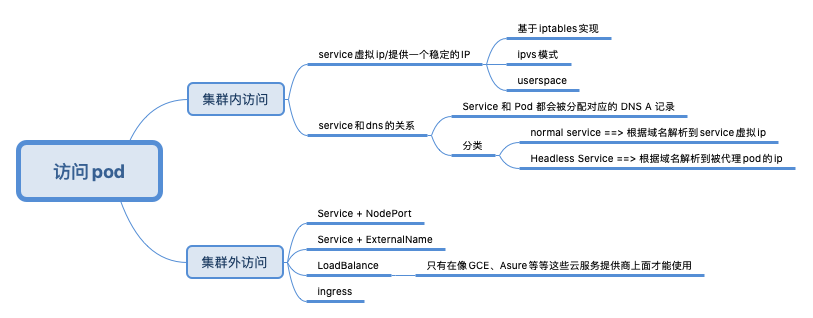
访问Kubernetes上的Service
简介
服务发现技术选型那点事儿常规的“服务发现”是“客户端的服务发现(client-side service discovery)”,假设订单系统运行在四个节点上,每个节点有不同的 IP 地址,那我们的调用者在发起 RPC 或者 HTTP 请求前,是必须要清楚到底要调用个节点的。在微服务世界,我们很希望每个服务都是独立且完整的,就像面向对象编程一样,细节应该被隐藏到模块内部。比如对于一个订单服务,在外来看它就应该是“一个服务”,它内部的几个节点是否可用并不是调用者需要关心的,这些细节我们并不想关心。按照这种想法,服务端的服务发现(server-side serivce discovery)会更具有优势,其实我们对这种模式并不陌生,在使用 NGINX 进行负载均衡的代理时,我们就在实践这种模式,一旦流量到了 proxy,由 proxy 决定下发至哪个节点,而 proxy 可以通过 healthcheck 来判断哪个节点是否健康。
深入理解 Kubernetes 网络模型 - 自己实现 kube-proxy 的功能在 kubernetes 中,您可以将应用程序定义为 Service。Service 是一种抽象,它定义了一组 Pods 的逻辑集和访问它们的策略。
在对应用进行横向扩容时,会在 Pod 网络中加入新的 Pod,新 Pod 自然也伴随着新的 IP 地址;如果对应用进行缩容,旧的 Pod 及其 IP 会被删除。应用的滚动更新和撤回也存在同样的情形——加入新版本的新 Pod,或者移除旧版本的旧 Pod。新 Pod 会加入新 IP 到 Pod 网络中,被终结的旧 Pod 会删除其现存 IP。如果没有其它因素,每个应用服务都需要对网络进行监控,并管理一个健康 Pod 的列表。这个过程会非常痛苦,另外在每个应用中编写这个逻辑也是很低效的。幸运的是,Kubernetes 用一个对象完成了这个过程——Service。
Kubernetes 网络异常分类及排错指南一个具体的排查实例,写的非常好。
Kubernetes 集群中流量暴露的几种方案 侧重于南北流量。
What is a service?
