Kubernetes监控
简介
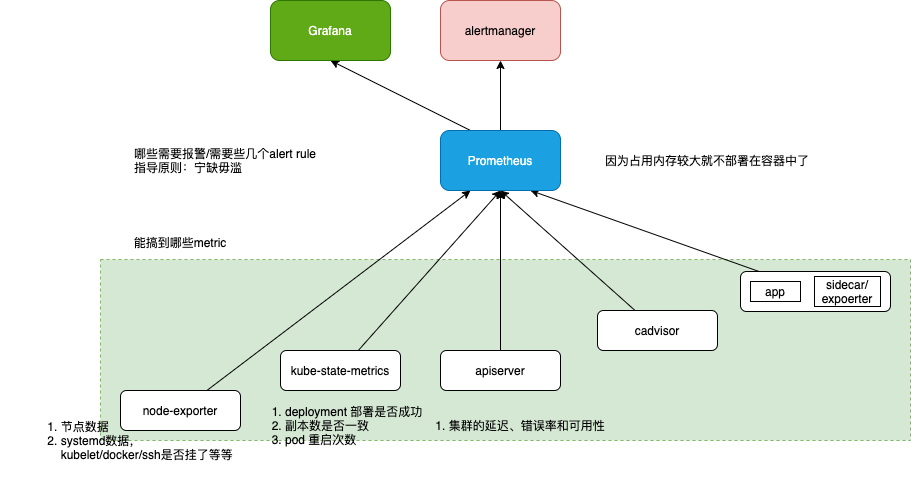
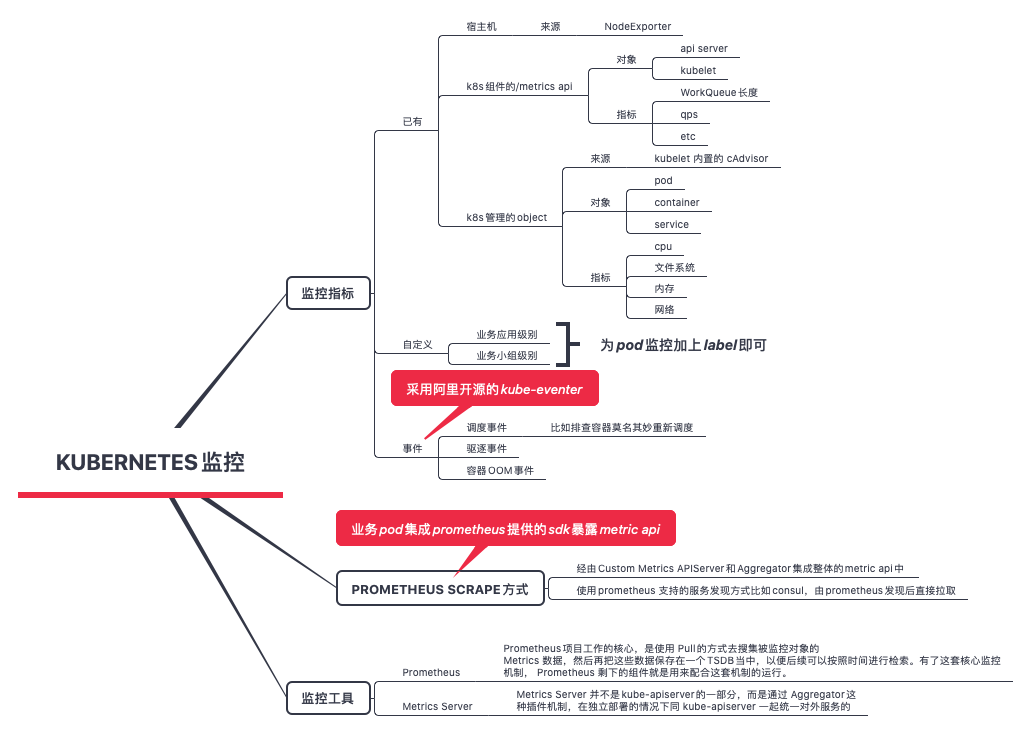
能搞到哪些metric
Kubernetes Pod状态异常九大场景盘点 列出了9个场景,并列出对应的监控来回答9个场景的问题
- Kubernetes 监控的 Pod 详情页包含了
- Pod 相关的 Kubernetes 信息,比如事件、Conditions、获取 YAML 能力,日志界面以及终端能力
- Pod 作为服务端的性能监控,可以快速发现错慢趋势。对于错慢请求,我们存储了明细,包含了请求和响应信息、整体耗时,以及请求接收,请求处理和请求响应的分段耗时
- Pod 的资源消耗以及特定容器的资源申请失败监控,可以看到哪些容器资源消耗得多,后续我们将会加上 profiling 能力,回答哪个方法占用 CPU 比较多,哪个对象占用内存比较多,与此同时详情页还包含了关联 Node 的资源消耗情况
- Kubernetes 监控的拓扑页面
- 会展示集群节点到外部服务以及集群节点之间的请求关系,点击请求关系,可以快速查看特定节点到特定外部服务的请求性能,可以快速定位下游问题。
- 会展示集群节点到外部服务以及集群节点之间的网络关系,点击网络关系,可以快速查看特定节点到特定外部服务的网络
在Kubernetes从1.10版本后采用Metrics Server作为默认的性能数据采集和监控,主要用于提供核心指标(Core Metrics),包括Node、Pod的CPU和内存使用指标。对其他自定义指标(Custom Metrics)的监控则由Prometheus等组件来完成。
