重新认识cpu
简介
- 简介
- cpu 指令执行
- 五级流水线
- 多层次内存结构
- cpu/服务器 三大体系numa smp mpp
- 并行计算能力
- SIMD(Single Instruction Multiple Data)
- 指令集
- 高密度计算场景下 CPU 架构新选择:云原生处理器和创新的硬件架构
- 其它
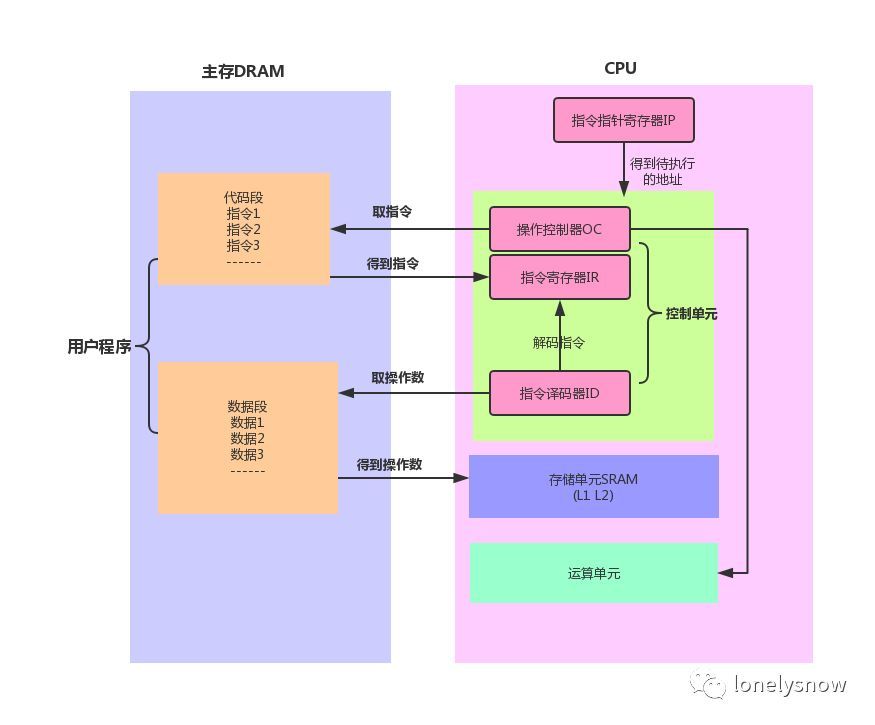
- CPU 可以直接访问的存储资源非常少,只有:寄存器、内存(RAM)、主板上的 ROM。
- 寄存器的访问速度非常非常快,但是数量很少,大部分程序员不直接打交道,而是由编程语言的编译器根据需要自动选择寄存器来优化程序的运行性能。
- 内存的地位非常特殊,它是唯一的 CPU 内置支持,且和程序员直接会打交道的基础资源。
cpu 指令执行
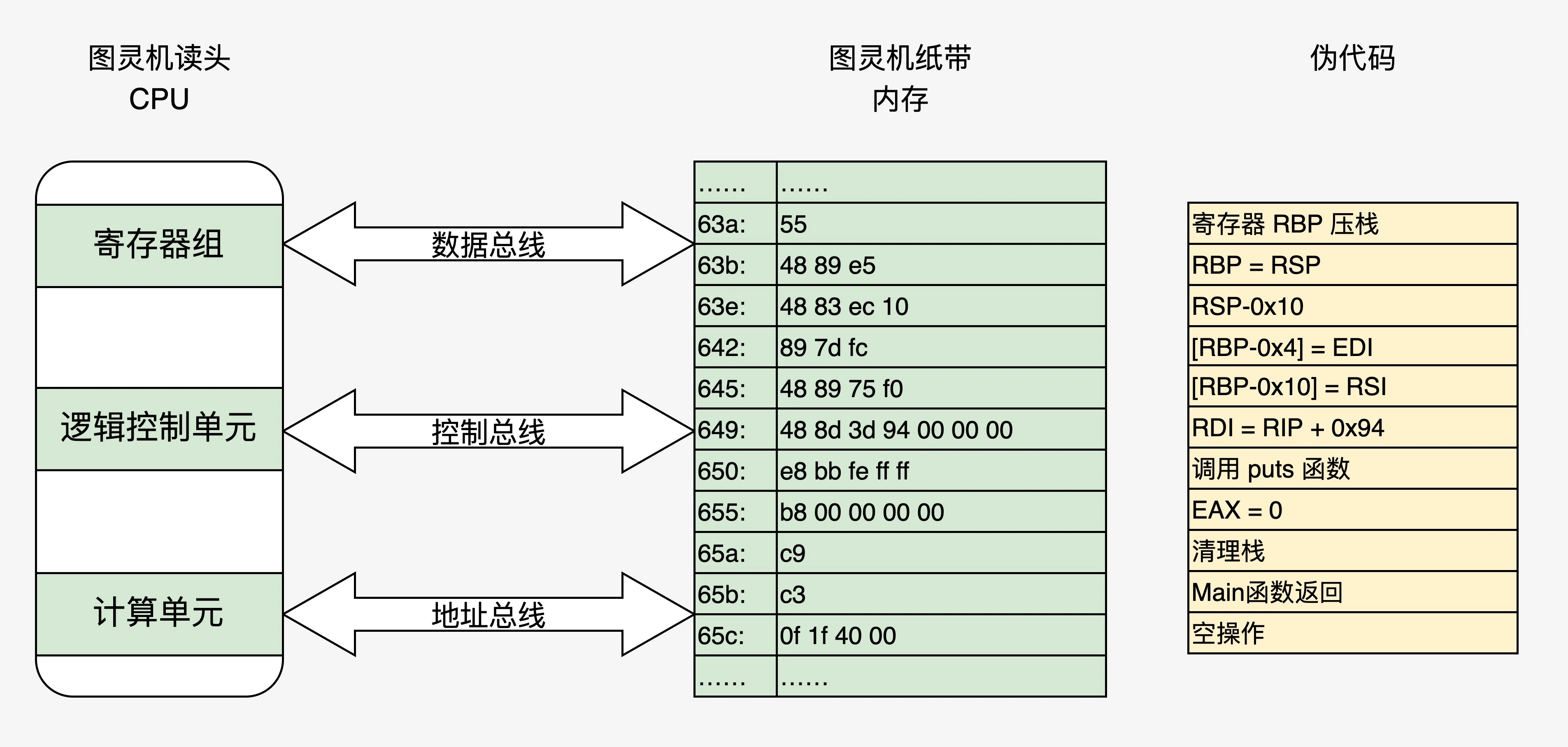
计算机是如何读懂0和1的?- CPU (上)计算机是如何读懂0和1的?- CPU (下) 可以学到几个问题
- alu 是如何构成的
- 时钟如何驱动寄存器、控制单元、计算单元alu
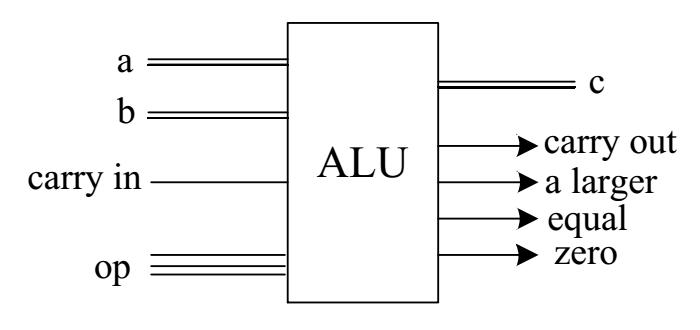
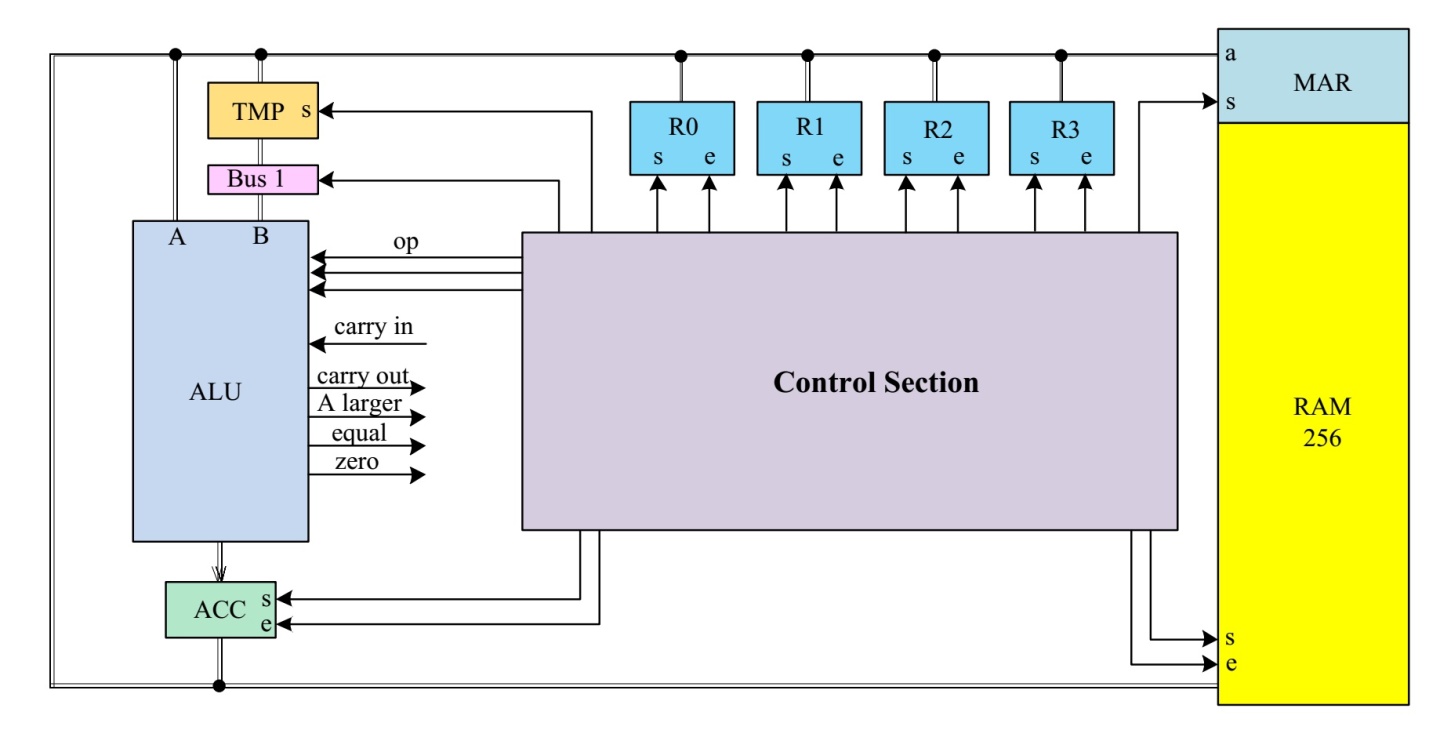
ALU 包含加法器、移位器(左)、移位器(右)、比较器、与门、非门、或门 等逻辑电路,所有的单元都有输入a,对于需要两个输入的单元,b也被连接。通过op操作码,可以选择不同的逻辑或算数单元。ALU计算会输出四个标志位,分别为:carry out(进位)、a larger、equal和zero。
ALU op操作码所对应的选择为:
| op | 逻辑/算数单元 | 含义 |
|---|---|---|
| 000 | ADD | 加法 |
| 001 | SHR | 右移 |
| 010 | SHL | 左移 |
| 011 | NOT | 取反 |
| 100 | AND | 与 |
| 101 | OR | 或 |
| 110 | XOR | 异或 |
| 111 | CMP | 比较 |
对于一个8位CPU来说,指令可以分为两大类,一类为ALU相关指令,主要包括需要ALU参与完成的相关指令,比如加法、移位、比较等;另一类是非ALU相关指令,比如加载数据,存储数据,跳转等。无论哪种指令,都可以分为前4位和后4位,前四位和动作有关,后四位和数据有关。
五级流水线
CPU 最早就是当年英特尔的一帮人,他们把储存器还有运算器,很多不同的模块、模组组合到了一起,给它取了个名字,这个东西叫做中央处理器。我们去看那个东西,最早是个解决方案。只是它通过磨合,通过工程的组合和封装,慢慢地大家就觉得这个东西是一个整体,也没人再关心里面是怎么工作的了,它就变成了一个产品。
一行代码能够执行,必须要有可以执行的上下文环境,包括:指令寄存器、数据寄存器、栈空间等内存资源。
许式伟:中央处理器支持的指令大体如下:
- 计算类,也就是支持我们大家都熟知的各类数学运算,如加减乘除、sin/cos 等等;
- I/O 类,从存储读写数据,从输入输出设备读数据、写数据;
- 指令跳转类,在满足特定条件下跳转到新的当前程序执行位置、调用自定义的函数。
为什么可以流水线/乱序执行?我们通常会把 CPU 看做一个整体,把 CPU 执行指令的过程想象成,依此检票进站的过程,改变不同乘客的次序,并不会加快检票的速度。所以,我们会自然而然地认为改变顺序并不会改变总时间。但当我们进入 CPU 内部,会看到 CPU 是由多个功能部件构成的。一条指令执行时要依次用到多个功能部件,分成多个阶段,虽然每条指令是顺序执行的,但每个部件的工作完成以后,就可以服务于下一条指令,从而达到并行执行的效果。比如典型的 RISC 指令在执行过程会分成前后共 5 个阶段。
- IF:获取指令;读取一条指令后,程序指针寄存器会根据指令的长度自动递增,或者改写成指定的地址。
- ID(或 RF):指令译码器对指令进行拆分和解释,识别出指令类别以及所需的各种操作数。
- 不过指令格式不同,指令译码模块翻译指令的工作机制却是统一的。首先译码电路会翻译出指令中携带的寄存器索引、立即数大小等执行信息。接着,在解决数据可能存在的数据冒险之后,由译码数据通路负责把译码后的指令信息,发送给对应的执行单元去执行。
- 译码模块得到的指令信号,可以分为两大类。一类是由指令的操作码经过译码后产生的指令执行控制信号,如跳转操作 jump 信号、存储器读取 mem_read 信号等;另一类是从指令源码中提取出来的数据信息,如立即数、寄存器索引、功能码等。
- 根据译码之后的指令信息,我们可以把指令分为三类(由 2 位执行类型字段 aluCrtlOp标记),分别是算术逻辑指令、分支跳转指令、存储器访问指令。因为RISC-V格式上比较简单而且规整,所以不同类别的指令执行过程也是类似的。这样,RISC 执行单元的电路结构相比 CISC 就得到了简化。在指令执行阶段,上述的这三类指令都能通过 ALU 进行相关操作。比如,存储访问指令用 ALU 进行地址计算,条件分支跳转指令用 ALU 进行条件比较,算术逻辑指令用 ALU 进行逻辑运算。根据译码模块里产生的指令控制字段 aluCrtlOp,执行控制模块可以根据上述的三类指令,相应产生一个 4 位的 ALU 操作信号 aluOp,为后面的 ALU 模块提供运算执行码。这三类指令经过 ALU 执行相关操作之后,统一由数据通路来输出结果。