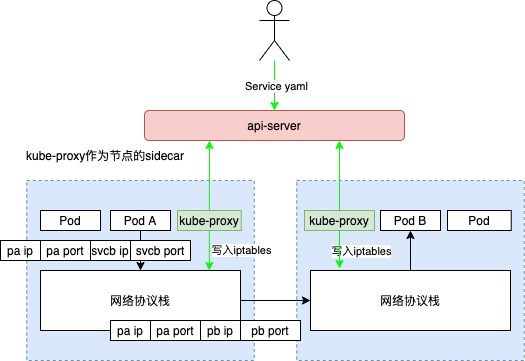
kube-proxy 运行在所有节点上,它监听 apiserver 中 service 和 endpoint 的变化情况,创建路由规则以提供服务 IP 和负载均衡功能。简单理解此进程是 Service 的透明代理兼负载均衡器,其核心功能是将到某个 Service 的访问请求转发到后端的多个 Pod 实例上。PS:service 相当于是 kube-proxy工作的配置文件。
Kubernetes 之所以需要 Service,一方面是因为 Pod 的 IP 不是固定的,另一方面则是因为一组 Pod 实例之间总会有负载均衡的需求。
一文读懂容器网络发展一句话概括 Service 的原理就是:Service = kube-proxy + iptables 规则。当一个 Service 创建时,K8s 会为其分配一个 Cluster IP 地址。这个地址其实是个 VIP,并没有一个真实的网络对象存在。这个 IP 只会存在于 iptables 规则里,对这个 VIP:VPort 的访问使用 iptables 的随机模式规则指向了一个或者多个真实存在的 Pod 地址(DNAT,将原本访问 ClusterIP:Port的数据包 DNAT 成 Service 的某个 Endpoint (PodIP:Port),然后内核将连接信息插入 conntrack 表以记录连接,目的端回包的时候内核从 conntrack 表匹配连接并反向 NAT,这样原路返回形成一个完整的连接链路),这个是 Service 最基本的工作原理。那 kube-proxy 做什么?kube-proxy 监听 Pod 的变化,负责在宿主机上生成这些 NAT 规则。这个模式下 kube-proxy 不转发流量,kube-proxy 只是负责疏通管道。
在 Grafana 中显示 K8s Service 之间的依赖关系
How do they work?——基于iptables实现
利用 eBPF 支撑大规模 K8s Service 对Service 的实现解释的非常精到。
K8S 集群的服务,本质上是负载均衡,即反向代理;在实际实现中,这个反向代理,并不是部署在集群某一个节点上(有单点问题),而 是作为集群节点的边车,部署在每个节点上的。把服务照进反向代理这个现实的,是 K8S 集群的一个控制器,即 kube-proxy。简单来 说,kube-proxy 通过集群 API Server 监听 着集群状态变化。当有新的服务被创建的时候,kube-proxy 则会把集群服务的状 态、属性,翻译成反向代理的配置。K8S 集群节点实现服务反向代理的方法,目前主要有三种,即 userspace、 iptables 以及 ipvs,k8s service 选了iptables。实现反向代理,归根结底,就是做 DNAT,即把发送给集群服务 IP 和端口的数 据包,修改成发给具体容器组的 IP 和端口。
Pod IP 地址是实际存在于某个网卡(可以是虚拟设备)上的,但Service Cluster IP就不一样了,没有网络设备为这个地址负责。它是由kube-proxy使用Iptables规则重新定向到其本地端口,再均衡到后端Pod的。
A service provides a stable virtual IP (VIP) address for a set of pods. It’s essential to realize that VIPs do not exist as such in the networking stack. For example, you can’t ping them. They are only Kubernetes- internal administrative entities. Also note that the format is IP:PORT, so the IP address along with the port make up the VIP. Just think of a VIP as a kind of index into a data structure mapping to actual IP addresses.
When a pod is scheduled, the master adds a set of environment variables for each active service.
示例
apiVersion: apps/v1
kind: Deployment
metadata:
name: hostnames
spec:
selector:
matchLabels:
app: hostnames
replicas: 3
template:
metadata:
labels:
app: hostnames
spec:
containers:
- name: hostnames
image: k8s.gcr.io/serve_hostname
ports:
- containerPort: 9376
protocol: TCP
用 selector 字段来声明这个 Service 只代理携带了 app=hostnames 标签的 Pod
apiVersion: v1
kind: Service
metadata:
name: hostnames
spec:
selector:
app: hostnames
ports:
- name: default
protocol: TCP
port: 80 # 通过Service暴露出来的一个Port,可以在Cluster内进行访问。
targetPort: 9376 # Pod和Container监听的Port.
