TIDB 学习
前言
源码TiDB (“Ti” stands for Titanium) is an open-source NewSQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability. TiDB 源码阅读系列文章(一)序
Ti表示Titanium钛
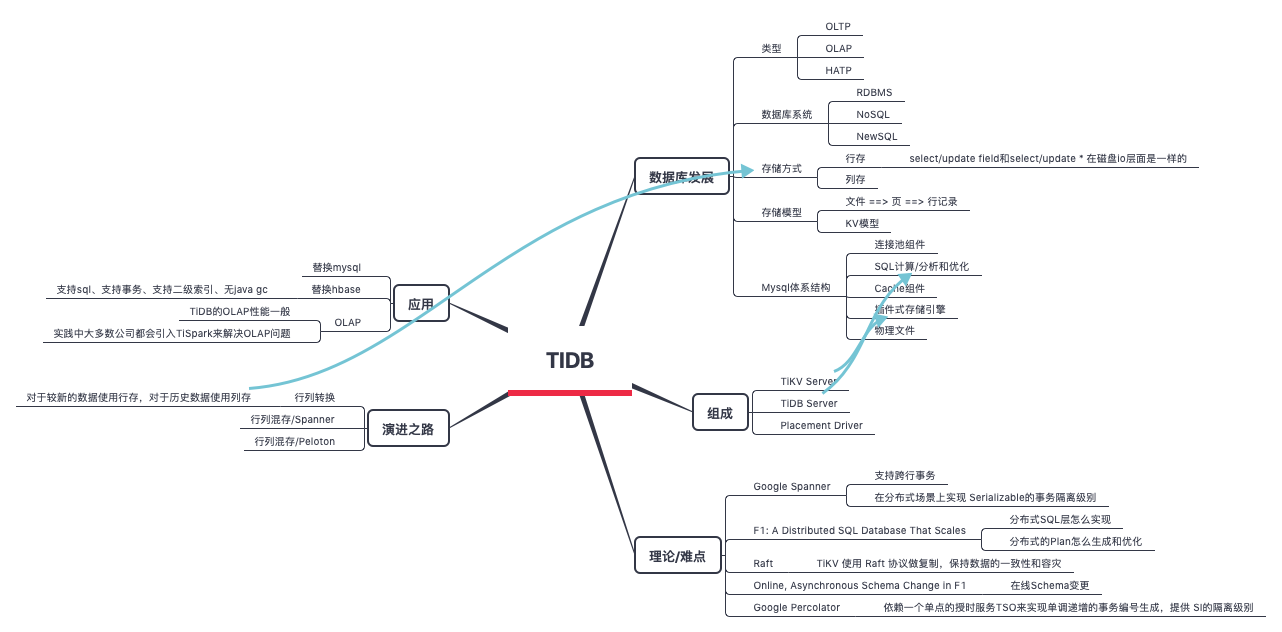
从TIDB 可以学习一个复杂的事情,如何分散到各层去解决。
- 假设我需要做一个高性能,支持亚毫秒低延迟读写的 User Profile 系统,数据量不大,可以容忍数据丢失,那我就用 Redis 好了!但是作为 Redis 的产品经理来说,ta 很难为了 User Profile 这个很特化的场景去设计 Redis 的功能。很多业务需要的「特性」是需要多个「技术点」组合出来的,或者通过引导到正确的问题从而提供更好的解决方案。优秀的基础软件产品经理通常会选择通用的技能点,用尽可能小的功能集合来包含更大的可能性。
- 我们的经常被用户问到:TiDB 有没有多租户功能?这个问题的我的回复并不是简单的「有」或者「没有」,而是会去挖掘用户真正想要解决的问题是什么?
