线性RAG的进化——agentic rag
简介(未完成)
Agentic 源自 “Agent”(代理)在 AI 领域特指具有自主性、目标导向和决策能力的智能系统。Agentic RAG通过让大模型反复优化搜索关键词来提升召回率,本质上是在用推理成本去弥补检索能力的不足。PS:区别于传统的被动式AI系统。
使用具有自主决策能力的 Agent 实现的 RAG 系统可以称为 Agentic RAG。与传统的线性RAG(单轮检索,检索不到就没戏 + 单轮生成,容易被无关信息带偏)流程不同,Agentic 特性的产品是通过嵌入具有自主决策能力的专业化智能体,LLM 系统能够自主选择控制流程,从根本上解决了传统方法的局限。这些智能体能够动态管理检索策略、迭代优化上下文理解、适应复杂工作流程(比如在两条潜在路径之间进行路由;决定调用哪些工具;判断生成的答案是否足够,或者是否需要进一步工作),将系统从被动信息处理转变为主动理解问题并规划解决。将固定的工作流基于用户场景动态生成。PS:与Native RAG相比,一般可以认为至少引入了工具,自然也就伴随着问题拆解和工具的先后调用,以及最后的对多个observation的反思/总结。
对比Naive RAG
Naive RAG方法在处理简单问题时表现良好,然而,当面对更复杂的问题时,Naive RAG的局限性就显现出来了。
- 总结性问题:例如,“给我一个公司10K年度报告的总结”,Naive RAG难以在不丢失重要信息的情况下生成全面的总结。
- 比较性问题:例如,“Milvus 2.4 与Milvus 2.3 区别有哪些”,Naive RAG难以有效地进行多文档比较。
- 结构化分析和语义搜索:例如,“告诉我美国表现最好的网约车公司的风险因素”,Naive RAG难以在复杂的语义搜索和结构化分析中表现出色。
- 一般性多部分问题:例如,“告诉我文章A中的支持X的论点,再告诉我文章B中支持Y的论点,按照我们的内部风格指南制作一个表格,然后基于这些事实生成你自己的结论”,Naive RAG难以处理多步骤、多部分的复杂任务。 PS: 依赖简单的「意图识别」、「查询重写」手段已不足以解决复杂的Q&A问题,通过智能体对用户问题拆分、规划已开始提上日程。AgenticRAG 引入了工具调用,将 RAG 从原本的「检索增强」,逐步过渡到「工具增强」形态
Naive RAG上述痛点的原因
- 单次处理:Naive RAG通常是一次性处理查询,缺乏多步骤的推理能力。
- 缺乏查询理解和规划:Naive RAG无法深入理解查询的复杂性,也无法进行任务规划。
- 缺乏工具使用能力:Naive RAG无法调用外部工具或API来辅助完成任务。
- 缺乏反思和错误纠正:Naive RAG无法根据反馈进行自我改进。
终于让Agentic RAG工作流正常运行了Agentic RAG(代理型 RAG) 是与 AI 智能体架构一起使用的 RAG(检索增强生成)。
- 首先,它需要具有一定的自主决策能力,如果你编写了一个执行一系列步骤的程序,其中一步是调用 LLM——恭喜你!你已经构建了一个调用 LLM 的程序工作流,只是不要称它为 AI 智能体。
- AI 智能体还需要有某种与环境交互的方式。对于软件来说,这意味着进行 API 调用、检索数据、向 LLM 发送提示等。大多数 LLM 仅支持一种类型的工具:函数。
