
简介
2025年认为的Agent: 25年什么样的 Agent 会脱颖而出:简单胜于复杂Anthropic 把下述两种统称为 agentic systems:
- Workflows: 通过预定义代码路径协调LLMs和Tools。
- Agents: LLM自主决定过程和Tools的使用,控制任务完成方式。一般来说是由agent loop驱动的一种专门的AI系统。在每一个循环迭代中,它借助LLM动态决策,自动调用适当的工具,存取恰当的记忆。每经过一次循环,就向着任务目标前进一步。
Agent的定义是随着大模型的发展而变化的;从人类编排任务流程到人类描述详细任务细节到人类发出简单指令,AI在其中扮演的规划、执行角色从少到多,Agent也在不同阶段有不同的定义。但是上述不同阶段会长久地并存,就像Python的出世,并不会影响到C/C++/Java的消亡,因为物理世界是复杂的,大家可以在不同领域发光发热。
Agent的构建分为不同复杂度级别,从基础的增强型大语言模型Augmented LLM开始,逐步发展到预定义的workflow,最终形成自主的 agent。
- 增强型大语言模型(augmented LLM)是Agent的基本构建单元,它集成了检索、工具和记忆等能力。现代模型能够主动使用这些功能,如生成搜索查询和选择适当工具。PS:比如让llm 输出struct,很多框架都提供llm.structured_predict
- 对于可预测、定义明确的任务,需要一致性时使用workflows;比如某些开源的 Deep Research 项目中,有几种复现方式
- 将用户问题分解为多个子查询,每个子查询由不同模型或模块处理,最后由一个模型统一整合答案。
- 模型先给出初步回答,然后自我评价打分,假如评价不 ok,就循环修改,直到达到满意结果,类似于毕业论文的修改过程。
- 相比于 workflow,Agent 的设计反而是很简单。背后依靠强大的推理模型,让模型自己去理解复杂输入、进行推理和规划、使用工具以及从错误中恢复。Agent在循环(loop)中工作,根据输入自己选择合适的工具,并能根据环境反馈调整策略——例如当代码执行失败时,能根据错误信息自动修正;智能体的核心在于模型主导全部决策过程(模型能够在 in a loop 中自主处理问题,无须人为定制某个step+prompt干预),人类无需预先定义详细流程,只需在特定情况下提供少量干预,如在Deep Research中我们只需要确认关键的信息或在Operator中当输入账号密码等敏感信息需要人类干预。本质上,agent将复杂任务的规划和执行权交给模型,所谓模型即服务,采用端到端的优化来提升效果。顶级的 Agent 可能工程代码及其简洁,这种简洁的背后,是超高质量的训练数据+极致的端到端强化训练。所有 if-else 和 workflow 的选择将由模型自身判断完成,而非依赖人工编写的规则代码。 做 LLM 项目最重要的不是构建最复杂的系统,而是为你的需求找到最合适的解决方案,建议从简单提示开始,只在必要时才引入复杂的智能体系统。
对于应用型算法工程师的启发
- 积累场景测试集,持续测试新的模型。
- 学会微调,积累微调insight。 要取得好的效果还是需要微调。无论是SFT还是RL,日常阅读论文时,要重点关注论文中数据的构建和实验思路。虽然现在有如llama_factory、openrlhf等微调框架,让微调变得简单,但工程师更重要的是积累微调的insight。例如,何时需要微调,何时通过改prompt即可解决问题;如何构建高质量数据集,怎么让业务同事也心甘情愿帮你标数据,多少数据能达到什么效果;何时使用SFT,何时使用RL。这些除了通过阅读论文获取一些方向思路外,更重要的是在自己的业务场景中多尝试。
- 工程实践中避免过度设计。遇到新场景时,优先考虑“做减法”,而非“加积木”。例如,你开发了一个算法应用,一段时间后产品经理提出需要处理一个边缘情况,此时你不应优先考虑叠加新的处理模型或增加模型,而是:查看新出的模型是否能解决该情况,并简化之前的流程。这对应第一点,积累场景测试集,持续测试新的模型;基于对业务和数据的理解,尝试通过高质量业务数据+微调的方式解决问题,甚至合并之前的流程。这对应第二点,学会微调,积累微调经验。
- 选择与大模型协同发展的方向。尽可能选择那些随着大模型的升级,应用效果会变得更好的解决方案,而不是做那些更强大的模型出来后之前的努力就白费的解决方案。
- 对于能够快速通过workflow达到交付要求的场景,直接使用工作流即可。所以工程师还是需掌握各类框架,以快速灵活应对不同需求。但如果是一个长期需要不断优化的应用,那么请考虑一下采用端到端优化的形式。
简单使用LLM 是不够的
纯问答的场景只是大模型落地的第一步,还有许许多多场景是需要AI大模型与现实世界进行“连接”才能完成的。我们并不需要一个只知道聊天的机器人“玩具”,我们需要的正是这种“有手有脚”的大模型、能做事情的大模型。比如客户的问题是“退款”,那么客户想要执行退款这个操作,而不是大模型提供一堆退款的规则和步骤,因为绝大多数的人对于很长的文字是很难完全有耐心能阅读下去的。试想一下,当你躺在家里的床上准备睡觉的时候,突然发现窗帘没有关上,如果这时候跟大模型说“请帮我关闭我家的窗帘”,其实我们并不想听到大模型回复了一大段的“关闭窗帘的步骤”,如果大模型真的像一个人一样能够完成这件事情,那该有多酷!甚至当你说出一些稍微复杂指令,比如“窗帘不用全部关上,给我留一个缝”,如果大模型也能“理解”并且能自动将“留一个缝”这种自然语言转换为控制“窗帘闭合百分比”这样的一个量化参数并且真正将窗帘关闭到合适位置的时候,那么大模型才真正能在各行各业的落地中带来一波大的浪潮。
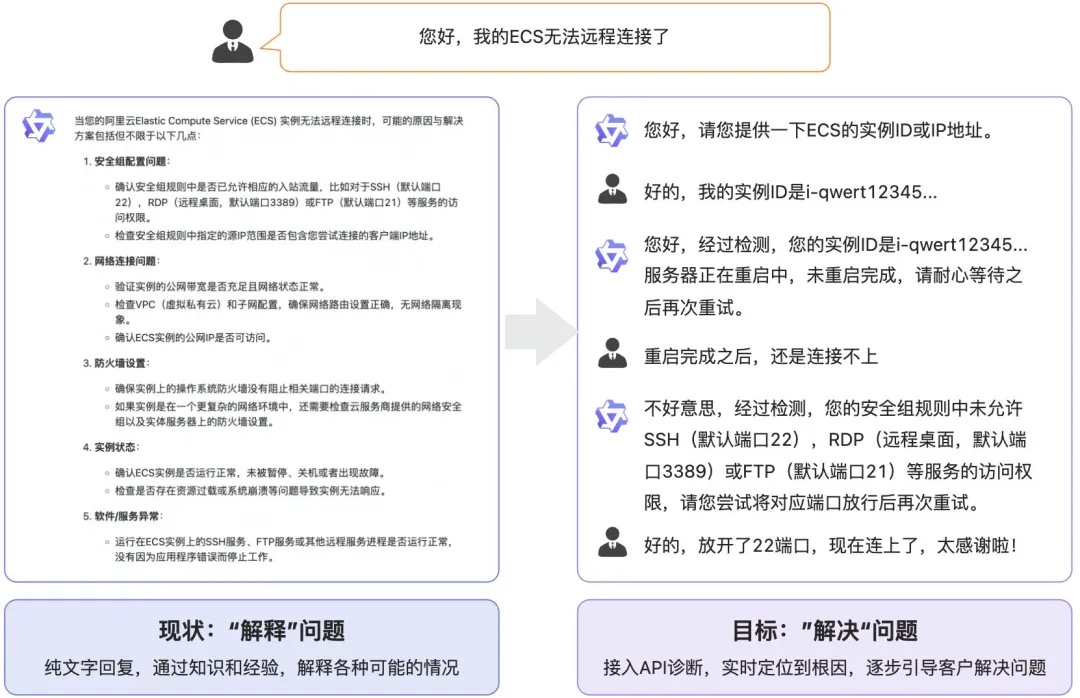
目前的大模型一般都存在知识过时、逻辑计算能力低等问题,通过Agent访问工具,可以去解决这些问题。Agent是指能够感知环境、做出决策和采取行动的实体。本质上还是prompt工程,通过Prompt去驱动模型进行 计划和工具调用。PS:你知道一个工具的存在,约等于你会调用这个工具;你会调用这个工具,约等于你会学习使用这个工具;会学习这个工具,约等于你已经会用这个工具;所以,你知道工具的存在,约等于你能把这件事做出来。搜索高于学习, 学习高于熟练。
吴恩达:目前,我们使用大语言模型的主要方式是一种non-agentic工作流程,即您输入一个提示,模型就生成一个回答。这有点像让一个人坐下来一次性从头到尾编写一篇文章,而不允许使用退格键,尽管这样做很难,但大语言模型的表现出奇地出色。相比之下,代理工作流程看起来是这样的:首先,让人工智能大语言模型写一个文章大纲,如果需要进行网络研究就先做研究,然后写出第一稿,然后阅读并思考需要修订的部分,再修改这一稿,如此循环往复、迭代多次。很多人没有意识到,这种做法可以带来显著的改进效果。我自己在使用这些代理工作流程时也感到非常惊讶,它们工作得如此之好。研究发现,GPT-3.5使用零样本提示时只有48%的正确率,GPT-4提高到了67%。但如果在GPT-3.5上使用一个代理工作流程,它的表现实际上比GPT-4还要好。如果在GPT-4上使用代理工作流程,它的表现也非常出色。这意味着采用代理工作流程对于构建应用程序至关重要。不过我们需要改变一种习惯,那就是习惯了在提示语言模型后立即获得响应。在代理工作流程中,我们需要学会能够耐心等待几分钟甚至几个小时,才能得到响应,就像我们交代任务给人时需要适当地等待一段时间再进行检查一样。
原理
在 Agent 应用的开发和实践中,核心挑战之一是如何优雅地实现一个可控的循环(Loop)机制。这个循环机制不仅需要能够自动化地执行任务,还要能够在执行过程中根据反馈进行自我调整和优化(Loop+Feedback )。通过这种方式,LLM 能够模仿人类解决问题的基本方法论,如 PDCA(计划-执行-检查-行动)循环,从而更有效地拆解和解决问题。
认知框架Cognitive Architecture
AgentType 对应一个Agent class,对应一个prompt(又是prompt 起了关键作用),AgentType 有以下几种选择
