keras 和 Estimator
简介
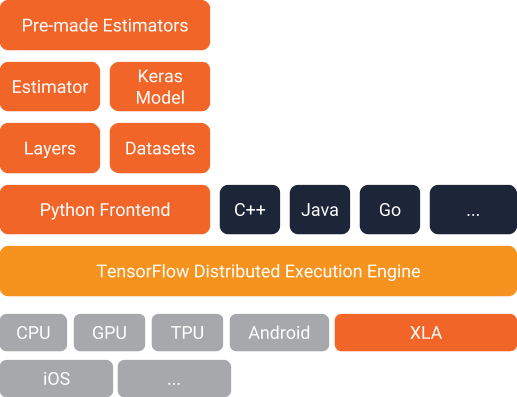
- 高层API (High level): 包括Estimators、Keras以及预构建好的Premade estimator(如线性回归、逻辑回归这些、推荐排序模型wide&deep);
- 中层API (Mid level): 包括layers, datasets, loss和metrics等具有功能性的函数,例如网络层的定义,Loss Function,对结果的测量函数等;
- 底层API (Low level): 包括具体的加减乘除、具有解析式的数学函数、卷积、对Tensor属性的测量等。
在tensorflow高阶API(Estimator、Dataset、Layer、FeatureColumn等)问世之前,用tensorflow开发、训练、评估、部署深度学习模型,并没有统一的规范和高效的标准流程。Tensorflow的实践者们基于低阶API开发的代码在可移植性方面可能会遇到各种困难。例如,单机可以运行的模型希望改成能够分布式环境下运行需要对代码做额外的改动,如何在一个异构的环境中训练模型。
原生api
用tf 原生api 写的代码 需要自己写 output/loss/optimizer等,比如
# model parameters
W = tf.Variable(0.3, tf.float32)
b = tf.Variable(-0.3, tf.float32)
# model inputs & outputs
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
# the model
out = W * x + b
# loss function
loss = tf.reduce_sum(tf.square(out - y))
# optimizer
optimizer = tf.train.GradientDescentOptimizer(0.001)
train = optimizer.minimize(loss)
# training data
x_train = np.random.random_sample((100,)).astype(np.float32)
y_train = np.random.random_sample((100,)).astype(np.float32)
# training
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for i in range(1000):
sess.run(train, {x:x_train, y:y_train})
current_loss = sess.run(loss, {x:x_train, y:y_train})
print("iter step %d training loss %f" % (i, current_loss))
print(sess.run(W))
print(sess.run(b))
keras
Keras 是开源 Python 包,由于 Keras 的独立性,Keras 具有自己的图形数据结构,用于定义计算图形:它不依靠底层后端框架的图形数据结构。PS: 所有有一个model.compile 动作? 聊聊Keras的特点及其与其他框架的关系
不足
- keras 为了解耦后端引擎, 自己定义了一套优化器,如SGD/RMSprop 等,因为它没有继承和封装 Tensorflow 的优化器,所以无法使用Tensorflow 为分布式模型设计的同步优化器,这导致短期内无法使用keras 编写分布式模型。PS:分布式用h
- 只能设计神经网络模型, 无法编写传统机器学习模型。
keras 提供两种模型范式
- 顺序模型,keras.models.Sequential类,基于函数式模型实现,适用于单输出的线性神经网络模型
- 函数式模型,keras.models.Model类,灵活性更好,适用于多输入多输出神经网络模型。
顺序模型
# 声明个模型
model = models.Sequential()
# 把部件像乐高那样拼起来
model.add(keras.layers.Dense(512, activation=keras.activations.relu, input_dim=28*28))
model.add(keras.layers.Dense(10, activation=keras.activations.softmax))
# 配置学习过程
model.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])
# 在训练数据上进行迭代,填充的数据和标签可以为 numpy 数组类型
model.fit(X_train,Y_train,nb_epoch=5,batch_size=32)
# 评估模型性能
model.evaluate(X_test,Y_test,batch_size=32)
# 对新的数据生成预测
classes = model.predict_classes(X_test,batch_size=32)
函数式模型
Keras 高级用法:函数式 API 7.1(一)有些神经网络模型有多个独立的输入,而另一些又要求有多个输出。一些神经网络模型有 layer 之间的交叉分支,模型结构看起来像图( graph ),而不是线性堆叠的 layer 。它们不能用Sequential 模型类实现,而要使用Keras更灵活的函数式 API ( functional API)。
函数式 API 可以直接操作张量,你可以将layers 模块作为函数使用,传入张量返回张量。下面来一个简单的例子,让你清晰的区别 Sequential 模型和其等效的函数式 API。
from keras.models import Sequential, Model
from keras import layers
from keras import Input
# Sequential model, which you already know about
seq_model = Sequential()
seq_model.add(layers.Dense(32, activation='relu', input_shape=(64,)))
seq_model.add(layers.Dense(32, activation='relu')) seq_model.add(layers.Dense(10, activation='softmax'))
对等的函数式模型代码。PS: 使用起来有点pytorch 的意思了。
# Its functional equivalent
input_tensor = Input(shape=(64,))
x = layers.Dense(32, activation='relu')(input_tensor)
x = layers.Dense(32, activation='relu')(x)
output_tensor = layers.Dense(10, activation='softmax')(x)
