) 便有了三种层级 ||生命周期|放置内容| |—|—|—| |Agent-level|常驻|agent 的静态配置、构造参数、策略参数,生命周期长,构建时就确定;不随每次调用变化| |Context-level|可跨多次 run|DB/Redis client、LLM client、缓存、工具集、logger,尤其是不可序列化的参数| |State-level|每次 run 独立|(可序列化的)用户输入、查询内容、中间结果、输出结果|
HITL/human in the loop
一文讲透AI Agent开发中的human-in-the-loop 。实现human-in-the-loop技术因素:
- 分布式。生产环境都不止一台服务器,a server 发起了hitl,client 把这个feedback发送回server端,由于server端有多个服务器节点,一般来说,来自client端的网络请求会被随机分配到某个服务器节点上。这样就会导致,来自client的feedback信息,未必会落在当初发起human-in-the-loop请求的节点A上;同时,节点A由于收不到feedback而没法把human-in-the-loop继续下去。
- 用户和AI Agent之间的通道性质。
这要求
- client端和server端之间具备长连接的条件,且能够做到会话保持的。这种实现方式对于基础设施存在比较高的要求。
- 对Agent的整个运行状态进行序列化、持久化、反序列化。把一个复杂对象进行序列化和反序列化,不是一件容易的事。难度来源于对象之间的关系:一个复杂的对象,可能引用了其他对象;而其他对象又引用了更多对象;面向对象编程带来的method和对象实例之间的绑定关系,也为序列化和反序列化带来了诸多麻烦。假设仅仅是对于某个数据对象进行序列化和反序列化,情况可能尚在可控范围内。数据对象通常只包含数据字段,数据对象之间的引用关系一般也呈现单向的引用关系。
彻底说清 Human-in-the-Loop实现带有HITL的Agent系统的关键在哪里:流程中断与恢复,以及为了支持它所需要的状态持久化机制。简单说,就是需要一种机制,将流程“挂起”在特定节点(或步骤),等待人类参与和反馈,然后能从中断点恢复运行。这要求系统能够记录中断时的上下文,并确保恢复后状态一致。很显然,你不能使用sleep等待或轮询这种糟糕的阻塞式方案。而LangGraph给出的解决方案是Interrupt(中断)、Command Resume(命令恢复)、Checkpoint(检查点)三大机制。
- Interrupt(中断),即暂停LangGraph工作流的执行,同时返回一个中断数据对象。其中含有给人类的信息,比如需要审核的内容,或者恢复时需要的元数据。典型的处理如下:
from langgraph.types import interrupt, Command ... #这是一个Agent的某个人工参与的节点 def human_review_node(state: State): # 暂停执行,输出需人工审核的数据 review_data = {"question": "请审核以下内容:", "output": state["llm_output"]} decision = interrupt(review_data) # 恢复后将根据人工决策更新状态或跳转 if decision == "approve": return Command(goto="approved_node") else: return Command(goto="rejected_node") ... - Command Resume(恢复),要恢复工作流,需要获得人类反馈并注入工作流状态(State),然后发出继续执行的命令:使用 Command(resume=value) 来反馈并恢复。这个工作通常是调用Agent的客户端来完成,比如:
# 假设 thread_id 标识此次任务,再次调用invoke恢复运行即可 user_decision = "approve" # 这里模拟用户最后的反馈,会变成之前Agent发起的interrupt调用的返回值 result = graph.invoke(Command(resume=user_decision), config={"configurable": {"thread_id": thread_id}}) - Checkpoint(检查点),为了实现“断点续跑”,必须要实现Agent的状态持久化,用来在恢复时“重建现场”。这种机制也有利于Agent发生故障时的轨迹重放。这需要你首先创建一个检查点管理器:
# 初始化 PostgreSQL 检查点保存器 with PostgresSaver.from_conn_string("postgresql://postgres:yourpassword@localhost/postgres?sslmode=disable") as checkpointer: checkpointer.setup() graph = builder.compile(checkpointer=checkpointer)
原理解析与注意点
- Interrupt的本质是什么?为什么它可以中断?原因很简单,因为它就是丢出了一个异常(Exception),异常信息就是中断时送出的数据。所以在发起Interrupt调用时不要做自定义异常捕获,否则可能无法中断。
- “断点续跑”只是从中断的node重新开始执行整个节点,并不是从Interrupt函数调用处那一行代码开始!所以不要在这个节点的Interrupt之前做改变状态(State)的动作!任何位于
interrupt()调用之前的、具有副作用的操作(如 API 调用、数据库写入)都会被重复执行。如果可能,尽量让人工节点只负责处理中断。PS:node粒度断点恢复,node内代码重复执行。 - 要有唯一的ID标识一次工作流运行过程。“断点续跑”依赖于首次Agent调用时的thread_id,所以如果需要处理HITL,就需要提供该信息。因为Checkpointer需要借助它做检查点,而恢复运行时则需要提供相同的thread_id来让Checkpointer找到对应的检查点。