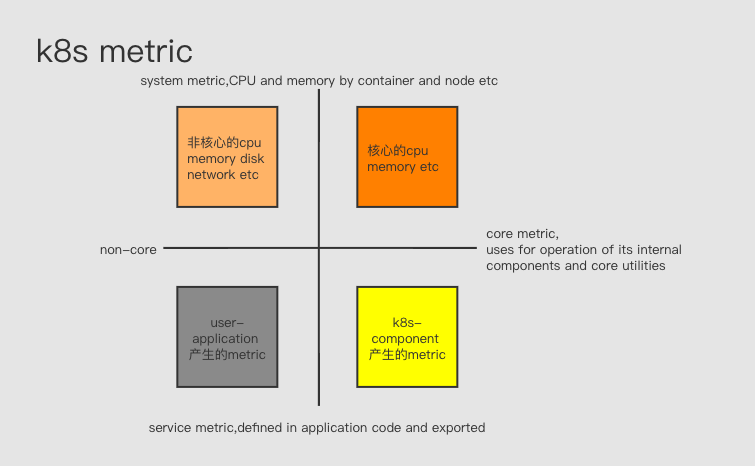
k8s 社区对k8s 监控的表述 Kubernetes monitoring architecture 将metric 分为
- core metrics, which are metrics that Kubernetes understands and uses for operation of its internal components and core utilities. metric 应用于k8s 内部组件,比如调度、扩缩容、dashboard、kubectl top. 由k8s 提供统一规范和支持(即metrics-server)。
- non-core metrics
prometheus使用missing-container-metrics监控pod oomkill
node-exporter
node-exporter提供了近1000个指标,以node_ 为前缀,包括node_cpu_*,node_memory_*, node_filesystem_*/node_disk_*, node_network_* 等。
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: node-exporter
namespace: monitoring
...