## The Model class turns an input tensor and output tensor into a model.
model = Model(input_tensor, output_tensor)
用一个输入张量和输出张量实例化了一个 Model 对象,在幕后,Keras从 input_tensor 到 output_tensor 检索每个 layer,将它们合并成一个有向无环图数据结构:一个 Model 对象。当然,这些可以运行的原因是输出张量output_tensor是从输入张量input_tensor不断转化得到的。
创建Model 对象后,可以 model.complile + model.fit 进行模型训练,也可以与tensorflow 原有api 结合,将Model 作为函数使用。
y_hat = model(input)
loss = loss(y_hat,y)
train_op = optrimizer(loss)
train_op.minimize()
实现
|-- docs #说明文档
|-- examples #应用示例
|-- test #测试文件
|-- keras #核心源码
|-- application #应用实例,如VGG16,RESNET50
|-- backend #底层接口,如:tensorflow_backend,theano_backend
|-- datasets #数据获取,如boston_housing,mnist
|-- engine #网络架构
|-- base_layer #网络架构层的抽象类
|-- network #Network类所在,构建layer拓扑DAG
|-- input_layer #输入层
|-- training #Model类所在
|-- training_generator #训练函数
|-- layers #各类层相关实现
|-- legacy #遗留源码
|-- preprocessing #预处理函数
Layer是计算层的抽象,其主要的处理逻辑是,给定输入,产生输出。因为各种layer作用的不同,所以在些基类中无法做具体实现,它们的具体功能留待各种子类去实现。
class Layer(module.Module, version_utils.LayerVersionSelector):
def __init__(self,trainable=True,name=None,dtype=None,dynamic=False,**kwargs):
self._inbound_nodes_value = []
self._outbound_nodes_value = []
# build方法一般定义Layer需要被训练的参数
def build(self, input_shape):
# call方法一般定义正向传播运算逻辑,__call__方法调用了它
def call(self, inputs, *args, **kwargs):
拓扑网络Network类
class Model(base_layer.Layer, version_utils.ModelVersionSelector):
def compile(...) # 配置学习过程
def fit(...) # 在训练数据上进行迭代
def evaluate(...) # 评估模型性能
def predict(...) # 对新的数据生成预测
model.fit
callbacks.set_model(callback_model)
callbacks.on_train_begin()
for epoch in range(initial_epoch, nb_epoch):
callbacks.on_epoch_begin(epoch)
训练
callbacks.on_epoch_end(epoch, epoch_logs)
if callback_model.stop_training:
break
callbacks.on_train_end()
训练代码
batches = make_batches(nb_train_sample, batch_size)
for batch_index, (batch_start, batch_end) in enumerate(batches):
callbacks.on_batch_begin(batch_index, batch_logs)
for i in indices_for_conversion_to_dense:
ins_batch[i] = ins_batch[i].toarray()
outs = f(ins_batch) # 对于较新的版本,进入 Model.train_step
outs = to_list(outs)
callbacks.on_batch_end(batch_index, batch_logs)
if callback_model.stop_training:
break
Keras调用tf进行计算,是分batch进行操作,每个batch结束keras可以对返回进行相应的存储等操作。
def _call(self, inputs):
if not isinstance(inputs, (list, tuple)):
raise TypeError('`inputs` should be a list or tuple.')