- 「每个业务都部署一套 TiDB,太贵了」,价值点:节约成本;
- 我确实有好多套业务使用 TiDB, 对我来说机器成本不是问题,但是配置管理太麻烦,还要挨个升级,监控什么的还不能复用」,价值点:降低运维复杂度;
- 「我有些场景特别重要,有些场景没那么重要,需要区别对待,对于不重要的我要共享,但是对于重要的要能隔离」,价值点:资源隔离+统一管控;
- 「我有监管要求,例如不同租户的加密和审计」,价值点:合规
- 有一些功能和其它功能不一样,这类功能可以作为构建其它功能的基础,组合出新的特性。这类功能我称之为:Meta Feature,上面提到的 Placement Rule 就是一个很典型的 Meta Feature, 例如:Placment Rule + Follower Read 可以组合成接近传统意义上的数据库一写多读(但是更灵活,更加细粒度,特别适合临时性的捞数或者做临时的查询,保证数据新鲜的情况下,不影响在线业务),Placement Rule + 用户自定义的权限系统 = 支持物理隔离多租户;Placement Rule + Local Transaction + 跨中心部属 = 异地多活(WIP);Placement Rule 还可以将精心设施数据的放置策略,让 TiDB 避免分布式事务(模拟分库分表),提升 OLTP 性能。
- 一来一回异步又低效的问题诊断是很大的痛苦的来源,以及 oncall 没办法 scale 的核心原因之一。对于用户来说,只需要在集群内执行 一个简单的命令,就会生成上面这样的一个链接,把重要的诊断信息与 PingCAP 的专业服务支持人员共享。 TiDB Clinic 是对于基础软件的维护性的一个新尝试:诊断能力的 SaaS 化,通过一个在云端不断强化的规则引擎,将故障的诊断和修复建议和本地的运维部署结耦。
基本理念
势高,则围广:TiDB 的架构演进哲学适合没事读一读
- 说到哲学,一定要有信念。人类对于未知的东西很难做一个很精确的推导,这时信念就变得非常重要了
- 相信云是未来,全面拥抱Kubernetes
- 不依赖特定硬件,不依赖特定云厂商
- 支持多种计算单元, X86,AMD64,ARM,MIPS,GPU
- 最初 TiDB 就决定是分层的,一层是 SQL 层,一层是 key-value 层,那么到底先从哪一个层开始写呢?软件开发领域有一条非常经典的哲学:「Make it work, make it right, make it fast」。所以当时我们就做另外一个决定,先在已有的 KV 上面构建出一个原形,用最短的时间让整个系统能够先能 work。