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
hostNetwork: true
hostPID: true
hostIPC: true
securityContext:
runAsUser: 0
利用Kubernetes DaemonSet控制器在集群中的每个节点上自动node-exporter pod。
- 启用systemd收 集器,并指定要监控的特定服务的正则表达式,而不是主机上的所有服务。
- 使用toleration来确保 node-exporter pod也会被调度到Kubernetes主节点,而不仅是工作节点。
- 以用户0或root运行pod(这允许访问systemd),并 且还启用了hostNetwork、hostPID和hostIPC,以指定实例的网络、进程和IPC命名空间在容器中可用。
containers:
- images: prom/node-exporter:latest
name: node-exporter
volumeMounts:
- mountPath: /run/systemd/private
name: systemd-socket
readOnly: true
args:
- "--collector.systemd"
- "--collector.systemd.unit-whitelist=(docker|ssh|rsyslog|kubelet).service"
ports:
- containerPort: 9100
hostPort: 9100
name: scrape
配置一个Prometheus scrape job,结合Kubernetes daemonset, 只需要定义一次,未来所有Kubernetes服务端点都将被自动发现 和监控。
k8s 组件 指标分析
Kubernetes 各组件的 Healthz 和 Metrics API
| Components | Healthz API | Metrics API |
|---|---|---|
| Apiserver | :6443/healthz |
:6443/metrics |
| Controller Manager | :10252/healthz |
:10252/metrics |
| Scheduler | :10251/healthz |
:10251/metrics |
| Kube-proxy | :10249/healthz |
:10249/metrics |
| Kubelet | :10248/healthz |
:10250/metrics |
| ETCD | :2379/healthz |
:2379/metrics |
kube-apiserver 是集群所有请求的入口,指标的分析可以反应集群的健康状态。Apiserver 的指标可以分为以下几大类:
- 请求速率和延迟,
apiserver_request_*/apiserver_response_* - 控制器队列的性能,
apiserver_admission_* - etcd 的性能,
etcd_* - 进程状态:文件系统、内存、CPU
- golang 程序的状态:GC、进程、线程,
go_gc_*/go_info
Pinterest如何平稳扩展K8s?监控apiserver,我们通过查看 QPS 和并发请求、错误率,以及请求延迟来监控 kube-apiserver 的负载。我们也可以将流量按照资源类型、请求动词以及相关的服务账号进行细分。而对于 listing 这类的昂贵流量,我们通过对象计数和字节大小来计算请求负载,即使只有很小的 QPS,这类流量也很容易导致 kube-apiserver 过载。最后,我们还监测了 etcd 的 watch 事件处理 QPS 和延迟处理的计数,以作为重要的服务器性能指标。
ETCD 指标分析
Kubernetes使用etcd来存储集群中组件的所有状态,是 Kubernetes数据库,监视etcd的性能和行为应该是整个Kubernetes监控计划的一部分。
etcd服务器指标以 etcd_* 为前缀,分为几个主要类别:
- Leader的存在和Leader变动率,
etcd_server_leader_* - 请求已提交/已应用/正在等待/失败,
etcd_server_proposals_* - 磁盘写入性能 ,
etcd_disk_* - 入站gRPC统计信息,集群内gRPC统计信息,
etcd_grpc_*
k8s object metric/kube-state-metrics
- kube-state-metrics is a simple service that listens to the Kubernetes API server and generates metrics about the state of the objects. It is not focused on the health of the individual Kubernetes components, but rather on the health of the various objects inside, such as deployments, nodes and pods. 上文关注的是 k8s组件是否健康, kube-state-metrics 关注的Kubernetes 的object 是否健康。
- kube-state-metrics uses client-go to talk with Kubernetes clusters,将Kubernetes的结构化信息转换为metrics,很多metric 都来自 Kubernetes object 的Status 或 Conditions 等字段,
kubectl describe xx一样可以看到。 - k8s custom resource 比如 verticalpodautoscalers 默认不采集, 需要额外配置
- 以Deployment 方式运行,以Service 对外服务
所有metric 以 kube_* 为前缀,每一个k8s resource 对应一批metric Exposed Metrics ,以kube_资源名_* 为前缀,以kube_deployment_*为例
kube_deployment_status_replicas
kube_deployment_status_replicas_available
kube_deployment_spec_replicas
...
