图数据库的一些考量
前言(未完成)
图数据模型是一种用于表示实体(节点)及其之间关系(边)的数据结构,在处理复杂关系数据时表现出色,尤其适合社交网络、推荐系统、知识图谱等应用场景。
- 直观的数据模型:图模型以节点(代表实体)、边(代表关系)和属性(附加信息)为基础,直接映射现实世界中的对象及其关系,使得数据结构更加直观易懂。
- 高效的关系查询:由于直接在图中表达实体间的关系,图模型可以快速地进行复杂的路径查询、模式匹配等操作,这些在传统关系型数据库中可能需要多表连接和复杂的SQL语句才能完成。
- 支持灵活的数据结构:图数据库对数据结构的约束较少,容易适应不断变化的数据模型,特别适合那些关系复杂且多变的应用场景。
- 强大的遍历能力:强大的图遍历功能能够轻松实现多跳关系的查询,非常适合发现数据中的隐藏关联和模式。
目前使用的图模型有两种:资源描述框架(RDF)模型和属性图(Property Graph/LPG)模型。
局限性
- 资源消耗:与关系型数据库相比,图数据库在存储空间和内存使用上可能更为昂贵,尤其是在处理大量节点和边的密集图时。
- 数值计算和聚合操作:虽然图模型在处理复杂关系数据方面表现出色,但在执行大规模的数值计算、统计分析或聚合操作时可能不如传统关系型数据库或专门的分析工具高效。
- 学习曲线:对于习惯于使用 SQL 的开发者来说,学习图数据库的思维方式可能需要一定时间,尤其是对于复杂的图遍历和模式匹配。
- 事务处理限制:但在某些高级特性(如分布式事务)的支持上可能不如成熟的 SQL 数据库,这可能限制了它在某些金融或银行领域中的应用。
- 数据导入/导出:由于图模型的独特性,将现有数据导入图数据库或从图数据库导出数据到其他系统会比关系型数据库更复杂,需要专门的 ETL 工具或自定义脚本。
Neo4j
概念
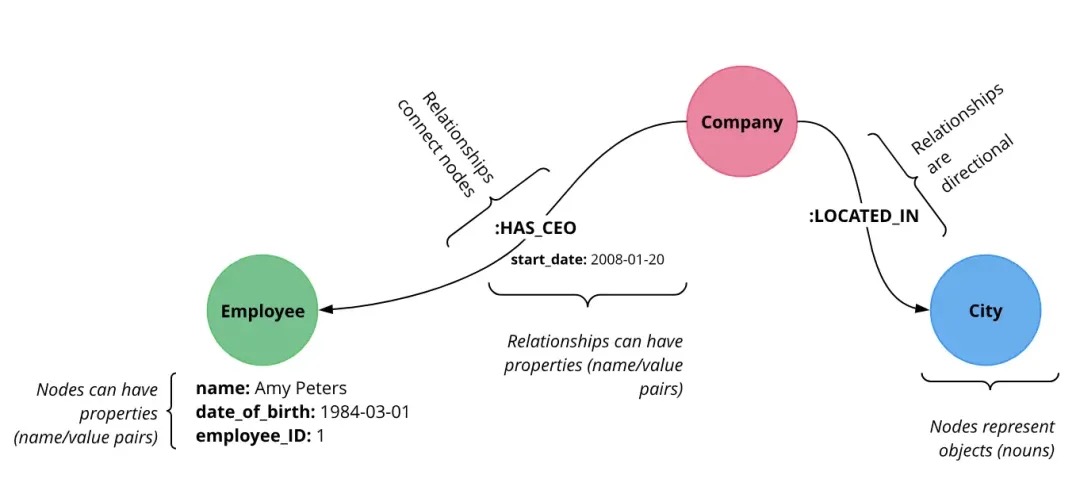
图是一种用于对对象之间的成对关系进行建模的数学结构。它由两个主要元素组成:节点和关系。
- 节点:节点可以看作是传统数据库中的记录。每个节点代表一个对象或实体,例如一个人或一个地方。节点按标签分类,这有助于根据其角色对其进行分类和查询,例如“客户”或“产品”。
- 关系:这些是节点之间的连接,定义不同实体之间的交互或关系。例如,一个人可以通过“EMPLOYED_BY”关系与公司建立联系;或者通过“LIVES_IN”关系与某个地方建立联系。 除了节点和关系之外,还包括属性、标签和路径特征来表示和存储数据。
- 属性:节点和关系都可以包含属性,即以键值对形式存储的属性。这些属性提供有关实体的特定详细信息,例如人的姓名或年龄,或关系的长度。
- 标签:标签是分配给节点的标记,用于将节点分为不同类型。单个节点可以有多个标签,有助于更动态、更灵活地查询图。
