深度学习泛谈
前言
吴恩达:假如有一件事是一个正常人可以在1s以下做到的,我们就可以使用人工智能自动做。 假如你可以拿到一个具体重复发生的事情的海量数据, 你就可以用这些数据来预测下一次的结果。
陆奇最新演讲:没有学习能力,看再多世界也没用 绝对高屋建瓴,推荐多看几遍。
火了这么久的 AI,现在怎么样了?机器学习的目标是利用有限的样本对未知的目标函数求近似。任何机器学习模型都有三个 component 组成,首先确定要学习的函数空间、然后确定使用的数据,用哪些训练数据拟合机器学习模型,最后是找到优化算法,让机器从函数空间中学习到最好的模型,即最佳匹配数据的模型。机器学习是考虑所有可能的函数,而深度学习只考虑一个特殊类的函数,神经网络。机器学习的本质,就是在拟合一个从输入X到输出Y的函数F(X)。
规律一直都在,但如何找到规律:算法 vs 数据相关性
吴军《见识》:在达尔文研究进化论的同时,奥地利的教士孟德尔从另一个角度开始研究生命的奥秘和物种之间的关联,并且最终发现了遗传的规律性。在他之后,美国科学家摩尔根确认了细胞内的染色体承载着物种的遗传物质,奠定了现代遗传学。在二战后,英美科学家一起确定了遗传物质DNA的双螺旋分子结构,从此破解了生命的奥秘,也了解到基因突变对物种变异和进化的影响。这些现代生物学和遗传学的结果,都支持了生物具有共同祖先的说法。不仅生物的遗传物质都是DNA,而且构成生命所需的蛋白质也保持了一致性,例如核糖体、DNA聚合酶和RNA聚合酶,不但出现在较原始的细菌里,也出现在复杂的动物体内。这些蛋白质的核心部分在不同生物中具有相似的构造和功能。PS:生物学和遗传学上的“一生二、二生三、三成无穷”。万事万物,都有一个共同的本源
《智能商业》如果我们将数据看做数据时代的一桶高标号汽油,那算法无疑就是这台引擎。机器学习是算法一次决定性的跃升,也正是在这次跃升中,数据对算法的巨大被充分显现出来。任何一个算法模型,尤其是能够自我学习、自我优化的算法模型,都承担着在成千上万可能的因素中寻找出所隐藏的联系的艰巨任务。工业革命使得体力劳动自动化,信息革命使得脑力劳动自动化,而机器学习使得自动化过程本身自动化。
为什么要深度学习?从计算机编程的角度讲,解决问题的手段一般有两种
- 将”规则”代码化
- 穷举,利用”规则”干掉不符合条件的
问题是,对于有些东西,无法用规则来描述,或者即便能够描述,对计算能力的要求也过高。这迫使人们使用新的方法来解决问题,即学习人脑的思维方式。
《动手学深度学习》用数据编程:与其坐在房间思考怎么设计一个识别猫的程序,不如用人类肉眼在图像中识别猫的能力,收集一些真实图像,从中推断出一个图像中是否有猫的函数。函数的形式针对特定的问题选定,比如使用一个二次函数来判断图像中是否有猫,但二次函数系数值则通过数据来确定。通俗来说,机器学习是一门讨论各式各样的适用于不同问题的函数形式,以及如何使用数据来有效的获取函数参数具体值的学科。深度学习是指机器学习中的一类函数,它们的形式通常为多层神经网络。 深度学习可以看做由许多简单函数复合而成的函数,当复合的函数足够多时,深度学习模型就可以表达非常复杂的变换。
当你需要用到一个概念的特征v),或者一个函数f,但是却不知道如何定义它们,没关系
- 先将v声明为特征向量,将f声明为一个小的神经网络,并随机初始化
- 然后让v和f,随着主目标(最终的分类或回归loss),一同被SGD所优化。
- 当主目标被成功优化之后,我们也就获得了有意义的v和f。 这种“无中生有”的套路,好似“上帝说,要有光,于是便有了光”的神迹。
神经网络
一个人在出生之前,脑中的1000亿个神经元已经几乎全部准备好,而神经元之间的连接网络则是十分稀疏的。因为婴儿未能意识思考,故此,他只会凭外界的刺激而制造连接网络。
任何声音、景物、身体活动,只要是新的(第一次),都会使得脑里某些神经元的树突和轴突生长,与其他神经元连接,构成新的网络。同样的刺激第二次出现时,会使第一次建立的网络再次活跃。就是说,新网络只能在有新刺激的情况下产生。一个人的一生之中,不断有新的网络产生出来,同时有旧的网络萎缩、消失。
一个旧的网络,对同样的刺激会特别敏感,每次都会比前一次启动得更快、更有力。多次之后,这个网络便会深刻到成为习惯或本能了。这便是学习和记忆的成因。
神经网络和MLP的关系:神经网络不仅仅是指MLP。CNN、RNN、Transformer也都是神经网络。整个深度学习都是在研究神经网络。这些神经网络也都是为了优化一个目标函数,也都是以梯度下降为基础的。可以说整个深度学习的繁荣,是建立在自动的微分系统上的。MLP虽然号称理论上可以做Universal Approximator,可以拟合一切,但是是以无限大的隐藏层为前提的。实际应用中,有限的计算资源下,MLP解决各种任务的表现并不好。图像分类上CNN完胜它,自然语言上Transformer最牛逼。
- 一个隐层的mlp就已经是universal approximator,但这个隐层内单元数得非常非常多才行。
- 问题结构和网络结构要有契合关系,如果两者不匹配,费劲不讨好。就如同只吃水果蔬菜治不了饿,只用mlp也搞不定nlp中需要建模的各种依存关系。
- 其实mlp普遍存在,transformer里有,cnn本身就是个指定输入输出窗口位置的mlp,只是大家设计了更外层的结构,让mlp用得更高效了。
发展历史
神经网络技术起源于上世纪五、六十年代,当时叫感知机(perceptron),拥有输入层、输出层和一个隐含层。输入的特征向量通过隐含层变换达到输出层,在输出层得到分类结果。但是,单层感知机有一个严重得不能再严重的问题,即它对稍复杂一些的函数都无能为力(比如最为典型的“异或”操作)。随着数学的发展,一票大牛发明多层感知机,摆脱早期离散传输函数的束缚,使用sigmoid或tanh等连续函数模拟神经元对激励的响应,在训练算法上则使用反向传播BP算法。对,这货就是我们现在所说的神经网络NN。多层感知机给我们带来的启示是,神经网络的层数直接决定了它对现实的刻画能力——利用每层更少的神经元拟合更加复杂的函数。但随着神经网络层数的加深带来了很多问题,参数数量膨胀,优化函数越来越容易陷入局部最优解,“梯度消失”现象更加严重。当然有一些通用方法可以解决部分问题, 但在具体的问题领域 人们利用问题域的特点提出了 一些变形来解决 层数加深带来的问题。PS:充分利用问题域的特点 是设计算法的基本思路。
