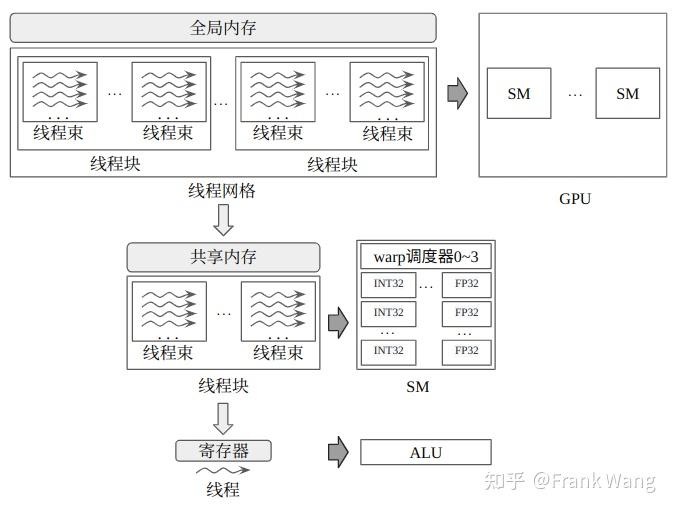
GPU入门
简介
针对计算性能,1974年Dennard等人提出了Dennard缩放比例定律(Dennard Scaling)。Dennard 缩放比例定律 (Dennard Scaling) :当晶体管特征尺寸缩小时,其功率密度保持恒定。具体表现为电压随特征尺寸线性下降,电流密度保持稳定,使得单位面积的功耗与晶体管尺寸成比例关系。 一言以蔽之:晶体管越小越省电。推导到芯片设计领域:晶体管缩小,芯片能塞入的晶体管更多,同时保持整体能耗稳定,推动计算机性能持续提升。在计算机发展的前四十年间,基于Dennard定律的晶体管微缩是提升性能的主要路径。但在2005-2007年间,随着晶体管进入纳米尺度,量子隧穿效应引发的漏电流呈指数增长,阈值电压难以继续降低,最终导致该定律失效。此时,工艺微缩带来的性能增益已无法抵消功耗的快速增长,著名的”功耗墙”问题开始显现。单纯依靠缩小晶体管尺寸来提升性能的方法不再可行,部分工程师开始转向专用硬件,即专门为了某种或某几种计算设计的计算硬件,例如Google的TPU(Tensor Processing Unit,张量处理器),就是一款专为加速机器学习任务而设计的专用硬件。然而,专用计算硬件只能聚焦于某一类或者某几类特定的计算任务,在处理其他任务时则可能力不从心。而GPU则是向通用性演进的典型代表。虽然其最初设计目标是为图形渲染加速,但高度并行的SIMT(单指令多线程)架构意外契合了通用计算的演进需求,无论是基于CUDA的深度学习训练,还是通过OpenCL加速的流体仿真,都能通过高度并行获得远超CPU的计算性能。
CPU 和 GPU - 异构计算的演进与发展世界上大多数事物的发展规律是相似的,在最开始往往都会出现相对通用的方案解决绝大多数的问题,随后会出现为某一场景专门设计的解决方案,这些解决方案不能解决通用的问题,但是在某些具体的领域会有极其出色的表现。
GPU 的架构;内存管理;任务管理;数据类型。
内存将数据传输到CPU大概每秒大概传输200GB(也就是每秒25G FP64),cpu 计算能力大概是2000 GFLOPs FP64,这两者的比值就是设备的计算强度。也就是cpu 每秒不对一个数据处理80次,cpu 就会空闲,但也没有什么算法需要对一个数据处理80次。当增加FLOPs速度比增加内存带宽的速度快的时候,计算强度就会上升。为什么?物理上光速 3亿米/秒,电脑时钟30亿Hz,在一个时钟周期,光只传播了10cm,电流在硅中的传播速度只有光的五分之一(6万公里/秒),物理实际上很复杂,根据经验,一个时钟周期内,电流的移动只有20mm。 CPU 的期望是一个线程基本完成所有工作,将这些线程从一个切换到另一个是非常昂贵的(上下文切换),cpu设计者把所有资源都投入到延迟上了。GPU 设计师将所有资源的都投入到增加线程中,而不是减少延迟。此外,gpu 使用寄存器缓存来解决高延迟问题,以及通过靠近数据来减少延迟(内存传输数据慢,cpu 没有忙起来,内存也没有忙起来)。gpu 选择增加线程,每个sm2048个线程,一次跑一批(warp)线程,当一些线程因为等待延迟关闭时,其它线程大概已经load好数据了准备运行了。这就是gpu工作的秘密,它可以在不同的warp之间切换,并且在一个时钟周期内完成,所以根本没有上下文开销。gpu 是一个吞吐量系统,总是超量分配线程,超量分配意味着总是在内存快的(指的是数据ready?)时候工作。(a grid represents all work to be done)所有要做的工作都被分解成线程块(the grid comprises many blocks with an equal number of threads),每个块都有并行线程,保证线程同时运行,这样它们就可以共享数据(threads within a block run independently but may synchrionze to exchange data)(机器学习有一些计算,比如all-to-all)。但所有的块都是在超量分配模式下独立调度的,这样才能两全其美。但它也允许一定数量的线程相互交互,这就是gpu编程的本质。PS:是不是可以认为,内存延迟高,这时为了cpu和内存提速(都别闲着),做大带宽,比如虽然10s传一次数据,但一次传10M,gpu 准备大量线程同时干活儿。后续有数据就干活儿,没干活儿就让位给另一批数据ready的线程。
GPU
GPU最初的使命是加速图形渲染。而渲染一帧图像,本质上就是对数百万个像素点进行相似的计算,这天然就是一种大规模并行任务。2001年NVIDIA发布GeForce 3,首次引入可编程着色器 (Programmable Shaders)。实质上允许开发者为 GPU 编写软件,让GPU的众多并行处理单元去同时执行,以精确控制光照和颜色如何加载到显示器上。这是朝着加速计算方向迈出的重要一步,因为它允许开发者直接为 GPU 编写软件。一批敏锐的研究人员意识到,GPU的本质就是一个拥有数百甚至数千个核心的大规模并行架构,其浮点运算吞吐量远超当时的CPU。他们的核心想法是:能不能用GPU进行科学计算? 开始探索利用GPU计算科学计算问题,从而利用GPU的算力。这便是GPGPU(通用计算GPU)的萌芽。但是门槛非常高, 需要开发者同时精通图形学和科学计算。NVIDIA敏锐地捕捉到了GPGPU的发展潜力,开始不再局限于加速图形渲染,主动拥抱GPGPU。2006年,发布了第一款为通用计算设计的统一架构GPU - GeForce 8800 GTX 显卡(G80架构)。它将GPU内部的计算单元统一起来,形成了一个庞大的、灵活的并行核心阵列,为通用计算铺平了硬件道路。2007年,NVIDIA正式推出了CUDA平台。CUDA的革命性在于,它提供了一套简单的编程模型,让开发者能用近似C语言的方式,轻松地驾驭GPU内部成百上千个并行核心。 开发者无需再关心复杂的图形接口,可以直接编写在数千个线程上并发执行的程序。至此终结了GPGPU编程的蛮荒时代,让GPU计算真正走下神坛,成为开发者触手可及的强大工具。
为图形而生
各种游戏里面的人物的脸,并不是那个相机或者摄像头拍出来的,而是通过多边形建模(Polygon Modeling)创建出来的。而实际这些人物在画面里面的移动、动作,乃至根据光线发生的变化,都是通过计算机根据图形学的各种计算,实时渲染出来的。
图像进行实时渲染的过程,可以被分解成下面这样 5 个步骤:
- 顶点处理(Vertex Processing)。构成多边形建模的每一个多边形呢,都有多个顶点(Vertex)。这些顶点都有一个在三维空间里的坐标。但是我们的屏幕是二维的,所以在确定当前视角的时候,我们需要把这些顶点在三维空间里面的位置,转化到屏幕这个二维空间里面。这个转换的操作,就被叫作顶点处理。这样的转化都是通过线性代数的计算来进行的。可以想见,我们的建模越精细,需要转换的顶点数量就越多,计算量就越大。而且,这里面每一个顶点位置的转换,互相之间没有依赖,是可以并行独立计算的。
