大模型RLHF框架
简介(未完成)
如果说SFT是呆板的学习标准答案,那么RL是给定题目后,让学生自己寻找答案,给学生的解题打分,最后学生根据打分结果来学习。所以,RL框架就分成了三大块
- 学生自己寻找答案。就是大家天天说的rollout,就是模型推理。
- 给学生答案打分。理论上给学生批改作业没那么容易,特别我们现在需要学生做的任务越来越难。但现在大家都在卷数学,物理,代码,这些方向根据结果+规则判断对错是可行的,也就是rule-based。以及,大家发现训练一个小的reward 模型(例如7B)好像也能用。但随着agent出来后,特别开始涉及到商业领域,例如我在做的电商领域,就没那么简单了。也是模型推理,只不过模型多几个(不同的算法量级不一样),这块有人直接算到rollout环节。
- 学生根据打分来学习。训练模块,基于传统的训练框架,改改loss function 所以,现在的RL训练框架,整体分成两块,训练和rollout。假如你来设计这个rl框架,你会碰到这些挑战。
- rollout和训练两个模块的管理。RL现在的共识是on policy效果好,rollout和训练必须顺序执行。但现在模型越来越大,多卡是必然的,如何管理资源?rollout是内存消耗型,因为要做kv cache,特别现在cot越来越长了,训练则是计算密集型。这俩现在都分别做了非常做的复杂的性能优化,如何对这两者做好资源管理?两者的参数同步如何优化?
- 一个典型的问题是 rollout 和训练之间的同步间隔。如果 Sync=1,就是探索一个 step 采样数据,再用这批数据训练一个 step,这种情况下机器利用率能有 50% 就不错了。
- 底层框架。训练框架有很多,megatron,fsdp,deepspeed,差异还不小。推理引擎vllm和sglang,你用那个?不同的训练框架搭配不同的推理引擎,仅仅是参数更新这块,逻辑代码都不一样。。
- 异步问题。rollout批次执行的,但同批次差异巨大,特别agent时代这个差异更是大的离谱。
梳理一下,基于先推理(ref/reward/critic forward)后训练(actor train + critic train)
- 控制流,同步 vs 异步。异步就不 on policy 。
- 同步一般训练和推理共用 GPU 集群。会存在很多 bubble,且推理时存在训练资源浪费,训练时存在推理资源浪费。
- 异步 RL。推理引擎做 rollout 相当于生产者,训练引擎需要数据相当于消费者。rollout 出的数据会放在一个消息队列中 ,这个管理队列相当于 replay buffer,当数据达到一定 batch size 后训练引擎会从这个消息队列中获取数据来进行训练。训练时将训练和推理部署在不同的 GPU 上,且二者需要去实验来获得一个比例,来保证异步 RL 训练和推理尽量的减少 bubble。PS: 毕竟可以一起跑了
- 需要注意一个参数:staleness,这个参数控制着数据是否需要丢弃,考虑现实情况,有一个任务需要 rollout 非常久,当这个任务 rollout 完成时训练引擎已经完成了多次模型权重更新,那这个任务的轨迹是之前模型推理出的,如果使用这个轨迹进行训练哪怕有重要性采样也容易被裁剪,从而导致最后没有梯度,也就是说 staleness 控制着 rollout 数据不能偏离最新模型分布太久,一般设为 1-2,很早的数据就丢弃掉,因为对训练意义不大。staleness 是如何实现数据控制的,也很简单,每一个 rollout 轨迹都有一个版本号,如果版本号与当前最新模型的版本号差距大于 staleness,则从消息队列中丢弃。
