Redis源码分析
前言
建议看下前文Redis 学习
参考《Apache Kafka源码分析》——server服务端网络开发的基本套路
源码来自带有详细注释的 Redis 3.0 代码(annotated Redis 3.0 source code)
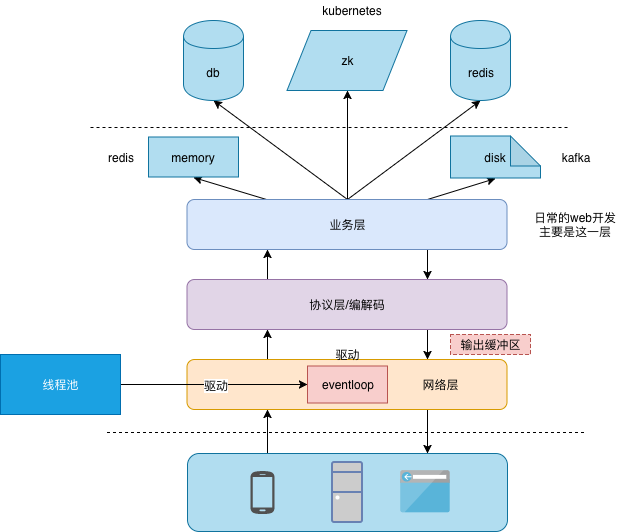
宏观梳理

整个轴线是redisServer 初始化并启动eventloop, eventLoop 创建redisClient 及驱动processCommand 方法进而 执行redisCommand 向 dict 中保存数据

本文 以一个SET KEY VALUE 来分析redis的 启动和保存流程
启动过程
redis.c
int main(int argc, char **argv) {
...
// 初始化服务器
initServerConfig();
...
// 将服务器设置为守护进程
if (server.daemonize) daemonize();
// 创建并初始化服务器数据结构
initServer();
...
// 运行事件处理器,一直到服务器关闭为止
aeSetBeforeSleepProc(server.el,beforeSleep);
aeMain(server.el);
// 服务器关闭,停止事件循环
aeDeleteEventLoop(server.el);
return 0
}
Redis是如何建立连接和处理命令的 未细读。
网络层
Redis的网络监听没有采用libevent等,而是自己实现了一套简单的机遇event驱动的API,具体见ae.c。事件处理器的主循环
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
// 如果有需要在事件处理前执行的函数,那么运行它
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 开始处理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS);
}
}
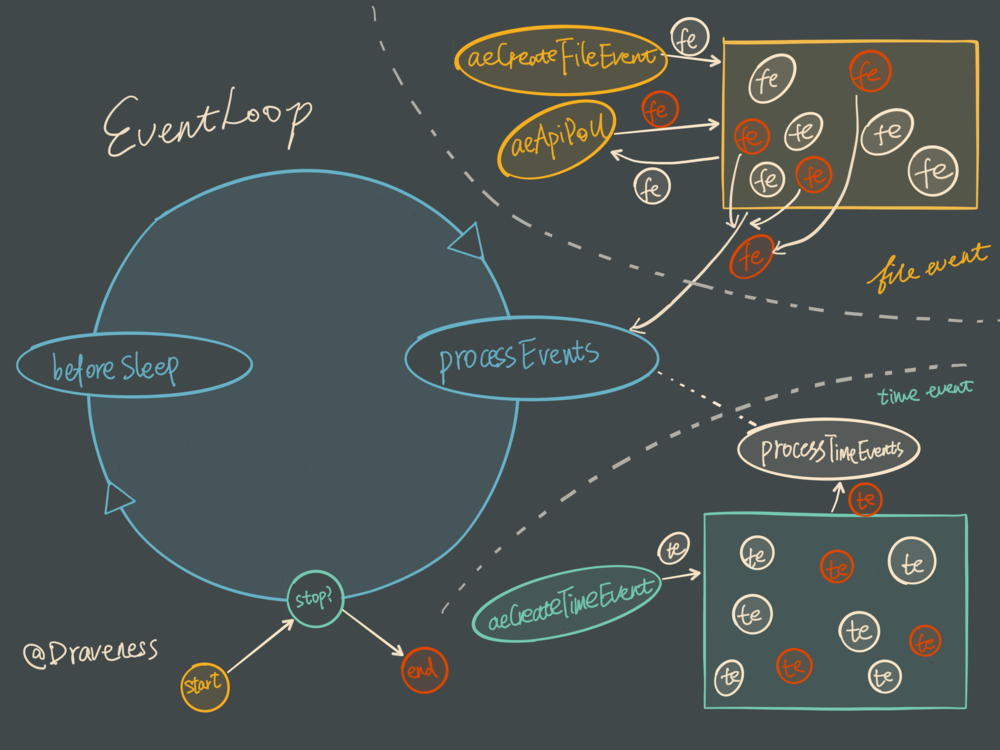
int aeProcessEvents(aeEventLoop *eventLoop, int flags)
{
struct timeval tv, *tvp;
...