一旦它被提交给 Kubernetes,那么 kube-proxy 就可以通过 Service 的 Informer 感知到这样一个 Service 对象的添加。而作为对这个事件的响应,它就会在宿主机上创建这样一条 iptables 规则
-A KUBE-SERVICES -d 10.0.1.175/32 -p tcp -m comment --comment "default/hostnames: cluster IP" -m tcp --dport 80 -j KUBE-SVC-NWV5X2332I4OT4T3
这条 iptables 规则的含义是:凡是目的地址是 10.0.1.175、目的端口是 80 的 IP 包,都应该跳转到另外一条名叫 KUBE-SVC-NWV5X2332I4OT4T3 的 iptables 链进行处理。这一条规则就为这个 Service 设置了一个固定的入口地址。并且,由于 10.0.1.175 只是一条 iptables 规则上的配置,并没有真正的网络设备,所以你 ping 这个地址,是不会有任何响应的。
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-X3P2623AGDH6CDF3
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -j KUBE-SEP-57KPRZ3JQVENLNBR
KUBE-SVC-NWV5X2332I4OT4T3 规则实际上是一组随机模式(–mode random)的 iptables 链,而随机转发的目的地,分别是 KUBE-SEP-WNBA2IHDGP2BOBGZ、KUBE-SEP-X3P2623AGDH6CDF3 和 KUBE-SEP-57KPRZ3JQVENLNBR,其实就是这个 Service 代理的三个 Pod。
-A KUBE-SEP-57KPRZ3JQVENLNBR -s 10.244.3.6/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-57KPRZ3JQVENLNBR -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.3.6:9376
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -s 10.244.1.7/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
-A KUBE-SEP-X3P2623AGDH6CDF3 -s 10.244.2.3/32 -m comment --comment "default/hostnames:" -j MARK --set-xmark 0x00004000/0x00004000
-A KUBE-SEP-X3P2623AGDH6CDF3 -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.2.3:9376
当你的宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中。
一个请求如何从 Service 到达 Pod ? 配图特别好。
ipvs 模式
Service服务负载均衡机制剖析 配图不错。
IPVS 也是构建在 netfilter 之上的,并作为 Linux 内核的一部分实现了传输层的负载均衡。它在主机上运行并充当真实服务器集群前面的负载均衡器,IPVS 可以将基于 TCP 和 UDP 的服务请求定向到真实服务器,并使真实服务器的服务作为虚拟服务出现在一个 IP 地址上。在使用 IPVS 模式的 Service 时,会发生三件事:在 Node 节点上创建一个虚拟 IPVS 接口,将 Service 的 VIP 地址绑定到虚拟 IPVS 接口,并为每个 Service VIP 地址创建 IPVS 服务器。
iptables与IPVS都是基于Netfilter实现的,但因为定位不同,二者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的规模扩张。
IPVS在Kubernetes1.11中升级为GA稳定版。在IPVS模式下,使用iptables的扩展ipset,而不是直接调用iptables来生成规则链。iptables规则链是一个线性的数据结构,ipset则引入了带索引的数据结构,因此当规则很多时,也可以很高效地查找和匹配。可以将ipset简单理解为一个IP(段)的集合,这个集合的内容可以是IP地址、IP网段、端口等,iptables可以直接添加规则对这个“可变的集合”进行操作,这样做的好处在于可以大大减少iptables规则的数量,从而减少性能损耗。
MySQL 在 Kubernetes IPVS 模式下引发的 TCP 超时问题
Service 的特别形式
iptables 和 ipvs 只是解决了负载均衡的问题,还没提到服务透出。K8s 服务透出的方式主要有 NodePort、LoadBalancer 类型的 Service。K8S 中定义了 4种 Service 类型:
- ClusterIP: 通过 VIP 访问 Service,但该 VIP 只能在此集群内访问
- NodePort: 通过 NodeIP:NodePort 访问 Service,这意味着该端口将保留在集群内的所有节点上
- ExternalIP: 与 ClusterIP 相同,但是这个 VIP 可以从这个集群之外访问
- LoadBalancer
- headless service, 设置了selector,但将 spec.clusterIP 设置成 None。因为没有ClusterIP,kube-proxy 并不处理此类服务,因为没有load balancing或 proxy 代理设置,在访问服务的时候回返回后端的全部的Pods IP地址。 如果servicename 与pod name一致且一对一,则可以起到 通过podname 访问另一个pod的效果。适合用于一些stateful 的workload 彼此间相互访问(stateful workload pod 间一般角色确定)
LoadBalancer
kind: Service
apiVersion: v1
metadata:
name: example-service
spec:
type: LoadBalancer
ports:
- port: 8765
targetPort: 9376
selector:
app: example
NodePort
所谓 Service 的访问入口,其实就是每台宿主机上由 kube-proxy 生成的 iptables 规则,以及 kube-dns 生成的 DNS 记录。而一旦离开了这个集群,这些信息对用户来说,也就自然没有作用了。比如,一个集群外的host 对service vip 一点都不感冒。
apiVersion: v1
kind: Service
metadata:
name: my-nginx
labels:
run: my-nginx
spec:
type: NodePort
ports:
- nodePort: 8080 # Cluster向外网暴露出来的端口,可以让外网能够访问到Pod/Container.
