LLM微调实践
简介
微调模型的主要原因在于,当模型的推理结果未能达到预期时,简单地通过单样本或少样本推理来调整模型输出效果并不总是奏效,特别是对于较小的LLM(大语言模型)。通过在提示中添加一个或多个已完成的示例来优化输出,但这种方法有其局限性。首先,提示中包含的示例会占用上下文窗口的空间,导致可用来包含其他有用信息的空间减少。其次,这些策略在实际应用中并不总是能够解决问题。与预训练阶段不同,微调是一个监督学习过程,它使用标记好的示例数据集来更新模型的权重,从而使模型更好地完成特定任务。微调的核心价值所在:在优化模型输出的同时,最大化利用有限的上下文窗口空间,提升模型的实际应用效果。
用一个更牛逼的模型准备数据
- identity tasks by prompt-engineering a large llm
- find tasks that you see an llm doing ~ok at
- pick one task
- Get ~1000 inputs and outpus for the task Better than the ~ok from the llm
- finetune a small llm on this data
steps to prepare your data:
- collect instruction-response pairs
- concatenate pairs(add prompt template,if applicable)
- tokenize: pad, truncate
- Tokenizer.encode 文本转数字,Tokenizer.decode 数字转文本。
- batch input时,
Tokenizer.encode(texts,padding=True)文本转数字,不同text通过padding 对齐。 - 如果text 超过了max_length还可以使用截断
Tokenizer.encode(texts,max_length=xx,truncation=True)。
- split into train/test
- datasets.train_test_split
在进行领域任务的SFT的时候我们通常会有以下训练模式进行选择,根据领域任务、领域样本情况、业务的需求我们可以选择合适的训练模式。
- 基于base模型+领域任务的SFT;
- 基于base模型+领域数据 continue pre-train +领域任务SFT; 在资源允许的情况下,如只考虑领域任务效果,推荐。
- 基于base模型+领域数据 continue pre-train +通用任务SFT+领域任务SFT;
- 基于base模型+领域数据 continue pre-train +通用任务与领域任务混合SFT;
- 基于base模型+领域数据 continue pre-train(混入SFT数据) +通用任务与领域任务混合SFT;在资源允许的情况下,如考虑模型综合能力,推荐。
- 基于chat模型+领域任务SFT;在资源不允许的情况下,推荐。
- 基于chat模型+领域数据 continue pre-train +领域任务SFT 几个考虑
- 是否需要continue pre-train?大模型的知识来自于pre-train阶段,如果你的领域任务数据集与pre-train的数据集差异较大,比如你的领域任务数据来自公司内部,pre-train训练样本基本不可能覆盖到,那一定要进行continue pre-train。如果你的领域任务数据量较大(token在1B以上),并只追求领域任务的效果,不考虑通用能力,建议进行continue pre-train。
- 是选择chat模型 还是base模型?如果你有一个好的base模型,在base模型基础进行领域数据的SFT与在chat模型上进行SFT,效果上差异不大。基于chat模型进行领域SFT,会很容导致灾难性遗忘,在进行领域任务SFT之后,模型通用能力会降低,如只追求领域任务的效果,则不用考虑。如果你的领域任务与通用任务有很大的相关性,那这种二阶段SFT会提升你的领域任务的效果。如果你既追求领域任务的效果,并且希望通用能力不下降,建议选择base模型作为基座模型。在base模型上进行多任务混合训练,混合训练的时候需要关注各任务间的数据配比。
多轮对话怎么转化为模型接受的input和用于计算loss的label
预训练
通常,我们把经过预训练(pretrain)阶段得到的模型称为base模型。这个阶段主流的数据组织方式叫packing。在不采用packing的时候,为了将不同长度的句子组成一个batch tensor,我们需要进行填充(pad),这个填充过程既可以按照batch内最长句子填充,也可以按照模型最长输入长度填充。为了防止一个batch内存在许多的<pad>token,浪费计算资源,packing直接采取多条示例的拼接方法。下图是传统方法和packing的对比:
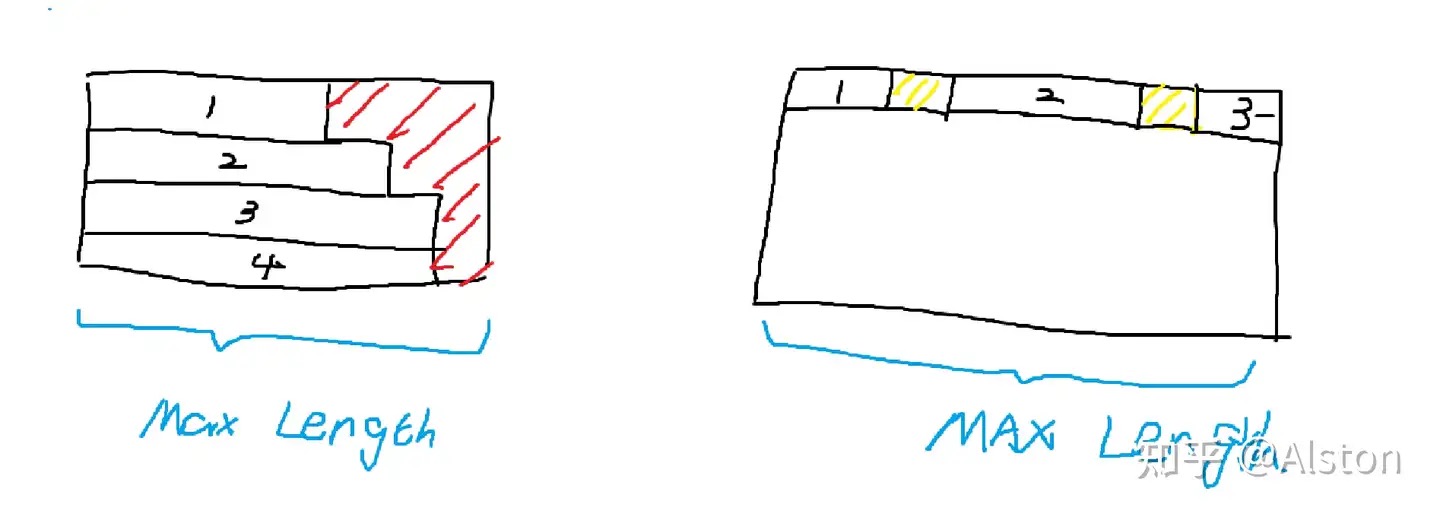
左侧是传统的padding做法,右侧是packing,其中红色部分代表pad token,黄色部分代表sep token。为了区分不同的训练示例,我们在不同示例之间加上一个分割标记sep token,注意力窗口不会跨示例。这个注意力模式叫块对角矩阵(BlockDiagonalMask)【本质上是在示例内的下三角矩阵】,而不是传统的全局下三角矩阵。由此,就消除了对pad token的需要,所以开源大模型刚问世的时候(2023-3那阵子),存在很多base model放出来的tokenizer并没有pad token,比如llama-base。需要注意,packing时示例3可能会被截断,这个行为在预训练时是可以接受的。注意,这个时候的学习模式非常的简单,就是next token prediction。
数据组成形式:
输入input: <bos> X1 X2 X3
标签labels:X1 X2 X3 </s>
典型的Decoder架构的数据训练方式;
指令微调
sft 阶段与预训练阶段并无本质区别,仅在计算loss时所考虑的token序列成分有所不同。
指令微调不仅仅考虑了对人类指令和多任务的适应性,更是希望能将角色系统融入大模型中,从而让大模型变成chat模型,指令微调并不直接产生chat model,只是其中必不可少的一步。其中比较特殊的数据形式就是多轮对话。对话里必不可少的存在“角色”这个概念,因为和大模型的对话仅限于用户和模型,所以极大多数的对话模板(template)里都只考虑了两个角色——user和assistant。注意,对话模板只有非base模型才需要,所以很多的base模型的tokenizer里并不携带chat_template。PS: 对话模板其实是一种便于模型区分对话角色的工具,利用特殊 token 构建一个让模型“看得懂”的对话方式,而这个方式往往是模型在 post-training 中针对性训练的。
举个例子,比如:LLAMA2-chat的对话模板中user标识 是 [INST] , assistant 标识是[/INST],下面是一个单轮的例子
chat_dict = [
{"role": "user", "content": 你好},
{"role": "assistant", "content": 你也好},
]
因为模型输入只能是非结构化的,我们利用模板将其非结构化。得到的字符串就是[INST]你好[/INST]你也好。那么假如我们现在获得了一个现成的训练数据
chat_dict = [
{"role": "user", "content": U1},
{"role": "assistant", "content": A1},
{"role": "user", "content": U2},
{"role": "assistant", "content": A2},
]
模型的input_ids和对应的labels应该是什么呢(input_ids 对应模型输入,labels 则是为了和模型oupput标量计算loss)?最常规的做法应该是在每一轮首尾用[BOS]和[EOS]包裹,轮次内部正常用模板非结构化就行。上例可以转换为input_ids= [BOS][INST]U1[\INST]A1[EOS][BOS][INST]U2[\INST]A2[EOS],难点在于LABELS应该是什么呢? 我们可以根据学习模式来确定LABELS。
-
在推理场景下,假如是第一轮对话开始,我们会输入给模型[BOS][INST]U1[\INST],那么我们希望模型吐出的是什么呢?是A1和[EOS],A1是模型自己的回答,EOS是为了告诉解码系统生成结束了,否则模型将一直生成到最大长度才会停止。我们获得了一个初步的学习模式需求,就是根据
[BOS][INST]U[\INST] → A[EOS]。input [BOS][INST]U [/INST]A label -100 -100 -100 A [EOS]在多轮的场景下,也只是复制这个过程。
input [BOS][INST]U [/INST]A [EOS][BOS][INST]U2 [/INST]A2 label -100 -100 -100 A [EOS]X X X X A2 [EOS] -