| 对比维度 | 传统RAG | Agentic RAG | 优势提升 |
|---|---|---|---|
| 架构核心 | 检索-生成管道 | Agent框架+RAG工具 | 从流程到智能体的范式转变 |
| 决策机制 | 固定流程或简单规则 | 自主动态规划 | 应对复杂任务的灵活性 |
| 检索策略 | 单一检索模式 | 多策略动态选择 | 适配多样查询类型 |
| 多源处理 | 通常单一数据源 | 多源协同检索 | 综合异构信息能力 |
| 工具集成 | 有限或需硬编码 | 动态工具调用 | 扩展系统能力边界 |
| 反思能力 | 通常不具备 | 结果评估与过程优化 | 持续改进回答质量 |
| 适用场景 | 简单事实性查询 | 复杂研究与分析任务 | 商业价值的显著提升 |
技术范式
一般过程:通过多个模型,或者本模型自己的回归方式来实现多步分解问题进而拆解,进而逐步解决。AI Agent的概念、自主程度和抽象层次具备高度自主性的Agent,一般来说是由agent loop驱动的运行模式。在每一个循环迭代中,它借助LLM动态决策,自动调用适当的工具,存取恰当的记忆,向着任务目标不断前进,最终完成原始任务。
笔者曾微调模型(要准备要给微调数据集),实践了一下ircot,通过与检索器进行多轮对话,系统地规划检索和细化查询,以获取有价值的知识,,这个过程一直持续到收集到足够的外部信息为止。但这一块其实很不可控,由于检索器和检索语料库的限制,在某些情况下可能无法获取回答问题的必要知识,导致无限次迭代。另一个是这个底层是依赖于大模型的判定能力,在每次迭代中,LLM根据当前状态进行推理,确定是否需要进一步的检索以及检索的具体信息。LLM生成查询并根据检索到的文档进行信息提取和答案推断。细分下来就是:
- 检索规划能力,LLM需要明确识别解决查询所需的知识和进一步检索的具体信息。这意味着LLM在每次迭代开始时,都会评估当前已有知识的不足,并决定需要检索哪些新信息。
- 信息提取能力,一旦LLM收到检索到的文档,它需要从中提取解决问题的关键信息。这一步骤类似于人类在阅读文档时的信息筛选过程,旨在去除无关信息,保留有用内容。
- 答案推断能力,在收集到所有相关信息后,LLM使用推理来形成最终答案。这一步骤确保LLM能够基于现有信息生成准确且合理的答案,避免生成虚假信息。
ReWOO/planer+executor+reporter/summarier
多智能体微调实践:α-UMi 开源它要求LLM不仅要准确理解用户的查询意图,还要具备高超的任务规划能力、精准的工具选择与调用技巧,以及出色的总结归纳技能。其中,任务规划依赖于模型的逻辑推理能力;工具的选择与调用,则考验模型能否准确无误地编写请求;而工具调用结果的总结,则是对模型归纳总结技能的一次全面检验。传统的方法往往试图在单个开源LLM框架内整合所有这些复杂的能力,这一做法在面对容量更小的小型开源LLM时,其性能局限性尤为突出。更为严峻的是,现实世界中的工具更新迭代速度极快,这意味着一旦外部工具发生变化,整个LLM系统可能都需要重新训练和调整,这不仅耗费大量资源,也给模型的维护和升级带来了前所未有的挑战。因此,如何设计出既能保持灵活性和适应性,又能有效应对工具更新带来的挑战的LLM代理系统,成为了当前研究亟待解决的关键问题。为了应对上述的挑战,通义实验室提出了一种名为“α-UMi”的多LLM工具调用智能体框架。