grpc学习
简介
gRPC 就是采用 HTTP/2 协议,并且默认采用 PB 序列化方式的一种 RPC。
grc特点
- 语言中立,支持多种语言;
- 基于 IDL 文件定义服务,通过 proto3 工具生成指定语言的数据结构、服务端接口以及客户端 Stub;
- 通信协议基于标准的 HTTP/2 设计,支持双向流、消息头压缩、单 TCP 的多路复用、服务端推送等特性,这些特性使得 gRPC 在移动端设备上更加省电和节省网络流量;
- 序列化支持 PB(Protocol Buffer)和 JSON,PB 是一种语言无关的高性能序列化框架,基于 HTTP/2 + PB, 保障了 RPC 调用的高性能。
| grpc | thrift | |
|---|---|---|
| 协议层 | TbinaryProtocol TCompactProtocol TJSONProtocol TDebugProtocol |
|
| 传输层 | HTTP/2 | TSocket TFramedTransport TFileTransport TMemoryTransport TZlibTransport |
| 服务端 | HTTP/2 | TSimpleServer TThreadPoolServer TNonblockingServer |
| 权限认证 | SSL/TLS OAuth2.0 API |
SSL |
| 流式处理 | 支持 | 不支持 |
基本过程
直接操作网络协议编程,容易让业务开发过程陷入复杂的网络处理细节。RPC 框架以编程语言中的本地函数调用形式,向应用开发者提供网络访问能力,这既封装了消息的编解码,也通过线程模型封装了多路复用,对业务开发很友好。
- 客户端(gRPC Stub)调用 A 方法,发起 RPC 调用。
- 对请求信息使用 Protobuf 进行对象序列化压缩(IDL)。
- 服务端(gRPC Server)接收到请求后,解码请求体,进行业务逻辑处理并返回。
- 对响应结果使用 Protobuf 进行对象序列化压缩(IDL)。
- 客户端接受到服务端响应,解码请求体。回调被调用的 A 方法,唤醒正在等待响应(阻塞)的客户端调用并返回响应结果。
序列化协议 protobuf
协议的作用就是用于分割二进制数据流。事实上的跨语言序列化方案只有三个: protobuf, thrift, json体积太大,protobuf 和 grpc 都是google 发明的。
为什么省空间?——查表
protobuf、thrift一个特点是数据有“模式”(schema),必须要先写一个 IDL(Interface Description Language)文件,在里面定义好数据结构,只有预先定义了的数据结构,才能被序列化和反序列化。
消息由多个kv对组成
{"name":"John","id":1234,"sex":"MALE"}