以pod为例:
kube_pod_info
kube_pod_owner
kube_pod_status_phase
kube_pod_status_ready
kube_pod_status_scheduled
kube_pod_container_status_waiting
kube_pod_container_status_terminated_reason # 比如OOMKilled
Kube-state-metrics self metrics,描述自身的工作状态,比如
kube_state_metrics_list_total{resource="*v1.Node",result="success"} 1
kube_state_metrics_list_total{resource="*v1.Node",result="error"} 52
kube_state_metrics_watch_total{resource="*v1beta1.Ingress",result="success"} 1
kube-state-metrics 可以采集到的 自定义的k8s label(比如deployment等),基于此经常将kube-state-metrics metric 与其它metric 聚合后 制作报警规则。
通过 kube-state-metrics 添加 CRD 状态指标
以pod 方式运行的业务的 metric
Kubernetes 集群监控 kube-prometheus 自动发现 Prometheus 通过与 Kubernetes API 集成主要支持5种服务发现模式:
- Node, 适用于与主机相关的监控资源
- Service、Ingress, 适用于通过黑盒监控的场景,如对服务的可用性以及服务质量的监控
- Pod、Endpoints, 获取 Pod 实例的监控数据
We need to grant some permissions to Prometheus to access pods, endpoints, and services running in your cluster. We can do this via the ClusterRole resource that defines an RBAC policy. prometheus 使用 kubernetes_sd_configs 发现k8s object 时 需要授权,运行在 k8s 内的prometheus 可以使用 sa,k8s 集群外的 prometheus 则需要指定 ca_file 和 bearer_token_file。
如何让Prometheus抓取
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- api_server: 'http://xx:8080';
role: node/service/ingress/pod/endpoints
tls_config:
ca_file: xx
bearer_token_file: xx
relabel_configs: # 对采集过来的指标做二次处理,比如要什么不要什么以及替换什么等等
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] # 以__meta_开头的这些元数据标签都是实例中包含的
action: keep
regex: true # 仅抓取到的具有 "prometheus.io/scrape: true" 的annotation的端点
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace # 根据regex来去匹配source_labels标签上的值,并将并将匹配到的值写入target_label中
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] # 以__开头的标签通常是系统内部使用的
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