“α-UMi”将单一LLM的能力分解为三个部分模型执行:规划器、调用器和总结器。每个部分由单个LLM执行,专注于特定的功能。规划器依据系统当前状态生成策略,决定是否选择调用器或总结器生成后续输出。调用器根据策略调用具体工具,而总结器则在规划器的指导下,根据执行轨迹构建最终的用户答案。这些组件协同工作,共同完成任务。与先前的方法相比,α-UMi框架具有三大优势: 1. 每个组件针对特定角色进行训练,确保了各自功能的优化。 2. 其次,模块化设计允许各组件按需独立更新,保证了系统的适应性和维护效率。 3. 由于每个组件聚焦于单一功能,缓解了模型等容量限制,意味着可以在小型LLM对工具调用智能体进行部署。 PS: 好想法,就是工作量有点大,训练时为每个模型准备单独的样本?文中给出了代码框架和 基于一个base 模型微调后的规划器、调用器和总结器模型。caller 用一个function-call 来训练应该问题不大。
CoRAG
multistep 是单一的链式结构,链式结构中间的一个step的判断错误或者偏离了问题的本质,导致最终的输出会长且错(当然这里也会通过经过self-correct等训练方式来补救)
在 CoRAG 中
- 候选链生成,CoRAG 会同时生成多个「查询-子答案链条」(检索链),每个链条是一个候选样本。
- 计算接受概率(评估链条质量),根据当前链条的子答案质量、预测得分(模型给出的概率)等指标,模型可以评估某条链条是否可能通向正确答案。
- 筛选有效链条(拒绝不好的链条),如果某条链的得分很低,或者生成的子答案不合理(比如与目标问题无关),模型会直接丢弃这条链,重新探索新的链条。
- 选最优答案,通过拒绝那些“不可能得出正确答案”的链条,模型最终能保留较优解,避免浪费计算资源。 这个最好的链是怎么选的呢?需要你对模型LLM进行训练。优化学习更好生成子查询,更好生成子回答,更好生成最终答案。 PS:微调模型来提高拆解子问题的能力。
计划和反思
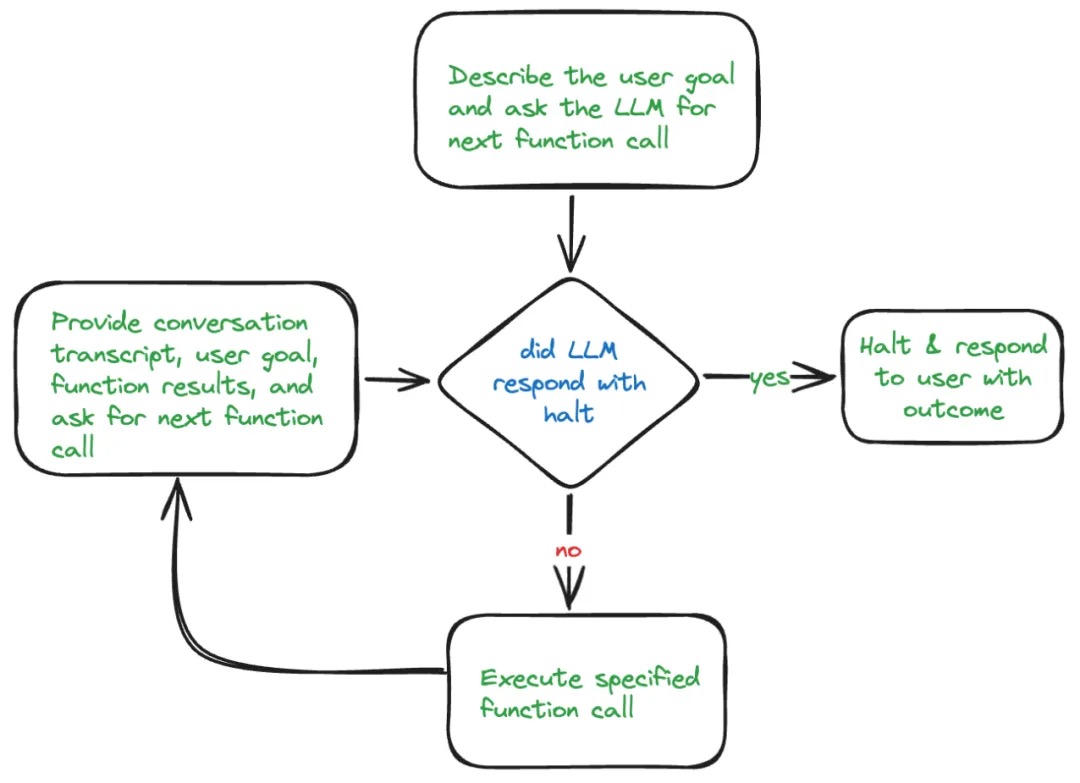
LLM 在具代理性的系统中如何决定使用哪个工具以及何时使用呢?这就是计划的作用。 LLM 代理中的计划涉及将给定任务分解为可操作的步骤。
- no plan。llm 隐式的有一个计划,但不外漏。
- 交错分解/plan next/react,执行完一个再决定下一个执行的内容,适合执行过程确定性不太强,比较发散的任务,系统一般需要人参与(比如卖家助手)。
- 如果任务比较复杂,不确定性比较高,随着执行轮数的增长,后面的计划可能会遗忘前面执行计划的结果,工程上需要做好优化。
- 分解优先/plan ahead/planning+execution。 在一开始就将任务分解为子目标,并提前规划好所有的任务,最后一个一个执行。适合执行过程确定性比较强的任务、不需要或者少需要人参与的系统。(比如代码生成)
- 非常依赖子任务的稳定性,如果子任务有问题,可能会影响整个任务的完成;
- 有时生成的计划赶不上变化和实际不符合,所以即便生成了计划,往往也会根据检索到的信息调整/replan(动态plan,多轮,in the loop)。
没有人,即使是具有 ReAct 的 LLM,也并非每个任务都能完美完成。失败是过程的一部分,只要你能反思这个过程就行。
任务规划是一个相对模糊的概念,至少在智能体系统内,有两类规划场景。