Artificial neural networks use networks of activation units (hidden units) to map inputs to outputs. The concept of deep learning applied to this model allows the model to have multiple layers of hidden units where we feed output from the previous layers. However, dense connections between the layers is not efficient, so people developed models that perform better for specific tasks.
The whole “convolution” in convolutional neural networks is essentially based on the fact that we’re lazy and want to exploit spatial relationships in images. This is a huge deal because we can then group small patches of pixels and effectively “downsample” the image while training multiple instances of small detectors with those patches. Then a CNN just moves those filters around the entire image in a convolution. The outputs are then collected in a pooling layer. The pooling layer is again a down-sampling of the previous feature map. If we have activity on an output for filter a, we don’t necessarily care if the activity is for (x, y) or (x+1, y), (x, y+1) or (x+1, y+1), so long as we have activity. So we often just take the highest value of activity on a small grid in the feature map called max pooling.
If you think about it from an abstract perspective, the convolution part of a CNN is effectively doing a reasonable way of dimensionality reduction. After a while you can flatten the image and process it through layers in a dense network. Remember to use dropout layers! (because our guys wrote that paper :P)
Let’s talk RNN. Recurrent networks are basically neural networks that evolve through time. Rather than exploiting spatial locality, they exploit sequential, or temporal locality. Each iteration in an RNN takes an input and it’s previous hidden state, and produces some new hidden state. The weights are shared in each level, but we can unroll an RNN through time and get your everyday neural net. Theoretically RNN has the capacity to store information from as long ago as possible, but historically people always had problems with the gradients vanishing as we go back further in time, meaning that the model can’t be differentiated numerically and thus cannot be trained with backprop. This was later solved in the proposal of the LSTM architecture and subsequent work, and now we train RNNs with BPTT (backpropagation through time). Here’s a link that explains LSTMs really well: http://colah.github.io/posts/2015-08-Understanding-LSTMs/Since then RNN has been applied in many areas of AI, and many are now designing RNN with the ability to extract specific information (read: features) from its training examples with attention-based models.