-
面对这么多的需求,我们考虑了两个点:
- 哪些是共性需求?
- 什么是彻底解决之道?
- 产品的广泛程度会决定产品最终的价值。早期坚定不移的往通用性上面走,有利于尽早感知整个系统是否有结构性缺陷,验证自己对用户需求的理解是否具有足够的广度。在拥有行业复制能力的之后,在产品层面我们要开始向着更高的性能、更低的延迟、更多 Cloud 支持(不管是公有云还是私有云都可以很好的使用 TiDB)等方向纵向发展。
- 如果要修建五百层的摩天大楼,要做的不是搭完一层、装修一层,马上给第一层做营业,再去搭第二层。而一定要先把五百层的架构搭好,然后想装修哪一层都可以
- 当时我们正准备创业,意气风发发了一条这样微博。这一堆话其实不重要,大家看一下阅读量 47.3 万,有 101 条转发,44 条评论,然而我一封简历都没收到。想想当时我也挺绝望的,想着应该还有不少人血气方刚,还有很多技术人员是有非常强大的理想的,但是前面我也说了,总有一个从理想到现实的距离,这个距离很长,好在现在我们能收到很多简历。所以很多时候大家也很难想象我们刚开始做这件事情的时候有多么的困难,以及中间的每一个坚持。只要稍微有一丁点的松懈,就可能走了另外一条更容易走的路,但是那条更容易走的路,从长远上看是一条更加困难的路,甚至是一条没有出路的路。
- 所有计算机科学里面的问题都可以把它不停地抽象,抽象到另外一个层次上去解决。
- 我们在做技术选型的时候,如果在有很大自由度的前提下,怎么去控制发挥欲望和膨胀的野心?你的敌人并不是预算,而是复杂度。 这一点跟 《从0开始学架构》笔记 异曲同工。
- 你怎么控制每一层的复杂度是非常重要的,特别是对于一个架构师来说,所有的工作都是在去规避复杂度,提升开发效率和稳定性。
- 我仔细看过 Etcd 的源码,每个状态的切换都抽象成接口,我们测试是可以脱离整个网络、脱离整个 IO、脱离整个硬件的环境去构建的。我觉得这个思路非常赞
- 对架构师而言一个很重要的工作就是查看系统中有哪些 block 的点,挨个解决掉这些问题。所有的东西,只要有 Metrices,能被监控,这个东西就能被解决。
十问 TiDB :关于架构设计的一些思考这个世界有很多人,感觉大于思想,疑问多于答案。
SQL存储易变,SQL协议长存