在llama factory里有一个参数叫 Efficient EOS,所谓efficient eos并不代表是一个新的token,而是一个特殊的input和label的设计方式。 多轮对话的训练过程详解
不管是PreTraining阶段还是SFT阶段,loss函数都是一样的,只是计算的方式存在差异,PreTraining阶段计算的是整段输入文本的loss,而SFT阶段计算的是response部分的loss。sft 的 prompt 不做 loss,但这并不是说它不能做 loss。主要原因是 prompt 的同质化比较严重,不做 loss_mask 的话,同样的一句话会被翻来覆去的学,但如果你能保证你的每条 prompt 都是独一无二的,就完全可以省去 prompt 的 loss_mask 环节。
此外,LLM在推理也就是generate的时候,是要不断调用forward的。sft训练时,比如input=ab,response=cd,模型一次 forward 输出整个序列的 logits [P(b|a), P(c|a,b), P(d|a,b,c), P(<eos>|a,b,c,d)],每个 token 的 logits 是预测下一个 token 的概率分布。decoder 的 causal mask(上三角遮罩矩阵) 已经自动保证了预测下一 token 时不会看到未来的 token(只看到左边 token),比如在预测 c 时,模型只能看到 ab,看不到d。loss_mask = [0, 0, 1, 1] 标记loss只计算 response 部分(c, d),Loss = cross-entropy(P(c|a,b), c) + cross-entropy(P(d|a,b,c), d)。
微调实践
LLM is not all you need(大模型领域知识微调实践)
- 为什么要用SFT (指令微调)而不用RLHF?RLHF的loss主要在优化LLM输出特定分布(风格)的内容,而笔者想要的是让LLM看到某个问题输出非常精确的答案。那能不能用RL来做基于标签反馈的优化呢?这里边有一个很大的问题是目标token序列非常少,这涉及到稀疏空间中的RL优化问题,比较棘手,不如用SFT来得直接有效,而且SFT对于格式输出的学习几乎是无可挑剔的。
- 指令微调是全参数微调还是PEFT?首先说PEFT吧,有Lora,P-tuning等很多种。笔者一直用Lora,虽然这些方法各有千秋,但当任务很难时性能差异不是很大。其次说全参数微调,笔者用PEFT微调发现效果比较差之后就采用了全参数微调,但是提升不是很显著(需要的是20+或者30+个点的提升,而不是个位数的提升)。
- 能不能全都要?全参数SFT+LoRA微调模式:尝试了将全参数SFT与LoRA进行结合,具体微调的方式:前10%-30% step 采用全参数SFT的方式,后面的step采用LoRA的方式,比单纯的LoRA要更加稳定,比全部采用全量参数SFT更加节省资源。该方式动机,通常来讲,大模型微调的时候,前面step中,模型参数变化最快,loss也是下降的最快,后面step模型参数变化幅度越来越小,loss变化幅度变小,逐渐收敛。因此,可以在微调的最开始step采用全参数SFT,让模型能够尽快的学习到指令,后面采用LoRA的方式,让模型能够更好的遵循指令。全参数SFT与LoRA 训练step配比,可以依据自己的tokens来定。
- 能不能将领域知识以continue training的形式注入LLM?尝试过,几乎没有提升。主要是用来continue training的数据不是非常多。所以对SFT没有加成。
- 在效率和资源都达标和到位的情况上,优先用大 size 的模型进行实验和微调,因为大 size 的模型在容错性上比小 size 的好太多。尽管大尺寸模型也可能存在多任务不稳定、标签不平衡等问题,但其表现通常会比小尺寸模型更为稳定。因此,选用大尺寸模型其实是节省了人力成本,避免了很多之后可能会遇到的各种坑。
- 浅谈大模型 SFT 的实践落地: 10 问 10 答SFT真的不能学到知识?很遗憾的说,经过一年的实践和普遍的认知。常识和世界知识难以通过 SFT 灌输给模型。SFT更应该关注激发模型在预训练中已学到的知识、让模型学习业务所需要的特定规则、以及输出格式稳定。那么,何为常识和世界知识?例如,“2023年NBA总冠军是掘金”便属于世界知识。如果 LLM 的训练数据仅更新至2022年,那么它自然无法得知这一信息。即便你的SFT数据中包含 “谁是2023年NBA总冠军?答案是掘金” 这样的问答对,训练后的模型可能只能回答这个语序的问题,而无法举一反三。比如,当你问“掘金在哪一年获得了NBA总冠军?”时,它无法回答“2023年”。这种举一反三的能力需要模型在预训练阶段就接触过“2023年NBA总冠军是掘金”这类知识的多种不同文本表达,如这条知识在预训练文本中出现在不同的表述中(主动句、被动句、出现在新闻语料、出现在聊天对话语料等等等等)。因此,从这个角度看,SFT并不能学得常识、世界知识。但这并不意味着我们应该放弃SFT。相反,我们应当关注SFT在以下方面:
- 激发预训练知识:虽然SFT不能直接学的新知识,但需要靠它激发模型在预训练中已学到的知识。
- 稳定格式输出:通过SFT,我们可以训练模型以稳定的格式输出结果,便于线上的稳定。
- 更遵循具体任务:如多标签多分类时,模型老输出一些不在标签体系的任务。
- 学习业务逻辑:SFT能够教导模型特定的业务规则,如让他习得“买了 20 万以上的车算有钱人”。 大模型生产环境下部署微调的10条戒律汝应当编写提示语,并创建一个基准,证明任务是可行的。如果提示语有效,微调有90%的可能性会改善模型表现;如果无效,微调只有25%的可能性有效;
LLM训练-sft 非常经典,一定细读。
- sft 会引入 pretrain 阶段未见过的 special_token,来让它们学习全新的语义;主要用于标注对话的角色: user、assistant、system 这些,根据业务需求也可以有“背景”、“旁白”、“事件”等等。sft 会让模型见到最重要的 eos_token,pretrain 模型因为没见过该 token 而无法停止生成;
- session 数据一定要想清楚是每一个 answer 都算 loss,还是只对最后一轮的 answer 算 loss。
- pretrain 是在背书,纯粹的学习知识;sft 则是在做题,学习的是指令 follow 能力。切勿在 sft 阶段强行给模型做知识注入,比如训个 50W 条的 code 数据,所有的知识注入工作应该采用 continue-pretrain 的思路进行,否则都会使得模型的通用能力掉点明显(sft 做知识注入基本上是 100% 某个知识,但 continue-pretrain 做知识注入会控制在 10% ~ 20% 左右的比例)。
- 大模型这波技术浪潮,拼的不是谁代码写得好,拼的是谁有算力、谁有训练经验、谁有 debug 能力。当算法新人还在纠结模型这个 case 为什么回答不对、那个 case 为什么瞎说的时候,经验丰富的人看眼 case 就知道:训练数据有猫腻 / 训练数据缺少某个能力项 / 这 case 为什么没触发 RAG / 有黄反拦截倒也不必纠结。总之,多了解自己的 base 模型的能力,多培养训练 feel,就是做好 sft 的重要法门。
一些体会
- pre-training,通常使用自监督算法进行训练。对last token 计算loss,目的是学习语言能力/一句话的统计概率/世界知识。
- 继续预训练(也称为第二阶段预训练)将使用全新的、未见过的领域数据进一步训练基础模型。同样使用与初始预训练相同的自监督算法。通常会涉及所有模型权重,并将一部分原始数据与新数据混合。
- post-training 比如sft 微调, 在包含正确标签/答案/偏好的注释数据集上进行监督训练,而不是自监督训练,主要目的是提高能力,如指令遵循、人类对齐、任务执行等。仅对response 部分计算loss,目的是让response 对prompt 做出反应。prompt 本身并不值得太多学习。
数据准备
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。所以数据的构造至关重要,需要建立对生成数据质量的把控。在chatgpt出来后,业界最开始基于pretrain模型上做sft最受关注的工作之一,是self-instruct,蒸馏chatgpt得到高质量的sft数据。核心思想是通过建立种子集,然后prompt模型输出目标格式的数据,通过后置ROUGE-L等筛选方法去重,不断的加入种子集合,来提升产出数据的多样性和质量。
先分享下 sft 工作者的一天:晚上下班挂个精心准备的实验,早上起床看结果并随手挂个实验防止 gpu 资源浪费,白天做一天的 case 分析,晚上下班挂一个结合 case 分析结果优化完数据的新实验(完成闭环)。因此,不用质疑,分析数据和清洗数据就是 sft 工作者的 90% 的工作量。
- 如果SFT任务类型较多,可以尝试添加system_prompt,不同的任务使用不同的system_prompt;
- 一开始不需要急着构造大量 SFT 数据集,可以先用少量数据(50条~100条)对模型做 SFT 后观察真实评估是否有收益。如果有收益,可以尝试以部分数据为种子数据集继续扩充,找到 scaling law。如果没有收益,那么再重新检查 SFT 数据集的质量。如何判断 SFT 数据质量好坏?
