大模型推理服务框架vLLM
简介
vLLM代码及逻辑介绍 值得细读。
显存管理技术的演进
- 虚拟化与按需分配: PagedAttention在请求长度高度不均、并发持续变化的服务负载下,把“为每个请求随序列增长而扩张的KV Cache”从粗放的预分配,变成可共享、可回收、可迁移的精细化资源,从而同时改善吞吐、TTFT与显存上限。PS:就好比linux即使有内存管理,也会有tcmalloc来提高内存管理效率。
- 结构化复用:在实际应用中,许多推理请求共享相同的前缀(Prefix),例如系统提示词(System Prompt)或多轮对话中的历史记录。SGLang框架引入的RadixAttention进一步扩展了显存管理的维度,它将KV Cache组织成一棵基数树(Radix Tree)。当新的请求到达时,系统会在树中进行最长前缀匹配。如果匹配成功,则直接复用已有的KV Cache,无需重新计算。
- 分层与分布式扩展:尽管PagedAttention优化了单卡显存的使用,但面对超长上下文(如1M+ Token),单机显存依然不足。此时,分层存储(Tiered Storage)成为必然选择。PrisKV和InfiniGen等系统提出将KV Cache卸载(Offload)到宿主内存(Host Memory)甚至NVMe SSD上。为了解决卸载带来的高延迟问题,PrisKV利用了RDMA(Remote Direct Memory Access)技术。通过构建一个分布式的、分层的KV存储池,PrisKV允许GPU直接通过PCIe和网络读取远程节点的内存,绕过CPU的干预。
从PagedAttention开始
图解大模型计算加速系列之:vLLM核心技术PagedAttention原理用KV cache做推理时的一些特点:
- 随着prompt数量变多和序列变长,KV cache也变大,对gpu显存造成压力
- 由于输出的序列长度无法预先知道,所以我们很难提前为KV cache量身定制存储空间。为KV cache分配存储空间的常规方式:当我们的服务接收到一条请求时,它会为这条请求中的prompts分配gpu显存空间,其中就包括对KV cache的分配。由于推理所生成的序列长度大小是无法事先预知的,所以大部分框架会按照(batch_size, max_seq_len)这样的固定尺寸,在gpu显存上预先为一条请求开辟一块连续的矩形存储空间。如果预留了2048长度的显存块,但请求仅生成了50个Token,那么剩余的显存实际上被浪费了,且无法被其他请求利用。
然而,这样的分配方法很容易引起“gpu显存利用不足”的问题,进而影响模型推理时的吞吐量。你会发现它们的毛病在于太过“静态化”。当你无法预知序列大小时,你为什么一定要死板地为每个序列预留KV cache空间呢?为什么不能做得更动态化一些,即“用多少占多少”呢?这样我们就能减少上述这些存储碎片,使得每一时刻推理服务能处理的请求更多,提高吞吐量。你可能会有以下疑问:
- vLLM是通过什么技术,动态地为请求分配KV cache显存,提升显存利用率的?
- 在最原始的做法中,不使用虚拟内存,,程序直接对物理内存进行操作,决定使用它的哪些存储地址。如果你只跑一个进程,那还好说。但如果需要运行多个进程时,麻烦就来了:由于我直接操作了物理内存地址,所以我在为自己的进程分配物理内存时,还要考虑别的进程是如何分配物理内存的(别人已经占用的我不能用)。这样不同进程间的耦合性太高了,给开发带来难度。有没有一种办法,让各个进程间的开发能够相互独立呢?一种直觉的做法是:给每个进程分配一个虚拟内存。每个进程在开发和运行时,可以假设这个虚拟内存上只有自己在跑,虚拟内存负责统一规划代码、数据等如何在物理内存上最终落盘。==> 虚拟内存的分页管理
- 对于相同数据对应的KV cache,能复用则尽量复用(不同request 的逻辑块指向相同的物理块);无法复用时,再考虑开辟新的物理空间(触发物理块copy-on-write机制)。
- 当采用动态分配显存的办法时,虽然明面上同一时刻能处理更多的prompt了,但因为没有为每个prompt预留充足的显存空间(有效地控制了注意力计算期间的内存浪费),如果在某一时刻整个显存被打满了,而此时所有的prompt都没做完推理,那该怎么办?
- 当有一堆请求来到vLLM服务器上时,vLLM需要一个调度原则来安排如何执行这些请求,这个调度原则概括如下:先来的请求先被服务(First-Come-First-Serve, FCFS);如有抢占的需要,后来的请求先被抢占(preemption)。当一堆请求来到vLLM服务器做推理,导致gpu显存不足时,vLLM暂停这堆请求中最后到达的那些请求的推理,同时将它们相关的KV cache从gpu上释放掉,以便为更早到达的请求留出足够的gpu空间,让它们完成推理任务。如果不这样做的话,各个请求间相互争夺gpu资源,最终将导致没有任何一个请求能完成推理任务。等到先来的请求做完了推理,vLLM调度器认为gpu上有足够的空间了,就能恢复那些被中断的请求的执行了。在资源不足的情况下,暂时中断一些任务的执行,这样的举动就被称为“抢占(preemption)”。
实现
- 当有一堆请求来到vLLM服务器上时,vLLM需要一个调度原则来安排如何执行这些请求,这个调度原则概括如下:先来的请求先被服务(First-Come-First-Serve, FCFS);如有抢占的需要,后来的请求先被抢占(preemption)。当一堆请求来到vLLM服务器做推理,导致gpu显存不足时,vLLM暂停这堆请求中最后到达的那些请求的推理,同时将它们相关的KV cache从gpu上释放掉,以便为更早到达的请求留出足够的gpu空间,让它们完成推理任务。如果不这样做的话,各个请求间相互争夺gpu资源,最终将导致没有任何一个请求能完成推理任务。等到先来的请求做完了推理,vLLM调度器认为gpu上有足够的空间了,就能恢复那些被中断的请求的执行了。在资源不足的情况下,暂时中断一些任务的执行,这样的举动就被称为“抢占(preemption)”。
PagedAttention通过额外的元数据即page table(也有叫Block table)管理KV cache,并将该table传入到GPU,由定制的GPU kernel进行attn计算。在kernel内部额外增加了逻辑,进行不连续地址的显存查找、拼接计算和汇总。
vLLM的PA(PagedAttention) kernel虽然用cuda开发,但是其余部分都是pytorch开发,包括Batch调度、模型定义、并行推理等。prefill阶段直接调用xformers处理计算密集的attn计算;decode阶段使用手写CUDA PagedAttention处理访存密集的attn计算。
整体架构
不玩花活儿的LLM Serving
from flask import Flask, request, jsonify
import torch
from transformers import AutoModelForCausalLM, Autotokenizer
app = Flask(__name__)
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3-8B").cuda()
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-3-8B")
@app.route("/generate", methods=["POST"])
def generate():
prompt = request.json["prompt"]
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=512)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return jsonify({"response": response})
高性能 LLM 推理(Serving)核心挑战:如何在有限的 GPU 资源下,高效处理大量动态变化的用户请求?
- 请求的高并发。不能排队等待批量处理
- 请求长短不一。一个请求只需输出 “OK”,另一个却要生成一篇万字小说。短请求不应该该被长请求拖累。
- GPU 算力很强,但极其厌恶被打断(比如等数据)。频繁的上下文切换或不合理的任务分配,会让 GPU 的效率断崖式下跌。 这些问题的本质,其实和构建高性能 Web 服务器(如 Nginx)或操作系统内核(如 Linux 调度器)所面临的挑战高度相似——核心都是在有限资源下,高效、公平、低延迟地调度大量并发任务。Nginx 通过事件驱动和异步 I/O 避免线程阻塞;Linux 内核通过 CFS(完全公平调度器)动态分配 CPU 时间片;而 vLLM 则必须在 GPU 这个更“敏感”的硬件上(长期驻守 GPU),持续接收请求,并在毫秒级时间内决定“此刻该让谁用 GPU”:最大化吞吐量,最小化延迟波动。
LLM Serving 的核心挑战不在于模型调用的“通”,而在于大规模并发下的计算编排(Orchestration)。
vLLM 三层架构,解耦了 Web 接入、逻辑调度与算力执行。
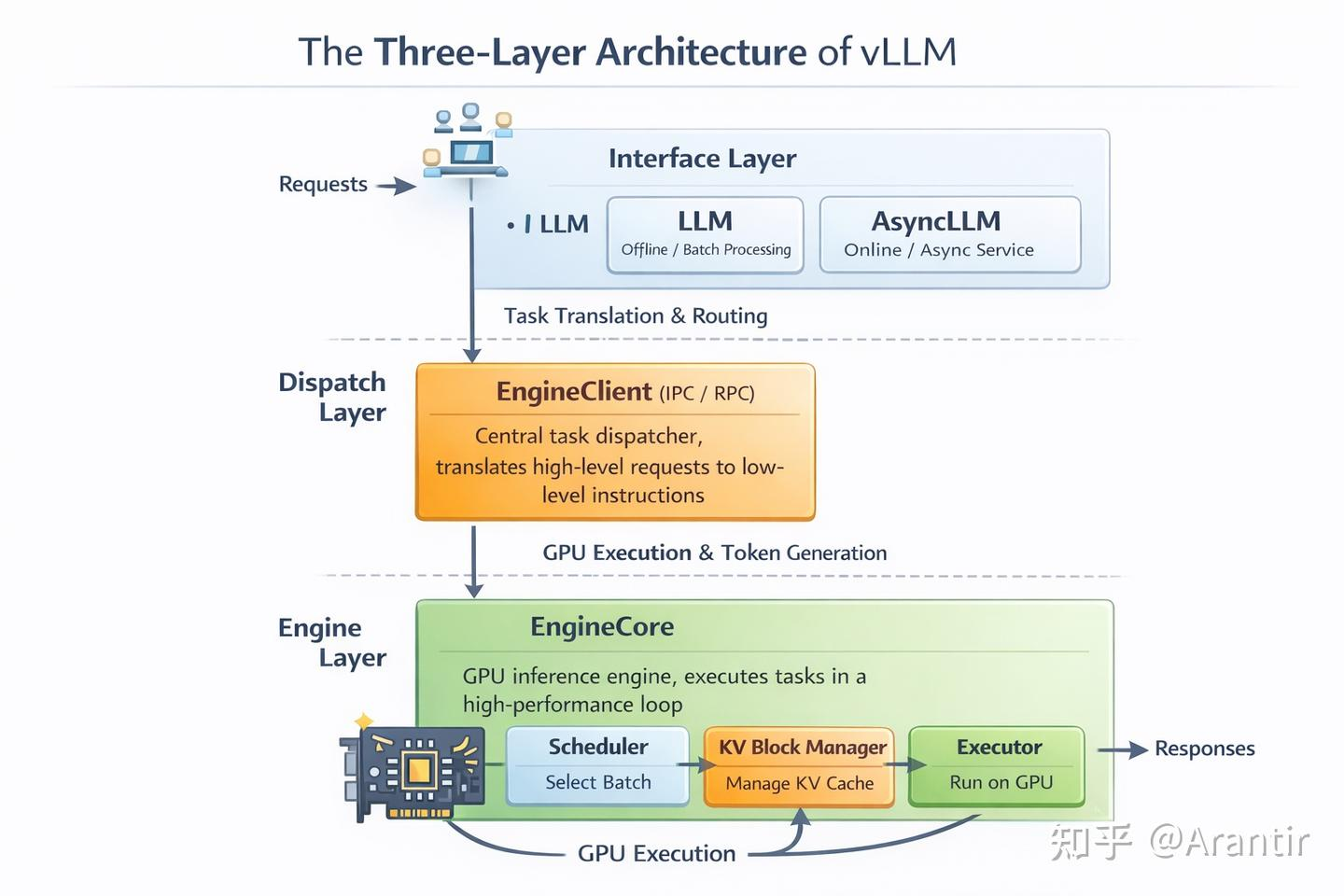
- 接口层 ,LLM离线批处理,AsyncLLM(在线服务驱动),它把同步的请求转化为异步的任务流,让 CPU 在等待 GPU 推理时,可以腾出手去处理成千上万个并发连接。