深度学习的收益正在逐步递减深度学习是人工智能长期趋势的现代化身,这一趋势已从以专家知识为基础的流水化系统转向灵活的统计模型。早期的人工智能系统是基于规则的,应用逻辑和专家知识来推导结果。后来的系统结合了学习,以设定其可调参数,但这些参数通常数量很少。今天的神经网络也学习参数值,但是这些参数是非常灵活的计算机模型的一部分,如果它们足够大,就能近似成通用函数,这意味着它们可以适用于任何类型的数据。这种无限的灵活性正是深度学习能够应用到如此多不同领域的原因。神经网络的灵活性来自于对模型的大量输入,并允许网络以无数种方式将其组合。这就是说,输出将不是应用简单公式的结果,而是极其复杂的公式。举例来说,当尖端的图像识别系统 Noisy Student 将图像的像素值转换为该图像中物体的概率时,使用了一个具有 4.8 亿个参数的网络。确定如此多的参数值训练甚至更了不起,因为它只用了 120 万张标记的图像,深度学习模型过度参数化,即其参数多于可用于训练的数据点。这常常导致过拟合,即模型不仅能学习总体趋势,还能学习其训练的数据的随机变化。深度学习通过随机初始化参数,然后迭代调整参数集,这样就可以使用一种称为随机梯度下降的方法更好地对数据进行拟合,从而避免这种陷阱。出人意料的是,这一程序已经被证明可以保证所学模型具有很好的通用性。
李彦宏——大模型即将改变世界:过去的人工智能是,我想让机器学会什么技能,就教它什么技能。教过的有可能会,没教过的就不会。大模型出现“智能涌现”之后,以前没教过的技能,它也会了。与此同时,人工智能发展方向从辨别式走向生成式。什么叫辨别式?搜索引擎就是典型的辨别式。什么叫生成式?用AI进行文学创作,写报告、绘制海报等等,这些都是生成式。那么大模型怎么重新定义人工智能?
- 大模型重新定义了人机交互。过去几十年,人机交互方式发生了三次变化:命令行 ==> 图形用户界面(GUI) ==> 用自然语言跟电脑进行交互。自然语言人机交互会带来提示词革命。
- 大模型会重新定义营销和客服。有了大模型,即使你有70亿个客户,每一个客户也都可以有一个专属的7×24小时的、什么都知道的助理去服务他。
- 大模型会催生AI原生应用。比如,DoNotPay,是一个用AI帮人打官司、写法律文书的应用,AI帮你把不该付的钱要回来。Jasper是一个通过Al帮助企业和个人写营销推广文案的应用。Speak是韩国一个学外语的应用。大模型成为一对一的教师,为每一个孩子提供个性化教育。未来,所有的应用都将基于大模型来开发,每一个行业都应该有属于自己的大模型,大模型会深度融合到实体经济当中去。云计算的游戏规则彻底被改变,客户选择云厂商,主要会看你的模型好不好,框架好不好,而不是算力、存储这些传统能力。
- 大模型改变人工智能的背后,IT技术栈也发生了非常根本的变化。过去,无论是PC还是移动时代, IT技术栈都是三层,芯片层、操作系统层、应用层。人工智能时代,IT技术栈变成了四层:底层仍然是芯片层,但主流芯片从CPU变成了GPU。芯片上面叫做框架层,就是深度学习框架。框架上面是模型层,最上面才是应用层,就是我们前面提到的这些AI原生应用。
分类
- 强化学习。强化学习与监督学习的区别,就是没有现成的标签。如果要训练网络,只能通过环境的反馈值构造出标签,即从历史经验中学习。
- 深度学习
- 监督学习
- 无监督学习
