go interface及反射
前言
interface,接口,restful接口,SQL 也是一种接口
从编码的角度看:Interfaces give programs structure. Interfaces encourage design by composition. You must do your best to understand what could change and use interfaces to decouple.
如何让 Go 反射变快 未读
Go 自定义类型系统
struct
我们编写程序的目的就是与真实世界交互,解决真实世界的问题,帮助真实世界提高运行效率与改善运行质量。所以我们就需要对真实世界事物体的重要属性进行提炼,并映射到程序世界中,这就是所谓的对真实世界的抽象。不同的数据类型具有不同的抽象能力,比如整数类型 int 可以用来抽象一个真实世界物体的长度,string 类型可以用来抽象真实世界物体的名字,等等。但是光有这些类型的抽象能力还不够,我们还缺少一种通用的、对实体对象进行聚合抽象的能力。你可以回想一下,我们目前可以用学过的各种类型抽象出书名、书的页数以及书的索引,但有没有一种类型,可以抽象出聚合了上述属性的“书”这个实体对象呢?有的。在 Go 中,提供这种聚合抽象能力的类型是结构体类型,也就是 struct。
结构体类型 在内存中布局是非常紧凑的,Go 为它分配的内存都用来存储字段了,没有被 Go 编译器插入的额外字段。但结构体字段实际上可能并不是紧密相连的,中间可能存在“缝隙”,是内存对齐的要求 Go 编译器插入的“填充物(Padding)。为什么会出现内存对齐的要求呢?这是出于对处理器存取数据效率的考虑。
interface
深度解密Go语言之关于 interface 的 10 个问题
一个语言的类型系统 经常需要 一个“地位超然”的类型,可以表示任何类型,比如void* 或者 Object, 但真正在使用这个 类型的变量时,需要判断其真实类型,在类型转换后才能使用,所以会有类型断言的需求。
func xx(p interface){
if v,ok := p.(string);ok{
xxx
}
switch v:=p.(type){
case int:
case string:
}
}
类型嵌入
类型嵌入的本质,就是嵌入类型的方法集合并入到新接口类型的方法集合中,并且,接口类型只能嵌入接口类型。可以是任意自定义类型或接口类型。结构体类型可以嵌入任意自定义类型或接口类型。
type S struct {
io.Reader
}
类型嵌入这种看似“继承”的机制,实际上是一种组合的思想。更具体点,它是一种组合中的代理(delegate)模式,S 只是一个代理(delegate),对外它提供了它可以代理的所有方法,如例子中的 Read 方法。当外界发起对 S 的 Read 方法的调用后,Go 会首先查看结构体自身是否实现了该方法,如果实现了,Go 就会优先使用结构体自己实现的方法。如果没有实现,那么 Go 就会查找结构体中的嵌入字段的方法集合中,是否包含了这个方法。将该调用委派给它内部的 Reader 实例来实际执行 Read 方法。
interface 底层实现
接口(interface)本质上是一种结构体,go 中的接口变量其实是用 iface 和 eface 这两个结构体来表示的:iface 表示某一个具体的接口(含有方法的接口),eface 表示一个空接口(interface{},不包含任何方法)
type Flyable interface {
Fly()
}
func main(){
var f1 interface{} // 在底层实际上是 eface 类型
println(f1) // CALL runtime.printeface(SB)
var f2 Flyable // 在底层实际上是 iface 类型
println(f2) // CALL runtime.printiface(SB)
}
eface 和 iface
Go Data Structures: InterfacesLanguages with methods typically fall into one of two camps: prepare tables for all the method calls statically (as in C++ and Java), or do a method lookup at each call (as in Smalltalk and its many imitators, JavaScript and Python included) and add fancy caching to make that call efficient. Go sits halfway between the two: it has method tables but computes them at runtime. I don’t know whether Go is the first language to use this technique, but it’s certainly not a common one.