- 一类是面向不确定的用户原始问题,如何拆分为具体的子任务,并安排好子任务的执行和依赖关系,即任务拆分,产出为 JobGraph。
- 另一类则是针对特定领域的子问题,如何设计合理的流程对任务分阶段处理,即 SOP,产出为 Workflow。 其实这两类场景其实本质是相同的,一种玩法是,JobGraph 更侧重于描述智能体间的职责分配,Workflow 则更侧重描述单智能体内部的职责,仅仅是对用户目标的拆分粒度在不同的层面而已。 PS:由此想到,一个问题适合multi agent解决还是单个agent(function+tool + 知识库)解决,不是一成不变的。一个可能的路线是,一开始系统沉淀的 agent比较少,靠multi-agent plan+几个基本的、无业务内涵的agent 驱动,这类问题不确定性大,plan ahead 都比较难,只能plan next。此时问题靠multi-agent(plan + common agent)解决,有一个60分体验。后续业务清晰了,相同问题归类为一个agent,有明确思路的问题用特定agent 解决(此时可以plan ahead ,或者大概率workflow 就够了),对这类问题,plan node路由好就可以。对这类问题提供90分体验。也契合了leader/架构师做方案解决未知问题,骨干解决明确问题。
计划
如何让 Agent 规划调用工具根据 Anthropic 和 OpenAI 的建议,对于多工具的 Agent 智能体,让模型在调用工具前规划都能有效提升效果。
- OpenAI 是通过 Prompt 引导模型思考,Prompt 如下:
You MUST plan extensively before each function call, and reflect extensively on the outcomes of the previous function calls. DO NOT do this entire process by making function calls only, as this can impair your ability to solve the problem and think insightfully. - Anthropic 的办法是让模型调用思考工具(思考工具化),并提供示例,让模型调用工具前/调用工具后思考。思考工具的定义如下:
{ "name": "think", "description": "Use the tool to think about something. It will not obtain new information or change the database, but just append the thought to the log. Use it when complex reasoning or some cache memory is needed.", "input_schema": { "type": "object", "properties": { "thought": { "type": "string", "description": "A thought to think about." } }, "required": ["thought"] } }
