另一种微服务架构Multi-Agent
简介
PS:与其说是多agent 不如说是多模型协同,每个模型擅长的不同。agent之间部分记忆不共享(也事太多了),总要有一个管控agent,会有控制权转移的过程。解决复杂问题业界普遍还是在 agent model、workflow、multi-agent 打转转。
在处理复杂问题时,就应该用更多的 Token 换取更好的效果这样的「力大砖飞」策略。为什么需要多智能体系统?会有两个截然不同的观点。
- 反方:模型越强大,所有 AI Agent 都有可能被“模型即产品”所替代,不需要多智能体系统。
- 正方:模型再智能,也无法主动甄别所有环境感知(Context),每个细分领域的 Agent,调研类 Agent、Coding Agent、表格 Agent,都需要花大量的时间,少则半年多则一年,去设计环境感知(Context),减少模型幻觉,Agent 会像互联网 APP 那样百家齐放,而不是一家独大。
这个需要时间来证明。单只从技术视角看,支持多智能体能力不失为一种稳健的选择。这样既保留了面向生态和未来的扩展性,也不妨碍我们专注于优化单智能体的能力。此外,多智能体不是一开始就需要的,而是在单体架构遇到根本性限制时的自然演进。当然如果是简单的单线程任务或需要紧密协作的任务不适合多智能体。
AI 工程化的路径:单体LLM → 流水线架构 → 多智能体架构。每一次架构变迁都是为了解决具体问题而自然涌现的。从单体到流水线,再到多智能体,技术选择的背后是对复杂性管理的不断深化。不要为了技术而技术,要为了解决问题而技术。多智能体不是“把大模型套上更多提示词”,而是“把复杂问题拆解成可治理的自治单元”,并通过可观测、可控的交接协议把它们编排起来。
Single-Agent面临的困境/单 agent 能走多远
真的可以有通用的 God Agent,它可能什么都会吗?GodAgent 不会存在,就好比世界上没有全知全能的人。
随着任务复杂度增加,单一智能体需要理解的语境和工具使用面临上下文窗口限制,导致性能下降。多智能体协作通过动态任务分解、专业化分工和协同工作克服这一挑战。在当前的现实中,在开发一个单智能体系统时会遇到的问题:
- 上下文污染。比如智能体可用的工具过多,在决定下一步调用哪个工具时效果不佳。
- (错误传递问题)在复杂推理链中,早期步骤的错误会随着推理过程不断放大,多步推理任务中,错误累积导致的最终答案错误率可达单步错误的3-5倍。错误需要跨任务隔离。单 agent 的统一 context 会让一处错误的中间结果被后续所有步骤看到,错误无法被隔离。
- 上下文过多对于单个智能体来说过于复杂,难以跟踪。(注意力分散/稀释问题)实验显示,在32k tokens的上下文中,模型对开头部分信息的回忆准确率比中间部分高出40%以上。(短期记忆偏差)定量分析表明,在长对话中,模型对最后20%内容的依赖度比前80%高出35%左右。
- 系统中需要多个专业领域(如规划器、研究员、数学专家等),同一个 system prompt 很难让 agent 在法律条文解析和财务模型计算上都做到足够深,通才在需要专家判断的场景是软肋。PS: 模型可以持续强大到什么都会么?
- 单体架构在扩展新功能或修改现有功能时,往往需要对整个系统进行调整,成本高且风险大。PS:微服务里的单体架构 vs 微服务架构
- 需要真正的并行执行。比如三个 Agent 并行干活,前端、后端、测试同时进行,时间缩短到原来的三分之一。
- 能够同时拆解出大量互不依赖的子任务。
- 多Agent的架构特别擅长处理需要广度优先(BFS)处理的问题,因为这类问题需要并行探索多个相互独立的线索。反之需要所有智能体共享同一个上下文(如实时协作编辑)的任务不适合用多智能体
- 信息量远超单个上下文窗口承载能力的场景,需要通过多个agent分头处理来突破记忆限制
为了解决上述的问题,可以考虑将应用拆分为多个更小的独立智能体,并将它们组合成一个多智能体系统,期望达到的效果
- 模块化:独立的智能体使开发、测试和维护变得更容易;不同服务可以并行处理任务,某个服务出现问题,其他服务可以继续运行。
- 专业化:可以创建专注于特定领域的专家智能体,或者简单领域用小模型,这有助于提高整个系统的性能和资源消耗。每个Agent可能有不同的工具类型可用(理想少于10个),也可能有不同的记忆系统。例如,让GPT-4负责创意生成,Claude处理逻辑推理,专业微调模型应对领域知识。
- 控制:可以明确控制智能体之间的通信方式(而不是依赖于函数调用)。 在处理复杂任务时,系统会将任务分解为多个子任务。每个子任务由专门的智能体处理,这些智能体在特定领域具有专长。智能体之间通过持续的信息交换和任务协调来实现整体目标,这种协作方法可能产生智能涌现,即系统整体表现超越单个智能体能力之和。
OpenAI 是以 AGI(Artificial General Intelligence) 为愿景的公司,现在的 Agent 在一定程度上可以看作 AGI 的代偿 —— 除工具使用外,规划和记忆本是 LLM 所应覆盖的范畴。如果 LLM 自身能力增强,一切还可能重新洗牌。不过在那之前,Retrieve 和 Task Decomposition 应该会长期把持 LLM 显学的位置。Agent 是角色和目标的承载,LLMs、Plans、Memory 和 Tools 服务于角色扮演和目标实现。那么,自然的,服务于相同或相关目标时,多个 Agent 之间可以共享 thread context,但需要保持自身权限的独立,即 Multi-Agent。