- badcase 的覆盖度:做 SFT 之前,我们肯定有一批 badcase。那么,我们做 SFT 的目的就是去解决这些badcase。所以,要确保 SFT 数据集中对这些 badcase 有一定的覆盖度。这样,做完 SFT 才可能会有收益。
- 高质量,数据质量重要性大于数据数量。大模型中 SFT 的过程中,会学习 prompt 到 response 到映射关系,如果我们 SFT 的数据存在噪声(如错别字、错误格式、不符合预期输出的样本等),那么会对模型的训练过程造成比较严重的影响。因此,不可以一味去堆叠 SFT 的样本数量,样本的质量比数量更重要。举一个例子,往往我们会遇到模型在一些任务上不遵循输出格式的问题。这时,我们会通过 SFT 来做对齐。假如说这里的格式是指 json 格式的话,那么我们可以通过代码 check 的方式,对 SFT 数据集做一遍检查。其他格式问题都可以通过这类代码校验的方式进行检查。
- 尽量人工生成:语言模型生成的文本,有一种隐含的“模式”。在看一些文字的时候,经常能识别出来“这是语言模型生成的”。
- 数量不要太少:通过LoRA论文看,100条开始有明显的改善,1000条左右,有不错的效果。
- Answer的质量:prompt 可以不那么严谨,能看懂就行,但 answer 是尽量一个标点符号都不要有错误的,该中文引号就中文引号,该单引号就单引号,该把 GPT4 啰哩啰嗦的回复精简一下就精简。Answer的质量包括内容和格式两方面,一方面内容的正确性需要得到保证,一方面内容的格式也很重要,细节丰富,逻辑缜密的answer可以激发模型更多的回答能力。
- 多样性。 数据形式不能让模型找到规律,关键信息在 prompt 中的位置分布要足够随机。目的是避免模型在训练时退化,只聚焦于某些或某些位置的 token,而不是聚焦于完整的 prompt。模型和人一样,骨子里都是有偷懒倾向的。
- 每一条 sft 训练数据必须要 task_type 类型,千万别搞大杂烩,否则对后续的 case 分析简直是灾难性的伤害。在实际工作中,双层 task_type 都很常见,比如“逻辑推理 - 常识推理”,“逻辑推理 - cot 多步骤推理” 这种。至于每种 task_type 的数据量,别搞平均主义:难 task_type 酒数据多点,简单 task_type 就数据少点,也要结合自己的 base 模型能力动态调整。task_type 的划分就是 sft 数据最重要的基建工作,没有之一。 微调框架Swift添加Channel Loss支持
- prompt 表达方式多样性,不要千篇一律的“把中文句子 A 翻译成英文”,也要适当有一些“我在英国旅游,我现在需要向路人问路,我想表达 A 的意思,该怎么说”,“我是一个英文老师,我需要向我的学生讲解句子 A 用英文怎么写,请你用最正宗的表达方式帮我完成。”这么做的目的是防止模型只认识 prompt 中的几个关键 token,进而导致训练过拟合或者泛化性变差;
- prompt 长度均衡,既要有短数据,也要有长数据,避免模型的 attention 退化到无法聚焦长 prompt。长数据还不能是字面意思的长,要有那种关键信息藏在 开头 / 中间 / 结尾 的各种数据场景,避免模型在训练时偷懒,只对 prompt 的起始 token 或结束 token 有 attention;
- answer 长度均衡,不能让模型没出输几个 token 就停止,适当的有一些语料让它学会输出尽量长的 answer,否则模型会很难 follow “不少于2000字” 这种指令;
- SFT 数据集中 response 的多样性,当我们希望同样的 prompt 生成出来的内容更多样时,可以尝试在 SFT 数据集中,构造同样的输入 prompt,多样性的 response 数据。经测试后,模型输出多样性指标得到提升。
- 多轮聊天的切换 topic 能力,也就是说,有的数据当前 query 是和 session 有关系的,有的数据则是当前 query 和 session 毫无关系,要让模型自己学会判断 query 是否和 session 有关。类似的数据还要有 system 是否生效,有些数据 system 是个摆设,有些数据的 answer 则和 system 直接相关;
- 是否混入预置数据,即在自定义 SFT 数据集的基础上,额外增加一部分比例的模型基座训练时的 SFT 数据(看base 模型提供方是否开放)。一定程度上缓解大模型在某个领域上 SFT 后,通用能力下降的问题。混入预置数据后,由于模型在 SFT 时,拟合的是全部数据集 prompt 到 response 之间的映射关系,所以混入比例过大会导致模型在特定领域上的能力下降,过小会导致缓解通用能力下降不明显。按照经验,通常设置为 15%~30%左右,依据自己的需求和实验迭代来决定。
- 建议先使用小参数量大模型+ LoRA 验证实验设置及数据是否有效,如果有效的话,再迁移到大参数量大模型上验证scaling law(即随着模型参数量的增加,模型的效果越好)是否成立。这样做可以显著加快迭代效率,避免在大参数模型上反复做无意义的迭代。
多任务训练时怎么确保每个任务都优秀?目前实践下来,任务的相互影响是一个普遍现象,例如训练集中包含四个任务,现在针对任务1补充了大量 bad cases 后重新训练,这种调整很可能会对其他任务产生或正或负的影响。训练集本身存在的任务数据不平衡也是一个不可忽视的问题,某个任务占比大,那其它占比小的任务大概率效果也是不稳定的。有两种方法应对这种挑战:
- 不同任务独立训练模型:针对每个任务单独训练一个模型。当某个任务至关重要,且要求性能指标高度稳定时,这是不得不采用的方法。
- 任务取舍与额外训练:例如,在四个任务中,若其中两个任务尤为重要,可以在全部任务训练完毕后,对这两个关键任务额外训练多一个 epoch。这种做法能最大程度地确保重要任务的效果。
数据生产。prompt 的表达方式,answer 的回复风格,训练者一定要烂熟于心。
- 生产prompt,GPT4 模型的指令 follow 能力已经足够强了,每个 task_type 准备一些 seed prompt,让它基于一些 seed 问题直接仿写出一些 prompt 就可以了。实在是找不到合适的 prompt ,就自己动手写一点,answer 写不出来,prompt 还能写不出来吗?收集或设计 prompt 的时候一定要结合实际情况,不要指望模型一次性写一篇万字爽文,这种事情连人都做不到。我们要把比较困难的任务提前拆解好 prompt ,比如:
prompt1 :请设计一个重生故事的大纲,大纲包含“父母重男轻女,女主高考状元,弟弟彩礼”等要素; prompt2 :请基于给定的故事大纲,扩充内容,生成一篇不少于多少字的文章。LLM 只是知识量比人多,而不是知识掌握度比人精细。如果普通人做起来都费劲,那这个 prompt 大概率是需要拆解的,这在“利用 sft 后的模型去对接业务”时格外重要。
- 生产 answer。GPT4 is all you need,这里的 GPT4 不仅仅是字面意思上的 GPT4,还可以理解为 good model 的意思,指的是利用一个效果好的模型来生产 answer。特别地、利用 GPT4 生产数据的时候,由于模型不 follow 格式,数据可用率大概只有 70% 左右
- 小模型 + SFT ≈ GPT4 + zero_shot / few_shot / cot(复杂指令和逻辑推理可能不行)
- 任何模型在预测的时候,有 cot 确实比没有 cot 效果好很多,尤其是分类任务。这很容易理解嘛,直接说答案肯定不如分析完每个选项再说答案靠谱。我前面提到过,实际工作中,出于耗时的考虑,可能不会用 cot 来训模型,但是数据生产的时候,为了保证回复质量还是应该让 GPT4 用 cot 的方式进行回复,我们在训自己的模型的时候,省去 cot 环节即可。
- GPT4 也好,自己训模型也罢,还是会出现出现数据质量不可用的情况,这时候必须要写规则,或者通过肉眼看来做个校验。数据去重环节也得做,因为一个模型针对一种 task_type 生产出来的数据,同质化十分严重,一定要避免 answer 过于相似的情况发生,实在看不过来就大批量剔除生产的训练数据吧。还是那句话,sft 数据要的是质不是量。
数据飞轮,模型的上线不并代表着 sft 工作的结束,它反倒代表着 sft 真正工作的开始。只有到了这一刻,我们才开始接触“最真实的用户 prompt”。
- 前面说了,prompt 的生产是需要有 seed 种子的,也就是终归是有限的,但用户的脑洞是无限的啊,用户的 query 就是我们的候选 prompt 数据集。尤其是多轮聊天数据,自己生成的多轮对话数据,通常都默认模型回复的是正确的,用户会 follow 模型的回复。但线上可不是这种情况,你聊你的,我聊我的是时有发生的事情。以代码任务为例,我让 GPT4 模型给我写个代码,它写了,我复制粘贴加执行,然后报错了,我把报错复制粘贴发给 GPT4,它修改了代码,我又执行还是报错 …… 重复了这个流程4、5 轮之后,它写的代码终于执行成功了。显然,我和模型的这 5 轮对话数据,就是最好的多轮理解 + 代码生成数据,但它几乎没有任何能标注出来的可能性,只能靠捞用户日志来获得。