- EX:执行指令;在“执行”阶段最关键的模块为算术逻辑单元(Arithmetic Logical Unit,ALU),它是实施具体运算的硬件功能单元。
- ME(或 MEM):内存访问(如果指令不涉及内存访问,这个阶段可以省略);
- WB:写回寄存器。如果是普通运算指令,该结果值来自于“执行”阶段计算的结果;如果是存储器读指令,该结果来自于“访存”阶段从存储器中读取出来的数据。
在执行指令的阶段,不同的指令也会由不同的单元负责。所以在同一时刻,不同的功能单元其实可以服务于不同的指令。五级流水线的 CPU 内就可以同时进行 5 个操作。这样平均下来,就相当于每条指令只需要五分之一的时钟周期时间来完成。处理器核参照 CPU 流水线的五个步骤 对功能模块进行划分,主要模块包括指令提取单元、指令译码单元、执行单元(比如运算器)、访问存储器和写回结果等单元模块。PS:从设计上说,cpu结构首先是由五级流水线决定的,其次才是传统课本上说的cpu=运算+控制单元。
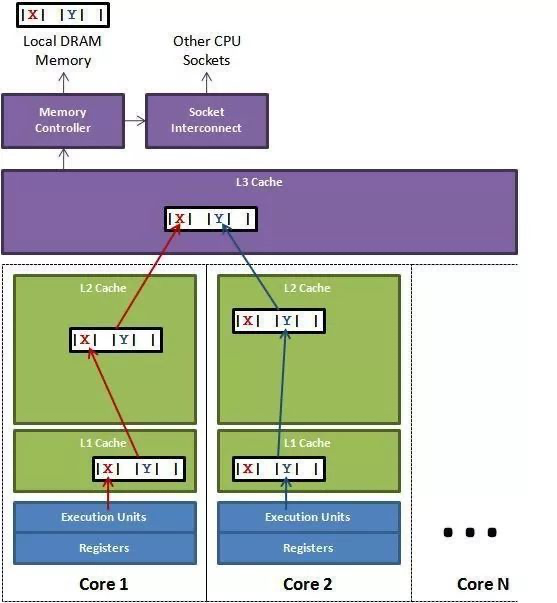
多层次内存结构
现代CPU和GPU进行ALU运算的速度(乘法、加法)远高于它们从内存读取输入的速度。AMD Ryzen 7950X的内存带宽为67 GB/s,浮点运算能力为2735 GFLOPS,FLOP:字节读取比为40:1。NVidia GeForce RTX 4090的内存带宽为1008 GB/s,运算能力为83 TFLOPS,FLOP:字节读取比为82:1。
总的思路:CPU 从单核发展为多核,增加缓存,导致出现了多个核间的缓存一致性问题 –> 为了解决缓存一致性问题,提出了 MESI 协议 –> 完全遵守 MESI 又会给 CPU 带来性能问题 –> CPU 设计者又增加 store buffer 和 invalid queue –> 又导致了缓存的顺序一致性变为了弱缓存一致性(引出了可见性问题 )–> 需要缓存的顺序一致性的,可见性问题抛给了开发者,需要软件工程师自己在合适的地方添加内存屏障。PS:本质就是cpu 默认会进行性能优化,但如果多核共享缓存了(也就是多线程竞争变量了),cpu 也提供指令 放弃优化,由使用方在合适的位置 插入这些指令,可以认为若不是为了优化MESI,多核对变量的原子操作应该是安全的。
缘起
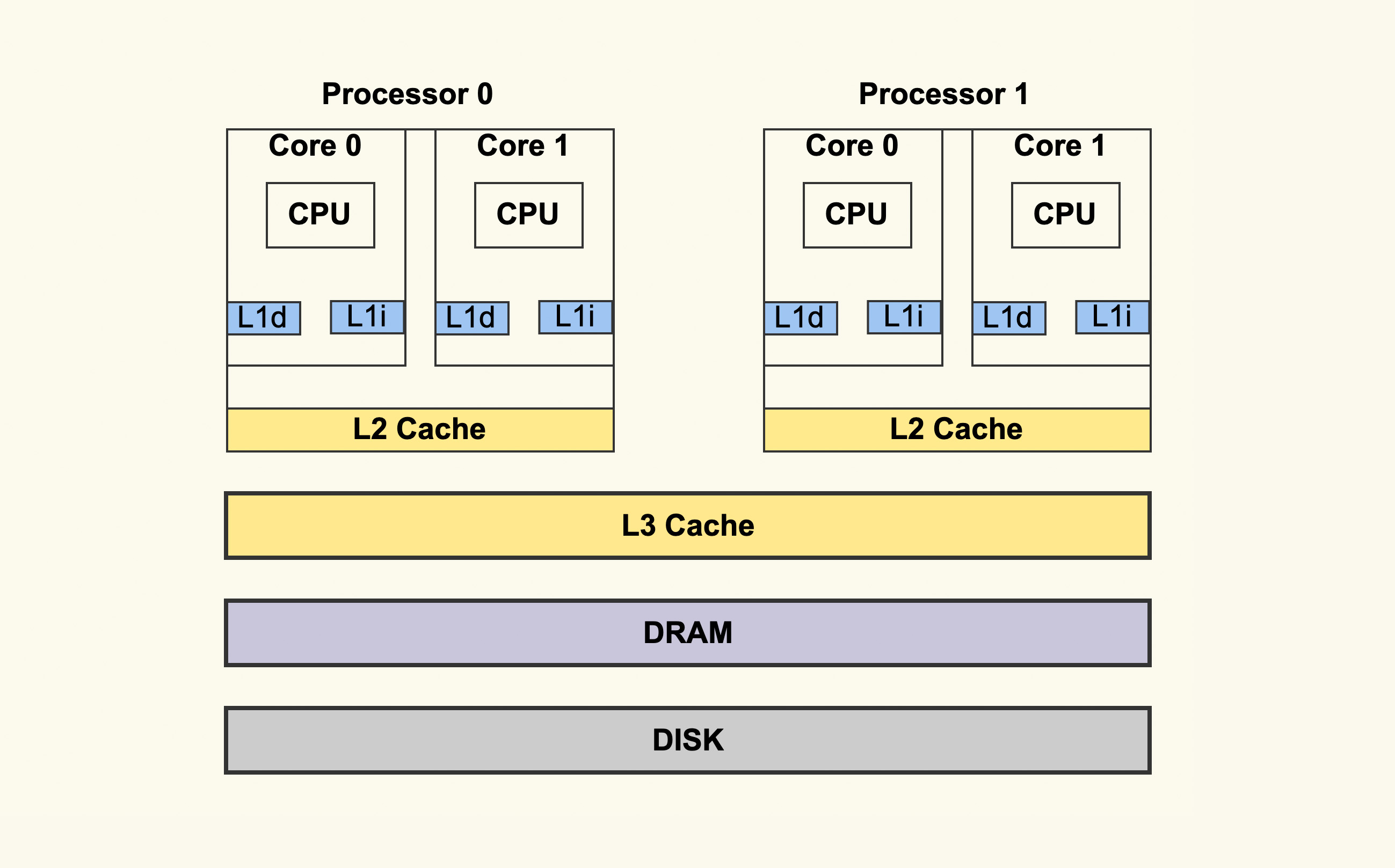
RAM 分为动态和静态两种,静态 RAM 由于集成度较低,一般容量小,速度快,而动态 RAM 集成度较高,主要通过给电容充电和放电实现,速度没有静态 RAM 快,所以一般将动态 RAM 做为主存,而静态 RAM 作为 CPU 和主存之间的高速缓存 (cache),用来屏蔽 CPU 和主存速度上的差异,也就是我们经常看到的 L1、L2 缓存。
一个 CPU 处理器中一般有多个运行核心,我们把一个运行核心称为一个物理核,每个物理核都可以运行应用程序。每个物理核都拥有私有的一级缓存(Level 1 cache,简称 L1 cache),包括一级指令缓存和一级数据缓存,以及私有的二级缓存(Level 2 cache,简称 L2 cache)。
- L1 和 L2 缓存是每个物理核私有的,不同的物理核还会共享一个共同的三级缓存。另外,现在主流的 CPU 处理器中,每个物理核通常都会运行两个超线程(每个核仍然只有一个ALU,但它有两套寄存器和其他元件。不需要切换线程,就可以让ALU在不同时间段处理两个线程),也叫作逻辑核。逻辑核的实现是通过共享物理核的大部分硬件资源,同时为每个逻辑核分配一些独立的资源(如独立的程序计数器、寄存器组等)。操作系统可以将多个线程分配到同一个物理核上的不同逻辑核上运行,逻辑核通过时间片轮转等方式共享物理核的执行单元。同一个物理核的逻辑核会共享使用 L1、L2 缓存。也有一种说法是,每个物理核包括两个逻辑核,逻辑核 独占的L1缓存,物理核独享L2 缓存。
缓存速度的差异
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80纳秒 | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles, | 约15ns |
| L2 cache | 约10 cycles, | 约3ns |
| L1 cache | 约3-4 cycles, | 约1ns |
| 寄存器 | 1 cycle |
当CPU执行运算的时候,它先去L1查找所需的数据,再去L2,然后是L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。如果你在做一些很频繁的事,你要确保数据在L1缓存中。
当然,缓存命中率是很笼统的,具体优化时还得一分为二。比如,你在查看 CPU 缓存时会发现有 2 个一级缓存,这是因为,CPU 会区别对待指令与数据。虽然在冯诺依曼计算机体系结构中,代码指令与数据是放在一起的,但执行时却是分开进入指令缓存与数据缓存的,因此我们要分开来看二者的缓存命中率。