- 当 rollout 产生 1 个 batch 数据,后训练引擎异步开始训练,当训练引擎完成训练时需要将新的模型权重传递给推理引擎,但这时推理引擎还在进行推理任务,partial rollout 的含义就是对正在 rollout 过程中的任务进行截断,保留已经 rollout 完成的那部分数据,暂停推理引擎的使用,开始从训练 rank 广播新的模型权重给推理 rank 进行模型参数更新,这个过程中训练引擎不受影响继续异步训练。当推理引擎完成参数更新后继续对之前截断的任务进行 rollout,也就是说这部分任务 rollout 轨迹前部分是旧策略模型生成的,后部分是新策略模型生成的。
- 数据流
- 在 verl 中将传统的 rlhf 训练的流程看成一个数据流图,数据在 actor、critic、reference、reward 中进行流转,最后来计算 PPO 公式得到损失,再对 actor 进行反向传播,为此 verl 专门设计了一种数据格式:DataProto。
- 框架:
- 训练用框架和推理框架不一样。 训练用FSDP和Megatron,推理用sglang 或者 vllm(rollout),训练和推理之间采用 ray 来充当胶水,作用就是分配资源,分布式远程调度等。sglang 和 vllm 这种推理引擎自己实现的 CUDA 算子以及存在的各种优化,训推异构导致硬件计算精度等原因会使得推理引擎得出的序列轨迹里每个 token 的 logits 与训练引擎相同序列轨迹的 logits 存在差异(PS:训推误差/训推不一致, token-level上不一致),这种差异会使得原本是 on policy 的训练退化成 off policy 的 RL 训练。在 MoE 结构中,每个 token 由一个 router 根据当前隐状态,选择 Top-k 个专家并进行加权计算。training–inference mismatch 不仅体现在概率数值上的偏差,还会直接导致在训练引擎与推理引擎中,对同一输入、同一模型参数,路由到的专家集合不一致。
- RL 训练框架真正实现的是对于数据的管理、训练引擎和推理引擎的调度、模型权重的迁移(训练后的模型权重更新到推理引擎,训练与推理不同切分方式的适配)以及环境的适配。每个rl框架在这四个方面有不同的侧重
2025年初,大部分 RL 框架还是同步模式,在一个完整的 FusedWorker 上同时做训练和推理。后来发现,这太慢了,有些 prompt 还卡在 rollout 上。是否能把这些长尾放到单独节点去,让它慢慢 rollout?对于已经 rollout 完的数据就先训练。这就顺理成章设计出了 partial rollout 和 stream rollout。在这种情况下效率虽然提高了,但带来了至少一个工程问题和一个算法问题,简单描述一下就是:
- 工程问题:如何保证不同轮之间的数据管理、参数同步、kvcache 管理。
- 算法问题:对于 off-policy 的容忍度到底有多高。
对比预训练
相比预训练来说,RL 的特点是:训练数据量少;训练 batch size 一般较小;训练资源占用少;单个 step 时间长;rollout 占训练实际时间比重大。