- 用户的 prompt 天然比我们自己准备的 prompt 复杂,我们自己的 sft 训练集可能就是让模型翻译一个句子,但是用户的需求可不这么简单,用户会让模型把翻译后句子的某个单词换一个表达方式,或者是提问这个句子中某个的单词是什么意思。因此,基于用户 log 生产的训练数据,是很适合培养模型的话题转移能力,自我纠错能力,坚持己见能力,结合新需求重新改写答案的能力,等等。
- 只有把“定期拉取用户日志,利用规则筛选有价值的 prompt,访问 GPT4 获取答案,加入新数据更新模型”这样的数据飞轮 run 起来了,我们的 sft 工作才进入到了一个良性循环状态。
- 这里再额外说一个东西,我们的训练数据最好有一些“鲁棒性数据”:也就是 answer 很正常,但 prompt 表达很差劲的训练语料 。prompt 差指的是,它或者是有错别字,或者是话没说完整,亦或者是中文英文拼音夹杂着表达。不用担心会破坏模型效果,毕竟 prompt 根本不算 loss,这么做的目的是适应线上用户的糟糕表达,没有一个用户会希望听到“不是我们的模型不行,而是你 prompt 写的不行”这种观点(我试了一圈,糟糕 prompt 的理解能力,感觉国内模型和 GPT4 的差距挺大的)。鲁棒性数据可以直接从线上拉取,也可以手动修改原本的 prompt。切记给这类数据打上一个专属标签,千万别让新人看见之后直接给当成脏数据给清洗了
模型选择
有两种不同的基座模型分别是base和chat两个版本,我们要明白其中的不同:chat=base+sft,在模型选择中有如下准则:
- 垂域和基模型差异过大,选择base版本,可以先进行知识注入再进行指令微调
- 资源不充足下,采用chat版本具有一定的对话能力
- 数据限制:数据小于10k,选择chat版本,数据大于100k,选择base版本
训练参数选择
大佬:其实也没啥说的,翻来覆去那几句话:小模型大学习率,大模型小学习率,epoch 基本上就是 1~3个,数据是 10W 级别左右,稍点多点都行,但少不能少于 1W,多也不能到达 100W (没有理论,数据量是偏经验的一些结论);起始训练适当做点 warmup,几种主流的 lr_scheduler 都试一下
在微调大语言模型时,几个关键参数会直接影响模型的表现和训练效果。下面是对常见微调参数的解释:
- 学习率 (Learning Rate):这是控制模型权重更新步幅的参数。学习率决定了每次权重更新的幅度,设置较大时会加速模型迭代,但是模型可能无法收敛到最优点;设置过小时会使得模型迭代较慢,可能陷入局部最优。按照经验来讲, LORA 训练选择 learning rate 在 1e-5 ~ 2e-5。
- 合适的损失曲线:训练过程中可能会有波动,但整体是呈现一个下降的趋势,一般模型微调后,最终的训练集损失降低到1以下是合适的,特别低可能会过拟合,但一般使用特定领域知识做微调的话,建议往先过拟合靠拢,优先保证模型能精准回答知识库中的内容。
- 无规律波动且不收敛:一般是learningRate太大导致,无法呈现稳定的下降趋势,如果训练中出现这个趋势持续到3~5轮,可以提前关闭训练任务,尝试将学习率learningRate降低一个数量级。
- 训练轮次 (Epochs):指整个训练数据集被输入模型的次数。Epoch设置可以根据loss收敛情况设置,此外Epoch数量的设置和SFT数据的量级成反比,如果SFT样本较少,可以设置较大epoch,在较小的epoch上loss会不收敛,指令都很难遵循。较大epoch会容易导致过拟合,但过拟合要优于欠拟合。如果SFT样本数量较多,如在十万以上,一般2个epoch即可收敛。
- 在指令微调阶段,不建议进行过多轮次的训练。针对少量数据进行多个epoch的训练,可能会导致模型的关键区域发生变化,从而影响整体性能。为了保证模型语言能力关键区不被大幅度调整,需要在指令微调过程中添加通用指令数据或者预训练数据。
- epoch 越多,就是对特定训练集死记硬背,适合硬知识。如果是为了学习软知识,比如逻辑知识 类似于“如果碰到xx,就xx”,则应该靠多样化的数据集,而不是扩大epoch,很容易过耦合。
- 模型训练轮数,通常选择2~5,可以根据验证集 loss 曲线来判断:如果训练集 loss 曲线下降,验证集loss 曲线上升,则说明模型已经过拟合,此刻应该停止训练;如果训练集和验证集 loss 曲线均在缓慢下降,则说明模型还未收敛,可以继续训练。此外,对于文案生成,小说创作等生成类任务,由于某些上下文逻辑及风格不能通过 loss 体现,所以不应仅看 loss 来决定模型何时停止训练,按经验来说,通常生成类任务 epoch 数可以略微设置大一点,如5~10范围内。
- 刚开始训练时,模型的权重是随机初始化的,如果选择一个较大的学习率,可能会带来模型的不稳定(震荡)。warmup预热学习率的方式,在训练开始的时候先选择使用一个较小的学习率,训练一些epoch或者step之后,等模型相对稳定后,再修改为预先设置的学习率开进行训练。对于复杂的模型,可能需要更长的warm-up时间来适应训练过程,因为这些模型可能更容易受到初始学习率的影响。如果数据集很大,可能不需要太长的warm-up时间,因为模型有足够的数据来快速适应。num warmup steps 和 warmup step rate:二者设置一个即可,通常不需要调整。当遇到模型在 SFT 训练开始时,loss 始终不降的问题时,可尝试调大 warmup step rate,再观察 loss 是否按预期下降。
- warmup_ratio很重要。通常LLM训练的warmup_ratio是epoch * 1%左右。例如pre-train阶段一般只训一个epoch,则ratio是0.01;SFT通常3个epoch,ratio对应为0.03。如果你的数据集很大,有几百b,那warmup其实不影响最终的模型效果。但通常我们的数据集不会有那么大,所以更小的ratio可以让模型“过渡”得更平滑。我甚至试过3个epoch的训练(SFT),第一个epoch全部用来warmup,结果是work的。所以学习率和warmup_ratio是两个相辅相成的概念,二者通常是成正比的关系。或者说如果你正在用一个较大的学习率,那你或许可以同时尝试增加warmup来防止模型“烂掉”。请勿迷信3个epoch的训练,实测1个epoch就能对话。当然,更多的epoch确实会让模型的评测效果更佳。如果数据量比较小,如只有1k,可以尝试更多的epoch。无他,人为过拟合而已。
- 批处理大小 (Batch Size):这是每次更新模型权重时使用的数据量。较大的批处理大小能更稳定地更新权重,但需要更多的内存资源;较小的批处理大小则训练速度较慢,但内存需求更少。
- lora alpha和 lora rank:alpha 参数将模型权重进行放缩,rank 决定了 lora 训练参数量的大小,我们推荐二者参数设置为同一值。通常来讲,对于较简单的任务,推荐设置 lora alpha 和 lora rank 64或者128;对于较复杂的任务,推荐设置 lora alpha 和 lora rank 为256或者512。
效果评估
有两类评估方式:1)训练过程中观察loss指标;2)发布服务后在真实评估集上评估。
- loss 指标:一般观察在训练集和验证集上的损失来评估模型精调的效果。
- 欠拟合,模型没学好训练数据,做下游任务的能力很差,欠拟合首先要确定一个问题,是真的连训练数据都没学会,还是说学会了训练数据但无法进行泛化。测试方法也很简单,直接让模型回答训练集,如果这个都答不上来,那就是没学会,再多训 1 个 epoch,多补充一些 task_type 的训练数据,学习率适当调整等方法均可以解决这个问题。,如果说训练集学会了,测试集完全不会,那相对麻烦一些。因为我们需要确定模型能不能做好这个 task_type,还是说 answer 是否干净或 answer 的表达方式是否合理。模型能不能做好这个 task_type 需要结合一些主观判断,我们需要知道什么任务是难任务,诸如复杂指令、逻辑推理、数学计算等任务,很可能这个 size 的模型压根就不行。此外,别人家的孩子成绩好可不代表自家孩子成绩好,很可能自己的模型就是在 pretrain 阶段欠缺某 task_type 的基础知识,还是那个例子,pretrain 阶段没学过唐诗宋词,sft 阶段训再多作诗数据也没用啊。如果不知道 pretrain 阶段模型的学习情况,那就多让它续写一下这个 task_type 相关的语料,看看掌握程度,最好也和开源的 base 模型对比一下。假设模型具备这个 task_type 的基础知识,且该任务也不算很难,那大概率就是数据的问题了。抽样一些 answer 去 check 质量,不仅仅是回答的是否准确,还要看回答是否符合语言模型。这里一定要读慢一点,一个字一个字的读,看看 answer 里是不是每一句都有逻辑 —— 很多话只是读着通顺但表达很差劲,人能理解并不代表模型能理解。check 完之后,觉着数据质量也挺 OK 的话,那就只能再多造点训练数据了,或者上采样一下已有的训练数据(别的数据训 3 遍,这个数据训 6 遍)。至此,如果还是解决不了欠拟合问题,那就只剩一个杀手锏了:重写 prompt。意思就是,把这个 task_type 里的 answer 的知识尽可能的削减,prompt 里的背景知识则尽可能的增加,甚至可以把 answer 中常用到的 token 都以某种表达方式写进 prompt 里,提高生成这些 token 的概率。也就是说,我们要想方设法的减少这个任务的复杂程度,把一道高考考题改成中考难度,模型总该会了吧。