与工作流模式对比:工作流模式适用于 Bot 技能流程相对固定的场景,在该模式下,Bot 用户的所有对话均会触发固定的工作流处理。在 AI 比你懂自己之前,场景分流方法将长期有效。多 Agent 模式通过以下方式来简化复杂的任务场景。
- 您可以为不同的 Agent 配置独立的提示词,将复杂任务分解为一组简单任务,而不是在一个 Bot 的提示词中设置处理任务所需的所有判断条件和使用限制。
- 多 Agent 模式允许您为每个 Agent 节点配置独立的插件和工作流。这不仅降低了单个 Agent 的复杂性,还提高了测试 Bot 时 bug 修复的效率和准确性,您只需要修改发生错误的 Agent 配置即可。
在 Multi-Agent 系统架构中,由众多独立自治的智能体代理组成,它们拥有各自独特的领域知识、功能算法和工具资源,可以通过灵活的交互协作,共同完成错综复杂的决策任务。与单一代理系统将所有职责高度集中在一个代理身上不同, Multi-Agent 系统则实现了职责和工作的模块化分工,允许各个代理按照自身的特长和专长,承担不同的子任务角色,进行高度专业化的分工协作。此外, Multi-Agent 系统具有天然的开放性和可扩展性。当系统面临任务需求的不断扩展和功能的持续迭代时,通过引入新的专门代理就可以无缝扩展和升级整体能力,而无需对现有架构进行大规模的重构改造。这与单一代理系统由于其封闭集中式设计,每次功能扩展都需要对整体架构做根本性的修改形成鲜明对比。此外,资源成本优化和并行处理,如果所有任务都指派给同一个性能最强的智能体,资源消耗大。采用多智能体系统,每个智能体系统因为只擅长各自领域的任务,参数更小,能显著降低资源消耗。另外,每个智能体可以根据自身任务需求分配计算资源、时间等,而且多个智能体可以同时处理不同任务,实现并行处理。容错性和可靠性,对于多智能体系统,某个智能体出现故障,其他智能体可以继续工作,通过智能体之间的协作和备份机制,确保系统整体的稳定性和可靠性。PS:跟单体系统与微服务系统的对比一样一样的。
以rag系统为例
- 简单的rewrite ==> retrieve ==> generate
- rag的尽头是agent
rewrite ==> retrieve ==> generate可以解决的问题终归有限, 这里涉及到很多花活,比如拆分子问题、联网、ircot等,需要agent 根据当前的已知信息,判断下一步 ==> 行动 ==> 根据观察判断下一步 - rag的尽头是multi-agent 单个agent 可以解决的问题也终归有限,用户的“知识”不只在文档里,也在数据库表里,也是知识图谱里,都编排在一个agent里,对路由器/plan 组件的要求很高,很多时候即便人也无法判断,这时候就要“三个臭皮匠,顶一个诸葛亮”了。 如果LLM能力足够,一个agent 选择tools 就能解决所有问题。实质上还是LLM 能力有限(无法较好的拆解问题,制定plan,也无法较好的判断问题结束),针对某一链路、某一场景进行特化,复查场景采取多角色协作方式。
- MultiAgent: 多个LLM,角色分工明确(角色扮演很重要!),偏向协作解决复杂任务,
- Agent-tools: 单个Agent调用工具(通常为API或功能模块)完成特定功能,偏向任务执行和效率。
从架构的角度,与 single agent 相比,multi-agent 架构更易于维护扩展。即使是基于 single agent 的接口,使用 multi-agent 的实施架构也可能使系统更加模块化,开发人员更容易添加或删除功能组件。目前的技术条件下,无法构建出一个满足所有功能的 single agent,但可以将不同的 Agent 和 LLM 进行组合,构建出一个满足使用要求的 multi-agent。
多Agent拓扑结构
多Agent系统(Multi-Agent System, MAS)是Agent系统的发展趋势,因为它更适用于解决复杂问题求解、分布式任务、模拟社会系统等问题,在多Agent系统中,每个Agent 专注单一领域(通过不同的Prompt、工具和知识库来定义),工具少于10个,团队协作需推理支持否则成功率低(目前成功率<50%)。Multi-Agent(多智能体系统) ,本质上是一群相对独立的智能体在协作。它们可能有各自的目标、各自的状态、各自的上下文,通过通信协议来协调。
其实Multi-Agent也并不是银弹,它引入了两个新的挑战:
- 路由准确率压力。当Sub-Agent数量达到几十上百的时候,主Agent面临着巨大的分类决策压力。一旦主Agent发生错误路由(Misrouting),后续所有Sub-Agent 的努力都将南辕北辙。
- “局部最优”导致的上下文割裂:由于子Agent往往只关注自身任务的局部最优路径,缺乏对全局上下文和用户完整意图的感知,极易出现以下现象:
- 重复执行:比如用户询问“ECS远程无法连接”,Agent A诊断出“资源负载高”;用户追问“为何负载高”,Agent B接手后,因不知晓前文已做过负载检测,可能再次执行相同的查询步骤,造成算力浪费和响应延迟
- 结论冲突:不同Agent基于局部信息得出的结论可能与前文矛盾,导致回答逻辑不自洽,给模型和用户都带来Confuse Multi-Agent为了解决上下文割裂,是可以考虑让Agent之间共享Context历史的。但在工程实践中,这又会带来一个通信带宽的限制问题:
- 信息有损压缩:Multi-Agent在通信的过程中,比如主Agent传递给子Agent的往往是经过Summary或 Rewrite后的上下文,而非原始对话流。这种有损传输很可能会导致关键细节的丢失
- Token爆炸与耗时增长:若为了保证效果,如果强行让模型扩大通信带宽来传递更多上下文,则会迅速引发新的Context Window爆炸,并显著增加LLM的生成时间和整体链路耗时 因此,Multi-Agent也是一把双刃剑:它能通过分工协作突破单点能力的上限,但也引入了复杂的协同损耗。
一个材料
Agent工程能力思考记录过去在微服务的实践上,我们在统一的一套系统框架(HSF)下进行交互,领域的互联以服务接口交互的方式进行,因此在AI时代,未来的系统交付物可能不再是现在的某个服务,而是某个Agent;它与接口最大的差别在于不是一轮input-output,而可能是多轮的,因此协议上的设计需要考虑多轮input-output完成某项任务;
即然单体Agent到多Agent协作是必然的客观演进规律,那么就有必要看一下多Agent协作模式:
| 任务分配机制 | 协作方式 | 冲突解决 |
|---|---|---|
| 集中式任务分配 分布式任务协商 基于角色的任务划分 动态任务重分配 |
平行协作:多Agent并行解决问题 层级协作:管理Agent统筹下级Agent 专家协作:不同领域Agent联合解决问题 |
基于优先级的决策 投票机制 仲裁Agent介入 基于规则的冲突处理 |
可以看到当前市面上关于多Agent协作的讨论,核心是围绕着任务的解决展开的:任务分发、任务处理、任务结果回收;这也是A2A协议引入任务这个概念的原因。
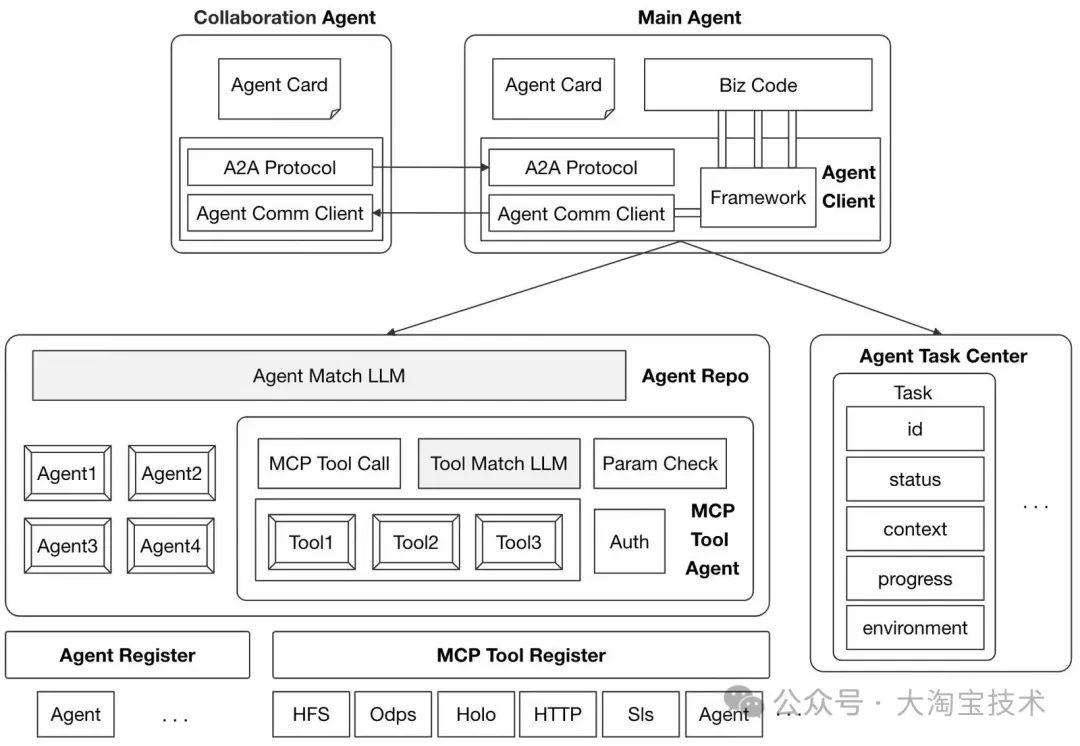
上图是对多Agent协作模块理解的一个简图,从业务主Agent出发,需要基于任务中心恢复当前任务上下文,继续本次任务的处理;接着通过Agent仓库找到需要协同的Agent;我们通过多Agent交互协议与其他协作Agent交互,并在主Agent业务流程中完成结果决策或子Agent的状态透传。
主从架构
- 上下文管理
- 维护完整但精简的上下文。并不是所有信息都同等重要。主 Agent 需要智能地压缩和总结历史信息。Claude Code 使用了一个策略:并不是所有信息都同等重要。主 Agent 需要智能地压缩和总结历史信息。Claude Code 使用了一个策略:
- 构建结构化的决策记录。不要只是简单地拼接所有的对话历史。需要结构化地记录:任务目标和约束;已做出的关键决策;各决策之间的依赖关系;待解决的问题队列
- 动态调整上下文窗口。根据任务的复杂度和当前阶段,动态调整传递给从 Agent 的上下文量。初期探索阶段可以更开放,后期执行阶段需要更精确。
- 从Agent 的设计原则。Agent 不是越智能越好,而是要专注和可控:
- 明确的能力边界
- 标准化的输入输出。从 Agent 的接口要标准化,这样主 Agent 可以用统一的方式调用它们。输出格式也要规范,便于主 Agent 解析和整合。
- 无状态设计。从 Agent 最好是无状态的,每次调用都是独立的。这样可以避免状态管理的复杂性,也便于并行化(当任务确实独立时)。
- 协调机制的关键点。主 Agent 的协调能力决定了整个系统的表现:
- 任务分解策略。并不是所有任务都要分解。主 Agent 需要学会判断:简单任务直接处理;简单任务直接处理;复杂任务分解但保持上下文
- 冲突检测与解决。即使在主从架构下,从 Agent 的建议也可能相互矛盾。主 Agent 需要:检测潜在的冲突;评估不同方案的优劣;做出最终决策并保持一致性
- 优雅降级。当从 Agent 失败或不可用时,主 Agent 应该能够:尝试从其它从 Agent 获取;降级到自己处理;调整任务策略 主从架构的优势与局限
- 优势
- 全局一致性保证主 Agent 作为唯一的决策中心,天然保证了架构决策的一致性。不只是技术栈的选择(比如统一使用 REST 还是 GraphQL),更重要的是接口约定、错误处理策略、命名规范等细节都能保持统一。这种一致性在复杂项目中价值巨大。
- 清晰的决策链路每个决策都有明确的来源和依据。你可以在主 Agent 的对话历史中追踪每个架构决定是如何做出的,为什么选择某个方案。这种可追溯性在调试问题或向他人解释系统设计时非常有价值。
- 优雅的错误处理主 Agent 掌握全局状态,当某个子任务失败时,它可以准确判断影响范围并制定恢复策略。比如,如果数据库设计出错,主 Agent 知道哪些 API 设计需要相应调整。而在去中心化系统中,这种级联影响很难追踪和修复。
- 上下文利用最大化看似串行的决策流程,实际上优化了整体效率:避免了重复劳动(多个 Agent 不会各自生成相似的代码);减少了协调开销(不需要 Agent 间的大量通信);上下文复用充分(主 Agent 的决策历史可以直接传递给从 Agent)
- 局限性
- 主 Agent 成为性能瓶颈所有决策都要经过主 Agent,当需要并行处理多个复杂子任务时,主 Agent 的串行决策会限制整体效率。就像一个项目经理同时管理太多团队,协调成本会急剧上升。
- 对主 Agent 能力的高度依赖系统的智能上限取决于主 Agent 的能力。如果主 Agent 对某个领域理解不深,即使有专业的从 Agent,整体表现也会受限。这就像一个不懂技术的经理,很难充分发挥技术团队的潜力。
- 缺乏真正的协作智能主从架构本质上是”分解-执行-组合”的模式,缺少 Agent 之间的平等协商和创造性互动。在需要头脑风暴或多视角探索的任务中,这种层级结构可能限制了解决方案的多样性。