# 下面主要是为了给样本添加额外信息
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace] # namespace 名称
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name] # service 对象的名称
action: replace
target_label: kubernetes_name
pod 中业务暴露的metric 监控
通过添加额外的配置来进行服务发现进行自动监控(自声明),比如 在 kube-prometheus 当中去自动发现并监控具有 prometheus.io/scrape=true 这个 annotations 的 Service/Pod。
# kubectl describe service xxx
Annotations: example.com/port: 2121
example.com/scrape: true
IP: 10.103.173.42
Port: <unset> 8080/TCP
Endpoints: 172.31.10.228:8080
业务监控 一般由业务直接暴露metric或通过边车模式暴露metric。在Pod 或Service 中定义注解,可以让Prometheus 自动发现当前metric endpoint 并抓取数据
apiVersion: v1
kind: Service
metadata:
name: tornado-db
annotations:
prometheus.io/scrape: 'true' # 告诉Prometheus抓取这个服务
prometheus.io/port: '9104' # 告诉 Prometheus要抓取的端口,将被放入__address__标签中
分布式系统可观测性之应用业务指标监控实践 Micrometer提供了多种度量类库(Meter),Meter是指一组用于收集应用中的度量数据的接口。为了方便微服务应用接入,我们封装了micrometer-spring-boot-starter。如果想要记录打印方法的调用次数和时间,需要给print方法加上@Timed注解,并给指标定义一个名称。
@Timed(value = "biz.print", percentiles = {0.95, 0.99}, description = "metrics of print")
public String print(PrintData printData) {
}
pod cpu和内存——Metrics Server/cadvisor
Metrics server复用了api-server的库来实现自己的功能,比如鉴权、版本等,为了实现将数据存放在内存中,去掉了默认的etcd存储,引入了内存存储。因为存放在内存中,因此监控数据是没有持久化的,可以通过第三方存储来拓展
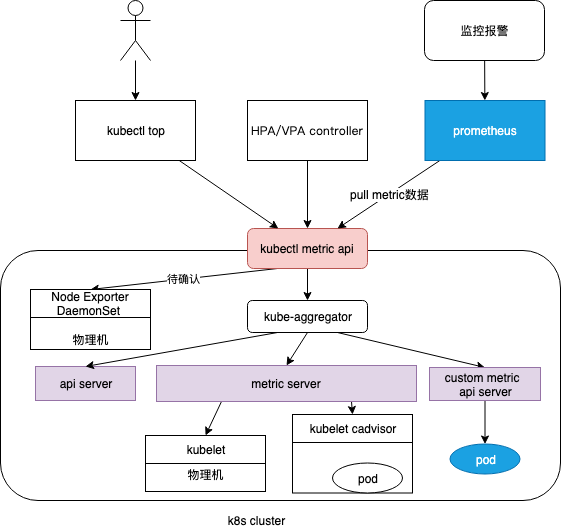
- Metrics API URI 为
/apis/metrics.k8s.io/,在k8s.io/metrics维护 - 必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 Kubelet Summary API 获取数据,Summary API 返回的信息,既包括了 cAdVisor 的监控数据,也包括了 kubelet 本身汇总的信息。Pod 的监控数据是从kubelet 的 Summary API (即
<kubelet_ip>:<kubelet_port>/stats/summary)采集而来的。 - Metrics server以Deployment 形式存在,复用了api-server的库来实现自己的功能,比如鉴权、版本等,为了实现将数据存放在内存中吗,去掉了默认的etcd存储,引入了内存存储。因此监控数据是没有持久化的,可以通过第三方存储来拓展
从cadvisor 视角看
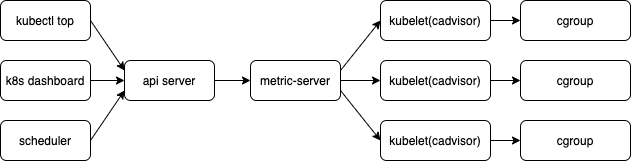
cadvisor 指标分析