Protobuf 将这 3 个字段名预分配了 3 个数字,定义在 proto 文件中:
message Person {
string name = 1;
uint32 id = 2;
enum SexType {
MALE = 0;
FEMALE = 1;
}
SexType sex = 3;
}
编码后的信息仅有 11 个字节。其中,报文与字段的对应关系如下图
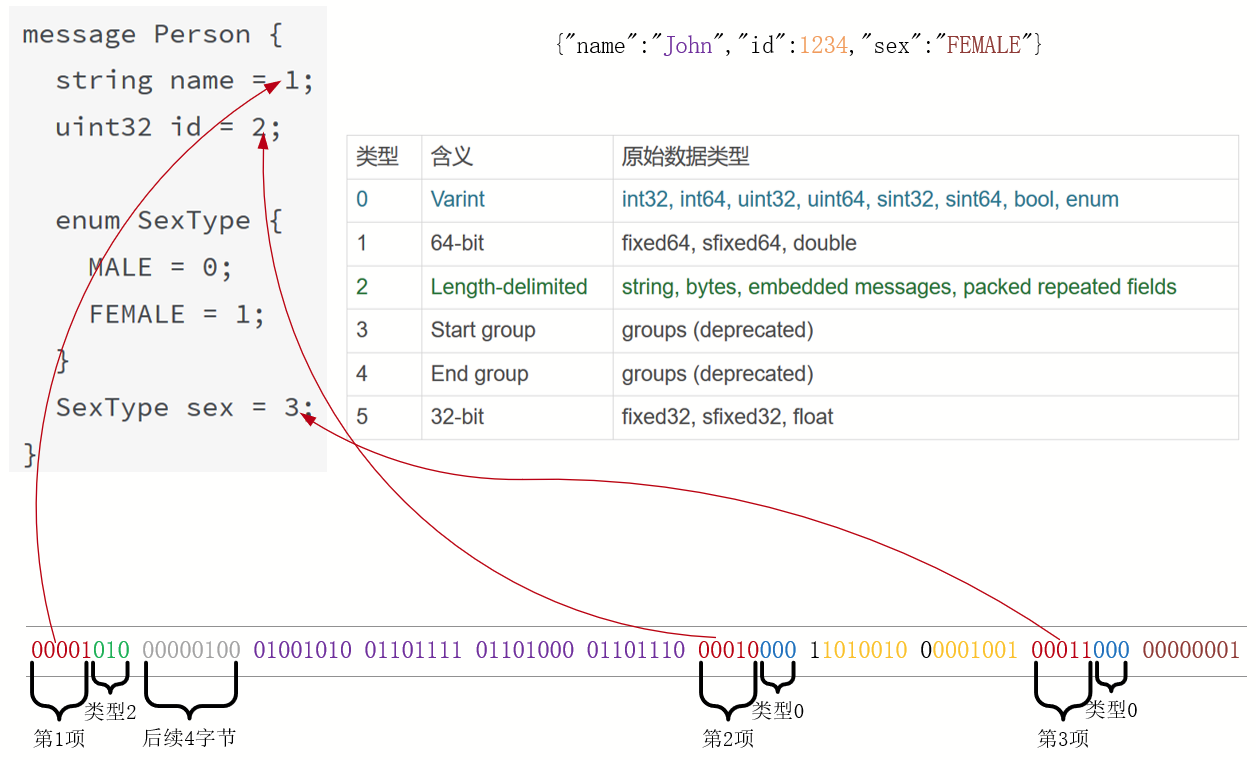
http2 在头部压缩中也使用了类似的机制。
官方示例
syntax = "proto3";
package helloworld;
// The greeting service definition.
service Greeter {
// Sends a greeting
rpc SayHello (HelloRequest) returns (HelloReply) {}
}
// The request message containing the user's name.
message HelloRequest {
string name = 1;
}
// The response message containing the greetings
message HelloReply {
string message = 1;
}
java序列化和反序列化接口调用
HelloRequest request
= HelloRequest.newBuilder().setName(name).build();
byte[] data = request.toByteArray();
// 反序列化
HelloRequest.parseFrom(data);
客户端和服务端
开发人员首先定义好所有的业务功能,然后根据 proto 文件生成服务端框架代码。类似地,可以使用相同的 proto 文件生成客户端存根代码。当客户端调用服务时,客户端 gRPC 库使用 protobuf 封装远程过程调用,然后通过 HTTP2 发送出去。在服务器端,请求被解封,并且通过 protobuf 执行相应的过程调用。响应遵循类似的流程,从服务器端发送到客户端。
go语言下的示例
helloworld
helloworld.proto
helloworld.pb.go ## 基于protoc --go_out=plugins=grpc:. helloworld.proto 生成
server.go
client.go
server.go
type GrpcServerDemo struct {
}
func (*GrpcServerDemo) SayHello(ctx context.Context, req *HelloRequest) (*HelloReply, error) {