- 任务分解的粒度难题主 Agent 需要准确判断任务分解的粒度。分得太细,协调成本高;分得太粗,从 Agent 可能无法胜任。而且随着任务复杂度增加,找到合适的分解方式越来越难。
PS: 能力提升自然也就分为了主agent 能力提升和从agent 能力提升
- Anthropic 的 Research 系统采用“编排者-工作者(orchestrator-worker)”模式:主智能体负责整体规划和任务分解,多个子智能体并行执行具体子任务。用户提交查询后,主智能体分析问题、制定策略,并生成多个子智能体,分别探索不同方向。子智能体像智能过滤器一样,利用搜索工具收集信息,最后将结果汇总给主智能体,由其整合成最终答案。与传统的 RAG(检索增强生成)不同,Anthropic 的多智能体架构采用多步动态搜索,能根据中间发现不断调整策略,生成高质量答案。
- 模型必须自主运行多轮,根据中间结果来决定追求哪个方向。线性的、一次性的处理流程无法胜任这些任务。
- 主导智能体将查询分解为子任务,并向子智能体描述它们。每个子智能体都需要一个目标、一个输出格式、关于使用哪些工具和来源的指导,以及明确的任务边界。没有详细的任务描述,智能体就会重复工作、留下空白,或找不到必要的信息。
- 根据查询的复杂度来调整投入。 智能体很难判断不同任务的适当投入量,所以我们在提示中嵌入了扩展规则。简单的事实查找只需要1个智能体进行3-10次工具调用,直接比较可能需要2-4个子智能体,每个进行10-15次调用,而复杂的研究可能需要超过10个子智能体,并有明确分工。这些明确的指导方针帮助主导智能体高效分配资源,并防止在简单查询上过度投入。
- 让智能体自我改进。当给定一个提示和一个失败模式时,它们能够诊断出智能体失败的原因并提出改进建议。
- 引导思考过程。 扩展思考模式(Extended thinking mode)引导 Claude 在一个可见的思考过程中输出额外的令牌,可以作为可控的草稿纸。主导智能体使用思考来规划其方法,评估哪些工具适合任务,确定查询复杂度和子智能体数量,并定义每个子智能体的角色。我们的测试表明,扩展思考改善了指令遵循、推理和效率。子智能体也会进行规划,然后在工具返回结果后使用交错思考(interleaved thmultiinking)来评估质量、发现差距,并完善下一步的查询。这使得子智能体在适应任何任务时都更加有效。
- 并行工具调用改变了速度和性能。 复杂的研究任务自然涉及探索许多来源。我们早期的智能体是按顺序执行搜索的,速度慢得令人痛苦。为了提高速度,我们引入了两种并行化:(1)主导智能体并行启动3-5个子智能体,而不是串行启动;(2)子智能体并行使用3个以上的工具。这些改变将复杂查询的研究时间缩短了高达90%,使得“研究”功能能在几分钟内完成更多工作,而不是几小时,同时覆盖的信息比其他系统更多。
sub-agent范式
Sub-Agent(子代理) ,本质上是集中式架构下的分工。一个主智能体掌控全局,把任务委派给几个专用的子代理。这些子代理更像工具,无状态,只处理被分配的子任务。关键区别在于:控制权和上下文。Multi-Agent模式下,控制权是分布式的,每个Agent都有一定的自主权,上下文是隔离的。而Sub-Agent模式下,控制权是集中式的,主智能体说了算,上下文是共享的。
Google Cloud的一篇文章给出了一个非常清晰的对比:Agent as Tool(工具式子代理)vs Sub-Agent(委派式子代理)。
- Agent as Tool就像一个专家顾问,主智能体调用它时,给出明确的输入,拿到明确的输出,就像调用一个API。这个专家顾问有自己的逻辑,但主智能体不需要知道细节。
- 而Sub-Agent更像一个项目经理的分身,它在主智能体的全局上下文中工作,处理复杂的多步骤流程,可以访问主智能体的对话历史和状态。
从单Agent起步,逐步演进。
- 当你真正遇到以下问题时,
- 上下文管理失控:单个prompt塞不下了,或者推理质量因为上下文过长而下降
- 分布式开发不可避免:多个团队需要独立维护不同模块
- 选择合适的Multi-Agent架构模式
- 需要多领域并行执行、集中式工作流管控 → Sub-Agents
- 需要轻量化多能力扩展、快速迭代 → Skills
- 需要分阶段顺序工作流、智能体需全程交互用户 → Handoffs
- 需要垂直领域多源查询、整合多专业结果 → Router 主Agent可以用最强的模型,因为需要全局规划和结果整合。但子Agent可以用更小更快的模型,因为它们只处理特定领域的任务。
与上下文工程(Context Engineering)的结合
- 专用上下文优化器智能体持续监控和调整提示结构,实验显示可将任务性能提升20-30%
- 元认知智能体分析其他智能体的知识盲区并动态补充上下文,在开放域问答中将回答完备性提高了40%
意图识别准确性
- 先topn => llm query+topn 对意图进行排序
- 意图识别是一个分类问题
- 分类体系足够清晰,要符合正交原则
- 每个子分类有足够样本,这样微调llm 效果最好
与UI的交互
A2UI与AG-UI深度对比:两大AI界面协议的异同与选择未细读
- Agent 需要一个比文本更丰富的展示
- A2UI 的核心理念:作为“消息序列”的声明式 UI,允许它增量式地生成和发送 UI 片段。
多Agent工程问题
智能体的发展:从单任务到多代理协同与人代理交互。多智能体应用让不同的Agent之间相互交流沟通来解决问题。