// 获取最近的时间事件
if (flags & AE_TIME_EVENTS && !(flags & AE_DONT_WAIT))
shortest = aeSearchNearestTimer(eventLoop);
if (shortest) {
// 如果时间事件存在的话,那么根据最近可执行时间事件和现在时间的时间差来决定文件事件的阻塞时间
// 计算距今最近的时间事件还要多久才能达到,并将该时间距保存在 tv 结构中
aeGetTime(&now_sec, &now_ms);
} else {
// 执行到这一步,说明没有时间事件,那么根据 AE_DONT_WAIT 是否设置来决定是否阻塞,以及阻塞的时间长度
}
// 处理文件事件,阻塞时间由 tvp 决定
// 类似于 java nio 中的select
numevents = aeApiPoll(eventLoop, tvp);
for (j = 0; j < numevents; j++) {
// 从已就绪数组中获取事件
aeFileEvent *fe = &eventLoop->events[eventLoop->fired[j].fd];
int mask = eventLoop->fired[j].mask;
int fd = eventLoop->fired[j].fd;
// 读事件
if (fe->mask & mask & AE_READABLE) {
fe->rfileProc(eventLoop,fd,fe->clientData,mask);
}
// 写事件
if (fe->mask & mask & AE_WRITABLE) {
if (!rfired || fe->wfileProc != fe->rfileProc)
fe->wfileProc(eventLoop,fd,fe->clientData,mask);
}
}
// 执行时间事件
if (flags & AE_TIME_EVENTS)
processed += processTimeEvents(eventLoop);
}
这个event loop的逻辑可不孤单,netty中也有类似的EventLoop 中的 Loop 到底是什么?
Redis 中会处理两种事件:时间事件和文件事件。在每个事件循环中 Redis 都会先处理文件事件,然后再处理时间事件直到整个循环停止。 aeApiPoll 可看做文件事件的生产者(还有一部分文件事件来自accept等),processEvents 和 processTimeEvents 作为 Redis 中发生事件的消费者,每次都会从“事件池”(aeEventLoop的几个列表字段)中拉去待处理的事件进行消费。
协议层
我们以读事件为例,但发现数据可读时,执行了 fe->rfileProc(eventLoop,fd,fe->clientData,mask);,那么rfileProc 的执行逻辑是啥呢?