- 提高数据缓存命中率,考虑cache line size
- 提高指令缓存命中率,CPU含有分支预测器,如果分支预测器可以预测接下来要在哪段代码执行(比如 if 还是 else 中的指令),就可以提前把这些指令放在缓存中,CPU 执行时就会很快。例如,如果代码中包含if else,不要让每次执行if else 太过于随机;在循环内部应尽量避免分支判断。
在一个 CPU 核上运行时,应用程序需要记录自身使用的软硬件资源信息(例如栈指针、CPU 核的寄存器值等),我们把这些信息称为运行时信息。同时,应用程序访问最频繁的指令和数据还会被缓存到 L1、L2 缓存上,以便提升执行速度。但是,在多核 CPU 的场景下,一旦应用程序需要在一个新的 CPU 核上运行,那么,运行时信息就需要重新加载到新的 CPU 核上。而且,新的 CPU 核的 L1、L2 缓存也需要重新加载数据和指令,这会导致程序的运行时间增加。因此,操作系统(调度器)提供了将进程或者线程绑定到某一颗 CPU 上运行的能力(PS:就好像将pod 调度到上次运行它的node)。建议绑定物理核,以防止绑到一个逻辑核时,因为任务较多导致目标线程迟迟无法被调度的情况。
缓存的存取——cache line
硬盘一般只负责存储数据,上面的数据不能做直接运算。内存存储了程序能直接「看到」的数据。使用高级编程语言时,内存是我们存储数据和对数据做运算的地方。但在最底层的运算实现中,程序实际上是先把数据从内存搬到寄存器上,再做运算,最后把数据搬回内存。只有在编写更底层的汇编语言时,我们才需要知道寄存器这一层。在寄存器和内存之间还有缓存(cache)这一层,但这属于硬件上的实现细节,它在编程模型中是不可见的,硬件会自动处理缓存的逻辑。
CPU从内存load数据是一次一个cache line;往内存里面写也是一次一个cache line,cache line是CPU缓存中的最小可读写单元,日常使用的 Intel 服务器或者 PC 里,Cache Line 的大小通常是 64 字节。这意味着,比如二维数组在内存中是按行排布的,读取array[i][j] 后,array [i][j+1] 大概率在缓存里,array[i+1][j]则很可能不在。从并发角度看,一个 cache line里面的数据最好是读写分开,否则就会相互影响,比如告知编译器将原子变量的内存地址以一个 cache line 大小对齐,从而避免多个原子变量位于同一个 cache line 中。。

- 标志位(flag):用于指示Cache Line当前是否有效。当一个Cache Line中存储的数据被更新或替换时,标志位会被清除,表示该Cache Line不再有效。(存MESI 的状态)
- 标记(tag):用于标识数据区域中存储的数据块是来自哪个主存地址。当CPU需要读取或写入特定地址的数据时,它会将该地址的一部分作为标记,并与Cache Line中存储的标记进行比较,以确定是否命中缓存。
- 数据区域(data):用于存储从主存中读取的数据块。
java 和c 都有相关机制来解决伪共享问题。
struct foo {
int a;
int b ____cacheline_aligned;
};
通过内存对齐可以避免一个字段同时存在两个缓存行里的情况,但还是无法完全规避缓存伪共享的问题,也就是一个缓存行中存了多个变量,而这几个变量在多核 CPU 并行的时候,会导致竞争缓存行的写权限,当其中一个 CPU 写入数据后,这个字段对应的缓存行将失效,导致这个缓存行的其他字段也失效。
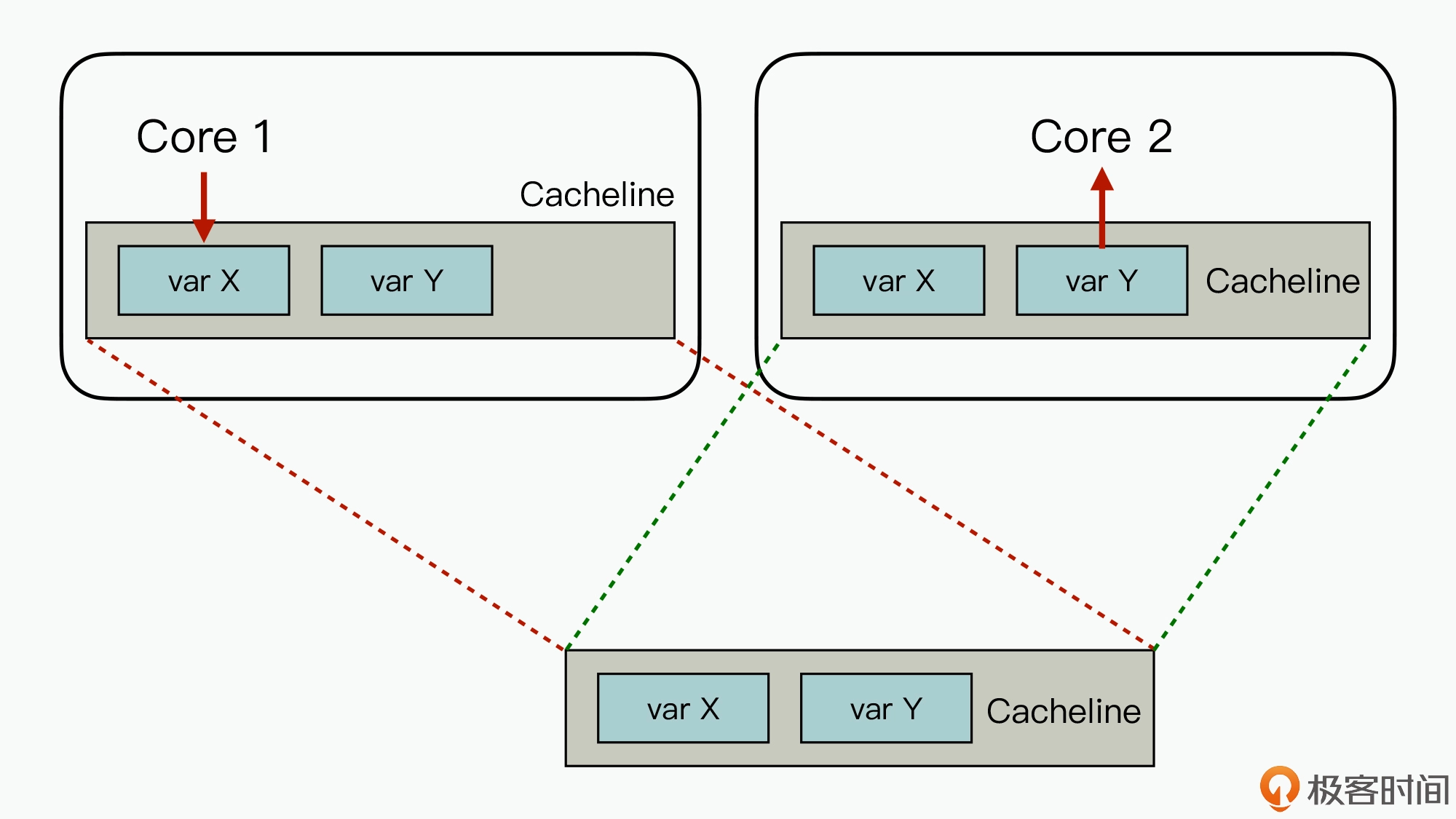
在 Disruptor 中,通过填充几个无意义的字段,让对象的大小刚好在 64 字节,一个缓存行的大小为64字节,这样这个缓存行就只会给这一个变量使用,从而避免缓存行伪共享,但是在 jdk7 中,由于无效字段被清除导致该方法失效,只能通过继承父类字段来避免填充字段被优化,而 jdk8 提供了注解@Contended 来标示这个变量或对象将独享一个缓存行,使用这个注解必须在 JVM 启动的时候加上 -XX:-RestrictContended 参数,其实也是用空间换取时间。
缓存一致性
CPU总线是所有CPU与芯片组连接的主干道,负责CPU与外界所有部件的通信,包括高速缓存、内存、北桥,其控制总线向各个部件发送控制信号、通过地址总线发送地址信号指定其要访问的部件、通过数据总线双向传输。在CPU1要做 i++操作的时候,其在总线上发出一个LOCK#信号(总线锁的实现是采用cpu提供的LOCK# 信号),其他处理器就不能操作缓存了该共享变量内存地址的缓存,也就是阻塞了其他CPU,使该处理器可以独享此共享内存。但我们只需要对此共享变量的操作是原子就可以了,而总线锁定把CPU和内存的通信给锁住了,使得在锁定期间,其他处理器不能操作其他内存地址的数据,从而开销较大,所以后来的CPU都提供了缓存一致性机制:当某块CPU对缓存中的数据进行操作了之后,就通知其他CPU放弃储存在它们内部的缓存,或者从主内存中重新读取。
- 当 CPU 修改了缓存中的数据后,这些修改什么时候能传播到主存?
