AQS——粗略的代码分析
简介
锁是同步器?同步器是锁?
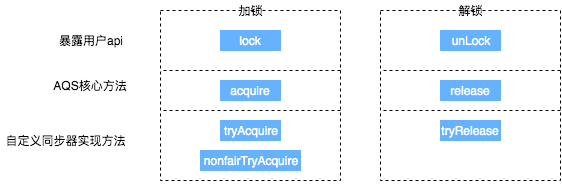
AbstractQueuedSynchronizer的介绍和原理分析锁的API是面向使用者的,它定义了与锁交互的公共行为。但锁的实现是依托给同步器来完成;同步器面向的是线程访问和资源控制,它定义了线程对资源是否能够获取以及线程的排队等操作。锁和同步器很好的隔离了二者所需要关注的领域
AbstractQueuedSynchronizer 父类和子类

AbstractQueuedSynchronizer的java类介绍:
Provides a framework for implementing blocking locks and related synchronizers (semaphores, events, etc) that rely on first-in-first-out (FIFO) wait queues. This class is designed to be a useful basis for most kinds of synchronizers that rely on a single atomic value to represent state. Subclasses must define the protected methods that change this state, and which define what that state means in terms of this object being acquired or released. Given these, the other methods in this class carry out all queuing and blocking mechanics. Subclasses can maintain other state fields, but only the atomically updated value manipulated using methods , and is tracked with respect to synchronization.
可以看到,AbstractQueuedSynchronizer并没有包办一切(否则就不会以Abstract开头了),而是通过 template 模式将同步器的工作划分成两个部分,在父类和子类中分别完成。
共享变量的值,对于不同的子类意味着不同的状态
- 对于ReentrantLock,它是所有者线程已经重复获取该锁的次数
- Semaphore,它表示剩余的许可数量
父类和子类的工作分别是
- 子类负责修改共享变量(a single atomic value to represent state),其操作必须是原子的(通过getState()、setState()和compareAndSetState()方法),根据返回值影响父类的行为(是否挂起当前线程,是否恢复被阻塞线程)。
- AbstractQueuedSynchronizer负责线程阻塞队列(FIFO)的维护,根据预留给子类的方法的返回值判断线程阻塞和唤醒(queuing and blocking mechanics)
AbstractQueuedSynchronizer留给子类实现的方法,一般以try开头,父类中对应的方法会调用这些方法。类似于操作系统的PV操作,或者说:我们在本文开始提到的synchronized一些问题,acquire和release基本是用来顶替wait和notify的。
-
排他模式