-
initServer ==> aeCreateFileEvent. 初始化server 时,创建aeCreateFileEvent(aeFileEvent的一种),当accept (可读事件的一种)就绪时,触发aeCreateFileEvent->rfileProc 方法 也就是 acceptTcpHandler
// redis.c void initServer() { ... // 为 TCP 连接关联连接应答(accept)处理器,用于接受并应答客户端的 connect() 调用 for (j = 0; j < server.ipfd_count; j++) { if (aeCreateFileEvent(server.el, server.ipfd[j], AE_READABLE,acceptTcpHandler,NULL) == AE_ERR){...} } ... } -
创建客户端,并绑定读事件到loop:acceptTcpHandler ==> createClient ==> aeCreateFileEvent ==> readQueryFromClient
void acceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) { int cport, cfd, max = MAX_ACCEPTS_PER_CALL; ... while(max--) { // accept 客户端连接 cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport); if (cfd == ANET_ERR) { ... return; } // 为客户端创建客户端状态(redisClient) acceptCommonHandler(cfd,0); } } static void acceptCommonHandler(int fd, int flags) { // 创建客户端 redisClient *c; if ((c = createClient(fd)) == NULL) { ... close(fd); /* May be already closed, just ignore errors */ return; } // 如果新添加的客户端令服务器的最大客户端数量达到了,那么向新客户端写入错误信息,并关闭新客户端 // 先创建客户端,再进行数量检查是为了方便地进行错误信息写入 ... } redisClient *createClient(int fd) { // 分配空间 redisClient *c = zmalloc(sizeof(redisClient)); if (fd != -1) { ... //绑定读事件到事件 loop (开始接收命令请求) if (aeCreateFileEvent(server.el,fd,AE_READABLE, readQueryFromClient, c) == AE_ERR){ // 清理/关闭资源退出 } } // 初始化redisClient其它数据 } -
拼接和分发命令数据 readQueryFromClient ==> processInputBuffer ==> processCommand
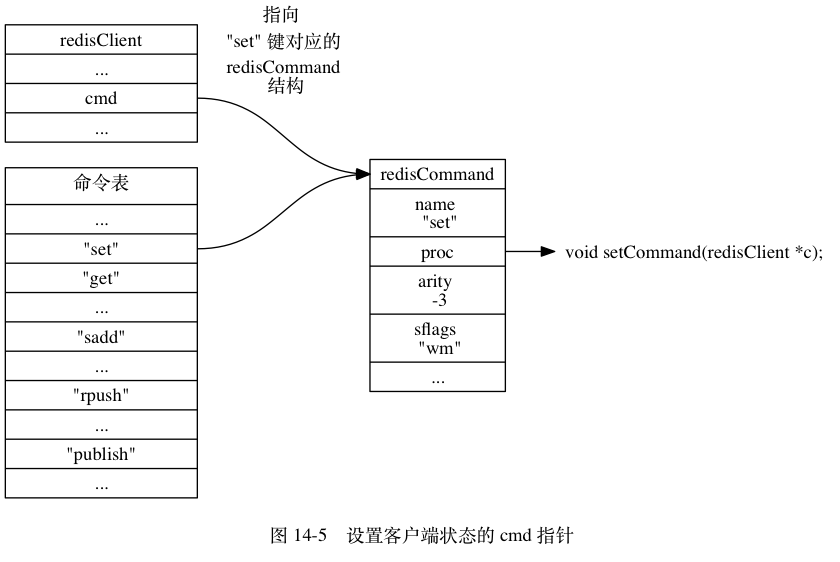
networking.c void readQueryFromClient(aeEventLoop *el, int fd, void *privdata, int mask) { redisClient *c = (redisClient*) privdata; // 获取查询缓冲区当前内容的长度 // 如果读取出现 short read ,那么可能会有内容滞留在读取缓冲区里面 // 这些滞留内容也许不能完整构成一个符合协议的命令, qblen = sdslen(c->querybuf); // 如果有需要,更新缓冲区内容长度的峰值(peak) if (c->querybuf_peak < qblen) c->querybuf_peak = qblen; // 为查询缓冲区分配空间 c->querybuf = sdsMakeRoomFor(c->querybuf, readlen); // 读入内容到查询缓存 nread = read(fd, c->querybuf+qblen, readlen); // 读入出错 // 遇到 EOF if (nread) { // 根据内容,更新查询缓冲区(SDS) free 和 len 属性 // 并将 '\0' 正确地放到内容的最后 sdsIncrLen(c->querybuf,nread); // 记录服务器和客户端最后一次互动的时间 c->lastinteraction = server.unixtime; // 如果客户端是 master 的话,更新它的复制偏移量 if (c->flags & REDIS_MASTER) c->reploff += nread; } else { // 在 nread == -1 且 errno == EAGAIN 时运行 server.current_client = NULL; return; } // 查询缓冲区长度超出服务器最大缓冲区长度 // 清空缓冲区并释放客户端 // 从查询缓存重读取内容,创建参数,并执行命令 // 函数会执行到缓存中的所有内容都被处理完为止 processInputBuffer(c); server.current_client = NULL; } // 处理客户端输入的命令内容 void