- 写回(Write Back),当 CPU 采取写回策略时,对缓存的修改不会立刻传播到主存,只有当缓存块被替换时,这些被修改的缓存块,才会写回并覆盖内存中过时的数据;
- 写直达(Write Through)。缓存中任何一个字节的修改,都会立刻传播到内存,这种做法就像穿透了缓存一样,所以用英文单词“Through”来命名。
- 当某个 CPU 的缓存中执行写操作,修改其中的某个值时,其他 CPU 的缓存所保有该数据副本的更新策略也有两种
- 写更新(Write Update)。每次它的缓存写入新的值,该 CPU 都必须发起一次总线请求,通知其他 CPU 将它们的缓存值更新为刚写入的值,所以写更新会很占用总线带宽。
- 写无效(Write Invalidate)。如果在一个 CPU 修改缓存时,将其他 CPU 中的缓存全部设置为无效。在具体的实现中,绝大多数 CPU 都会采用写无效策略。这是因为多次写操作只需要发起一次总线事件即可,第一次写已经将其他缓存的值置为无效,之后的写不必再更新状态,这样可以有效地节省 CPU 核间总线带宽。
- 当前要写入的数据不在缓存中时,根据是否要先将数据加载到缓存中
- 写分配(Write Allocate)。在写入数据前将数据读入缓存。
- 写不分配(Not Write Allocate)。在写入数据时,直接将要写入的数据传播内存,而并不将数据块读入缓存。
组合排列一下,因为写直达会导致更新直接穿透缓存,所以这种情况下只能采用写不分配策略。写更新和写不分配这两种策略在现实中比较少出现。
| 缓存和内存的更新关系 | 写缓存时 CPU 之间的更新策略 | 写缓存时数据是否被加载 |
|---|---|---|
| 写回 | 写更新 | 写分配 |
| 写回 | 写更新 | 写分配 |
| 写回 | 写无效 | 写不分配 |
| 写回 | 写无效 | 写不分配 |
| 写直达 | 写无效 | 写不分配 |
所谓缓存一致性,就是保证同一个数据在每个 CPU 的私有缓存(一般为 L1 Cache)中副本是相同的。为了保证缓存一致性,必须解决两个问题,分别是写传播和事务串行化。
- 写传播是指,一个处理器对缓存中的值进行了修改,需要通知其他处理器,也就是需要用到“写更新”或者“写无效”策略。
- 事务串行化是指,多个处理器对同一个值进行修改,在同一时刻只能有一个处理器写成功,必须保证写操作的原子性,多个写操作必须串行执行。PS:反面是乱序
相比CPU总线锁只允许一个CPU访问内存,缓存一致性阻止同时修改由两个以上处理器缓存的内存区域数据,当其他处理器回写已被锁定的缓行的数据时,会使缓存行无效。 PS:总线锁粒度太大,缓存锁粒度小一些,体现在MESI 又有点读写锁的味道,cach line flag就是缓存锁标志位。
MESI协议是⼀个基于失效的缓存⼀致性协议,是⽀持写回(write-back)缓存的最常⽤协议。是以缓存行(缓存的基本数据单位,在Intel的CPU上一般是64字节)的几个状态来命名的(全名是Modified、Exclusive、 Share or Invalid)。该协议要求在每个缓存行上维护两个状态位,使得每个数据单位可能处于M、E、S和I这四种状态之一。
- 为了解决多个核心之间的数据传播问题,提出了总线嗅探(Bus Snooping)策略。本质上就是把所有的读写请求都通过总线(Bus)广播给所有的核心,然后让各个核心去嗅探这些请求,再根据本地的状态进行响应。
- 当CPU需要写数据时,只有在其缓存行是M或者E的时候才能执行,否则需要发出特殊的RFO指令(Read Or Ownership,这是一种总线事务),通知其他CPU置缓存无效(I),这种情况下性能开销是相对较大的。在写入完成后,修改其缓存状态为M。
- 当CPU需要读取数据时,
- 如果其缓存行的状态是I的,则需要从内存中读取,并把自己状态变成S
- 如果不是I,则可以直接读取缓存中的值,但在此之前,必须要等待其他CPU的监听结果,如其他CPU也有该数据的缓存且状态是M,则需要等待其把缓存更新到内存之后,再读取。
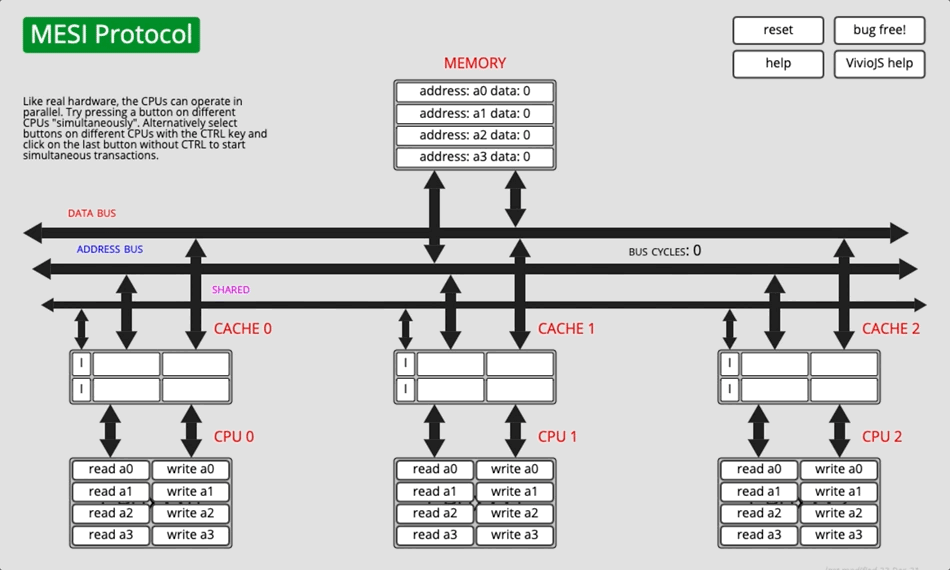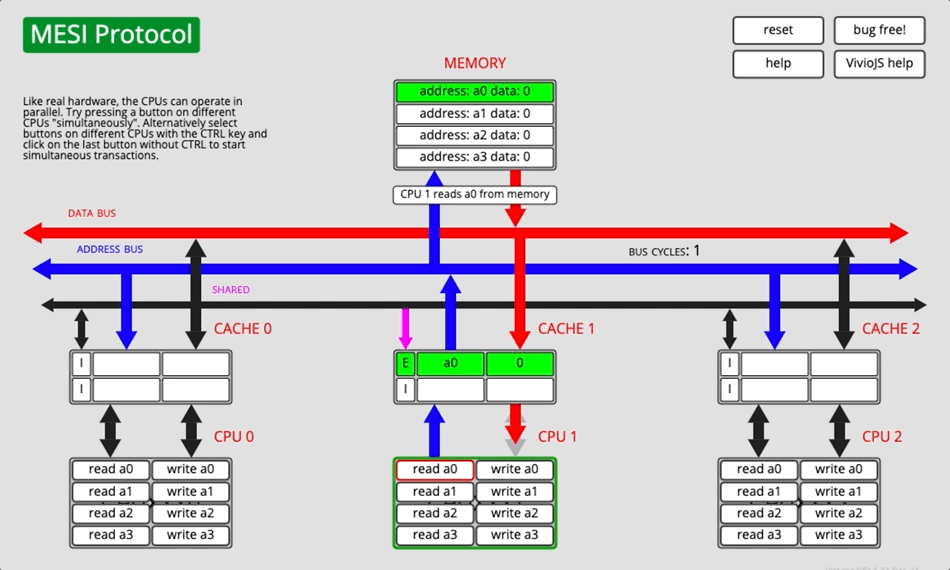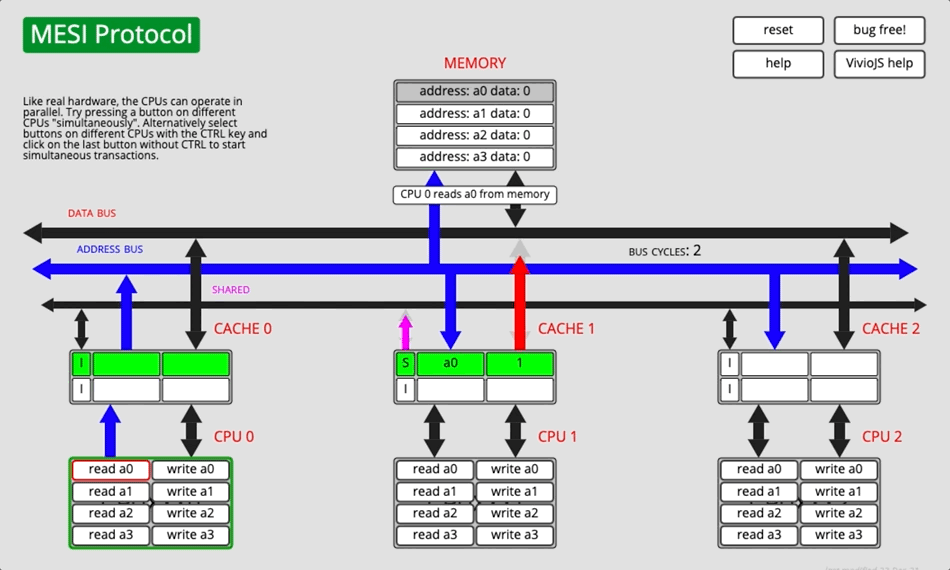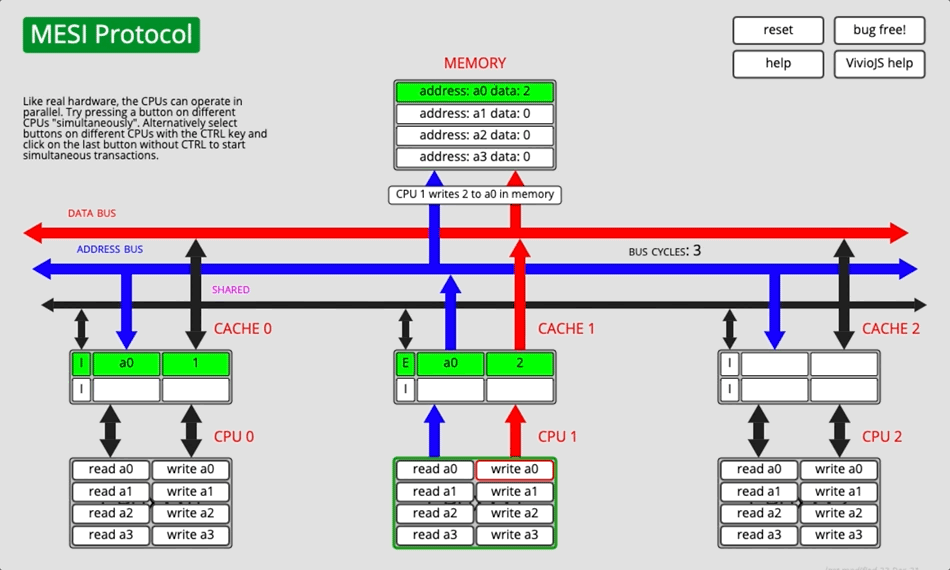
并非所有情况都会使用缓存一致性的,如被操作的数据不能被缓存在CPU内部或操作数据跨越多个缓存行(状态无法标识),则处理器会调用总线锁定。另外当CPU不支持缓存锁定时,自然也只能用总线锁定了。
写传播
怎样解决写传播所带来的缓存一致性问题呢?那就需要缓存一致性协议,前面提到缓存中的值同步给主存有两种策略(写回和写直达),而且,不同的写策略,对应不同的缓存一致性协议。
- 基于“写直达”的缓存一致性协议,VI协议,缺点是需要很高的带宽
- 基于“写回”策略的缓存一致性协议,MESI 协议,MESI 协议通过引入了 Modified 和 Exclusive 两种状态,并且引入了处理器缓存之间可以相互同步的机制,非常有效地降低了 CPU 核间带宽
有的CPU,比如x86,它的硬件提供了比较强的缓存一致性支持,但有的CPU,比如Arm,它指供的缓存一致性支持就很弱,这就需要软件工程师在正确的位置插入内存屏障来保证这种一致性。
有序执行内存操作 ==> 内存屏障(x86 lock)
一文彻底搞懂并发编程与内存屏障 乱序是为了提高性能的,如果所有的乱序都会有问题,那还不如不乱,CPU再怎么任性,也不会如此乱来。一定是大多数情况下,乱序不会有问题,CPU才会乱序的。Store Store、Load Load、Load Store都不会乱序。Store Load可能乱序,少数情况有可能造成问题:一个Core先写的值,被另一个Core后读。为了避免问题,需要mfence、Lock add这样的内存屏障。
- 对于Core来说,读、写变量都是针对L1的。类似数据库所有读操作,都是针对缓存(在PostgreSQL中,就是针对Shared Buffer,MySQL是Buffer Pool,Oracle是Buffer Cache)。一条写指令,数据写到L1,指令就算完成了。但CPU还要继续把L1中的脏数据,写到L2、L3、主存。这就好像数据库缓存中的脏块一样,并不是在DML语句执行时立即就要把脏块落盘。对于DML语句来说,只要数据写入缓存,DML语句的执行就算结束了。