return &HelloReply{
Message: fmt.Sprintf("Hello: %s", req.Name),
}, nil
}
func Server() {
lis, err := net.Listen("tcp", "127.0.0.1:8080")
if err != nil {
fmt.Printf("failed to listen: %v\n", err)
}
grpcServer := grpc.NewServer()
RegisterGreeterServer(grpcServer, &GrpcServerDemo{})
grpcServer.Serve(lis)
}
插段题外话: http1 server 的代码如下
func helloHandler(w http.ResponseWriter, req *http.Request) {
io.WriteString(w, "hello, world!\n")
}
func Server() {
http.HandleFunc("/", helloHandler)
http.ListenAndServe(":12345", nil)
// http.ListenAndServe 是下面三行代码的封装
//server := &http.Server{}
//ln, _ := net.Listen("tcp", ":12345")
//server.Serve(ln)
}
可以看到,gprc server 和 http server 的代码风格大体保持一致
client.go
func Client() {
// 创建connection
conn, _ := grpc.Dial("127.0.0.1:8080", grpc.WithInsecure())
defer conn.Close()
// 创建client
cli := NewGreeterClient(conn)
// 调用RPC接口
response, _ := cli.SayHello(context.Background(), &HelloRequest{Name: "zhangsan"})
fmt.Println(response.Message)
}
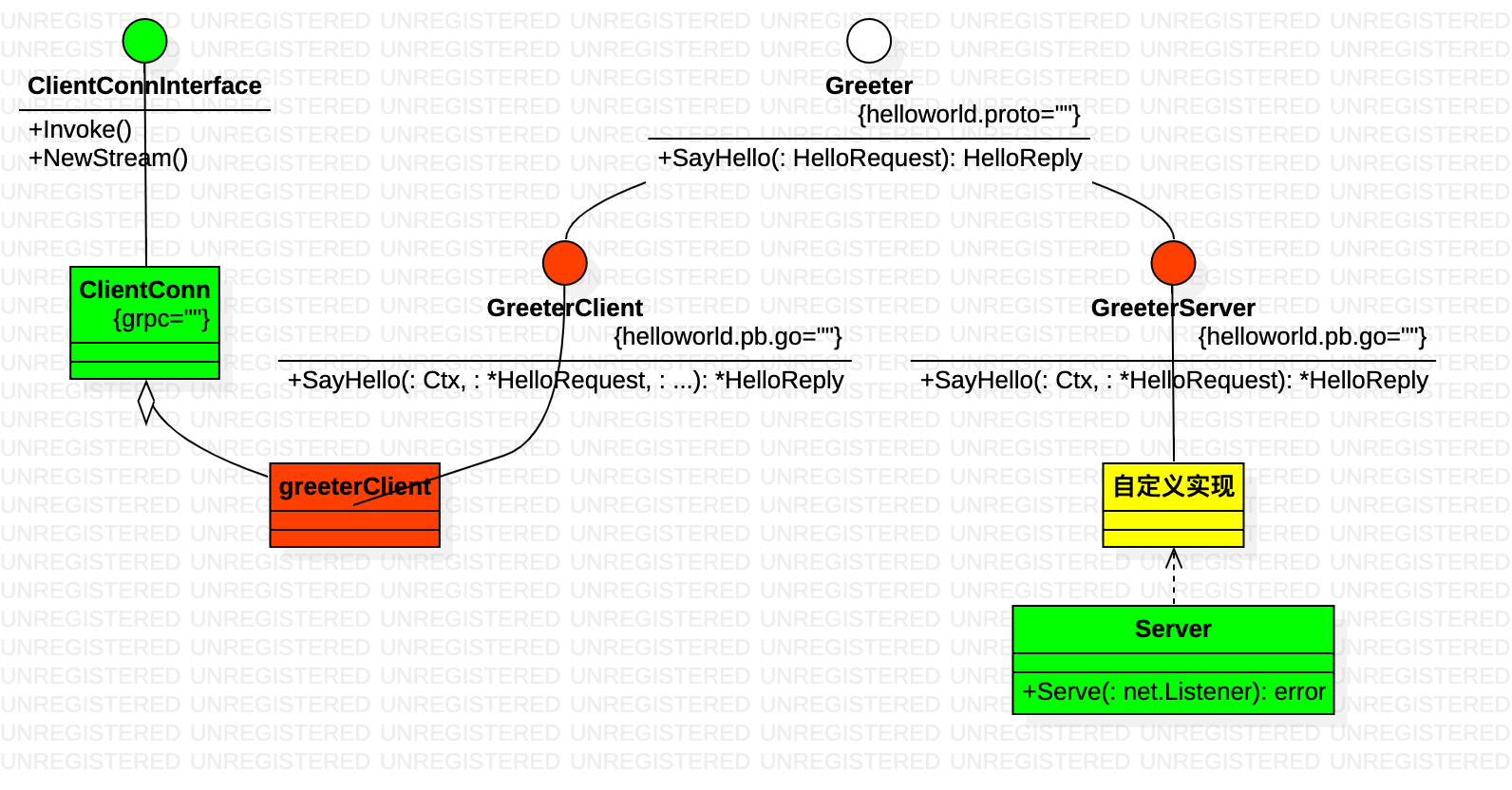
- 针对helloworld.proto 中定义的 Greeter service, gprc 生成的go 文件 helloworld.pb.go 分别定义了GreeterClient 和 GreeterServer interface。这点与thrift client和server 共用一个interface 不同。