- zero-shot ReAct,完全依靠对所用到的tools 的说明书来理解和使用tools,理论上支持无限多个。
- Structured tool chat,跟第一个不同的地方在于接收一个结构化的dict 作为参数且能记住上下文。
- OpenAI functions,OpenAI 在大模型层面针对 API的调用做了训练,相当于帮大家做了SFT,可以想象效果必然好。
- conversational,类似于第一、二类型,针对对话场景做了优化,比如聊天记录、聊天轮次等meta-data
- self-ask,通过自问自答的方式把大问题拆解成小问题之后再组成最终的单子。
ReAct是 Shunyu Yao 等人在 ICLR 2023 会议论文《ReAct: Synergizing Reasoning and Acting in Language Models》中提出的,一个关键启发在于:大语言模型可以通过生成推理痕迹和任务特定行动来实现更大的协同作用。具体来说,就是引导模型生成一个任务解决轨迹:观察环境 - 进行思考 - 采取行动,也就是观察 - 思考 - 行动。那么,再进一步进行简化,就变成了推理 - 行动,是一种将推理和行动相结合的思考链模式(PS:知行合一?),以交错的方式产生与任务相关的语言推理轨迹和行动。ReAct 框架会提示 LLMs 为任务生成推理轨迹和操作,这使得代理能系统地执行动态推理来创建、维护和调整操作计划,同时还支持与外部环境(例如 Google 搜索、Wikipedia)的交互,以将额外信息合并到推理中。PS:使用LLM来做ifelse,ReAct提示大型语言模型为给定任务生成口头推理历史步骤和操作。这些提示由少量的上下文示例组成,这些示例指导模型的思考和操作生成。
与CoT推理一样,ReAct 也是一种提示工程方法,它使用少量学习来教模型如何解决问题。CoT 被认为是模仿人类如何思考问题,ReAct 也包括了这个推理元素,但它更进一步,允许Agent操作文本,让它与环境互动。人类使用语言推理来帮助我们制定策略并记住事情,但也可以采取行动来获得更多的信息并实现目标。这就是 ReAct 的基础(PS:知行合一?)。ReAct 提示包括行动的例子、通过行动获得的观察结果,以及人类在过程中各个步骤中转录的思想(推理策略)。LLM 学习模仿这种交叉思考和行动的方法,使其成为其环境中的Agent。
一定要记住,观察结果不是由 LLM 生成的,而是由环境生成的,环境是一个单独的模块,LLM 只能通过特定的文本操作与之交互。因此,为了实现 ReAct,需要:
- 一种环境,它采取一个文本操作, 从一组可以根据环境的内部状态改变的潜在操作中返回一个文本观察。
- 一个输出解析器框架,一旦Agent编写了一个有效的操作,它就停止生成文本,在环境中执行该操作,并返回观察结果, 一般是将其追加到目前生成的文本中,并用该结果提示 LLM。
- 人工产生的示例,混合了思想,行动和观察,在环境中可以使用few-shot,例子的数量和细节取决于目标和开发者的设计
ReAct Agent 的一般提示词结构:
前缀:引入工具的描述
格式:定义React Agent的输出格式
问题:用户输入的问题
思考:React Agent推理如何行动
行动:需要使用的工具
行动输入:工具所需输入
观察:行动执行后得到的结果
(按需重复:思考-行动-观察流程)
终点推理:产生最终结论
最后回答:问题的答案
stop token
How to Get Better Outputs from Your Large Language ModelIt is especially useful to design a stopping template in a few-shot setting so the model can learn to stop appropriately upon completing an intended task. Figure shows separating examples with the string “===” and passing that as the stop word.我们知道一般 LLM 都会长篇大论,说一大堆废话,我们希望 LLM 在返回了我们需要的信息后就停止输出,这里就需要用到stop参数,这个参数是一个列表,列表中的每个元素都是一个字符串,代表了 LLM 输出中的某一句话,当 LLM 输出中包含了这句话时,LLM 就会停止输出,这样我们就可以只获取到我们需要的信息了
框架
开发AI Agent到底用什么框架——LangGraph VS. LlamaIndex为什么LangGraph和LlamaIndex都基本上能做到用一个统一的底层编排系统来支持各种自主程度不同的Agentic System?(workflow和agent)不同程度的自主性,本质意味着什么?这个本质在于系统编排的执行路径是在何时决策的。静态编排的执行路径是完全提前确定好的,不具有太多自主性。自主性必然要求某种程度的动态编排特性才能支持。LangGraph和LlamaIndex的编排系统都有一个重要特性:能够在执行过程中动态地改变节点偏序关系。在LangGraph中,这是通过节点在superstep末尾发送动态消息做到的,而在LlamaIndex中则是通过每个step节点动态地发送事件做到的。换句话说,它们都具有动态编排的特性。对比一下,类似Dify那样,在程序执行之前就可视化地编排出整个Workflow的系统,对于自主系统的支持则是非常有限的。当深入到这个抽象层次上来看,LangGraph和LlamaIndex的编排系统,虽然它们暴露的编程接口、实现的完备程度、对于概念的抽象都完全不同,但最最底层的逻辑又是殊途同归的。
langchain使用
在chain中,操作序列是硬编码的。智能体通过将LLM与动作列表结合,自动选择最佳动作序列,从而实现自动化决策和行动。Agent在LangChain框架中负责决策制定以及工具组的串联,可以根据用户的输入决定调用哪个工具。通过精心制定的提示,我们能够赋予代理特定的身份、专业知识、行为方式和目标。提示策略为 Agent 提供了预设模板,结合关键的指示、情境和参数来得到 Agent 所需的响应。具体的说,Agent就是将大模型进行封装来简化用户使用,根据用户的输入,理解用户的相应意图,通过action字段选用对应的Tool,并将action_input作为Tool的入参,来处理用户的请求。当我们不清楚用户意图的时候,由Agent来决定使用哪些工具实现用户的需求。
自定义tool 实现
from langchain.tools import BaseTool
# 天气查询工具 ,无论查询什么都返回Sunny
class WeatherTool(BaseTool):
name = "Weather"
description = "useful for When you want to know about the weather"
def _run(self, query: str) -> str:
return "Sunny^_^"
async def _arun(self, query: str) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("BingSearchRun does not support async")
# 计算工具,暂且写死返回3
class CustomCalculatorTool(BaseTool):
name = "Calculator"
description = "useful for when you need to answer questions about math."
def _run(self, query: str) -> str:
return "3"
async def _arun(self, query: str) -> str:
raise NotImplementedError("BingSearchRun does not support async")
# 这里使用OpenAI temperature=0,temperature越大表示灵活度越高,输出的格式可能越不满足我们规定的输出格式,因此此处设置为0
llm = OpenAI(temperature=0)
tools = [WeatherTool(), CalculatorTool()]
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
agent.run("Query the weather of this week,And How old will I be in ten years? This year I am 28")
# 执行结果
I need to use two different tools to answer this question
Action: Weather
Action Input: This week
Observation: Sunny^_^
Thought: I need to use a calculator to answer the second part of the question
Action: Calculator
Action Input: 28 + 10
Observation: 3
Thought: I now know the final answer
Final Answer: This week will be sunny and in ten years I will be 38.
LangChain Agent中,内部是一套问题模板(langchain-ai/langchain/libs/langchain/langchain/agents/chat/prompt.py):
PREFIX = """Answer the following questions as best you can. You have access to the following tools:"""
FORMAT_INSTRUCTIONS = """Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question"""
SUFFIX = """Begin!
Question: {input}
Thought:{agent_scratchpad}"""
这个提示词就是 Agent 之所以能够趋动大模型,进行思考 - 行动 - 观察行动结果 - 再思考 - 再行动 - 再观察这个循环的核心秘密。有了这样的提示词,模型就会不停地思考、行动,直到模型判断出问题已经解决,给出最终答案,跳出循环。
通过这个模板,加上我们的问题以及自定义的工具,会变成下面这个样子(# 后面是增加的注释)
Answer the following questions as best you can. You have access to the following tools: # 尽可能的去回答以下问题,你可以使用以下的工具:
Calculator: Useful for when you need to answer questions about math.
# 计算器:当你需要回答数学计算的时候可以用到
Weather: useful for When you want to know about the weather # 天气:当你想知道天气相关的问题时可以用到
Use the following format: # 请使用以下格式(回答)
Question: the input question you must answer # 你必须回答输入的问题
Thought: you should always think about what to do
# 你应该一直保持思考,思考要怎么解决问题
Action: the action to take, should be one of [Calculator, Weather] # 你应该采取[计算器,天气]之一
Action Input: the input to the action # 动作的输入
Observation: the result of the action # 动作的结果
... (this Thought/Action/Action Input/Observation can repeat N times) # 思考-行动-输入-输出 的循环可以重复N次
Thought: I now know the final answer # 最后,你应该知道最终结果了
Final Answer: the final answer to the original input question # 针对于原始问题,输出最终结果
Begin! # 开始
Question: Query the weather of this week,And How old will I be in ten years? This year I am 28 # 问输入的问题
Thought:
我们首先告诉 LLM 它可以使用的工具,在此之后,定义了一个示例格式,它遵循 Question(来自用户)、Thought(思考)、Action(动作)、Action Input(动作输入)、Observation(观察结果)的流程 - 并重复这个流程直到达到 Final Answer(最终答案)。如果仅仅是这样,openai会完全补完你的回答,中间无法插入任何内容。因此LangChain使用OpenAI的stop参数,截断了AI当前对话。"stop": ["\nObservation: ", "\n\tObservation: "]。做了以上设定以后,OpenAI仅仅会给到Action和 Action Input两个内容就被stop停止。以下是OpenAI的响应内容:
I need to use the weather tool to answer the first part of the question, and the calculator to answer the second part.
Action: Weather
Action Input: This week
这里从Tools中找到name=Weather的工具,然后再将This Week传入方法。具体业务处理看详细情况。这里仅返回Sunny。 由于当前找到了Action和Action Input。 代表OpenAI认定当前任务链并没有结束。因此向tool请求后拼接结果:Observation: Sunny 并且让他再次思考Thought。开启第二轮思考:下面是再次请求的完整请求体:
Answer the following questions as best you can. You have access to the following tools:
Calculator: Useful for when you need to answer questions about math.
Weather: useful for When you want to know about the weather
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [Calculator, Weather]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: Query the weather of this week,And How old will I be in ten years? This year I am 28
Thought: I need to use the weather tool to answer the first part of the question, and the calculator to answer the second part.