AutoGen、ChatDev、CrewAI CrewAI:一个集众家所长的MutiAgent框架 PS: 你要是上万个tool的话,llm 上下文塞不下,此时让一个llm 针对一个问题决策使用哪一个tool 就很难(ToolLLaMa已经支持16k+了),此时很自然的就需要多层次的Agent,低层次的Agent 更专业聚焦一些。
- 智能体和环境的交互(Agent-Environment Interface);智能体交互的环境可分为以下几类:
- 沙箱环境(Sandbox);
- 物理环境(Physical)
- 无环境(None),例如多智能体对一个问题进行辩论以达成共识,无环境下的应用主要关注智能体间的交互,而非智能体和外部环境的交互。
- 智能体画像构建(Agents Profiling);多智能体中各智能体承担不同的角色,每个角色均有相应的描述,包括特征、能力、行为、约束和目标等,这些描述构成智能体的画像(Profile)。
- 智能体间的通信(Agents Communication);从通信范式、通信结构和通信内容三个方面对智能体间的通信进行解析:
- 智能体能力获取(Agents Capabilities Acquisition)。能力获取包括智能体从哪些类型的反馈中学习以增强其能力,以及智能体为有效解决复杂问题而调整自己的策略。根据反馈的来源,可将反馈分为以下几类:
- 来自真实或模拟环境的反馈(Feedback from Environment),这种反馈在问题求解应用中比较普遍,包括软件研发中智能体从代码解释器(Code Interpreter)获取的代码执行结果,机器人这类具身智能体从真实或模拟环境获取的反馈等;
- 来自智能体间交互的反馈(Feedback from Agents Interactions),这种反馈在问题求解应用也比较常见,包括来自其他智能体的判断,或来自智能体间的通信等,例如在科学辩论中,智能体通过智能体间的通信评估和完善结论,在博弈游戏中,智能体通过之前几轮和其他智能体的交互完善自己的策略;
- 来自人类反馈(Human Feedback),人类反馈对智能体对齐人类偏好很重要,这种反馈主要在人机回环(Human-in-the-loop)应用中
- 无反馈(None),无反馈主要出现世界模拟这类应用中,因为这列应用主要侧重结果分析,例如传播模拟的结果分析,而非智能体能力获取,所以无需引入反馈对智能体的策略进行调整。 而智能体调整策略、增强能力的方式又可以分为三类:记忆(Memory),自我进化(Self-Evolution)和动态生成(Dynamic Generation)。
智能体间的通信
通信范式(Communication Paradigms):智能体间通信的方式、方法:合作;辩论;竞争
- 系统的通信拓扑主要有两种方式:一种是静态结构,另一种是动态结构。静态拓扑是事先规划好的。它不变,按既定规则连接各个Agent。相比之下,动态拓扑不是一开始就设定好,而是Agent会根据当前情况,比如任务难度、资源分配或执行表现,自动调整连接方式和团队分工。
- 静态拓扑常见的几种结构:
- 分层(Layered)结构;类似多层前馈神经网络,只是将其中的神经元替换为智能体,其针对给定问题,在推理时根据智能体优选算法选择各层中最优的智能体,然后使用选出的智能体逐层向前传递求解给定问题;
- 去中心化(Decentralized)结构;各智能体间直接点对点地相互通信,这种结构主要用于世界模拟(World Simulation)应用中;
- 中心化(Centralized)结构/单主动-多被动,由一个或一组智能体构成中心节点(root agent/main agent/orchestrator),其他智能体只与中心节点通信;中心节点负责协调和集成所有智能体的信息,然后向各个智能体发出指令或反馈。中心节点可以全局地了解所有智能体的状态和信息,有助于做出全局最优的决策。但是容易出现单点故障,中心节点的故障可能导致整个系统的通信瘫痪。
- 共享消息池(Shared Message Pool)结构,所有智能体发送消息至共享消息池,并订阅和自己相关的消息。

- 通信协议
可扩展性是另一个核心问题。Agent一多,通信量就飙升。全连接结构里,每多一个Agent,通信路径不是加一条,而是多出一大片,计算资源很快就吃不消。有的系统尝试用有向无环图(DAG)来控制结构复杂度,有的则采用分布式架构和并发机制来提升系统吞吐量。
多Agent系统的评估
评估分为两个方向:
- 一是解决特定任务时的表现。包括代码生成、知识推理、数学推理等任务,测试的是分布式任务解决的能力——即让多个Agent分工协作,优化每一步的处理过程。比如在代码生成中,有的系统会让不同的Agent担任“程序员”、“测试员”、“评审员”等角色,从而把复杂的代码任务拆解成流水线式的操作,大幅提升正确率和效率。
- 二是系统整体能力的衡量。强调沟通是否顺畅、任务是否分配合理、是否能在突发情况下做出反应,比如一个Agent“出故障”时,其他Agent是否能顶上。评估标准不再只有准确率和完成率,还包括沟通效率、决策质量、协调能力和环境适应能力。
再进一步
配置驱动的动态Agent架构网络:实现高效编排、动态更新与智能治理
- 这种架构模式下,Agent不再是一个庞大的单体应用,而是由一份清晰的配置清单定义的、动态组装而成的智能实体。配置文件指明了构成该Agent所需的一切资源,实现了定义与实现的解耦。
- AI Registry注册中心。
