dddfirework源码分析
简介
ddd这么多年一直曲高和寡的一部分原因是,在代码层面缺少框架支持,用户从0到1使用ddd从概念理解上和代码实现上都成本非常大,给人带来的困惑、给团队带来的争论相比便利来说一点都不少,这点相对“声明式API + 控制器模型”之于kubebuilder/controller-runtime 都差距很大。既提供了大量辅助代码(比如client、workqueue等)、自动生成代码(比如clientset)以减少代码量,又显式定义了实现规范(比如crd包含spec和status)和约束(实现reconcile等)。所以落地声明式api 大家会有更多细节上的直观感受。
dddfirework 是一个支持 DDD (领域驱动设计)实现的引擎框架,他提供对领域实体从创建,修改,持久化,发送事件,事件监听等完整生命周期的封装,以及锁,数据库,事件总线等组件的集成。笔者有幸参与贡献了一部分源码。
缘起
- 从概念开始理解DDD,涉及到聚合根、领域对象、领域服务、领域事件、仓储、贫血充血模型、界限上下文、通用语言
- 从分层开始理解DDD,
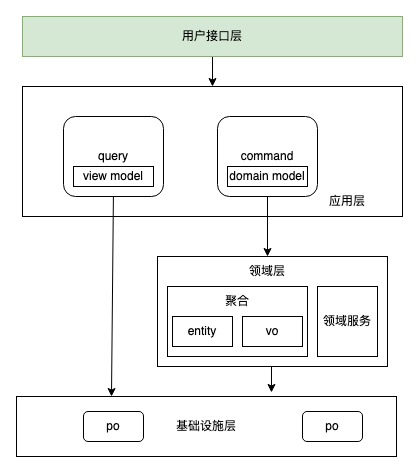
- 用户接口层/Presentation。一般是http handler 或rpc handler
- 应用层,定义软件要完成的任务,并且指挥表达领域概念的对象来解决问题。应用层是很薄的一层,包含业务规则,只为下一层中的领域对象协调任务,分配工作。通过直接持有领域层的聚合根,infra层等直接进行业务表达。
- 领域层。负责表达业务概念,业务状态信息以及业务规则。尽管保存业务状态的技术细节由基础设施层提供,但反应业务情况的状态是由本层控制并使用的。
- 基础设施层。为上面各层提供通用的技术能力:为应用层传递消息,为领域层提供持久化机制等。
- 从CQRS命令查询职责分离的角度看DDD,主要是读写分离,将没有领域模型的查询功能,从命令中分离出来。
比如以http handler作为ddd逻辑的入口,对于cqrs command 操作来说,一般会有以下逻辑
1. 构建domain 对象
2. 触发domain 对象执行业务方法,domain.bizfunc()
3. 持久化domain对象
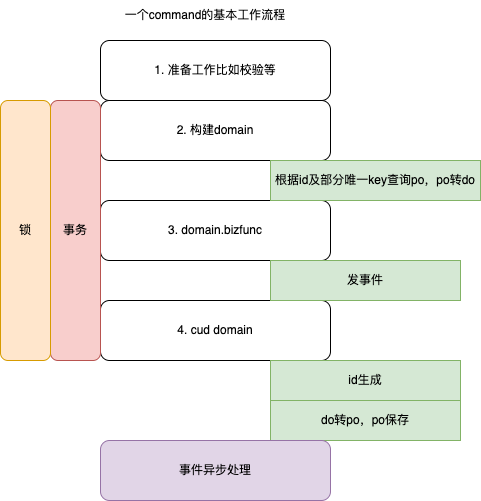
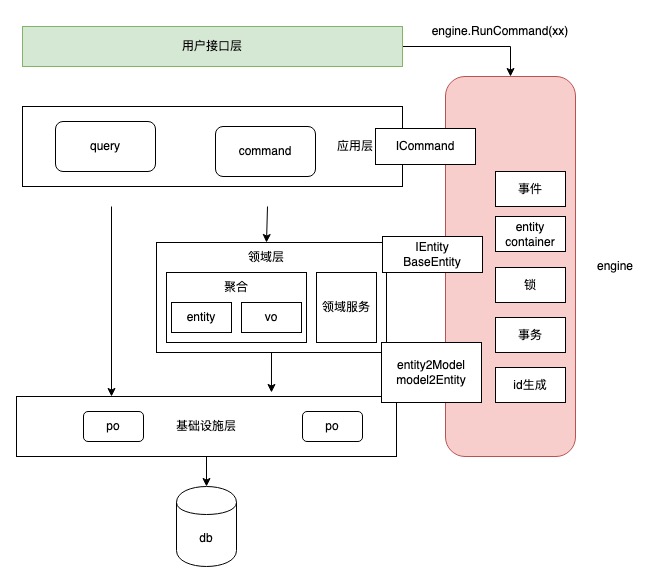
以上是构建一个cqrs command 的基本动作,我们对其提取一个ICommand。整个ddd引擎抽象为一个engine/bootstrap。则engine 的核心工作即为驱动ICommand执行,ICommand 的操作对象是实体,抽象为IEntity,IEntity 的读取和存储离不开PO。 所以我们可以说 一个ddd+cqrs 框架包含 engine、ICommand、IEntity、PO 等核心概念,它们的各层的体现如下:
- 用户接口层
- 构建engine,触发comamnd执行。 engine.runCommand(xxCommand{param})
- 应用层
- 定义command接口规范 ICommand,负责实现cqrs command三个基本逻辑:构建domain 对象、触发domain 对象、持久化domain对象。
- domain层
- Entity规范,比如IEntity,每个entity均需实现IEntity,以约束其提供GetID等实现。
- 提一个container的概念,作为domian在内存中的容器,维护root entity 与entity的关系。 domain.bizfunc 会改动内存,engine 将domain 持久化到db。
- infra层
- domain model基于id的crud
- domain model/entity与po的转换
- 其它/非业务特性,一个复杂的业务系统不仅有数据的crud。
- 事件机制,entity变更时对外发出通知,可以减少domain.bizFunc 中关于非核心域的代码
- 事务,一个聚合包含多个entity,持久化时保持一致性
- 锁机制,在操作一个entity的时候,不允许其他线程操作entity,以免破坏一致性
- 定时任务
实现
核心组件
核心逻辑是 new Engine().Run(xxxCommand()),创建engine 对象并执行command。其成员主要分为两个部分
- 驱动command 执行的,比如IExecutor 和 IDGenerator。IExecutor 主要负责 Entity和 po的转换
- 涉及到旁路系统能力,比如ILock/IEventBus
type Engine struct {
executor IExecutor // 驱动db的crud,以及po与Entity的转换
idGenerator IIDGenerator // id生成器,每个domain/Entity 都应具有一个唯一id
locker ILock // 支持锁机制