- 路径:路径描述节点序列和连接节点的关系。它们表示图中的路线,显示不同节点如何互连。路径在查询中很有用,可以揭示节点之间的关系,例如在社交网络中发现从一个人到另一个人的所有可能路线。
使用/Cypher
Cypher 的基本概念是它允许你要求数据库查找与特定模式相匹配的数据。通俗地说,我们可能会要求数据库“找到类似这样的东西”,而我们描述“类似这样的东西”的方式是使用 ASCII 字符来绘制它们。
Cypher语言主要分为增删改查(CRUD)四个部分,也可抽象成读和写两个部分。但是不能同时读和写数据,每个部分要么匹配,要么更新。当需要使用聚合进行过滤时,必须使用WITH将读和写连接起来。
- 读:MATCH, OPTIONAL MATCH, WHERE, START, 聚合, LOAD CSV
- OPTIONAL MATCH 相当于SQL中的OUTER JOIN,找的和MATCH一样,找不到的项用null代替。
- 要过滤查询结果可以使用WHERE关键字,然后跟上过滤表达式。
- 写:CREATE, MERGE, SET, DELETE, REMOVE, FOREACH, CREATE, UNIQUE
- CREATE 用于创建点和边。创建数据不是INSERT,而是CREATE,因为图数据里不是简单地插入数据,而是创建节点、关系、属性或模式。使用逗号分隔。注意创建边的前提是,首先要找到边的两个节点!使用CREATE时,模式中所有不存在的部分都会被创建。
//创建边 MATCH (a:Person),(b:Person) WHERE a.name = 'Gaoj' AND b.name = 'Neoob' CREATE (a)-[r:RELATION1]->(b) RETURN a,b,r; - 更新属性使用SET,删除属性用REMOVE
- 删除节点或关系使用DELETE
- CREATE 用于创建点和边。创建数据不是INSERT,而是CREATE,因为图数据里不是简单地插入数据,而是创建节点、关系、属性或模式。使用逗号分隔。注意创建边的前提是,首先要找到边的两个节点!使用CREATE时,模式中所有不存在的部分都会被创建。
- 通用: RETURN, ORDER BY , LIMIT , SKIP, WITH, UNWIND, UNION , CALL
- WITH将分段的查询连接在一起,传递给另外一部分作为查询的开始。WITH 会影响查询结果集里的变量,WITH 语句外的变量不会传递到后续查询中。PS: match 后跟的是模式,不适合再跟count 等等计算了,所以用with 帮了一手。如果没有WITH子句,每个查询部分(或子句)将独立执行,不会保留前一个部分的结果或变量。
- UNION。将多个查询组合起来。和SQL类似,多个查询的列的名称和数量要一致!