笔者在学习Redis时,看到Redis 通信协议,除了Redis 一些基于磁盘的KV 存储也在使用Redis 协议与客户端交互,比如Qihoo360/pika,一个大牛提到:Redis 后端易变,Redis协议/规范长存。
相比Redis规范,SQL 则更是老当益壮的典范,早就超脱了RDBMS的范畴
- RDBMS,用SQL 表达对磁盘的存取逻辑
- Hive, 用SQL 编写逻辑来代替 mapreduce, 读取 hdfs 文件
- Spark SQL,用SQL 编写逻辑来表达spark 计算,进行大数据计算
- 用SQL 编写逻辑来表达flink 计算,进行实时计算
- 业界的一些通用平台,用SQL来表达逻辑,进行跨hdfs、mysql等多存储系统的 计算
- TiDB,用SQL 表达对TiKV的存取逻辑
这些系统的通用架构 都是
- 接口层
- SQL 解释层,将SQL 转换为对应底层系统的逻辑计算
- 系统本身的逻辑 + 存储层
整体设计
HTAP
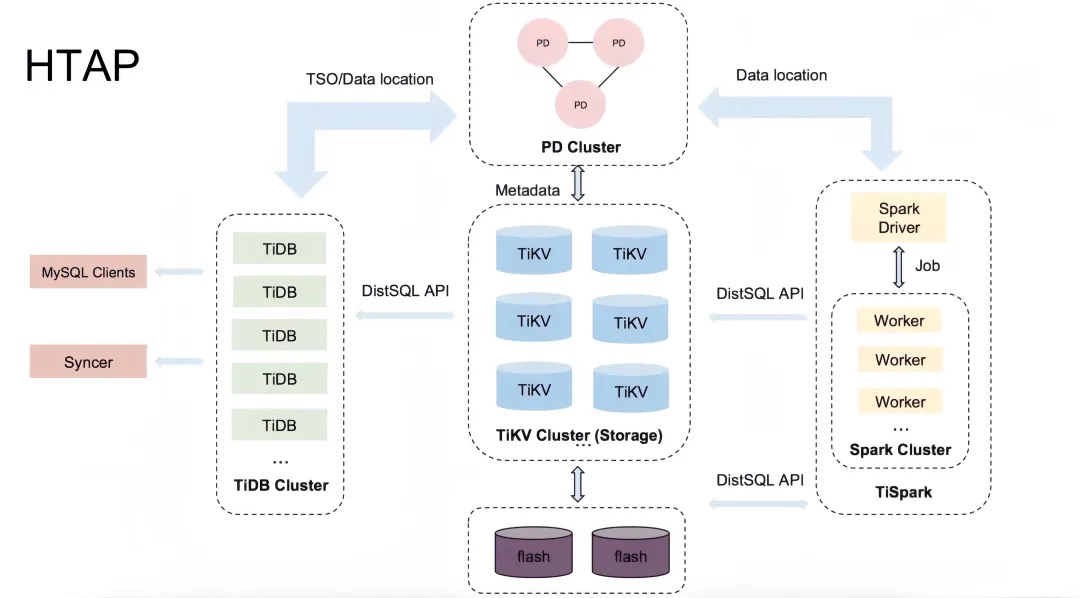
计算引擎层
- TiDB:作为 OLTP 计算引擎,负责处理事务性工作负载,对外提供 MySQL 协议接口,实现 SQL 解析、优化并生成分布式执行计划。TiDB 服务器无状态,易于横向扩展,通过负载均衡器均衡客户端连接,但本身不存储数据,而是将数据操作请求转发给 TiKV。
- TiSpark:集成 Apache Spark,专为复杂的 OLAP 查询设计,直接在 TiKV 数据上运行 Spark SQL 作业,实现大数据分析能力,与大数据生态无缝对接。TiSpark 与 TiFlash 结合,增强了 TiDB 在数据分析领域的表现。 存储引擎层
- TiKV:负责存储行格式数据,支撑 OLTP 业务,是一个分布式、事务性的键值存储系统。数据被切分为多个 Region,每个 Region由多个 TiKV 节点复制存储,确保高可用性和数据一致性。TiKV 支持事务隔离级别,是 TiDB 处理 SQL 查询的底层存储。
- TiFlash:针对 OLAP 场景设计,采用列式存储优化分析查询性能。TiFlash 能够近乎实时地复制 TiKV 中的数据,保持数据一致性的同时,提供高效分析查询能力。它兼容 TiDB 和 TiSpark,分别适用于不同规模的分析需求,与 ClickHouse 的高效分析技术相融合,提升了 TiDB 的分析处理能力。 分布式协调层