// $GOROOT/src/runtime/runtime2.go
type iface struct {
// 方法表
tab *itab // iface 除了要存储结构体类型信息之外,还要存储接口本身的信息(接口的类型信息、方法列表信息等)以及结构体类型所实现的方法的信息,因此 iface 的第一个字段指向一个itab类型结构。
data unsafe.Pointer // 指向变量本身的指针
}
// $GOROOT/src/runtime/runtime2.go
type itab struct {
inter *interfacetype // 这个接口类型自身的信息
_type *_type // 接口类型变量的结构体类型的信息
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // 结构体类型已实现的接口方法的调用地址数组
}
// $GOROOT/src/runtime/type.go 根据 interfacetype 我们可以得到关于接口所有方法的信息
type interfacetype struct {
typ _type // 接口类型自身的信息
pkgpath name // 包路径名
mhdr []imethod // 接口方法集合
}
iface 里面保存的 itab 中保存了具体类型的方法指针列表,data 保存了具体类型值的内存地址。
type eface struct {
// 接口变量的类型
_type *_type // eface 表示的空接口类型并没有方法列表,因此它的第一个指针字段指向一个_type类型结构,这个结构为该接口类型变量的结构体类型的信息
data unsafe.Pointer // 指向变量本身的指针
虽然 eface 和 iface 的第一个字段有所差别,但 tab 和 _type 可以统一看作是结构体类型的类型信息。Go 语言中每种类型都会有唯一的 _type 信息,无论是内置原生类型,还是自定义类型都有。Go 运行时会为程序内的全部类型建立只读的共享 _type 信息表(类似于java的 kclass?),因此拥有相同结构体类型的同类接口类型变量的 _type/tab 信息是相同的。过 _type 我们可以得到结构体里面所包含的方法这些信息。
运行时类型结构(类似于jvm的kclass?)
type _type struct {
size uintptr
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32
tflag tflag
align uint8
fieldAlign uint8
kind uint8 // 类型
// function for comparing objects of this type (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
// gcdata stores the GC type data for the garbage collector. If the KindGCProg bit is set in kind, gcdata is a GC program. Otherwise it is a ptrmask bitmap. See mbitmap.go for details.
gcdata *byte
str nameOff
ptrToThis typeOff
}
eface 内部结构
type Binary uint64
func main() {
b := Binary(200)
any := (interface{})(b)
fmt.Println(any)
}
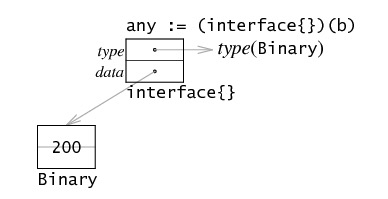
iface 内部结构
type Binary uint64
func (i Binary) String() string {
return strconv.FormatUint(i.Get(), 10)
}
func (i Binary) Get() uint64 {
return uint64(i)
}
func main() {
b := Binary(200)
any := Stringer(b)
fmt.Println(any)
}
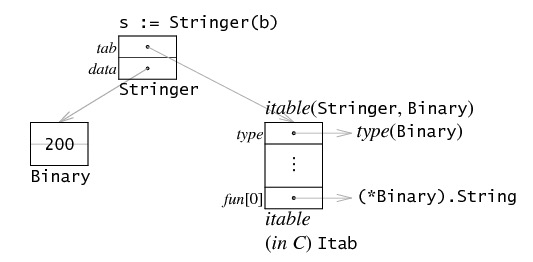
装箱