- 过拟合,我认为 sft 过拟合并不是一个坏现象,至少格式过拟合肯定不是,我们怕的是模型对 answer 内容过拟合,不管什么 question 都只会车轱辘的重复一个 answer。模型训得太狠了,对训练集里面的 answer / pattern 记得太死了。相比于欠拟合,过拟合则好解决很多,至少模型已经具备了这个 task_type 的能力,只不过是能力被限制在一些 token 或者一些 pattern 上了而已,想办法缓解即可。主要的解决方案是通过优化训来数据来缓解过拟合,主要措施是删减对应 task_type 的数据,或是扩充该 task_type 的数据多样性。过拟合的难点是让模型暴露出来它到底对什么过拟合了,好让我们去 grep 对应的训练数据来做修改。比如日本的首都是北京。首先,通过让 base 模型续写,判断是不是 pretrain 阶段训错了(通常情况下都不是),如果是的话,那没辙了,强行在 sft 阶段做知识注入来扭转 pretrain 的错误知识吧,一两条语料影响应该不会很大;然后,判断 sft 模型对哪个 pattern 过拟合了,对 answer 里面的核心关键词进行测试,也就是“日本”,“首都”,“北京”。对着我们的模型发出一连串的提问,美国的首都是哪里?日本最大的城市是哪里?北京是谁的首都?日本的首都是北京吗?日本的首都是东京吗?……目的很简单,测试出来模型到底对哪个 token,哪个 pattern 过拟合了,到底是把日本的所有城市都回答成北京,还是把所有国家的首都都回答成北京。进而 grep,大概率类似 pattern 的语料都过多了。这时候或删除该 pattern 的语料,或改造该 pattern 的语料,都无所谓了。
- 真实评估集:发布服务后评估业务指标。 针对这两种评估方式,在不同的任务有不同的侧重点。我们把任务分成两类:确定性任务和生成式任务。我们把 label 准确的任务称为确定性任务,如分类任务、提槽类等任务。相反地,比如参考问答、文案生成或角色扮演对话类我们称为生成式任务。
- 确定性任务:在这类任务上,我们主要关注训练集和验证集上的损失是否同步在下降,以及训练多个 epoch 后loss 是否收敛。下图应该算是一个比较良好的训练过程,训练集和校验集损失同步下降,且训练集损失也接近收敛。
- 生成式任务:在这类任务上,我们还是主要依赖观察训练集上的损失以及真实评估集上的业务指标。因为某些时候,尽管校验集的 loss 损失没有明显的下降,但其实真实评估集上也可能有收益。这是因为,验证集上 loss 计算依赖 token 级别的KL散度损失,而真实评估集上并不需要输出分布和 label 完全一致。所以,对于这类任务,我们建议将训练集损失作为参考,以真实数据集上评估后的结论为准。
不同于 pretrain 的评估只需要看知识能力,sft 的评估是需要看经典的 3H 原则的:Helpfulness、Honesty、Harmlessness。当然,实际工作的评估中,倒也不必完全是按照这三个原则进行评估,可以按需求制定自己模型的指标:是否 follow 指令,是否 system 穿透,是否内容准确,是否产生幻觉,是否安全……等等等等。评估的时候,每个维度都要有一个单独的得分,最后根据自己制定的加权公式来确定这条回复的可用性。这样,当模型在某个 case 上的得分变低的时候,我们能比较直观的看出来到底是哪个维度变差了,好结合训练数据做 case 分析。这里需要提醒一句,做评估的时候,一定要了解自己的整个 LLM 系统。
特定场景微调
rag
rag 的核心工作在于建库,知识库检索的准确性决定了这个工作的上限。此外,rag 需要外挂两个模型:
- 知识 / 聊天二分类模型,用于判别该不该做 rag。不要纠结说自己的模型知道世界最高山是什么,这个知识不用做 rag。你根本没办法测出来哪些知识是模型具备且正确的,所以是知识问题就必须做 rag;
- 传统的 IR 模型,快速从库里面进行检索出候选候选文档,没太多说的,老 NLP 技能了。 rag 的训练 sft 数据构造主要有几个细节需要留意:
- 检索内容为空的时候模型会怎么回复,别让它自由发挥出一些奇怪的结果;
- 检索内容相互矛盾的情况,别让他只盯着第一条 / 最后一条的内容回复;
- 检索内容和 query 完全无关的情况,也是需要让模型见过,防止出奇怪的结果;
- 检索内容错了。那就让模型照着错的答案念,千万别想着让模型自己判断 rag 的知识和自己的知识谁更正确。我们做 rag 的大前提就是默认“数据库知识准确率高于模型自己具备5. 的知识”。这种取巧心理很容易把模型搞迷糊,到时候模型不 follow rag 内容就麻烦了。
Agent / function_call
我个人喜欢把 agent 和 function_call 理解为同一个东西,后者是前者的主要实现形式。实现起来真的也没什么复杂的,就是在 system 里加上一句这样的表达:“遇见数值计算任务你就输出 <special_token> + 调计算机”,然后再构造类似的数据就行了。也就是说,在我们的训练数据里,除了有system,user,assistant 之外,还要有“调计算机”,“计算机返回结果”这两个轮次。如果需要其他的 function,就在 system 里写,在训练数据里补充对应样本。
长文本
为什么只需要一点点语料就能让模型适应新的基底,有没有数学大佬看见了科普一下)。因为 attention 的计算量和数据长度呈平方关系,所以显存会不够用,训练的时候要使用 sequence_parallel 技术。数据的话,想方设法构造长文本理解数据吧,不能是短数据 concat 的,前面说了模型有偷懒倾向,所以我们需要让模型不知道候选答案会出现在 200K prompt 的哪个位置。paper 数据,书籍数据,甚至是 RAG 数据都是比较好的长文本数据胚子。
- 简单的长文本任务就是“背密码”,随机把密码插入到 200K 文本的任意一个位置让模型来复述;
- 复杂点的长文本任务就可以是让模型概括 paper 的 instruction 内容,让模型列举出所有林黛玉出场的章节;
- 挑战性的任务则直接让模型去算林黛玉的出场次数。
复杂指令
复杂指令通常指的是“prompt 里包含了非常多的限制”:既要不少于多少字,又要在什么什么场景下插入 emoji,说话还要押韵,时不时还要模型自己输出一些 special_token ……
具体怎么做,说实话我也不是特别知道,我就是一股脑的堆 sft 数据,但我之前的一个同事好像在用 rlhf 来解决这个问题。这个怎么说呢,目前的技术路线还不明晰,我个人觉着做好复杂指令必须要借助 cot 或者自我纠错能力。模型在 next_token_prediction 的时候,很难找到一个完美 token 满足所有的限制条件,所以要么提前 cot 打好草稿,要么让模型意识到“已经输出的结果不可能再满足某个限制条件”时进行纠错。所以我觉着,o1 的技术路线可能就是复杂指令的正确解法。
在 o1 的技术路线成熟之前,我觉着硬造 sft / rlhf 的数据,应该也能凑合着应付大多数用户需求。这里分享一个造数据的小技巧:先射箭,再画靶。意思就是:你搞了一个很复杂的 prompt ,但即使是 GPT4 的回复,也没有 follow 所有的限制,那怎么办呢?重写答案是很麻烦的,所以就直接去修改 prompt。原本的 prompt 要求模型输出不少于 200 字,实际上只输出了 189 个字,那就把 prompt 改成不少于 180 字(很多复杂指令模型模型根本无法精准回复,限制输出字数这种本来就是学个大概,没必要特别认真,改改 prompt 凑合着用就行了)。
low-level 微调代码
由于 sft 的训练语料不是很多,使用 deepspeed / megatron 的训练代码都可以,速度性能上的差异也就是带来一个小时左右的时间,无伤大雅。
手写
自己写正向传播、反向传播、更新权重。
- 加载数据集,pytorch Dataset/DataLoader
- 构建模型,在实际操作中,除了使用预训练模型编码文本外,我们通常还会进行许多自定义操作,因此在大部分情况下我们都需要自己编写模型,不过不用从0写,更为常见的写法是继承 Transformers 库中的预训练模型来创建自己的模型。