- rollout 是 RL 的核心,主要在于优化 rollout 的输出时间对整个 RL 训练端到端时间的提升有显著收益。大量RL训练的探索,变动的位置均发生在rollout阶段,因此RL的多样性,有很大一部分改动发生在rollout阶段。
- Infra 更面向业务。对于预训练来说,训练完一个模型、让 TB 甚至 PB 级数据顺利训完是终极目标。为此,负责预训练的同学需要对从 loader、训练到 ckpt 等各个阶段投入大量人力优化。如果单个 step 能减少 1% 的开销,对于按 GPU 月衡量的任务也有显著收益。而 RL 是在基础模型的基础上,根据不同的 recipe 训练出若干模型。各模型的能力侧重点也不同:有的擅长 code,有的擅长逻辑,有的擅长 VLM。相比预训练,RL 的训练链路更花样百出,工程同学写的代码也更偏向“胶水”与实现本身,而不是纯粹的优化。RL 优化力度不高主要有两个原因:
- RL 训练步数少,训练时间短:即便每步优化 1%,端到端收益也不会显著。
- 不同任务优化方向不同:有的希望模型 rollout 更快,有的卡在工具调用或 sandbox 交互,有的打分效率不行,还有的可能是数据 IO 需要优化。优化带来的共享性并不明显,ROI 也不突出。当然,如果某个瓶颈会阻塞所有训练,那我建议赶紧修好它。
- 框架设计比实际优化更重要。本质上,因为大家在同一个主干上参与训练(rollout -> … -> train),但预期行为却五花八门。如何在共用与分叉之间做有前瞻性的框架设计,并尽可能模块化、插件化地组织代码,对工程和算法都大有益处,也非常考验框架设计者的能力。说白了,算法同学可以接受优化不够极致的框架,但接受不了易用性差的框架。好的框架设计可能上午找 GPT 写完代码,下午就能顺利开测。而差的设计则会让不熟悉底层逻辑的算法同学先理几天的线头,极大阻碍实际进度。
从一个朴素的rl 框架开始
强化学习中的训练和推理引擎各自并没有本质上的新颖之处。强化学习框架所做的,是针对强化学习的on-policy特性
- 管理训练和推理引擎的资源,如分卡和offloading
- 将训练引擎的参数同步到推理引擎 其他的部分,如训练和推理引擎内部的分布式和checkpointing,只需沿用先前的成熟方案。
Task-Collocated
Verl架构解析朴素的RL框架
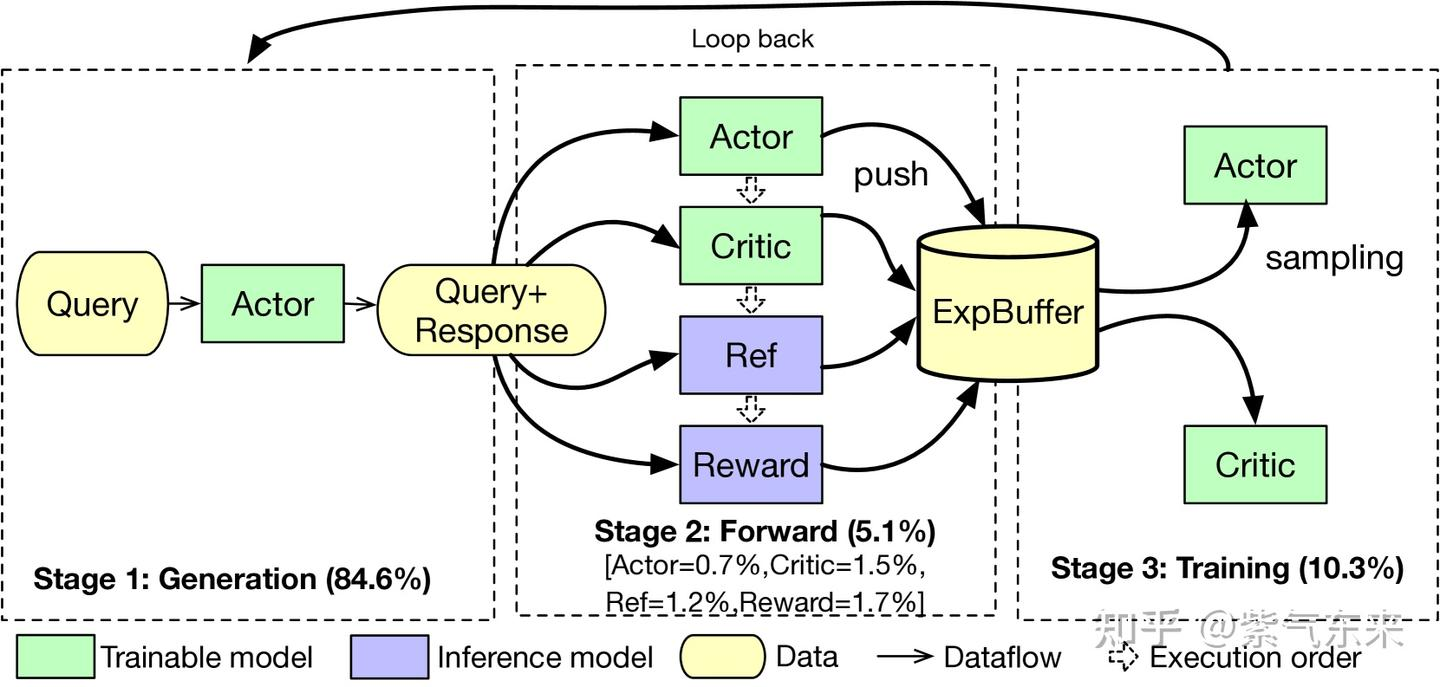
- Generation:输入 prompt,Actor 产生 response 的过程,;
- Forward:按公式要求准备数据。产生的 response 会和 query 一起传给 Actor、Critic、Ref、Reward 这4个模型执行 one-pass forward,forward的数据会放在 Experience Buffer 中, 该步和上一步通常被合称为 rollout(耗时占比超过80%);
- 然后输入actor计算old_log_prob
- 输入critic计算value
- 输入ref model计算ref_log_prob
- 输入reward model计算reward
- Training。从 Experience Buffer 中取数据对 Actor、Critic去进行训练。基于2求得的值计算优势adv,计算loss,更新actor model和critic model。
- 如此重复直到达到规定的步数。

存在哪些问题呢?