- GreeterClient 实现类 greeterClient 聚合ClientConn ,greeterClient.SayHello ==> ClientConn.Invoke ==> ClientStream.SendMsg + ClientStream.RecvMsg。 这点与thrift client 类似,接口实现本质是 send+recv
- 服务端则是 Server.Serve 启动服务端,GreeterServer 实现类 作为业务处理逻辑在 必要时候被调用。
gRPC 框架中就没有使用动态代理,它是通过代码生成的方式生成 Service 存根,当然这个 Service 存根起到的作用和 RPC 框架中的动态代理是一样的。gRPC 框架用代码生成的 Service 存根来代替动态代理主要是为了实现多语言的客户端,因为有些语言是不支持动态代理的,比如 C++、go 等,但缺点也是显而易见的。如果你使用过 gRPC,你会发现这种代码生成 Service 存根的方式与动态代理相比还是很麻烦的,并不如动态代理的方式使用起来方便、透明。PS:待进一步理解
整体架构/分层架构
主要以客户端源码为主描述

| 接口 | 实现struct | ||
|---|---|---|---|
| 应用/治理层 | ClientConnInterface | ClientConn | ClientConn represents a virtual connection to a conceptual endpoint, to perform RPCs 负责负载均衡及路由解析 |
| Stream+协议层 | ClientStream | clientStream | 负责Stream 抽象及解压缩、协议编解码 |
| transport层 | ClientTransport | http2Client+parser | 负责收发字节数据、处理流控等http2控制逻辑 |
| tcp层 | net.Conn |
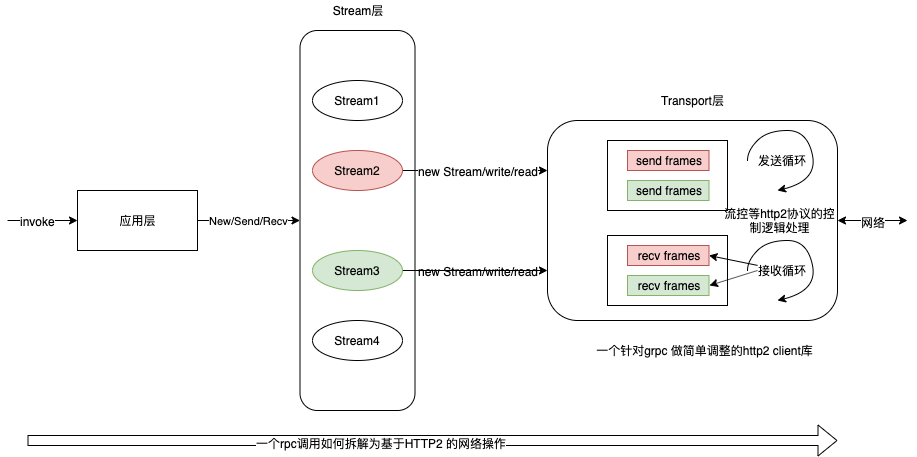
HTTP/2 传输基本单位是 Frame,Frame 格式是以固定 9 字节长度的 header,后面加上不定长的 payload 组成。gprc java 发送端的逻辑就是 将方法+参数序列化后,构造 Frame Header 和 Frame Body,然后再把构造的 Frame 发送到 NettyClientHandler,最后将 Frame 写入到 HTTP/2 Stream 中,完成请求消息的发送。
服务端流程(待具体分析)gRPC-Go服务端源码分析
应用/治理层
很多应用在最顶层封装一个 Connection 对象,但此Connection 非tcp Connection,以Java访问mysql 数据库代码为例
//加载驱动程序
Class.forName(driver);
//1.getConnection()方法,连接MySQL数据库!!