eventbus IEventBus // 支持异步event机制
timer ITimer // 支持定时任务
logger logr.Logger
options Options
}
一次 new Engine().Run(xxxCommand()) 的执行会产生许多临时数据,这些临时数据 如果作为Engine的成员,engine并发执行是会有问题,因此提取了一个 Stage 对象,其成员主要分为两个部分
- 能力对象,比如ILock和IEventBus 等。
- 运行时产生的临时数据,比如meta/snapshot,Stage的各个方法传递信息靠的就是共享Stage 这些临时成员
// Stage 取舞台的意思,表示单次运行
type Stage struct {
lockKeys []string
main MainFunc
locker ILock
executor IExecutor
eventBus IEventBus
timer ITimer
idGenerator IIDGenerator
logger logr.Logger
options Options
// 临时数据
meta *EntityContainer
snapshot entitySnapshotPool
result *Result
eventCtx context.Context
}
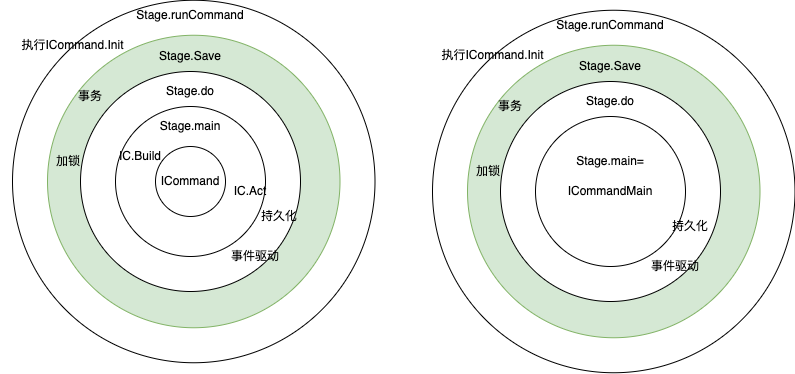
cqrs command的基本步骤与ICommand对应关系:构建domain对应ICommand.Build,触发domain.bizfunc 对应ICommand.Act。
// 通用command 接口
// 将command的基本动作: 构建domain;domain.bizFunc; 保存domain 通过接口的形式固化下来
type ICommand interface{
// Init 会在锁和事务之前执行,可进行数据校验,前置准备工作,可选返回锁ID
Init(ctx context.Context) (lockKeys []string, err error)
// Build 构建并返回聚合根实体,框架会为返回值自动生成快照,作为持久化比对的依据
// 注意,Create 的情况不需要在 Build 方法返回
Build(ctx context.Context, builder DomainBuilder) (roots []IEntity, err error)
// Act 调用实体行为
Act(ctx context.Context, container RootContainer, roots ...IEntity) (err error)
}
ICommand.Act 会带来domain 内存数据的变动,Stage通过对比meta 与snapshot 的差异,将domain diff转为po变化,并持久化到db。
ICommand 可以满足大部分场景,但只能在其Init/Build/Act写逻辑,开发比较难干预engine的执行(或者说ICommand 暴露的engine 细节太少),进而无法实现一些个性化场景。比如开发在 ICommand.Act 只能触发domain的内存改动,如果希望持久化立即生效且拿到生效后的一些数据的话,则无能为力。为此dddfirework还提供了一个ICommandMain 抽象,实质是 ICommandMain.Main 有Repository 参数,你可以拿来干很多事儿,但domain的获取必须通过 Repository,这样Stage可以保持对 domain的跟踪。
type ICommandMain interface {
Main(ctx context.Context, repo *Repository) (err error)
}
驱动逻辑
每次RunCommand 都会新建一个Stage ,持有 meta:*EntityContainer 和 snapshot:map[IEntity]*entitySnapshot{}(snapshot 暂存Act 之前的meta )。engine/Stage 执行过程中,随着domain.bizfunc 的执行涉及到domain对象成员数据的改变,stage.snapshot用来记录快照的。
func (e *Engine) RunCommand(ctx context.Context, c ICommand, opts ...Option) *Result {
return e.NewStage().WithOption(opts...).RunCommand(ctx, c)
}
func (e *Stage) RunCommand(ctx context.Context, c ICommand) *Result {
return e.Run(ctx, c)
}
func (e *Stage) Run(ctx context.Context, cmd interface{}) *Result {
...
