influxdb入门
前言(未完成)
时序模型是专门设计用于高效存储、索引和查询时间序列数据的系统。时间序列数据是指按时间顺序排列的数据序列,每个数据点通常包含一个时间戳和一个或多个与该时间相关的值,广泛应用于监控系统、金融分析、物联网(IoT)、传感器网络、气象预报等领域。
MySQL 的执行引擎和存储引擎是分开的。存储引擎提供了一些基础的方法(比如通过索引,或者扫描表)来获取表数据,而做连接、计算等功能,是在 MySQL 的执行引擎中完成的。
influxdb 提供统一的TICK 技术栈,The TICK stack - Open Source Components
- Telegraf - Data collection
- InfluxDB - Data storage
- Chronograf - Data visualization
- Kapacitor - Data processing and events
InfluxDB自带web管理界面,在浏览器中输入 http://服务器IP:8083 即可进入web管理页面。
schema
与传统数据库中的名词做比较
| influxDB中的名词 | 传统数据库中的概念 |
|---|---|
| database | 数据库」 |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
InfluxDB中独有的概念
Point由时间戳(time)、数据(field)、标签(tags)组成。
Point相当于传统数据库里的一行数据,如下表所示:
| Point属性 | 传统数据库中的概念 |
|---|---|
| time | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields | 各种记录值(没有索引的属性)也就是记录的值:温度, 湿度 |
| tags | 各种有索引的属性:地区,海拔 |
存储
InfluxDB 采用的时间结构合并树(Time-Structured Merge Tree, TSM)存储引擎是对日志结构化合并树(Log-Structured Merge Tree, LSM)的一种优化和定制。
LSM 树
- Memtable:位于内存中,用于存储新写入的数据,按 Key 排序。Memtable 作为写缓存,提高写入速度,但易受断电影响导致数据丢失,故需配合WAL机制。
- Immutable Memtable:当 Memtable 达到一定大小后,会转换为 Immutable 状态,不再接受写操作,等待刷写到磁盘。
- SSTable(Sorted String Table):Immutable Memtable 经过压缩和排序后形成的持久化文件,存储在磁盘上,数据有序且不可更改,多个 SSTable 通过层次结构进行管理,以支持高效查询。
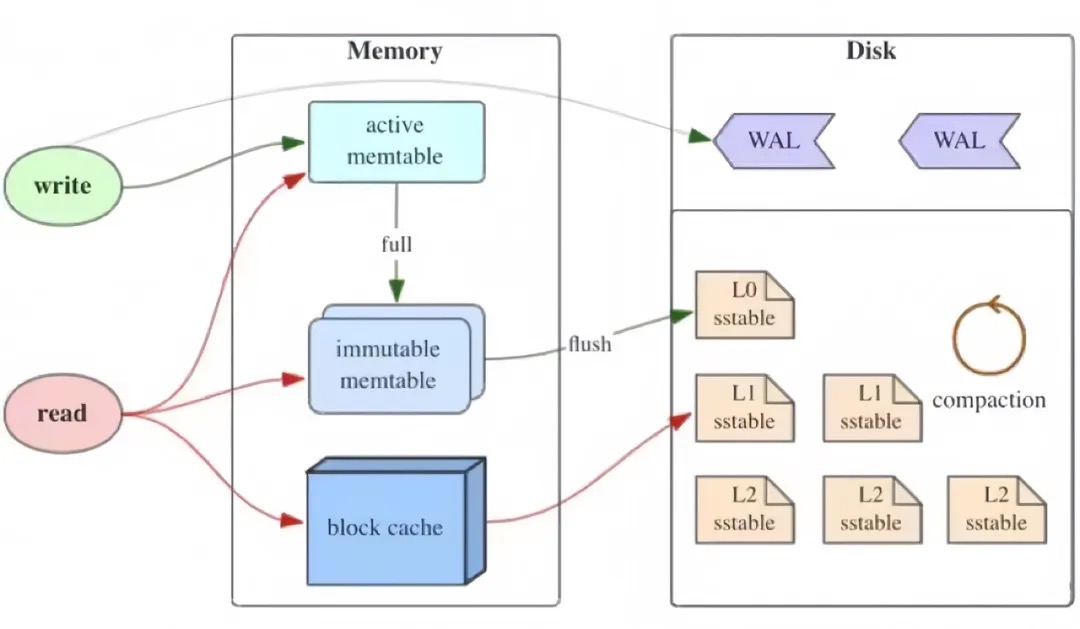
TSM 存储引擎改进与机构
- Cache:类似于 LSM 中的 Memtable,用于暂存新写入的数据,但针对时间序列数据进行了优化,考虑了时间戳的重要性。
- WAL(Write-Ahead Log):同样用于确保数据的持久性,先于实际数据写入记录,即使系统崩溃也能恢复。
- TSM File:是 InfluxDB 特有的数据文件格式,结合了时间序列特点,相较于 SSTable,TSM 对数据进行了更高效的压缩和组织,包括数据分块、字典压缩等,减少存储空间并加快读取速度。
- Compactor:负责整理和压缩 Cache 及 TSM File,包括将多个小的 TSM File 合并成更大的文件,移除过期数据,以及维护索引以加速查询。这一过程进一步优化存储效率和查询性能。
- Shard:这是 InfluxDB 中数据分区的概念,基于时间范围划分数据,每个 Shard 包含独立的 Cache、WAL和 TSM File 集合,以及 Compactor 作业。Sharding 机制便于管理和优化大规模时间序列数据的存储与查询。
留下评论