- PD(Placement Driver):作为整个集群的元数据管理和调度中心,存储集群拓扑信息及数据分布状态,控制数据的自动均衡与故障恢复,分配事务ID,是集群的控制大脑。PD 集群通常由三个或以上节点构成,确保高可用性。
OLTP
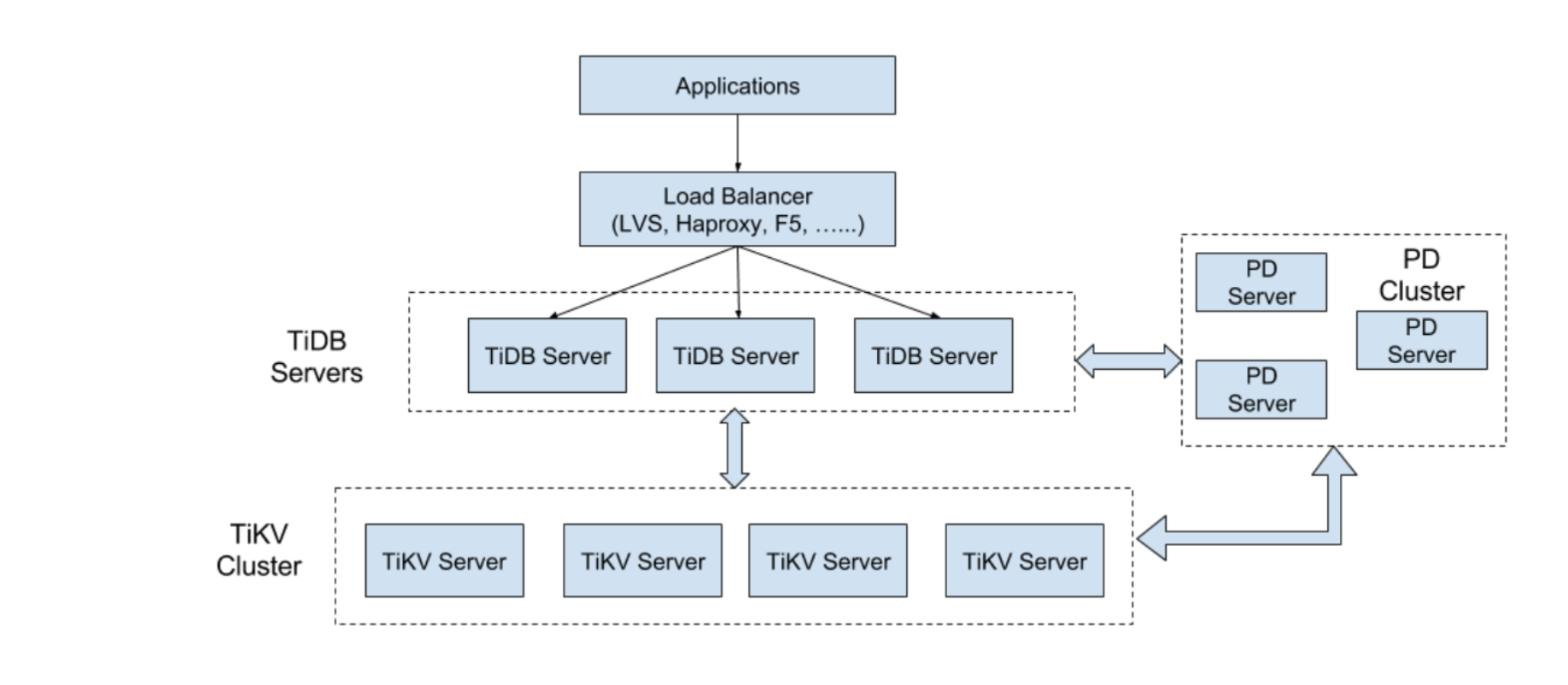
从下往上看
- TiKV Server, pingcap 将其独立的作为 一个源码库 tikv/tikv,TiKV 是一个支持事务的、分布式、Key-Value、存储引擎。如果不考虑Region复制,一致性,和事务的话,TiKV其实和HBase很像,底层数据结构都是LSM-Tree, Region都是Range分区, Region都是计算和负载均衡的基本单位。详情参见TIDB存储——TIKV
- TiDB Server 负责接收 SQL 请求,生成SQL的逻辑计划和物理计划,并通过 PD 找到存储计算所需数据的 TiKV 地址,将SQL转换为TiKV的KV操作,与 TiKV 交互获取数据,最终返回结果。TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展。
-
Placement Driver 主要有以下职责:
- 集群的元信息 (某个 Key 存储在哪个 TiKV 节点)
- TiKV 集群进行调度和负载均衡
- 分配全局唯一且递增的事务 ID
SQL 层
关系模型到 Key-Value 模型的映射
SQL 和 KV 结构之间存在巨大的区别,那么如何能够方便高效地进行映射,就成为一个很重要的问题。一个好的映射方案必须有利于对数据操作的需求。
TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(如果表有整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID)
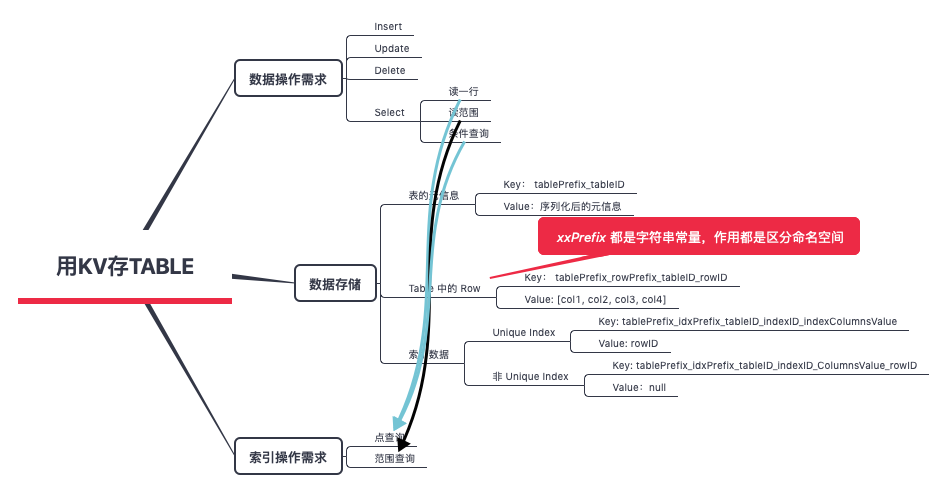
以下标为例
CREATE TABLE User {
ID int,
Name varchar(20),
Role varchar(20),
Age int,
PRIMARY KEY (ID),
Key idxAge (age)
};
假设有3条记录
1, "TiDB", "SQL Layer", 10
2, "TiKV", "KV Engine", 20
3, "PD", "Manager", 30
