单元测试的新解读
前言
为什么国内的开发团队普遍忽视测试这个大家都知道是正确的软件工程实践?因为测试做简单了没用,做复杂了成本太高,开发效率低,国内业务变化快,没必要。
单元测试,只是测试吗?单元测试除了是一种测试手段外,更是一种改善代码设计的工具,容易写单测的代码往往也具有更加良好的设计。这里需要强调一下 “工具” 属性,工具能放大人的智力或者体力,让干活的时候不会这么累,比如你去种树带把铲子,你肯定不会把铲子当成负担的,因为他是你种树的工具,你写 Java,肯定不会因为 IDEA 启动时间长,就把它当成一种负担,因为 IDEA 也是你写 Java 的一个工具,很多人把写单测当成一种负担,往往就是没有意识到”单测”是一种工具,单纯把他当成一种测试。
许式伟:我们不把推广单元测试看作是让大家去多做一件额外的事情,而是规范大家做单元测试的方法。为什么这么说?因为实际上单元测试大家都会去做,很少有人会不经验证就直接交付。但是验证方式上可能有各种 “土” 方法,比如用 print,用可视化的界面做输入测试,用调试工具做单步跟踪等等。但是这些方法代价其实一样不低,但是却不可回归,正确与否还需要人脑临时去判断。更重要的是,这些方法最大的问题是没有办法去固化已知的 Bug,最大程度保留下来我们的测试案例。这其实才是最核心的一个认知问题:我们应当重视我们的测试代码,它同样也是我们的开发成果,理应获得和模块的功能代码同等重要的地位,理应被保留下来。
那些年,我们写过的无效单元测试编写单元测试用例的目的,并不是为了追求单元测试代码覆盖率,而是为了利用单元测试验证回归代码——试图找出代码中潜藏着的BUG。PS:参与了一个tob的系统, 因为性能问题整体重构,接口不变,这个时候如果有完整的e2e 测试用例,就可以方便的评估重构的 正确性。 反过来说,你交付的系统 如果没有这种整体、部分推倒重来的诉求,体会就不会深刻。很多toc的业务需求 只是一次性的需求实现,很多公司、小组不认可重构价值,更倾向于当裱糊匠。
为了单元测试而重构
含有核心业务的代码应该首先思考如何让主体业务逻辑可以写无 Mock 单测
@Service
public class ShopService{
@Resource
private CreditCardService creditCardService;
public void buyBread(CreditCard creditCard){
Bread bread = new Bread();
creditCardService.change(creditCard,bread.getPrice());
}
}
假设这是一个商店系统,里面有一个买面包的方法,里面会调用银行提供的信用卡服务 creditCardService 来扣除传入的信用卡的钱。这段程序如果使用 Mockito 的话,估计你很快就能写出测试了,只需要把 creditCardService 给 Mock 掉,然后验证它传入的参数就可以了。如果总是像上面这样思考的话,单测对于你改善代码设计就没什么帮助了。我们在给代码写单测的时候不应该上来就思考用什么样的工具来测试代码,而是应该思考如何重构代码,才能让代码变得更加容易测试。