cadvisor 是监控容器的,容器像物理机一样为业务提供运算资源,因此按照 USE 对容器的指标进行分析。监控的黄金指标
cadvisor 指标以container_ 为前缀,包括container_cpu_*,container_memory_*, container_fs_*, container_network_* 等,还有 container_spec_* 获取了 container 配置相关的内容。部分指标如下
cpu
- container_cpu_user_seconds_total —“用户”时间的总数(即不在内核中花费的时间)
- container_cpu_system_seconds_total —“系统”时间的总数(即在内核中花费的时间)
- container_cpu_usage_seconds_total—以上总和
- container_cpu_cfs_throttled_seconds_total 当容器超出其CPU限制时,Linux运行时将“限制”该容器并在container_cpu_cfs_throttled_seconds_total指标中记录其被限制的时间
cAdvisor中提供的内存指标是从node_exporter公开的43个内存指标的子集。以下是容器内存指标:
- container_memory_cache-页面缓存的字节数。
- container_memory_rss -RSS的大小(以字节为单位)。
- container_memory_swap-容器交换使用量(以字节为单位)。
- container_memory_usage_bytes-当前内存使用情况(以字节为单位,包括所有内存,无论何时访问。) 包括了文件系统缓存
- container_memory_max_usage_bytes- 以字节为单位记录的最大内存使用量。
- container_memory_working_set_bytes-当前工作集(以字节为单位)。简称 wss,k8s使用wss作为oom kill的依据
- container_memory_failcnt-内存使用次数达到限制。
- container_memory_failures_total-内存 分配失败的累积计数。
网络
使用 k8spacket 与 Grafana 可视化 K8s Tcp流量
监控平台设计
Kubernetes 稳定性保障手册 – 极简版未细读 KubeNode:阿里巴巴云原生容器基础设施运维实践 仅仅是一个kubelet 是不够用的。
KubeEye:Kubernetes 集群自动巡检工具 一键自动巡检!青云 Kubernetes 集群巡检 SaaS 服务正式发布
通过Kubernetes监控探索应用架构,发现预期外的流量 是一个系列文章,阿里已经将应用 ==> k8s ==> 内核监控打通。构建拓扑图 ==> 发现异常流量、阈值报警(拓扑图的边黄色或红色)==> 异常流量上下游各种信息。
当容器应用越发广泛,我们又该如何监测容器?阿里云推出 Kubernetes 监测服务
- 代码无侵入:通过旁路技术,无需代码埋点,即可获取到网络性能数据。
- 多语言支持:通过内核层进行网络协议解析,支持任意语言及框架。
- 低耗高性能:基于 eBPF 技术,以极低消耗获取网络性能数据。
- 资源自动拓扑:通过网络拓扑,资源拓扑展示相关资源的关联情况。
- 数据多维展现:支持可观测的各种类型数据(监测指标、链路、日志和事件)。
- 打造关联闭环:完整关联架构层、应用层、容器运行层、容器管控层、基础资源层相关可观测数据。 应用在以下场景:
- 通过 Kubernetes 监测的系统默认或者自定义巡检规则,发现节点,服务与workload的异常。
- 使用 Kubernetes 监测定位服务与工作负载响应失败根因,Kubernetes 监测通过分析网络协议对失败请求进行明细存储,利用失败请求指标关联的失败请求明细定位失败原因。
- 使用 Kubernetes 监测定位服务与工作负载响应慢根因,Kubernetes 监测通过抓取网络链路关键路径的指标,查看 DNS 解析性能,TCP 重传率,网络包 rtt 等指标。利用网络链路关键路径的指标定位响应慢的原因,进而优化相关服务。