Connection con = DriverManager.getConnection(url,user,password);
//2.创建statement类对象,用来执行SQL语句!!
Statement statement = con.createStatement();
//要执行的SQL语句
String sql = "select * from student";
//3.ResultSet类,用来存放获取的结果集!!
ResultSet rs = statement.executeQuery(sql);
接口定义
type ClientConnInterface interface {
// Invoke performs a unary RPC and returns after the response is received
// into reply.
Invoke(ctx context.Context, method string, args interface{}, reply interface{}, opts ...CallOption) error
// NewStream begins a streaming RPC.
NewStream(ctx context.Context, desc *StreamDesc, method string, opts ...CallOption) (ClientStream, error)
}
ClientConn represents a virtual connection to a conceptual endpoint, to perform RPCs.
A ClientConn is free to have zero or more actual connections to the endpoint based on configuration, load, etc. It is also free to determine which actual endpoints to use and may change it every RPC, permitting client-side load balancing. A ClientConn encapsulates a range of functionality including name resolution, TCP connection establishment (with retries and backoff) and TLS handshakes. It also handles errors on established connections by re-resolving the name and reconnecting. ClientConn 除了封装 connection ,还管负载均衡、 name resolution 等
Stream+协议层
一次方法调用对应一个http2 Stream,在该层次实现 解压缩和编解码
type ClientStream interface {