Action: Weather
Action Input: This week
Observation: Sunny^_^
Thought:
同第一轮一样,OpenAI再次进行思考,并且返回Action 和 Action Input 后,再次被早停。
I need to calculate my age in ten years
Action: Calculator
Action Input: 28 + 10
由于计算器工具只会返回3,结果会拼接出一个错误的结果,构造成了一个新的请求体进行第三轮请求:
Answer the following questions as best you can. You have access to the following tools:
Calculator: Useful for when you need to answer questions about math.
Weather: useful for When you want to know about the weather
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [Calculator, Weather]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: Query the weather of this week,And How old will I be in ten years? This year I am 28
Thought: I need to use the weather tool to answer the first part of the question, and the calculator to answer the second part.
Action: Weather
Action Input: This week
Observation: Sunny^_^
Thought:I need to calculate my age in ten years
Action: Calculator
Action Input: 28 + 10
Observation: 38
Thought:
此时两个问题全都拿到了结果,根据开头的限定,OpenAi在完全拿到结果以后会返回I now know the final answer。并且根据完整上下文。把多个结果进行归纳总结:下面是完整的相应结果:
I now know the final answer
Final Answer: I will be 38 in ten years and the weather this week is sunny.
可以看到。ai严格的按照设定返回想要的内容,并且还以外的把28+10=3这个数学错误给改正了。通过 verbose=True 可以动态查看上述过程。 PS: 通过prompt 引导llm 进行文字接龙,通过解析文字接龙来进行tool 的调用。
根据输出再回头看agent的官方解释:An Agent is a wrapper around a model, which takes in user input and returns a response corresponding to an “action” to take and a corresponding “action input”. 本质上是通过和大模型的多轮对话交互来实现的(对比常规聊天时的一问一答/单轮对话), 不断重复“Action+ Input -> 结果 -> 下一个想法”,一直到找到最终答案。通过特定的提示词引导LLM模型以固定格式来回复,LLM模型回复完毕后,解析回复,这样就获得了要执行哪个tool,以及tool的参数。然后就可以去调tool了,调完把结果拼到prompt中,然后再让LLM模型根据调用结果去总结并回答用户的问题。
大多数 Agent 主要是在某种循环中运行 LLM。目前,我们使用的唯一方法是 AgentExecutor。我们为 AgentExecutor 添加了许多参数和功能,但它仍然只是运行循环的一种方式。langgraph是一个新的库,旨在创建语言 Agent 的图形表示。这将使用户能够创建更加定制化的循环行为。用户可以定义明确的规划步骤、反思步骤,或者轻松设置优先调用某个特定工具。
agno
agnoWhat are Agents? Agents are AI programs that execute tasks autonomously. They solve problems by running tools, accessing knowledge and memory to improve responses. Unlike traditional programs that follow a predefined execution path, agents dynamically adapt their approach based on context, knowledge and tool results.
Instead of a rigid binary definition, let’s think of Agents in terms of agency and autonomy.
- Level 0: Agents with no tools (basic inference tasks).
- Level 1: Agents with tools for autonomous task execution.
- Level 2: Agents with knowledge, combining memory and reasoning.
- Level 3: Teams of specialized agents collaborating on complex workflows. PS: llm 根据kb、memory来执行tool(相对传统结构化编程 if else while 明确过程来说)
从框架设计思想上来说
- 几个基本组件都做了抽象,比如Document/Embedder/AgentKnowledge(知识库)/AgentMemory/Model(模型)/Reranker/Toolkit/VectorDb。PS:一般业务开发时,langchain 或llamaindex 的类似抽象也很难完全满足需要,往往要独立的提出这些组件的抽象,此时就是一个很好的参考。
- 只有一个Agent class,持有了几乎所有可能需要的组件,Agent.run 用一个最复杂的流程 来兼容L0到L3。PS:这也导致我们很难对链路做个性化调整,但确实是很多开源框架的思路。具体细节上有很多值得参考的地方,比如流式吐字、多模态、推理模型等。
| 手写Agent | 使用框架 | |
|---|---|---|
| 入口 | Agent.run | Workflow.run |
| 逻辑串联 | 代码手撸,父类定义几个抽象方法,做好编排,子类做个性化实现 | 使用langgraph或llamaindex workflow 来做逻辑串联 |
| 步骤定义 | 类的方法 | workflow类的方法 |
| 状态共享 | 类的成员 | workflow.context, workflow类成员 |
| 推理的上下文 | memory | memory,之前笔者不太熟的时候,会用current_reasonngs 来记录 |
agent = Agent(
model=OpenAIChat(id="gpt-4o"),
description="You are a Thai cuisine expert!",
instructions=[
"Search your knowledge base for Thai recipes.",
"If the question is better suited for the web, search the web to fill in gaps.",
"Prefer the information in your knowledge base over the web results."
],
knowledge=PDFUrlKnowledgeBase(
urls=["https://agno-public.s3.amazonaws.com/recipes/ThaiRecipes.pdf"],
vector_db=LanceDb(
uri="tmp/lancedb",
table_name="recipes",
search_type=SearchType.hybrid,
embedder=OpenAIEmbedder(id="text-embedding-3-small"),
),
),
tools=[DuckDuckGoTools()],
show_tool_calls=True,
markdown=True
)
agent.print_response("How do I make chicken and galangal in coconut milk soup", stream=True)
langchain源码
Agent 可以看做在Chain的基础上,进一步整合Tool 的高级模块。与Chain 相比,Agent 具有两个新增的能力:思考链和工具箱。能根据环境变化更新计划,使决策更加健壮。思考链释放了大模型的规划和调度潜能,是Agent的关键创新,Agent 定义了工具的标准接口,以实现无缝集成。与Chain 直接调用模块/Runnable相比,它只关心tool 输入和输出,tool内部实现对Agent 透明,工具箱大大扩展了Agent的外部知识来源,使其离真正的通用智能更近一步。
LangChain关键组件
- 代理(Agent):这个类决定下一步执行什么操作。它由一个语言模型和一个提示(prompt)驱动。提示可能包含代理的性格(也就是给它分配角色,让它以特定方式进行响应)、任务的背景(用于给它提供更多任务类型的上下文)以及用于激发更好推理能力的提示策略(例如 ReAct)。LangChain 中包含很多种不同类型的代理。PS: 一般情况下,一个Agent 像Chain一样,都会对应一个prompt。
- 工具(Tools):工具是代理调用的函数。这里有两个重要的考虑因素:一是让代理能访问到正确的工具,二是以最有帮助的方式描述这些工具。如果你没有给代理提供正确的工具,它将无法完成任务。如果你没有正确地描述工具,代理将不知道如何使用它们。LangChain 提供了一系列的工具,同时你也可以定义自己的工具,或者将函数转换为tool。
class BaseTool(RunnableSerializable[Union[str, Dict], Any]): name: str description: str def invoke(self, input: Union[str, Dict],config: Optional[RunnableConfig] = None,**kwargs: Any,) -> Any: ... return self.run(...) class Tool(BaseTool): description: str = "" func: Optional[Callable[..., str]] coroutine: Optional[Callable[..., Awaitable[str]]] = None - 代理执行器(AgentExecutor):代理执行器是代理的运行环境,它调用代理并执行代理选择的操作。执行器也负责处理多种复杂情况,包括处理代理选择了不存在的工具的情况、处理工具出错的情况、处理代理产生的无法解析成工具调用的输出的情况,以及在代理决策和工具调用进行观察和日志记录。AgentExecuter负责迭代运行Agent,直至满足设定的停止条件,这使得Agent能够像生物一样循环处理信息和任务。
AgentExecutor由一个Agent和Tool的集合组成。AgentExecutor负责调用Agent,获取返回(callback)、action和action_input,并根据意图将action_input给到具体调用的Tool,获取Tool的输出,并将所有的信息传递回Agent,以便猜测出下一步需要执行的操作。AgentExecutor.run也就是chain.run ==> AgentExecutor/chain.__call__ ==> AgentExecutor._call() 和逻辑是 _call 方法,核心是 `output = agent.plan(); tool=xx(output); observation = tool.run();
def initialize_agent(tools,llm,...)-> AgentExecutor:
agent_obj = agent_cls.from_llm_and_tools(llm, tools, callback_manager=callback_manager, **agent_kwargs)
AgentExecutor.from_agent_and_tools(agent=agent_obj, tools=tools,...)