processInputBuffer(redisClient *c) { // 尽可能地处理查询缓冲区中的内容 while(sdslen(c->querybuf)) { ... // 判断请求的类型 // 简单来说,多条查询是一般客户端发送来的, // 而内联查询则是 TELNET 发送来的 if (!c->reqtype) { if (c->querybuf[0] == '*') { // 多条查询 c->reqtype = REDIS_REQ_MULTIBULK; } else { // 内联查询 c->reqtype = REDIS_REQ_INLINE; } } // 将缓冲区中的内容转换成命令,以及命令参数 if (c->reqtype == REDIS_REQ_INLINE) { if (processInlineBuffer(c) != REDIS_OK) break; } else if (c->reqtype == REDIS_REQ_MULTIBULK) { if (processMultibulkBuffer(c) != REDIS_OK) break; } else { redisPanic("Unknown request type"); } ... } } redis.c int processCommand(redisClient *c) { // 特别处理 quit 命令 // 查找命令,并进行命令合法性检查,以及命令参数个数检查 c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr); // 没找到指定的命令 或 参数个数错误 直接返回 // 检查认证信息 // 如果开启了集群模式,那么在这里进行转向操作。 // 如果设置了最大内存,那么检查内存是否超过限制,并做相应的操作 // 如果这是一个主服务器,并且这个服务器之前执行 BGSAVE 时发生了错误 // 那么不执行写命令 // 如果服务器没有足够多的状态良好服务器 // 并且 min-slaves-to-write 选项已打开 // 如果这个服务器是一个只读 slave 的话,那么拒绝执行写命令 // 在订阅于发布模式的上下文中,只能执行订阅和退订相关的命令 /* Only allow INFO and SLAVEOF when slave-serve-stale-data is no and * we are a slave with a broken link with master. */ // 如果服务器正在载入数据到数据库,那么只执行带有 REDIS_CMD_LOADING // 标识的命令,否则将出错 /* Lua script too slow? Only allow a limited number of commands. */ // Lua 脚本超时,只允许执行限定的操作,比如 SHUTDOWN 和 SCRIPT KILL /* Exec the command */ if (c->flags & REDIS_MULTI && c->cmd->proc != execCommand && c->cmd->proc != discardCommand && c->cmd->proc != multiCommand && c->cmd->proc != watchCommand) { // 在事务上下文中除 EXEC 、 DISCARD 、 MULTI 和 WATCH 命令之外 // 其他所有命令都会被入队到事务队列中 queueMultiCommand(c); addReply(c,shared.queued); } else { // 执行命令 call(c,REDIS_CALL_FULL); c->woff = server.master_repl_offset; // 处理那些解除了阻塞的键 if (listLength(server.ready_keys)) handleClientsBlockedOnLists(); } return REDIS_OK; }
业务层
redis.c
// 调用命令的实现函数,执行命令
void call(redisClient *c, int flags) {
// start 记录命令开始执行的时间
// 记录命令开始执行前的 FLAG
// 如果可以的话,将命令发送到 MONITOR
/* Call the command. */
c->flags &= ~(REDIS_FORCE_AOF|REDIS_FORCE_REPL);
redisOpArrayInit(&server.also_propagate);
// 保留旧 dirty 计数器值
dirty = server.dirty;
// 计算命令开始执行的时间
start = ustime();
// 执行实现函数
c->cmd->proc(c);
// 计算命令执行耗费的时间
duration = ustime()-start;
// 计算命令执行之后的 dirty 值
dirty = server.dirty-dirty;
...
// 如果有需要,将命令放到 SLOWLOG 里面
// 更新命令的统计信息
...
server.stat_numcommands++;
}
redis.c
struct redisCommand redisCommandTable[] = {
{"get",getCommand,2,"r",0,NULL,1,1,1,0,0},
{"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0},
...