- 使用 Kubernetes 监测探索应用架构,发现预期外的网络流量。Kubernetes 监测支持查看全局流量构建起来的拓扑大图,支持配置静态端口标识特定服务。 如何发现 Kubernetes 中服务和工作负载的异常
- 首先还是先有指标,指标能反应服务的监控状态,我们应尽可能地收集各种指标,并且越全越好
- 然后,指标是宏观数据,需要做根因分析我们得有 Trace 数据,多语言、多协议的情况下要考虑采集这些 Trace 的成本,同样尽可能地支持多一点协议、多一点语言;
- 最后,用一张拓扑将指标、Trace、事件汇总起来、串联起来,形成一张拓扑图,用来做架构感知分析、上下游分析。
- 但我们不应该就此停止前进的脚步,加入这个异常下次再来,那么我们这些工作得重来一遍,最好的办法是针对这类异常配置对应的告警,自动化地管理起来。 个人理解: 服务(web/rpc/mq/db等)是点,调用关系(网络通信)是边,根据trace 连接点和边(建立拓扑),配置报警规则为点和边着色。
抓取间隔也是一个很重要的问题,很多异常现象只是瞬间发生,有可能因为抓取间隔的原因而没有被发现。
需要哪些 alert rule
monitoring.mixin 列出了各个组件建议配置的alert 规则。
指导原则:宁缺毋滥。其实有十几个报警就不少了,再多也处理不过来。 可以参照《Prometheus 监控实战》中提到的对Prometheus 的报警规则。
报警的哲学追踪所有收到的报警。如果收到了报警,而人们只是说 “我看了,没有什么问题”,这是一个相当强烈的信号,你需要删除报警规则,或者降级,或者以其他方式收集数据。准确率低于 50% 报警是不能使用的;即使是那些 10% 的假阳性警报,也值得多加考虑是否对齐进行修改。
制作哪些dashboard
Grafana 官方有一个 dashboard 市场,可以针对各个组件找到 全面丰富的dashboard
k8s监控平台
Kubernetes监控在小米的落地 为了更方便的管理容器,Kubernetes对Container进行了封装,拥有了Pod、Deployment、Namespace、Service等众多概念。与传统集群相比,Kubernetes集群监控更加复杂:
- 监控维度更多,除了传统物理集群的监控,还包括核心服务监控(apiserver,etcd等)、容器监控、Pod监控、Namespace监控等。
- 监控对象动态可变,在集群中容器的销毁创建十分频繁,无法提前预置。
- 监控指标随着容器规模爆炸式增长,如何处理及展示大量监控数据。
- 随着集群动态增长,监控系统必须具备动态扩缩的能力。
监控 Pod 时,我们在监控什么Kubernetes 和 KVM 的区别在不同组件存在区别:
- CPU 区别最大,这是 Kubernetes 技术本质决定的
- 内存有一定区别,但是基本可以和 KVM 技术栈统一
- 网络、磁盘区别不大,基本没有额外的理解成本
物理机
对于一个独立的 CPU core,它的时间被分成了三份:
- 执行用户代码时间
- 执行内核代码时间
- 空闲时间(对于 x86 体系而言,此时会执行 HLT 指令)
KVM 环境下计算 CPU 使用率很直接:(执行用户代码时间 + 执行内核代码时间)/ 总时间。
CPU load 用于衡量当前系统的负载情况, Linux 系统使用当前处于可运行状态的线程数来标识,包括:
- 处于 running 状态的线程,这个是最正常的情况,获得 CPU 分片,执行用户态或者内核态代码的线程
- 处于 uninterruptible sleep 状态的线程,这个是特殊的情况,表明这个线程在进行 I/O 操作 因此
- CPU load 高,CPU 使用率低,一般表明性能瓶颈出现在磁盘 I/O 上
- CPU 使用率高,CPU load 远高于 CPU 核数,表示当前 CPU 资源严重不足
在KVM场景中,内存的具体使用量并没有一个非常清晰的标准,cache/buffer/slab 内存对于应用性能的影响和应用本身的特点有关,没有统一的计算方案,综合各种因素,监控使用 total - available 作为内存使用
pod