session = get_session()
feed_arrays = []
array_vals = []
feed_symbols = []
symbol_vals = []
#数据处理转换
for tensor, value in zip(self.inputs, inputs):
if is_tensor(value):
# Case: feeding symbolic tensor.
feed_symbols.append(tensor)
symbol_vals.append(value)
else:
feed_arrays.append(tensor)
# We need to do array conversion and type casting at this level, since `callable_fn` only supports exact matches.
array_vals.append(np.asarray(value,dtype=tf.as_dtype(tensor.dtype).as_numpy_dtype))
if self.feed_dict:
for key in sorted(self.feed_dict.keys()):
array_vals.append(np.asarray(self.feed_dict[key],dtype=tf.as_dtype(key.dtype).as_numpy_dtype))
# Refresh callable if anything has changed.
if (self._callable_fn is None or feed_arrays != self._feed_arrays or symbol_vals != self._symbol_vals or feed_symbols != self._feed_symbols or session != self._session):
#生成一个可以调用的graph
self._make_callable(feed_arrays,feed_symbols,symbol_vals,session)
#运行graph
if self.run_metadata:
fetched = self._callable_fn(*array_vals, run_metadata=self.run_metadata)
else:
fetched = self._callable_fn(*array_vals)
#返回结果
return fetched[:len(self.outputs)]
PS:在高层是 layer/model 等概念,在底层,都是op 构成的数据流图,layer/model 隐藏了op。
其它
和session 的关系
和 TensorFlow session 的关系:Keras doesn’t directly have a session because it supports multiple backends. Assuming you use TF as backend, you can get the global session as:
from keras import backend as K
sess = K.get_session()
If, on the other hand, yo already have an open Session and want to set it as the session Keras should use, you can do so via: K.set_session(sess)
callback
callbacks能在fit、evaluate和predict过程中加入伴随着模型的生命周期运行,目前tensorflow.keras已经构建了许多种callbacks供用户使用,用于防止过拟合、可视化训练过程、纠错、保存模型checkpoints和生成TensorBoard等。
callback 的关键是实现一系列 on_xx方法,callback与 训练流程的协作伪代码
callbacks.on_train_begin(...)
for epoch in range(EPOCHS):
callbacks.on_epoch_begin(epoch)
for i, data in dataset.enumerate():
callbacks.on_train_batch_begin(i)
batch_logs = model.train_step(data)
callbacks.on_train_batch_end(i, batch_logs)
epoch_logs = ...
callbacks.on_epoch_end(epoch, epoch_logs)
final_logs=...
callbacks.on_train_end(final_logs)
Estimator
使用
Introduction to TensorFlow Datasets and Estimators 它最大的特点在于兼容分布式和单机两种场景,工程师可以在同一套代码结构下即实现单机训练也可以实现分布式训练。 PS: 隐藏了 Session、Strategy 这些概念,这些概念 单机和分布式都不一样。
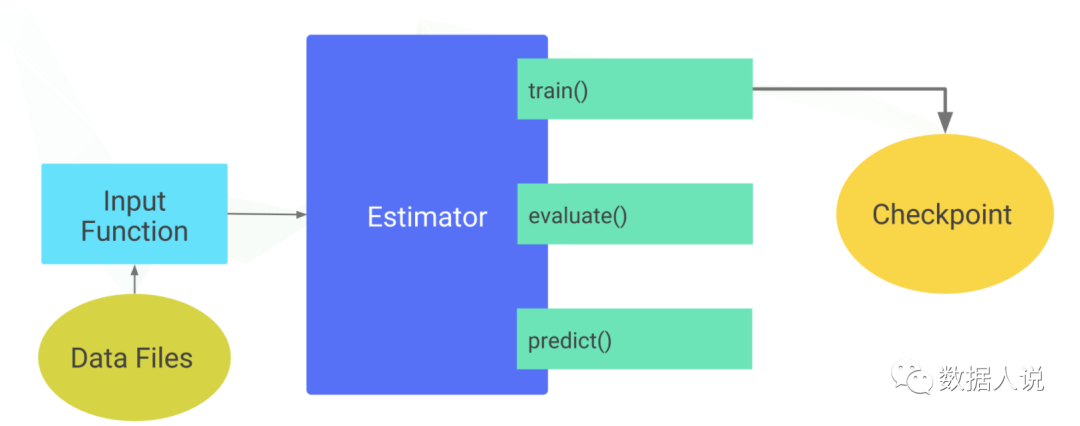
- 创建一个或多个输入函数,即input_fn
def input_fn(file_path,perform_shuffle,repeat_count): # 第一个返回值 must be a dict in which each input feature is a key, and then a list of values for the training batch. # 第二个返回值 is a list of labels for the training batch. # 将输入 转为 Dataset 再转为 input_fn 要求的格式 return ({ 'feature_name1':[values], ..<etc>.., 'feature_namen':[values] },[label_value]) - 定义模型的特征列,即feature_columns
- 实例化 Estimator,指定特征列和各种超参数。
- 在 Estimator 对象上调用一个或多个方法,传递适当的输入函数作为数据的来源。(train, evaluate, predict)
花的识别,示例代码
feature_names = ['SepalLength','SepalWidth','PetalLength','PetalWidth']
def my_input_fn(...):
...<code>...