| 元素 | 图数据库 | 元素 | 关系型数据库 |
|---|---|---|---|
| 点 | (matrix) | 表 | entity |
| 点标签 | (matrix:Movie) | 表名 | create table Movie (...) |
| 点属性 | {title,release,tagline} | 表字段 | create table Movie (id uuid pirmary key, title char,release number,tagline text); |
| 点数据(标签+属性键值对) | (TheMatrix:Movie {title:’The Matrix’, released:1999, tagline:’Welcome to the Real World’}) | 表的一行数据 | select * from Movie where id = 0; |
| 相同标签的点的所有数据 | MATCH (n:Movie) RETURN n LIMIT 25; | 表的所有数据 | select * from Movie limit 25; |
新增节点
create (n:Person) return n
create :新增关键字
( ) :一对小括号表示 node (节点)。Entity structure: alias:label {filters}
n :变量,用来代表当前节点,后面也可以使用它来引用。
Person :节点n的标签
return :用来把结果进行返回
新增属性
- 已有节点
match (n:Person) set n.name = "张三" , n.age = 18 return n match :查询关键字,在neo4j中用来执行查询操作,类似mysql中的select set :用来设置属性 - 新节点
create (n:Person{name:"李四"}) set n.age = 20 return n 没有节点的情况下,直接在create时,使用set进行赋值,或者是在节点标签后,使用一对大括号,进行赋值新增关系
match (n:Person{name:"张三"}) match (n1:Person{name:"李四"}) create p = (n)-[r:KNOWS{date:"2023-04-02",city:"北京"}]->(n1) return p 关系总是从一个起点指向一个终点。因此,需要有两个已知点。 ()-[]->():关系结构。箭头总是从起点指向终点 p:表示当前路径。包含起点、终点、关系信息 r:表示当前关系。仅仅包含关系信息删除属性
- remove
match (n:Person{name:"里斯"}) remove n.age return n - set
match (n:Person{name:"张三"}) set n.age = null return n 在Neo4j中,可以通过给属性赋值为 null,来进行属性的删除操作。删除关系
match (s:Person{name:"里斯"})-[r]->(t:Person) delete r
删除节点
match (n:Person{name:"里斯"}) delete n
如果两个节点之间有关系的时候。此时,执行节点删除,会提示删除失败。需要先删除关系,然后才能对节点进行删除。针对这种情况,还有另外一种删除方法。可以同时删除节点和关系
match (n:Person) detach delete n
更新属性
match (n:Person{name:"张三"}) set n.name = "小红" return n
查询节点
match (n:Person{name:"张三"} return n
查询属性
match (n:Person{name:"里斯"}) return n.name as name
查询关系
match p = (s:Person)-[r]->(e) return p
可以使用参数代替字面量来写Cypher。参数为字母+数字。已json文件的格式提供,具体如何提交取决于使用的驱动程序。
示例:参数 { "name": "John" }
示例:使用参数构建查询
MATCH (n)
WHERE n.name = $name
RETURN n;
或
MATCH (n {name: $name}) RETURN n;
其它
- 基于属性过滤做一些操作,比如
MATCH (n) where n.id = xx DETACH DETETE n或者MATCH (n {id: xx}) DETACH DETETE n都可以,但大佬们说后者性能更好,且有时只有后者生效。
逻辑架构
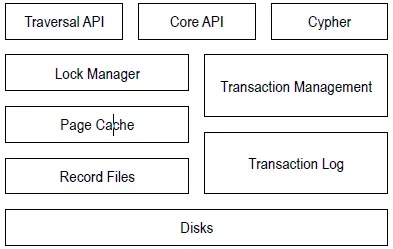
接口层:这是用户与数据库交互的层面,提供了多样化的访问和操作途径。
- Traversal API:专注于图遍历操作,允许用户高效地执行复杂的图路径查找。
- Core API:为核心 Java 组件提供接口,支持低级别数据访问,包括读取节点、关系和属性的原始图数据,以及确保数据操作的原子性和一致性。
- Cypher:作为 Neo4j 的声明式查询语言,Cypher 简化了图数据查询,类似于 SQL 对于关系型数据库的作用,通过 CQL 接口执行复杂的数据检索和更新。
数据管理层:负责数据访问的高级控制和优化,确保数据处理的高效与安全。
- 并发锁管理:通过有效的锁机制处理多线程或多用户的并发访问,防止数据冲突。
- 事务管理:确保数据修改的一致性和可靠性,支持事务的提交、回滚及隔离级别管理。
- 缓存管理:利用内存缓存技术加速数据访问,减少磁盘 I/O,提升整体性能。
- 存储管理:组织和优化数据结构,为上层提供高效的数据存取策略。
存储层:构成数据库的物理基础,负责实际数据的持久化存储。
- 这一层包含了图数据的实际存储空间,使用专门设计的数据结构(如 Neo4j 的原生图存储格式)来高效存储节点、关系及其属性,确保数据的长期保存和可恢复性。
存储
存储结构:Neo4j 采用固定大小的记录存储策略,分别在不同的存储文件中保存节点、关系和属性信息,主要文件包括:
neostore.nodestore.db
neostore.relationshipstore.db
neostore.propertystore.db
......