Header() (metadata.MD, error)
Trailer() metadata.MD
CloseSend() error
Context() context.Context
// SendMsg is generally called by generated code.
SendMsg(m interface{}) error
RecvMsg(m interface{}) error
}
传输层
grpc源码中自己实现了http2的服务端跟客户端,并没有用net/http包
// ClientTransport is the common interface for all gRPC client-side transport implementations.
type ClientTransport interface {
Close() error
GracefulClose()
Write(s *Stream, hdr []byte, data []byte, opts *Options) error
// NewStream creates a Stream for an RPC.
NewStream(ctx context.Context, callHdr *CallHdr) (*Stream, error)
CloseStream(stream *Stream, err error)
Error() <-chan struct{}
GoAway() <-chan struct{}
GetGoAwayReason() GoAwayReason
RemoteAddr() net.Addr
IncrMsgSent()
IncrMsgRecv()
}
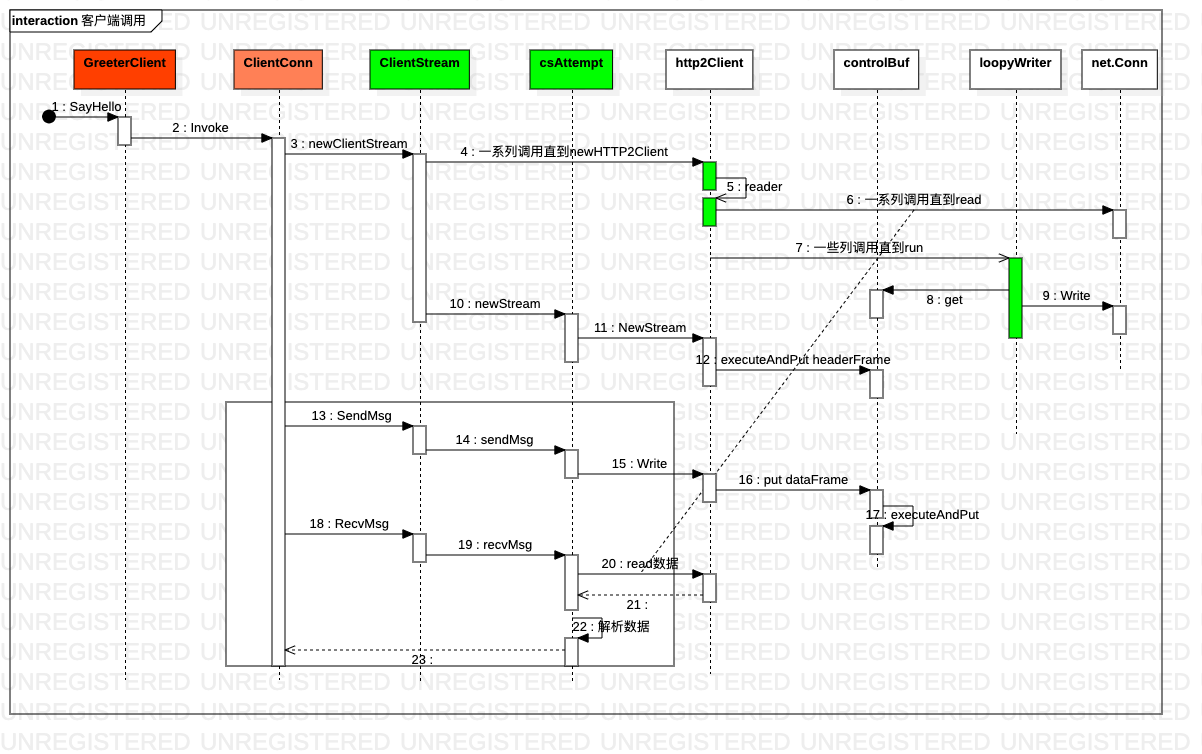
从发送流程看传输层实现
- 该层次只负责字节数组 的收发
- 传输层负责数据的收发,本身维护了类似tcp socket 的收发缓存,上游的Write和Read 本质是读写缓存,另起专门的读写 goroutine 实际负责数据的收发,在数据的收发过程中,处理http2 协议约定的控制层逻辑,比如流控等。这与tcp socket 是一样一样的
- http2 协议具有Stream 和 Frame 两层概念,每个Stream 有一个StreamId,再收到数据时, 接收goroutine 会根据数据包中的 StreamId 将Frame dispatch 到对应的Stream 数据中。
与http2 的协作
相比较于一些框架将应用层协议构建在裸 TCP 上,gRPC 选择了 HTTP/2.0 作为传输层协议。通过对 Header 内容和 Payload 格式的限定实现上层协议功能。
从实践到原理,带你参透 gRPCgrpc 基于http2 通信,便有一个grpc 数据、状态 等如何对应 到http2 上的问题 (待抓包及源码进一步深入了解)
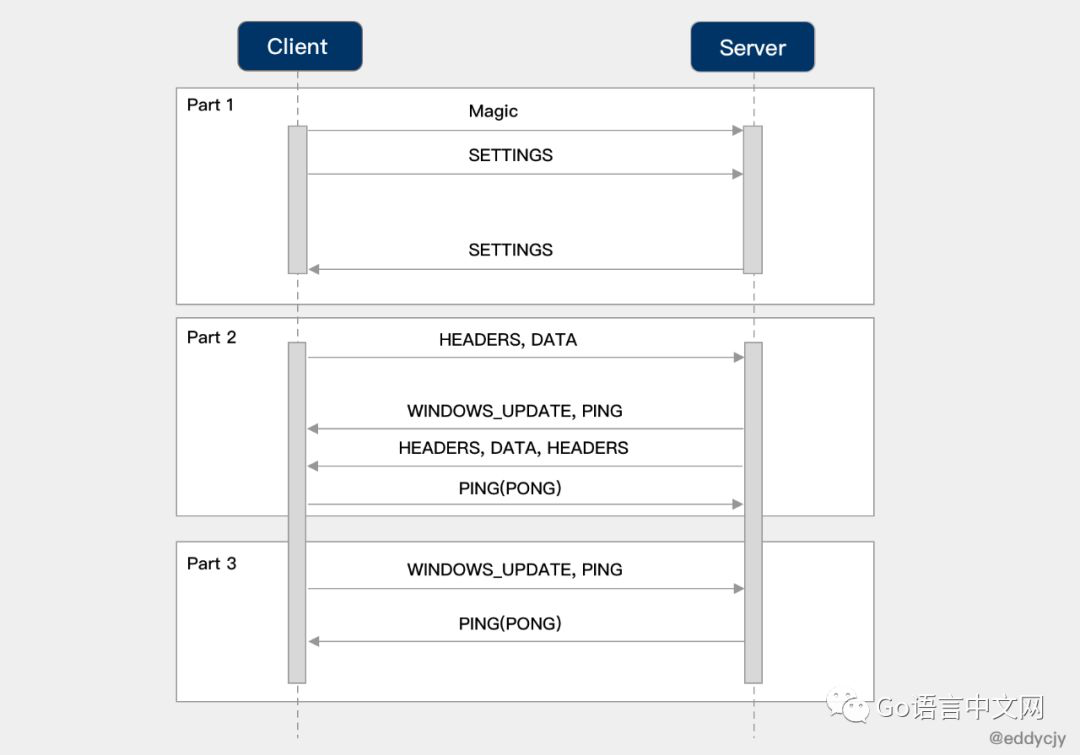