Interface values are represented as a two-word pair giving a pointer to information about the type stored in the interface and a pointer to the associated data. Assigning b to an interface value of type Stringer sets both words of the interface value.一个结构体实现了一个接口,把这个结构体变量赋值给这个接口变量,就是赋值这个接口变量里的俩指针,就完成了数据和实现的绑定。
Note that the itable corresponds to the interface type, not the dynamic type. In terms of our example, the itable for Stringer holding type Binary lists the methods used to satisfy Stringer, which is just String: Binary’s other methods (Get) make no appearance in the itable.itable(Stringer,Binary) 的方法表只包含 String 方法不包含 Get 方法。
any := Stringer(b) 用伪代码表示 就是
创建 iface struct for any
创建 itab struct
tab := getSymAddr(`go.itab.main.Binary,main.Stringer`).(*itab)
tab.inter = getSymAddr(`type.main.Stringer`).(*interfacetype)
tab._type = getSymAddr(`type.main.Binary`).(*_type)
tab.fun[0] = getSymAddr(`main.(*Binary).String`).(uintptr)
any.String() 相当于 any.tab->fun[0]
接口类型变量赋值是一个“装箱”的过程,实际就是创建一个 eface 或 iface 的过程(PS:any 赋值就是给iface赋值,只不过我们没有显式定义 iface 而已,被隐藏掉了)。在将结构体类型变量赋值给接口类型变量语句对应的汇编代码中,我们看到了convT2E和convT2I两个 runtime 包的函数。convT2E 用于将任意类型转换为一个 eface,convT2I 用于将任意类型转换为一个 iface。两个函数的实现逻辑相似,主要思路就是根据传入的类型信息(convT2E 的 _type 和 convT2I 的 tab._type)分配一块内存空间,并将 elem 指向的数据拷贝到这块内存空间中,最后传入的类型信息作为返回值结构中的类型信息,返回值结构中的数据指针(data)指向新分配的那块内存空间。
// $GOROOT/src/runtime/iface.go
func convT2E(t *_type, elem unsafe.Pointer) (e eface) {
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2E))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
e._type = t
e.data = x
return
}
func convT2I(tab *itab, elem unsafe.Pointer) (i iface) {
t := tab._type
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2I))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
i.tab = tab
i.data = x
return
}
不过,装箱操作是由 Go 编译器和运行时共同完成的,有一定的性能开销,因此 Go 也在不断对装箱操作进行优化,包括对常见类型如整型、字符串、切片等提供系列快速转换函数。这些函数去除了 typedmemmove 操作,增加了零值快速返回等特性。同时 Go 建立了 staticuint64s 区域,对 255 以内的小整数值进行装箱操作时不再分配新内存,而是利用 staticuint64s 区域的内存空间。PS: 有点Java的意思了,Java是对 -128~127 范围内的整数做了享元模式的处理