- Prompt Center(提示词中心)。每个Prompt都有一个唯一的promptKey,并包含版本、标签、描述等元数据。支持A/B测试、灰度发布、权限管理和版本回滚,确保提示词更新的安全性与一致性。
- MCP Registry(MCP注册中心)
- Agent Registry(Agent注册中心)记录了每个Agent的agentName、访问端点、认证方式以及其能力描述(Agent Spec)。实现了Agent之间的动态发现和调用,构建了松耦合的Agent协作网络。
- Agent Spec Execution Engine。它是一个高性能、高可用的通用框架,被嵌入到每个Agent运行时基础镜像中,其核心使命是:将静态的、声明式的Agent Spec配置,在运行时动态地实例化、执行并持续维护一个活的、可交互的智能Agent。
- 运行时部署形态:分布式、高可用的Agent集群。多个Agent以独立进程的形式在多节点上部署,通过共享的记忆与知识库保持状态一致性,并通过远程通信实现MCP 工具调用与Agent协作(A2A)。Agent之间不直接持有彼此的物理地址(IP/Port),而是通过查询Agent Registry,使用对方的逻辑名称(agentName)来获取访问端点。PS:有点像web开发中的tomcat PS:以Agent为核心,有一个agent spec,运行在agent runtime上,将焦点从“如何编写Agent”转移到“如何定义和治理Agent能力”。
Anthropic 在其实验性文章《Orchestrate Teams of Claude Code Sessions》中提出了一个比较新的概念:Agent Teams。
- 传统Mulit-Agent:传统的Multi-Agent架构下,Sub-Agent一般来说更像是独立的“员工”。它们接收指令,独立完成任务,然后仅向主模型(Master)提交一份最终结果报告。在此过程中,Sub-Agent之间是零交流的,或者通过Agent之间的通信协议进行交流,上下文隔离,彼此不知道对方在做什么,也无法利用对方的中间过程发现。
- Agent Teams模式,它的核心,更多是为了探索高度不确定性的决策难题。多维度的试错,避免单一路径的风险,可能最优解涌现。
- 并行探索:多个具有不同Identity身份的Agent同时启动,针对同一问题从不同角度并发运行
- 上下文共享:这是最关键的变化。所有队员在一个共同的Task List或Shared Context共享空间中实时写入进度、发现和思考
- 动态协同:Agent不仅能感知自己的任务,还能“看到”队友正在做什么。这种机制打破了信息孤岛,实现了真正的团队智能的效果
- 目标一致:Agent Teams中的Agent共享同一个终极目标(完成用户的主任务),只是过程中的分工有所不同。
工程实例
无论你选择哪种框架来创建Multi-Agent系统,它们通常由几个要素组成,包括其档案、对环境的感知、记忆、计划和可用行动。每个框架在Agent之间的通信方式上略有不同。但归根结底,它们都依赖于这种协作性的沟通。Agent有机会相互交流,以更新它们的当前状态、目标和下一步行动。
开发AI Agent到底用什么框架——LangGraph VS. LlamaIndex当使用一个框架来实现某个具体的multi-agent系统的时候,需要把上层系统的概念同底层抽象概念有效对应起来。
- 使用LangGraph来支持multi-agent的方案,节点可以表示LLM,可以表示某个Tool,可以表示任意的一段程序执行逻辑,也可以表示一个完整的Agentic System子图(也就是可以嵌套子图)。如何用LangGraph构建多Agent系统架构各个Agent被定义为图节点,Agent通过图状态进行通信。
- 使用LlamaIndex来支持multi-agent的方案,调用工具 (handletoolcall) 、调用模型 (speakwithsub_agent)、做路由分发 (orchestrator) ,等等这些逻辑,都使用一个step来实现(具体代码层面就是在方法上标注一个 @step的decorator)。 LlamaIndex的Workflow,只需要在方法上标注 @step,就能创建出一个step,非常灵活易用。但是对于step之间的执行偏序关系没法直接指定,只能通过声明和匹配事件类型来隐式地指定,不是那么方便。而LangGraph要求开发者显式地调用 add_node、 add_edge来构建执行图。这些用来构建图的代码,对于开发者的代码有一定的侵入,你需要去理解node、edge这些与你的业务逻辑无关的概念,并在代码中穿插调用它们。另外,不管是LlamaIndex还是LangGraph,对于multi-agent的上层封装都不太够。
Qwen-Agent(未细读)
Qwen-Agent 使用篇 未细读
OpenAI-Swarm Multi-Agent
OpenAI-Swarm Multi-Agent 框架源码解读 未细读。
初识 OpenAI 的 Swarm:轻量级、多智能体系统的探索利器 未细读。
autogen-magentic-one
https://github.com/microsoft/autogen/tree/main/python/packages/autogen-magentic-one
multi-agent-orchestrator
langchain deepagents