- 图元处理。把顶点处理完成之后的各个顶点连起来,变成多边形。其实转化后的顶点,仍然是在一个三维空间里,只是第三维的 Z 轴,是正对屏幕的“深度”。所以我们针对这些多边形,需要做一个操作,叫剔除和裁剪(Cull and Clip),也就是把不在屏幕里面,或者一部分不在屏幕里面的内容给去掉,减少接下来流程的工作量。
- 栅格化。我们的屏幕分辨率是有限的。它一般是通过一个个“像素(Pixel)”来显示出内容的。对于做完图元处理的多边形,把它们转换成屏幕里面的一个个像素点。每一个图元都可以并行独立地栅格化。
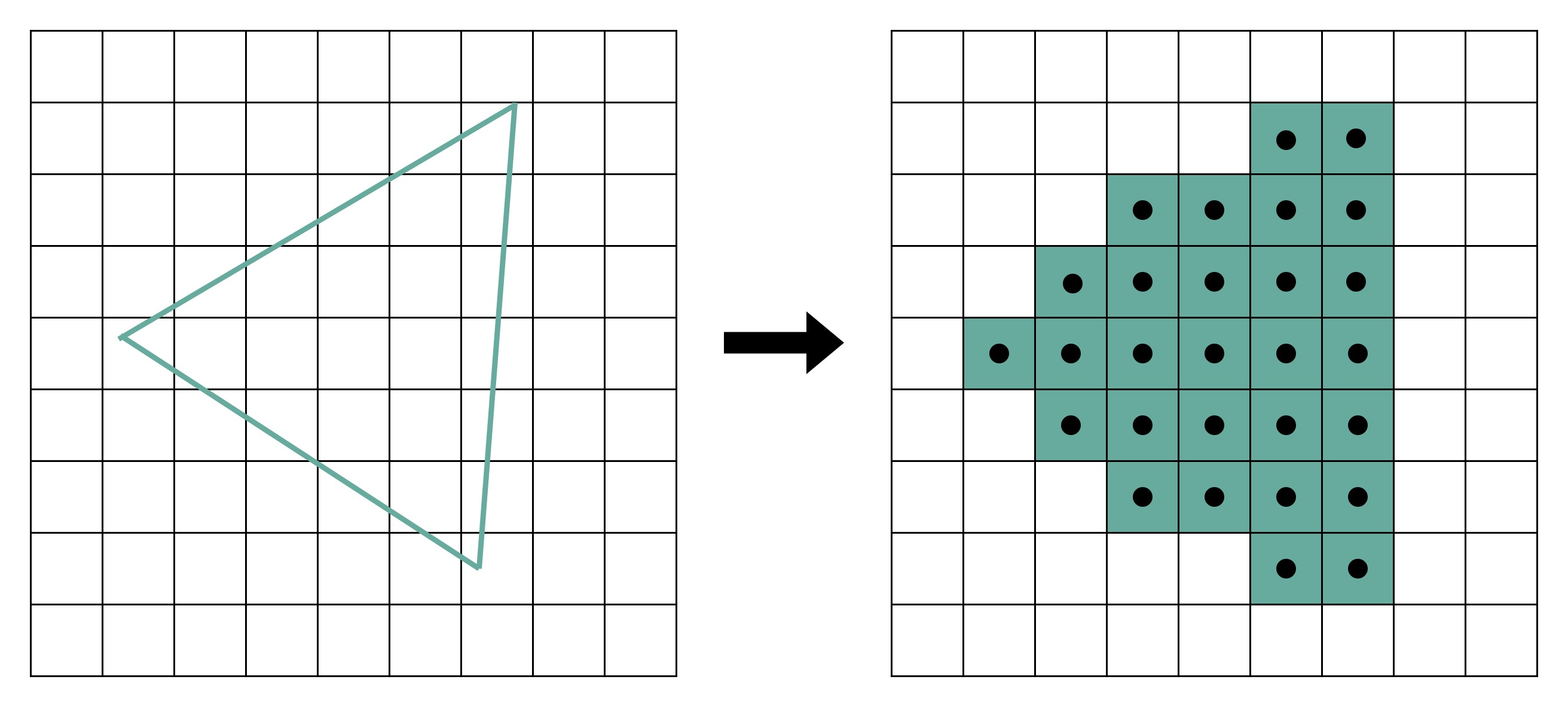
- 片段处理。在栅格化变成了像素点之后,我们的图还是“黑白”的。我们还需要计算每一个像素的颜色、透明度等信息,给像素点上色。
- 像素操作。把不同的多边形的像素点“混合(Blending)”到一起。可能前面的多边形可能是半透明的,那么前后的颜色就要混合在一起变成一个新的颜色;或者前面的多边形遮挡住了后面的多边形,那么我们只要显示前面多边形的颜色就好了。最终,输出到显示设备。
经过这完整的 5 个步骤之后,完成了从三维空间里的数据的渲染,变成屏幕上你可以看到的 3D 动画了。称之为图形流水线(Graphic Pipeline)。这个过程包含大量的矩阵计算,刚好利用了GPU的并行性。

GPU ==> GPGPU
现代 CPU 里的晶体管变得越来越多,越来越复杂,其实已经不是用来实现“计算”这个核心功能,而是拿来实现处理乱序执行、进行分支预测,以及高速缓存部分,竭力于不可预测代码的快速执行。而在 GPU 里,这些电路就显得有点多余了,GPU 的整个处理过程是一个流式处理(Stream Processing)的过程。因为没有那么多分支条件,或者复杂的依赖关系,我们可以把 GPU 里这些对应的电路都可以去掉,做一次小小的瘦身,只留下取指令、指令译码、ALU 以及执行这些计算需要的寄存器和缓存就好了。
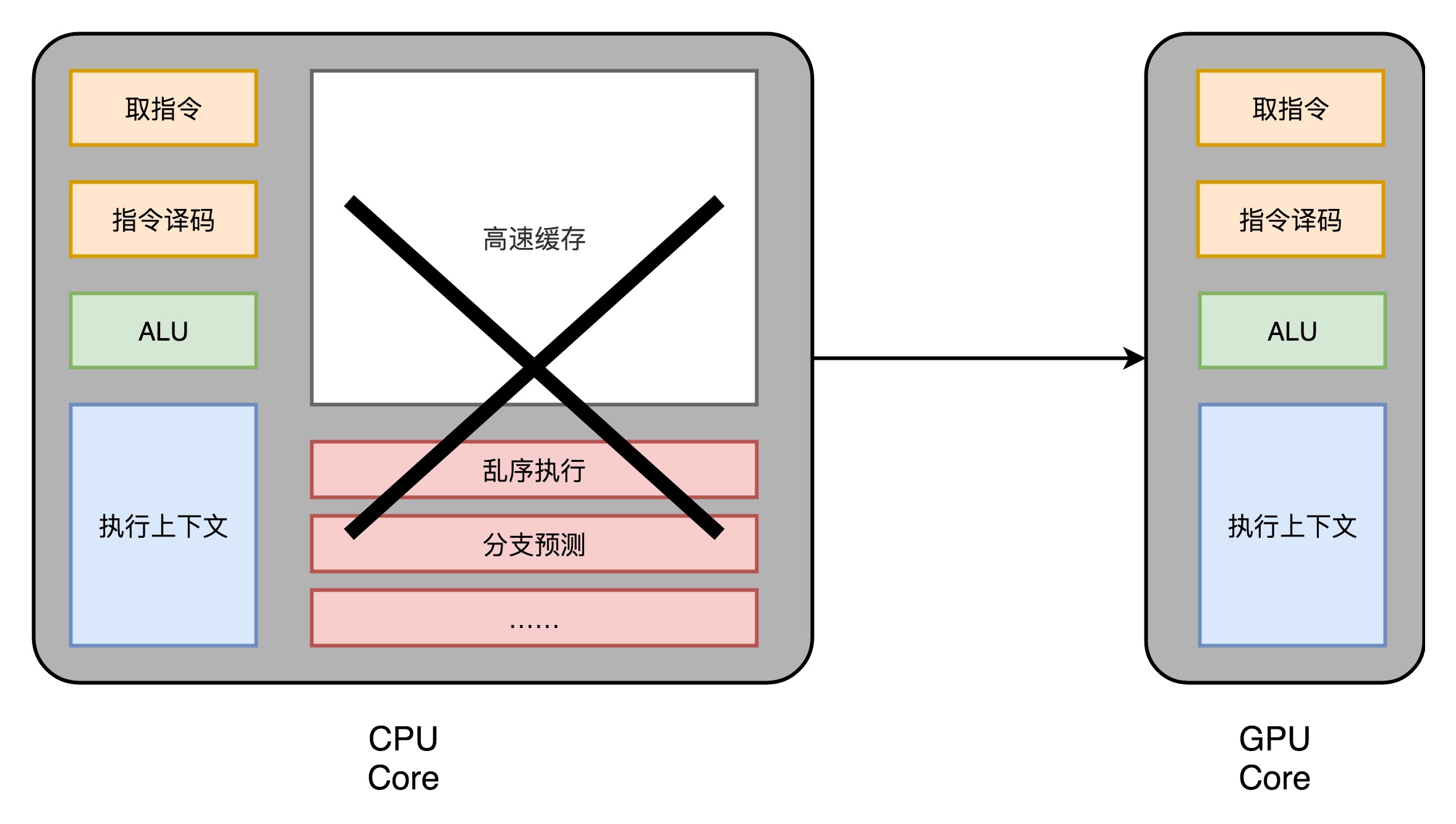
于是,我们就可以在一个 GPU 里面,塞很多个这样并行的 GPU 电路来实现计算,就好像 CPU 里面的多核 CPU 一样。和 CPU 不同的是,我们不需要单独去实现什么多线程的计算。因为 GPU 的运算是天然并行的。无论是对多边形里的顶点进行处理,还是屏幕里面的每一个像素进行处理,每个点的计算都是独立的。我们说 GPU 比 CPU 快,并不是因为 GPU 里的计算单元比 CPU 的高级,而是因为 GPU 里的计算单元更多。GPU 通过超额分配来优化吞吐量:创建足够多的线程,确保始终有任务可做。
一方面,GPU 是一个可以进行“通用计算”的框架,我们可以通过编程,在 GPU 上实现不同的算法。另一方面,现在的深度学习计算,都是超大的向量和矩阵,海量的训练样本的计算。整个计算过程中,没有复杂的逻辑和分支,非常适合 GPU 这样并行、计算能力强的架构。
TPU 通过确定性来优化吞吐量:提前调度所有操作,并通过构建方式保持管道满负荷运转。TPU 芯片是由少量的大模块组成,MXU 是一个脉动阵列(systolic array)。它没有硬件管理的 L1 或 L2 缓存。取而代之的是,每个芯片都拥有VMEM(矢量内存),这是一个大型的软件管理 SRAM 暂存区。
为什么深度学习需要使用GPU
为什么深度学习需要使用GPU?相比cpu,gpu
- gpu核心很多,比如CPU来讲它多少core呢?我看过前几天发布会有至强6的E系列最高288core的,那GPU呢,上一代H100是1万8。
- gpu内存带宽更高,速度快就贵,所以显存容量一般不大。因为 CPU 首先得取得数据, 才能进行运算, 所以很多时候,限制我们程序运行速度的并非是 CPU 核的处理速度, 而是数据访问的速度。
- 控制流,cpu 控制流很强,alu 只占cpu的一小部分。gpu 则要少用控制语句。CPU需要很强的通用性来处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU 里的晶体管变得越来越多,越来越复杂,其实已经不是用来实现“计算”这个核心功能,而是拿来实现处理乱序执行、进行分支预测,以及高速缓存。GPU 专门用于高度并行计算,面对的则是类型高度统一的、相互无依赖的大规模数据和不需要被打断的纯净的计算环境。因此设计时更多的晶体管用于数据处理,而不是数据缓存和流量控制。GPU 只有 取指令、指令译码、ALU 以及执行这些计算需要的寄存器和缓存。CPU 上不同线程一般是执行不同任务,GPU同一个block的线程执行的则是相同的kernel函数。PS: 将更多晶体管用于数据处理,例如浮点计算,有利于高度并行计算。我们一般习惯将cpu的控制单元和计算单元视为一个整体,而gpu 一般会独立看待控制单元和计算单元,所以觉得它们差别很大。
- 编程,cpu 是各种编程语言,编译器成熟。
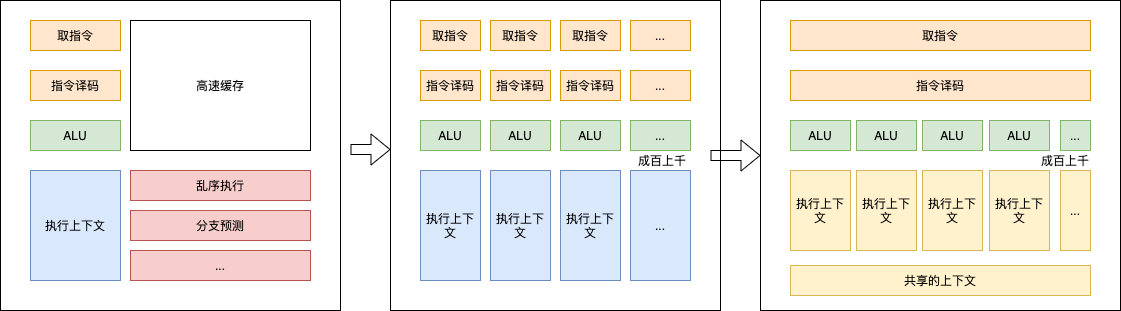
如图所示,CPU在芯片领域中主要用于降低指令时延的功能,例如大型缓存、较少的算术逻辑单元(ALU)和更多的控制单元。与此相比,GPU则利用大量的ALU来最大化计算能力和吞吐量,只使用极小的芯片面积用于缓存和控制单元,这些元件主要用于减少CPU时延。
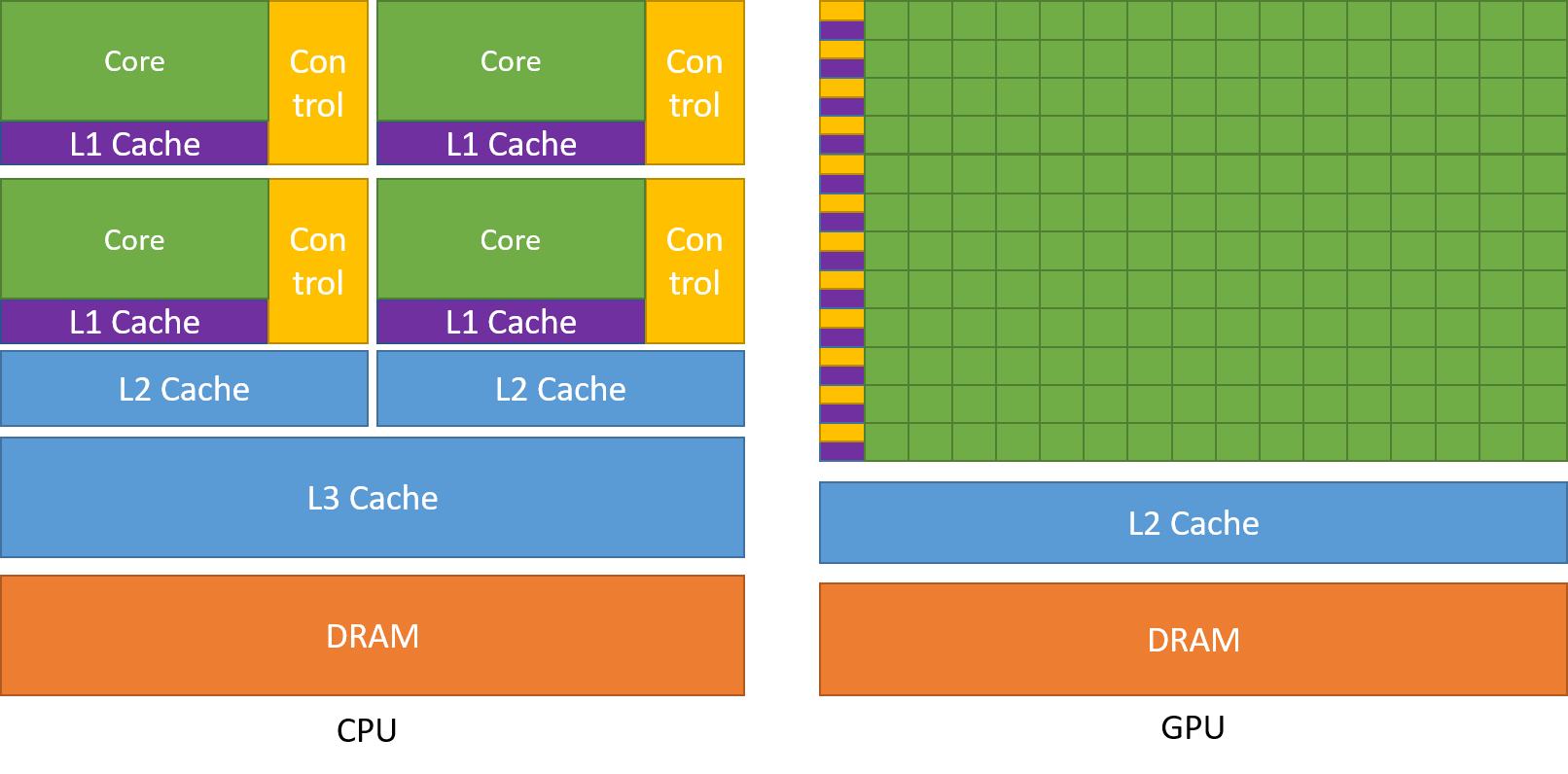
CPU / GPU原理与 CUDAGPU 一开始是没有“可编程”能力的,程序员们只能够通过配置来设计需要用到的图形渲染效果(图形加速卡)。在游戏领域, 3D 人物的建模都是用一个个小三角形拼接上的, 而不是以像素的形式, 对多个小三角形的操作, 能使人物做出多种多样的动作, 而 GPU 在此处就是用来计算三角形平移, 旋转之后的位置。为了提高游戏的分辨率, 程序会将每个小三角形细分为更小的三角形,每个小三角形包含两个属性, 它的位置和它的纹理。在游戏领域应用的 GPU 与科学计算领域的 GPU 使用的不同是, 当通过 CUDA 调用 GPU 来进行科学计算的时候, 计算结果需要返回给 CPU, 但是如果用 GPU 用作玩游戏的话, GPU 的计算结果直接输出到显示器上, 也就不需要再返回到 CPU。
深度学习的模型训练,指的是利用数据通过计算梯度下降的方式迭代地去优化神经网络的参数,最终输出网络模型的过程。在这个过程中,通常在迭代计算的环节,会借助 GPU 进行计算的加速。
GPU 架构
现代的GPU架构,先不论不同厂家,仅NVIDIA一家就有数十年的架构迭代史,其中涉及的各种优化改进,限于篇幅,本文不可能一一介绍。但是,要想完整了解整个GPU架构的发展,作者认为可以分两步走:以NVIDIA为例,就是“从0到Fermi“,和”从Fermi到Blackwell“。Fermi架构是现代通用GPU架构的基石,其中许多核心设计思想传承至今,而此后直到作者撰文的2025年最新的Blackwell架构,都可以看做在基础上的一路迭代。