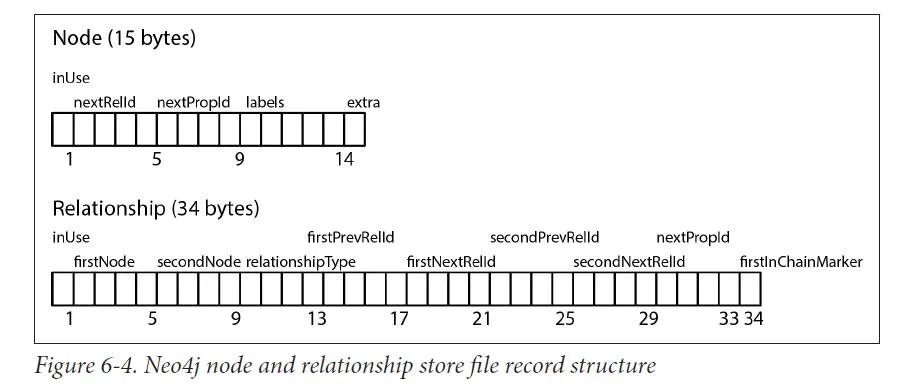
- 节点记录结构(neostore.nodestore.db):每个节点记录包含标志位、首个关系ID、首个属性ID、标签信息和一个预留位。节点不直接存储大量属性或关系数据,而是存储指向这些数据(如关系ID和属性ID)的指针,使得节点记录保持轻量。这样的设计允许快速定位节点及其关联关系和属性,得益于固定大小记录的直接寻址能力。
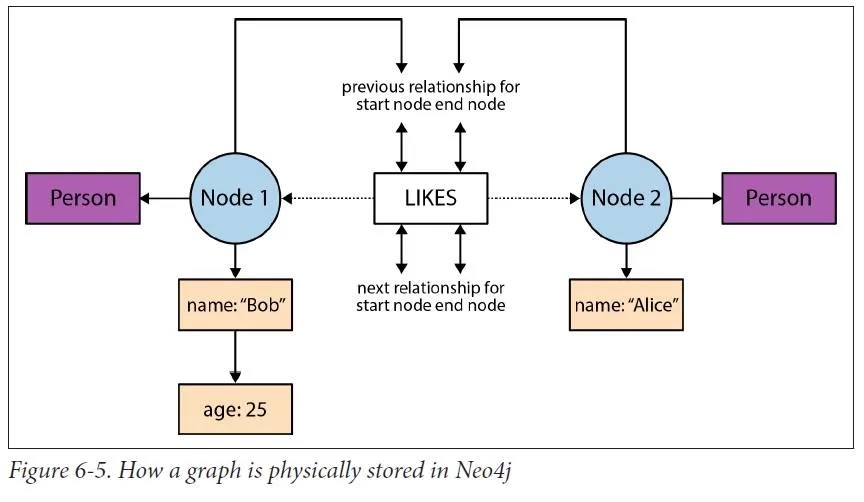
- 关系记录结构(neostore.relationshipstore.db):包括起始节点ID、结束节点ID、关系类型指针及关系链的前后指针,支持双向遍历。关系并非双倍存储,而是通过双向链表结构在两个节点之间共享,节省空间并保持高效。
- 属性存储(neostore.propertystore.db):属性以固定大小记录存储,每个记录可含多个属性块,并且根据属性值大小采用内联或外联存储策略。大属性值存储于独立的动态字符或数组存储文件中,仍保持高效访问。
关系是双向链表,属性是单向链表,额外的关系会按照链式结构存储在 neostore.relationshipstore.db 中:
遍历算法
图形数据库对于关系问题的解决比较擅长多对多关系的处理。之所以它能够擅长于各种基于图的业务场景的检索处理,就在于其强大的遍历算法。常见遍历算法有15种:
- 广度优先搜索(BFS):适合寻找最近的邻居和最短路径,适用于对等网络搜索、社交网络的局部探索。
- 深度优先搜索(DFS):适合深入探索分支结构,如在游戏中模拟决策树,寻找所有可能路径。
- 单源最短路径:计算一个节点到所有其他节点的最短路径,应用于导航系统、最低成本路由等。
- 全源最短路径:计算图中所有节点对之间的最短路径,支持动态路径选择,如备用网络路由规划。
- 最小生成树(MST):寻找连接所有节点的最低成本路径,应用于网络设计、基础设施规划等领域。