return cls(agent=agent, tools=tools, callback_manager=callback_manager, **kwargs)
# AgentExecutor 实际上是一个 Chain,可以通过 .run() 或者 _call() 来调用
class AgentExecutor(Chain):
agent: Union[BaseSingleActionAgent, BaseMultiActionAgent]
tools: Sequence[BaseTool]
"""Whether to return the agent's trajectory of intermediate steps at the end in addition to the final output."""
max_iterations: Optional[int] = 15
def _call(self,inputs: Dict[str, str],...) -> Dict[str, Any]:
while self._should_continue(iterations, time_elapsed):
next_step_output = self._take_next_step(name_to_tool_map,inputs,intermediate_steps,...)
# 返回的数据是一个AgentFinish类型,表示COT认为不需要继续思考,当前结果就是最终结果,直接将结果返回给用户即可;
if isinstance(next_step_output, AgentFinish):
return self._return(next_step_output, intermediate_steps, run_manager=run_manager)
if len(next_step_output) == 1:
next_step_action = next_step_output[0]
# See if tool should return directly
tool_return = self._get_tool_return(next_step_action)
if tool_return is not None:
return self._return(tool_return, intermediate_steps, run_manager=run_manager)
iterations += 1
time_elapsed = time.time() - start_time
return self._return(output, intermediate_steps, run_manager=run_manager)
def _take_next_step(...):
# 调用LLM决定下一步的执行逻辑
output = self.agent.plan(intermediate_steps,**inputs,...)
if isinstance(output, AgentFinish): # 如果返回结果是AgentFinish就直接返回
return output
if isinstance(output, AgentAction): # 如果返回结果是AgentAction,就根据action调用配置的tool
actions = [output]
result = []
for agent_action in actions:
tool = name_to_tool_map[agent_action.tool]
observation = tool.run(agent_action.tool_input,...)
result.append((agent_action, observation)) # 调用LLM返回的AgentAction和调用tool返回的结果(Obversation)一起加入到结果中
return result
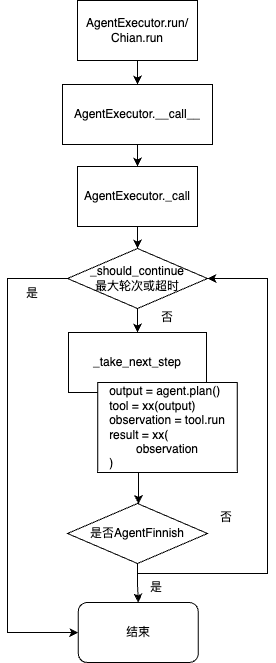
Agent.plan() 可以看做两步:
- 将各种异构的历史信息转换成 inputs,传入到 LLM 当中;
- 根据 LLM 生成的反馈,采取决策。LLM 生成的回复是 string 格式,langchain 中ZeroShotAgent 通过字符串匹配的方式来识别 action。
因此,agent 能否正常运行,与 prompt 格式,以及 LLM 的 ICL 以及 alignment 能力有着很大的关系。
- LangChain主要是基于GPT系列框架进行设计,其适用的Prompt不代表其他大模型也能有相同表现,所以如果要自己更换不同的大模型(如:文心一言,通义千问…等)。则很有可能底层prompt都需要跟著微调。
- 在实际应用中,我们很常定期使用用户反馈的bad cases持续迭代模型,但是Prompt Engeering的工程是非常难进行的微调的,往往多跟少一句话对于效果影响巨大,因此这类型产品达到80分是很容易的,但是要持续迭代到90分甚至更高基本上是很难的。
# 一个 Agent 单元负责执行一次任务
class Agent(...):
llm_chain: LLMChain
allowed_tools: Optional[List[str]] = None
# agent 的执行功能在于 Agent.plan()
def plan(self,intermediate_steps: List[Tuple[AgentAction, str]],callbacks: Callbacks = None,**kwargs: Any,) -> Union[AgentAction, AgentFinish]:
# # 将各种异构的历史信息转换成 inputs,传入到 LLM 当中
full_inputs = self.get_full_inputs(intermediate_steps, **kwargs)
# 根据 LLM 生成的反馈,采取决策
full_output = self.llm_chain.predict(callbacks=callbacks, **full_inputs)
# full_output 是纯文本,通过断点调试可以看到,真的就是靠正则表达式提取tool的名称
# 最后的输出 AgentAction 中会包括:需要使用的 tool,使用该 tool 时候,对应的执行命令。
return self.output_parser.parse(full_output)
有人希望通过一些开源的 LLM 来实现 ReAct Agent,但实际开发过程中会发现开源低参数(比如一些 6B、7B 的 LLM)的 LLM 对于提示词的理解会非常差,根本不会按照提示词模板的格式来输出(例如不按Action: xx Action Input: xx返回),这样就会导致我们的 Agent 无法正常工作,所以如果想要实现一个好的 Agent,还是需要使用好的 LLM,目前看来使用gpt-3.5模型是最低要求。
代码解释器
ChatGLM3 的代码解释器(Code Interpreter)实现原理:背后的原理其实跟工具调用是一样的。无非就是将普通的函数替换成代码解释器,大模型预测的结果不再是函数的入参,而是具体的代码,根据这些代码我们调用代码解释器执行,然后在界面上面支持显示代码执行的结果。
要了解大模型是如何学会使用代码解释器的,就要先看训练样本是如何构造的。下面是一个官方提供的例子:
<|system|>
你是一位智能AI助手,你叫ChatGLM3,你连接着一台电脑,但请注意不能联网。在使用Python解决任务时,你可以运行代码并得到结果,如果运行结果有错误,你需要尽可能对代码进行改进。你可以处理用户上传到电脑上的文件,文件默认存储路径是/mnt/data/。