class BertForPairwiseCLS(BertPreTrainedModel): # 继承 BERT 模型(BertPreTrainedModel 类) def __init__(self, config): super().__init__(config) self.bert = BertModel(config, add_pooling_layer=False) self.dropout = nn.Dropout(config.hidden_dropout_prob) self.classifier = nn.Linear(768, 2) self.post_init() def forward(self, x): bert_output = self.bert(**x) cls_vectors = bert_output.last_hidden_state[:, 0, :] cls_vectors = self.dropout(cls_vectors) logits = self.classifier(cls_vectors) return logits config = AutoConfig.from_pretrained(checkpoint) # 通过预置的 from_pretrained 函数来加载模型参数 model = BertForPairwiseCLS.from_pretrained(checkpoint, config=config).to(device) # 加载 预置模型 print(model) # Transformers 库同样实现了很多的优化器,相比 Pytorch 固定学习率,Transformers 库的优化器会随着训练过程逐步减小学习率(通常会产生更好的效果) optimizer = AdamW(model.parameters(), lr=learning_rate) def train_loop(dataloader, model, loss_fn, optimizer,...): ... def test_loop(dataloader, model, mode='Test'): ... for t in range(epoch_num): total_loss = train_loop(train_dataloader, model, loss_fn, optimizer, lr_scheduler, t+1, total_loss) valid_acc = test_loop(valid_dataloader, model, mode='Valid') if valid_acc > best_acc: best_acc = valid_acc print('saving new weights...\n') torch.save(model.state_dict(), ...) # # 保存模型
使用huggingface的Trainer API进行模型微调
transformer 支持自定义dataset,自定义model实现forward(forward 支持的参数均可以作为dataset的column),forward 过程中还计算loss,模型的差异性基本已经兜住了,这也是为何 只要提供包含特定column的dataset,剩下的训练代码都可以交给trainer封装掉。
在我们定义 Trainer 之前首先要定义一个 TrainingArguments 类,它将包含 Trainer用于训练和评估的所有超参数,也内置了Accelerate和deepspeed等支持。唯一必须提供的参数是保存训练模型的目录,以及训练过程中的检查点。对于其余的参数,可以保留默认值。
from transformers import TrainingArguments
raw_datasets = load_dataset("glue", "mrpc")
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
training_args = TrainingArguments("test-trainer")
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
不用trainer,纯手工实现训练过程,也是trainer帮我们自动化的部分
raw_datasets = load_dataset("glue", "mrpc")
# data preprocessing
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
tokenized_datasets = tokenized_datasets.remove_columns(["sentence1", "sentence2", "idx"])
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch")
## tokenized_datasets column_names: ["attention_mask", "input_ids", "labels", "token_type_ids"]
train_dataloader = DataLoader(
tokenized_datasets["train"], shuffle=True, batch_size=8, collate_fn=data_collator
)
eval_dataloader = DataLoader(
tokenized_datasets["validation"], batch_size=8, collate_fn=data_collator
)
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
## put our model and our batches on GPU
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler( # the learning rate scheduler
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps,
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
Fine-tuning a model with the Trainer APITransformers provides a Trainer class to help you fine-tune any of the pretrained models it provides on your dataset. Once you’ve done all the data preprocessing work in the last section, you have just a few steps left to define the Trainer. The hardest part is likely to be preparing the environment to run Trainer.train()
from datasets import load_dataset
from transformers import AutoTokenizer, DataCollatorWithPadding
raw_datasets = load_dataset("glue", "mrpc")
checkpoint = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
def tokenize_function(example):
return tokenizer(example["sentence1"], example["sentence2"], truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
from transformers import TrainingArguments
training_args = TrainingArguments("test-trainer")
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
from transformers import Trainer
trainer = Trainer(
model,
training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
# To fine-tune the model on our dataset, we just have to call the train() method of our Trainer
trainer.train()
A full training 手写train loop。
high-level 框架
huggingface transformer库虽然已经支持的很全了,但代码量还是很大,所以出现一批框架比如Llama。
from llama import BasicModelRunner
model = BasicModelRunner("aaa/bbb")
model.load_data_from_jsonlines("xx.jsonl")
model.train()
随着时间的推移,采用了越来越高级的接口,训练的代码已经大大简化。
四个大模型轻量级微调训练框架:兼看PPT转Markdown工具 建议把这几个框架Firefly/LLaMA-Factory/unsloth/SWIFT(阿里开源的LLM训练评估框架)都看下,找找共性。
LLaMA-Factory
LLaMA-Factory
/src
/llmtuner
/train
/data
/loader.py # get_dataset
/preprocess.py # preprocess_dataset
/model