}
t_string.c
/* SET key value [NX] [XX] [EX <seconds>] [PX <milliseconds>] */
void setCommand(redisClient *c) {
int j;
robj *expire = NULL;
int unit = UNIT_SECONDS;
int flags = REDIS_SET_NO_FLAGS;
// 设置选项参数
// 尝试对值对象进行编码
c->argv[2] = tryObjectEncoding(c->argv[2]);
setGenericCommand(c,flags,c->argv[1],c->argv[2],expire,unit,NULL,NULL);
}
void setGenericCommand(redisClient *c, int flags, robj *key, robj *val, robj *expire, int unit, robj *ok_reply, robj *abort_reply) {
long long milliseconds = 0; /* initialized to avoid any harmness warning */
// 取出过期时间
// 如果设置了 NX 或者 XX 参数,那么检查条件是否不符合这两个设置
// 在条件不符合时报错,报错的内容由 abort_reply 参数决定
// 将键值关联到数据库
setKey(c->db,key,val);
// 将数据库设为脏
// 为键设置过期时间
if (expire) setExpire(c->db,key,mstime()+milliseconds);
// 发送事件通知
// 设置成功,向客户端发送回复
}
db.c
void setKey(redisDb *db, robj *key, robj *val) {
// 添加或覆写数据库中的键值对
if (lookupKeyWrite(db,key) == NULL) {
dbAdd(db,key,val);
} else {
dbOverwrite(db,key,val);
}
incrRefCount(val);
// 移除键的过期时间
removeExpire(db,key);
// 发送键修改通知
signalModifiedKey(db,key);
}
前面说过, 命令实现函数会将命令回复保存到客户端的输出缓冲区里面, 并为客户端的套接字关联命令回复处理器, 当客户端套接字变为可写状态时, 服务器就会执行命令回复处理器, 将保存在客户端输出缓冲区中的命令回复发送给客户端。
当命令回复发送完毕之后, 回复处理器会清空客户端状态的输出缓冲区, 为处理下一个命令请求做好准备。
在保存到dict 的过程中,数据的形态也一直在变化
相关的数据结构
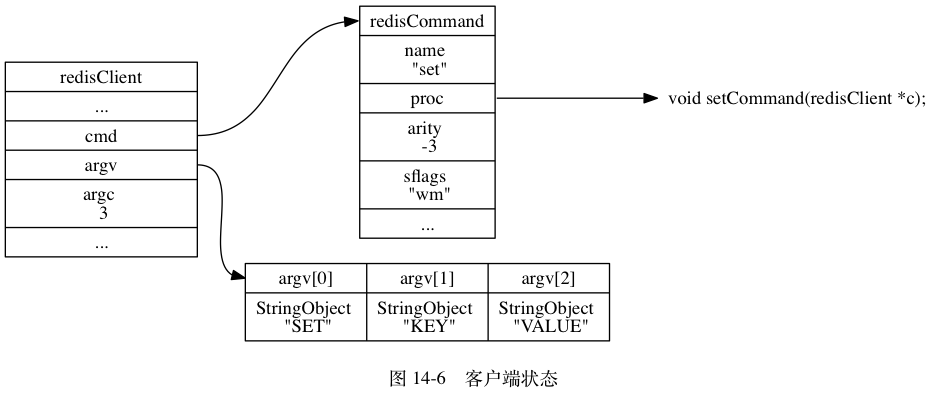
struct redisClient {
// 查询缓冲区
sds querybuf;
// 参数数量
int argc;
// 参数对象数组
robj **argv;
}
typedef struct redisObject {
// 类型
unsigned type:4;
// 编码
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
// 引用计数
int refcount;
// 指向实际值的指针
void *ptr;
} robj;
转换的代码
networking.c
// 将 c->querybuf 中的协议内容转换成 c->argv 中的参数对象
int processMultibulkBuffer(redisClient *c) {
// 读入命令的参数个数
// 比如 *3\r\n$3\r\nSET\r\n... 将令 c->multibulklen = 3
if (c->multibulklen == 0) {
// 检查缓冲区的内容第一个 "\r\n"
newline = strchr(c->querybuf,'\r');
if (newline == NULL) {
...
return REDIS_ERR;
}
// 协议的第一个字符必须是 '*'
// 将参数个数,也即是 * 之后, \r\n 之前的数字取出并保存到 ll 中
// 比如对于 *3\r\n ,那么 ll 将等于 3
ok = string2ll(c->querybuf+1,newline-(c->querybuf+1),&ll);
// 参数的数量超出限制
// 设置参数数量
// 根据参数数量,为各个参数对象分配空间
if (c->argv) zfree(c->argv);
c->argv = zmalloc(sizeof(robj*)*c->multibulklen);
}
// 从 c->querybuf 中读入参数,并创建各个参数对象到 c->argv
while(c->multibulklen) {
// 读入参数长度
if (c->bulklen == -1) {
// 确保 "\r\n" 存在
// 确保协议符合参数格式,检查其中的 $...