- 这三个阶段相互依赖,需要顺序执行;每个阶段内的步骤相互独立,可以并行执行。
- RL的效率瓶颈主要集中在rollout阶段,表现为少数耗时极长的trajectories会严重拉长整个rollout的耗时,而RL workflow一般又是generation和training交替进行的synchronous方式,进而拖慢整个训练流程。Agentic RL框架优化篇
- 我们发现计算old_log_prob、value、ref_log_prob、reward之间是不存在数据依赖的,是可以并行的,单纯的串行执行效率较低。
- 默认这些模型都会放在同一个集群中,这样会存在并行设置等问题,从而增加通信开销。
- 通信开销增加。单个大模型就已经很大了,三个或者四个大模型全部放在一个集群中,爆显存的风险会大大增加,因此需要增加模型的并行度,比如张量并行度,才能放得下这么多模型。但是增大张量并行度,也会导致通信开销增大。
- 所有模型共用这个集群,导致它们的分布式策略会受到限制。训练与推理的计算负载特性明显不同。对于generator推理,希望增加推理速度,因此希望张量并行度设置得小一些;actor或critic训练,会占用大量显存,因此希望张量并行度设置得大一些。这样就会产生矛盾。 因此,可以将不同角色放置在不同的集群中。这样就不会造成并行度的影响了。同时注意到在第一个阶段generator推理样本和最后一个阶段actor训练的时候使用的模型是相同的。因此actor和generator在一个集群上;critic也有推理和更新,也放在同一个集群上;其他角色在另外的集群上。多个角色放在同一个集群上的策略,就叫colocate。
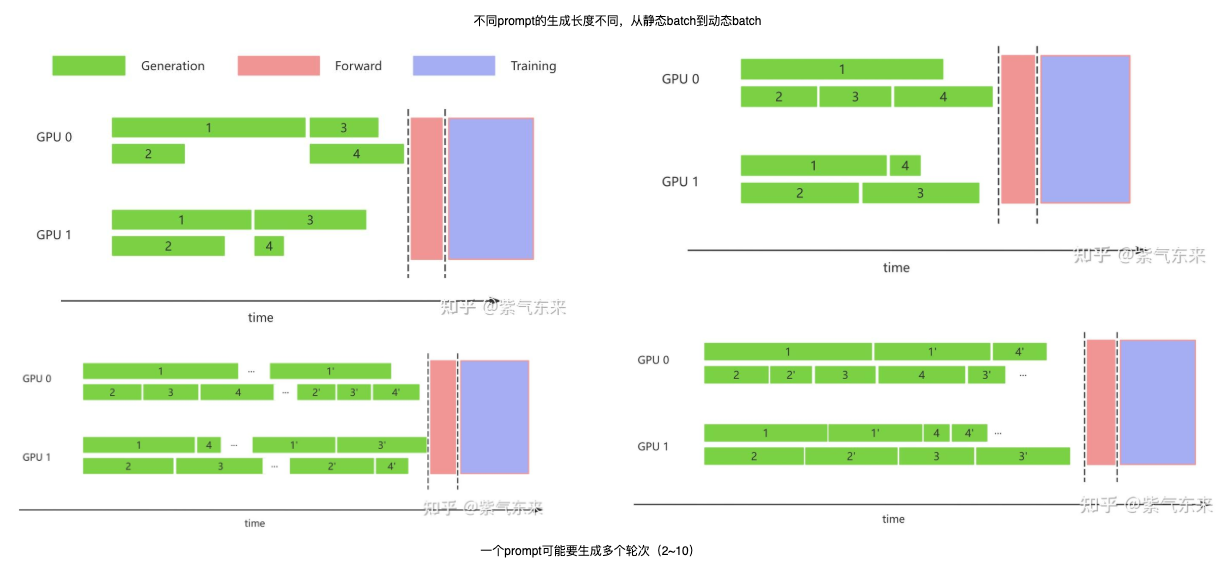
由于涉及的模型较多,出现众多分布式策略,包括平铺策略、交错策略、训推分离策略、时分共用策略(即colocate)。仅以generate 阶段来说,就有如下缩短时间的方式
改进:
- 串行实现就是单控制流,并行实现就是多控制流(但是彼此之间状态同步较难管理)。它们的数据流如下图所示:
 verl的数据流可以大致理解为,虽然表面上还是串行,但是ref到critic,critic到RM是异步的操作,因此并不会阻塞住,实际上它们三个是并行执行的。因此兼具了代码的简洁性和实现的高效性。
verl的数据流可以大致理解为,虽然表面上还是串行,但是ref到critic,critic到RM是异步的操作,因此并不会阻塞住,实际上它们三个是并行执行的。因此兼具了代码的简洁性和实现的高效性。 - verl为了实现上面的colocate的策略,进行了一些额外的优化和改动。RayResearchPool和 HybridEngine(针对actor和generator共置) 对于verl的核心改进,个人理解是通过使用ray框架,异步+并行执行解决了状态同步的问题,driver进程管理传输数据解决了数据通信的问题。以及半colocate的方案与修改权重切分的方案,解决了模型放置的问题。
- 在 AReaL 实现了中一个纯异步的方案,即解耦生成和训练,分别在独立的 GPU 集群上运行。生成节点持续生成新输出而不等待,而训练工作节点在收集到一批数据时随时更新模型。
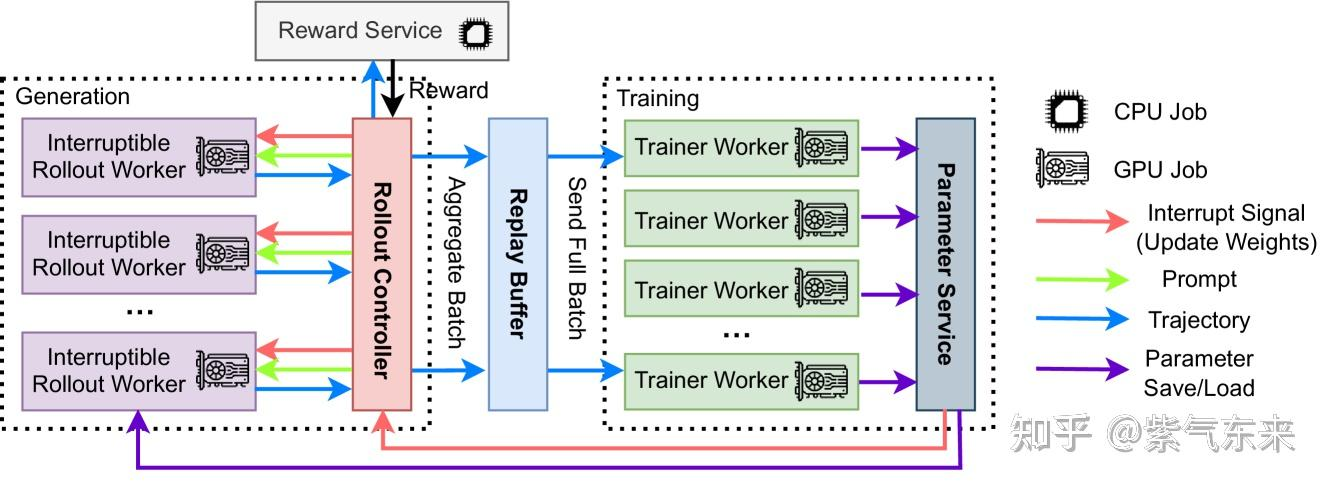
事实上,极致的异步就是 off-policy,而 off-policy 则有更高的样本效率,从另一方面来了,off-policy 本质等同于 SFT 和 DPO,这样 SFT 与 RLHF 的概念又再次被模糊
Task-Separated