假设这个表的 Table ID 为 10,因为有一个 Int 类型的 Primary Key,所以 RowID 的值即为这个 Primary Key 的值,row的数据为
t_r_10_1 --> ["TiDB", "SQL Layer", 10]
t_r_10_2 --> ["TiKV", "KV Engine", 20]
t_r_10_3 --> ["PD", "Manager", 30]
假设这个 Index 的 ID 为 1,则其数据为:
t_i_10_1_10_1 —> null
t_i_10_1_20_2 --> null
t_i_10_1_30_3 --> null
SQL 运算,分布式 SQL 运算
将 SQL 查询映射为对 KV 的查询,再通过 KV 接口获取对应的数据,最后执行各种计算。比如select count(*) from user where name = "TIDB"(没有对name建索引)
- 构造出 Key Range:一个表中所有的 RowID 都在
[0, MaxInt64)这个范围内,那么我们用 0 和 MaxInt64 根据 Row 的 Key 编码规则,就能构造出一个[StartKey, EndKey)的左闭右开区间 - 扫描 Key Range:根据上面构造出的 Key Range,读取 TiKV 中的数据
- 过滤数据:对于读到的每一行数据,计算 name=”TiDB” 这个表达式,如果为真,则向上返回这一行,否则丢弃这一行数据
- 计算 Count:对符合要求的每一行,累计到 Count 值上面
这个方案肯定是可以 Work的,缺陷也是显而易见的
- 将计算尽量靠近存储节点,以避免大量的 RPC 调用
- 需要将 Filter 也下推到存储节点进行计算,这样只需要返回有效的行,避免无意义的网络传输
- 将聚合函数、GroupBy 也下推到存储节点,进行预聚合,每个节点只需要返回一个 Count 值即可,再由 tidb-server 将 Count 值 Sum 起来
恍惚之间,有一个mapreduce 逻辑下发到 slave节点执行的感觉,运算跟着数据走,将一个集中式运算 转换一个 集中协调 + 并行计算的逻辑。
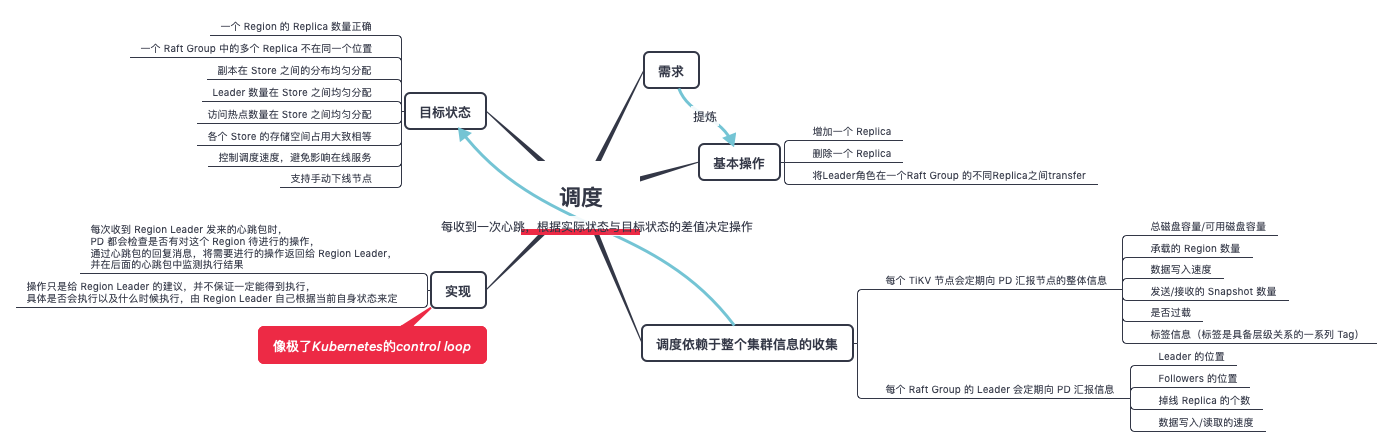
调度
三篇文章了解 TiDB 技术内幕 —— 谈调度 文章适宜精读,仔细品味一个复杂的需求如何抽丝剥茧、条缕清晰的
留下评论