- 内存变量_y,它被读入好多地方,两个Core的从L3到L1,各级缓存中,到处都有_y的影子。同一个变量,在两个地方,如果一个地方的_y被改了,另一个地方的_y也要跟着改,这就是“同步”,但这个“同步”的时间,还是比较慢的。L1的延迟,是4、5个周期,这里说的同步也就是一个Core向另一个Core发一次消息,至少就60、70周期。一次同步需要来回至少传递两次消息,这就120到140个周期。
- Core 1并不等待_y = 1的完成,它只用一个周期,把_y = 1这条指令发出去(“我要修改_y了,你那里有没有_y,有的话,就要变成为无效了。我会把新值给你或者你到L3中取。”),从逻辑上,_y = 1就算完成了,然后Core 1就开始执行下一条指令:r2 = _x 。
- 但_y的新值:1,什么时候能写到公共的L3中?要等待Core 0回馈消息到达(我这里有_y,我已经设为无效状态了)。
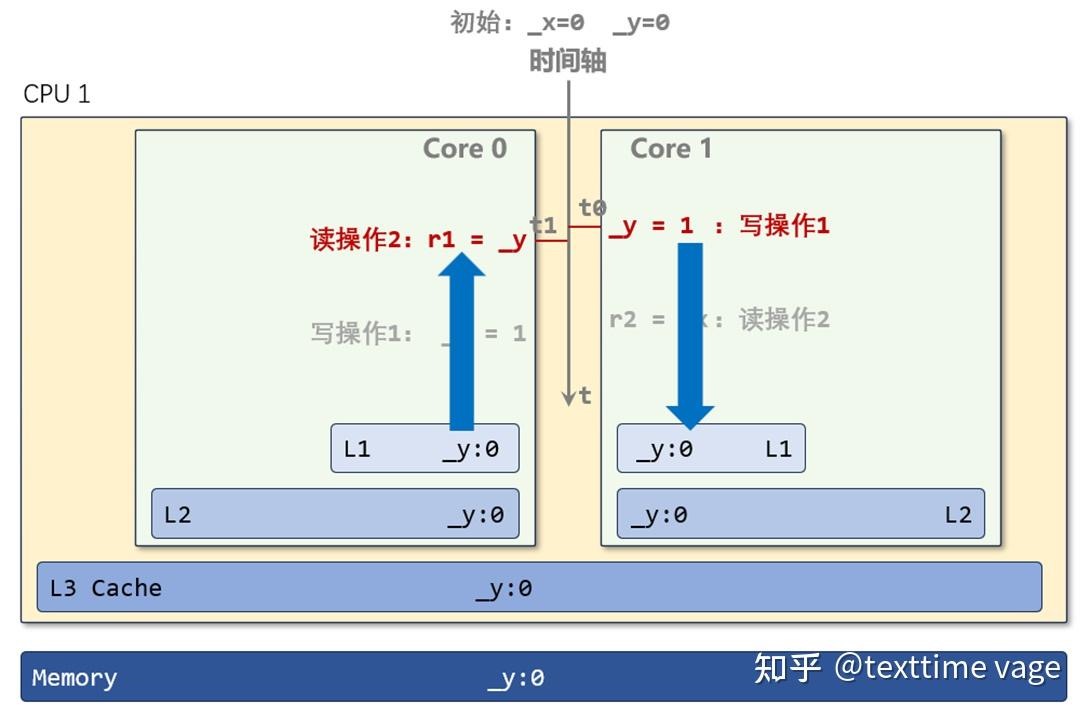
- 当两边执行操作2时,_x,_y在两个Core的L1中都还没有失效,都是有效的值:0。都执行完后,结果仍有可能是r1 = 0,r2 =0。两个Core的“读操作2“,虽然晚于写操作1执行,但它们都先于”写操作1“完成(指进入到L1 或者内存里)。
传统的MESI协议中有两个行为的执行成本比较大。一个是将某个Cache Line标记为Invalid状态,另一个是当某Cache Line当前状态为Invalid时写入新的数据。所以CPU通过Store Buffer和Invalidate Queue组件来降低这类操作的延时。
内存模型:有了MESI为什么还需要内存屏障?如果 CPU 严格按照 MESI 协议进行核间通讯和同步,核间同步就会给 CPU 带来性能问题。严格遵守 MESI 协议的 CPU 设计,在它的某一个核在写一块缓存时,它需要通知所有的同伴:我要写这块缓存了,如果你们谁有这块缓存的副本,请把它置成 Invalid 状态。Invalid 状态意味着该缓存失效,如果其他 CPU 再访问这一缓存区时,就会从主存中加载正确的值。发起写请求的 CPU 中的缓存状态可能是 Exclusive、Modified 和 Share,每个状态下的处理是不一样的。
- 如果缓存状态是 Exclusive 和 Modified,那么 CPU 一个核修改缓存时不需要通知其他核,这是比较容易的。
- 但是在 Share 状态下,如果一个核想独占缓存进行修改,就需要先给所有 Share 状态的同伴发出 Invalid 消息,等所有同伴确认并回复它“Invalid acknowledgement”以后,它才能把这块缓存的状态更改为 Modified,这是保持多核信息同步的必然要求。这个过程相对于直接在核内缓存里修改缓存内容,非常漫长。这也就会导致,某个核请求独占时间比较长。
那怎么来解决这个问题呢?CPU 的设计者为每个核都添加了一个名为 store buffer 的结构,store buffer 是硬件实现的缓冲区,它的读写速度比缓存的速度更快,所有面向缓存的写操作都会先经过 store buffer。它会收集多次写操作,然后在合适的时机进行提交。PS:当前CPU核如果要读Cache Line中的数据,需要先扫描Store Buffer之后再读取Cache Line(Store-Buffer Forwarding)。
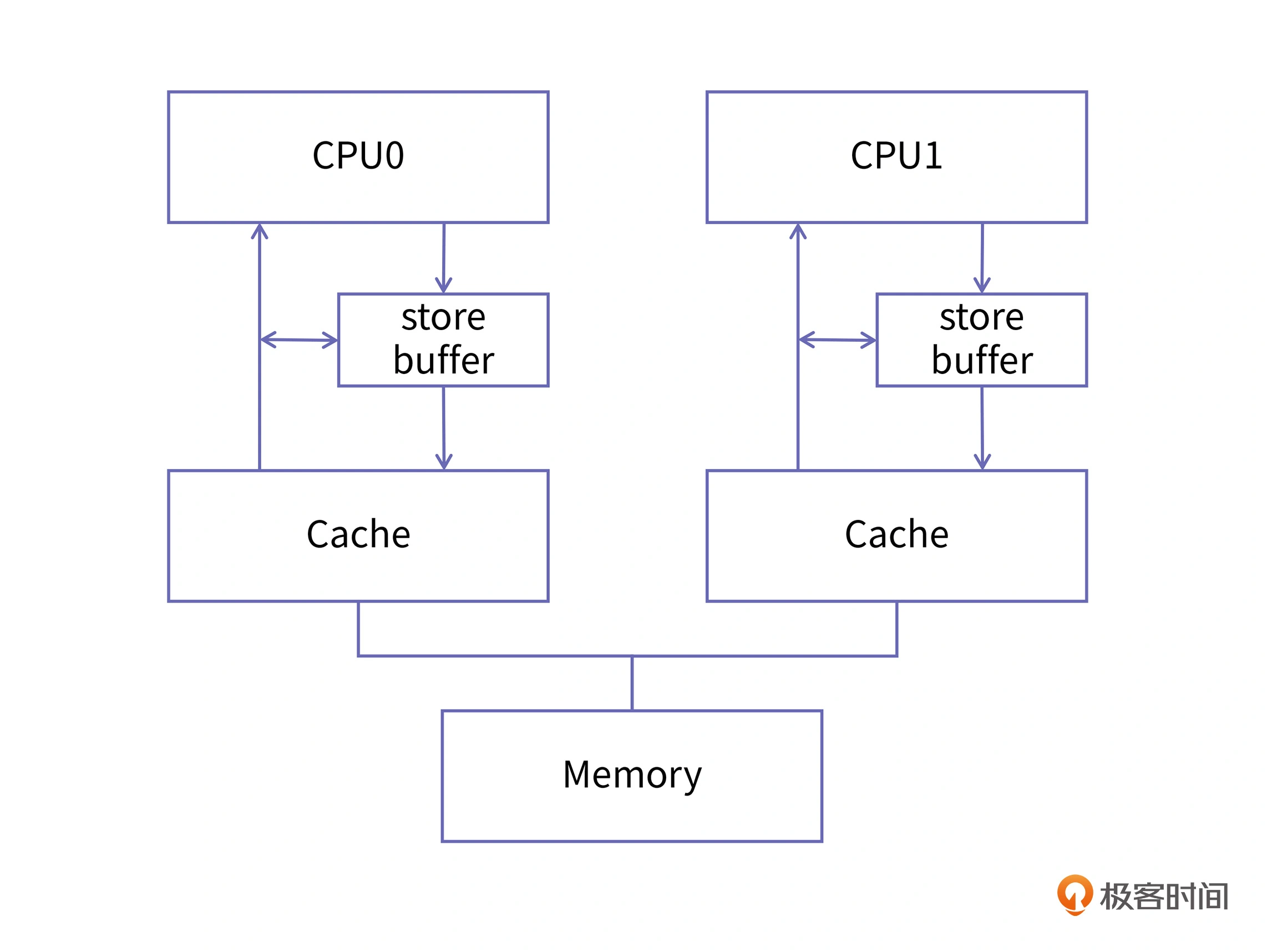
在这样的结构里,如果 CPU 的某个核再要对一个变量进行赋值,它就不必等到所有的同伴都确认完,而是直接把新的值放入 store buffer,然后再由 store buffer 慢慢地去做核间同步,并且将新的值刷入到 cache 中去就好了。而且,每个核的 store buffer 都是私有的,其他核不可见。但用 store buffer 也会有一个问题,那就是它并不能保证变量写入缓存和主存的顺序。为了解决这个问题,CPU 设计者就引入了内存屏障,屏障的作用是前边的读写操作未完成的情况下,后面的读写操作不能发生。
store buffer 的存在是为提升写性能,放弃了缓存的顺序一致性,我们把这种现象称为弱缓存一致性。在正常的程序中,多个 CPU 一起操作同一个变量的情况是比较少的,所以 store buffer 可以大大提升程序的运行性能。但在需要核间同步的情况下,我们还是需要这种一致性的,这就需要软件工程师自己在合适的地方添加内存屏障了。
核间同步还有另外一个瓶颈,也就是“读”的问题。当一个 CPU 向同伴发出 Invalid 消息的时候,它的同伴要先把自己的缓存置为 Invalid,然后再发出 acknowledgement。这个从“把缓存置为 Invalid”到“发出 acknowledgement”的过程所需要的时间也是比较长的。而且,由于 store buffer 的存在提升了写入速度,那么 invalid 消息确认速度相比起来就慢了,这就带来了速度的不匹配,很容易导致 store buffer 的内容还没有及时更新到 cache 里,自己的容量就被撑爆了,从而失去了加速的作用。为了解决这个问题,CPU 设计者又引入了“invalid queue”,也就是失效队列这个结构。加入了这个结构后,收到 Invalid 消息的 CPU,比如我们称它为 CPU1,在收到 Invalid 消息时立即向 CPU0 发回确认消息,但这个时候 CPU1 并没有把自己的 cache 由 Share 置为 Invalid,而是把这个失效的消息放到一个队列中,等到空闲的时候再去处理失效消息,这个队列就是 invalid queue。经过这样的改进后,CPU1 响应失效消息的速度大大提升了。
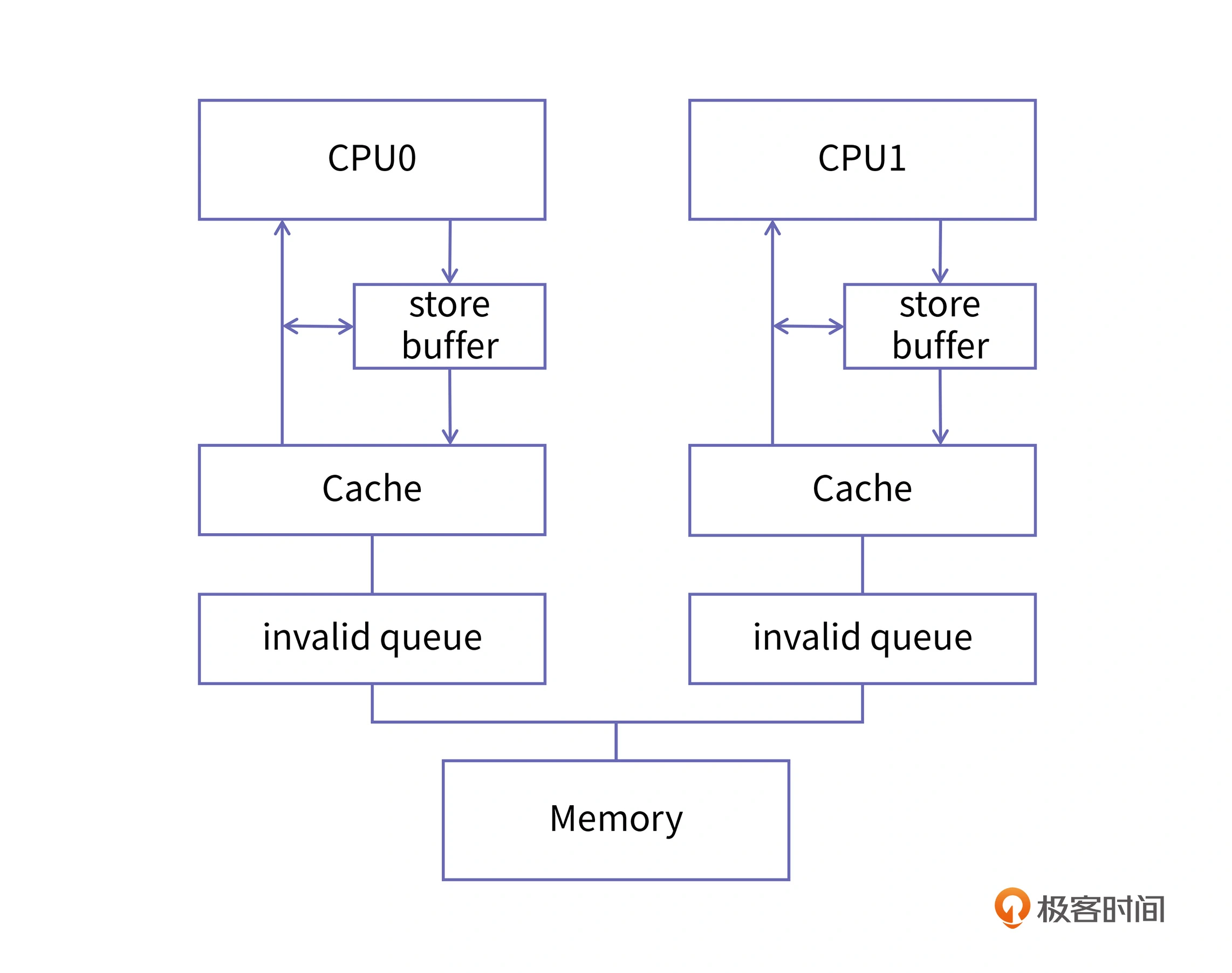
在 CPU 的具体实现中,通过放宽 MESI 协议的限制来获得性能提升。具体来说,我们引入了 store buffer 和 invalid queue,它们采用放宽 MESI 协议要求的办法,提升了写缓存核间同步的速度,从而提升了程序整体的运行速度。但在这放宽的过程中,我们也看到会不断地出现新的问题,也就是说,一个 CPU 的读写操作在其他 CPU 看来出现了乱序。甚至,即使执行写操作的 CPU 并没有乱序执行,但是其他 CPU 观察到的变量更新顺序确实是乱序的。这个时候,我们就必须加入内存屏障来解决这个问题。在不同的情况下,我们需要的内存屏障是不同的。使用功能强大的内存屏障会给系统带来不必要的性能下降,为了更精细地区分不同类型的屏障,CPU 的设计者们提供了分离的读写屏障 (alpha),或者是单向屏障 (Arm)。PS:cpu 本身为了速度也会乱序执行。
示例:Arm 上 dmb((Data Memory Barrier)) 指令,cpu会保证当遇到dmb指令的时候,cpu会停下来,直到条件满足了才会继续执行。
