2019年终小结
简介
人
改变别人是神经病
谈工程师成长的另一面,从老书新版开始Kelly从此获得了非常宝贵的经验:要学会带领(lead),而不是驱赶(drive)。必要的时候驱赶自己没有错,但绝对不要去驱赶其他人。在我看来,“驱赶”的做法对体力劳动或许有效,但对于脑力劳动,尤其是需要高度使用创造力的脑力劳动,“驱赶”绝对是不明智的。积极奋进的人或许很难找,但一门心思偷懒的人也不多,大多数人是需要被带动的。而且越是挑战大的项目越是不能用强,也越是需要尊重员工。普通人离开学校之后已经没有了“绝对权威”的概念,再也没有老师有权利“强迫”你接受什么学说。普遍的规律是,时间越晚,年纪越大,接受新东西的难度就越大。所谓“理性”,很多时候纯粹是惰性和惯性。这可能会让人更沉稳,更不容易被煽动,但如果缺失正确的信念,也可能一直缺失。
闲谈爱情、婚姻、家庭自己的许多追求和坚持,只适合用来约束自己,绝不是臧否其他人的利器;其他人的许多言行,即便自己看不惯,也未必需要时刻去讨伐、去纠正。如今许多人都会强调相处的“边界”,只要能把住这两点,哪怕大家差异很大,也比较愿意互相理解,边界就比较容易建立。如果把握不住这两点,即便划定了边界,也往往是徒有形式,矛盾仍然层出不穷。“严于律己,宽于待人”,其实并不是什么道德的煎熬,而是明白世界上不只有一种生活方式,一种价值观。
重设计,再一个参与所有设计(设计工作不下放)。有一个小伙伴, 我故意等了他一周让他自己试试做一下设计,但最后也是找不到关键点。以前碰到这种情况,我总是怨人不愿意主动,不愿意用功花心思。后来发现,越是设计的事情,越考验人的审美、对编程、工作的热情。很多人拿钱干活的状态, 不去研究过十个、八个的系统,干不了这种活。我总监教我最重要的一件事,说出来都不值一提,但很多人没有:要去做一点事,就去研究十个、八个的人这个事儿是怎么做的,基本上这个事儿有哪些关键、哪些坑就摸清楚了。这样最后设计出来的,基本就是一个不太差的系统。所谓管理,不是大家都很能干,你指点一下就行了。而是尽快识别出小伙伴是什么水平,给他能干的活儿,尽量人尽其用。
混沌研习社李云龙 四级人才思维模型
- 四等人才赋予动作,这类人才,就是教一步会一步,但每一步都能完成好。如果连这一步都做不到,那真的不能称之为“人才”了。身处此层,是不可能获得提拔的,哪怕你自己感觉累的要死。
- 三等人才赋予方法,不需要领导告知每一个细节。只需要被教授一次方法,对于类似的问题都可以很好的解决掉。但是对于非同类问题又找不到方法了。
- 二等人才赋予原则,能够对不同领域问题的解决方法进行迁移,只需要被告知什么能做什么不能做,基本就可以很好的完成工作。
- 一等人才赋予角色。如果不是去创业,差不多能做到这一层就是最厉害的了。只要被赋予一个角色,便自然知道在在这个角色之下该怎么做,而且会主动驱动事情往前走。
优秀的人应该像海绵,在不停的吸收,吸收做成某个事情必要的信息,身边人的技能经验,一本书,一个框架源码,一个事儿的前因后果,给人一种这个人(可能当下绝对实力还不够)不能小看的感觉。
沟通
沟通的本质:换位思考,没有人喜欢被说服,被改变。
阿里产品专家:高情商的技术人,如何做沟通?沟通是“有目的的多向信息交流
- 沟通是有目的的:你的初衷是什么?你现在的行为和言语有没有妨碍你完成你的初衷?
- 沟通是多向信息交流:你有让对方get到你的真实想法么?你get到对方的真实想法了么?