LLM强化学习后训练框架大致可以分为共置式(Task-Collocated)与分离式(Task-Separated)两类。共置框架下,各个计算任务部署在整个集群上串行执行,构成一个时分复用的系统;而分离框架则允许部分或全部计算任务布放在不同的设备,构成一个空分复用的系统。从25年开始,分离式架构逐渐成为了主流(其实很多共置式框架也支持把诸如Reference Inference等计算分离部署,但这里我们主要关注Actor Rollout和Actor Update是否分离)。背后的原因主要是:提高效率与降低成本。既然分离式架构这么好,为什么之前大家用得并不多呢?这就和分离式架构先天的缺点有关了。
- 强化学习算法里有多个计算任务,其中计算任务之间有很复杂的数据依赖。
- 各个计算任务之间的数据依赖具有动态性。强化学习中的Response是动态生成的,我们很难在一开始就精确预测每个Sample的Token总量。因此,如果我们在训练开始的时候按照Sample数在各路DP之间切分数据,会造成负载不均,影响训练效率。
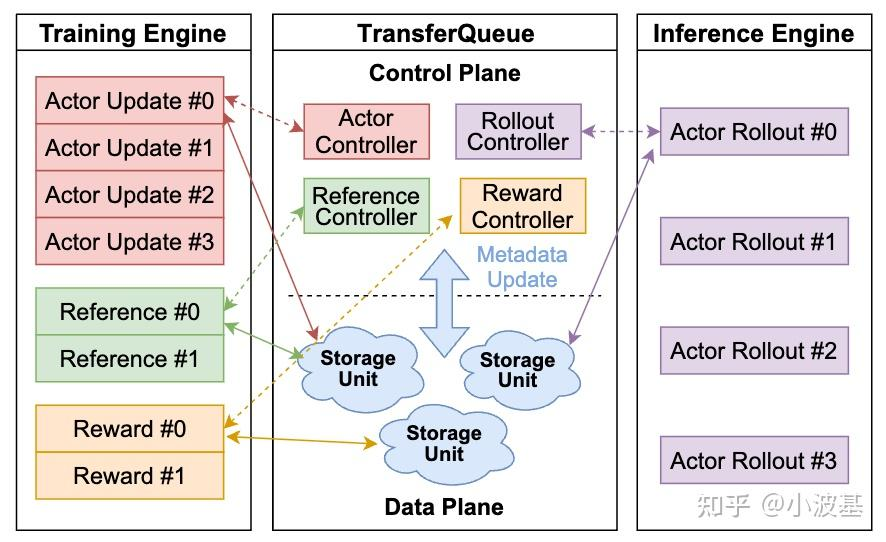
- 传统的On-Policy算法要求训练和推理采用相同版本的模型,那么在分离式架构下,推理生成一个Global Batch的数据后就只能干等训练任务完成,并把新的模型参数加载好之后才能进行下一个Global Batch的推理,从而在Iteration之间造成大量空泡。 既然后训练里数据依赖关系那么复杂,我们就不妨设计一个数据的“转运港口“,管理整个系统中的数据流动。数据的上游生产者将处理好的数据”装箱“发送至TransferQueue,TransferQueue将这些数据“拆箱”并保存起来,并在下游消费者请求数据时,重新”打包“并发送过去,实现计算任务间数据的动态路由。
- 各个计算任务之间不再有显式的数据依赖关系。TransferQueue作为一个中心化的数据组件,把各个计算任务分离开,我们就不再需要手动编排各个计算任务之间的输入输出,也无需在时间轴上调优每个任务的开始和结束
- 数据的调度粒度变得更精细。TransferQueue在“拆箱”与“装箱”的过程中,实现了Sample粒度的数据管理。只要系统里凑够了一个Micro Batch的数据,不管之前是由哪个生产者实例生成的,都可以及时调度给下游的消费者实例,实现了细粒度调度,有助于缓解快慢卡问题,减少了任务之间的等待。
- 最后,TransferQueue具有整个Global Batch的全景视角,在上述重组调度过程中可以便捷地实现多种负载均衡算法,进一步增加系统吞吐。
理念
豆包大模型团队发布全新 RLHF 框架,现已开源! 待细读。
在深度学习中,数据流(DataFlow)是一种重要的计算模式抽象,用于表示数据经过一系列复杂计算后实现特定功能。神经网络的计算就是典型的 DataFlow ,可以用计算图(Computational Graph)来描述,其中节点代表计算操作,边表示数据依赖。大模型 RL 的计算流程比传统神经网络更为复杂。在 RLHF 中,需要同时训练多个模型,如 Actor 、Critic 、参考策略(Reference Policy)和奖励模型(Reward Model),并在它们之间传递大量数据。这些模型涉及不同的计算类型(前向反向传播、优化器更新、自回归生成等),可能采用不同的并行策略。传统的分布式 RL 通常假设模型可在单个 GPU 上训练,或使用数据并行方式,将控制流和计算流合并在同一进程中。这在处理小规模模型时效果良好,但面对大模型,训练需要复杂的多维并行,涉及大量分布式计算,传统方法难以应对。
大模型 RL 本质上是一个二维的 DataFlow 问题:high-level 的控制流(描述 RL 算法的流程)+ low-level 的计算流(描述分布式神经网络计算)。近期开源的 RLHF 框架,如 DeepSpeed-Chat、OpenRLHF采用了统一的多控制器(Multi-Controller)架构。各计算节点独立管理计算和通信,降低了控制调度的开销。然而,控制流和计算流高度耦合,当设计新的 RL 算法,组合相同的计算流和不同的控制流时,需要重写计算流代码,修改所有相关模型,增加了开发难度。与此前框架不同,HybridFlow 采用了混合编程模型,控制流由单控制器(Single-Controller)管理,具有全局视图,实现新的控制流简单快捷,计算流由多控制器(Multi-Controller)负责,保证了计算的高效执行,并且可以在不同的控制流中复用。