聊聊原子变量、锁、内存屏障那点事内存屏障指令直接控制 CPU 与其缓存的交互,以及它的写缓冲区(持有等待刷新到内存的数据的存储)和它的用于等待加载或推测执行指令的缓冲。内存屏障 (Memory Barrier)分为写屏障(Store Barrier)、读屏障(Load Barrier)和全屏障(Full Barrier),其作用有两个:
- 防止指令之间的重排序
- 保证数据的可见性。写屏障会阻塞直到把Store Buffer中的数据刷到Cache中;读屏障会阻塞直到Invalid Queue中的消息执行完毕。以此来保证核间各级数据的一致性。
除了显式的内存屏障指令,有些指令也会造成指令保序的效果,比如I/O操作的指令、exch等原子交换的指令,任何带有lock前缀的指令以及CPUID等指令都有内存屏障的作用。
cpu/服务器 三大体系numa smp mpp
单个cpu 即使用尽全力, 能设计的物理核数量仍然是有限的,另一个扩展思路是多处理器互联,在一台服务器上安装多个物理cpu,进而达到扩展算力的目的。 把个人电脑上的 CPU 拔下来插到服务器上行不行?普通的个人电脑都不支持多 CPU 。而服务器 CPU 为了更大程度地在单服务器内增加算力,还在芯片内设计了 QPI/UPI 模块,用来支持多 CPU 之间的互联。现在主流的服务器,至少都是采用的双物理 CPU 的设计,当需要访问对方直连的内存时,通过 UPI 总线来进行跨 CPU 内存通信。CPU物理核在访问不同的内存条的延迟是不同的。 Kubelet从入门到放弃:识透CPU管理
- SMP(Symmetric Multi-Processor) 所谓对称多处理器结构,是指服务器中多个CPU对称工作,无主次或从属关系。各CPU共享相同的物理内存,每个 CPU访问内存中的任何地址所需时间是相同的,因此SMP也被称为一致存储器访问结构(UMA:Uniform Memory Access)。SMP服务器的主要特征是共享,系统中所有资源(CPU、内存、I/O等)都是共享的。也正是由于这种特征,导致了SMP服务器的主要问题,那就是它的扩展能力非常有限。对于SMP服务器而言,每一个共享的环节都可能造成SMP服务器扩展时的瓶颈,而最受限制的则是内存。由于每个CPU必须通过相同的内存总线访问相同的内存资源,因此随着CPU数量的增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使 CPU性能的有效性大大降低。实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU。
- 在传统的多CPU架构中,所有CPU以及CPU内的多个核心(Core)都通过一条总线与内存相连,使用统一寻址方式访问数据,即一致性内存访问架构(Uniform Memory Architecture, UMA),使用MESI缓存一致性协议来解决不同CPU以及不同Core之间数据通信和数据一致性。在CPU数量较少时这种架构通信效率最高,但是随着主机中CPU数量的不断增加,UMA结构中内存总线带宽会成为数据通信的瓶颈。
- NUMA(Non-Uniform Memory Access)基本特征是具有多个CPU模块,每个CPU模块由多个CPU(如4个)组成,并且具有独立的本地内存、I/O槽口等。由于其节点之间可以通过互联模块(如称为Crossbar Switch)进行连接和信息交互,因此每个CPU可以访问整个系统的内存(这是NUMA系统与MPP系统的重要差别)。显然,访问本地内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致存储访问NUMA的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同CPU模块之间的信息交互。PS: 所以k8s 调度这块因为NUMA 的原因会玩一点花活,一个pod多个cpu 不要跨numa
- 在多CPU计算节点中,使用非一致性内存访问架构(Non-Uniform Memory Access, NUMA)可以有效解决多CPU与内存之间通信性能瓶颈的问题。在NUMA架构中CPU被分配到多个Node中,每个Node都有自己独立的内存空间和PCI-E总线系统,每个Node包含一个或多个CPU,每个CPU又可以包含多个Core,Node内部CPU采用UMA架构直接和内存相连,不同Node之间通过QPI总线进行数据通信。Core访问本地Node内的数据速度要比访问其他Node的数据速度快,所以要尽量避免或减少跨Node的数据访问。
- MPP(Massive Parallel Processing)其基本特征是由多个SMP服务器(每个SMP服务器称节点)通过节点互联网络连接而成,每个节点只访问自己的本地资源(内存、存储等),是一种完全无共享(Share Nothing)结构,因而扩展能力最好,理论上其扩展无限制。在MPP系统中,每个SMP节点也可以运行自己的操作系统、数据库等。但和NUMA不同的是,它不存在异地内存访问的问题。换言之,每个节点内的CPU不能访问另一个节点的内存。节点之间的信息交互是通过节点互联网络实现的,这个过程一般称为数据重分配(Data Redistribution)。但是MPP服务器需要一种复杂的机制来调度和平衡各个节点的负载和并行处理过程。
并行计算能力
SIMD(Single Instruction Multiple Data)
SIMD 表示 利用单条指令执行多条数据,是相对于传统的 SISD(Single Instruction Single Data)来说的。向量化代码实践与思考:如何借助向量化技术给代码提速
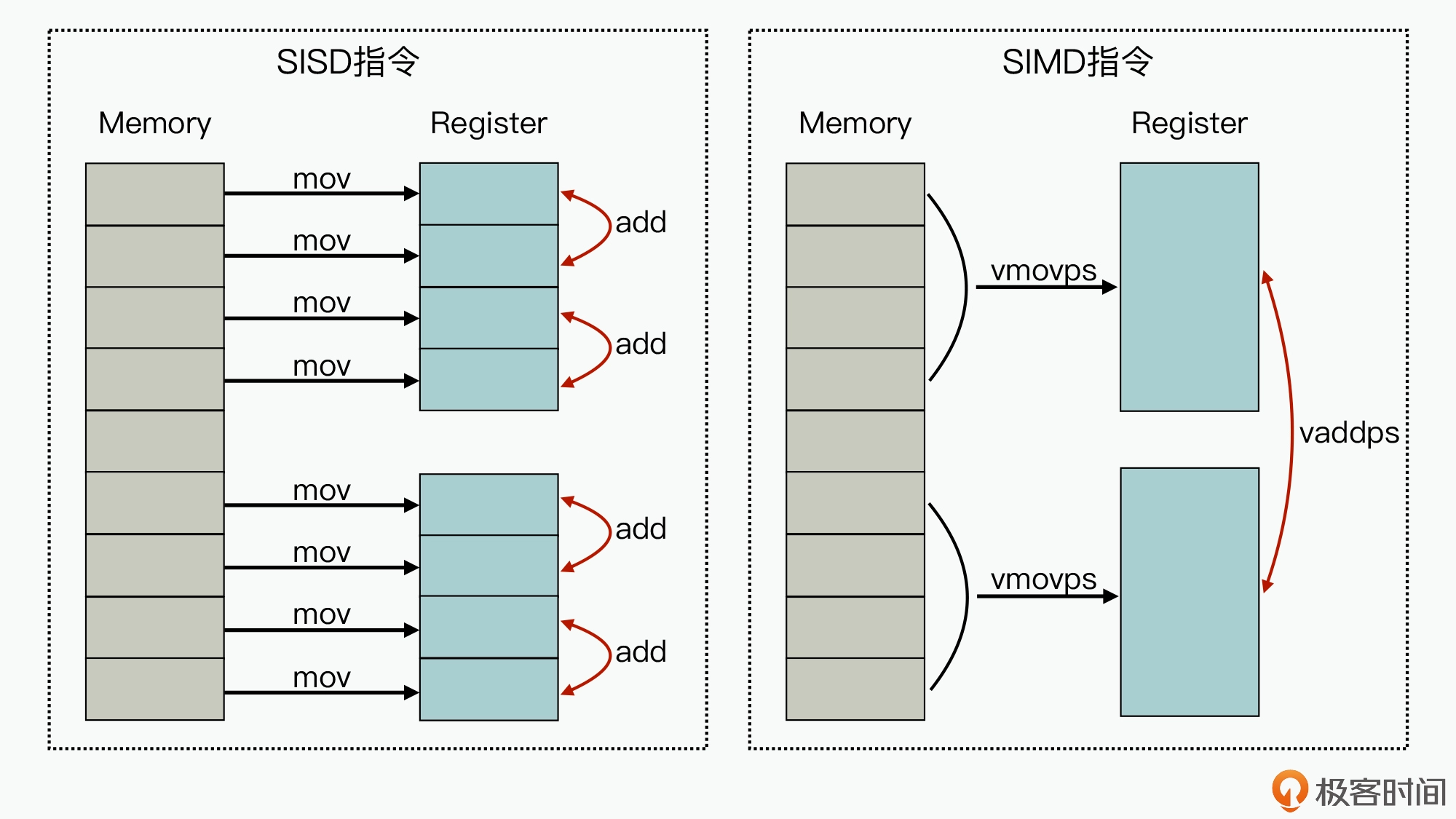
图的左边,代表的是单条指令执行单条数据的实现方式,我们可以看到,针对两组包含 4 个元素的数据,在进行两两相加的操作时,最少需要 12 条指令(8 条 mov 指令,4 条 add 指令)才能完成业务。而图的右边,因为在 CPU 芯片中集成了比较大的寄存器,从而就实现了多条数据导入和多条数据相加操作都可以在一条指令周期内完成,减少了执行 CPU 的指令数,进一步也就提升了计算速度。对于 GPU 来说,也正是因为它可以实现通过单条指令来运行矩阵或向量计算,才可以在数据处理和人工智能领域有比较大的性能优势。
一个是实用的例子:解析http 协议数据时,http header line 的边界是\r\n(header和 body的边界,http 协议header部分 没有长度,只能解析),给一个数据包从 []byte找 \r\n 常规来说没啥好办法,就是遍历,o(n)复杂度。此时可以使用 SIMD 一次指令遍历16个字符,加快遍历速度。