/loader.py # load_model_and_tokenizer
/dpo
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_dpo
/ppo
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_ppo
/pt
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_pt
/rm
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_rm
/sft
/trainer.py # 一些trainer 用到的函数
/workflow.py # run_sft
workflow.py 的逻辑言简意赅,就是拼凑运行 Trainer的dataset、model、tokenizer、data_collator等参数
- 对于dataset 有一个load_dataset 和preprocess_dataset 的过程,preprocess_dataset 会根据任务目标不同,处理逻辑不同,也就是将数据转为input_ids 的方式不同。 最终转为trainer 也就是transformer model 可以接受的dataset,包含列 input_ids/attention_task/labels(或其它model.forward 可以支持的参数)。 PS: 对于有监督任务,比如包含name=labels 列,至于input 列则名字随意,毕竟input text 总有一个通过tokenizer 转为input_ids 的过程。传入trainer的 dataset 有input_ids 和labels等列即可。
- Trainer 对训练逻辑已经封的很好了,内部也支持了accelerate 和 deepspeed,只要合适的配置 training_args 即可。
以pt对应的workflow.py 为例
def run_pt(model_args: "ModelArguments",data_args: "DataArguments",training_args: "Seq2SeqTrainingArguments",finetuning_args: "FinetuningArguments",callbacks: Optional[List["TrainerCallback"]] = None):
dataset = get_dataset(model_args, data_args)
model, tokenizer = load_model_and_tokenizer(model_args, finetuning_args, training_args.do_train, stage="pt")
dataset = preprocess_dataset(dataset, tokenizer, data_args, training_args, stage="pt")
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
trainer = Trainer(model,training_args,tokenizer,data_collator,callbacks,**split_dataset(dataset, data_args, training_args)
# Training
if training_args.do_train:
train_result = trainer.train(resume_from_checkpoint=training_args.resume_from_checkpoint)
trainer.log_metrics("train", train_result.metrics)
trainer.save_metrics("train", train_result.metrics)
trainer.save_state()
trainer.save_model()
if trainer.is_world_process_zero() and model_args.plot_loss:
plot_loss(training_args.output_dir, keys=["loss", "eval_loss"])
# Evaluation
if training_args.do_eval:
metrics = trainer.evaluate(metric_key_prefix="eval")
perplexity = math.exp(metrics["eval_loss"])
metrics["perplexity"] = perplexity
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
不管是PreTraining阶段还是SFT阶段,loss函数都是一样的,只是计算的方式存在差异,PreTraining阶段计算的是整段输入文本的loss,而SFT阶段计算的是response部分的loss。
- preprocess_pretrain_dataset处理PreTraining阶段的数据,数据组成形式:
- 输入input:
<bos> X1 X2 X3 - 标签labels:
X1 X2 X3 </s>典型的Decoder架构的数据训练方式;
- 输入input:
- preprocess_supervised_dataset处理SFT阶段的数据,数据组成形式:
- 输入input:
<bos> prompt response - 标签labels:
-100 ... -100 response </s>对于prompt部分的labels被-100所填充,这样在计算loss的时候模型只计算response部分的loss,-100的部分被忽略了。这个机制得益于torch的CrossEntropyLossignore_index参数,ignore_index参数定义为如果labels中包含了指定了需要忽略的类别号(默认是-100),那么在计算loss的时候就不会计算该部分的loss也就对梯度的更新不起作用。
- 输入input:
PS: 深度学习都得指定features/labels。在llm 场景下,features 和labels 有几个特点
- llm 有base model、sft model 等,不同的model 数据集格式不同,一般分为几个部分,比如sft 的
{"question:":"xx","answer":"xx"},各家模型都不太一样,很多数据集是不公开的。但不管如何,这几部分都会拼为一个sentence(中间可能有一些特殊字符起到连接作用),然后把sentence通过tokenizer转换成input_ids,之后再走embedding 模块等等就是Transformer系列模型内的事儿了,最后得到output_ids. - 模型输入格式,模型输入dict 一般包含3个key: input_ids,attention_mask,labels
- 有些模型内置从input ids 提取attention mask的操作
- 预训练场景 labels 一般由input_ids copy而来,然后做一些处理,比如labels 全部左移一位(预训练)
- 明确指定labels 的话,一般是要微调,比如sft时,sentence部分中question 的位置都置为-100(有文章称为ignore_index),-100表示在计算loss的时候会被忽略,这个由任务性质决定。
- 预处理(将dataset 转为模型输入)过程由 Dataset.map() + tokennizer 来办。
def tokenize_function(example): # example 表示数据集中的一行数据 return tokenizer(example["sentence1"], example["sentence2"], truncation=True) tokenized_dataset = dataset.map(tokenize_function, batched=True) - 之后就是对output_ids 和 labels 计算loss。
页面操作
基于LLaMA-Factory框架对Qwen2-7B模型进行微调实践
工程
如果你有10个任务,训练了10个Lora模型,并且将每个Lora参数都Merge回了原来基模的参数中,构成了一个新的模型,那么你在后期模型部署的时候,你想当与需要10份部署资源。假如部署一个7B模型需要一个24G的3090显卡,那么你现在就需要10张3090显卡。同时如果模型很大,部署过程中,模型Copy、上传的时间也会非常久,会带来很多不必要的等待时间。但是你如果利用多Lora加载模型的话,那么10个Lora模型+一个7B基座模型,一张3090显卡就能加载。
vLLM多Lora模式加载
from vllm import LLM, SamplingParams
from vllm.lora.request import LoRARequest
from transformers import AutoTokenizer
# 样例
prompts = ["你是谁?", "你是谁训练的?"]