return ({ 'SepalLength':[values], ..<etc>.., 'PetalWidth':[values] },
[IrisFlowerType])
# Create the feature_columns, which specifies the input to our model.All our input features are numeric, so use numeric_column for each one.
feature_columns = [tf.feature_column.numeric_column(k) for k in feature_names]
# Create a deep neural network regression classifier.Use the DNNClassifier pre-made estimator
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns, # The input features to our model
hidden_units=[10, 10], # Two layers, each with 10 neurons
n_classes=3,
model_dir=PATH) # Path to where checkpoints etc are stored
# Train our model, use the previously function my_input_fn Input to training is a file with training example Stop training after 8 iterations of train data (epochs)
classifier.train(input_fn=lambda: my_input_fn(FILE_TRAIN, True, 8))
# Evaluate our model using the examples contained in FILE_TEST
# Return value will contain evaluation_metrics such as: loss & average_loss
evaluate_result = estimator.evaluate(input_fn=lambda: my_input_fn(FILE_TEST, False, 4)
原理
# tensorflow/python/estimator/estimator.py
class Estimator(object):
def __init__(self,
model_fn, # 定义模型,根据不同的模式分别定义训练、评估和预测的图。
model_dir=None, # 模型导出目录
config=None, # 配置参数
params=None, # 自定义Estimator的额外参数
warm_start_from=None): # 模型热启动
def train(self,
input_fn, # 返回训练特征和标签的tuple
hooks=None, # 通过hook指定训练过程中的自定义行为
steps=None, # 训练步数
max_steps=None, # 训练总步数
saving_listeners=None):
with context.graph_mode():
hooks.extend(self._convert_train_steps_to_hooks(steps, max_steps))
loss = self._train_model(input_fn, hooks, saving_listeners)
logging.info('Loss for final step: %s.', loss)
# _train_model根据不同的配置,分别走到分布式训练和本地训练的函数
def _train_model(self, input_fn, hooks, saving_listeners):
if self._train_distribution:
return self._train_model_distributed(input_fn, hooks, saving_listeners)
else:
return self._train_model_default(input_fn, hooks, saving_listeners)
其中最核心的参数为model_fn
def _model_fn(features, # 特征,可以是Tensor或dict of Tensor
labels, # 标签
mode, # 模式,ModeKeys.TRAIN, ModeKeys.EVAL, ModeKeys.PREDICT
params, # 自定义参数,即上面Estimator构造函数中的params
config): # 配置参数
...
# return EstimatorSpec
Estimator.train ==> _train_model ==> _train_model_default, 本地训练的实现
class Estimator(object):
def _train_model_default(self, input_fn, hooks, saving_listeners):
with ops.Graph().as_default() as g, g.device(self._device_fn):
random_seed.set_random_seed(self._config.tf_random_seed)
# 先创建global_step
global_step_tensor = self._create_and_assert_global_step(g)
# 调用input_fn来得到训练特征和标签
features, labels, input_hooks = (self._get_features_and_labels_from_input_fn(input_fn, ModeKeys.TRAIN))
worker_hooks.extend(input_hooks)
# 调用model_fn来得到训练图
estimator_spec = self._call_model_fn(features, labels, ModeKeys.TRAIN, self.config)
global_step_tensor = training_util.get_global_step(g)
# 进入training loop
return self._train_with_estimator_spec(estimator_spec, worker_hooks,hooks, global_step_tensor,saving_listeners)
def _train_with_estimator_spec(self, estimator_spec, worker_hooks, hooks,global_step_tensor, saving_listeners):
# 配置Hook
worker_hooks.extend(hooks)
worker_hooks.append(training.NanTensorHook(estimator_spec.loss)
worker_hooks.append(training.LoggingTensorHook(...))
saver_hooks = [h for h in all_hooks if isinstance(h, training.CheckpointSaverHook)]
worker_hooks.extend(estimator_spec.training_hooks)
worker_hooks.append(training.SummarySaverHook(...))
worker_hooks.append(training.StepCounterHook(...))
# 使用MonitoredTrainingSession进行Training loop
with training.MonitoredTrainingSession(master=self._config.master,is_chief=self._config.is_chief,checkpoint_dir=self._model_dir,scaffold=estimator_spec.scaffold,hooks=worker_hooks,....) as mon_sess:
loss = None
any_step_done = False
while not mon_sess.should_stop():
_, loss = mon_sess.run([estimator_spec.train_op, estimator_spec.loss])
any_step_done = True
if not any_step_done:
logging.warning('Training with estimator made no steps. Perhaps input is empty or misspecified.')
return loss
分布式训练实现用到了 Strategy,记录在 tensorflow 分布式原理的文章中。
留下评论