veRL:All in RL元年的必修课RL 训练任务可被视为一种数据流(DataFlow),比如 RLHF的DataFlow主要可以分解为以下三个阶段:
- 第一阶段:回复生成(Generation/Rollout):Actor 模型(一个预训练或微调的 LLM)使用一批提示(prompts)自动回归地生成回复(responses),这一步执行 LLM 推理。这一步步骤通常称为 Rollout,也是常常是 RL 中时间占比 80% 以上的热点部分。
- 第二阶段:经验准备(Preparation):使用提示和生成的回复,通过各自模型的单次前向计算,对生成的回复进行评分。这个阶段通常涉及以下模型:
- Critic Model:计算生成回复的值(values)。
- Reference Model:计算生成回复的参考对数概率,它通常是 Actor 模型在 RLHF 之前的版本,用于限制 Actor 模型在训练过程中偏离过远。
- Reward Model:计算生成回复的奖励(rewards)。奖励模型通常是一个基于人类偏好数据进行微调的 LLM,其语言建模头被替换为标量输出头。
- 第三阶段:训练(Training):Actor 模型和 Critic 模型使用前两个阶段产生的数据以及相应的损失函数进行更新。这个过程就是 LLM 训练过程。Actor 模型的训练目标是最大化奖励模型给出的奖励,同时避免偏离参考策略过远 。Critic 模型的训练目标是准确预测状态的Value。
R1 出现后,RL 从 Human Alignment 向 Reasoning 转变,除对齐任务外,还可用于代码生成、数学推理等领域。这些任务有明确 ground truth,可通过评估代码在测试用例中的正确性或验证数学结果准确性确定。奖励模型可用非神经网络的奖励模块替代,如代码生成任务用沙箱环境评估执行结果,数学推理任务用奖励函数验证结果正确性。
将工作流抽象成DataFlow 并不稀奇,比如在线推理服务微服务MLOps pipeline,每个节点都是一个在线的微服务,每个微服务的实例也可以运行在多个 GPU 上,例如 vLLM/SGLang的并行推理服务。RL DataFlow 有几个独特的特点,使得为其特定设计一个 RL 训练变的必要。
- RL 训练是离线任务,这一点比在线任务挑战更小,不需要考虑并发请求、扩缩容、负载均衡等问题。
- RL Actor 的 rollout 和 train共享权重。这也是 RL DataFlow的特色,同一个模型训练又生成,是有状态的。这也是设计 RL 定制训练框架的主要动机,很多重要功能都是围绕这一特点进行设计。
RL 训练框架要解决的问题是:
- 灵活定义 DataFlow
- 将定义出来的 DataFlow 在 GPU 集群上高效执行
一个完美的 RL 训练框架,希望为 DataFlow 的每个节点灵活定义 Placement 和 Parallelism。Placement 表示模型放置在哪些卡上,如下图所示,可以 colocate 所有模型相同 GPU 上,每个模型放在单独设备上,还有混合的方式。Parallelism 则是模型并行方式,有 ZeRO、TP(Tensor Parallel)、PP(Pipeline Parallel) 等策略。在pre-LLM时代,RL 的每个节点在单个 CPU/GPU 上进行。但是 LLM 时代,RL 训练 DataFlow 中每个节点都需要多 GPU 上分布式执行。