targetPort: 80
protocol: TCP
name: http
- nodePort: 443
protocol: TCP
name: https
selector:
run: my-nginx
ExternalName
kind: Service
apiVersion: v1
metadata:
name: my-service
spec:
type: ExternalName
externalName: my.database.example.com
Ingress
Ingress exposes HTTP and HTTPS routes from outside the cluster to services within the cluster. Traffic routing is controlled by rules defined on the Ingress resource. An Ingress may be configured to give Services externally-reachable URLs, load balance traffic, terminate SSL / TLS, and offer name based virtual hosting.
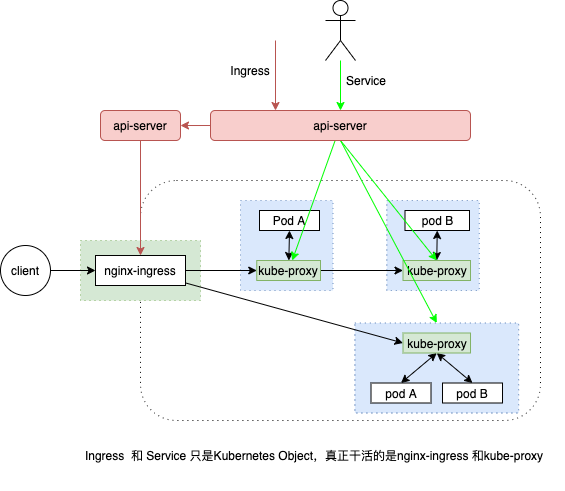
| 对外形态 | Kubernetes Object | 工作组件 |
|---|---|---|
| ip | Pod | docker |
| stable virtual ip | Service | apiserver + kube-proxy |
| externally-reachable URLs | Ingress | apiserver + nginx-ingress |
Ingress和Pod、Servce等等类似,被定义为kubernetes的一种资源。本质上说Ingress只是存储在etcd上面一些数据,我们可以通过kubernetes的apiserver添加删除和修改ingress资源。
有了 Ingress 这样一个统一的抽象,Kubernetes 的用户就无需关心 Ingress 的具体细节了。在实际的使用中,你只需要从社区里选择一个具体的 Ingress Controller,把它部署在 Kubernetes 集群里即可。这个 Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。目前,业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为 Kubernetes 专门维护了对应的 Ingress Controller。PS: 把nginx 搬到k8s上,把路由规则 k8s object化,service作为backend。
Ingress Controller 部署和实现
从 Nginx Ingress 窥探云原生网关选型 值得细读。
部署 Nginx Ingress Controller Installation with Manifests 简单安装可以使用 helm Installation with Helm 注意处理下google 的镜像源问题。nginx ingress 会安装一个 Deployment:ingress-nginx-controller 在 ingress-nginx namespace 下(helm 安装的好像不是 这个namespace),这个 Pod 本身就是一个监听 Ingress 对象以及它所代理的后端 Service 变化的控制器。
当一个新的 Ingress 对象由用户创建后,nginx-ingress-controller 就会根据Ingress 对象里定义的内容,生成一份对应的 Nginx 配置文件(/etc/nginx/nginx.conf),并使用这个配置文件启动一个 Nginx 服务。而一旦 Ingress 对象被更新,nginx-ingress-controller 就会更新这个配置文件。如果这里只是被代理的 Service 对象被更新,nginx-ingress-controller 所管理的 Nginx 服务是不需要重新加载(reload)的,因为其通过Nginx Lua方案实现了 Nginx Upstream 的动态配置。
Ingress 示例
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod-demo-for-test-ingress
labels:
app: nginx-pod-demo-for-test-ingress
spec:
containers:
- name: nginx-container
image: nginx
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service-demo-for-test-ingress
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
name: http
selector:
app: nginx-pod-demo-for-test-ingress
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-ingress
spec:
rules:
- host: localhost
http:
paths:
- path: /