- 分发层 (EngineClient / IPC / RPC)负责将请求准确地送达正确的 Engine Core。它通过进程间通信(本地 IPC),把 LLM/AsyncLLM 接收到的高层请求(prompt、sampling 参数、request_id),翻译为具体 Engine Core 能执行的指令,并维护请求在多个 GPU 进程间的一致性与生命周期。它决定:这个请求该发给 哪个 Engine Core 进程;是否需要 跨多个 GPU 进程协同。让“接单的 CPU 进程”和“干活的 GPU 进程”彻底解耦。
- 核心引擎层。Engine Core 是一个长期运行的 GPU 推理进程,它独占一份模型权重与显存空间,持续在内部的 step loop 中执行推理。在实际部署中,系统通常会启动多个 EngineCore 实例——每个实例作为一个独立的 CPU 进程运行,并绑定到一组固定的 GPU 设备(例如单卡、多卡张量并行组)。这些实例可以部署在同一台机器的不同 GPU 上,也可以分布到多个服务器节点(配合 RPC 通信),从而实现横向扩展。
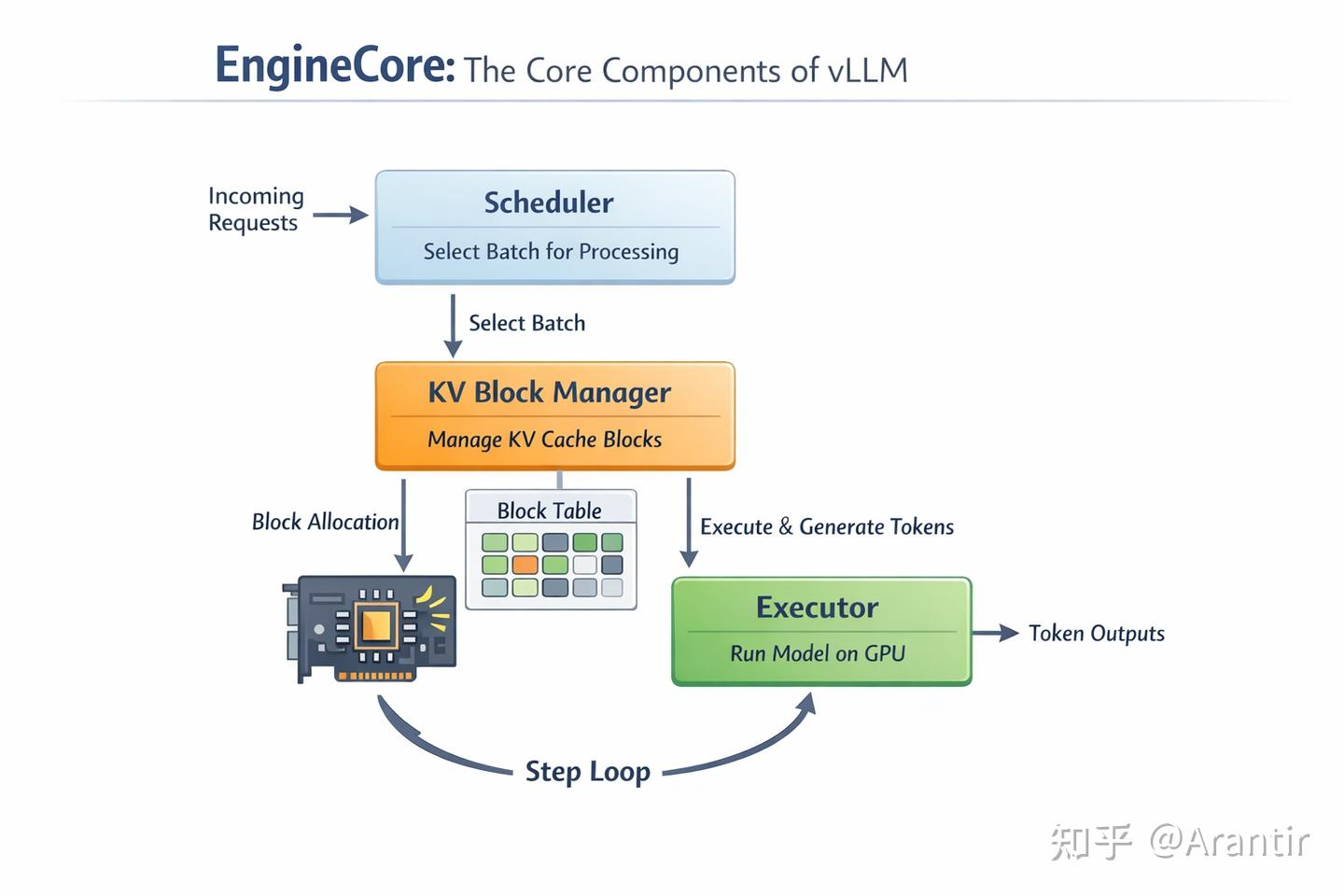 在每一次 step 中,EngineCore 按固定顺序协调三个核心组件:
在每一次 step 中,EngineCore 按固定顺序协调三个核心组件:
- 调度器(Scheduler)决定哪些request能进入本轮推理的batch。决策主要基于每个请求已计算的 token 数、请求的目标 token 数、KV 缓存块的可用性。当显存块不足时,Scheduler 会抢占(preempt)最低优先级的请求,释放其占用的 KV 缓存块以保证系统能继续向前推进。对于长请求:通过 chunked prefill 机制分块推进,避免一次性占用过多显存资源。Scheduler 不关心“文本含义”,只关心 token 进度 + 显存水位 + 系统是否能继续跑下去。
- 执行器(Executor)真正触碰 GPU 硬件,接收 Scheduler 给出的 batch 计划,使用 KVCacheManager 提供的缓存映射,在 GPU 上执行推理。执行实际的模型推理计算:加载模型权重,调度 CUDA 算子,在 GPU 上完成 attention、MLP 等核心运算。Executor 不做决策,只负责 把“这一轮该算什么”高效地算出来。
- KV Cache 管理器则负责显存中缓存的读写与复用。 整个流程高度优化,目标是让 GPU 计算单元尽可能持续满载。
请求调度
vLLM V1 Scheduler的调度逻辑&优先级分析 未读。
由于像GPU 这样的加速器具有大量的并行计算单元,推理服务系统通常会对作业进行批处理,以提高硬件利用率和系统吞吐量。启用批处后,来自多个作业的输入会被合并在一起,并作为整体输入模型。但是此前推理服务系统主要针对确定性模型进行推理(LLM输出长度未知,使得一个推理任务总执行时间未知),它依赖于准确的执行时间分析来进行调度决策,而这对LLM并不适用。此外,批处理与单个作业执行相比,内存开销更高,因此LLM的尺寸限制了其推理的最大批处理数量。传统的作业调度将作业按照批次运行,直到一个批次中的所有作业完成,才进行下一次调度,这会造成提前完成的作业无法返回给客户端,而新到达的作业则必须等当前批次完成。因此提出 iteration-level 调度策略,在每次批次上只运行单个迭代,即每个作业仅生成一个token。每次迭代完成后,完成的作业可以离开批次,新到达的作业可以加入批次。
vLLM(二)架构概览 图解大模型计算加速系列:vLLM源码解析1,整体架构 Offline Batched Inference
from vllm import LLM, SamplingParams
prompts = ["Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",]
# 采样参数
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
# 初始化vLLM offline batched inference实例,并加载指定模型
llm = LLM(model="facebook/opt-125m")
# 推理
outputs = llm.generate(prompts, sampling_params)
# 对每一条prompt,打印其推理结果
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
LLM 是对 LLM serving 部分的封装,也是核心部分。首先它会初始化这个类。初始化过程中大部分参数都会被用来构造 EngineArgs,这是一个 dataclass,封装了 Engine 的初始化参数。然后构建 LLM Engine。一个 LLM 只有一个 LLM Engine,所以它就是对 Engine 再包一层。不过按照作者的这个设计意思,LLM Engine 也可以单提出来使用。初始化 LLM Engine 时候会先调用 create_engine_configs 将EngineArgs分解成ModelConfig,CacheConfig, ParallelConfig和SchedulerConfig。然后对于每个 device(也即每张卡 / 每个 rank)创建一个 Worker。Worker 是运行 model 的单位。一个 Engine 管理所有的 workers。同时给这个 engine 创建它的 scheduler,以及初始化这个 engine 的 KV cache。
从 llm engine 的 add request开始,在 Sampling 设置中有一个 best_of 参数,它指定了每个 prompt 我们生成多少个 output sequences。在使用 beam search 时候这个参数也作为 beam width。所以对每个 request,我们就需要构造 best_of 个 Sequence。每个 Sequence 就是对应一个从 prompt 生成出来的完整语句。这些个 Sequence 组成一个 SequenceGroup,也就是从粒度上一个 request 对应一个 seq group。构造 Sequence 的时候会给这个 Sequence 分配相应的 logical token blocks。一个 logical blocks 对应 block_size 个 token ids。初始化的时候会把 token ids 分段存储在 logical blocks 中,最后一个 block 可能不满。
构造好 seq group 后就会把它添加到 scheduler 的 waiting 队列里。Scheduler 内部维护了三个队列:waiting,running 和 swapped,分别对应三种 STATE。队列里的元素都是 SequenceGroup。此外,一个 scheduler 还包含一个 BlockSpaceManager,它用来管理 logical blocks 和 physical blocks 之间的映射关系。然后就是 Scheduler 的关键接口 schedule。现在它只有一个 policy:FCFS(先来先服务)。
- 首先,它会把 runnning 队列里的每个 seq group 都弹出来,然后 check 目前的 free blocks 数是否够塞得下。 如果不行,则它会 preempt running 队列中优先级最低的 seq group(如果此时队列里没有其它 seq group,则 preempt 自己)。如果空间够的话,则会对这个 seq group allocate 相应的 physical blocks,然后将其放入 update 后的 running 队列中。经过这个过程,scheduler 在新的内存状态下更新了 running 队列,并把部分任务 preempt 掉。
- 然后 scheduler 会过一遍 swapped 队列,尝试 swap in 那些能够 swap 的 seq group,并把它们放到新的 running 队列中。
- 接下来是 waiting 队列。在 scheduler 中, SWAPPED 状态严格优先于 WAITING 状态,这是因为我们想 bound 那些 swapped 队列占据的 CPU 内存。这个 scheduler 会尝试将不超过 max_num_seqs 数量的 seq_group 转为 running(包括分配相应的 blocks)。这些做完会把相应的信息(swap in/out 的 blocks,blocks copy)塞进 scheduler output 里供后面的执行单元实使用。 总结来说,Scheduler 每次调用 schedule 都会把上个时刻的这三个队列往下一个时刻进行一次更新。按照优先级顺序:首先它优先保证 running 队列继续运行,其次它尝试将 swapped 的任务 swap out 回来,如果没有可用的 swapped 队列则会尝试将 waiting 队列中的任务放到 running。
在传统离线批处理中,我们每次给模型发送推理请求时,都要等一个batch的数据齐全后,一起发送;整个batch的数据一起做推理;等一个batch的数据全部推理完毕后,一起返回推理结果。这种“团体间等成员到齐,再一起行动”的行为,就被称为“同步”。但推理内核引擎(LLMEngine)在实际运作时,batch_size是可以动态变更的:在每一个推理阶段(prefill算1个推理阶段,每个decode各算1个推理阶段)处理的batch size可以根据当下显存的实际使用情况而变动(vLLM会用自己的调度策略从waiting队列中依次取数,加入running队列中,直到它认为取出的这些数据将会打满它为1个推理阶段分配好的显存。此时waiting队列中可能还会剩一些数据)。但将LLMEngine包装成离线批处理形式后,所有的数据必须等到一起做完推理才能返给我们。所以从体感上,我们可能很难感知到内核引擎的“动态”逻辑。