C++ 和 Go 在定义接口方式上的不同,也导致了底层实现上的不同。C++ 通过虚函数表来实现基类调用派生类的函数;而 Go 通过 itab 中的 fun 字段来实现接口变量调用实体类型的函数。C++ 中的虚函数表是在编译期生成的;而 Go 的 itab 中的 fun 字段是在运行期间动态生成的。
interface{} 不是任意类型
package main
type TestStruct struct{}
func NilOrNot(v interface{}) bool {
return v == nil
}
func main() {
var s *TestStruct
fmt.Println(s == nil) // #=> true
fmt.Println(NilOrNot(s)) // #=> false
}
出现上述现象的原因是 —— 调用 NilOrNot 函数时发生了隐式的类型转换,除了向方法传入参数之外,变量的赋值也会触发隐式类型转换。在类型转换时,*TestStruct 类型会转换成 interface{} 类型,转换后的变量(eface struct)不仅包含转换前的变量,还包含变量的类型信息 TestStruct,所以转换后的变量与 nil 不相等。
变量的赋值、向方法传入参数会触发隐式类型转换,类型转换的情况比较多:
- 同一类型的转换,比如int64与int
- 某类型与字符串的转换,这个有专门的包
- 字符串与字符/short数组的转换,比如string与
[]uint8等 - 具体类型转换成接口类型。
类型断言是,一个大类型,比如interface{},怀疑它可能是字符串,则可以xxx.(string)
等值比较操作
而接口类型变量的 data 部分则是指向一个动态分配的内存空间,这个内存空间存储的是赋值给接口类型变量的结构体类型变量的值。也就是说,我们判断两个接口类型变量是否相同,只需要判断 _type/tab 是否相同,以及 data 指针指向的内存空间所存储的数据值是否相同就可以了。这里要注意不是 data 指针的值相同噢。在创建 eface 时一般会为 data 重新分配新内存空间,将结构体类型变量的值复制到这块内存空间,并将 data 指针指向这块内存空间。因此我们多数情况下看到的 data 指针值都是不同的。
由于 eface 和 iface 是 runtime 包中的非导出结构体定义,我们不能直接在包外使用,所以也就无法直接访问到两个结构体中的数据。不过,Go 语言提供了 println 预定义函数,可以用来输出 eface 或 iface 的两个指针字段的值。在编译阶段,编译器会根据要输出的参数的类型将 println 替换为特定的函数,这些函数都定义在$GOROOT/src/runtime/print.go文件中,而针对 eface 和 iface 类型的打印函数实现如下:
// $GOROOT/src/runtime/print.go
func printeface(e eface) {
print("(", e._type, ",", e.data, ")")
}
func printiface(i iface) {
print("(", i.tab, ",", i.data, ")")
}
反射
反射是计算机语言提供的一个关键特性,掌握它,对我们编写通用(不要写死)的代码有比较大的帮助,另外,一些库或者框架提供的关键特性也是通用反射来实现。可以在一定程序上避免硬编码,提供灵活性和通用性,但
- 由于将部分类型检查工作从编译期推迟到了运行时,使得一些隐藏的问题无法通过编译期发现,提高了代码出现bug的几率,搞不好就会panic
- 反射出变量的类型需要额外的开销,降低了代码的运行效率
- 反射的概念和语法比较抽象,过多的使用反射,使得代码难以被其他人读懂,不利于合作与交流
Golang 中反射的应用与理解反射,就是能够在运行时更新变量和检查变量的值、调用变量的方法和变量支持的内在操作,而不需要在编译时就知道这些变量的具体类型。这种机制被称为反射。Golang 的基础类型是静态的(也就是指定 int、string 这些的变量,它的 type 是 static type),在创建变量的时候就已经确定,反射主要与 Golang 的 interface 类型相关(它的 type 是 concrete type),只有运行时 interface 类型才有反射一说。当程序运行时, 我们获取到一个 interface 变量, 程序应该如何知道当前变量的类型,和当前变量的值呢?当然我们可以有预先定义好的指定类型, 但是如果有一个场景是我们需要编写一个函数,能够处理一类共性逻辑的场景,但是输入类型很多,或者根本不知道接收参数的类型是什么,或者可能是没约定好;也可能是传入的类型很多,这些类型并不能统一表示。这时反射就会用的上了,典型的例子如:json.Marshal。在 Golang 中为我们提供了两个方法,分别是 reflect.ValueOf 和 reflect.TypeOf,见名知意这两个方法分别能帮我们获取到对象的值和类型。Valueof 返回的是 Reflect.Value 对象,是一个 struct,而 typeof 返回的是 Reflect.Type 是一个接口。我们只需要简单的使用这两个进行组合就可以完成多种功能。