- GPU的core不能做任何类似out-of-order exectutions那样复杂的事情,总的来说,GPU的core只能做一些最简单的浮点运算,例如 multiply-add(MAD)或者 fused multiply-add(FMA)指令,后来经过发展又增加了一些复杂运算,例如tensor张量(tensor core)或者光线追踪(ray tracing core)相关的操作。
- 多个core之间通讯:在图像缩放的例子中,core与core之间不需要任何协作,因为他们的任务是完全独立的。然而,GPU解决的问题不一定这么简单,假设一个长度为8的数组,在第一步中完全可以并行执行两个元素和两个元素的求和,从而同时获得四个元素,两两相加的结果,以此类推,通过并行的方式加速数组求和的运算速度。如果是长度为8的数组两两并行求和计算,那么只需要三次就可以计算出结果。如果是顺序计算需要8次。如果GPU想要完成上述的推理计算过程,显然,多个core之间要可以共享一段内存空间以此来完成数据之间的交互,需要多个core可以在共享的内存空间中完成读/写的操作。我们希望每个Cores都有交互数据的能力,但是不幸的是,一个GPU里面可以包含数以千计的core,如果使得这些core都可以访问共享的内存段是非常困难和昂贵的。出于成本的考虑,折中的解决方案是将各类GPU的core分类为多个组,形成多个流处理器(Streaming Multiprocessors )或者简称为SMs。
- SM块的底部有一个96KB的L1 Cache/SRAM。每个SM都有自己的L1缓存,SM间不能互相访问彼此的L1。L1 CACHE拥有两个功能,一个是用于SM上Core之间相互共享内存(寄存器 也可以),另一个则是普通的cache功能。存在全局的内存GMEM,但是访问较慢,Cores当需要访问GMEM的时候会首先访问L1,L2如果都miss了,那么才会花费大代价到GMEM中寻找数据。
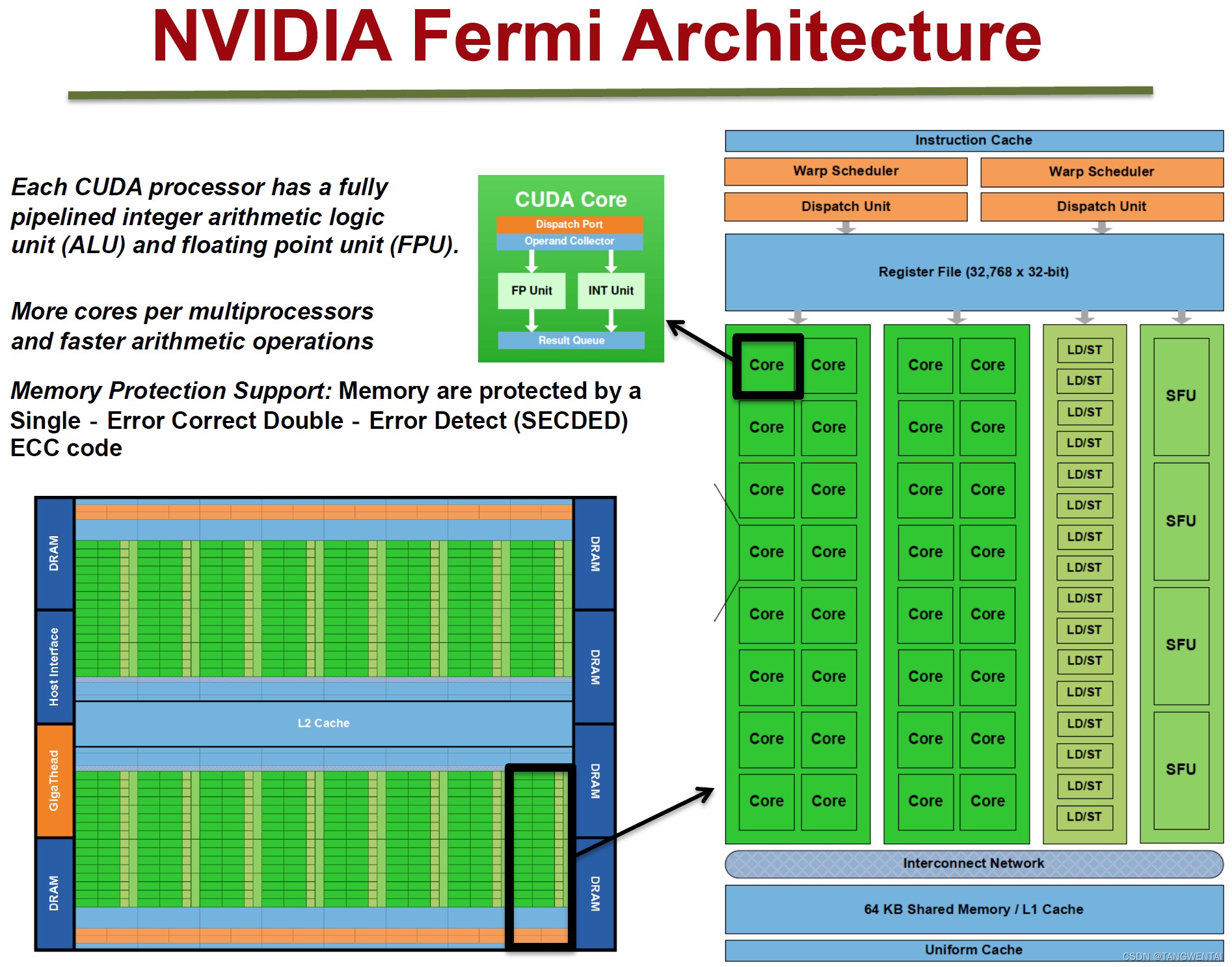
和CPU对比
CPU和GPU的主要区别在于它们的设计目标。CPU的设计初衷是执行顺序指令,一直以来,为提高顺序执行性能,CPU设计中引入了许多功能。其重点在于减少指令执行时延,使CPU能够尽可能快地执行一系列指令。这些功能包括指令流水线、乱序执行、预测执行和多级缓存等(此处仅列举部分)。而GPU则专为大规模并行和高吞吐量而设计,但这种设计导致了中等至高程度的指令时延。这一设计方向受其在视频游戏、图形处理、数值计算以及现如今的深度学习中的广泛应用所影响,所有这些应用都需要以极高的速度执行大量线性代数和数值计算,因此人们倾注了大量精力以提升这些设备的吞吐量。我们来思考一个具体的例子:由于指令时延较低,CPU在执行两个数字相加的操作时比GPU更快。在按顺序执行多个这样的计算时,CPU能够比GPU更快地完成。然而,当需要进行数百万甚至数十亿次这样的计算时,由于GPU具有强大的大规模并行能力,它将比CPU更快地完成这些计算任务。
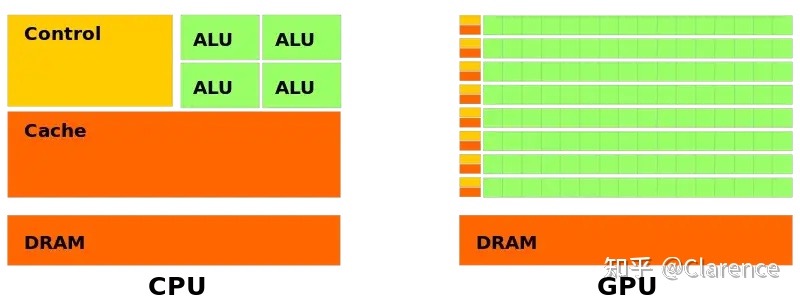
计算架构
GPU架构总体如下图所示:
为什么要有 Block?如果 GPU 的 10,000 个线程共享一个巨大的显存/VRAM,光是从显存读数据就要花掉 90% 的时间(读一次数据需要几百个时钟周期)。把线程分成一个个 Block,每个 Block 内部配一小块极速的共享内存(Shared Memory)。先把这块数据从显存搬到Shared Memory,同一个block内的thread之间据此交换数据。PS:减少显存带宽瓶颈,提供快速局部通信。
为什么要有 Warp?节省指令发射器。在 CPU 里,每个核心都有自己独立的“大脑”(指令解码器、分支预测器)。如果 GPU 的 10,000 个线程也各自配一个大脑,芯片光放解码器就放不下了,没地方放运算器(ALU)。GPU 把 32 个线程捆成一个 Warp,这 32 个人共享同一个指令解码器。当一个 Warp 去显存读数据时,它必须等待,在 CPU 看来,这是灾难性的停顿;但 GPU 的做法是:换人上。CPU 的理念是“我跑得快,所以任务完成得快”;GPU 的理念是“我有的是人,只要有人在干活,我就不亏”。当 Warp 0 因为等数据卡住时,硬件调度器会瞬间(零开销)切换到 Warp 1。

两级线程层次结构(带上grid也有说三层的,比较新的Hooper 架构 引入了Thread Block Clusters 层次),可以分为两个粒度来看 GPU:
- 以SM(Streaming Multiprocessor)为基本单元来看GPU 整体架构,GPU由多个SM组成,而在SM之外,仅仅有global memory和L2 cache两个组件。PS:gpu sm 更类似于cpu 里的core,不同sm执行不同的指令单元
- SM的硬件架构:核心组件包括内存、计算单元和指令调度。每个SM包含多个核心(在 Fermi 架构之前,处理核心被称为 Stream Processor,每个 SP 可以执行一个线程的计算任务,在 Fermi 架构之后,英伟达将处理核心更名为 CUDA 核心),它们共享一个指令单元,但能够并行执行不同的线程。每个SM中的共享内存允许线程之间进行有效的数据交换和同步。 在Fermi 架构中,每个 SM 包含 2 个线程束(Warp),一个 Warp 中包含 16 个 Cuda Core,共 32 个 CUDA Cores。随着 Volta 架构的推出,V100 GPU 每个SM配备了 8 个 Tensor Core。PS: sm类似cpu,cuda core/tensor等更类似与加法器和乘法器。
流式多处理器(Streaming Multiprocessor、SM)是 GPU 的基本单元,每个 GPU 都由一组 SM 构成,SM 中最重要的结构就是计算核心 Core
- 线程调度器(Warp Scheduler):线程束(Warp)是最基本的单元,每个线程束中包含 32 个并行的线程,GPU 控制部件面积比较小,为了节约控制器,一个 Warp 内部的所有 CUDA Core 的 PC(程序计数器)一直是同步的,但是访存地址是可以不同的,每个核心还可以有自己独立的寄存器组,它们使用不同的数据执行相同的命令,这种执行方式叫做 SIMT(Single Instruction Multi Trhead)。调度器会负责这些线程的调度;
-
一个 Warp 中永远都在执行相同的指令,如果分支了怎么处理呢?其实 Warp 中的 CUDA Core 并不是真的永远都执行相同的指令,它还可以不执行。这样会导致 Warp Divergence,极端情况下,每一个Core的指令流都不一样,那么甚至还可能导致一个 Warp 中仅有一个 Core 在工作,效率降低为 1/32.