这导致在 veRL 出现之前,面向 LLM 的 RL 训练框架难以平衡编程灵活性和分布式执行效率的问题。比如,一些实现限制了编程灵活性,每个 DataFlow 节点是一个运行在独立资源上的的并行程序,不同节点通过定制化的 P2P 通信串联起来,构成完整 DataFlow,这导致可编程性很差,比如 NemoAligner。在另一些实现限制了DataFlow 的 Placement 和 Parallelism方式,比如 DeepSpeed-Chat,不同DataFlow 节点在同一个程序中运行在同一份资源上,互相抢占显存,导致效率很低。
single-controller + multi-controller:
- veRL 借助混合控制方式,在一定程度上解决了数据流(DataFlow)灵活定义与高效执行的问题。具体而言,它在不同层级分别采用了单控制器(single -controller)和多控制器(multi - controller)两种模式。其中,单控制器负责控制,多控制器负责计算。具体来说:在模型(DataFlow 的节点)之间(Inter-node level),HybridFlow 采用了single-controller模式。有中央化的控制器负责协调不同的模型在 RLHF 数据流中的执行顺序和数据传输。这个单控制器运行在一个独立的进程中,类似 master。 它保证了 DataFlow 定义的灵活性,而且在模型数量不多的 RLHF 数据流中,控制分发的开销可以忽略不计。veRL 的 single controller 使用 Ray 实现,也是发挥大家常说的 ray 适合做胶水层的作用。在每个模型内部的分布式计算(DataFlow 的一个节点内)中(Intra-node level),HybridFlow 采用了multi-controller模式。这意味着每个计算设备(例如 GPU)都有自己的控制器,独立管理其上的计算任务,就是的 SPMD 方式运行的,也就是复用sglang/vllm/torchdpp 启动推理/训练的方式。
- 灵活 Placement+Parallelism:用户定义了一个 DataFlow,veRL能够高效执行出来,并行保持,veRL 还需要相对自动地帮用户解决如下事情:
- DataFlow node 之间如何传递 tensor:实际的 tensor 数据传输通常发生在计算 GPU 之间,而不通过中央master 节点。因为不同 node 的 Parallelism 方式不同,导致输出 tensor 的 sharding 方式是不同的。比较呆板实现就是在每个 node 算完 gather,然后 node 计算前去 shard。veRL 定义数据依赖和传输协议简化用户的编程:对于节点之间的 tensor 传递,会通过 @register 装饰器将节点的操作与预定义的若干种传输协议关联起来。传输协议定义了如何收集发送节点的输出以及如何分发到接收节点的输入。
- Async DataFlow Execution:通过 Ray 的 future 机制 实现异步数据流执行,使得没有依赖关系的节点可以并发执行。
- 3D-HybridEngine,尽管我们期望能够任意配置 Placement,但对于 Actor 而言,将 Generation 和 Train 进行并置(colocate)的方式最为有效。veRL 最核心的功能是 3D-HybridEngine。
- Auto-Mapping,single-controller 做控制,实现了对 DataFlow编程的灵活性。给定一个模型如何找到适合的Placement+Parallelism 方法?论文中提出了 Auto - Mapping 算法来搜索每个 node 最佳 Parallelism 和 Placement 方式,但我认为在实际应用中仍需依赖基于经验的试验。最后试验结果部分也表明:在较小的 GPU 集群(例如 16 到 64 块 GPU)上,将所有模型共置 (colocate) 在同一组设备上通常能获得最佳性能。在较大的 GPU 集群(例如 96 到 128 块 GPU)上,分割 (split) 策略(例如将 Actor 和 Reference Policy 放在一组 GPU 上,Critic 和 Reward Model 放在另一组 GPU 上)有时会成为最优选择。