对于 Kubernetes Pod 而言,它不再享有独立的 CPU core,因此这个公式不再成立。在 Kubernetes 语境下,CPU 的资源总量/使用量是通过时间表示的。由于 Kubernetes 对 CPU Limit 的实现粒度有限,同时考虑到统计的误差,因此在压测等极限场景中 CPU 使用率会出现高于 100% 的”毛刺“。Kubernetes 虽然也提供了 cpu_load 指标,却只包含了处于 running 状态的线程,这个指标也失去了判断系统性能瓶颈是否出现在 I/O 的作用。
Kubernetes 通过 Completely Fair Scheduler (CFS) Cgroup bandwidth control 限制 Pod 的 CPU 使用:
- 首先,我们将 1s 分成多个 period,每个 period 持续时间为 0.1s
- 在每个 peroid 中,Pod 需要向 CFS 申请时间片,CFS 通过 Limit 参数判断这个申请是否达到这个 Pod 的资源限制
- 如果达到了 Pod 的资源限制,”限流时间“ 指标会记录限流的时间 因此,当一个 Pod 的”限流时间“非常高时,意味着这个 Pod CPU 资源严重不足,需要增加更多的资源了。
Kubernetes 对于内存使用暴露了不同的值:
- MemUsed:和 Linux 的 used 一样,包含了 cache 值
- WorkingSet:比 memUsed 小一些,移除了一些“冷数据”,即长期没有访问的 cache 内存
- RSS:移除了 cache 的内存 一般情况下,我们认为 WorkingSet 是比较合理的内存使用量指标
整体设计
基于 eBPF 的 Kubernetes 一站式可观测性系统
- 复杂度是永恒的,我们只能找到方法来管理它,无法消除它,云原生技术的引入虽然减少了业务应用的复杂度,但是在整个软件栈中,他只是将复杂度下移到容器虚拟化层,并没有消除。
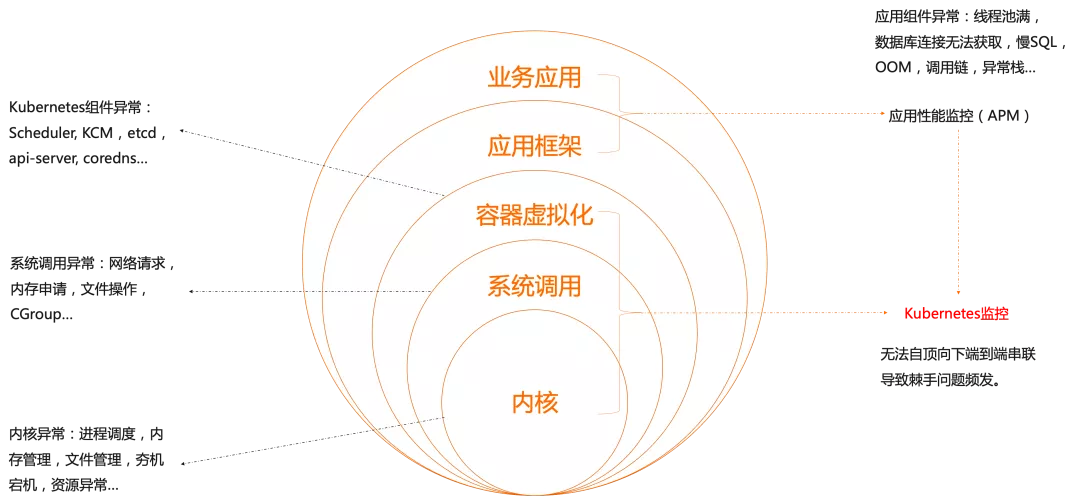
- 我们以容器为核心,采集关联的 Kubernetes 可观测数据,与此同时,向下采集容器相关进程的系统和网络可观测数据,向上采集容器相关应用的性能数据,通过关联关系将其串联起来,完成端到端可观测数据的覆盖。
- 我们的数据类型包含了指标,日志和链路,采用了 open telemetry collector 方案支持统一的数据传输。背靠 ARMS 已有的基础设施,指标通过 ARMS Prometheus 进行存储,日志/链路通过 XTRACE 进行存储。PS: 应该是一个agent 支持采集日志、metrics、trace
- 使用路径:核心场景上支持架构感知、错慢请求分析、资源消耗分析、DNS 解析性能分析、外部性能分析、服务连通性分析和网络流量分析。支持这些场景的基础是产品在设计上遵循了从整体到个体的原则:先从全局视图入手,发现异常的服务个体,如某个 Service,定位到这个 Service 后查看这个 Service 的黄金指标、关联信息、Trace等进行进一步关联分析。
- datadog 的 CEO 在一次采访中直言 datadog 的产品策略不是支持越多功能越好,而是思考怎样在不同团队和成员之间架起桥梁,尽可能把信息放在同一个页面中(to bridge the gap between the teams and get everything on the same page)
在阿里巴巴,我们如何先于用户发现和定位 Kubernetes 集群问题? 探测、巡检、根因分析。
基于 eBPF 的 Kubernetes 问题排查全景图 监测工具不是功能越多功能越好,而是要思考怎样在不同团队和成员之间架起桥梁,尽可能把信息放在同一个页面中。那么具体怎么关联呢?信息怎么组织呢?主要从两方面来看:
- 横向,端到端:展开说就是应用到应用,服务到服务,两者调用关系是关联的基础,因为调用才产生了联系。
- 纵向,以 Pod 为媒介,Kubernetes 层面关联 Workload、Service 等对象,基础设施层面可以关联节点、存储设备、网络等,应用层面关联日志、调用链路等。
其它
留下评论