HEADERS 帧的主要作用是存储和传播 HTTP 的标头信息。 HEADERS 里有一些眼熟的信息,分别如下:
method:POST
scheme:http
path:/proto.SearchService/Search
authority::10001
content-type:application/grpc
user-agent:grpc-go/1.20.0-dev
gGRPC把元数据放到HTTP/2 Headers里,请求参数序列化之后放到 DATA frame里
为什么是http2
Introducing gRPC, a new open source HTTP/2 RPC Framework
gRPC is based on many years of experience in building distributed systems. With the new framework, we want to bring to the developer community a modern, bandwidth and CPU efficient, low latency way to create massively distributed systems that span data centers, as well as power mobile apps, real-time communications, IoT devices and APIs. 从设计的立意上,grpc 就没有仅局限于 data center 内部rpc 调用,也希望用到 mobile 和 iot 设备上,这便要求协议尽量通用,随着nginx 支持grpc,未来有机会 brower/mobile ==> nginx ==> web server ==> rpc server 全链路使用grpc 协议。又想用到实时通讯上,那么 相对普通rpc 支持 双向 stream 也就是顺理成章了。
Building on HTTP/2 standards brings many capabilities such as bidirectional streaming, flow control, header compression, multiplexing requests over a single TCP connection and more. These features save battery life and data usage on mobile while speeding up services and web applications running in the cloud.
- HTTP/2 是一个公开的、实践检验过的标准
- HTTP/2 天然支持物联网、手机、浏览器,多语言客户端实现容易,在Gateway/Proxy很容易支持
- HTTP/2支持Stream和流控,PS:考虑到对Streaming rpc 的支持,使用http2 就更自然了,Stream RPC 参见下文
- HTTP/2 安全性有保证,HTTP/2 鉴权成熟
缺点呢?