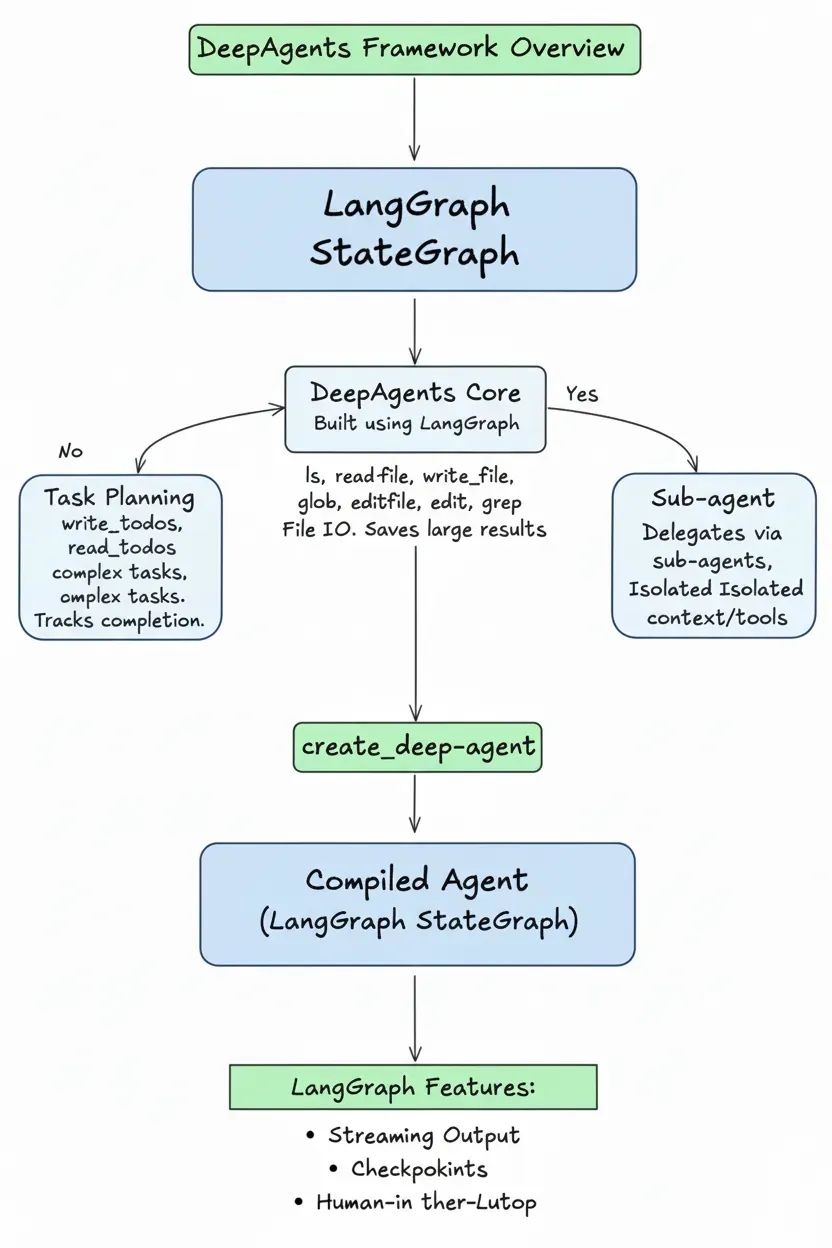
- 任务规划(Planning):使用内置 write_todos 和 read_todos 工具将复杂任务分解为结构化待办事项列表,agent 按列表执行并标记完成状态。
- 文件系统访问(Computer Access):提供 ls、read_file、write_file、edit_file、glob、grep 等工具,让 agent 能够读写文件、搜索文件内容。大型工具调用结果自动保存到文件,避免消耗上下文窗口。
- 长周期任务面临的核心挑战是上下文窗口限制与成本控制之间的矛盾。传统 agent 将所有工具调用结果堆入上下文,导致 token 成本激增,同时模型在海量信息中逐渐失焦。deepagents 的解决思路是重新设计信息流架构:引入文件系统作为上下文缓冲区,大型工具结果自动写入文件,agent 上下文中仅保留路径引用。配合自动摘要和提示缓存机制,系统显著降低成本的同时保持任务执行效率。
- 子 agent 委托(Sub-agent Delegation):通过 task 工具将子任务委托给专门的子 agent 执行,每个子 agent 拥有独立的上下文窗口和工具集。
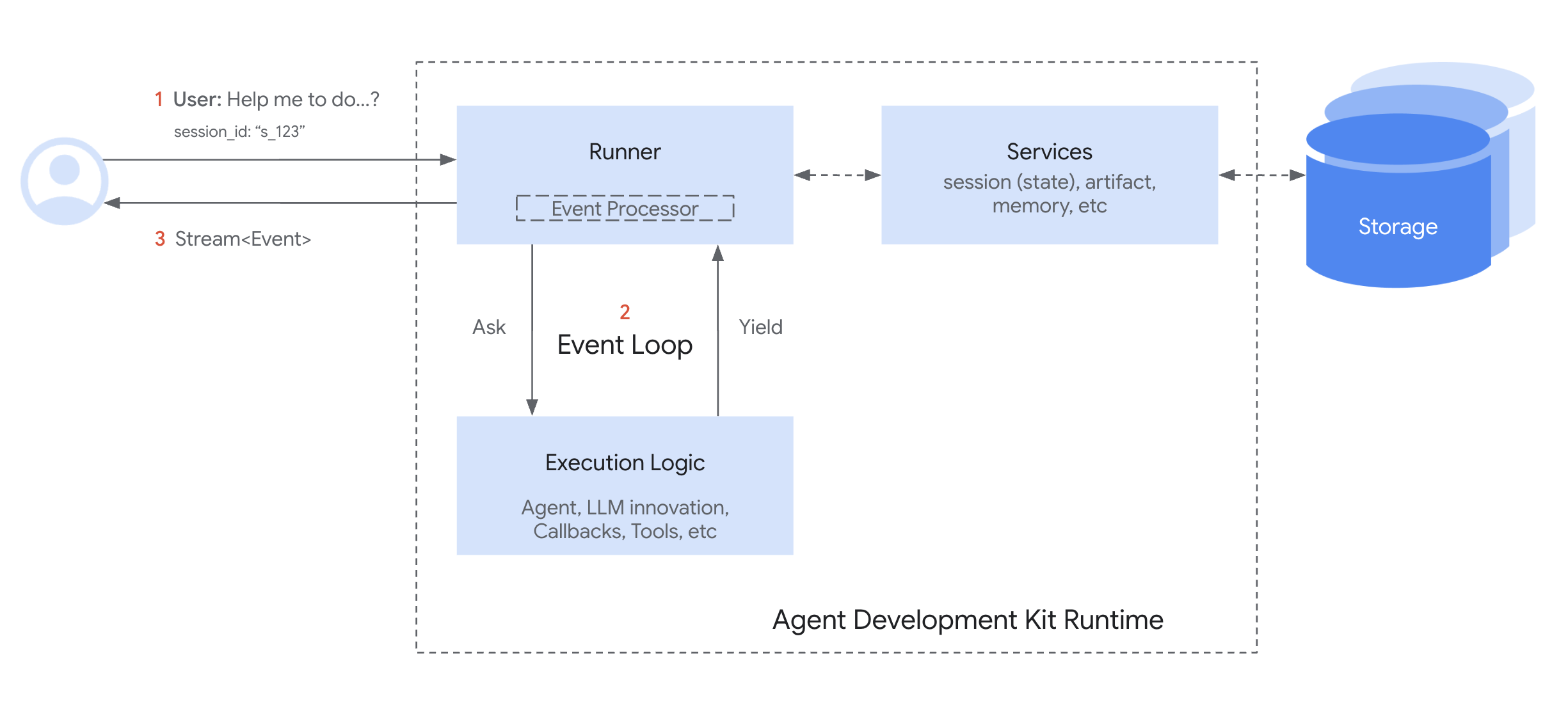
google adk
https://google.github.io/adk-docs 官方文档将各个方面介绍的很全面
- 有类似BaseLLM、BaseTool等抽象,以及围绕这些抽象的Callbacks/Events(比如模型安全就可以通过Callbacks来做),这些是构成一个Agent的基本要素。
- 与langgraph相比,明确提出了BaseAgent抽象,具体有LLM Agents/Workflow Agents/Custom agents,以及围绕这些的Context/State传递与共享等。
class BaseAgent(BaseModel): name: str description: str = '' parent_agent: Optional[BaseAgent] = Field(default=None, init=False) sub_agents: list[BaseAgent] = Field(default_factory=list) before_agent_callback: Optional[BeforeAgentCallback] = None after_agent_callback: Optional[AfterAgentCallback] = None # AsyncGenerator是AsyncIterator 的子类 # 返回[Event, None] 跟语法没关系,类似tuple[Event,None],一般一个作为数据,一个作为控制信号 async def run_async(self,parent_context: InvocationContext,) -> AsyncGenerator[Event, None]: with tracer.start_as_current_span(f'agent_run [{self.name}]'): ctx = self._create_invocation_context(parent_context) if event := await self.__handle_before_agent_callback(ctx): yield event if ctx.end_invocation: return async for event in self._run_async_impl(ctx): yield event if ctx.end_invocation: return if event := await self.__handle_after_agent_callback(ctx): yield event - 在agent 之上提出了agent team(Agent.sub_agents,与agno 有些不同),进一步提出了几种Multi-Agent Patterns
- Coordinator/Dispatcher Pattern, A central LlmAgent (Coordinator) manages several specialized sub_agents.
- Sequential Pipeline Pattern, A SequentialAgent contains sub_agents executed in a fixed order.
- Parallel Fan-Out/Gather Pattern
- Hierarchical Task Decomposition, A multi-level tree of agents where higher-level agents break down complex goals and delegate sub-tasks to lower-level agents. PS:a.sub_agents=b, b.sub_agents=cd
- Review/Critique Pattern
- Iterative Refinement Pattern, Uses a LoopAgent containing one or more agents that work on a task over multiple iterations.