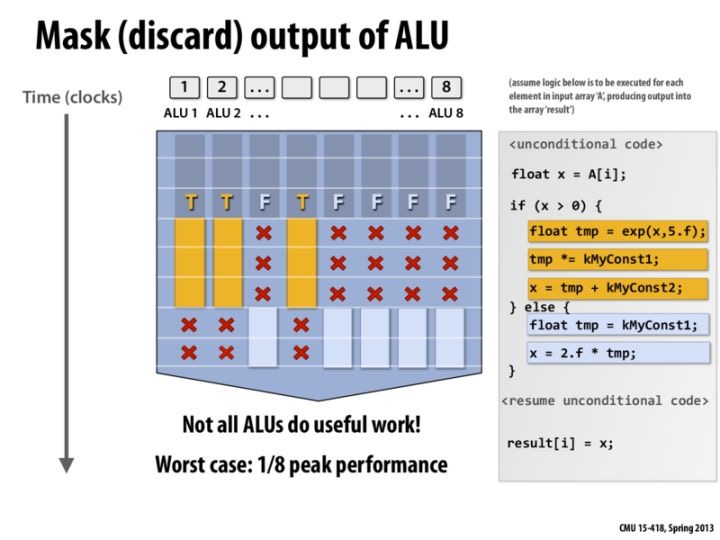
- GPU 需要数据高度对齐,一个 Warp 的内存访问是成组的,一次只能读取连续的且对齐的 128byte(正好是WarpSize 32 * 4 byte),CPU 是一个核心一个 L1,GPU 是两个 Warp 一个 L1 Cache,整个Warp 有一个核心数据没准备好都执行不了。
- GPU 的线程切换不同于 CPU,在 CPU 上切换线程需要保存现场,将所有寄存器都存到主存中,GPU 的线程切换只是切换了寄存器组(一个 SM 中有高达 64k 个寄存器),延迟超级低,几乎没有成本。一个 CUDA Core 可以随时在八个线程之间反复横跳,哪个线程数据准备好了就执行哪个。 这是 GPU 优于 CPU 的地方,也是为了掩盖延迟没办法的事情。
-
- CUDA Core:向量运行单元 ,在Fermi 架构中,每一个 Cuda Core 由 1 个浮点数单元 FPU 和 1 个逻辑运算单元 ALU 组成。
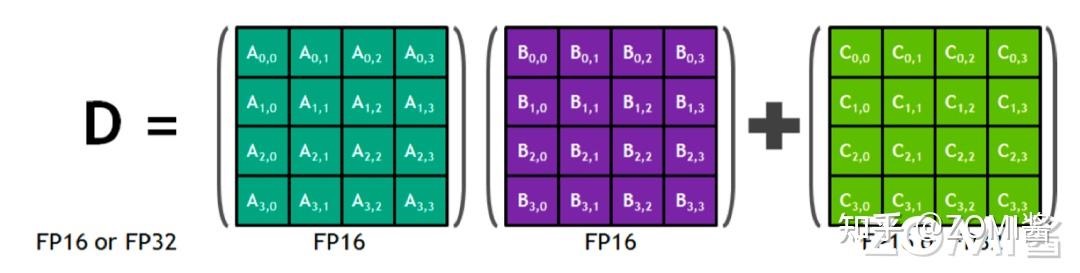
- Tensor Core:张量运算单元(FP8、FP16、BF16、TF32、INT8、INT4),2017 年提出的 Volta 架构,引入了张量核 Tensor Core 模块,一种专为 AI 训练和推理设计的可编程矩阵乘法和累加单元。TensorCore及其相关的数据路径是定制的,以显著提高浮点计算吞吐量。每个TensorCore提供一个4x4x4矩阵处理数组,它执行操作D=A*B+C,其中A、B、C和D是4×4矩阵。每个TensorCore每个时钟周期可以执行64个浮点FMA混合精度操作,而在一个SM中有8个TensorCore,所以一个SM中每个时钟可以执行1024(8x64x2)个浮点操作。 Tensor Core
- 特殊函数的计算单元(Special Functions Unit、SPU),(超越函数和数学函数,反平方根、正余弦啥的)
- Dispatch Unit:指令分发单元
与个人电脑上的 GPU 不同,数据中心中的 GPU 往往都会用来执行高性能计算和 AI 模型的训练任务。正是因为社区有了类似的需求,Nvidia 才会在 GPU 中加入张量(标量是0阶张量,向量是一阶张量, 矩阵是二阶张量)核心(Tensor Core)18专门处理相关的任务。张量核心与普通的 CUDA 核心其实有很大的区别,CUDA 核心在每个时钟周期都可以准确的执行一次整数或者浮点数的运算,时钟的速度和核心的数量都会影响整体性能。张量核心通过牺牲一定的精度可以在每个时钟计算执行一次 4 x 4 的矩阵运算。PS:就像ALU 只需要加法器就行了(乘法指令转换为多个加法指令),但为了提高性能,直接做了一个乘法器和加法器并存。
内存架构
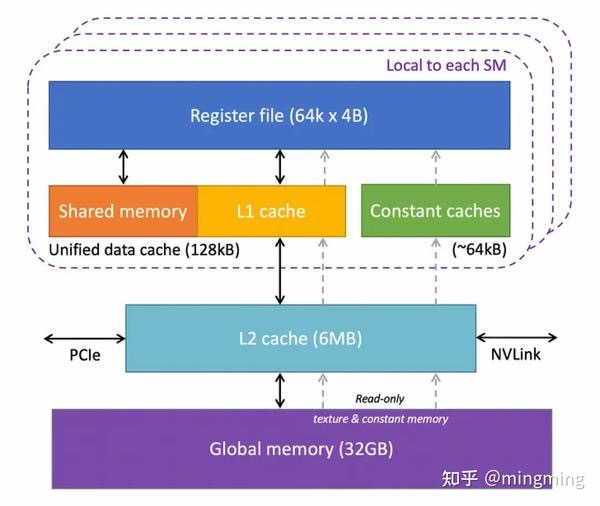
PS:在学习计算机时,我们一般会将存储分为寄存器、内存、硬盘。在 GPU 上,也有类似的存储模型CPU DRAM、GPU HBM、GPU SRAM。
与线程层次对应的是显存层次,不同层次的线程可以访问不同层次的显存。
- Multi level Cache:多级缓存(L0/L1 Instruction Cache、L1 Data Cache & Shared Memory)。GPU的特点是有很多的ALU和很少的cache. 缓存的目的不是保存后面需要访问的数据的,这点和CPU不同,而是为thread提高服务的。如果有很多线程需要访问同一个相同的数据,缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面),获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色。但是由于需要访问dram,自然会带来延时的问题。GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
- 每个SM还有一个L1缓存,缓存从L2缓存中频繁访问的数据
- 所有SM都共享一个L2缓存,缓存全局内存中被频繁访问的数据,以降低时延。需要注意的是,L1和L2缓存对于SM来说是公开的,也就是说,SM并不知道它是从L1还是L2中获取数据。SM从全局内存中获取数据,这类似于CPU中L1/L2/L3缓存的工作方式。
- 存储和缓存数据的寄存器文件(Register File)。每个SM有大量的寄存器,被SM内的核心(Core)之间共享。
- 常量内存 (Constants Caches)::用于SM上执行的代码中使用的常量数据, Constant 声明的变量就会在这里存。仅可由 CPU 写入,但可被所有 GPU 线程读取。适合存储小规模的、不变的数据(如配置信息、系数等)。
__constant__ float constData[256]; // 常量内存 - 访问存储单元(Load/Store Queues):在核心和内存之间快速传输数据;
- 共享内存(Shared Memory)。每个SM有一块共享内存,SRAM内存,供运行在SM上的线程块(thread block)共享使用,是实现Block内线程高效协作和数据交换的核心,对于矩阵乘法等需要数据复用的算法至关重要。
__shared__ float sharedA[TILE_SIZE][TILE_SIZE]; // 共享内存 -
Global memory(也就是常说的显存):我们用nvidia-smi命令得到的就是显存的大小,也叫全局内存,or 片外全局内存,存取的时延比较高
// 通常而言,全局内存主要适用于存储程序的大部分输入输出数据,尤其是需要 GPU 和 CPU 共享的大容量数据。 // 示例:在矩阵乘法中,两个矩阵的元素可以存储在全局内存中,以便所有线程都可以访问。 __global__ void matrixMultiplication(float *A, float *B, float *C, int N) { int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; float sum = 0.0; // 本地内存(Local Memory) for (int i = 0; i < N; ++i) { sum += A[row * N + i] * B[i * N + col]; } C[row * N + col] = sum; }
不同层次的显存访问延迟不同,Ampere 架构的 GPU一些重要的运算延迟周期时间
- 访问全局内存(高达80GB):约380个周期
- 二级缓存(L2 cache):约200个周期
- 一级缓存或访问共享内存(每个流式多处理器最多128KB):约34个周期
- 乘法和加法在指令集层面的结合(fused multiplication and addition,FFMA):4个周期
- Tensor Core(张量计算核心)矩阵乘法运算:1个周期
由于不同的存储器访问延迟差距较大,如果我们在编程的时候可以利用片内存储器降低访问延迟,就可以提升 Kernel 的性能。庆幸的是,在 GPU 编程中,CUDA 为 Shared Memory 提供编程接口,这使得开发者在设计 Kernel 实现时,可以利用 Shared Memory 访问延迟低的特点加速 Kernel 的性能。所以在 GPU 编程中,Kernel 的设计是以 Thread Block 这个粒度展开的。但这样会导致两个问题:
- 单个 Thread Block 处理的数据规模有限,原因是 Shared Memory 的容量有限。
- SM 利用率较低。单个 Thread Block 可配置的最大线程数为 1024,每个 Thread Block 会分配到一个 SM 上运行。假如每个 Thread Block 处理较大规模的数据、计算,Kernel 一次仅发射很少的 Thread Block,可能导致某些 SM 处于空闲状态,计算资源没有被充分挖掘,这样同样会限制 Kernel 的整体性能。例如在 LLM 长文本推理 进行 Decoding Attention时, 𝐾、𝑉 长度较长,此时由于显存上限问题, batch size 会小,这导致单个 Thread Block 访问的数据量、计算量较大,同时发射的 Thread Block 的数量较少,导致某些 SM 处于空闲状态,限制 Kernel 性能。 按 Thread Block 这个粒度划分子任务已经难以处理一些场景,限制了 Kernel 运行效率。解决这个问题的最直接的方式是:提供更大粒度的线程组Thread Block Clusters。 Hopper 架构特性:Distributed Shared Memory
CPU 与GPU
CPU是整个系统的核心,是总指挥,GPU的任务指令是由CPU分配的。CPU通过PCIe总线给GPU发送指令和数据交互。
CPU 与GPU 协作
GPU 无法自己独立工作,其工作任务还是由 CPU 进行触发的。整体的工作流程可以看做是 CPU 将需要执行的计算任务异步的交给 GPU,GPU 拿到任务后,会将 Kernel 调度到相应的 SM 上,而 SM 内部的线程则会按照任务的描述进行执行。
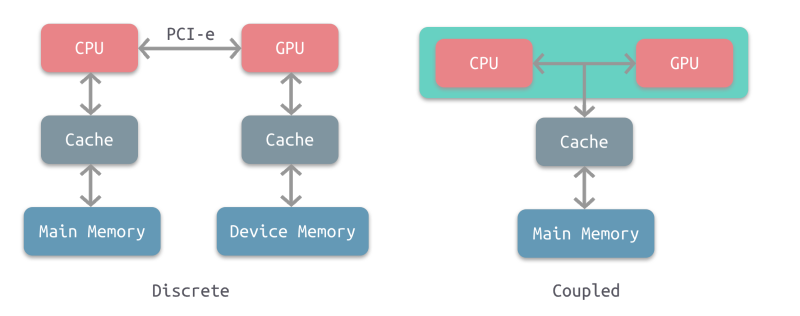
大多数采用的还是分离式结构,AMD 的 APU 采用耦合式结构,目前主要使用在游戏主机中,如 PS4。
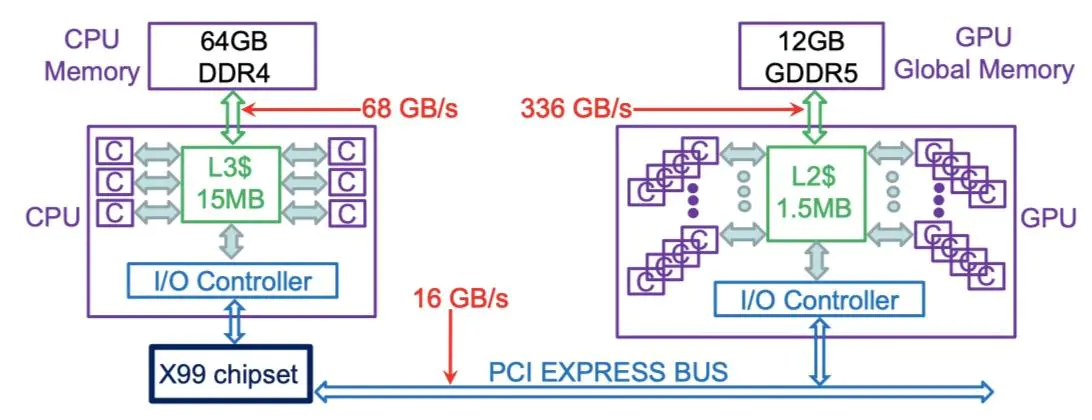
- 锁页:GPU 可以直接访问 CPU的内存。出于某些显而易见的原因,cpu 和gpu 最擅长访问自己的内存,但gpu 可以通过DMA 来访问cpu 中的锁页内存。锁页是操作系统常用的操作,可以使硬件外设直接访问内存,从而避免过多的复制操作。”被锁定“的页面被os标记为不可被os 换出的,所以设备驱动程序在给这些外设编程时,可以使用页面的物理地址直接访问内存。PS:部分内存的使用权暂时移交给设备。
- 命令缓冲区:CPU 通过 CUDA 驱动写入指令,GPU 从缓冲区 读取命令并控制其执行,