原因是 OpenAI 并不是单纯通过 Prompt 指令让模型规划,他们还通过后训练让模型严格遵循这一指令。而我们使用开源模型,没有经过微调的话,指令遵循的效果肯定会打折,而以工具的形式能够提升遵循能力:
- 模型调用工具有固定的格式,例如参数的 thought, plan, action,通过工具调用能够让模型以更结构化的方式输出,不会遗漏;
- 「调用xx工具」是一个可明确执行和评判的指令,而「做一个规划」是一个模糊的指令,相对来说以工具的形式指令遵循效果更好,尤其是在复杂 prompt 和多工具的场景。
当然类 manus 的方案通过链路工程让规划和执行分离(如下图),Agent 系统的规划和遵循规划的能力肯定会更好,尤其是针对15分钟甚至30分钟以上的长程任务。但是不是所有场景都需要类 manus 的长程任务规划,我在这里介绍的方案比较轻量,适用于快速任务(期望完成任务的时间较短)。
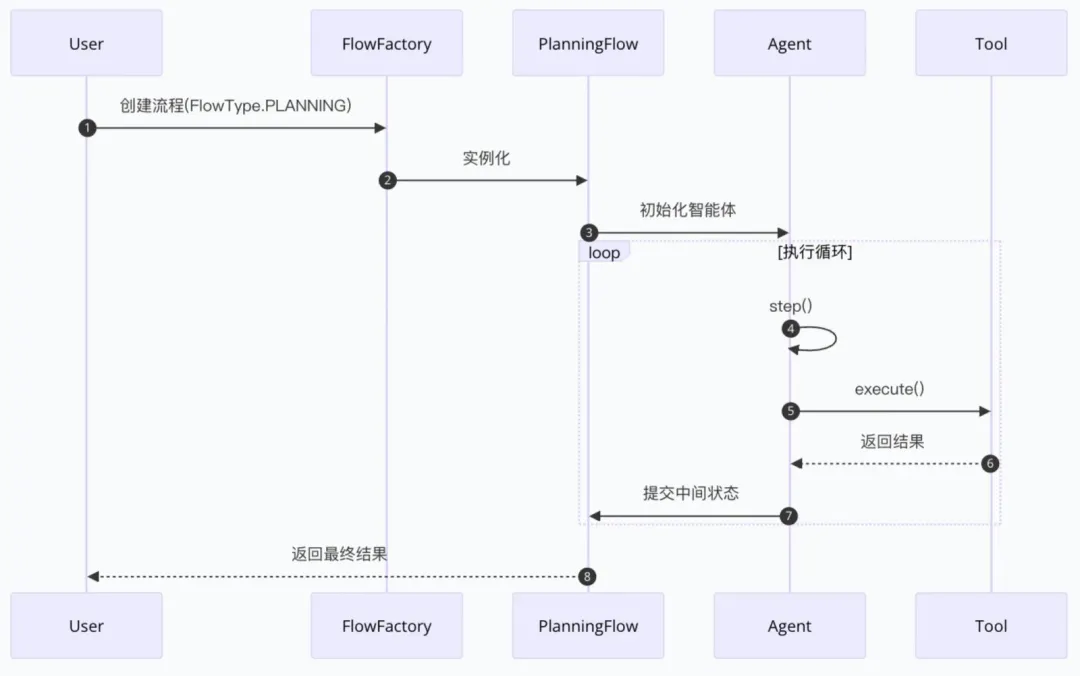
技术架构
Agentic RAG: 构建自主决策型检索增强系统 与顺序式简单 RAG 架构相比,代理式 RAG 架构的核心是代理。Agentic RAG架构
- 单代理 RAG(路由器),最简单的形式是,其核心思想是构建一个具备规划能力的 Master 智能体,将各种RAG管道和外部工具作为该 Agent 可调用的”工具”。在这种架构中,传统RAG的检索器、生成器等组件被工具化,成为 Agent 执行计划时可选择的资源。当用户查询进入系统后,Master Agent 会首先分析查询意图和复杂度,然后动态规划解决方案,可能包括:决定是否需要检索、选择哪种检索策略(如向量检索、关键词检索或混合检索)、确定是否需要进行多步检索以及是否需要调用外部工具等。
- 单代理RAG仅限于一个代理,集推理、检索和答案生成于一体。设计相对简单,适合中等复杂度的应用场景。
- 多Agent分层架构(多agent 自由博弈在RAG场景下一般不太实用),通过引入层级化的 Agent 组织,实现关注点分离和专业化分工。典型的双层架构包含一个顶层协调Agent和多个专业领域Agent,每个下层Agent负责特定类型的数据源或任务,而顶层Agent则负责任务分解、协调和结果整合。
- 多Agent架构的核心优势在于其卓越的可扩展性和专业分工
对应用的影响
AI 产品思维:我如何把一个 AI 应用从基础 RAG 升级到 multi-agent 架构从工作流的定义到边界与目标定义:软件产品专注于定义明确的用户旅程和工作流程。去梳理业务场景,然后把业务拆解为可解释的固定环节,然后对应构建产品,每个步骤都有确定的输入、输出和 UI 元素。产品经理精确规定系统在每个场景中的行为。AI 产品则需要根本不同的方法。产品经理不再规定精确工作流,而是定义:
- 边界:智能体责任范围的清晰界限,
- 目标:成功结果的明确标准,
- 环境/容器:智能体有效运行所需的上下文环境
这种面向目标的方法关注智能体应当实现什么,而非在每种可能情况下如何实现,要更加的拥抱灰度,与此同时,要构建评估思维,因为需求的迭代不再是固定且线性的,这就需要有很强的评估思维(解决方案可能从”超出期望”到”基本满足需求”再到”没有解决问题”形成价值连续体),根据结果来反推 AI 系统中某个环节或某个变量的调整,形成反馈循环。
留下评论