var keys []string
var options []Option
if cmdInit, ok := cmd.(ICommandInit); ok {
initKeys, err := cmdInit.Init(ctx)
if err != nil {
return ResultErrOrBreak(err)
}
keys = initKeys
}
if cmdPostSave, ok := cmd.(ICommandPostSave); ok {
options = append(options, PostSaveOption(cmdPostSave.PostSave))
}
return e.WithOption(options...).Lock(keys...).Main(c.Main).Save(ctx)
...
}
Stage 中的WithOption/Lock/Main 方法都只是“赋值”方法,将参数或函数赋给内部的成员,Stage.Save 触发了最后逻辑的执行。 就好比spark rdd的api 分为transformer 和 action api两种,只有action api 才会真正触发执行。
func (e *Stage) do(ctx context.Context) *Result {
// 创建聚合
var err error
if e.main != nil {
repo := &Repository{stage: e}
if err := e.main(ctx, repo); err != nil {
return ResultErrOrBreak(err)
}
if err := repo.getError(); err != nil {
return ResultError(err)
}
}
err = e.persist(ctx)
if err != nil {
return ResultErrors(err)
}
events := e.collectEvents()
if len(events) > 0 && e.options.EventPersist != nil {
action, err := e.makeEventPersistAction(events)
if err != nil {
return ResultErrors(err)
}
if err := e.exec(ctx, []*Action{action}); err != nil {
return ResultError(err)
}
}
// 发送领域事件
if len(events) > 0 {
if e.eventBus == nil {
return ResultErrors(ErrNoEventBusFound)
}
if err := e.dispatchEvents(ctx, events); err != nil {
return ResultErrors(err)
}
}
return e.result
}
持久化
持久化的核心 是Stage.meta和 Stage.snapshot,在构建domain时,domain 会记录在Stage.meta 以及Stage.snapshot中,之后ICommand.Act 会触发domain.bizfunc 即domain 数据的改变,此时Stage.meta 持有最新的domain 数据,Stage.snapshot 持有ICommand.Act 之前的domain 数据,之后便是计算domain 粒度的diff:domain新增、删除很直接;domain有更新则依靠用户主动调用 IEntity.Dirty来标记。
// Stage 取舞台的意思,表示单次运行
type Stage struct {
// 临时数据
meta *EntityContainer
snapshot entitySnapshotPool
result *Result
eventCtx context.Context
}
type EntityContainer struct {
BaseEntity
roots []IEntity // 保存聚合根实体
deleted []IEntity // 保存所有被删除实体
}
得到domain 的diff 之后,如何将domain的diff 保存的db里?以cqrs来看,复杂的查询主要发生在Query,Command 会用到一些查询,但不会很复杂,集中在根据id的获取。每一个domain/entity 都会有一个唯一id,每个domain 会在db里对应一个多个po/表,除了domain 与po 的转换逻辑之外,Command 场景下 po的crud 可以由一个组件统一负责,即IExecutor。
- 对于新增的 domain,将其转为po/IModel 之后,insert
- 对于删除的 domain,将其转为po/IModel 之后(实际不用转,只有id即可),delete
- 对于更新的 domain,将其转为po/IModel 之后,与之前po/IModel 计算diff,得出要update的fields,
gormdb.Select(fields).Updates(model)即可。type IExecutor interface { ITransaction IConverter Exec(ctx context.Context, actions *Action) error } type Action struct { Op OpType Models []IModel // 当前待操作模型,stage 确保一个 Action 下都是同类的模型 PrevModels []IModel // 基于快照生成的模型,跟 Models 一一对应,Executor 需要对两者做差异比对后更新 Query IModel // 指定查询字段的数据模型 QueryResult interface{} // Model 的 slice 的指针,形如 *[]ExampleModel }
留下评论