“周哈里窗”根据信息是否被“我”知道,以及是否被“对方”知道,分成四个区域:
- 公众区:我知道且对方也知道的信息
- 隐私区:我知道的但对方不知道的信息
- 盲点区:我不知道但对方知道的信息
- 黑洞区:我跟对方都不知道的信息
周哈里窗模型认为沟通的关键是要“拓展公众区的信息”
不要一个人闷着,找高人请教, 安排一个小伙伴去做(一些新东西可以安排给小伙伴学习),只要可以形成讨论,就可以有意想不到的收获。
别人的任何动作,都先想想他想干啥。第一考虑情绪,第二才考虑内容
团队建设:程序员的品格:羞耻心、同理心与榜样的力量现在的互联网应用相对企业应用,可以更快更轻更容错,给年轻人一种错觉好像出点错没什么大不了的,也导致现在的年轻程序员对于BUG, 对于生产环境没有太多的敬畏心。
事儿
通过任务、流程来影响团队、个人、士气,用排期来安排、挡需求
一个项目换一个人就要让项目大地震一下、解决 bug 换一个人就不行因为只有老人知道要改哪一行的哪个关键字”,这不说明这个项目所涉及的技术有多复杂、不说明这个老人是什么技术大牛,而只说明这个项目的项目经理是蠢货,因为这个项目已经失控了。
有时候任务粒度要足够精细, 切记安排模糊的任务。研究性的任务要求较高,要找到合适的人。
真正去做一个带有数据反馈的闭环系统
如果你觉得学一个东西很吃力,那是因为你觉得每个东西都是新东西。如果你觉得学东西和推进工作不是一个事儿,那说明你一直在执行的层面。
《反脆弱》中有个观点:只有脆弱的人才会每时每刻努力证明自己是正确的,反脆弱的人则会时常思考自己还有哪些地方做错了,哪些地方可以改进。
长期利益往往意味着短期利益的下降,因为你在花更多的时间,做一个看似没有成果的事情。19世纪德国普鲁士军事理论家卡尔·冯·克劳塞维茨在《战争论》里讲到将领的作用时说,在茫茫的黑暗中,要能发出内在的微光。PS:很多时候,你是最后坚持的那个人,你再不坚持,这事儿就凉了
文档体现了一个人的思路,文档不是事无巨细的流水账,写文档以及组织文档是需要智商的、是需要架构师去设计的。
真正的高手,都有对抗熵增的底层思维。说白了就是控制复杂性,代码做的事情多了,要通过代码和架构设计控制复杂性,人员多了,要通过分级管理控制复杂性。
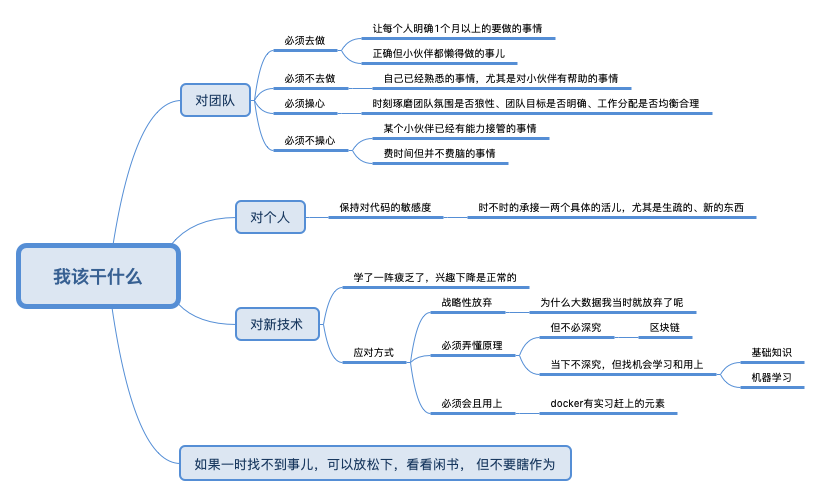
当你是组长时,你要放弃学一些东西,尤其是细枝末节的,必须去学原理那些一通百通的东西
有的人看见草原就知道有肉吃,有的人看见羊才知道有肉吃,有的人非得你杀好了羊烤成了羊肉串才知道有肉吃。
先想理想状态,一切以理想状态推进设计。
你得对你的环境先知先觉,你碰到的问题大部分时候都不是你独有的,一定可以抽象出一个问题,汇总几个解决方法, 然后去试错提炼,找到适合自己的最佳实践。
做工作
15 年工龄的资深技术专家职场历程自述一定要用 20% 的时间快速掌握 80% 的知识点,然后就可以开展工作,后续的 20% 知识点,可能会占用 80% 的时间掌握,可以拆散打乱到平时工作中继续学习,或者请教专业人士慢慢补足,没有必要为了追求完美持续学习,而是要转身开始开展工作或者开始其他方向的学习。
学习的最终目的不是获得现成的知识,更重要的是锻炼出“从已知到未知”,不断主动扩展知识领地的能力。要锻炼出这种能力,就必须在“获得知识”的过程中,不断审视自己已有的知识,不断培养自己的学习习惯,优化自己的学习方式。比如常常问自己“这是真的吗?”,反思“我之前错在哪里了”,自问“我还需要学习什么”,以及坦然面对与已有认知冲突甚至让自己“丢面子”的信息,从而获得更立体全面的认知…… ==> 糖衣炮弹来了怎么办?好办!糖衣吃掉,炮弹打回去。
15 年工龄的资深技术专家职场历程自述工程师的工作是千头万绪,有很多很多问题需要解决,那该怎么找到其中的关键点呢?我觉得吧,一定要时不时的停下手头的工作,环顾下自己的工作,看看里面哪些问题是只要自己个人投入足够时间就可以解决的,哪些问题是需要多方协调,需要其他资源投入才可以解决的,特别是对于第二种情况,一定要有危机感,一定要有警惕性和前瞻性,因为这种问题,可能就是我说的关键点,需要提高优先级来解决。,我们每天有很多重要而紧急的事情,我的时间管理该怎么做?其实,如果你有很好的危机感,或者前瞻性,及时规划重要而不紧急的事情,那么你接下来就不太容易碰到重要而紧急的事情。比如阿里有年度考评,需要做很多 PPT 和自评,这些事情平时做肯定是重要而不紧急,平时多收集汇报的素材,并记录下来,那么等到年度考评的事情,可以快速和轻松的做好。如果平时不收集素材,到了年度考评的时候,你就要花很多时间回忆自己一年都有哪些亮点,该怎么总结自己的一年工作,这样就把一个重要而不紧急的事情变成一个重要而紧急的事情。一个优秀工程师,有一个很重要的标准,那就是他不太有重要而紧急的事情,每天大部分时间,他都在处理重要而不紧急的事情,这样他的工作和学习都是非常的闲庭信步。打个比方,类似下棋走一步看三步,这个刚开始很难,只要你对项目的方方面面多思考,对技术保持前瞻性思考,你就慢慢会有这种能力。