也正是因为LLMEngine这种“动态处理”的特性,才使得它同时也能成为异步在线服务的内核引擎:当一条条请求发来时,它们都先进入LLMEngine调度器(Scheduler)的waiting队列中(实际并不是直接进入waiting队列中的,而是在传给LLMEngine前先进入asyncio.Queue()中,然后再由LLMEngine调度进waiting队列中的,这些细节我们也放在后面说,这里不影响理解就行)。此时模型正常执行它的1个推理阶段,调度器也正常处理新来的请求。当模型准备执行下1个推理阶段时,调度器再根据设定的策略,决定哪些数据可以进入running队列进行推理。由于在线服务是异步的,先推理完成的数据就可以先发给客户端了(如果采用流式传输,也可以生成多少先发多少)。vLLM在实现在线服务时,采用uvicorn部署fastapi app实例,以此实现异步的请求处理。而核心处理逻辑封装在AsyncLLMEngine类中(它继承自LLMEngine)。所以,只要我们搞懂了LLMEngine,对vLLM的这两种调用方式就能举一反三了。
vLLM对请求的调度处理流程:
- 当一堆请求来到vLLM服务器上时,按照First-Come-First-Serve(FCFS)原则,优先处理那些最早到来的请求。
- 当gpu资源不足时,为了让先来的请求能尽快做完推理,vLLM会对那些后到来的请求执行“抢占”,即暂时终止它们的执行。
- 一旦vLLM决定执行抢占操作,它会暂停处理新到来的请求。在此期间,它会将被抢占的请求相关的KV block全部交换(swap)至cpu上。等交换完成后,vLLM才会继续处理新到来的请求。
- 当vLLM认为gpu有足够资源时,它会将cpu上的KV block重新加载回gpu,恢复被抢占请求的执行(recomputation)
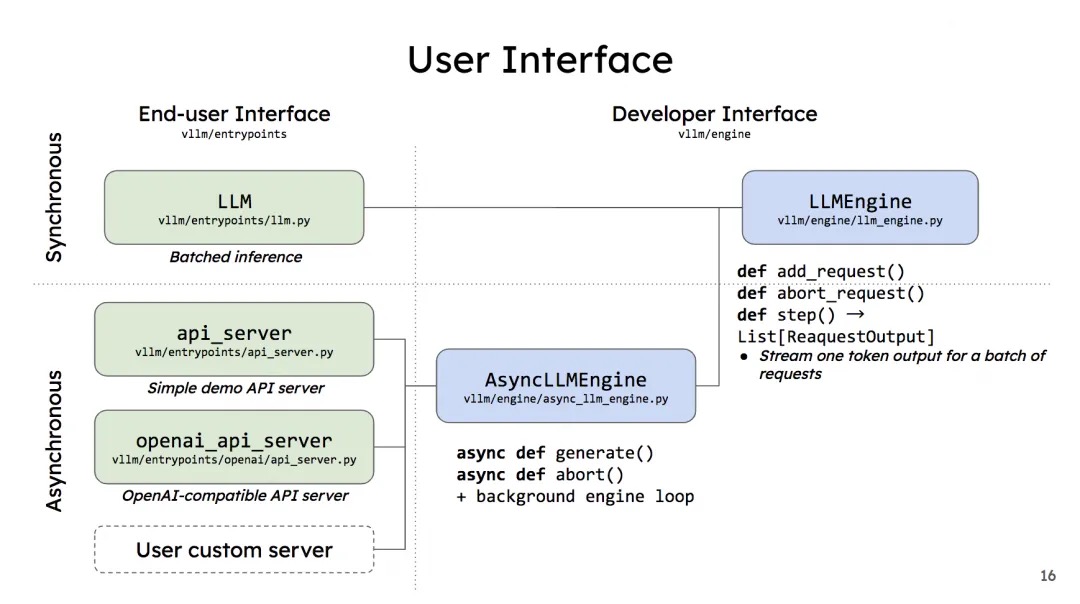
vLLM的两种调用方式与内核引擎LLMEngine的关系如下。
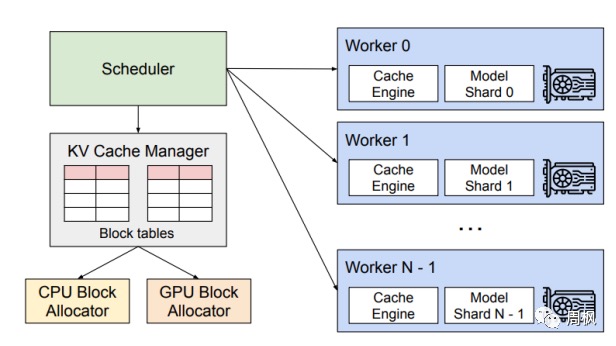
对于多gpu,vLLM是怎么处理的呢?
- 首先,vLLM有一个中央调度器(Scheduler),它负责计算和管理每张卡上KV cache从逻辑块到物理块的映射表(block tables)
- 在做分布式计算时,Schedular会将映射表广播到各张卡上,每张卡上的Cache engine接收到相关信息后,负责管理各卡上的KV block。 上图中给出的例子,是用张量模型并行(megatron-lm)做分布式推理时的情况,所以图中每个worker上写的是model shard。在张量并行中,各卡上的输入数据相同,只是各卡负责计算不同head的KV cache。所以这种情况下,各卡上的逻辑块-物理块的映射关系其实是相同的(用的同一张block table),只是各卡上物理块中实际存储的数据不同而已。
源码
目前,主流 LLM 推理框架 Continuous batching 的实现都是借鉴论文 Orca: A Distributed Serving System for Transformer-Based Generative Models 而来, Continuous batching 更是在 vLLM 的推动下已成为 LLM 推理框架标准功能。只是不同框架实现有差别,主要体现在对prefill处理的方式上。将prefill单独处理还是和decoding融合,以什么样的粒度融合,有一些讲究。ORCA的系统架构包括请求池、调度器和执行引擎。调度器负责从请求池中选择请求,执行引擎则负责执行模型的迭代。
在vLLM中,通过 LLM 引擎类 LLMEngine 接收请求并生成文本。它接收来自客户端的请求并从 LLM 生成文本。它包括一个分词器、一个语言模型(可能分布在多个 GPU 上)以及为中间状态分配的 GPU 内存空间(或称为 KV Cache)。该类利用迭代级调度和高效的内存管理来最大化服务的吞吐量。而每一次迭代级调度都是在 step() 方法中完成,即完成一次推理过程(整个prefill阶段算1个次推理,decode阶段每迭代生成一个Token算1次推理)。
vllm
/attention
/core
/block
/block_manager_v1.py
/evictor_v1.py
/scheduler.py
/distributed
/engine
/openai
/api_server.py
/llm.py
/entrypoints
/executor # 模型执行
不难发现LLMEngine是vLLM的核心逻辑。有几个函数
- add_request():该方法将每一个请求包装成vLLM能处理的数据类型SequenceGroup,并将其加入调度器(Scheduler)的waiting队列中。
- abort_request:在推理过程中,并不是所有的请求都能有返回结果。比如客户端断开连接时,这个请求的推理就可以终止了(abort),这个函数就被用来做这个操作。
入口
图解大模型计算加速系列:vLLM源码解析2,调度器策略(Scheduler)
class LLM:
def __init__(self,model,tokenizer,quantization,...) -> None:
engine_args = EngineArgs(...)
self.llm_engine = LLMEngine.from_engine_args(engine_args, usage_context=UsageContext.LLM_CLASS)
...
def generate(self,prompts,sampling_params,...)-> List[RequestOutput]:
# 将输入数据传给LLMEngine
self._validate_and_add_requests( inputs=inputs,params=sampling_params,lora_request=lora_request,)
# 执行推理
outputs = self._run_engine(use_tqdm=use_tqdm)
return LLMEngine.validate_outputs(outputs, RequestOutput)
def _add_request(self,inputs,params,lora_request,...) ) -> None:
# 在vLLM内核运算逻辑中,1个prompt算1个request,需要有1个全局唯一的request_id
request_id = str(next(self.request_counter))
self.llm_engine.add_request(request_id,inputs,params,lora_request=lora_request)
def _run_engine(self,...):
outputs: List[Union[RequestOutput, EmbeddingRequestOutput]] = []
while self.llm_engine.has_unfinished_requests():
step_outputs = self.llm_engine.step()
for output in step_outputs:
if output.finished:
outputs.append(output)
return sorted(outputs, key=lambda x: int(x.request_id))
所以,想要知道调度器的运作流程,我们只要从LLMEngine的add_request()和step()两个函数入手就好了。
class LLMEngine:
def __init__( self,model_config,cache_config,parallel_config,scheduler_config,device_config,...) -> None:
self.model_executor = executor_class(...)
...
def _add_processed_request(self,request_id,processed_inputs,...)
block_size = self.cache_config.block_size
seq_id = next(self.seq_counter)
eos_token_id = self._get_eos_token_id(lora_request)
seq = Sequence(seq_id, processed_inputs, block_size, eos_token_id, lora_request)
# 把每1个prompt包装成一个SequenceGroup对象
seq_group = self._create_sequence_group_with_xx(...)
min_cost_scheduler = self.scheduler[costs.index(min(costs))]
# 把包装成SequenceGroup对象的数据加入调度器(Scheduler)的waiting队列,等待处理。
min_cost_scheduler.add_seq_group(seq_group)
add_reques/SequenceGroup
为什么要把每个prompt都包装成一个SequenceGroup实例?SequenceGroup又长什么样呢?