@Service
public class ShopService{
public Payment buyBread(CreditCard creditCard){
Bread bread = new Bread();
return new Payment(creditCard,bread.getPrice());
}
}
public class Payment{
private final CreditCard creditCard;
private int amount;
}
上面这段代码,我们换个角度,思考下如何重构代码,才能让这段逻辑不需要 mock 就能测试?其实非常简单的一个办法是,返回一个计划,而不是立即就执行外部调用。此时这一段逻辑不需要 Mock 就可以测试了,只要校验方法返回的 Payment 对象里面的属性是否正确即可。可以把 Payment 按照银行卡分组统一扣钱,这样就可以减少 rpc 调用的次数,以后如果有需要的话,甚至可以直接将 Payment 作为消息发出去,到另一个系统执行,业务层根本无需关心 Payment 最后是怎么执行,只需要在付款的时候生成一个 Payment 就可以了。
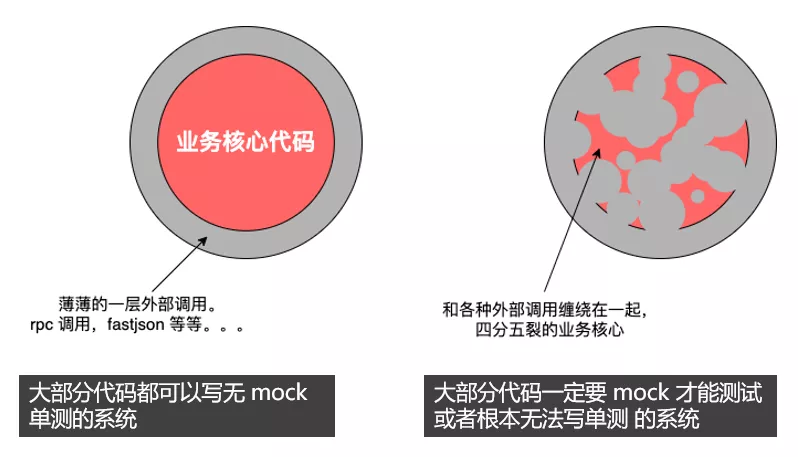
如果你的系统大部分代码都一定要 Mock 才能测试的话,或者根本无法测试的话,就像右图一样,说明你的业务根本就没有自己的核心逻辑,而是和各种外部调用缠绕在一起。
另外需要说明的是,图中红色的部分才是单测真正能够起作用的场景,因为它是比较稳定的业务逻辑,而且红色部分的单测也比较好些,只需要传几个参数进去,然后校验一下返回值就行了。灰色的外部调用部分理论上不写单测也无所谓,因为外部调用是不稳定的,即使你跟对方约定好了出入参数,他依旧有可能返回不符合约定的参数,或者直接就发生了网络错误,这一部分是集成测试发挥的场景。为什么在我们的系统里,大家都觉得单测没用,其实我也觉得单测对我们现在的系统没什么用,因为我们现在系统的主体代码就像右图一样,大部分都是灰色的外部调用,单测能够发挥作用的领域少之又少,即使写了覆盖率 80% 的测试用例,又能测出来啥?
为什么单测能够验证代码结构的合理性?
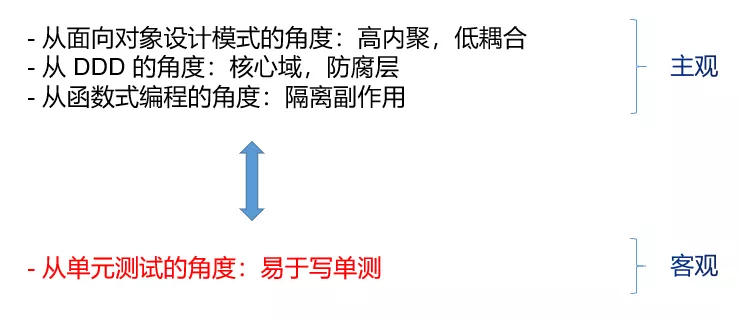
上面这三种评价代码的方式其实都是比较“主观”的,什么样的代码才能叫“高内聚”,在每个人看来可能都不一样。但是对于是否易于写单测,大家的标准基本是一样的,难写单测的系统给谁都很难写。而好写单测的代码一般都满足编程范式所倡导的原则,所以写单测的难易程度可以作为一个非常客观的代码质量评价指标。
如果有个程序员跟你说我程序的性能达到了多少 QPS,你肯定会立马拿起测试工具就去测,看到底能不能到达这个 QPS。但是如果有程序员画了框框图说他的代码分成了 A B C 模块,要怎么验证他的代码真的分成了这几个模块呢?很简单,你看看每一个模块能否脱离其他模块单独测试就可以了,如果单独测试非常困难,那就说明模块并没有真的分开,而是或多或少耦合在了一起。
单元测试的运行速度重要吗?