- PageRank:评估节点的重要性,根据链接的数量和质量,广泛应用于搜索引擎排名、社交影响力分析。
- Degree Centrality:通过节点的连接数衡量中心性,有助于识别关键节点或信息传播的源头。
- Closeness Centrality:衡量节点到达其他所有节点的效率,适合分析响应速度、信息扩散能力。
- Betweenness Centrality:测量通过节点的最短路径的数量,评估节点作为信息或资源流通桥梁的重要性,应用于网络瓶颈识别、社交网络影响力分析。
- Label Propagation:基于邻域多数的标签作为推断集群的手段,快速的社区检测方法,适用于共识分析、生物网络模块识别等。
- Strongly Connected Components:找出完全互相可达的节点集,有助于识别强关联群体或循环依赖。
- Union-Find/Connected Components:不考虑边的方向,找到互相可达的节点集,基础的图划分工具。
- Louvain Modularity:通过比较它的关系密度与适当定义的随机网络来测量社团分组的质量(即假定的准确性),用于复杂网络分析、组织结构优化。
- Local Clustering Coefficient:量化节点周围邻接的紧密程度,反映网络的局部凝聚力。
- Triangle-Count and Average Clustering Coefficient:测量网络中的三角形数量和节点聚集趋势,用于理解“小世界”现象、疾病传播模型等。
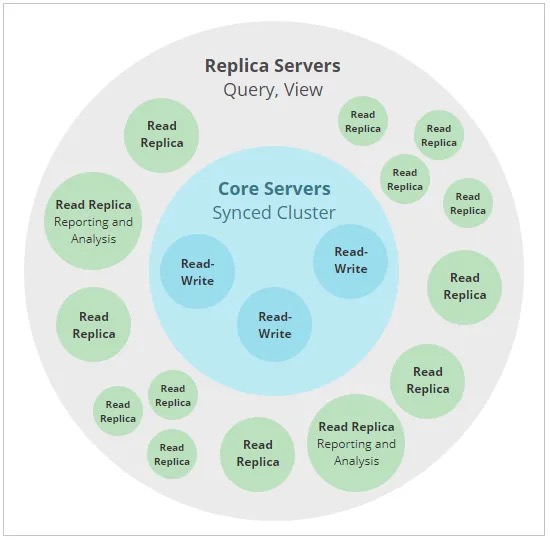
集群架构
集群架构,Neo4j 的 Causal Cluster 架构涉及两个关键角色:
- Core Servers:确保数据一致性与高可用性,通过 Raft 协议管理事务复制。
- Read Replicas:扩展读取能力,作为功能完整的只读数据库缓存,异步接收更新以分担查询负载,不参与集群决策。
留下评论