- 在一般的推理场景中,我们通常给模型传1个prompt及相关的采样参数,让模型来做推理。此时你的输入可能长下面这样:
("To be or not to be,",SamplingParams(temperature=0.8, top_k=5, presence_penalty=0.2))。 - 但在其余的场景中,模型decoding的策略可能更加复杂,例如:
- Parallel Sampling:你传给模型1个prompt,希望模型基于这个prompt,给出n种不同的output
("What is the meaning of life?", SamplingParams(n=2, temperature=0.8, top_p=0.95, frequency_penalty=0.1)) - Beam Search:你传给模型1个prompt,在采用Beam Search时,每个推理阶段你都会产出top k个output,其中k被称为Beam width(束宽)
("It is only with the heart that one can see rightly", SamplingParams(n=3, best_of=3, use_beam_search=True, temperature=0.0)),总结来说,可能出现”1个prompt -> 多个outputs”的情况。那是否能设计一种办法,对1个prompt下所有的outputs进行集中管理,来方便vLLM更好做推理呢?一个seq_group中的所有seq共享1个prompt。”1个prompt -> 多个outputs”这样的结构组成一个SequenceGroup实例,其中每组”prompt -> output”组成一个序列(seq,属于Sequence实例),每个seq下有若干状态(status)属性。我们来通过一个具体的例子,更好感受一下SequenceGroup的作用:
- Parallel Sampling:你传给模型1个prompt,希望模型基于这个prompt,给出n种不同的output
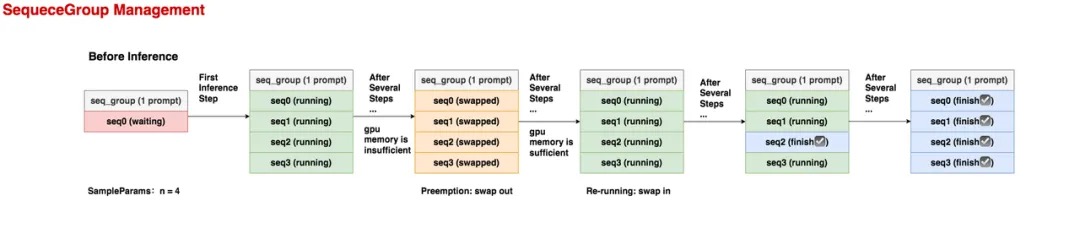
- 在推理开始之前,这个seq_group下只有1条seq,它就是prompt,状态为waiting。
- 在第1个推理阶段,调度器选中了这个seq_group,由于它的采样参数中n = 4,所以在做完prefill之后,它会生成4个seq,它们的状态都是running。
- 在若干个推理阶段后,gpu上的资源不够了,这个seq_group不幸被调度器抢占(preemption),它相关的KV block也被swap out到cpu上。此时所有seq的状态变为swapped。这里要注意,当一个seq_group被抢占时,对它的处理有两种方式:
- Swap:如果该seq_group下的seq数量 > 1,此时会采取swap策略,即把seq_group下【所有】seq的KV block从gpu上卸载到cpu上。(seq数量比较多,直接把算出的KV block抛弃,比较可惜)
- Recomputation:如果该seq_group下的seq数量 = 1,此时会采取recomputation策略,即把该seq_group相关的物理块都释放掉,然后将它重新放回waiting队列中。等下次它被选中推理时,就是从prefill阶段开始重新推理了,因此被称为“重计算”。(seq数量少,重新计算KV block的成本不高)
- 又过了若干个推理阶段,gpu上的资源又充足了,此时执行swap in操作,将卸载到cpu上的KV block重新读到gpu上,继续对该seq_group做推理,此时seq的状态又变为running。
- 又过了若干个推理阶段,该seq_group中有1个seq已经推理完成了,它的状态就被标记为finish,此后这条已经完成的seq将不参与调度。
- 又过了若干个推理阶段,这个seq_group下所有的seq都已经完成推理了,这样就可以把它作为最终output返回了。
class SequenceGroup:
def __init__(self,request_id,seqs,...) -> None:
self.request_id = request_id
self.seqs_dict = {seq.seq_id: seq for seq in seqs} # 其中每个seq是一个Sequence对象。
self.sampling_params = sampling_params # 采样参数
# 该seq_group在剩余生命周期内并行running的最大seq数量。
def get_max_num_running_seqs(self) -> int:
...
class Sequence:
"""Stores the data, status, and block information of a sequence. """
def __init__(self,seq_id,inputs,block_size,eos_token_id,...)-> None:
...
# 1个Sequence实例下维护着属于自己的逻辑块列表
self.logical_token_blocks: List[LogicalTokenBlock] = []
# Initialize the logical token blocks with the prompt token ids.
self._append_tokens_to_blocks(self.prompt_token_ids)
...
def _append_tokens_to_blocks(self, token_ids: List[int]) -> None:
cursor = 0
while cursor < len(token_ids):
if not self.logical_token_blocks:
self._append_logical_block()
last_block = self.logical_token_blocks[-1]
if last_block.is_full():
self._append_logical_block()
last_block = self.logical_token_blocks[-1]
num_empty_slots = last_block.get_num_empty_slots()
last_block.append_tokens(token_ids[cursor:cursor +num_empty_slots])
cursor += num_empty_slots
def _append_logical_block(self) -> None:
block = LogicalTokenBlock(block_number=len(self.logical_token_blocks),block_size=self.block_size,)
self.logical_token_blocks.append(block)
# 计算一个逻辑块的hash值,是对文本内容的hash
def hash_of_block(self, logical_idx: int) -> int:
当一个seq只有prompt时,这个方法负责给prompt分配逻辑块;当这个seq开始产出output时,这个方法负责给每一个新生成的token分配逻辑块
step():调度器策略
LLMEngine 的step方法
- 调用 scheduler 的schedule方法选择要处理的 sequence group 列表。在 _schedule 结束后 scheduler 还会对 schedule 出来的结果进行一次封装,包装成 SequenceGroupMetadata,然后再通过 prepare input 转成 tokens_tensor,position_tensor 和 InputMetadata。这个转换过程中 Group 这层抽象会被褪开,batch_size 变成 sequence 的个数(一般来说,就是 seq groups 个数 * beam_width)。
- 调用 worker 的execute_model方法推理 sequence group
- 调用_process_model_outputs方法完成模型输出的后处理 先从 scheduler 获取本次要作为输入的 seq_group_metadata_list ,同时产生一个 scheduler_outputs 和 ignored_seq_groups。然后 engine 会调用 workers 的 execute_model。
在1个推理阶段中,调度器是通过什么策略来决定要送哪些seq_group去做推理的?
class LLMEngine:
def step(self) -> ...:
seq_group_metadata_list, scheduler_outputs = self.scheduler.schedule()
if not scheduler_outputs.is_empty():
execute_model_req = ExecuteModelRequest(seq_group_metadata_list,blocks_to_swap_in,blocks_to_swap_out,...)
output = self.model_executor.execute_model(execute_model_req=execute_model_req)
else:
output = []
request_outputs = self._process_model_outputs(output,scheduler_outputs.scheduled_seq_groups,...)
...
return request_outputs
class Scheduler:
def __init__( self,scheduler_config,cache_config,lora_config,...)-> None:
...
BlockSpaceManagerImpl = BlockSpaceManager.get_block_space_manager_class(version)
# 物理块管理器,有v1、v2等版本
self.block_manager = BlockSpaceManagerImpl(block_size=...,num_gpu_blocks,num_cpu_blocks,...)
self.waiting: Deque[SequenceGroup] = deque() # 存放所有还未开始做推理的seq_group
self.running: Deque[SequenceGroup] = deque() # 存放当前正在做推理的seq_group
self.swapped: Deque[SequenceGroup] = deque() # 存放被抢占的seq_group
def add_seq_group(self, seq_group: SequenceGroup) -> None:
# Add sequence groups to the waiting queue.
self.waiting.append(seq_group)
- waiting队列中的数据都没有做过prefill,每个seq_group下只有1个seq(prompt)
- running队列中存放着上一个推理阶段被送去做推理的所有seq_group。
- swapped队列中存放着之前调度阶段中被抢占的seq_group running队列中的seq_group不一定能继续在本次调度中被选中做推理,这是因为gpu上KV cache的使用情况一直在变动,以及waiting队列中持续有新的请求进来的原因。所以调度策略的职责就是要根据这些变动,对送入模型做推理的数据做动态规划。
在1次推理中,所有seq_group要么一起做prefill(来自running队列),要么一起做decode(来自running + swapped队列)。先做哪个呢?
- 以swapped是否非空为判断入口。如果当前调度步骤中swapped队列非空,说明在之前的调度步骤中这些可怜的seq_group因为资源不足被抢占,而停滞了推理。所以根据FCFS规则,当gpu上有充足资源时,我们应该先考虑它们,而不是考虑waiting队列中新来的那些seq_group。
- waiting队列是否达到调度间隔阈值。在做推理时,waiting队列中是源源不断有seq_group进来的,一旦vLLM选择调度waiting队列,它就会停下对running/swapped中seq_group的decode处理,转而去做waiting中seq_group的prefill,也即vLLM必须在新来的seq_group和已经在做推理的seq_group间取得一种均衡:既不能完全不管新来的请求,也不能耽误正在做推理的请求。所以“waiting队列调度间隔阈值”就是来控制这种均衡的。PS:将Prefill和Decode阶段放在同一个 GPU 上处理,优先prefill 会导致TPOT(每个输出 Token 的时间)增加。反之,如果优先解码,TTFT(首次 Token 时间)也会增加。
- 调度间隔设置得太小,每次调度都只关心waiting中的新请求,这样发送旧请求的用户就迟迟得不到反馈结果。且此时waiting队列中积累的新请求数量可能比较少,不利于做batching,浪费了并发处理的能力。
- 调度间隔设置得太大,waiting中的请求持续挤压,同样对vLLM推理的整体吞吐有影响。
- 内存空间是否充足?
- 如果决定调度 waiting队列的seq_group,从waiting中取出一个seq_group,必须先判断:gpu上是否有充足的空间为该seq_group分配物理块做prefill(给每个seq分配若干个token的位置),判断的入口代码为
can_allocate = self.block_manager.can_allocate(seq_group) - 从running队列中调度seq_group时,我们也会判断是否能为该seq_group分配物理块。这时,我们的物理块空间是用来做decode的(给每个seq分配1个token的位置)。对于1个seq_group,除了那些标记为“finish”的seq外,其余seqs要么一起送去推理,要么一起不送去推理。即它们是集体行动的。判断能否对一个正在running的seq_group继续做推理的最保守的方式,就是判断当前可用的物理块数量是否至少为n。
- 如果决定调度 waiting队列的seq_group,从waiting中取出一个seq_group,必须先判断:gpu上是否有充足的空间为该seq_group分配物理块做prefill(给每个seq分配若干个token的位置),判断的入口代码为
vLLM 中的调度策略是:优先调度 prefill,然后调度 decode,但是会设置一个阈值防止 decode 一直等待。也就是优先确保 TTFT,然后设置一个阈值来保证 TPOT 不会太差。很明显,这只是一个折中的方法。
class Scheduler:
def _schedule(self) -> SchedulerOutputs:
# 如果swapped队列为空
if not self.swapped:
scheduled: List[SequenceGroup] = [] # 记录本次被调度的seq_group
# 计算Scheduler running队列中还没有执行完的seq数量
num_curr_seqs = sum(seq_group.get_max_num_running_seqs() for seq_group in self.running)
leftover_waiting_sequences = deque()
# 当waiting队列中有等待处理的请求,且当前时刻可以处理请求
while self._passed_delay(now) and self.waiting:
seq_group = self.waiting[0] # 取出waiting队列中的第一个请求,也即最早到达的请求(seq_group)
waiting_seqs = seq_group.get_seqs(status=SequenceStatus.WAITING)
num_prefill_tokens = waiting_seqs[0].get_len()
# 决定是否能给当前seq_group分配物理块
can_allocate = self.block_manager.can_allocate(seq_group)
# 若是延迟分配,则说明现在没有足够的block空间,所以跳出while循环(不继续对waiting队列中的数据做处理了)
if can_allocate == AllocStatus.LATER:
break
elif can_allocate == AllocStatus.NEVER:
for seq in waiting_seqs:
seq.status = SequenceStatus.FINISHED_IGNORED
ignored_seq_groups.append(seq_group) # 记录因为太长而无法处理的seq_group
self.waiting.popleft() # 将该seq_group从waiting队列中移除
continue
# 走到这一步时,说明当前seq_group已经通过上述种种验证,可以被加入本次调度中执行了先将其从waiting队列中移出
self.waiting.popleft()
self._allocate(seq_group) # 为当前seq_group分配物理块
self.running.append(seq_group) # 将当前seq_group放入running队列中
if scheduled or ignored_seq_groups:
# 如果本次有被调度的seq_group(scheduled非空) 或者本次有被设置为不再处理的seq_group(ignored_seq_groups非空) 就将其包装成SchedulerOutputs对象
...