很多人会觉得单测反正也不是系统中的代码,运行的快慢无所谓,然后写出很多其慢无比的单测,以至于系统全量跑一次单测要几十分钟。这样的话就完全偏离了单测的定位,单测的目的就是为了方便快速迭代,改了两行代码就可以在本地用 30 秒到几分钟的时间全量跑一次单测来确定影响范围,而不是每次都要通读系统源码才能知道改动的影响范围,这样新人很快就可以大胆改代码了,而不是先花几个月通读系统源码,或者先踩好几个坑,才能上手干活。那些全量跑单测要几十分钟的系统,他的开发者根本就不会在本地全量运行单测,每次都在 aone 上跑半天才知道单测不过,这样的单测就形同虚设了。
违背这个原则的典型反例,就是在单测中启动 Spring。
数据驱动测试
用例数据尽量和测试逻辑分离:使用多组测试数据是否就意味着多写很多代码呢?并不是,我们只要注意将测试用例的逻辑与数据分离就可以,测试代码依次读取测试数据,校验其是否符合预期。这样的逻辑与数据分离的测试一般称做 “数据驱动测试”,常见的单元测试框架都会提供这种支持。
public void testAdd(){
assertEquals(2,AddUtil.add(1,1));
assertEquals(4,AddUtil.add(2,2));
assertEquals(0,AddUtil.add(1,null));
assertEquals(0,AddUtil.add(null,1));
assertEquals(0,AddUtil.add(null,null));
}
基于 Spock 的数据驱动测试。大家所熟悉的 junit 框架也是可以做的
def testAdd(Integer a,Integer b,int expect){
expect:
assert expect == AddUtil.add(a,b)
where:
a | b | expect
1 | 1 | 2
2 | 2 | 4
1 | null | 0
null| 1 | 0
null| null | 0
}
其它
事故驱动开发TDD 为什么落不了地?大多数业务系统的生命周期都很短,日常的迭代就像是在没完没了地做 MVP-Minimum Viable Product 版本的系统。连稳定的业务逻辑都没有,想要维护和业务保持一致的测试还是比较难的。解决浮出水面的问题才是大老板的 KPI,也是帮助你和老板一起升官发财的不二法宝。而那些还潜伏在水面下的,没有发生的问题,提前做规划去预防?这不是给你老板添堵吗?没有问题就做预防?最后沦为无用功。
软件研发的道德情操开发者不能只考虑自己,也不能只考虑机器,他必须要学会考虑其他开发者的感受,做出有益于其他开发者的行为,如此整个研发组织才能繁荣。在大型组织中,开发者每天都依赖其他开发者的中间产物进行工作,而自己也在不断生产中间产物:文档、代码、服务。良好的软件研发道德,或者有时候也会认为这是良好的工程师文化,就是大家形成一种以交付高质量软件中间产物为荣,以交付低质量软件中间产物为耻的共识文化。然而在实际的情况下,我们往往看到很多组织未能形成这种共识文化。这种失效的直接原因是:
- 生产高质量软件中间产物的行为没有得到应有的奖励。
- 生产低质量软件中间产物的行为没有得到应有的惩罚。
当我们和任何一个研发的 TL 讨论软件质量的时候,没有一个 TL 会和你说软件质量不重要。但是我们都明白,一件事情的关键不在于那个人怎么说,而在于那个人怎么做。而在软件研发道德的失效的组织和团队,我们无一例外地看到:当质量和时间发生冲突的时候,优先级被放在了时间上,质量被牺牲了;当质量和功能范围发生冲突的时候,优先级被放在了功能范围扩大上,质量被牺牲;在做绩效评定的时候,并没有认真考核研发在质量上做的贡献,换言之,对一个研发同学的短期业务结果,规划思考能力,质量贡献等角度综合评定的时候,质量贡献往往被忽略了。
我以前一直认为软件质量的问题,研发效率的问题,是技术的问题,是因为先进的技术没有得到理解和应用;但是行文至此,相信大家能理解,软件质量和研发效率的核心不是技术问题,而是一种类似社会学的问题,是人的问题。既然是人的问题,就必须从改变人的行为入手,这里首先要让质量的信息透明化,其实是要让质量相关的行为得到应有的评价。透明化是合理评价的前提。具体包括:
- 代码全面开放:让每个研发提交的代码都能被其他人看到(git blame 是个很好用的命令),代码质量的好坏自然一目了然;
- 开发文档全面开放(也需要有版本化记录):让每个研发的设计和思考都能被其他人看到;
- Code Review 机制的推行,让代码进入主干之前都能被同事认真审视;
- CI Dashboard:是否有足够的自动化单元测试覆盖等等,也得到透明的展示。
单元测试运行原理探究 未读
5个关键问题让单元测试的价值最大化 未细读。PS:一般多人协同(尤其是陌生人协同)做框架开发看重一些,业务开发往往很难坚持,老实讲,很多业务的价值都读不起程序员的时间成本。
留下评论