<|user|>
帮我画一个爱心
<|assistant|>interpreter
```python
import numpy as np
import matplotlib.pyplot as plt
# 爱心形状的参数方程
def heart(t):
x = 16 * np.sin(t) ** 3
y = 13 * np.cos(t) - 5 * np.cos(2 * t) - 2 * np.cos(3 * t) - np.cos(4 * t)
return x, y
t = np.linspace(0, 2 * np.pi, 1000)
x, y = heart(t)
plt.figure(figsize=(6, 6))
plt.plot(x, y, color='red')
plt.axis('equal')
plt.axis('off')
plt.show()
```
<|observation|>
```result
【image】
```
<|assistant|>
这是一个爱心形状。我使用了参数方程来描述这个形状,并使用matplotlib进行了绘制。如果您有任何其他需求或问题,请随时告诉我。
<|user|> # End
调优
BFCL 评测评估模型 Agent 能力。PS:llm 作为agent 使用时,选择工具的能力(结构化输出json);制定计划;识别问题是否充分回答;对特定工具的使用(网络检索、代码解释器等)是否得心应手。
模型AgentTuning
AgentLM:能打的 Agent 模型来了!开源模型并非没有完成智能体任务的能力,可能只是在智能体任务上缺乏对齐。对于 Agent 能力提升的策略,现有许多工作多使用 Prompt / 微调方法优化模型,在单项智能体任务上取得了卓越的表现,但智能体任务之间的促进及泛化效果有待进一步探索。智谱AI&清华KEG提出了一种对齐 Agent 能力的微调方法 AgentTuning,该方法使用少量数据微调已有模型,显著激发了模型的 Agent能力,同时可以保持模型原有的通用能力。AgentTuning 主要包括 2 个阶段。首先,我们收集并过滤得到一个多任务指令微调数据集 AgentInstrcut;然后,我们将 AgentInstruct 数据集与通用数据对模型进行混合微调。评估结果表明,AgentTuning 能让 LLM 的 Agent 能力在未见过的 Agent 任务中展现出强大的泛化,同时保持良好的通用语言能力。AgentInstruct 是一个经过筛选的智能体任务数据集。其包含 6 项智能体任务,从 Shell 交互到数据库操作,平均回合数从 5 到 35 不等,每条轨迹都有 ReAct 形式的 CoT 标注,帮助模型深入理解决策过程。PS: 大家发现Agent/react 有用,就微调LLM强化这方面的能力。
大模型Agent RL训练多轮planning技术DeepSeek R1带火基于GRPO的强化学习技术后,agentic tool use learning也开始用上了GRPO,Reinforce++, PPO, policy gradient等各种算法了(以前是SFT+DPO,需要大量的标注数据来cover bad case,当时标注高质量数据都把我标哭了),想让大模型学会使用code interpreter, web search等工具来增强现有模型的数学和推理能力, 单轮就是调用一次tool,多轮就是调用多次tools, 多轮tool use更难一点,主要是数据难以获取和建模方式(MDP这种只考虑当前状态的训练模式,还是使用full history,考虑所有的状态的模式)不清晰,tool-use rl也算是一个新的研究方向了,潜力还有待挖掘。最近的工作还是集中设计这个multi turn tool-use的prompt template,以及训练的时候需要设计rule based reward(correctness reward, format reward, tool execcution rewad等), 训练的tool output的mask操作,sampling的时候加入异步并行,融入megatron的pipeline parallel,加入多模态信息等等,训练的范式基本是先收集一波expert trajectory做sft,然后使用rl训练(例如ReTool),或者直接应用RL(例如TORL,ToolRL,OTC等),目前还没有出现一个真正为agent rl设计的方法,都是复用现有的基建(比如verl, open-rlhf, trl, ms-swift),做了一些拓展。最近在tool-use的基础上还出现了一个tool integrated reasoning, 跟cot的区别就是在推理的过程中会使用工具,这样推理过程动态的添加了search,code,各种定制化的API的输入,推理能力得到了进一步的增强。
工程调优
使用langchain中自带的react框架进行text2api的构造,发现几个问题:
- langchain完全依赖底座模型,在chatgpt4上表现很好。但在一些中文模型上无法很好识别api的输入参数,经常出现幻觉导致乱编参数的现象。
- langchain调用链路很长,导致我们在改写较复杂问题text2api的时候会有大量的工作。并且react框架因为没有penalty机制,如果出现调用错误的情况,只能人工检查然后通过增强prompt的方式进行修正。 后来我们尝试引进了Reflexion框架,相较于传统的Reactor,Reflexion提供了自我反思机制,然后在memory模块中保存之前的短期记忆和长期记忆,从而在之后的决策中,基于储存的记忆诱导大模型生成更好的答案。
Agent模型
对研究人员和一般开发者的一个问题是,目前的开源推理模型的工具使用能力、特别是多轮工具使用能力普遍较弱。PS:后续就是,推理+多模态,推理+functioncall(plan 相对内置)等等,从工程上可能喜欢plan单独输出,进而可以人工矫正(进而持续训练),保证输出质量。
Agent 模型是在推理模型基础上通过端到端的面向任务的工具增强训练得到的。它能够自动生成耦合的CoT思维链和CoA行动链序列。其中每个动作调用工具与外部环境交互,交互得到的反馈指导后续的推理和动作,直至任务完成。Agent 模型增强了使用工具的能力,这要求模型不局限于自身内部的推理行为,而能与外部环境进行交互。Chatbot和Reasoner仅关注人与模型之间的二元交互。而Agent 模型要求能够同时进行思考与行动,形成了由人、模型和环境构成的三元结构:使用工具与环境进行交互以获得反馈,经过多轮的思考、行动和observation后,最终生成回复。PS:其实也说明,调用工具场景能用functioncall 模型就用functioncall模型,常规llm也不是不行,但不专业。
这里有个问题:如果模型在预训练阶段已经具备了工具使用能力,并继承到了推理模型中,还需要进行专门的CoA学习么?即CoT+A是否可以自然地获得CoA的能力?当预训练基座模型的工具使用能力和推理模型的推理能力较强时,这是有可能的。讨论更一般的情况:预训练阶段的工具使用更多的关注的还是单步行动能力,适合处理孤立的任务,有点像对特定技能的学习;而CoA学习面向任务执行端到端训练,学会执行一连串相互依赖的动作,形成逻辑性强、目标导向的行动序列,更像是对技能的综合应用。以OpenAI的Deep Research为例:其核心能力是通过网络搜索完成复杂研究任务,就需要解决上面两个问题:
- 知识边界的判断:模型需要自主判断“什么时候该查资料”——既不能过度依赖搜索,也不能盲目自信;需要清楚自己的短板,并在合适的时候采取行动
- 动态环境的适配:调用搜索引擎要花时间和资源,成本高、效率低,而且网络环境一直在变,如何在有外部环境交互的情况下进行高效RL训练?