backend:
serviceName: nginx-service-demo-for-test-ingress
servicePort: 80
一个 Ingress 对象的主要内容,实际上就是一个“反向代理”服务(比如:Nginx)的配置文件的描述。而这个代理服务对应的转发规则,就是 IngressRule。
root@ubuntu-01:~# kubectl get pod
NAME READY STATUS RESTARTS AGE
my-release-nginx-ingress-5c57477464-gssbk 1/1 Running 0 71m
nginx-pod-demo-for-test-ingress 1/1 Running 0 57m
root@ubuntu-01:~# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
my-release-nginx-ingress LoadBalancer 10.101.164.118 <pending> 80:32000/TCP,443:31723/TCP 64m
nginx-service-demo-for-test-ingress ClusterIP 10.103.226.14 <none> 80/TCP 49m
每个ingress 对象会有一个对应的pod 实际运行nginx ,以及一个LoadBalancer Service 作为这个pod的访问入口。
kubectl 进入my-release-nginx-ingress-5c57477464-gssbk,在/etc/nginx/conf.d 下可以看到 ingress 对应一个conf 文件。upstream 指定了 nginx pod对应的ip。 可见 虽然创建了 nginx service,但网络包并没有真正走 service iptables。
# configuration for default/nginx-ingress
upstream default-nginx-ingress-localhost-nginx-service-demo-for-test-ingress-80 {
zone default-nginx-ingress-localhost-nginx-service-demo-for-test-ingress-80 256k;
random two least_conn;
server 10.244.2.52:80 max_fails=1 fail_timeout=10s max_conns=0;
}
server {
listen 80;
server_tokens on;
server_name localhost;
location / {
proxy_http_version 1.1;
proxy_connect_timeout 60s;
proxy_read_timeout 60s;
proxy_send_timeout 60s;
client_max_body_size 1m;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Port $server_port;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_buffering on;
proxy_pass http://default-nginx-ingress-localhost-nginx-service-demo-for-test-ingress-80;
}
}
进化
超越 Gateway API:深入探索 Envoy Gateway 的扩展功能Ingress 是 Kubernetes 中定义集群入口流量规则的 API 资源。Ingress API 为用户提供了基本的定义 HTTP 路由规则的能力,但是 Ingress API 的功能非常有限,只提供了按照 Host、Path 进行路由和 TLS 卸载的基本功能。在实际应用中, Ingress API 的基本功能往往无法满足应用程序复杂的流量管理需求。这导致各个 Ingress Controller 实现需要通过 Annotations 或者自定义 API 资源等非标准的方式来扩展 Ingress API 的功能。这些非标准的扩展方式都导致 Ingress API 的可移植性变差,用户在不同的 Ingress Controller 之间切换时,需要重新学习和配置不同的 API 资源。分裂的 Ingress API 也不利于社区的统一和发展。为了解决 Ingress API 的问题,Kubernetes 社区提出了 Gateway API,Gateway API 是一个新的 API 规范,旨在提供一个统一的、可扩展的、功能丰富的 API 来定义集群入口流量规则。Gateway API 定义了多种资源,包括 Gateway、HTTPRoute、GRPCRoute、TLSRoute、TCPRoute、UDPRoute 等。原来很多需要通过 Annotations 或者自定义 API 资源来扩展的功能,现在都可以直接通过 Gateway API 来实现。但是任何一个标准,不管定义得多么完善,理论上都只能是其所有实现的最小公约数。Gateway API 作为一个通用的 API 规范,为了保持通用性,无法对一些和具体实现细节相关的功能提供直接的支持。例如,虽然请求限流、权限控制等功能在实际应用中非常重要,但是不同的数据平面如 Envoy,Nginx 等的实现方式各有不同,因此 Gateway API 无法提供一个通用的规范来支持这些功能。Gateway API 提供了 Policy Attachment 扩展机制,允许各个 Controller 实现在不修改 Gateway API 的情况下,通过关联自定义的 Policy 到 Gateway 和 HTTPRoute 等资源上,以实现对流量的自定义处理。此外,Gateway API 还支持将自定义的 Backend 资源关联到 HTTPRoute 和 GRPCRoute 等资源上,以支持将流量路由到自定义的后端服务。支持在 HTTPRoute 和 GRPCRoute 的规则中关联自定义的 Filter 资源,以支持对请求和响应进行自定义处理。