return scheduler_outputs
# 如果swap队列非空,且本次没有新的需要被发起推理的seq_group,
self.running = self.policy.sort_by_priority(now, self.running)
running: Deque[SequenceGroup] = deque()
preempted: List[SequenceGroup] = []
while self.running:
seq_group = self.running.popleft() # 取出running队列中最早到来的seq_group
# 对于running队列中这个最早到来的seq_group,检查对于其中的每一个seq,是否能至少分配一个物理块给它,如果不能的话
while not self.block_manager.can_append_slot(seq_group):
if self.running: # 如果从running队列中取出最早达到的seq_group后,running队列还是非空
victim_seq_group = self.running.pop() # 抢占running队列中最晚到来的seq_group(可怜的被害者)
self._preempt(victim_seq_group, blocks_to_swap_out)
preempted.append(victim_seq_group)
else: # 那就只能抢占这个最早到达的seq_group了
self._preempt(seq_group, blocks_to_swap_out)
preempted.append(seq_group)
break
...
物理块管理器
图解大模型计算加速系列:vLLM源码解析3,块管理器(BlockManager)上篇 图解大模型计算加速系列:vLLM源码解析3,Prefix Caching 未读
逻辑块结构(一切尽在注释中),它是Sequence实例(seq)下维护的一个属性。逻辑 Block 的使用逻辑是根据需要实时实例化一个对象,如果当前的 LogicalBlock没有剩余空间了,就再实例化一个新的。在 vLLm 的使用场景是在vllm/vllm/sequence.py里的Sequence类中根据需要动态创建LogicalBlock Sequence._append_logical_block 和 Sequence._append_tokens_to_blocks。
# vllm/block.py
class LogicalTokenBlock:
"""A block that stores a contiguous chunk of tokens from left to right.Logical blocks are used to represent the states of the corresponding physical blocks in the KV cache.
KV cache的逻辑块
"""
def __init__(self,block_number: int, block_size: int, ) -> None:
self.block_number = block_number # PhysicalTokenBlock 实例对象的索引
self.block_size = block_size # 表示一个 block 内存储多少个 token 的 kv cache 数据。
# 逻辑块刚初始化时,将其中的每个token_id都初始化为_BLANK_TOKEN_ID(-1)
self.token_ids = [_BLANK_TOKEN_ID] * block_size
# 当前逻辑块中已经装下的token的数量,当self.num_tokens==block_size时则表示这个 block 已经被使用完了。
self.num_tokens = 0
def is_full(self) -> bool:
"""判断当前逻辑块是否已经被装满"""
return self.num_tokens == self.block_size
def append_tokens(self, token_ids: List[int]) -> None:
"""将给定的一些token_ids装入当前逻辑块中"""
# 给定的token_ids的长度必须 <= 当前逻辑块剩余的槽位
assert len(token_ids) <= self.get_num_empty_slots()
# 当前逻辑块第一个空槽的序号
curr_idx = self.num_tokens
# 将这些tokens装进去
self.token_ids[curr_idx:curr_idx + len(token_ids)] = token_ids
# 更新当前逻辑块中tokens的数量
self.num_tokens += len(token_ids)
def get_token_ids(self) -> List[int]:
"""获取当前逻辑块中所有被装满的位置的token_ids"""
return self.token_ids[:self.num_tokens]
def get_last_token_id(self) -> int:
"""获取当前逻辑块所所有被装满的位置的最后一个token_id"""
assert self.num_tokens > 0
return self.token_ids[self.num_tokens - 1]
物理块结构(一切尽在注释中):
# vllm/block.py
class PhysicalTokenBlock:
"""Represents the state of a block in the KV cache."""
def __init__(self,device: Device,block_number: int, block_size: int,block_hash: int,num_hashed_tokens: int,) -> None:
self.device = device # 设备,gpu/cpu
self.block_number = block_number # 该物理块在对应设备上的全局block index
self.block_size = block_size # 该物理块的尺寸(即槽位数量,默认为16)
self.block_hash = block_hash # 该物理块的hash值 (在prefix caching场景下使用,非此场景则附值为-1)
self.num_hashed_tokens = num_hashed_tokens # 该物理块的hash值是由多少个前置token计算而来的(prefix caching场景下使用,非此场景则附值为0)
self.ref_count = 0 # 该物理块被多少个逻辑块引用,可以大于等于 1,表示这个 block 内 token 的 cache 被重复利用
self.last_accessed = DEFAULT_LAST_ACCESSED_TIME # 该物理块最后一次被使用的时间(prefix caching场景下使用,非此场景则附值为-1)
self.computed = False # 该物理块是否被计算过(prefix caching场景下使用)
PhysicalTokenBlock只是针对单个 block 的描述。vLLM 在vllm/vllm/core/block_manager.py文件下实现了BlockAllocator类用来初始化所有物理 block,并负责分配这些 block。
BlockAllocator分成两种类型:
- CachedBlockAllocator:按照prefix caching的思想来分配和管理物理块。在原理篇中,我们提过又些prompts中可能含有类似system message(例如,“假设你是一个能提供帮助的行车导航”)等prefix信息,带有这些相同prefix信息的prompt完全可以共享用于存放prefix的物理块,这样既节省显存,也不用再对prefix做推理。
- UncachedBlockAllocator:正常分配和管理物理块,没有额外实现prefix caching的功能。
blockAllocator又分成gpu和cpu两种类型,分别管理这两类设备上的物理块。你可能会问,cpu上的物理块是什么呢?你还记得调度器有一个swap策略吗?当gpu上显存不足时,它会把后来的请求抢占,并将其相关的KV cache物理块全部都先swap(置换、卸载)在cpu上,等后续gpu显存充足时,再把它们加载回gpu上继续做相关请求的推理。所以在cpu上我们也需要一个管控物理块的BlockAllocator。
class UncachedBlockAllocator(BlockAllocatorBase):
def __init__(self, device: Device,block_size: int,num_blocks: int,) -> None:
self.device = device # 设备:cpu/gpu
self.block_size = block_size # 该设备上每个物理块的槽位数,默认为16
self.num_blocks = num_blocks # 该设备上留给KV cache的总物理块数量
self.free_blocks: BlockTable = []
for i in range(num_blocks):
# vllm/vllm/block.py
# 定义物理块
block = PhysicalTokenBlock(device=device,block_number=i,block_size=block_size,block_hash=-1,num_hashed_tokens=0)
self.free_blocks.append(block)
def allocate(self,block_hash,num_hashed_tokens: int = 0) -> PhysicalTokenBlock:
block = self.free_blocks.pop()
block.ref_count = 1 # 该物理块首次有逻辑块引用了,所以ref_count=1
return block
def free(self, block: PhysicalTokenBlock) -> None:
...
class CachedBlockAllocator(BlockAllocatorBase):
def __init__(self, device: Device,block_size,num_blocks,eviction_policy,...)-> None:
...
self.evictor: Evictor = make_evictor(eviction_policy) # 默认是LRUEvictor
# 为哈希值为block_hash分配一个物理块
def allocate_block(self, block_hash: int,num_hashed_tokens: int) -> PhysicalTokenBlock:
...
每个Sequence的KVCache序列会分成多个block_size长度的cache block,每个cache block的位置信息记录在BlocKspaceManager。每个seq维护自己的一份逻辑块列表,BlockManager中的self.block_tables(形式如:{seq_id: List[PhysicalBlock]})则记录者每个seq下的物理块列表,通过seq这个中介,我们维护起“逻辑块->物理块”的映射。
BlockSpaceManager是一个高级内存管理器,功能是管理各个SequenceGroup对应KVCache存储信息,也就是管理逻辑数据块和物理内存块之间的映射。实际上,BlockSpaceManager只负责维护cache block到gpu/cpu空间的索引,真正进行换入、换出、拷贝操作都需要通过Worker中CacheEngine进行。。因此在Scheduler调度的时候,也会收集BlockSpaceManager返回结果,得到当前step所需KVCache的block_to_swap_in、block_to_swap_out、block_to_copy(in 就是 cpu to gpu,out 就是 gpu to cpu,由专门的 cu 函数 支持),以供后续CacheEngine操作内存空间。
class BlockSpaceManagerV1(BlockSpaceManager):
"""Manages the mapping between logical and physical token blocks."""
def __init__(self,block_size: int,num_gpu_blocks: int,num_cpu_blocks: int,...)-> None:
self.gpu_allocator = ...
self.cpu_allocator = ...
# 负责维护每个seq下的物理块列表,本质上它是一个字典,形式如{seq_id: List[PhysicalTokenBlock]}
self.block_tables: Dict[int, BlockTable] = {}
def can_allocate(self, seq_group: SequenceGroup) -> AllocStatus:
seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0]
num_required_blocks = len(seq.logical_token_blocks)
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
# 如果设备中所有的物理块数量 - 该seq实际需要的物理块数量 < 水位线block数量,则不分配(说明当前seq太长了)
if (self.num_total_gpu_blocks - num_required_blocks < self.watermark_blocks):
return AllocStatus.NEVER
# 如果设备中可用的物理块数量 - 该seq实际需要的block数量 >= 水位线block数量,则分配
if num_free_gpu_blocks - num_required_blocks >= self.watermark_blocks:
return AllocStatus.OK
# 否则,现在不能分配,但可以延迟分配
else:
return AllocStatus.LATER
# 是否至少能为这个seq_group下的每个seq都分配1个空闲物理块
def can_append_slots(self,seq_group: SequenceGroup,num_lookahead_slots: int = 0) -> bool:
num_free_gpu_blocks = self.gpu_allocator.get_num_free_blocks()
num_seqs = seq_group.num_seqs(status=SequenceStatus.RUNNING)
return num_seqs <= num_free_gpu_blocks
# 为当前seq_group分配物理块做prefill
def allocate(self, seq_group: SequenceGroup) -> None:
seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0]
num_prompt_blocks = len(seq.logical_token_blocks) # 计算该seq的逻辑块数量
block_table: BlockTable = []
for logical_idx in range(num_prompt_blocks):
block = self.gpu_allocator.allocate()
block.ref_count = seq_group.num_seqs()
block_table.append(block)
# prefill阶段,这个seq_group下所有的seq共享一个prompt,也即共享这个prompt代表的物理块
for seq in seq_group.get_seqs(status=SequenceStatus.WAITING):
self.block_tables[seq.seq_id] = block_table.copy()
def append_slots(self,seq: Sequence,) -> Optional[Tuple[int, int]]:
...
if ...
maybe_new_block = self._maybe_promote_last_block( seq, last_block)
block_table[-1] = maybe_new_block
return ...
if ...