在理解了这几个注意点后,最后来总结与回顾整个处理过程,以一个本地SDK模式下直接调用Agent的客户端为例:
- 客户端调用invoke启动Agent工作流,指定thread_id和输入信息
- 工组流运行到人工节点的interrupt调用,发生中断,并携带了中断数据
- 中断发生。客户端收到Agent的返回状态,从中发现有中断,则提示用户
- 用户输入反馈后,调用invoke恢复工作流,指定thread_id和resume信息
- 再次进入人工节点,此时由于有resume信息,interrupt函数不会触发中断,interrupt函数直接返回Command(resume=…)提供的信息;流程得以继续运行。至此,一次中断过程处理结束

在LangChain 0.x时代,虽然官方提供的 Human-in-the-Loop 相关 API,但是该 API 设计上较为零散,开发者还需要手动处理很多底层细节(如中断后的状态恢复、决策结果的传递等)。LangChain 1.0 版本带来了全新的 Middleware 架构,这一架构通过统一的拦截层和内置的状态管理机制,彻底改变了 Human-in-the-Loop 的实现方式;其中专门推出的 HumanInTheLoopMiddleware 组件,更是将原本复杂的审批触发逻辑、状态保存与恢复、人机决策交互等功能进行了高度封装,开发者只需通过简单的配置(如指定需要拦截的工具名称、允许的决策类型、审批提示信息等),就能快速实现灵活且可靠的 Human-in-the-Loop 效果,让整个开发过程变得更加优雅且高效。
状态机
LangGraph 本质是:一个可持久化的状态机,而不是一个“函数”。从输出就可以看出来
- LangChain 输出 = 一个值(通常经 OutputParser 处理)
- LangGraph 输出 = 一次状态机运行后的“State”
class State(TypedDict):
messages: list[BaseMessage]
foo: str
result = await graph.ainvoke(input, config)
# 返回的就是
{
"messages": [...],
"foo": "...",
}
# 如果发生了中断返回的是
{
"__interrupt__": [Interrupt(...)]
}
result : AsyncIterator[Event] = await graph.astream_events(version="v2")
async for event in result:
# 每个 event 是一个 dict
{
"event": "on_chat_model_stream",
"name": "model",
"run_id": "...",
"parent_ids": [...],
"data": {...}
}
其它
从llamaindex的代码看,问答链路多种多样(比如RouterQueryEngine/MultiStepQueryEngine等),一种链路是一种queryEngine,每种queryEngine有不同的组件,比如RouterQueryEngine提出了 BaseSelector(可以EmbeddingSingleSelector 也可以是LLMSingleSelector) summarizer(BaseSynthesizer子类) 抽象,有分有合。langchain类似,会提各种xxChain,创建chain的时候也会指定一些抽象,比如xxComprossor(实质就是rerank)但不如llamaindex 明显。
class RouterQueryEngine(BaseQueryEngine):
def __init__( self,
selector: BaseSelector,
query_engine_tools: Sequence[QueryEngineTool],
llm: Optional[LLM] = None,
summarizer: Optional[TreeSummarize] = None,
) -> None:
...
也就是,问答链路复杂了,有多个step, step 如何串成pipeline, spep 之间如何传递数据,此时有几种选择
- 每个组件都遵守比如Runnable 接口(输入输出是dict 或很宽泛的Input/Oupput,也是一种抽象,但这种抽象几乎意义不大),然后串起来。 此时要解决 控制流(分支、循环)以及组件间的参数传递问题。
- 每种链路提出一个抽象
- 控制流:一个抽象固化了问答的先后顺序,比如 RouterQueryEngine/MultiStepQueryEngine。langchain的各种xxChain。
- 组件抽象:具体到链路的每个step也逐步提出一些抽象,比如MultiStepQueryEngine.selector 和 MultiStepQueryEngine.summarizer,selector/summarizer实质都是llm 调用,主要是用的prompt以及附带的入参不同。稍微复杂一点的复用,可以抽象为tool。比如对于MultiStepQueryEngine 链路就是:selector ==> tool ==> selector == tool ==>summarizer。业务开发时,自己手撸方法 子方法,相当于是RouterQueryEngine及BaseSelector 的丐版。
- 参数传递:参数的传递可以通过QueryEngine/XXChain 的成员变量
- langgraph 是一种中间态,复用靠把箭头指向原有链路,一条子链路存在的本身就是一种抽象,信息传递靠GraphState。
框架的作用,很多时候也不是没它不行,框架是一个约束和规范,没有它经常会跑偏。比如使用LangGraph 时大部分需要使用 Langchain 对象才能顺利运行。
留下评论