- Human-in-the-Loop Pattern PS: 总之agent 多起来之后,跟微服务一样,它们的组合关系也很多样,看业务需要。
- 在以上抽象的基础上,提出了runtime。The ADK Runtime is the underlying engine that powers your agent application during user interactions. It’s the system that takes your defined agents, tools, and callbacks and orchestrates their execution in response to user input, managing the flow of information, state changes, and interactions with external services like LLMs or storage.Think of the Runtime as the “engine” of your agentic application. You define the parts (agents, tools), and the Runtime handles how they connect and run together to fulfill a user’s request. PS:adk管的很挺全乎,还囊括了会话(Session) 和记忆。
XAgent - Agent 并行计算, LLM 汇总
XAgent采用双环机制,外循环用于高层任务管理,起到规划(Planning)的作用,内循环用于底层任务执行,起到执行(Execution)的作用。
- PlanAgent首先生成一个初始计划,为任务执行制定基本策略。该部分会将给定的复杂任务分解为更小、更易管理的子任务,其表现为一个任务队列,可以直接地执行。
- 迭代式计划优化:在初始规划之后,PlanAgent通过从任务队列中释放出第一个任务,然后将该子任务传递给内循环,PlanAgent持续监视任务的进展和状态。在每个子任务执行后,内循环会返回来自ToolAgent的反馈。根据反馈,PlanAgent触发适当的处理机制,如优化计划或继续执行后续子任务。直到队列中没有剩余的子任务为止,外循环结束。
- 内循环负责执行外循环分配的各个子任务。基于外循环给定的子任务,内循环会指定一个合适的ToolAgent,确保任务达到预期的结果。内循环的主要职责包括:
- Agent调度和工具获取:根据子任务的性质,派遣合适的ToolAgent,该Agent具备完成任务所需的能力。
- 工具执行:ToolAgent首先从外部系统中获取工具以帮助完成任务。然后,Agent使用ReACT来解决子任务,寻找最佳的一系列工具调用来完成子任务。
- 反馈和反思:在一系列动作之后,ToolAgent可以发出一个名为“subtask_submit”的特定动作,以完成当前子任务的处理,并将反馈和反思传递给PlanAgent。这个反馈可以指示子任务是否成功完成,或者强调潜在的改进。
动态规划和迭代改进:PlanAgent赋予Agent不断制定和修订计划的能力,以适应多变的环境和突发需求。这些能力对于确保灵活性、弹性和效率以应对未预见的挑战至关重要。PlanAgent专用于外循环,其通过生成初始计划和不断修订计划来实现这一目标。PlanAgent包含四个函数来优化计划:
- 子任务拆分:使系统能够将特定的子任务分解为粒度更细、更易管理的单元。只有当前正在执行或尚未启动的子任务才有资格进行此操作。
- 子任务删除:删除尚未开始的子任务。已经在进行中或已完成的子任务不具备删除资格。这确保了一定的灵活性,可以修剪多余或不相关的任务,以优化整体执行。
- 子任务修改:修改子任务的内容。要修改的子任务不能是已经开始或已经完成,以保持整体计划的完整性。
- 子任务添加:在特定子任务之后插入新的子任务。只能在当前处理的子任务或其后继任务之后添加子任务。这确保了新任务按顺序编排,简化了执行流程,并保持了一致性。
XAgent缺乏多Agent的能力,例如多Agent的协作模式、通信模式和自定义等,其内部定了的多个Agent,但这些Agent更像是函数的封装。XAgent定义给出的是通用智能体:从XAgent开发框架来看,本质是想通过Agent的任务分解能力加上集成更多的Tools的能力,将复杂任务有效的分解成细粒度的任务执行,但从当前的业界实现,BabyAGI,AutoGen都不是很理想,只能在有限的问题上可能效果可以,但还不是很稳定,完全依赖GPT4的能力,遇到专业性强的复杂问题,效果都不会很好。
应用
用于RAG
https://github.com/padas-lab-de/PersonaRAG 未读
未来
REAPER——一种基于推理的规划器,专为处理复杂查询的高效检索而设计
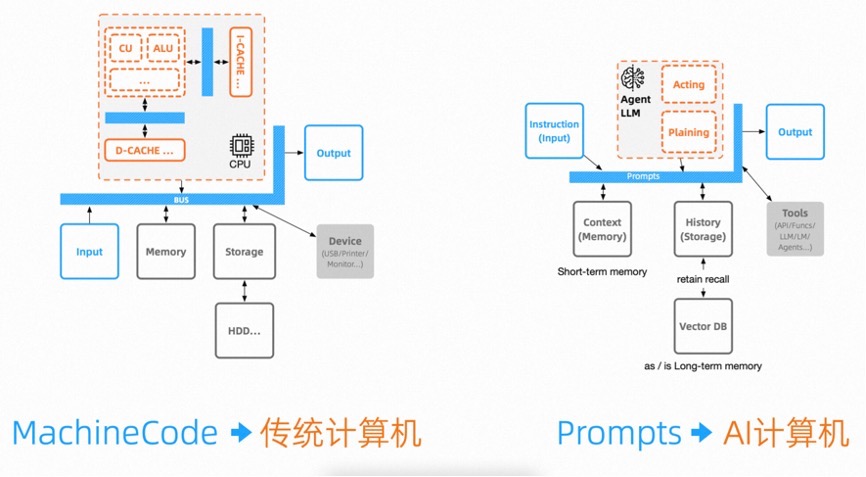
探索AI时代的应用工程化架构演进,一人公司时代还有多远?在冯诺依曼架构或者哈佛架构设备的实际开发中,我们会去关心如何使用相应协议去寻址去读写总线操作不同设备,如UART、I2C、SPI总线协议,这都是我们要学习掌握的,但我们基本不会关心CPU中的CU、ALU等单元。计算机架构这样求同存异的继续发展下去,将这些单元与高速存储及总线等作为抽象概念去进一步封装。而AI应用也是类似的,Agent会将相关的规划反思改进能力不断的作为自身的核心能力封装。因此,对于未来的AI应用极有可能不是在传统计算机上运行的程序,而是标准化的需求,在以规划能力专精的Agent 大模型作为CPU的AI计算机虚拟实例上直接运行的,而我们今天所谈论的应用架构,也会沉积到底层转变为AI计算机的核心架构。最终AI计算机将图灵完备,通过AI的自举将迭代产物从工程领域提升到工业领域。
留下评论