# 如果当前物理块的slots满了
new_block = self._allocate_last_physical_block(seq)
block_table[-1] = new_block
return ...
当一个物理块没有任何逻辑块引用时(例如一个seq刚做完整个推理),这时它理应被释放。但是在prefix caching的前提下,我们的优化思想是:即使这个物理块当前没有用武之地,可是如果不久之后来了一个新seq,它的prefix(例如system message)和这个物理块指向的内容高度一致,那么这个物理块就可以被重复使用,以此减少存储和计算开销。所以,我们设置一个驱逐器(evictor)类,它的free_tables属性将用于存放这些暂时不用的物理块。此时,该设备上全部可用的物理块 = 正在被使用/等待被使用的物理块数量 + evictor的free_tables中的物理块数量。在prefill阶段,当我们想创建一个物理块时,我们先算出这个物理块的hash值,然后去free_tables中看有没有可以重复利用的物理块,有则直接复用。如果没有可以重复利用的hash块,那这时我们先检查下这台设备剩余的空间是否够我们创建一个新物理块。如果可以,就创建新物理块。如果此时没有足够的空间创建新物理块,那么我们只好从free_tables中驱除掉一个物理块,为这个新的物理块腾出空间,驱逐策略如下:
- 先根据LRU(Least Recently Used)原则,驱逐较老的那个物理块
- 如果找到多个最后一次使用时间相同的老物理块,那么则根据max_num_tokens原则,驱逐其hash值计算中涵盖tokens最多的那个物理块。
- 如果这些老物理块的LRU和max_num_tokens还是一致的话,那就从它们中随机驱逐一个
使用prefix caching,是不是就意味着两个seq的prompt必须完全一致,才可以重复利用物理块呢?
- prefill阶段。比如下图,seq1的block0~2都可以复用seq0的,但是
hash(seq1 block3) != hash(seq0 block3),因此我们需要为seq1 block3(红色)开辟新空间。因为KV cache的计算也需要考虑位置编码的原因,hash值的计算考虑了当前block及其之前所有block所维护的token值,也是为了找到最长可复用的prefix。
- 在decode阶段,当两个seq物理块还没满的时候,我们会给它附一个相互不重复的默认hash值,两个seq继续做decode(风平浪静的美丽日子),当一个seq用完当前物理块的所有slots时,我们再对这个物理块重新做hash计算(对所有的prefix计算一次hash值),拿着这个new_hash,我们去cached_blocks(当前正在被使用的物理块列表)和free_tables(驱逐器的冷宫,曾经被使用的物理块列表)寻找。如果找到可以复用的物理块,我们就释放当前这个物理块,复用旧物理块,如果没有找到可以复用的物理块,我们就把当前这个物理块的旧hash值从cached_blocks中释放掉,取而代之以新hash值。

cacheManager
调度器的block manager只负责物理块id的分配,CacheEngine则是根据这个id分配结果实打实地在管理物理块中的数据。 初始化时候,CacheEngine先根据之前 profile 的数据(cpu/gpu blocks数)来 allocate cache。
预分配显存:在模型部署的初始化阶段(推理正式开始前),vLLM会通过模拟实验的方式,来决定gpu/cpu上到底有多少个KV cache物理块可以分配给后续的请求们做推理。vLLM管这个步骤叫profile_num_available_blocks。
- 杜撰假数据。首先,用户在初始化LLMEngine引擎时,会提供两个重要参数:max_num_seqs=256(在1个推理阶段中,LLMEngine最多能处理的seq数量),max_num_batched_tokens=2048(在1个推理阶段中,LLMEngine最多能处理的token数量)
- 用假数据模拟一次前向推理。我们现在想知道在1次推理过程中,可以分配多少的显存给KV cache。我们可以使用如下公式计算:分配给KV cache显存 = gpu总显存 - 不使用KV cache做1次推理时的显存占用(包括模型本身和推理过程中的中间数据)对于“不使用KV cache做1次推理时的显存占用”,我们就可以用杜撰出来的假数据模拟一次前向推理来计算得出。
- 计算可分配的KV cache物理块总数。从(2)的模拟实验中,我们已经预估了一块卡上“分配给KV Cache的总显存”。现在,我们可以来计算总的物理块数量了。我们易知:总物理块数量 = 分配给KV Cache的显存大小/ 物理块大小,其中“大小”的单位是bytes。物理块大小(block_size)也是可以由用户自定义的,vLLM推荐的默认值是block_size = 16。
- 一个 block 占用内存大小(Byte)= token 数量 (block_size) ✖️ 一个 token 的 kv cache 占用 内存大小。所以,我们只需要计算出单个 token 的 kv cache 对应的大小即可。
- block 大小的计算方法由vllm/vllm/worker/cache_engine.py文件里CacheEngine类的get_cache_block_size函数实现。一个 block 占用的内存 = token 数量(block_size)✖️ 层数 (num_layers) ✖️ 单层 kv cache 占用内存 (2✖️num_heads✖️head_size)✖️ 数据类型大小(如果是 fp16,则每个数据占用 2 Bytes)
- CPU上物理块总数也是同理,但与GPU不同的是,它不需要做模拟实验。CPU上可用的内存总数是用户通过参数传进来的(默认是4G)。也就是我们认为只能在这4G的空间上做swap。
- 将预分配的KV Cache加载到gpu上。当我们确定好KV Cache block的大小后,我们就可以创建empty tensor,将其先放置到gpu上,实现显存的预分配。以后这块显存就是专门用来做KV Cache的了。也正是因为这种预分配,你可能会发现在vLLM初始化后,显存的占用比你预想地要多(高过模型大小),这就是预分配起的作用。
def _allocate_kv_cache(self,num_blocks: int,device: str, ) -> List[torch.Tensor]: """Allocates KV cache on the specified device.""" kv_cache_shape = self.attn_backend.get_kv_cache_shape( num_blocks, self.block_size, self.num_heads, self.head_size) pin_memory = is_pin_memory_available() if device == "cpu" else False kv_cache: List[torch.Tensor] = [] # ======================================================================= # kv_cache_shape: (2, num_blocks, block_size * num_kv_heads * head_size) # ======================================================================= for _ in range(self.num_layers): kv_cache.append(torch.empty(kv_cache_shape,dtype=self.dtype,pin_memory=pin_memory,device=device)) return kv_cache
整个预分配的过程,其实也是在提醒我们:当你发现vLLM推理吞吐量可能不及预期,或者出现难以解释的bug时,可以先查查输出日志中pending(waiting)/running/swapped的序列数量,以及此时KV Cache部分的显存利用程度,尝试分析下这些默认的预分配设置是不是很好契合你的推理场景,如果不行,可以先尝试调整这些参数进行解决。
PS:kv cache是通过Worker 中类型为CacheEngine的一个数据成员allocate出来的。所谓申请gpu内存,就是torch.zeros(device='cudda')。也没有固定划分显存区域 说xx 是kvcache,xx是模型权重,就是kvcache空间一次性全申请好,运行期间不释放。
class CacheEngine:
"""Manages the KV cache.
This class is responsible for initializing and managing the GPU and CPU KV
caches. It also provides methods for performing KV cache operations, such
as swapping and copying.
"""
def __init__(self,cache_config,model_config,parallel_config,...) -> None:
self.attn_backend = get_attn_backend(...)
# Initialize the cache.
self.gpu_cache = self._allocate_kv_cache(self.num_gpu_blocks, "cuda")
self.cpu_cache = self._allocate_kv_cache(self.num_cpu_blocks, "cpu")
def _allocate_kv_cache(self,num_blocks: int,device: str,) -> List[torch.Tensor]:
"""Allocates KV cache on the specified device."""
kv_cache_shape = self.attn_backend.get_kv_cache_shape(num_blocks, self.block_size, self.num_kv_heads, self.head_size)
pin_memory = is_pin_memory_available() if device == "cpu" else False
kv_cache: List[torch.Tensor] = []
for _ in range(self.num_layers):
# null block in CpuGpuBlockAllocator requires at least that block to be zeroed-out. We zero-out everything for simplicity.
kv_cache.append(torch.zeros(kv_cache_shape,dtype=self.dtype,pin_memory=pin_memory,device=device))
return kv_cache
刚从CacheEngine 分配出来的KV Cache从整体上看确实是一块连续的内存,只不过会将它们分成不同的block使用。kv_cache 的shape上看,也确实如此。那么如何将不同token的KV tensors存储到kv_cache 的某一地址?这个问题的答案是:我们的reshape_and_cache算子,会接受一个slot_mapping参数。slot_mapping是根据SequenceGroupMetadata 中的block_tables 计算得到的。block_tables 是由BlockSpaceManager 负责管理和维护的。PS:注意力kernel因为非连续内存访问变得更复杂。
一个seq 有一个跟它一样生命周期的kv cache tensors(甚至后者实际更长一点)。seq 封装了一个请求所有的上下文(用户侧配置,比如温度;内容配置,比如token id list;资源侧配置,比如kvcache tensor), 一个seq 有一个跟它一样生命周期的kv cache tensors(甚至后者实际更长一点),具体说是持有了block_tables/kv cache tensors所在的block 引用,kv cache 所在空间是vllm 一启动便申请好的完整物理显存空间。调度层、推理层取出seq 后都是根据这些信息在干活儿。
模型执行
vllm模型执行笔记: LLMEngine, Executor, Worker, ModelRunner - 陈star的文章 - 知乎
执行模型其实就是正常的 infrence,除了一些 kernel 的实现比较特殊,其他的整个流程和常规流程都是一样的。LLMEngine.step 运行一次推理,此处有4个层级的概念 LLMEngine/Executor/Worker/ModelRunner,层层分解,各管一摊。Executor的抽象是后加的,Executor是分布式runtime管理器,一个Executor里会有多个worker。
LLMEngine 负责调度请求,取一个待执行请求交给executor,拿到output,对output 进行后处理。
class LLMEngine:
def step(self) -> ...:
seq_group_metadata_list, scheduler_outputs = self.scheduler.schedule()
if not scheduler_outputs.is_empty():
execute_model_req = ExecuteModelRequest(seq_group_metadata_list,blocks_to_swap_in,blocks_to_swap_out,...)
output = self.model_executor.execute_model(execute_model_req=execute_model_req)
else:
output = []
# 模型输出后处理
request_outputs = self._process_model_outputs(output,scheduler_outputs.scheduled_seq_groups,...)
...
return request_outputs
Executor 作为 LLMEngine与Worker 中间层,干的活儿不多,主要是中转,主要是抽象 单卡和分布式执行。NeuronExecutor/CPUExecutor/RayGPUExecutor/GPUExecutor。GPUExecutor.execute_model ==> Worker.execute_model
class GPUExecutor(ExecutorBase):
"""
An executor is responsible for executing the model on a specific device
type (e.g., CPU, GPU, Neuron, etc.). Or it can be a distributed executor
that can execute the model on multiple devices.