指令集
假如你有一条狗,经过一段时间的训练,它能“听懂”了你对它说一些话。当你对它说“坐下”,它就乖乖地坐在地上;当你对它说“汪汪叫”;它就汪汪汪地叫起来,当你对它说“躺下”,它马上就会躺下来……这里你说的“坐下”、“汪汪叫”、“躺下”这些命令,就相当于计算机世界里的指令。
在 CPU 发展初期,CISC 体系设计是合理的,设计大量功能复杂的指令是为了降低程序员的开发难度。因为那个时代,开发软件只能用汇编或者机器语言,这等同于用硬件电路设计帮了软件工程师的忙。编译器技术的发展,导致各种高级编程语言盛行。这些高级语言编译器生成的低级代码,比程序员手写的低级代码高效得多,使用的也是常用的几十条指令。文明的发展离不开工具的种类与材料升级。指令集的发展,我们也可以照这个思路推演。芯片生产工艺升级之后,人们在 CPU 上可以实现高速缓存、指令预取、分支预测、指令流水线等部件。不过,这些部件的加入引发了新问题,那些一次完成多个功能的复杂指令,执行的时候就变得捉襟见肘,困难重重。比如,一些串操作指令同时依赖多个寄存器和内存寻址,这导致分支预测和指令流水线无法工作。另外,当时在 IBM 工作的 John Cocke 也发现,计算机 80% 的工作由大约 20% 的 CPU 指令来完成,这代表 CISC 里剩下的 80% 的指令都没有发挥应有的作用。这些最终导致人们开始向 CISC 的反方向思考,由此产生了 RISC——精简指令集计算机体系结构。RISC 设计方案非常简约,通常有 20 多条指令的简化指令集。每条指令长度固定,由专用的加载和储存指令用于访问内存,减少了内存寻址方式,大多数运算指令只能访问操作寄存器。而 CPU 中配有大量的寄存器,这些指令选取的都是工程中使用频率最高的指令。由于指令长度一致,功能单一,操作依赖于寄存器,这些特性使得 CPU 指令预取、分支预测、指令流水线等部件的效能大大发挥,几乎一个时钟周期能执行多条指令。
RISC-V 采用的是模块化的指令集,RISC-V 规范只定义了 CPU 需要包含基础整形操作指令,如整型的储存、加载、加减、逻辑、移位、分支等。其它的指令称为可选指令或者或者用户扩展指令,比如乘、除、取模、单精度浮点、双精度浮点、压缩、原子指令等,这些都是扩展指令。扩展指令需要芯片工程师结合功能需求自定义。
高密度计算场景下 CPU 架构新选择:云原生处理器和创新的硬件架构
阿里云架构师张先国:揭秘ECS倚天实例背后的技术 影响应用性能的四大要素包括ALU(逻辑计算单元)、Cache、主频、加速指令。
- x86架构是两个vCPU/HT共享一个物理核,1份ALU(算术逻辑运算单元)。倚天710处理器无超线程概念,避免了性能争抢的问题:独享物理核,性能更强劲;独享Cache,应用缓存更高效。在Cache维度,过去两个vCPU/HT共享一二级缓存,相互争抢,性能波动较为严重。采用倚天CPU独享Cache的设计,让vCPU之间相互不影响,为重负载计算带来更高性能。
- 大家知道为什么多数Web、App、DB的生产业务CPU使用率的安全水位线是50%,日常水位低于30%吗?以下图中的视频编码为例,并发超过4路后,性能下降40%;再加上前面说到的核争抢问题,如果客户的实际业务超过50-60%水位,关键生产应用将响应放慢,客户感知卡顿甚至超时问题。因此需要将CPU使用率安全水位压低,牺牲成本保证安全,浪费了另外50%资源。背后的原因是x86功耗大,高算力负载很容易造成功耗过大,温度上升,因此采用降频规避,进而影响了性能。倚天710的功耗是主流x86的1/6,没有任何降频问题。同时也推荐倚天的安全水位可以提高到70-80%,减少资源浪费。
- 倚天710还针对特定算法场景进行了加速与优化。比如像NEON、SVE等矢量计算技术,可以让单条指令处理更长的数据,可以大幅提升机器学习、视频编码和高性能计算等场景性能;另外,倚天实例还支持BF16和INT8,在机器学习场景下,大幅提升计算效率,为客户提供更多选择。
除了芯片本身能力,为了实现降本增效,倚天ECS实例基于云原生的硬件架构设计。传统的服务器常常设计为2路或4路,通过多NUMA互连的方式提升整机CPU密度,让一个OS调度更多CPU算力,却也增加了复杂度。在这种架构下,随着核数增加,网络和存储IO也快速翻番,还要保持跨NUMA cache一致性,导致应用性能下降;同时也带来爆炸半径过大的问题,在云计算场景下,多路的设计会让局部硬件故障的影响范围更大。阿里云采用云原生的思想重新设计。倚天710 CPU单颗CPU即实现了128核的高密度设计,同时以CIPU为中心的硬件架构,通过CIPU连接2颗或者更多倚天的芯片,去NUMA方案下实现整机核密度更高,避免了跨NUMA带来的性能下降,同时由整机的高密度带来了成本下降,使得倚天实例更有竞争力。同时,多单路的硬件机型设计,爆炸半径减半,产品更稳定。此外CIPU硬件本身也是创新性的设计,通过将虚拟化与IO转发等数据面卸载到专用硬件上进行加速,消除了原来虚拟化损耗与性能争抢,并大幅加速了IO,也会使得整体性能更高;VPC环境下支持弹性RDMA加速能力,相比TCP时延降低70%以上。
英特尔助力龙蜥加速 AI 应用及 LLM 性能大语言模型算法的基础就是 transform,再往下分可能是 atention、MLP 各种算法。这些算法需要很多变化,要有很多运算。典型算法是向量乘向量的计算,或者是矩阵乘矩阵的运算。要做的事情都可以往下 breakdown 成 A 乘 B 再加上 C 这样的运算。为了完成乘加的运算,在早期平台比如像第一代 SKYLAKE 平台上需要三条指令去完成这样的运算。在后来的 CPU 上引入了 VNNI,如果数据的精度是 8bit,比较整齐用一条 VNNI 指令就可以完成乘加的运算。第四代引入了 AMX 矩阵运算单元,可以完成一个 A 矩阵乘 B 矩阵得到 C 矩阵。如果运算的 A 矩阵和 B 矩阵数据是 8bit 整形,可以一次性完成 16 行 64 列的 A 矩阵乘 64 行 16 列的矩阵。大语言模型对于硬件资源的另一需求体现在内存带宽上。要进行一次推理需要将所有的模型权重访问一遍,这些模型参数通常大于硬件容量,所以模型参数通常放在内存中。每进行一次推理,需要将参数或者模型权重访问一遍,需要很大的内存带宽。第四代引入了 HBM 支持,再加上系统在 DDR 通道上支持的内存,实现了 1TB 每秒内存带宽的内存区域,兼顾了内存速度和内存容量。
其它
许式伟:最早期的计算机毫无疑问是单任务的,计算的职能也多于存储的职能。每次做完任务,计算机的状态重新归零(回到初始状态)都没有关系。汇编语言的出现要早于操作系统。操作系统的核心目标是软件治理,只有在计算机需要管理很多的任务时,才需要有操作系统。