技术人员如果要上升到技术管理,演讲力也是一个重要的考察指标,有很好演讲力,很好表达力的工程师,说明这个人,既有技术功底,又有宏观抽象能力,并可以从非技术角度思考问题,绝对是技术管理人员的好人选。
世界上没有技术驱动型公司?一个程序员,应该花 80% 的时间做代码设计、画 UML 图、画时序图,20% 的时间写 code 和 debug;菜鸟程序员的这个比例恰好是反的。一句话,不论这个需求有多紧急,你都一定要“想好再动手”;“想好”的标志就是设计文档写好了;文档一旦写好,写代码就是纯粹的无脑工作。 写文档的目的是让你在 coding 的时候,不需要停下来思考更不需要推倒重来。如果没有文档也可以做到这一点,你当然可以不写文档同时思考下自己水平这么高是不是可以要求升职加薪了……或者,你是不是在做无聊的 if else 编码工作?
我们不是在做系统,我们是在解决问题,系统存在了半年一年,问题依然没有解决,系统就毫无价值。我们在做任何一件事之前,重要的就是定义评价标尺,标尺的基本要素就是问题有没有解决。“为什么”“有什么价值”是真正的“核心思考区间”,而如何把how做到极致 只是“边缘思考区间”。对“为什么”没有认识和决心,执行“how”的时候就会犹疑不定。不管是任何工作,最根本、最核心的能力,一定是“识别问题”的能力,看清楚在当下的任务中,到底哪些事情才是它的“核心思考区间”,才是我们目前所遇到的“关键挑战”,将它解决,后续的边缘问题自然就会解决。
解决问题,close 问题,问题不解决,事情就没有结束。 一切问题 都可以变着法儿用技术问题去解决。测试环境配置瞎填,那就嗅探出来,做出报警。
为什么你的高效交付,却没有好的业务成果?当堆了那么多功能之后,突然发现竞品刚刚推出了一个很火的活动,不是自家刚做过的吗?我们没火但为什么竞品火了?是自家公司的人不行吗?是自家的用户不行吗?其实不是!这里有两个原因,一是在被误解的“小步快跑”交付思想下,许多业务的价值点没有挖透。二是职能团队之间没有形成联动,只做了功能的交付和自运营。试想,一个功能的交付如何打得过一个由产品、运营、PR、市场、渠道等多职能海陆空协同的业务交付呢?价值挖掘不到位,就好比下图的挖井,明知道下面有水源,但不管换多少个地方挖但总挖不出水来。
未来技术
未来,仅凭几个前端工程师,就能 hold 住一家企业吗?微前端架构旨在解决单体应用在一个相对长的时间跨度下,由于参与的人员、团队的增加,从一个普通应用演变成一个巨石应用(Frontend Monolith),随之而来的应用不可维护问题。
阿里云提供的很多商业化产品和服务,本质上是对外提供「能力」,普惠中小企业。目前,能力输出主要是通过 OpenAPI,用以集成到企业自己的业务场景中,这里主要解决的还是企业底层的能力问题——无需雇佣算法工程师,就可以拥有语音、图像识别等能力。但是,随着云技术不断的下沉,与产业结合的越来越紧密,OpenAPI 唯有把粒度做得越来越细,才能满足各种各样的业务场景,但同时企业侧的学习成本和开发复杂度自然就上去了。如果你问我 Ant Design 有什么技术价值?它的价值就是有大量的企业在用,形成某种能力依赖,不需要找设计师或者多么资深的前端工程师,就可以做出看上去很专业的后台界面。在这条价值链路上,OpenAPI 太底层,控制台不灵活,UI 库太通用。其中的空白点是绑定能力的商业化组件。举个例子,企业的后台管理页上,可以直接 inside 一个「漏洞管理」的微前端应用,和一个 DataV 的微前端应用展示数据,只需要简单配一下即可,不用开发,就能做到“就像自己开发的一样”。反过来也一样,ISV 在阿里云的产品平台上,不仅可以通过小程序的形式,也可以通过微前端应用的形式输入自己的服务。简单地说,搞微前端目的就是要将产品原子化(跟原子化的 OpenAPI 一个道理),再根据客户业务场景组合。每个功能模块能单独迭代,自由集成。云时代的开发模式注定是「碎片化」的,开发是面向模块的,而页面只是一种组合场景,一种运行时容器。我想,未来的产品开发主要时间是在「编排」——编排服务、编排逻辑、编排组件、编排访问策略、编排流程。
留下评论