// 读取长度
// 比如 $3\r\nSET\r\n 将会让 ll 的值设置 3
ok = string2ll(c->querybuf+pos+1,newline-(c->querybuf+pos+1),&ll);
...
// 参数的长度
c->bulklen = ll;
}
// 读入参数
// 确保内容符合协议格式
// 为参数创建字符串对象
if (pos == 0 &&
c->bulklen >= REDIS_MBULK_BIG_ARG &&
(signed) sdslen(c->querybuf) == c->bulklen+2){
c->argv[c->argc++] = createObject(REDIS_STRING,c->querybuf);
sdsIncrLen(c->querybuf,-2); /* remove CRLF */
c->querybuf = sdsempty();
/* Assume that if we saw a fat argument we'll see another one
* likely... */
c->querybuf = sdsMakeRoomFor(c->querybuf,c->bulklen+2);
pos = 0;
} else {
c->argv[c->argc++] =
createStringObject(c->querybuf+pos,c->bulklen);
pos += c->bulklen+2;
}
// 清空参数长度
// 减少还需读入的参数个数
c->multibulklen--;
}
// 从 querybuf 中删除已被读取的内容
// 如果本条命令的所有参数都已读取完,那么返回
// 如果还有参数未读取完,那么就协议内容有错
}
object.c
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = REDIS_ENCODING_RAW;
o->ptr = ptr;
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution). */
o->lru = LRU_CLOCK();
return o;
}
-
最开始命令数据在redisClient->querybuf 中以字符串形式存在
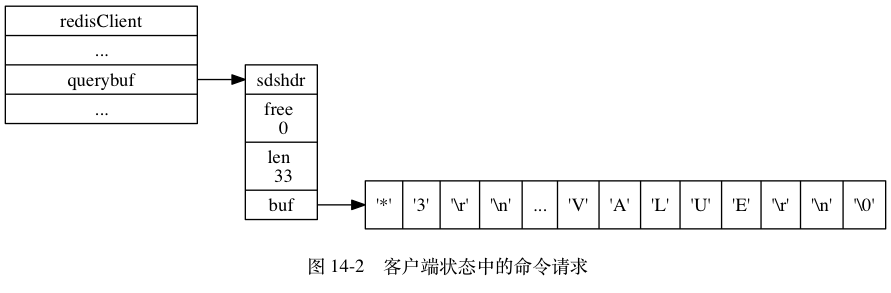
-
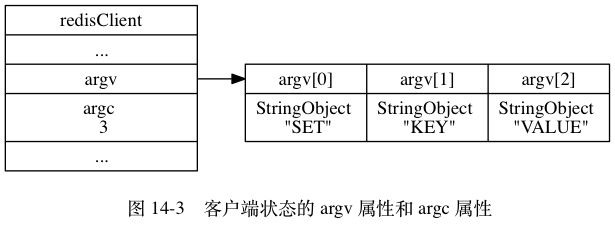
processMultibulkBuffer 然后字符串 数据被拆分为 redisObject 保存在 redisClient->argv[1],redisClient->argv[2],当然redisObject 的类型仍被标记为字符串
- t_string.c setCommand 对值对象进行编码
- 到db.c 时,
setKey(robj *key,robj *val) - dict.c
dictAdd(void *key, void *val)key 已被转换为 sds。
定义新的数据类型
来自 《Redis核心技术与实现》
- 定义新数据类型的底层结构,可以自己创建和命名
.h和.c文件 - 在 RedisObject 的 type 属性中,增加这个新类型的定义。在 Redis 的 server.h 文件中
- 开发新类型的创建和释放函数。主要是用 zmalloc 做底层结构分配空间。
- 开发新类型的命令操作。在 server.c 文件中的 redisCommandTable 里面,把新增命令和实现函数关联起来。
小结
如果你看到一个新东西,却没有理清它的逻辑,直到打通你已熟悉的东西(学名叫已有的知识体系),那肯定是没有真正理解它。 在redis 源码分析这里,你已知的是各种内存操作(即业务层部分),未知的网络层到业务层的通路。
留下评论