深度解密GO语言之反射反射的本质是程序在运行期探知对象的类型信息和内存结构(泛化一点说,就是我想知道某个指针对应的内存里有点什么),不用反射能行吗?可以的!使用汇编语言,直接和内存打交道,首地址指针+偏移什么信息不能获取?但是,当编程迁移到高级语言上来之后,就不行了!就只能通过反射来达到此项技能。
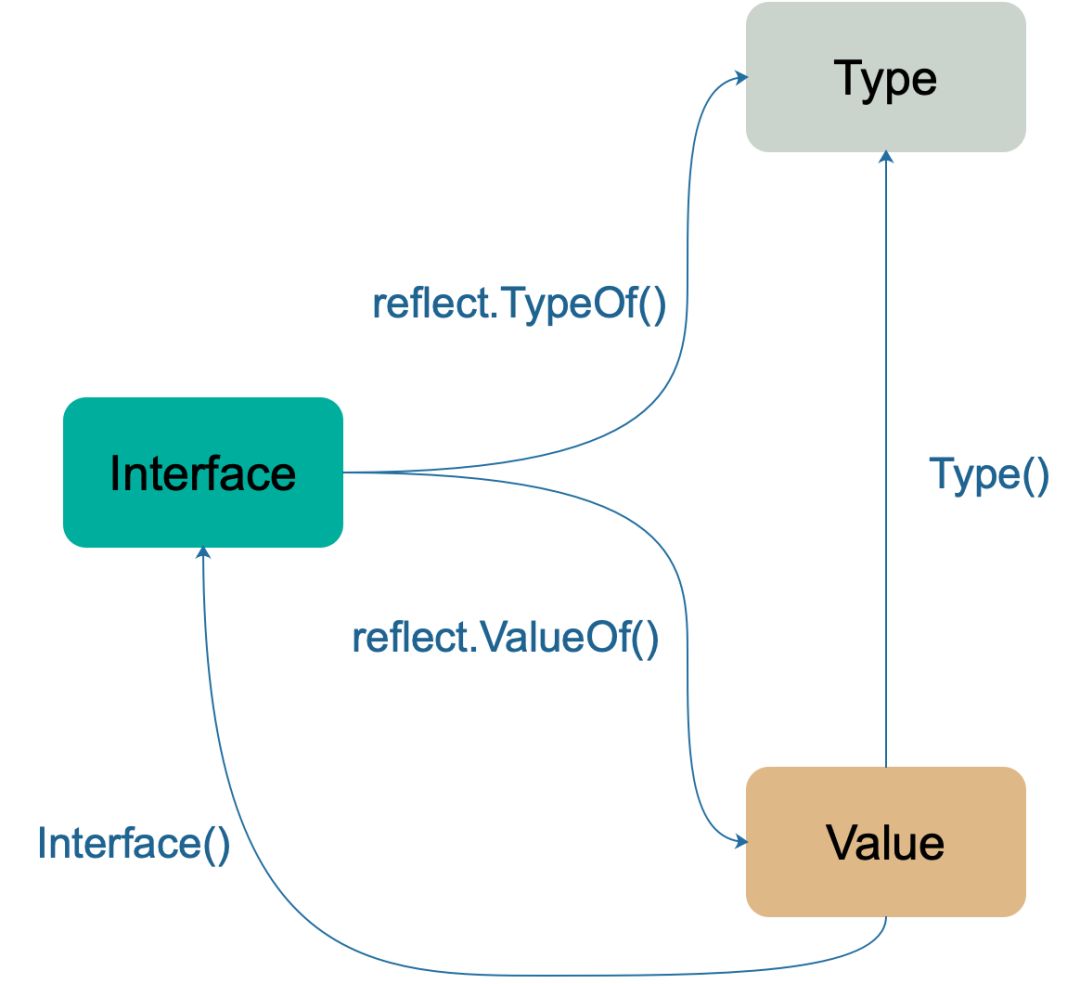
![]()
reflect 包里定义了一个接口reflect.Type和一个结构体reflect.Value,它们提供很多函数来获取存储在接口里的类型信息,反射包中的所有方法基本都是围绕着 Type 和 Value 这两个类型设计的。reflect.Type 主要提供关于类型相关的信息,所以它和 _type 关联比较紧密; reflect.Value 则结合 _type 和 data 两者,因此程序员可以获取甚至改变类型的值。

TypeOf
TypeOf 函数用来提取一个接口中值的类型信息(比如有哪些字段)。由于它的输入参数是一个空的 interface{},调用此函数时,实参会先被转化为 interface{} 类型。这样,实参的类型信息、方法集、值信息都存储到 interface{} 变量里了。
Type是什么
type rtype struct {
size uintptr // 类型占用内存大小
ptrdata uintptr // 包含所有指针的内存前缀大小
hash uint32 // 类型 hash
tflag tflag // 标记位,主要用于反射
align uint8 // 对齐字节信息
fieldAlign uint8 // 当前结构字段的对齐字节数
kind uint8 // 基础类型枚举值
equal func(unsafe.Pointer, unsafe.Pointer) bool //比较两个形参对应对象的类型是否相等
gcdata *byte // GC 类型的数据
str nameOff // 类型名称字符串在二进制文件段中的偏移量
ptrToThis typeOff // 类型元信息指针在二进制文件段中的偏移量
}
func TypeOf(i interface{}) Type{
// 任意类型的变量都可以被强转为emptyInterface
eface := *(*emptyInterface)(unsafe.Pointer(&i))
return toType(eface.typ)
}
func toType(t *rtype) Type {
if t == nil {
return nil
}
return t
}
ValueOf
reflect.Value 表示 interface{} 里存储的实际变量,它能提供实际变量的各种信息。相关的方法常常是需要结合类型信息和值信息。例如,如果要提取一个结构体的字段信息,那就需要用到 _type (具体到这里是指 structType) 类型持有的关于结构体的字段信息、偏移信息,以及 *data 所指向的内容 —— 结构体的实际值。
Value是什么? PS: 对值内存区域指针的封装
type Value struct {
// typ 包含由值表示的值的类型。
typ *rtype
// 指向值的指针。
ptr unsafe.Pointer
// flag 保存有关该值的元数据
flag
}
PS:持有首地址,再持有类型信息,也就知道了某个字段在偏移量,进而就可以获取某个字段的值。
func ValueOf(i interface{}) Value {
if i == nil {
return Value{}
}
escapes(i)
return unpackEface(i)
}
func unpackEface(i interface{}) Value {
e := (*emptyInterface)(unsafe.Pointer(&i))
t := e.typ
if t == nil {
return Value{}
}