- CPU 与GPU 同步:cpu 如何跟踪GPU 的进度
对于一般的外设来说,驱动程序提供几个api接口,约定好输入和输出的内存地址,向输入地址写数据,调接口,等中断,从输出地址拿数据。输出数据地址 command_operation(输入数据地址)。gpu 是可以编程的,变成了输出数据地址 command_operation(指令序列,输入数据地址)
系统的三个要素: CPU,内存,设备。CPU 虚拟化由 VT-x/SVM 解决,内存虚拟化由 EPT/NPT 解决,设备虚拟化呢?它的情况要复杂的多,不管是 VirtIO,还是 VT-d,都不能彻底解决设备虚拟化的问题。除了这种完整的系统虚拟化,还有一种也往往被称作「虚拟化」的方式: 从 OS 级别,把一系列的 library 和 process 捆绑在一个环境中,但所有的环境共享同一个 OS Kernel。
不考虑嵌入式平台的话,那么,GPU 首先是一个 PCIe 设备。GPU 的虚拟化,还是要首先从 PCIe 设备虚拟化角度来考虑。一个 PCIe 设备,有什么资源?有什么能力?
- 2 种资源: 配置空间;MMIO(Memory-Mapped I/O)
- 2 种能力: 中断能力;DMA 能力

一个典型的 GPU 设备的工作流程是:
- 应用层调用 GPU 支持的某个 API,如 OpenGL 或 CUDA
- OpenGL 或 CUDA 库,通过 UMD (User Mode Driver),提交 workload 到 KMD (Kernel Mode Driver)
- Kernel Mode Driver 写 CSR MMIO,把它提交给 GPU 硬件
- GPU 硬件开始工作… 完成后,DMA 到内存,发出中断给 CPU
- CPU 找到中断处理程序 —— Kernel Mode Driver 此前向 OS Kernel 注册过的 —— 调用它
- 中断处理程序找到是哪个 workload 被执行完毕了,…最终驱动唤醒相关的应用
本质上GPU 还是一个外设,有驱动程序(分为用户态和内核态)和API,用户程序 ==> API ==> CPU ==> 驱动程序 ==> GPU ==> 中断 ==> CPU.
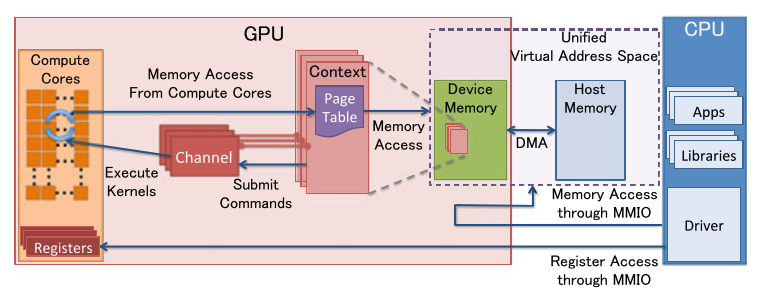
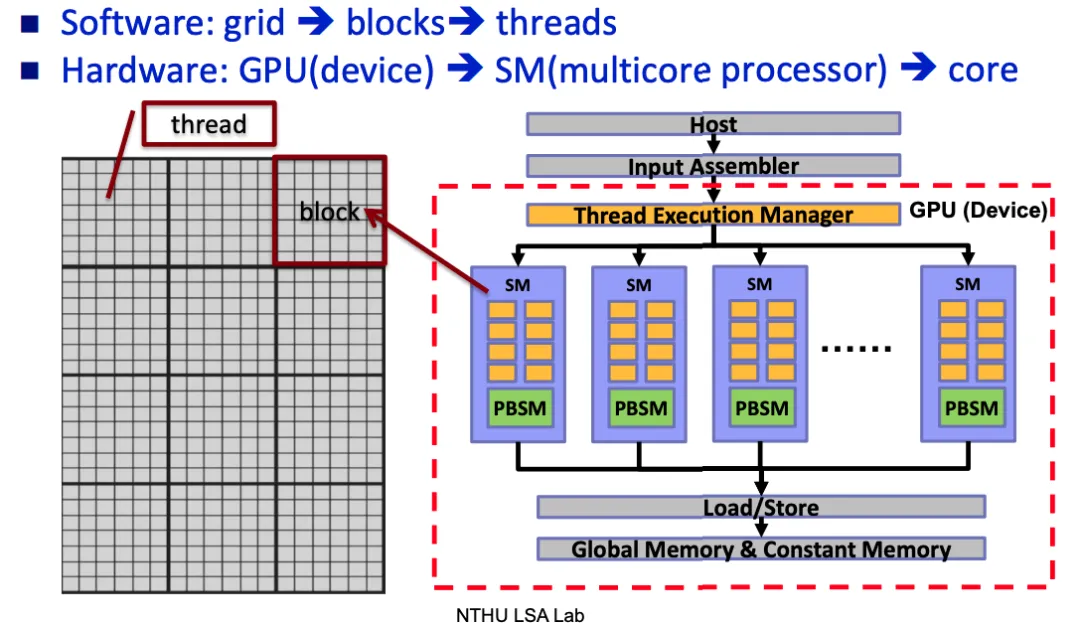
Grid—> Block—>threads
CUDA里另外一个不次于kernel的概念就是三级线程管理:Grid—> Block—>threads。在CUDA编程中,线程以thread,thread block,grid的层级结构进行组织。待批量并发的数据也要组织成Grid、Thread Block、Thread的结构。
- grid:kernel 在 device上跑,实际上启动一大堆线程,一个 kernel 所启动的所有线程称为一个Grid,一个Grid的所有线程是共享一大段内存,也就是相同的全局内存(显存)空间。
- CUDA 不光支持 1D grid,还支持 2D grid、3D grid。
- Grid再分下去就是block层级,block里面才是装的thread,也就是线程。虽然一个Grid里面的所有线程,都是共享全局显存地址空间,但是,block之间都是隔离的,自己玩自己的,并行执行(注意,不是并发),每个 block自己的共享内存(Shared Memory),里面的Thread 共享,别的block的thread不能来访问,但block 和 block 之间只能通过全局内存/global memory(ddr)进行数据交互。
- 单个 Block 的线程数有限制(NVIDIA目前最大1024个线程/Block)PS:如果要处理的数据量远大于一个 block 能容纳的线程数(比如数组 1e7 个元素,矩阵 4k×4k),一个 block 根本不够,所以要有Grid
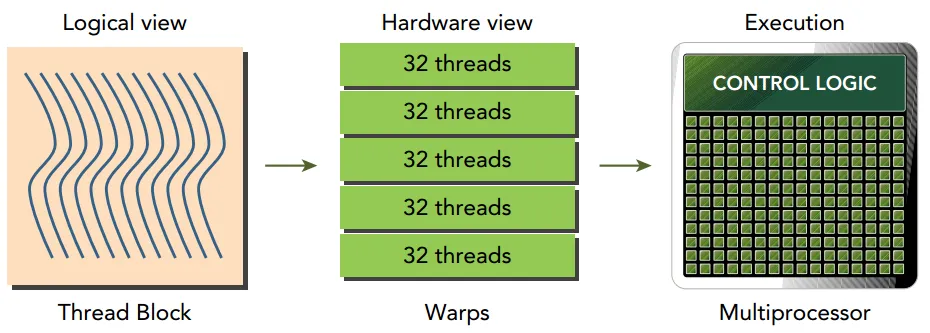
- block 内部的 threads,怎么玩都可以了,可以同步,也可以通过 shared memory通信。线程是最基本的执行单元,包含独立寄存器状态和独立程序计数器。thread block中的所有线程会运行同一个 kernel 函数的代码(共享程序计数器),但它们可以通过 threadIdx、blockIdx 等标识处理不同的数据。一个 thread block 会被硬件切分成若干个 warp(每 32 个线程一个 warp,不足 32 的最后也会形成一个 warp,但部分线程无效)。
- 线程块与warp的关系:warp是底层概念,NVIDIA的warp固定包含32个线程,warp是线程硬件调度的最小粒度。线程块是软件概念,线程块有多少个线程组成由代码指定。假设一个block有512个thread,就会有16个warp,执行时会先发射Warp0的指令,如果Warp0执行了耗时指令(比如从全局内存加载数据),然后可能切换到 Warp1,Warp 之间的切换是 流水线/时分复用,用来隐藏内存访问延迟。
线程块和线程的数量取决于数据的大小和我们所需的并行度。例如,在向量相加的示例中,如果我们要对256维的向量进行相加运算,那么可以配置一个包含256个线程的单个线程块,这样每个线程就可以处理向量的一个元素。如果数据更大,GPU上也许没有足够的线程可用,这时我们可能需要每个线程能够处理多个数据点。
编写一个kernel需要两步。第一步是运行在CPU上的主机代码,这部分代码用于加载数据,为GPU分配内存,并使用配置的线程网格启动kernel;第二步是编写在GPU上执行的设备(GPU)代码。在GPU上执行Kernel的步骤
- 将数据从主机复制到设备。 在调度执行kernel之前,必须将其所需的全部数据从主机(即CPU)内存复制到GPU的全局内存(即设备内存)。在最新的GPU硬件中,我们还可以使用统一虚拟内存直接从主机内存中读取数据。
- SM上线程块的调度。当GPU的内存中拥有全部所需的数据后,它会将线程块分配给SM,整个block只能分配到一个SM上运行。为此,GPU必须在开始执行线程之前在SM上为这些线程预留资源。在实际操作中,可以将多个线程块分配给同一个SM以实现并行执行。由于SM的数量有限,而大型kernel可能包含大量线程块,因此并非所有线程块都可以立即分配执行。GPU会维护一个待分配和执行的线程块列表,当有任何一个线程块执行完成时,SM再从剩下的block队列里取新block。
- 单指令多线程 (SIMT) 和线程束(Warp)。众所周知,一个块(block)中的所有线程都会被分配到同一个SM上。但在此之后,线程还会进一步划分为大小为32的组(称为warp),并一起分配到一个称为处理块(processing block)的核心集合上进行执行。SM通过获取并向所有线程发出相同的指令,以同时执行warp中的所有线程。然后这些线程将在数据的不同部分,同时执行该指令。在向量相加的示例中,一个warp中的所有线程可能都在执行相加指令,但它们会在向量的不同索引上进行操作。由于多个线程同时执行相同的指令,这种warp的执行模型也称为单指令多线程 (SIMT)。
- 这类似于CPU中的单指令多数据(SIMD)指令,SIMD范式常见的一种实现是CPU的向量化运算,将N份数据存储在向量寄存器里,执行一条指令,同时作用于向量寄存器里的每个数据。但通常SIMD所使用的寄存器长度有限,例如ARMv9架构 SVE指令集使用的寄存器长度最大为2048byte,高通HVX指令集使用寄存器长度为1024byte。PS:相比之下GPU的线程数是非常多的,例如RTX 3090有82个SM,每个SM支持1536个线程,理论最大并发线程数约为82×1536≈12.6万。
- SIMT是对SIMD进行“线程级抽象”得到的,或者说,SIMT是“基于Warp的SIMD”。在各线程实际运行时,硬件层面便会回归SIMD范式。实际执行时GPU硬件会将其组织为warp,warp中的每个线程基于唯一索引,访问不同的内存位置,以不同的数据执行相同的指令,这便是SIMD。
- 底层实现SIMD,表面上提供线程级编程模型,让编程者很大程度上可以从串行的角度思考,而屏蔽了很多并行角度的执行细节。这种编程便利最好的体现就是在出现分支(如if-else)时:Warp执行每个Branch Path,执行某个path时,不在那个path上的线程闲置不执行,线程活跃状态通过一个32位的bitmask标记,分支收敛时再对齐汇总到下一段指令等等。PS:为何要有warp,为何是32,因为向量寄存器和bitmask 长度? PS: 有点类似hadoop 任务调度的意思,cpu 是driver 进程,gpu是 worker 进程。 SIMT编程模型由Thread和Block组成,block偏软件概念(一个block多少个thread 可配),warp偏硬件概念(32个thread)。
GPU到底是如何工作的?Grids是跑在Device(GPU)层级,软件层面将grid切分成多个Thread Block是为了对硬件的抽象,这样程序员就不必关心GPU具体有多少个物理核心、多少个SM。Thread Block是最小的“资源分配与调度”单位,Warp是最小的硬件调度单位。一个任务软件层面上被分为Grid和Thread Block,GPU的全局调度器(GigaThread Engine)将Thread Blocks分配给有空闲资源的 SM,SM又将Thread Block按照32个Thread为一组分成Warp,SM内部的调度硬件,会将这32个Warp分配给它内部的4个Warp Scheduler。而一个Warp Scheduler同一时刻只能运行一个Warp, 当某个正在执行的Warp因为等待内存而暂停时,它可以立刻从剩下的Warp中挑选一个就绪的来执行。这就是所谓的隐藏延迟 (hide latency)。而如何充分利用这个特性呢?给每个Warp Scheduler足够多的可切换的Warp。每个SM都包含一个巨大、单一的物理寄存器文件,为实现零开销Warp上下文切换的提供了硬件基础。这是与CPU昂贵的上下文切换(需要保存和恢复大量状态)的根本区别。要让每个 Warp Scheduler (Warp 调度器) 有足够的可切换 Warp,其本质是提高 GPU 的占用率。占用率指的是一个 SM 上实际活跃的 Warp 数量与该 SM 理论上能支持的最大 Warp 数量的比例。一个 SM 能同时运行多少 Warp(一个 SM 在同一时刻只能为一个 Kernel 服务,但可以同时运行该Kernel的多个线程块(只要资源允许)),取决于以下三个主要资源的限制:
- Registers。每个线程都需要使用寄存器来存储其局部变量。一个 SM 上的寄存器总数是固定的,假设一个 SM 有 65536 个寄存器,最大支持 2048 个线程 (64 Warps)。 每个Kernel需要 64 个寄存器,那么一个 Block (假设 256 线程) 就需要 256 * 64 = 16384 个寄存器。这个 SM 最多可以容纳 65536 / 16384 = 4 个这样的 Block,也就是 1024 个线程 (32 Warps),占用率为 50%。如果 Kernel 每个线程需要 128 个寄存器,那么这个 SM 只能容纳 2 个这样的 Block,占用率就更低了。
- Shared Memory。共享内存是分配给每个线程块 (Block) 的、速度很快的片上内存。一个 SM 上的共享内存总量是固定的。假设一个 SM 有 96KB 共享内存,最大支持 16 个 Block。如果Kernel 每个 Block 需要 32KB 共享内存,那么这个 SM 最多只能同时运行 96KB / 32KB = 3 个 Block。在这个场景下,共享内存成为了主要的限制因素。这就将 SM 上并发的 Block 数量上限从硬件支持的 16 个锐减到了 3 个,从而严重限制了 SM 上的总并发 Warp 数量,降低了占用率。
- 线程块/线程数限制。每个 SM 架构本身就有硬件限制,比如一个 SM 最多能同时调度多少个 Block(例如 16 或 32),以及最多能同时管理多少个线程(例如 2048)。这个是硬性上限,无法通过代码改变。不过提高 GPU 的占用率来隐藏延迟也不是万能的,隐藏延迟的有效性,本质上取决于 Warp调度器是否有“就绪态”的Warp可供切换。比如:如果一个Kernel非常简单,每个线程只使用极少的寄存器,并且不使用共享内存,那么一个SM上可能会驻留大量的Warp。但如果这个Kernel的计算是访存密集型且延迟很高的,同时计算/访存指令比例很低,那么即使占用率达到100%,Warp调度器可能依然会“无Warp可调”,因为所有Warp都在等待数据返回。这时候我们就不得不提另外一个概念,访存比(Ratio = Total Bytes / Total FLOPs)或者计算强度(Roofline,I = Total FLOPs / Total Bytes), 说白了,就是看一个程序是计算密集型(Compute-bound)还是IO(内存访问)密集型(Memory-bound)。可以使用NVIDIA Nsight Compute分析Kernel函数的占用率和计算强度。
CUDA的编程模型(Grid -> Block -> Thread)与GPU的硬件架构(GPU -> SM -> Warp -> Core)
warp(gpu的一个单位)是典型的单指令多线程(SIMT,SIMD单指令多数据的升级)的实现,也就是32个线程同时执行的指令是一模一样的,只是线程数据不一样,这样的好处就是一个warp只需要一个套逻辑对指令进行解码和执行就可以了,芯片可以做的更小更快,之所以可以这么做是由于GPU需要处理的任务是天然并行的。
CUDA有host和device的概念,在 CUDA程序构架中,Host 代码部分在CPU上执行,就是一般的C。当遇到程序要进行并行处理的,CUDA就会将程序编译成GPU能执行的程序,并传送到GPU,这个被编译的程序在CUDA里称做核(kernel),Device 代码部分在 GPU上执行。kernel是CUDA中的核心概念之一。CUDA执行时最重要的一个流程是调用CUDA的核函数来执行并行计算。Kernel 程序通常以一种拷贝和计算(copy and compute)模式执行,即,首先从全局内存中获取数据,并将数据存储到共享内存中,然后对共享内存数据执行计算,并将结果(如果有)写回全局内存。
| CUDA编程抽象 | 线程层次结构 | 存储层次结构 | 缓存 |
|---|---|---|---|
| 线程/thread | ALU/cuda core | Local Memory。每个线程都有本地内存,存储临时变量。 | |
| 线程块/thread block | 流多处理器 (SM) | 共享内存/Shared Memory。同一个Block内的线程可以用共享内存共享数据。 | 每个流式多处理器(SM)都有自己的L1 Cache |
| 网格/grid | GPU device | 全局内存/Global Memory。可以被所有块上的所有线程访问 | 所有 SM 共享L2 Cache |
不同层次的显存访问延迟不同,以 PCIE 80GB 的 H800为例,其 Global Memory 的访问延迟约为 478 个时钟周期,Shared Memory 的访问延迟约为 30 个时钟周期,Register 约为 1 个时钟周期。由于不同的存储器访问延迟差距较大,如果我们在编程的时候可以利用片内存储器降低访问延迟,就可以提升 Kernel 的性能。庆幸的是,在 GPU 编程中,CUDA 为 Shared Memory 提供编程接口,这使得开发者在设计 Kernel 实现时,可以利用 Shared Memory 访问延迟低的特点加速 Kernel 的性能。所以在 GPU 编程中,Kernel 的设计是以 Thread Block 这个粒度展开的。
从大到小来谈:CUDA编程就是在GPU硬件上启动了线程集合,为了更好的调度线程,GPU采用了分层的架构,在最高层的Grid负责将Block分配到哪些SM硬件上,在SM内部将由Warp调度那些线程来执行当前的任务:SM在实际计算时,会把block中的thread进一步拆分为warp,一个warp是32个thread,同一个warp里的thread,会以不同的数据,执行同样的指令,SM 一次只会执行一个warp。为了使SM忙碌起来,当一个warp遇到IO时,指令调度器会让SM执行另一个warp,这样就可以使SM保持忙碌,从而提高效率。因此,在编程时,最好是保证SM有足够多的warp进行切换。但是,warp驻留在SM是有代价的,即占据了内存,包括寄存器和共享内存等。为此,CUDA中有一个重要的概念叫做Occupancy(占用率),占用率是每个多处理器的活动warp与可能的活动warp的最大数量的比值,占用率跟寄存器数量、共享内存使用等因素有关。例如,在计算能力为7.0的设备上,每个多处理器有65,536个32位寄存器,最多可以有2048个线程同时驻留(64个warps)。PS:这不就是进程(wrap)等cpu排队嘛,只有64个wrap在同一时间能跑
从小到大来谈:CUDA 编程主打一个多线程 thread,多个 thread 成为一个 thread block,同一个 block 内的 thread 共享Shared Memory/L1 cache/SRAM,而 thread block 就是由这么一个 Streaming Multiprocessor (SM) 来运行的。
- 一个 SM 里面有多个 subcore,每个 subcore 有一个 32 thread 的 warp scheduler 和 dispatcher, 在一个 warp 中的所有线程都会同时执行相同的指令,但是输入的数据不同,这种机制也被称为 SIMD(单指令多数据)或 SIMT(单指令多线程)模型。
- GPU 的调度单元以 warp 为单位进行调度,而不是单个线程。这意味着整个 warp 会被分配到一个流多处理器(SM)上并一起执行。在 CUDA 中,占用率是一个重要的性能指标,表示每个 SM 上激活的 warps 与 SM 可以支持的最大 warp 数量的比例。更高的占用率通常意味着更好的硬件利用率。
- 如果 warp 中的所有线程都采取相同的分支路径(例如,都满足某个条件语句),则它们会继续同步执行。但是,如果线程在分支上有不同的路径(即分歧),则 warp 会执行每个路径,但不是所有线程都会在每个路径上活跃。这可能导致效率下降,因为即使某些线程在特定路径上没有工作,整个 warp 也必须等待该路径完成。为了确保高效执行,开发人员可能需要确保他们的代码减少 warp 分歧。
- Global memory 就是我们常说的 显存 (GPU memory),其实是比较慢的。Global memory 和 shared memory 之间是 L2 cache,L2 cache 比 global memory 快。每次 shared memory 要到 global memory 找东西的时候, 会去看看 l2 cache 里面有没有, 有的话就不用去 global memory 了. 有的概率越大, 我们说 memory hit rate 越高, CUDA 编程的一个目的也是要尽可能提高 hit rate. 尤其是能够尽可能多的利用比较快的 SRAM (shared memory).但是因为 SRAM 比较小, 所以基本原则就是: 每次往 SRAM 移动数据的, 都可能多的用这个数据. 避免来来回回的移动数据. 这种 idea 直接促成了最近大火的 FlashAttention. FlashAttention 发现很多操作计算量不大, 但是 latency 很高, 那肯定是不符合上述的 “每次往 SRAM 移动数据的”. 怎么解决呢?Attention 基本上是由 matrix multiplication 和 softmax 构成的. 我们已经知道了 matrix multiplication 是可以分块做的, 所以就剩下 softmax 能不能分块做? softmax 其实也是可以很简单的被分块做的. 所以就有了 FlashAttention.