真正的LLM AgentAlexander:未来智能体会自主掌控任务执行的全过程,包括动态规划搜索策略、主动调整工具使用等,而不再依靠外部提示/prompt或工作流驱动( 真正的智能体,是不靠「提示词」工作的)。这种转变意味着智能体设计的核心复杂性将转移到模型训练阶段,从根本上提升模型的自主推理能力,最终彻底颠覆目前的应用层生态。AI 模型本身,就是未来的产品。为什么这么说?
- 通用型模型的扩展,遇到了瓶颈。GPT-4.5 发布时传递的最大信息就是:模型的能力提升只能呈线性增长,但所需算力却在指数式地飙升。尽管过去两年 OpenAI 在训练和基础设施方面进行了大量优化,但仍然无法以可接受的成本推出这种超级巨型模型。
- 定向训练(Opinionated training)的效果,远超预期。强化学习与推理能力的结合,正在让模型迅速掌握具体任务。这种能力,既不同于传统的机器学习,也不是基础大模型,而是某种神奇的第三形态。比如一些极小规模的模型突然在数学能力上变得惊人强大;编程模型不再只是简单地产生代码,甚至能够自主管理整个代码库;又比如 Claude 在几乎没有专门训练、仅靠非常贫乏的信息环境下,竟然也能玩宝可梦。
- 推理(Inference)的成本,正在极速下降。DeepSeek 最新的优化成果显示,目前全球所有可用的 GPU 资源,甚至足以支撑地球上每个人每天调用一万个顶尖模型的 token。而实际上,目前市场根本不存在这么大的需求。简单卖 token 赚钱的模式已经不再成立,模型提供商必须向价值链更高层发展。 未来 2-3 年内,所有闭源 AI 大模型提供商都会停止向外界提供 API 服务,而将转为直接提供模型本身作为产品。简单来说,API 经济即将走向终结。模型提供商与应用层(Wrapper)之间原本的蜜月期,已彻底结束了。未来很多最赚钱的 AI 应用场景(如大量仍被规则系统主导的传统产业)尚未得到充分开发。谁能训练出真正针对这些领域的专用模型,谁就能获得显著优势。
大佬
- AI agent的意思是说,人类不提供明确的行为或步骤的指示,人类只给AI目标,至于怎么达成目标,AI要自己想办法。通常你期待AI agent要达成的目标需要通过多个步骤,跟环境做很复杂的互动才能够完成。而环境会有一些不可预测的地方,所以AI agent还要能够做到灵活地根据现在的状况来调整计划。
- 来看语言模型,怎么套用到agent的框架下。从llm的角度来看,首先ta得到一个目标,然后接下来得到一个observation,然后根据这个observation,决定接下来要采取什么样的action。当它采取完动作之后,他的动作会影响外界的环境,看到新的observation。看到新的observation以后,要采取新的动作,这个过程就会再反复继续下去。在那一系列的过程中,看到observation采取action,看到observation采取action,其实凭借的都是语言模型原来就有的文字接龙能力。所以从语言模型的角度来看,AI agent并不是一个语言模型的新技术,它比较像是一个语言模型的应用。那用LLM来运行一个AI agent,相较于其他的方法,可能有样什么样的优势呢?
- llm可以讲任何话,可以产生各式各样近乎无穷无尽的输出,这就让AI agent可以采取的行动不再有局限,有更多的可能性。
- observation可能是电脑的屏幕画面。AI agent要决定的就是要按键盘上哪一个键,或者是要用鼠标按哪一个按钮。
- 分三个方面来剖析今天这些AI agent的关键能力。
-
AI agent能不能够根据它的经验,通过过去的互动中所获得的经验来调整他的行为。问题是,如果我们把过去所有的经验都存起来,要改变语言模型的行为,要让它根据过去的经验调整行为,就是把过去所有发生的事情一股脑给它,也许在第100步的时候还行,到第1万步的时候,过去的经验太长了,也许没有足够的算力来回顾一生的信息,就没有办法得到正确的答案。所以怎么办呢?也许我们可以给这些AI agent memory,这就像是人类的长期记忆一样,把发生过的事情存到这个memory里面。当AI agent看到第一万个observation的时候,他不是根据所有存在memory里面的内容去决定接下来要采取什么action,而是有一个叫做read的模块,这个read的模块会从memory里面选择跟现在要解决的问题有关系的经验,把这些有关系的经验放在observation的前面,让模型根据这些有关系的经验跟observation再做文字接龙,接出他应该进行的行动。 有关记忆的部分,是不是要把所有的信息存到memory里面呢?存到长期的记忆库里面呢?如果我们把这些agent经历的所有的事情都放到长期的记忆库里面的话,那里面可能会充斥了一堆鸡毛蒜皮不重要的小事,最终你的memory长期记忆库也可能被塞爆。所以怎么办呢?应该只要记重要的信息就好。怎么让语言模型只记重要的信息就好呢?你可以有一个write的module,那怎么打造这个write的记忆库呢?有一个很简单的办法就是write的模块也是一个语言模型,甚至就是AI agent自己。除了Read跟Write这两个模块以外,还有第三个模块,我们可以暂时叫reflection反思的模块。这个模块的工作是对记忆中的信息做更好的,更high level的,可能是抽象的重新整理。你可以把这些记忆里面的内容,在经过reflection的模块重新反思之后,得到新的想法。那也许read的模块可以根据这些新的想法来进行搜索,这样也许可以得到更好的经验,那帮助模型做出更好的决策。除了产生新的想法之外,也可以为以前观察到的经验建立经验与经验之间的关系,也就是建立一个knowledge graph,然后让read的module根据这个knowledge graph来找相关的信息。