- 生成式学习:GAN、VAE。
- 对比式学习。
VAE 举个例子,给一张图片P1,将其模糊化处理P2,训练模型使其根据P2 可以生成P1,这样就可以得到一个模型可以对图片进行去模糊处理(比如去水印)。
对比式学习举一个例子,直接问一个模型图片是啥,可能对模型有点难,至少需要大量的标注数据。给一张图片P1,我们可以对图片做一些处理得到P11(正样本),再随机给另一张图片P2(负样本),此时我们控制损失函数让模型处理P1与P2的“距离”大于P1与P11的“距离”。
用监督信号训模型,模型只是尝试从input里面学习一些pattern,并且建立pattern和label的关系。对比学习是强迫模型从输入中找出一些pattern,并且要建立起pattern和pattern的关系。所以,模型通过对比学习能学习到pattern更丰富的语义信息。这个事情在一定程度上和人类的学习方式是一样的。我们每天视觉看到很多图像。虽然我们没有强迫自己记忆每一幅画面,但是我们的脑子已经不自觉地学习到了事物之间的关系。比如你在开车,你会知道斑马线是在路面上的、红灯出现的时候车流停下了、鸟会飞在天上。这些物体间的相对关系已经潜移默化地刻在了你的脑子里。在这里,你眼里看到的所有景物就是我上述提到的input,鸟、车流、蓝天、红绿灯则是你抽象出来的pattern,“鸟飞在天上”是你学习到的关于鸟和天的语义信息。综上,对比学习能学习到更多语义丰富的pattern。这些pattern的泛化能力会强于通过监督信号学习到的较为单一的pattern。所以,在大规模的测试集上,对比学习学出来的模型往往效果会更好些。
AI 在国内的发展
- 中国最近兴起了一个产业,活跃于十八线县城及农村, 比如给你几十万张图片,标记出图片中所有的垃圾桶。然后位于北京的人工智能it 公司通过机器学习 就可以识别各种垃圾桶。这其实就是模拟了人的学习过程,一开始认为蓝色的是垃圾桶,后来发现跟颜色没关系。后来认为圆的也是垃圾桶, 后来发现跟形状没关系,等见得足够多,机器就会有一个模糊的认知:能装东西的、较深的、桶形都可以是垃圾桶。
- 一个技术分享,分享人提到人工智能的当前阶段:有多少人工,就有多少智能。
如何看待张潼老师离职腾讯? - 姚冬的回答 - 知乎 中国过去三十年,IT行业应用的技术基本都是美国那边已经成熟了的技术,已经在欧美普遍使用,甚至有些已经形成盈利性产业了。AI 是我们第一次和全球同步遇到一次新技术浪潮,AI技术在欧美也没有成熟,中国的IT企业其实基本没有落后多少,我们第一次感受到了新技术发展初期带来的各种问题。比如 新技术在实践中比旧技术表现还差,新技术不可靠,新技术成本太高,找不到落地用途等等。AI技术很新,也就意味着问题很多,但是并不意味着技术没前途,只是需要些时间去发展完善。
邵浩:大家现在都在谈人工智能技术,而且很多人都会把人工智能和 AlphaGo 以及深度学习划上等号。其实人工智能涵盖的学科范围是非常广泛的,包括心理学、神经科学、哲学、认知科学等等。我们目前看到的大量成果都只是深度学习和大数据的化学反应。而且,大量的人工智能应用还都是人工 + 智能,离真正的认知智能差距甚远。如何利用技术赋能产品,得到用户和资本的认可,才是最重要的
影响