GPU的线程相对于CPU来讲属于十分轻量级的线程,创建和切换的开销都很小,而并行执行的数量以千计。但是另外一方面,GPU的线程并不能像CPU的线程那样自由。GPU的线程在执行的时候是分块(block)执行的,所以块(block)内的线程其实是共享pc寄存器。因此,虽然在编程的时候(编程模型当中),GPU的线程与CPU的线程类似,单独执行一段代码(称为kernel),但是实际上在GPU硬件上执行的时候,其实是将使用同一个kernel的多个线程归并在一个块(block)当中,用SIMD的方式去执行的。这种执行方式就隐含了,在任何一个时刻,一个块当中的所有线程,会进行一模一样的动作:如果是读内存,那么大家一起读;如果是写内存,那么大家一起写。从而,对于这种情况,相较于各个线程有自己的一片内存区域(按照线程组织数据),按照块组织数据效率会更高。所以我们可以看到,一般给CPU用的数据,都是线性排列的。而给GPU用的数据,基本上都是按照块(对应着GPU编程模型当中的线程块)来组织的。例如,从全局内存中加载的粒度是32*4字节,恰好是32个浮点数,每个线程束中的每个线程恰好一个浮点数。同样的原因,在片上存储空间以及多层高速缓存(cache)的组织方面,GPU也是突出了一个分块交换的概念,对线程组(block)的尺寸是非常敏感的。而这些在CPU上就不是那么明显。GPU深度学习性能的三驾马车:Tensor Core、内存带宽与内存层次结构 PS:线程多 ==> 共享pc/线程按block组织 ==> simd ==> 内存按块组织。
从执行视角来理解
假设对len=10000 的array=x 对其每个元素都乘以2,一个block 256个thread,则1w个元素需要40个block(一个grid)。
- 在 CPU(host)上,准备一个长度为 10,000 的数组 x[10000]。分配 GPU 全局内存(device memory),把数据从 host 拷贝到 device。
- GPU 上启动启动 kernel,形成 grid,包含 gridSize=40 个 block。GPU 把这 40 个 block 放入队列。
- GPU 有多个SM,分批执行,每个 SM 先拿 2 个(GPU 硬件自动决定) block干活儿。sm 为 block 分配 shared memory(多大可以在kernel里声明,每个 SM 有固定大小的shard memory,这也是限制sm 可以同时驻留几个block的因素之一)
- 每个 block 有 256 个线程 → 被切成 256 / 32 = 8 个 warp。
- 每个 SM 内部有多个 warp 调度器(warp scheduler),每次调度器从驻留的 warp 中挑一个就绪 warp(比如是warp0),发射下一条指令。当 Warp 0 执行比如io操作时,warp调度器会立刻切换到 Warp 1、Warp 2(或此时在sm驻留的其它block的就绪warp)。这样虽然单个 warp 在等待,但整个 SM 仍然保持忙碌 ==> 隐藏访存延迟。PS:GPU 调度的粒度就是一次一个 warp,而不是一次一个 thread
- 当一个 block 的 8 个 warp 全部执行完成 → 这个 block 就算结束,释放其占用的 共享内存 / 寄存器 / 线程名额;
- SM 会从全局队列里取新的 block,直到 40 个 block 全部完成。
- 当所有 40 个 block 执行完,整个 kernel 结束。最后把结果数组 d_y 拷回到 host
从更偏硬件的视角进一步了解GPU架构
SIMT核心架构SIMT核心是NVIDIA的SM,但是,线程以Warp为单位在SM上执行,具体如何执行,执行的流程是什么,每个组件发挥什么作用,单单从结构体是看不出来的,因此我们需要引入SM的指令流水线结构图来进行讲解:
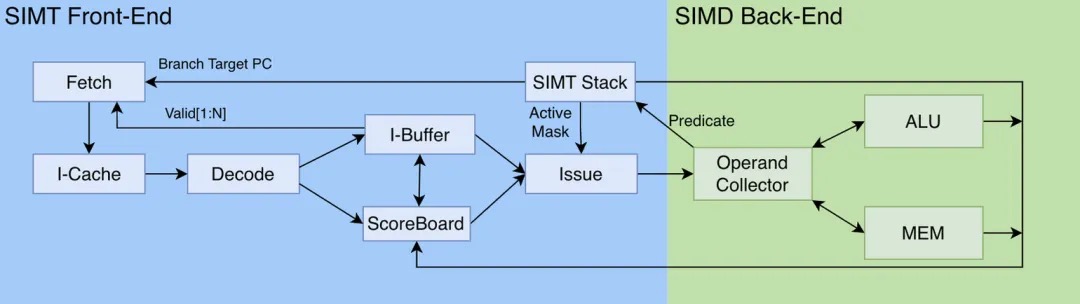
如图所示,SIMT核心流水线从运行的处理阶段可以分为SIMT前端和SIMD后端两个部分:
- SIMT前端:主要负责指令的获取、译码和发射、分支预测、以及线程的管理和调度。这部分设计的组件对应SM结构图中的蓝色、橙色部分(Warp Scheduler、Register File)。
- SIMD后端:主要负责完成计算。这部分设计的组件对应SM结构图中的绿色部分(Core)。
SIMT前端与SIMD后端的划分本质上是控制流与数据流的解耦,SIMT前端关注指令流/控制流,而SIMD后端关注单个指令执行/数据流。SIMT前端在硬件运行时“落实”了程序对线程的调度:SIMT前端以warp为单位调度线程,其包含的指令缓存(I-Cache)、解码器和程序计数器PC组件集中管理线程的指令流,并使用SIMT堆栈等技术实现线程间的条件分支独立控制流。SIMD后端主要负责执行实际的计算任务。在SIMT前端确定了warp要执行的指令后,指令发射,SIMD后端负责高效地完成一条条指令。具体的数据计算单元ALU,以及存取计算数据的寄存器访问(Operand Collector)、寄存器文件(Register File)、内存读写(Memory)位于此处。说到这里,这么多组件、组件之间有各种配合,不少同学估计已经要绕晕了。下面本文如果平铺直叙地直接深入一个个组件的细节,就会变得难以理解。因此,下面本文将采取一种“三步走”的讲解策略,先构建一个能执行计算任务的“最小系统”流水线,然后逐步向其中添加优化与功能,最终经过三步,构建出上图中完整的流水线架构。
第一步:最小可用系统
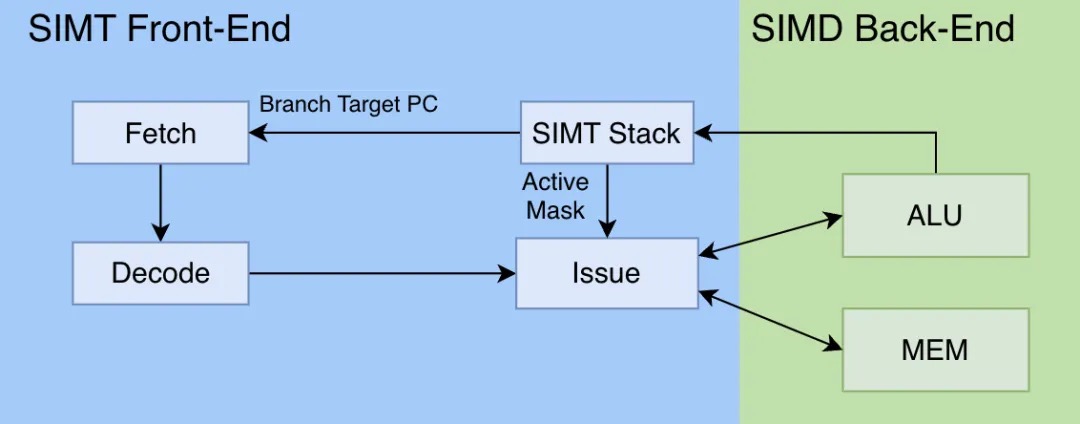
如上图,我们将SIMT内核的架构做了最大可能的简化,构成了一个“最简GPU”。这个最小可用系统由6部分构成,此6个组件相互配合,使得我们的最简GPU可以做到最简的指令执行功能:即顺序执行每一条指令,一条指令执行完再执行下一条:
- Fetch:取指令
- Decode:指令解码
- SIMT Stack:SIMT堆栈,管理线程束的分支执行状态,下文讲解
- Issue:指令发射
- ALU:算数逻辑单元,代表执行计算的组件
- MEM:存储器访问单元,代表对L1 Cache、共享内存等各层级内存访问的管理。 其中1、2、4、5、6部分是在CPU上久而有之的“老面孔”了,本文不多做解释。本节将重点介绍GPU独有的“新面孔”:SIMT堆栈。PS:从cpu视角,完整的控制、取指、取数、运算、存储才算一个core。从这个角度,sm 是一个core,但运算是一次性跑一个warp,并且在一个warp取数的过程中,可能调度另一个warp运行。
分支发散:哪些线程执行哪条指令?在GPU并行计算的发展历程中,SIMT堆栈是早期架构解决线程分支管理问题的核心机制。现实中的计算任务常包含大量条件分支(if-else、循环等)。在遇到条件分支发散(Branch Divergence)当线程束内线程选择不同执行路径时,会产生线程发散(Thread Divergence):
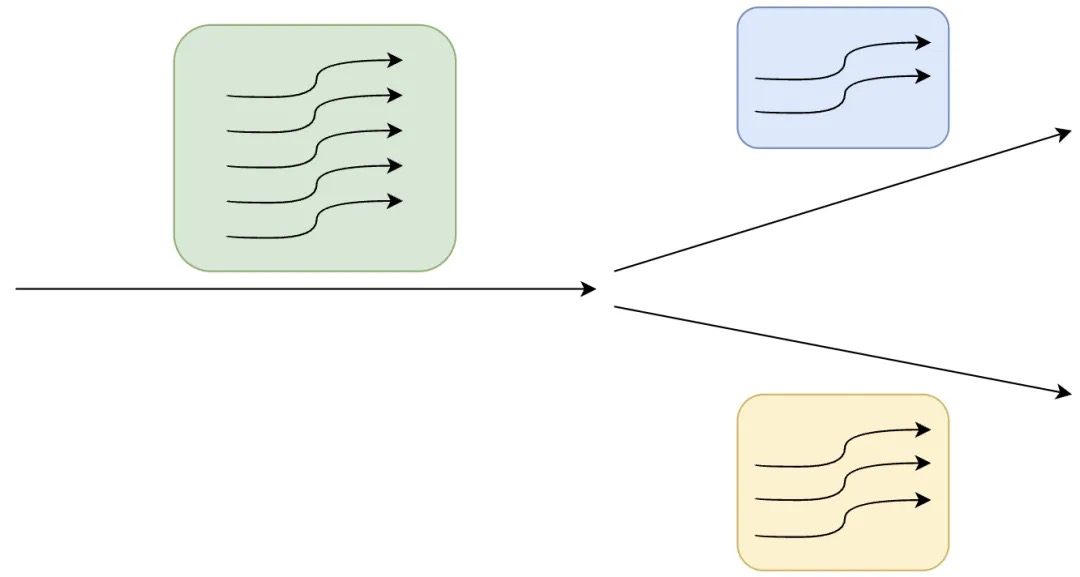
如上图,起初有5个线程执行相同的指令,直到分支发散处,根据SIMT的特性:多线程执行相同指令,但每个线程有自己独立的数据,假设此处是一个if-else,有不同数据的线程将得到不同的条件判断结果,2个线程进入if分支,3个线程进入else分支,进入不同分支的线程执行的指令流自然不同。此处便出现了线程发散,即同一warp内的线程要执行不同指令,单由于线程以warp为最小单位调度,同一时钟周期内同一warp内的线程必须执行相同的指令,那么不同执行分支的线程就需要分开调度,例如一个时钟周期调度该warp执行if分支(if分支的线程活跃),下个时钟周期再调度该warp执行else分支的线程(else分支的线程活跃)。也就是说,以warp为单位调度不代表每次调度warp,其中全部32个线程都活跃,也可以只有部分线程活跃,其余线程闲置。为解决分支发散时的线程调度,NVIDIA于2008年在Tesla架构中首次引入SIMT堆栈,并作为2010年Fermi架构的核心技术,其核心思想是:
- 路径跟踪:当线程束遇到分支时,通过堆栈记录所有可能执行路径的上下文(如程序计数器PC、活跃线程掩码)。
- 串行化执行:依次调度warp中每个分支路径上的线程,其他线程暂时闲置。例如:线程0-3执行分支A的指令,线程4-31执行分支B的指令,则必须排队执行