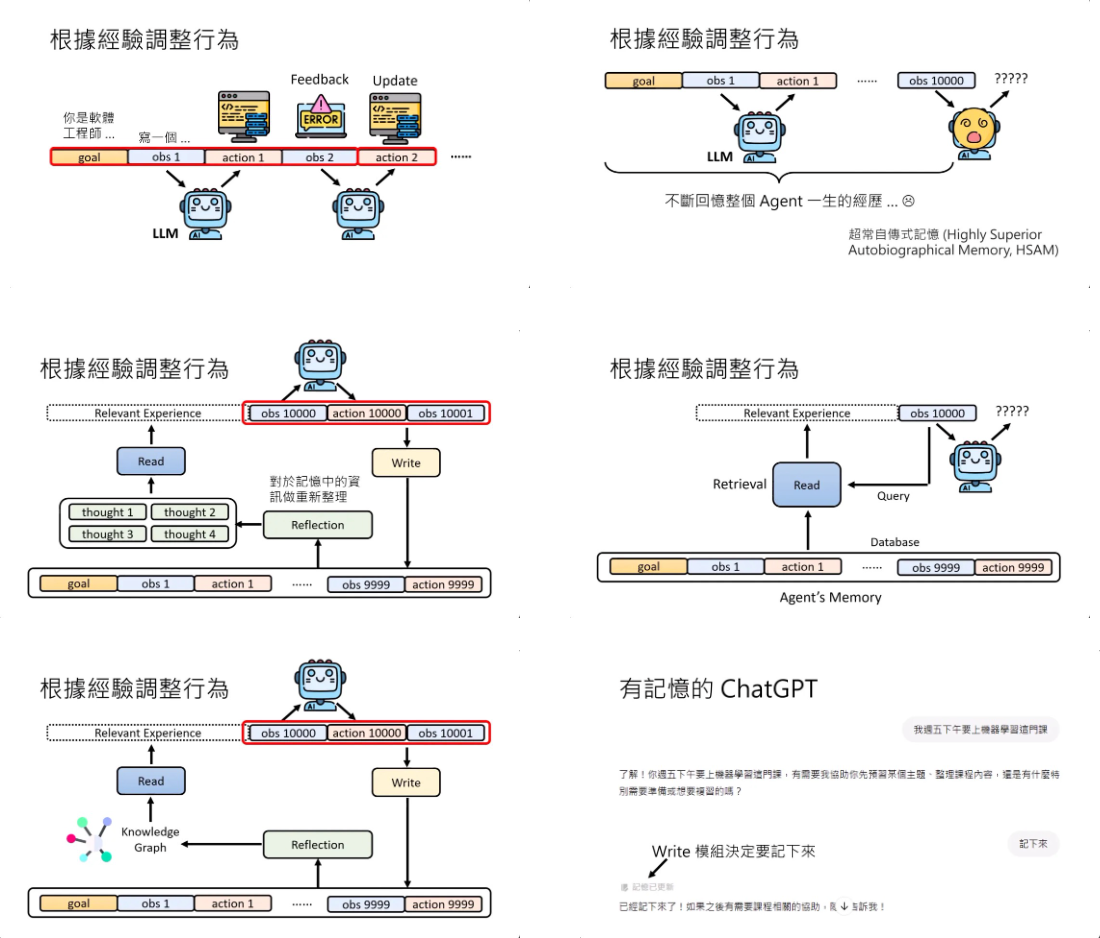
- AI agent如何呼叫外部的援助,如何使用工具。
- 所谓的工具就是这个东西,你只要知道怎么使用他就好,他内部在想什么,他内部怎么运作的,你完全不用管。其实这些工具对语言模型来说都是function,都是一个函数。它不需要知道这些函数内部是怎么运作的,它只需要知道这些函数怎么给它输入,这些函数会给什么样的输出。因为使用工具就是调用函数,所以使用工具又叫做function call。
- 使用工具也有其他的挑战,假设工具很多怎么办呢?假设现在可以用的工具有上百个上千个,那你岂不是要先让语言模型读完上百个上千个工具的使用说明书才开始做事吗?你可以采取一个跟我们刚才前一段讲AI agent memory非常类似的做法,你就把工具的说明通通存到AI agent的memory里面,打造一个工具选择的模块。另外一方面,语言模型甚至可以自己打造工具,,语言模型怎么自己打造工具呢?不要忘了所有的工具其实就是函数,语言模型今天是可以自己写程序的,所以他就自己写一个程序,自己写一个function出来就可以当作工具来使用。放到他的工具包里面,那之后这个工具就有可能在选择工具的时候被选出来,用在接下来的互动中使用。跟模型把过去的记忆,比如说一些比较成功的记忆放到memory里面再提取出来,其实是差不多的意思。
- 工具输出有错,语言模型今天是有自己一定程度的判断力的,它也不是完全相信工具,就是语言模型有它内部对世界的信念,这是它的internal knowledge,存在它的参数里面。它从工具会得到一个外部的knowledge,那它会得到什么样的答案,其实就是internal knowledge跟external knowledge,内外的知识互相拉扯以后得到的结果。那什么样的外部知识比较容易说服AI,让他相信你说的话呢?外部的知识如果跟模型本身的信念差距越大,模型就越不容易相信。如果跟本身的信念差距比较小,模型就比较容易相信。模型本身对它目前自己信念的信心,也会影响它会不会被外部的信息所动摇。有一些方法可以计算模型现在给出答案的信心,如果他的信心低,他就容易被动摇。如果他的信心高,他就比较不会被动摇。
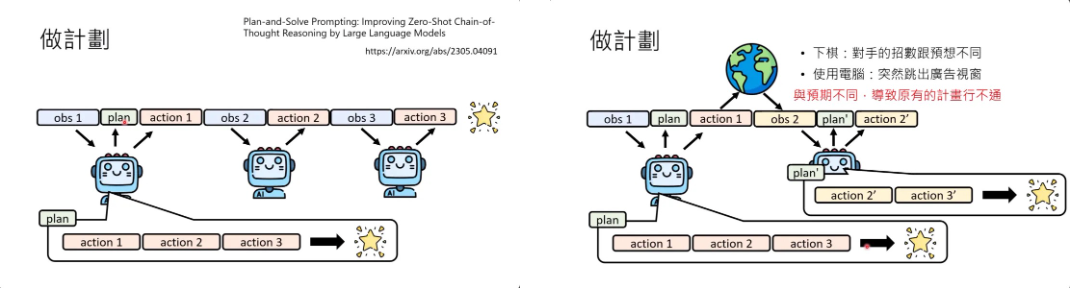
- 讲AI agent能不能够执行计划,能不能做计划。
- 语言模型有没有在做计划呢?也许在给输出的过程中,它有进行计划才给出输出,但是我们不一定能够明确地知道这件事。也许语言模型现在给的输出只是一个反射性的输出,它看到输入就产生一个输出,它根本没有对未来的规划。普遍认为介于有跟没有之间吧,就是你也不能说它完全没有,但你也不能说它真的非常强。但是你可以强迫语言模型直接明确地产生规划。当语言模型看到现在的第一个observation的时候,你可以直接问语言模型说,如果现在要达成我们的目标,从这个observation开始,你觉得应该做哪些行动,这些一系列可以让语言模型达到目标的行为合起来,就叫做计划。而在语言模型产生这个计划之后,把这个计划放到语言模型的observation里面,当作语言模型输入的一部分,语言模型接下来在产生action的时候,它都是根据这个plan来产生action,期待说这个plan定好之后,语言模型按照这个规划一路执行下去,最终就可以达成目标。
- 但是天有不测风云,世界上的事就是每一件事都会改变,计划就是要拿来被改变的。所以一个在看到observation 1的时候产生的计划,在下一个时刻不一定仍然是适用的。为什么计划会不适用呢?因为从action到observation这一段并不是由模型控制的,模型执行的动作接下来会看到什么样的状态,是由外部环境所决定的,而外部环境很多时候会有随机性,导致看到的observation跟预期的不一样,导致原有的计划没有办法执行。
- 语言模型怎么改变他的计划呢?也许一个可行的方向是每次看到新的observation之后,都让语言模型重新想想还要不要修改他的计划。看到observation 2之后,语言模型重新思考一下,从observation 2要到达他最终的目标,要做哪一些的行为,那这部分的计划形成plan pi。把plan pi放到现在的input里面,把plan pi放到这个sequence里面,语言模型接下来在采取行为的时候,可能会根据plan pi来采取跟原来plan里面所制定的不同的行为。
-