工业生产的发展从人力,到蒸汽机,再到电能和计算机。人们想要解放繁重的重复劳动的需求从来没有改变。而只有深度学习才能满足下一波劳动力的解放,也就是重复的脑力劳动。这些影响力都是别的技术时髦远远不能相比的(比如今年流行这个前端框架,明年流行那个前端框架,今年流行这个语言,明年流行那个语言)。我们看一个技术的影响力,就是看这个技术能够解决哪些曾经不能解决的问题。而深度学习技术所能解决的新问题,几乎涵盖了人类社会发展的各个方面。
在自动驾驶中,输入是摄像头拍摄的实时画面(即当前状态),输出为方向盘的控制方向或车速大小。
对人的影响
王天一:无人超市和无人工厂的出现都表明:人工智能的真正威胁在于使绝大多数人沦为机器的附庸。人工智能本质上是一种劳动工具,但当劳动工具已经强大到反客为主时,作为劳动者的人类便成了多余的角色,有降格为“亚人工智能”的风险。如何应对?一个方法是专精于依赖创造力的领域,比如科学和艺术,但这对天赋要求较高,显然不适用于每一个人。另一种门槛更低的办法就是掌握核心技术,“知己知彼”,让人工智能回到“为我所用”的工具性。
李智慧:现在我们对待人工智能还有些不理智的态度,有的人认为人工智能会越来越强大,将来会统治人类。实际上,稍微了解一点人工智能的原理就会发现,这只是大数据计算出来的统计规律而已,表现得再智能,也不可能理解这样做的意义,而有意义才是人类智能的源泉。按目前人工智能的发展思路,永远不可能出现超越人类的智能,更不可能统治人类。
对架构的影响
从技术演变的角度看互联网后台架构到了2017之后,前面千奇百怪的后端体系基本上都趋同了。Kafka的实时消息队列,Spark的流处理(当然现在也可以换成Flink,不过大部分应该还是Spark),然后后端的存储,基于Hive的数据分析查询,然后根据业务的模型训练平台。各个公司反正都差不多这一套,在具体细节上根据业务有所差异,或者有些实力强大的公司会把中间一些环节替换成自己的实现,不过不管怎么千变万化,整体思路基本都一致了。个人认为,Machine Learning的很大一个好处,是简化业务逻辑,简化后台流程,不然一套业务一套实现,各种数据和业务规则很难用一个整体的技术平台来完成。
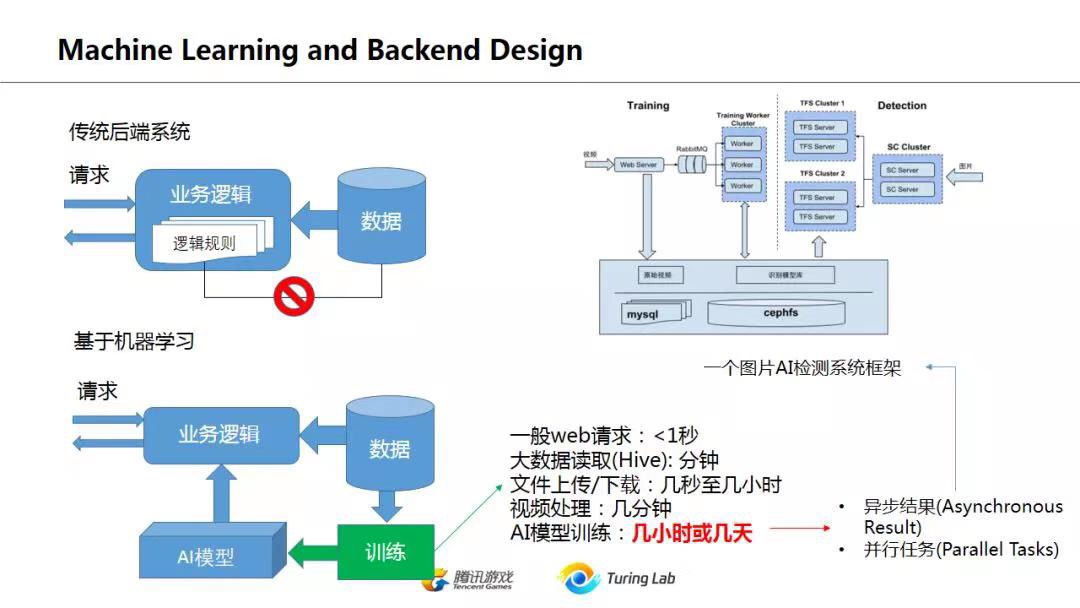
在传统后端系统中,业务逻辑其实和数据是客观分离的,逻辑规则和数据之间并不存在客观联系,而是人为主观加入,并没形成闭环,如上图左上所示。而基于机器学习的平台,这个闭环就形成了,从业务数据->AI模型->业务逻辑->影响用户行为->新的业务数据这个流程是自给自足的。这在很多推荐系统中表现得很明显,通过用户行为数据训练模型,模型对页面信息流进行调整,从而影响用户行为,然后用新的用户行为数据再次调整模型。而在机器学习之前,这些观察工作是交给运营人员去手工猜测调整。PS:从图示看,不是完全接管系统(与用户直接交互),而是接管系统的配置部分
现代的后端数据处理越来越偏向于DAG的形态,Spark不说了,DAG是最大特色;神经网络本身也可以看作是一个DAG(RNN其实也可以看作无数个单向DNN的组合);TensorFlow也是强调其Graph是DAG,另外编程模式上,Reactive编程也很受追捧。无论如何,数据,数据的跟踪Tracking,数据的流向,是现代后台系统的核心问题,只有Dataflow和Data Pipeline清晰了,整个后台架构才会清楚。
留下评论