Services without selectors
Services, in addition to providing abstractions to access Pods, can also abstract any kind of backend(service不仅可以做访问pod的桥梁,还可以做访问任何后端的桥梁). For example:
- you want to have an external database cluster in production, but in test you use your own databases.
- you want to point your service to a service in another Namespace or on another cluster.
- you are migrating your workload to Kubernetes and some of your backends run outside of Kubernetes.
In any of these scenarios you can define a service without a selector:
{
"kind": "Service",
"apiVersion": "v1beta1",
"id": "myapp",
"port": 80
}
Then you can explicitly map the service to a specific endpoint(s):
{
"kind": "Endpoints",
"apiVersion": "v1beta1",
"id": "myapp",
"endpoints": ["173.194.112.206:80"]
}
Accessing a Service without a selector works the same as if it had selector. The traffic will be routed to endpoints defined by the user (173.194.112.206:80 in this example).(以后,pod访问这个serivce的ip:80 就会被转到173.194.112.206:80了)(此时,一旦这个endpoint终止或者转移,k8s就不负责跟踪,并将specs与新的endpoint绑定了)
(serivce将请求转发到各个pod也是 “specs + endpoint”方式实现的 )
有了个这个endpoint + service,基本就解决了pod如何访问外网数据的问题。比如
etcd-service.json 文件
{
"kind": "Service",
"apiVersion": "v1beta1",
"id": "myetcd",
"port": 80
}
etcd-endpoints.json
{
"kind": "Endpoints",
"apiVersion": "v1beta1",
"id": "myetcd",
"endpoints": ["masterip:4001"]
}
那么在pod中,就可以通过myetcd的serviceip:80来访问master主机上的etcd服务了。
跨集群通信
其它
Kubernetes networking 101 – Services
Kubernetes networking 101 – (Basic) External access into the cluster
Kubernetes Networking 101 – Ingress resources
Getting started with Calico on Kubernetes(未读)
kubernetes和kubernetes-ro
kubernetes启动时,默认有两个服务kubernetes和kubernetes-ro
$ kubectl get services
NAME LABELS SELECTOR IP PORT
kubernetes component=apiserver,provider=kubernetes <none> 10.100.0.2 443
kubernetes-ro component=apiserver,provider=kubernetes <none> 10.100.0.1 80
Kubernetes uses service definitions for the API service as well(kubernete中的pod可以通过10.100.0.1:80/api/xxx来向api server发送控制命令,kubernetes-ro可操作的api应该都是只读的).
留下评论