"""
def _init_executor(self) -> None:
self.driver_worker = self._create_worker()
self.driver_worker.init_device()
self.driver_worker.load_model()
def execute_model(self, execute_model_req: ExecuteModelRequest) -> List[Union[SamplerOutput, PoolerOutput]]:
output = self.driver_worker.execute_model(execute_model_req)
return output
Worker 是对单个 GPU 的抽象。Engine 通过调用 _run_workers("<method_name>", *args, get_all_outputs, **kwargs) 来在 所有 workers 上执行方法。
Worker利用CacheEngine 完成KV Cache block的基本操作(e.g. swap_in, swap_out, copy),然后调用ModelRunner 执行模型前向推理。注意两点:
- 将KV cache作为参数传过去了。对KV cache中block的处理以及调度都不是ModelRunner 所关心的,它只是将它们的处理结果作为输入。
- attn_metadata里有slot_mapping这个信息。slot_mapping是一个很重要的输入信息,它给出了sequence中每个token对应到KV cache哪个slot。slot_mapping tensor的计算是在_prepare_model_input 接口内完成的。
class Worker(WorkerBase):
"""A worker class that executes (a partition of) the model on a GPU.
Each worker is associated with a single GPU. The worker is responsible for
maintaining the KV cache and executing the model on the GPU. In case of
distributed inference, each worker is assigned a partition of the model.
"""
def __init__(self,model_config: ModelConfig,xxConfig,rank,...):
...
self.model_runner = ModelRunnerClass(...)
# Uninitialized cache engine. Will be initialized by initialize_cache.
self.cache_engine: CacheEngine
def initialize_cache(self, num_gpu_blocks: int,num_cpu_blocks: int) -> None:
"""Allocate GPU and CPU KV cache with the specified number of blocks.
This also warms up the model, which may record CUDA graphs.
"""
...
self.cache_config.num_gpu_blocks = num_gpu_blocks
self.cache_config.num_cpu_blocks = num_cpu_blocks
self._init_cache_engine()
self._warm_up_model()
def _init_cache_engine(self):
assert self.cache_config.num_gpu_blocks is not None
self.cache_engine = CacheEngine(self.cache_config, self.model_config,self.parallel_config)
self.gpu_cache = self.cache_engine.gpu_cache
@torch.inference_mode()
def execute_model(self,execute_model_req: Optional[ExecuteModelRequest] = None) -> List[Union[SamplerOutput, PoolerOutput]]:
...
seq_group_metadata_list = execute_model_req.seq_group_metadata_list
num_seq_groups = len(seq_group_metadata_list)
# `blocks_to_swap_in` and `blocks_to_swap_out` are cpu tensors.
# they contain parameters to launch cudamemcpyasync.
blocks_to_swap_in = torch.tensor(execute_model_req.blocks_to_swap_in, device="cpu",dtype=torch.int64).view(-1, 2)
blocks_to_swap_out = torch.tensor(execute_model_req.blocks_to_swap_out,device="cpu",dtype=torch.int64).view(-1, 2)
# `blocks_to_copy` is a gpu tensor. The src and tgt of
# blocks to copy are in the same device, and `blocks_to_copy`
# can be used directly within cuda kernels.
blocks_to_copy = torch.tensor(execute_model_req.blocks_to_copy,device=self.device,dtype=torch.int64).view(-1, 2)
data: Dict[str, Any] = {
"num_seq_groups": num_seq_groups,
"blocks_to_swap_in": blocks_to_swap_in,
"blocks_to_swap_out": blocks_to_swap_out,
"blocks_to_copy": blocks_to_copy,
}
broadcast_tensor_dict(data, src=0)
self.cache_swap(blocks_to_swap_in, blocks_to_swap_out, blocks_to_copy)
# If there is no input, we don't need to execute the model.
if num_seq_groups == 0:
return []
output = self.model_runner.execute_model(seq_group_metadata_list,self.gpu_cache)
# Worker only supports single-step execution. Wrap the output in a list
# to conform to interface.
return [output]
ModelRunner 是真正干推理的。hidden_states计算、compute_logits 接口和sample。
class ModelRunner:
def __init__(self,model_config,xx_config,...):
...
# Lazy initialization
self.model: nn.Module # Set after load_model
@torch.inference_mode()
def execute_model(self,seq_group_metadata_list,kv_caches: List[torch.Tensor],) -> Optional[SamplerOutput]:
(input_tokens, input_positions, attn_metadata, sampling_metadata,
lora_requests, lora_mapping, multi_modal_input
) = self.prepare_input_tensors(seq_group_metadata_list)
# 以llama为例,这里具体的模型model_executable是LlamaForCausalLM,在vllm/model_executor/models/llama.py里定义了具体的模型结构。
model_executable = self.model
execute_model_kwargs = {
"input_ids": input_tokens,
"positions": input_positions,
"kv_caches": kv_caches,
"attn_metadata": attn_metadata,
}
hidden_states = model_executable(**execute_model_kwargs)
# Compute the logits.
logits = self.model.compute_logits(hidden_states, sampling_metadata)
# Sample the next token.
output = self.model.sample(logits=logits,sampling_metadata=sampling_metadata, )
return output
ModelRunner.execute_model(seq_group_metadata_list,kv_caches) 中kv_caches 来自Worker.gpu_cache,也就是cache_engine 初始化时申请的kv_caches。PS:cache_engine 在初始化时,计算gpu 显存可以有多少空间给kvcache 用,将这部分空间按block shape初始化赋给了cache_engine.gpu_cache,ModelRunner 在推理时都会持有这个全局唯一引用,重点是也会携带seq 相关的input_metadata(包含seq相关的 block_tables),这些数据一直会透传到attention layer的cuda 算子层。这样虽然推理时持有的都是同一份gpu_cache 引用,但彼此不会干扰,带上了seq 的block_tables 可以支持访问seq对应的离散的物理block,也就是block映射关系也透传到算子层了。vllm重写模型推理代码,因为要适配paged attention等相关优化,为的就是这里。
经过 Sampler 会得到一个 Dict[int, SequenceOutputs],也就是 seq id -> 对应的输出,输出包含着 log prob。这个输出会被传到 scheduler 的 update 接口,用于更新对应的 running sequences(即我 auto regression 部分)。然后传到 llm engine 会被包成 RequestOutput 出来。
class LlamaForCausalLM(nn.Module):
def forward( self,input_ids: torch.Tensor, positions: torch.Tensor,kv_caches: List[KVCache],input_metadata: InputMetadata,) -> torch.Tensor:
hidden_states = self.model(input_ids, positions, kv_caches,input_metadata)
return hidden_states
class LlamaAttention(nn.Module):
def __init__(self,...):
...
self.attn = PagedAttention(self.num_heads,self.head_dim,self.scaling,num_kv_heads=self.num_kv_heads)
def forward(self,positions: torch.Tensor,hidden_states: torch.Tensor,kv_cache: KVCache,input_metadata: InputMetadata,) -> torch.Tensor:
qkv, _ = self.qkv_proj(hidden_states)
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
q, k = self.rotary_emb(positions, q, k)
k_cache, v_cache = kv_cache
attn_output = self.attn(q, k, v, k_cache, v_cache, input_metadata)
output, _ = self.o_proj(attn_output)
return output
class PagedAttention(nn.Module):
def forward(self,query: torch.Tensor,key: torch.Tensor,value: torch.Tensor,key_cache: Optional[torch.Tensor],value_cache: Optional[torch.Tensor],input_metadata: InputMetadata,) -> torch.Tensor:
...
if input_metadata.is_prompt:
out = xops.memory_efficient_attention_forward(query,key,value,...)
else:
# Decoding run.
output = _paged_attention(query,key_cache,value_cache,input_metadata,...)
def _paged_attention(query: torch.Tensor,key_cache: torch.Tensor,value_cache: torch.Tensor,input_metadata: InputMetadata,num_kv_heads: int,scale: float,alibi_slopes: Optional[torch.Tensor],) -> torch.Tensor:
if use_v1:
# Run PagedAttention V1.
ops.paged_attention_v1(output,query,key_cache,value_cache,...input_metadata.block_tables,...)
else:
ops.paged_attention_v2(...)
return output
vLLM 架构详解(二):内存管理 - CalebDu的文章 - 知乎