- RPC 的元数据的传输不够高效
- HTTP/2 标准本身是只有一个 TCP 连接,但是实际在 gRPC 里是会有多个 TCP 连接
- gRPC 选择基于 HTTP/2,那么它的性能肯定不会是最顶尖的。但是对于 gRPC 来说中庸的 QPS 可以接受,通用和兼容性才是最重要的事情。
为什么很多rpc 框架喜欢 直接用tcp
http 和 tcp 是传输协议,rpc 相对于传输协议,更多的是封装了“服务发现”,”负载均衡”,“熔断降级”一类面向服务的高级特性。使用http 作为传输层协议 倒也不少见,比如 Spring Cloud REST 风格直接把 HTTP 作为应用协议。
以http1.1 为例,建连开销可以使用连接池复用解决,http 协议也可以传输二进制数据。为什么很多rpc 框架喜欢 直接用tcp 作为传输协议?通用定义的http1.1协议的tcp报文包含太多废信息,一个POST协议的格式大致如下
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
<html>
<body>Hello World</body>
</html>
报文元数据也就是header头的键值对却用了文本编码,非常占字节数。假如我们使用自定义tcp协议的报文如下
| 1->4 byte | 5->8 byte | 9->16 byte | 17->length+16 byte |
|---|---|---|---|
| length(int) | type int | package_id(long) | package_data |
报头占用的字节数也就只有16个byte,极大地精简了传输内容。http2.0协议已经优化编码效率问题。
注册中心(待补充)
gRPC 注册中心,常用的注册中心你懂了?AP 还是 CP (七)
Streaming rpc
grpc 调用方式分为四种:
- Unary RPC 一元RPC
- Server-side streaming RPC 服务端流式RPC
- Client-side streaming RPC 客户端流式RPC
- Bidirectional streaming RPC 双向流式RPC
为什么需要流式 rpc
以Server-side streaming RPC 为例,改写helloworld.proto
syntax = "proto3";
package helloworld;
// The greeting service definition.
service Greeter {
// 为HelloReply 加上stream 标识
rpc SayHello (HelloRequest) returns (stream HelloReply) {}
}
// The request message containing the user's name.
message HelloRequest {
string name = 1;
}
// The response message containing the greetings
message HelloReply {
string message = 1;
}
server.go
type GrpcServerDemo struct {
}
func (*GrpcServerDemo) SayHello(req *HelloRequest, stream Greeter_SayHelloServer) error {
// stream.Send 可以发送任意多次
stream.Send(&HelloReply{
Message: fmt.Sprintf("Hello1: %s", req.Name),
})
stream.Send(&HelloReply{
Message: fmt.Sprintf("Hello2: %s", req.Name),
})
return nil
}
func Server() {
// 代码与前文无变化
}
client.go
func Client() {
conn, _ := grpc.Dial("127.0.0.1:8080", grpc.WithInsecure())
defer conn.Close()
cli := NewGreeterClient(conn)
stream, _ := cli.SayHello(context.Background(), &HelloRequest{Name: "zhangsan"})
// stream.Recv 发送次数与 服务端stream.Send 次数一致即可
resp1, _ := stream.Recv()
fmt.Println(resp1.Message)
resp2, _ := stream.Recv()
fmt.Println(resp2.Message)
}
流式为什么要存在呢,是 Simple RPC 有什么问题吗?通过模拟业务场景,可得知在使用 Simple RPC 时,有如下问题:
- 数据包过大造成的瞬时压力
- 以服务端处理为例,接收数据包时,需要所有数据包都接收成功且正确后,才能够回调业务逻辑函数,进行业务处理(无法客户端边发送,服务端边处理)
为什么用 Streaming RPC
- 大规模数据包
- 实时场景
Stream 层
对于simple rpc 来说, 以客户端逻辑为例:一般方法调用 ==> 负载均衡/路由策略等治理逻辑 ==> 协议层 ==> 传输层。具体的说,就是将请求数据(方法 + 请求参数) 序列化之后 发出去,收到响应之后 反序列化为响应对象,请求对象和响应对象 通过唯一id 关联起来,一次方法调用对应一个<请求对象, 响应对象>。
有了Streaming rpc 之后, 一次方法调用 涉及到多个<请求对象, 响应对象>,或者说, 请求对象和响应对象变成了Stream 对象,可多次Send 和 Recv。 序列化和反序列化 层复用原先逻辑,额外抽取一个Stream 层,一次方法调用 对应一个StreamId,一个StreamId 对应多个<请求对象, 响应对象>。
留下评论