ps: 看来还在快速演进中
工程
分布式RLHF武庙十哲上 未读。 梳理了rhlf 框架
RL2:一个极简的后训练框架在 Reasoning 和 Agentic RL 爆火之后,开源训练框架层出不穷,包括 veRL、AReaL、ROLL 和 slime。这些框架主要面向工业界的大规模训练(通常以 Megatron 为后端),并且高度封装,不利于初学者学习与 researcher 开发。因此,我们开发了一个简易的后训练框架 RL2 (RL square, or Ray Less Reinforcement Learning)。
单节点运行
torchrun \
--nproc_per_node=<number of GPUs> \
-m RL2.trainer.ppo \
<args>
def train(self):
for epoch in range(self.config.trainer.n_epochs):
for data_list in tqdm(
self.train_dataloader,
desc=f"Epoch {epoch + 1}",
disable=(dist.get_rank() != 0)
):
data_list = self.rollout(data_list, True, step)
if self.config.actor.kl.coef > 0:
data_list = self.ref_actor.compute_logps(data_list, step)
if self.config.adv.estimator == "gae":
data_list = self.critic.compute_values(data_list, step)
if self.config.actor.kl.coef > 0 or self.config.actor.update_per_rollout > 1:
data_list = self.actor.compute_logps(data_list, step)
if dist.get_rank() == 0:
if self.config.actor.kl.coef > 0:
self.compute_approx_kl(data_list, step)
self.compute_advantages(data_list, step)
self.actor.update(data_list, step)
if self.config.adv.estimator == "gae":
self.critic.update(data_list, step)
self.rollout.update(self.actor, step)
step += 1
if step % self.config.trainer.test_freq == 0:
for data_list in self.test_dataloader:
self.rollout(data_list, False, step)
PS: train的前几个步骤,是像data_list 加入新的列存各种值,最后基于各个列的值计算loss,反向传递并更新参数?
FlexRLHF
稳定性
训练稳定性,一般指机器别坏、网络别断、显卡别掉。但在 RL 场景下,更像是在说训练怎么才能不崩,怎么才能训更多步。若在指标起飞、打分猛跌时基本宣告这一把训练结束了:要么想办法救一下,要么就再开一把。
留下评论