- 重新收敛:在所有路径执行完毕后,恢复完整warp的并行执行。 从Volta架构开始,引入了独立线程调度(Independent Thread Scheduling)。每个线程拥有独立的程序计数器(PC)和执行状态寄存器,允许同一Warp内的线程在不同分支路径上并行执行指令流。但硬件层面仍以Warp为基本调度单元。同时,也是从Volta架构开始,随着独立线程调度的引入,传统SIMT堆栈被弃用,分支收敛机制也升级到了无堆栈分支重新收敛(Stackless Branch Reconvergence)机制,通过收敛屏障(Convergence Barriers)技术来低成本解决分支代码执行调度问题,独立线程调度为无堆栈分支重新收敛提供了硬件支持。无堆栈收敛屏障机制的核心手段之一是屏障参与掩码(Barrier Participation Mask)与线程状态协同管理,其核心思想可以通过ADD和WAIT操作来展示:
- ADD(屏障初始化):当Warp执行到分支发散处前,通过专用ADD指令,活跃线程将其标识位注册到指定收敛屏障的32位掩码中,标记参与该屏障的线程组。
- WAIT(屏障同步):在预设的收敛点(如分支汇合处),硬件插入WAIT指令。到达此处的子线程组将线程状态标记为“阻塞”,并更新屏障状态寄存器。当所有参与线程均抵达屏障后,调度器才重新激活完整线程束。另外,通过新增的syncwarp()函数,开发者也可手动指定分支后的同步点,强制线程在特定位置重新收敛。
相比于SIMT堆栈,收敛屏障只需要使用仅需位掩码和状态寄存器,对于一个Warp(32个线程),一个屏障只需要32bit(每个bit对应一个线程),操作成本和硬件资源占用均极低,且不会再有堆栈深度限制,可以支持任意深度的条件分支嵌套。这一设计使得现代GPU(如NVIDIA Volta+架构)在复杂控制流场景下仍能保持高吞吐量,成为实时光追、AI推理等应用的关键支撑。
第二步:动态指令调度以提高并发
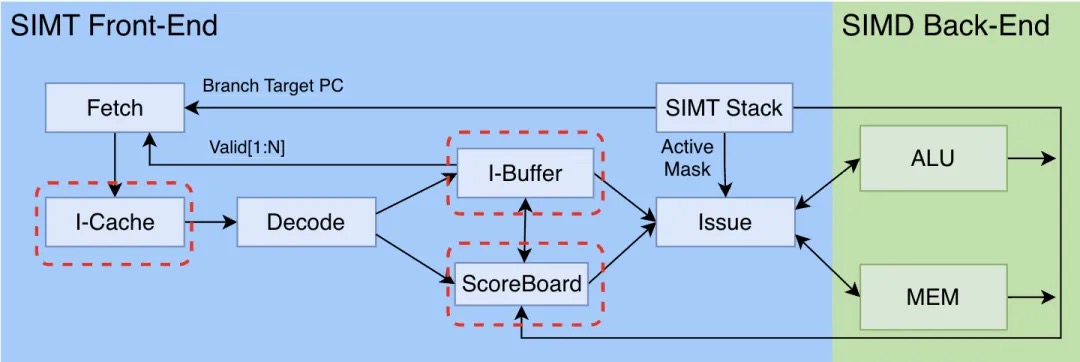
在第一步构建的最小可用系统中,采用的是“一条指令执行完再执行下一条”的最简执行策略。前文提到过,GPU为了隐藏内存访问的延迟,需要在内存访问指令为执行完前,先分配warp去执行其他指令。这里的策略其实就是动态指令调度,根据指令依赖关系和执行单元可用性,动态决定指令发射顺序。但此处有一个重要条件,就是先分配执行的这个其他指令,不能依赖于未完成指令的结果,否则无法执行。因此,需要先判断指令之间是否存在依赖关系,才能选择出不依赖未完成指令的指令进行执行。为了分析指令之间的依赖关系,以支持乱序执行,第二步为我们的系统增加了I-Cache、I-Buffer和ScoreBoard三个组件,并且ALU和MEM又多了一个指向ScoreBoard的“回写”操作。I-Cache(指令缓存)、I-Buffer(指令缓冲区):缓存从内存中读取的指令,和解码后的指令。此二者将一系列指令存放在一起,用于进行依赖分析,并在分析结束后快速读取指令进行乱序执行。I-Cache和I-Buffer为指令依赖分析提供了数据,ScoreBoard(计分牌)则是实际执行依赖分析操作的组件。GPU计分板的核心目标是检测指令间的数据依赖关系(如RAW、WAR、WAW),并控制指令发射顺序以避免冲突。数据依赖关系反映到硬件层面体现为对寄存器的读写依赖关系,因此,GPU的计分板被设计为一个bitmap,其记录了每一条未完成指令的目标寄存器,即如果这条指令要写寄存器R1,则将R1对应的bit置为1。在指令完成后,再将R1对应的bit写回0。
由于寄存器是线程私有的,需要为每个线程分配足够的寄存器,因此SIMT核心中的寄存器数量是很大的,即便做到一个寄存器只需要一个bit表示状态,ScoreBoard也会变得过大。因此,实际设计中,每个warp维护一个自己的ScoreBoard,由于每个warp同一时间只能执行同一条指令,一条指令能访问的寄存器也是有限的,因此每个warp的ScoreBoard有3-4bit即可,每一个bit称为一个表项(entry)。在判断一条指令是否能执行时,将该指令的源/目标寄存器与其所属warp的计分板表项做比较(计算AND),生成依赖位向量(Dependency Bit Vector)。如果依赖位向量有任何一位为1,则说明存在数据冲突(依赖),该指令不能执行,反之如果全部为0,则可以发射执行。
第三步:提高并发指令的数据供给效率
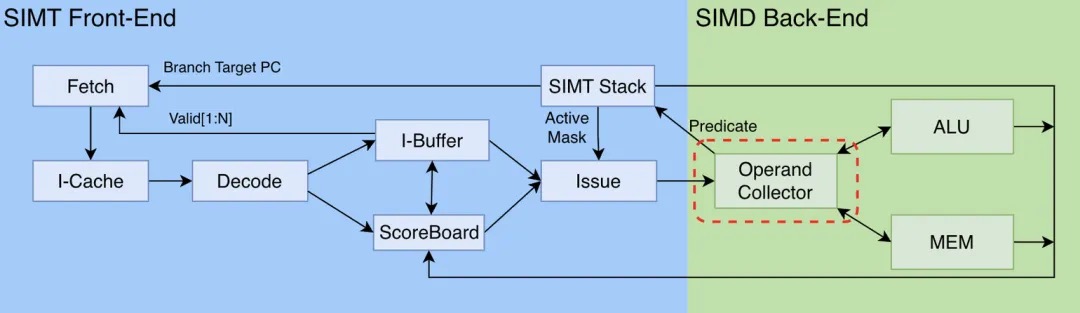
寄存器是处理器内部的高速存储单元,用于临时存放指令执行过程中所需的操作数、中间结果和地址信息。在GPU中,每个SIMT核心都拥有独立的寄存器文件(寄存器的集合体,本质上是一组寄存器组成的存储阵列)。第二步引入的计分板(ScoreBoard)机制,解决了时序维度上的数据依赖问题,从而支持发射无依赖指令进行延迟隐藏,除了时序上的复杂性,指令并行还会带来空间上的复杂性,即大量并发指令同时尝试访问寄存器文件获取指令数据,寄存器文件必须支持多warp并发访问。
端口(port),是读写存储单元的接口。每多一个端口,存储单元就可以多支持一个并发读写操作,单端口的情况下,同时只能支持一个读或一个写,若一个读操作与一个写操作并发,则只能串行执行,而增加一个端口,称为双端口,则此时的一读一写就可以并发完成。因此,为了支持大量warp并发访问寄存器数据,一个简单粗暴的做法是,为寄存器文件设计足够多的端口,来容纳所有并发读写操作。尽管多端口设计在理论上可行,但其硬件代价呈指数级增长,包括导致芯片面积暴增,同时,动态功耗会随端口数平方增长、高访问延迟等。因此,简单的硬件堆料是低效且不可取的。PS:之后就是各种优化细节,目的是解决并发执行中的数据访问冲突问题
其它
- 理论算力计算:GPU算力常以FLOPS(Floating-Point Operations Per Second,每秒浮点运算次数)来表示,通常数量级为T(万亿),也即是大家听到的TFLOPS。最常见的计算方式为CUDA核心计算法。
# CUDA核心计算法 算力(FLOPS)= CUDA核心数 × 加速频率 × 每核心单个周期浮点计算系数 # 以A100为例 A100的算力(FP32单精度)= 6912(6912个CUDA核心) × 1.41(1.41GHz频率) × 2(单周期2个浮点计算) = 19491.84 GFLOPS ≈ 19.5 TFLOPS - 实测性能评估:通过计算只能得到纸面上的理论算力,如果同学们手上真的有GPU,那么实测性能评估则可以直接让你获取你的GPU的性能。此处为大家提供几种最常见的实测方式和思路。首先推荐一个非常实用的工具 GPU-Z,它是一款免费工具,可提供计算机中显卡的详细参数信息,支持实时监控 GPU 负载、温度、显存使用情况等关键数据,是排查显卡性能问题或计算故障的实用诊断工具。GPU-Z是监控工具,而3DMark则是最流行的性能测试工具,通过模拟高负载游戏场景评估电脑图形处理能力(在steam平台即可购买,电脑上有GPU的同学不妨买来跑个分试试)。最后再介绍一下GEMM(General Matrix Multiplication,通用矩阵乘法),这是一种经典的并行计算领域的计算密集型应用,与跑分工具这样的封装好的峰值性能测试工具相比,GEMM的重点反而不是进行性能测试,而是不断调整优化逼近理论峰值的过程。GEMM通过执行时间 T 和总操作数(M×K与K×N的两矩阵相乘)计算实测算力:
算力 = 总操作数 / 执行时间 = A(M, K) × B(K, N)/ T = 2 × M × N × K / T如果实测算力低于GPU理论峰值算力,则表明可能存在低效内存访问、计算资源利用率低、未充分利用硬件加速单元等问题,这些问题均可通过逐步优化来解决,以逼近理论峰值,当然也有温度/功耗问题和显存带宽瓶颈等硬问题,但影响较小。对实际操作进行GPU编程有兴趣的同学可以选择深入了解GEMM,学习实现的比较好的GEMM库是如何优化以逼近理论峰值的,在这个过程中深入理解GPU计算和编程。
与模型的关系(不完整):在计算模型推理时,我们通常会将模型视为单个块(block),但实际上模型由许多矩阵组成。当我们运行推理时,每个矩阵都被加载到内存中。具体来说,每个矩阵的块被加载到设备内存中,即共享内存单元(在A100上只有192KB)。然后,该块用于计算批次中每个元素的结果。需要注意的是,这与GPU RAM(即HBM)不同,A100具有40GB或80GB的HBM,但只有192KB的设备内存。因为我们不断地在设备内存中搬运数据,所以这在执行数学运算时会导致一个内存带宽瓶颈。我们可以通过计算模型大小/内存带宽比来近似传输权重所需的时间,并通过模型FLOPS/GPU FLOPS来近似计算所需的时间。
留下评论