prompt/prefill phase 的流程从用户添加一个新的request开始,LLM Engine根据request中的prompt string 创建一个新的Sentence,创建Sentence时构造 prompt_len/block_size logical token block 列表(Logical Table)。并由该Sentence 创建一个新的SentenceGroup,并加入Scheduler waiting 队列。在Step 最初Scheduler 将waiting 队列中的Sentence调度,被成功调度的SentenceGroup 根据其中每个Sentence Logical Table 的大小分配对应的physical token block列表(Physical Table),组成block table。prompt phase不涉及swap-in、swap-out、copy-on-write,把成功调度的SentenceGroupMetaData与KV Cache Tensor输入Model_Runner 调用模型的forward,在Attention Module中 通过自定义算子reshape_and_cache_kernel把kv-project计算得到的KV根据block table 每个token 对应的slot_mapping 存储到全局的KV Cache Tensor内。模型执行一次end2end 的推理之后得到SampleOutput,由于不同的Sample策略,一个parent Sentence 可能采样出多个output token,这些不同output token的child Sentence会fork parent Sentence的logical Table ,并把各自的output token加入每个child Sentence 各自的Logical Table并fork parents 的Physical Table,并将child Sentence 加入SentenceGroup供之后的 step Scheduler调度,直至满足结束条件。
decode phase的流程从新一次step 开始,Scheduler 会根据调度策略 把running队尾的元素的block swap-out(Swap Mode),并将符合要求的swapped 队列中的SentenceGroup 的block swap-in,并对这一轮成功调度的所有Sentence append slot 用于存储这一轮decode 生成的新token。append slot会先校验physical table 长度是否与logical table一致,若不一致直接分配一个新的physical block加入physical table 并返回。若两表长度一致则校验last phyiscal block 的ref count,若ref count==1,说明该phyiscal block只被一个Sentence拥有,直接返回,否则说明多个Sentence 共享这个block,分配一个新的block把该block 加入copy-on-write,原始的block ref count–。将Scheduler 调度输出的结果传给Worker执行,Cache Engine 根据Scheduler 提供的swap-in 、swap-out、copy-on-write的block 索引 通过自定义算子swap_blocks、 copy_blocks进行实际的KV Cache数据搬运。之后的模型执行及采样后处理与 prompt phase基本一致。PS:也就是不管prefill 还是decode 阶段,在推理之前,本次推理用到的/新增的token对应的kv cache tensor空间都安排物理block了,不是临时申请的显存空间。
模型并行的执行细节参考 vLLM源码之模型并行
推理框架的演进
SGLang:LLM推理引擎发展新方向大语言模型LLM的推理引擎经过一年时间发展,现在主流方案收敛到了开源的vLLM和半闭源的TensorRT-LLM。TRT-LLM基于C++开发,有NV算子开发黑魔法加持,在其重点支持的场景里,性能可以做到极致。vLLM基于python开发,代码简洁架构清晰,和开源互动紧密,灵活地满足了二次开发的需求。比如,最近流行的分离式架构,比如Sarathi-Serve,Mooncake等都是基于vLLM。
vLLM可以算是非常成功,对大模型发展的贡献也是史诗级的。正如吕布死后,人皆称赛吕布;vLLM开源之后,人人皆可自研LLM推理框架。但是以史为鉴,我认为大模型推理引擎的发展仍是初级阶段。就像当年深度学习框架发展经历了cuda-convnet(2012)-> Caffe (2014)-> TensorFlow(2016)-> PyTorch(2017)长达五年跨度若干的阶段,大模型推理框架一步到位也不太现实。vLLM有点像当年的Caffe阶段,比如下面几个方面:
- 高性能:Caffe率先做到了在GPU上高性能运行,它写了大量cuda kernel,比如im2col后调用cuBLAS来优化卷积算子。同时很早支持数据并行方式多卡训练。其性能优势让很多人从Theano切换到Caffe,正如vLLM的Paged Attention打开了吞吐天花板。
- 开源影响力:工程和学术界大量model zoo都基于caffe开发,比如很多年的ImageNet比赛的模型都用Caffe,其中就包括CVPR 16’ best paper Resnet。和vLLM现在的地位颇为相似。
- 学术机构维护:Caffe和vLLM都诞生于UCB实验室项目。Caffe的主程Yangqing Jia后来去Facebook,写了Caffe2后来合并进了PyTorch项目。
随着深度学习需求的升级,导致Caffe被更灵活和更高效设计替代。原因是多方面的,首先,更复杂的模型架构,Caffe就很难定义其计算图,比如循环架构的LSTM。另外,随着竞争加剧,实验室方式维护开源项目难以为继,后期的TensorFlow和PyTorch成功都离不开大公司的投入与推广。种种原因导致Caffe淡出历史舞台,但是Caffe的影响还是广泛存在于现在的深度学习基础设施之中。vLLM今天很可能面临着和当年Caffe相似的局面。在Caffe时代,深度学习框架完成了算子库和框架解耦,Caffe从自己实现各种算子进化成调用cuDNN。vLLM也重演了类似的演化,现在vLLM开始利用FlashInfer和xformers作为算子库,最开始PA的cuda代码渐渐淡出。
vLLM主要考虑简单的单轮对话形式与LLM进行交互,输入prompt,Prefill+Decode计算后输出。随着大模型应用发展深度,LLM的使用方式正在发生变化。比如,LLM参与multi-round planning、reasoning和与外部环境交互等复杂场景,需要LLM通过工具使用、多模态输入以及各种prompting techniques,比如self-consistency,skeleton-of-thought,and tree-of-thought等完成。这些过程都不是简单的单轮对话形式,通常涉及一个prompt输出多个结果,或者生成内容包含一些限制,比如json格式或者一些关键词。这些模式的涌现标志着我们与LLMs交互方式的转变,从简单的聊天转向更复杂的程序化使用形式,这意味着使用类似编程语言的方式来控制LLMs的生成过程,称为LM Programs。LM Programs有两个共同特性:
- LM Program通常包含多个LLM调用,这些调用之间穿插着控制流。这是为了完成复杂任务并提高整体质量所必需的。
- LM Program接收结构化输入并产生结构化输出。这是为了实现LM Program的组合,并将其集成到现有的软件系统中。
最近广受关注的工作SGLang正是瞄准LLM Programs设计的。其RadixAttention共享KVCache Prefix的优化,也被最近的各种新型推理引擎所采用,比如MoonCake,MemServe等之中。SGLang的后端Runtime有三个核心创新优化点,我下面分别介绍:
- Efficient KV Cache Reuse with RadixAttention。SGLang程序可以通过“fork”原语链接多个生成调用并创建并行副本。此外,不同的程序实例通常共享一些公共部分(例如,系统提示)。这些情况在执行过程中创建了许多共享提示前缀,从而提供了许多重用KV缓存的机会。与现有系统在生成请求完成后丢弃KV缓存不同,我们的系统在RadixTree中保留prompt和生成结果的KVCache,实现高效的前缀搜索、重用、插入和驱逐。SGLang用LRU驱逐策略和缓存感知调度策略,以提高缓存命中率。
- Efficient Constrained Decoding with Compressed Finite State Machine。在LM Programs中,用户通常希望将模型的输出限制为遵循特定格式,如JSON模式。这可以提高可控性和鲁棒性,并使输出更易于解析。SGLang通过正则表达式提供了一个regex参数来强制执行这些约束,这在许多实际场景中已经足够表达。现有系统通过将正则表达式转换为有限状态机(FSM)来支持这一点。在解码过程中,它们维护当前的FSM状态,从下一个状态检索允许的token,并将无效token的概率设置为零,逐个token解码。
- Efficient Endpoint Calling with API Speculative Execution。上述优化RadixAttention和Constrained Decoding还是针对模型是白盒情况。如果调用的模型是OpenAI这种黑盒API,SGLang通过使用推测执行来加速多调用SGLang程序的执行并降低API成本。SGLang不只是推理引擎,还可以做作为推理引擎的上层调用框架。
使用RadixAttention和Constrained Decoding可以减少LLM Program的计算量,这些优化也是和vLLM的PA、Continous Batching兼容的。如果你对LLM的用法可以使用SGLang定义成LLM Program,在业务中是可以显著获得收益的。
大模型推理引擎经过一年多发展,进入了一个关键的调整期。一方面,针对定制集群的分离式架构出现,很多业务方自己定制更复杂的并行和调度方案。另一方面,LLM的用法更加复杂,催生了LLM Programs使用范式。此外,非NVIDIA的NPU如雨后春笋般涌现,它们独特的硬件特性亟待新的系统架构来充分挖掘与利用。在这一背景下,以vLLM为代表的开源LLM推理引擎正面临着前所未有的进化压力。而SGLang此次的升级,不仅从框架层面揭示了vLLM仍有巨大的提升潜力,也对LLM场景需求进行了一些探索,值得大家关注。PS:其实就是应用层的信息(比如system prompt共用、输出json)进一步透传到底层,以优化底层的调度及显存使用。甚至部分应用层控制流通过dsl下传到调度层做。
算子层
vLLM皇冠上的明珠:深入浅出理解PagedAttention CUDA实现 未细读。
vllm集群运维
为了高效管理和优化 vLLM 服务,企业在日常开发与运维中需应对以下几个关键领域:
- 上下文理解:在多数应用场景中,LLM 通过对话提供推理服务,因此服务必须确保每行对话之间的连贯性。避免每次对话被分配到不同的后端资源导致上下文信息丢失。LLM 同时需要稳定的长连接,为用户提供一个持久的交互窗口。这意味着底层系统必须能够有效地管理和协调众多底层资源生命周期,确保对话的连贯性和稳定性。
- 模型与框架迭代:随着 vLLM 技术的发展,框架本身的迭代升级是必不可少的。而模样也同样需要持续改进和更新,以适应变化的需求。随着模型数量和类型的增加,版本控制、更新部署由于大体检而变得更加复杂。
- vLLM 服务器管理:规模化系统需要管理、调度和监控大量 vLLM 服务器,确保每个节点高效运行并能快速响应推理请求。同时,vLLM 集群需要具备足够的弹性来应对流量波动,并保持低延迟和高吞吐量。对于 vLLM 的生命周期管理也是一大难题。
- 版本控制与兼容性:确保不同版本之间的兼容性和可追溯性,便于回滚和修复问题,这对企业的技术栈提出了更高的要求。
其他
大模型推理显存优化系列(1):vTensorPagedAttn虽然效果明显,也广受欢迎,然而我们观察到它也存在一些不足,影响一些场景的使用和推广。概况主要以下三点:
- 首先,PagedAttn解显存碎片的解法把kernel实现和显存管理紧耦合,对attn kernel升级适配(例如支持TensorCore、GQA、各种奇怪的mask、稀疏、量化等)不太友好,周期很长,门槛很高。考虑到attn 计算是大模型的核心,业界依然在不断创新,这些创新实验通常基于PyTorch或HuggingFace,多数算法同学对高效kernel实现并不擅长,导致从算法实验(例如训练阶段)到推理部署适配周期很长。最终影响大模型的迭代效率。
- 其次,PagedAttn由于额外的元数据管理和实现,在一些场景下存在一定的性能开销。特别是早期不支持TensorCore,GQA attn kernel性能差
- 最后,PagedAttn本身也是个大碎片:由于PagedAttn静态预分配了KV cache,这部分显存无法动态再分配给其他需求,例如激活和其他实例(混部),本质也画地为牢,圈了一大块碎片。 我们希望找到一种新的办法,它同时满足以下三个目标条件:
- 解决好KV cache显存碎片问题:显存不能浪费,这是必备。
- 快速适配各种attn kernel:小白用户也能分分钟把一个attn kernel适配上continous batching来高效推理。
- 性能足够好:适配后的attn kernel要足够好,比如支持TensorCore,支持prompt cache等重要场景。
为此我们提出几个核心思路:
- 解耦attn kernel和KV cache显存管理:正如没有KV cache碎片问题之前,attn kernel开发者重点关注创新attn机制(与训练场景复用);显存管理由推理引擎在运行时负责。而不是如PagedAttn在kernel里处理碎片导致的问题,将二者糅合一起,一个人要懂两个人的事。
- KV cache显存管理核心基于CUDA VMM API:引入虚拟-物理显存两层指针,对模型提供的永远是地址连续的虚拟地址,这样模型(算法用户)不感知也不应关心KV cache碎片问题。正如绝大多数用户只需调用malloc分配CPU内存即可(malloc拿到的是虚拟内存,物理内存由更底层来负责),专业的事情由专业角色负责。注:VMM(Virtual Memory Management)从CUDA 10.2引入的driver层Low-level API,用于更精细管理控制显存。
- 复杂留给内部:引擎内统一协调KV cache的分配、释放和异步操作。一方面为算法用户提供一致的接口(兼容性);另一方面,需要精细的管理(如pooling、async)来降低运行时开销,提高效率。所设计的vTensor相关核心管理运行在CPU上,与GPU异步执行的计算有很多协同,有较复杂的逻辑和优化。正如不是所有简单调用malloc就能堆出来一个高效的数据库或Nginx一样,它也需要专门的优化。 vTensor是基于torch.tensor构造出的新的tensor对象,可以实现高效的KV Cache管理。在常见tensor属性之外,为解决KV cache碎片问题而内部做了特殊设计和优化,特别是管理物理块(handle)、虚拟地址(pointer)和请求(request)之间灵活的映射关系。典型特性包括:
- 虚拟地址永远连续:一个请求的KV cache最终可以分布在多个不连续的物理块中。
- 虚拟地址足够大:虚拟地址不值钱,虚拟指针的size可以比实际物理块更大,即部分range并没实际映射到物理块(如同存储里的hole)。这样每个用户请求都可以开心地拿到一个支持最大序列长度的虚拟显存地址,而实际的物理块的分配是按需、lazy的。这种机制非常自然的消除了 KV cache的(物理显存)碎片。注:虚拟地址也不能无休止的浪费,内置会定期回收复用。
- 虚-实的灵活映射:虚拟与物理可以1对1,也可以将一个物理块同时映射给多个虚拟地址,支持特殊场景如prompt cache和快照(copy-on-write)等,这个mapping管理需要结合scheduler;当然mapping逻辑搞错,映射坏或并发race,那是bug。
大模型推理显存优化系列(2):LayerKV它是在推理引擎层,针对prefill阶段的KV cache管理进行系统优化,来解决由于显存不足导致排队,排队导致首字延迟激增的问题。收到新请求时,并非reserve全部KV cache显存,例如80层的模型可以先给它8层(可配)的量,先开始启动prefill计算,减少等待。计算得到KV cache后,分层异步换出到CPU memory,腾出显存给后续layer。到了decode阶段,需要prefetch KV cache (HtoD)。此时二字延迟可能有影响,而总QPS实测可基本持平。
留下评论