f := flag(t.Kind())
if ifaceIndir(t) {
f |= flagIndir
}
return Value{t, e.word, f}
}
通过 Type() 方法和 Interface() 方法可以打通 interface、 Type、 Value 三者。Type() 方法也可以返回变量的类型信息,与 reflect.TypeOf() 函数等价。Interface() 方法可以将 Value 还原成原来的 interface。
- 按名字访问结构的成员
reflect.ValueOf(e).FieldByName("Name") - 按名字访问结构的方法
reflect.ValueOf(e).methodByName("updateAge").Call(args)
三大定律
反射建立在类型系统之上,以java 视角来表述的话,反射为程序提供了部分操作 jvm 数据的能力。
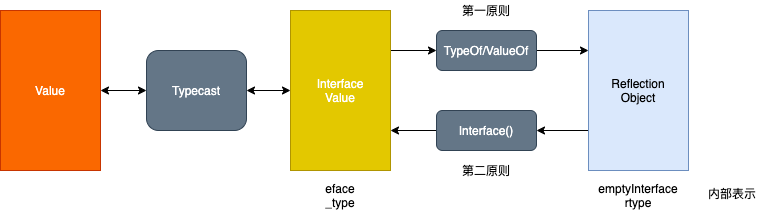
- Reflection goes from interface value to reflection object. 我们能将 Go 语言的
interface{}变量转换成反射对象。为什么是从interface{}变量到反射对象?当我们执行reflect.ValueOf(1)时,虽然看起来是获取了基本类型 int 对应的反射类型,但是由于reflect.TypeOf、reflect.ValueOf两个方法的入参都是interface{}类型,所以在方法执行的过程中发生了类型转换。 - Reflection goes from reflection object to interface value. 我们可以从反射对象可以获取
interface{}变量(Interface()方法)。 - To modify a reflection object, the value must be settable.如果需要操作一个反射变量,那么它必须是可设置的。PS: 可设置 ==> 可以找到原变量地址 ==> go 是值传递 ==>
reflect.ValueOf(引用)反射变量 Value 必须要 hold 住原变量的地址才行
与java 对比
hotspot 内部c++对java 对象的表示

java中的反射,设计思路是,先类型后值。意思是,无论如何,都是先找到属性和方法的描述,然后根据描述来获取属性的值、调用方法的执行。要进行这样的操作,入口都是由类的描述开始。
Class cls = obj.getClass();
Constructor constructor = cls.getConstructor();
Method[] methods = cls.getDeclaredFields();
golang设计思路为,值和类型划分的非常清晰,两条腿走路。Go 没有类的概念,并且结构体只包含了已声明的字段。因此,我们需要借助“reflection”包来获得所需的信息
| java | go | |
|---|---|---|
| 获取对象的类型/表示 | getClass() |
objType := reflect.TypeOf(obj) |
| 获取对象的值/表示 | 不支持 | objValue := reflect.ValueOf(obj) |
| 获取属性描述 | getClass().getField("fieldName") |
objType.Field(index) |
| 获取属性的值 | field.get(obj) |
objValue.Filed(index).Interface() |
| 获取方法的描述 | getClass().getMethod("methodName") |
objType.Method(index) |
| 方法调用 | method.invoke(obj, args) |
objValue.Method(index).Call(args) |
在java中,通过类的描述,来获得method,由于该method是属于类级别的,所以,调用时,需要传入参数obj和args;而golang中,method是对象级别的,所以,调用时,不需要参数obj,只需要args。
其它
我们经常看到结构体字段后面,会跟一个反引号括起来的键值对字符串,格式是:key:"value",并且可以使用多个,中间用空格隔开,信息内容是任意定义的。这种语法在Golang中叫做标签Tag,类似其他语言中的注解(Annotation),可以通过Golang的反射机制(reflect.StructTag)来解析。

留下评论