许式伟:引入了输入输出设备的电脑,不再只能做狭义上的计算(也就是数学意义上的计算),如果我们把交互能力也看做一种计算能力的话,电脑理论上能够解决的计算问题变得无所不包。
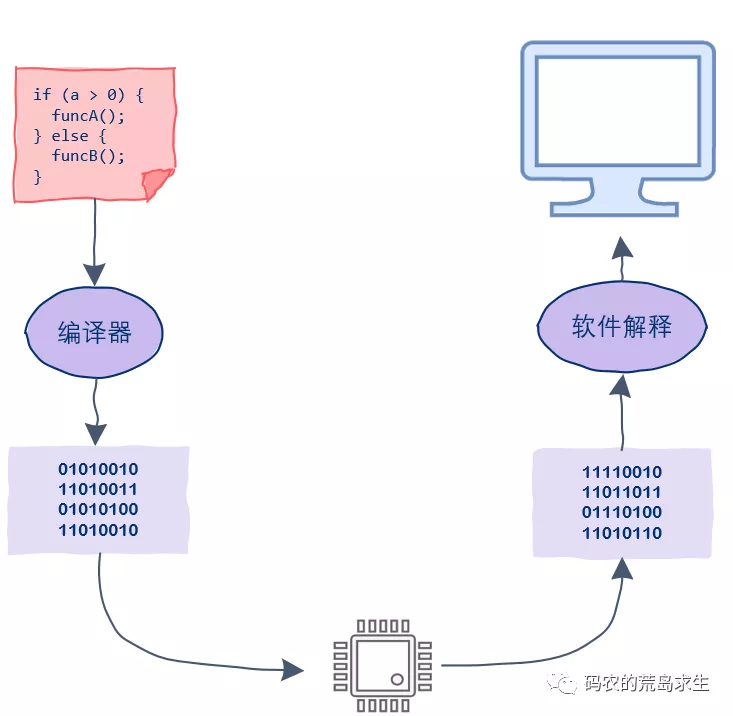
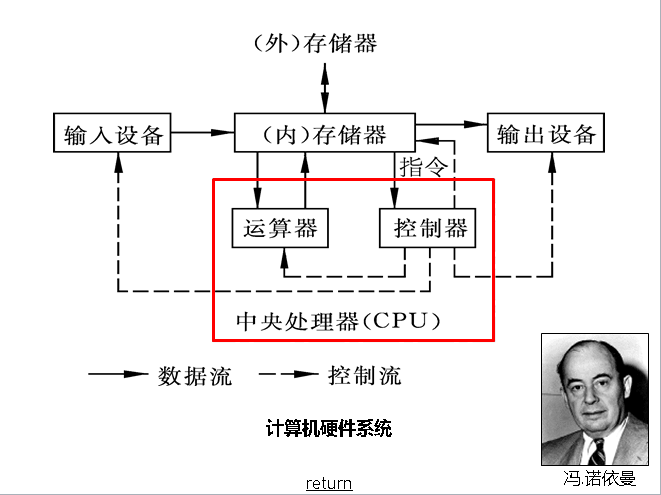
从下图的视角看,运算器、输入、输出、内存在控制器看来地位差不多。
通用寄存器数目的多少是由ISA决定的,指令编码时会单独给寄存器字段进行编码,比如5bits就可以索引2^5=32个通用寄存器,一条指令的长度是有限的,指令类型,源操作数字段、目的操作数字段,可能的状态位字段(比如谓词寄存器等)以及立即数字段都需要一些bits来编码,所以相互之间存在竞争关系,如果寄存器太多,一条指令上能携带的操作数种类和数量就会受限,这里需要一个精巧的权衡。x86一开始并没有使用太多的通用寄存器,原因之一(注意,只是之一)是当时的编译器无力进行寄存器分配,让编译器自动决定程序中众多变量哪些应该装入寄存器哪些应该换出、哪些变量应该映射到同一个寄存器上,并不是一件易事,JVM采用堆栈结构的原因之一就是不信任编译器的寄存器分配能力,转而使用堆栈结构,躲开寄存器分配的难题。到80年代早期,IBM的G. J. Chaitin公开了他们的图染色寄存器分配算法之后,编译器的分配能力获得长足进步,形成了现在这样的编译器主导的寄存器分配格局。
超标量架构是单个物理核内部的一种设计方式。一个物理核可以采用超标量架构来提高自身的执行效率。超标量处理器是一种微处理器架构,它能够在一个时钟周期内发射(开始执行)多条指令。超标量架构通过增加指令发射的宽度,使得多个执行单元可以同时工作,从而提高处理器的吞吐量。具体的说,超标量处理器内部包含多个执行单元(如整数执行单元、浮点执行单元等),并且具备复杂的指令调度机制。它可以在指令解码阶段就对多条指令进行分析,判断它们之间是否存在依赖关系。如果多条指令之间不存在数据依赖或者依赖关系可以被解决,那么这些指令就可以被同时发射到不同的执行单元中去执行。比如对循环的优化通常可以做循环展开(一般O3编译器会做)
int accRes = 0;
int acc[4] = {0};
for(int i = 0; i < 1000 / 4; i+=4)
{
acc[0] += data[i];
acc[1] += data[i + 1];
acc[2] += data[i + 2];
acc[3] += data[i + 3];
}
accRes = acc[0] + acc[1] + acc[2] + acc[3];
重排序的种类
- 编译期重排。通过调整代码中的指令顺序,在不改变代码语义的前提下,对变量访问进行优化。从而尽可能的减少对寄存器(内存?)的读取和存储,并充分复用寄存器。但是编译器对数据的依赖关系判断只能在单执行流内,无法判断其他执行流对竞争数据的依赖关系。
- 运行期重排,机器指令在流水线中经历取指、译码、执行、访存、写回等操作。为了CPU的执行效率,流水线都是并行处理的,在不影响语义的情况下。处理器次序(Process Ordering,机器指令在CPU实际执行时的顺序)和程序次序(Program Ordering,程序代码的逻辑执行顺序)是允许不一致的,即满足As-if-Serial特性。显然,这里的不影响语义依旧只能是保证指令间的显式因果关系,无法保证隐式因果关系。即无法保证语义上不相关但是在程序逻辑上相关的操作序列按序执行。
前者是编译器进行的,不同语言不同。后者是cpu 层面的,所有使用共享内存模型进行线程通信的语言都要面对的。
为什么会有人觉得优化没有必要,因为他们不理解有多耗时
Teach Yourself Programming in Ten Years
Remember that there is a “computer” in “computer science”. Know how long it takes your computer to execute an instruction, fetch a word from memory (with and without a cache miss), read consecutive words from disk, and seek to a new location on disk.
Approximate timing for various operations on a typical PC:
| 耗时 | |
|---|---|
| execute typical instruction | 1/1,000,000,000 sec = 1 nanosec |
| fetch from L1 cache memory | 0.5 nanosec |
| branch misprediction | 5 nanosec |
| fetch from L2 cache memory | 7 nanosec |
| Mutex lock/unlock | 25 nanosec |
| fetch from main memory | 100 nanosec |
| send 2K bytes over 1Gbps network | 20,000 nanosec |
| read 1MB sequentially from memory | 250,000 nanosec |
| fetch from new disk location (seek) | 8,000,000 nanosec |
| read 1MB sequentially from disk | 20,000,000 nanosec |
| send packet US to Europe and back | 150 milliseconds = 150,000,000 nanosec |
| 上下文切换 | 数千个CPU时钟周期,1微秒 |
为什么要有用户态和内核态:由于需要限制不同的程序之间的访问能力,防止他们获取别的程序的内存数据,或者获取外围设备的数据,并发送到网络。用户态:只能受限的访问内存,运行所有的应用程序。核心态:运行操作系统程序,cpu可以访问内存的所有数据,包括外围设备。
|上下文切换|CPU上下文|线程相关结构:栈等|进程相关结构:虚拟内存TLB等| |—|—|—| |进程|切换|切换|切换| |进程内线程|切换|切换|不切换| |中断|切换|用户态不切换,内核态切换|用户态不切换,内核态切换| |系统调用|切换|未切换|未切换| 每次上下文切换都是cpu 失忆再回忆的过程(顺带缓存失效)。
留下评论