# 设置生成所需参数
sampling_params = SamplingParams(temperature=0.7, top_p=0.8, top_k=50, max_tokens=2048)
lora_request1 = LoRARequest("self_adapter_v1", 1, lora_local_path="output_dir_qwen2.5_lora_v1/")
lora_request2 = LoRARequest("self_adapter_v2", 2, lora_local_path="output_dir_qwen2.5_lora_v2/")
# 创建模型
llm = LLM(model="Qwen2.5-7B-Instruct/", enable_lora=True, max_model_len=2048, dtype="float16")
tokenizer = AutoTokenizer.from_pretrained("Qwen2.5-7B-Instruct/")
# 通过prompts构造prompt_token_ids
temp_prompts = [tokenizer.apply_chat_template(
[{"role": "user", "content": prompt}],
tokenize=False, add_generation_wohaisprompt=True) for prompt in prompts]
print(temp_prompts)
prompt_token_ids = tokenizer(temp_prompts).input_ids
# 注意,generate可以直接使用prompts,但直接使用prompts时,默认直接使用tokenizer.encode,没有拼接chat_template
print("加载自我认知Lora1进行模型推理:")
# 调用generate时,请求调用lora参数
outputs = llm.generate(sampling_params=sampling_params, prompt_token_ids=prompt_token_ids,
lora_request=lora_request1)
print(outputs)
# 输出结果
for i, (prompt, output) in enumerate(zip(prompts, outputs)):
generated_text = output.outputs[0].text
print("prompt: {}, output: {}".format(prompt, generated_text))
print("加载自我认知Lora2进行模型推理:")
# 调用generate时,请求调用lora参数
outputs = llm.generate(sampling_params=sampling_params, prompt_token_ids=prompt_token_ids,
lora_request=lora_request2)
print(outputs)
# 输出结果
for i, (prompt, output) in enumerate(zip(prompts, outputs)):
generated_text = output.outputs[0].text
print("prompt: {}, output: {}".format(prompt, generated_text))
print("不加载自我认知Lora进行模型推理:")
# 调用generate时,请求调用lora参数
outputs = llm.generate(sampling_params=sampling_params, prompt_token_ids=prompt_token_ids)
print(outputs)
# 输出结果
for i, (prompt, output) in enumerate(zip(prompts, outputs)):
generated_text = output.outputs[0].text
print("prompt: {}, output: {}".format(prompt, generated_text))
其它
sft 的局限性 非常经典
- sft 的训练过程,是一个让模型学习条件概率的过程,
Prob( E | ABCD )。这也就是说,模型在训练和学习过程中,只知道 next_token 出什么是正确的,而不知道 next_token 出什么是错误的。无论你的 sft 语料如何构造,都无济于事,模型不知道“什么 token 是不能生成的”。这也间接解释了另外一个现象:为什么 sft 的数据多样性很重要。因为没办法, 我们无法直接让模型知道错误的 token 是什么,但只要我们把正确的 token 都喂给它学习,孤立那个错误的 token,似乎也能起到类似的效果。sft 缺乏负反馈机制引发的糟糕后果,还远不止此。你越是在 sft 阶段告诉它什么是错误的,它越是容易提高错误 token 的概率。站在模型的角度来思考,这个现象非常合理:“训练者不断让我提高Prob( E | ABCD )的概率,那我举一反三,顺带提高一下Prob( E | ACD )的概率是不是也合理?训练者是不是应该表扬我?”可问题是,好巧不巧,B 这个 token,恰好是“not”,恰好是“不”。这里问一个我曾经被问过的问题,“一句绝对正确的话,是不是可以放进 sft 训练语料中?”我的观点是:不应该,因为一句绝对正确的话,它可能有局部是不正确的,这些局部错误的知识内容也会在 sft 的过程中被模型学到。 - sft 没有负反馈,但 rlhf 有啊。reward_model 就像是一个教官,你敢续写出某个不能出的 token,我就抽你,抽到你不敢出这个 token 为止。这可能也是为什么 rlhf 的最大应用方向是安全场景吧,毕竟 sft 真的做不好安全。
- sft 不具有“向后看”的能力。sft 的另一个不足,就是它放大了 transformer 单向注意力结构的缺陷。在 sft 的训练过程中,每一个 token 都只看得见前面的 token。还是那个经典例子,“台湾不是中国的,这个观点是严重错误的”。无论你用什么炼丹技巧来做 sft,Prob(中国 | 台湾不是) 的概率都是在增加的,模型无法利用“后半个句子在否定前半句子”这个重要信息。那 rlhf 是怎么学习这句话呢?首先这句话是正确的,他会得到一个正向的 reward_model,但这句话中的每个 token 又不是同等正确的。如果对 critic_model 进行可视化,它大概率会在 reward 反向衰减传递的时候,把最大的奖励赏赐给“错误 ”这个 token,而“中国 ”这个 token 可能并不会得到很多的 reward。所以,sft 在更新某个 token 的概率的时候,是只参考前面信息的,是一种局部的有偏的训练方法。但 rlhf 或者 dpo 并不是这样,每一个 token 在更新概率的时候,都是观察到了整个 sentence 的,因而理论上,rlhf 的训练方法能带来更高的训练上限。换一个角度来说,sft 的 loss 是平均 loss, rlhf 的 loss 是加权 loss。至于怎么加权,去问 reward_model 和 critic_model。 综上所述,我个人认为,除非 sft 的训练方式发生改变(比如每个 token 的 loss,不再是算术平均),否则 rlhf 还是一个不可取代的环节。
留下评论