protected boolean tryAcquire(int arg) // 根据当前状态,是否挂起线程(获取操作,还会影响共享变量值) protected boolean tryRelease(int arg) // 新的状态,是否允许唤醒某个线程 protected boolean isHeldExclusively() -
共享模式(允许有限的多个线程同时进入临界区)
protected int tryAcquireShared(int arg) protected boolean tryReleaseShared(int arg)
一般情况下,在tryAcquire中判断state值,判断是否阻塞线程,如果阻塞,cas增加state值,在tryRelease减少state值。
在AQS框架下,我们可以自定义一个锁的实现
public class Mutex{
private final Sync sync = new Sync();
public void signal(){sync.releaseShared(0);}
public void await() throws InterruptedException{
sync.acquireShared(0);
}
private class Sync extends AbstractQueuedSynchronizer{
protected int tryAcquireShared(int ignored){
// 共享变量为1表示锁空闲,为0表示锁被占用
return (getState() == 1) ? 1 : -1;
}
protected boolean tryReleaseShared(int ignored){
setState(1);
return true;
}
}
}
Mutex是面向用户的,用户使用Mutext时只需mutex.await和mutex.signal即可。同步器面向的是线程访问和资源控制,使用时除调用acquire和release方法外,还要设置具体的参数值,为数据的变化赋予意义(Mutex中参数是没用的)。
AQS中最重要的一个字段就是state,锁和同步器的实现都是围绕着这个字段的修改展开的。AQS可以实现各种不同的锁和同步器的原因之一就是,不同的锁或同步器按照自己的需要可以对同步状态的含义有不同的定义,并重写对应的tryAcquire, tryRelease或tryAcquireshared, tryReleaseShared等方法来操作同步状态。
AQS架构
从ReentrantLock的实现看AQS的原理及应用 入队出队过程未读完
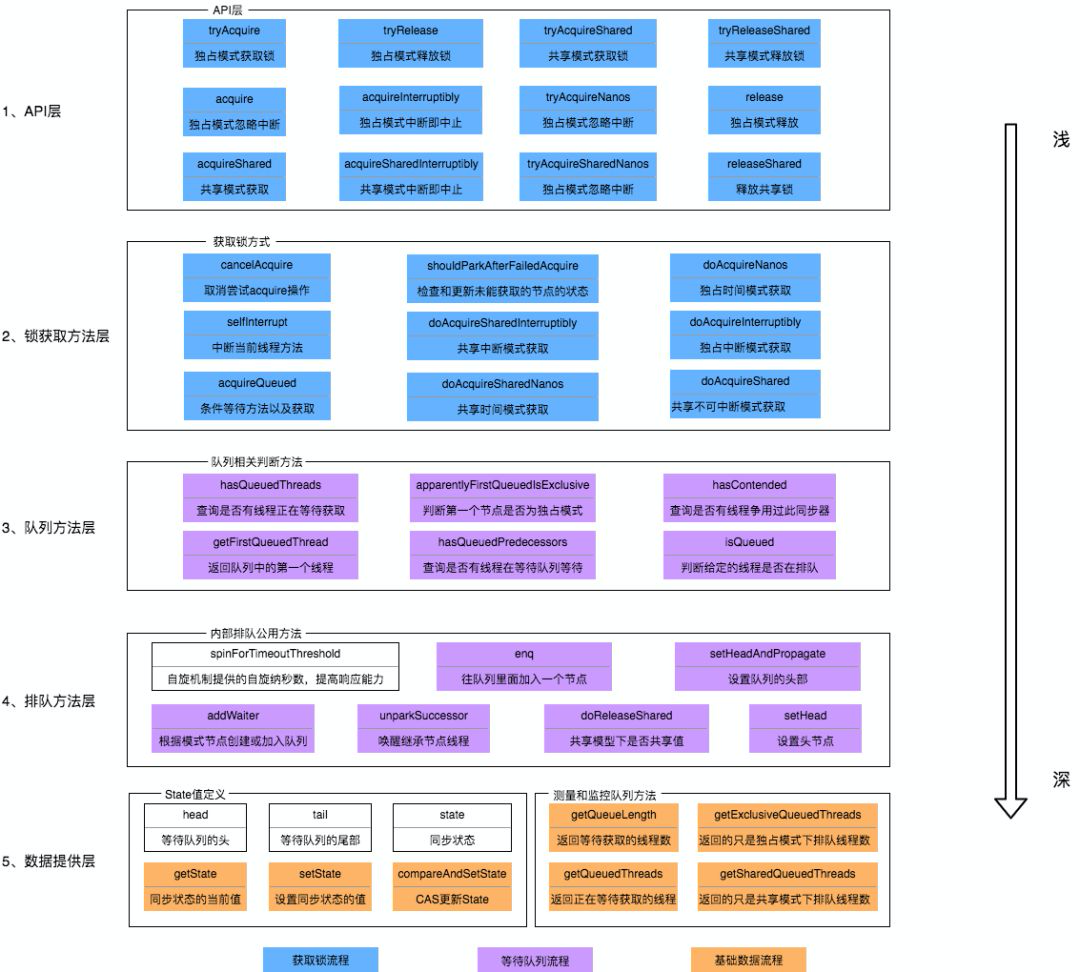
- 上图中有颜色的为Method,无颜色的为Attribution。
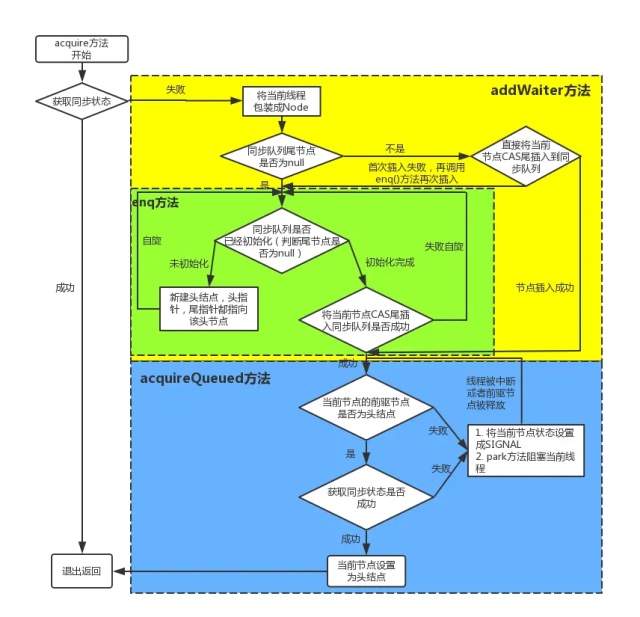
- 当有自定义同步器接入时,只需重写第一层所需要的部分方法即可,不需要关注底层具体的实现流程。当自定义同步器进行加锁或者解锁操作时,先经过第一层的API进入AQS内部方法,然后经过第二层进行锁的获取,接着对于获取锁失败的流程,进入第三层和第四层的等待队列处理,而这些处理方式均依赖于第五层的基础数据提供层。
一个线程的AQS之旅: 入队 ==> 自旋 ==> 获取锁失败 ==> 阻塞 ==> 被唤醒 ==> 获取锁 ==> 出队 ==> 干业务逻辑 ==> 唤醒其它线程。 这个过程中,除了不能自己唤醒自己,入队、出队等都当前线程操作自己干的。 真的是“师傅领进门,修行靠个人”
从队列开始说起
AQS中的队列(并且是一个双向队列,头结点为虚结点)采用链表作为存储结构,通过节点中的next指针维护队列的完整。AbstractQueuedSynchronizer关于队列操作的部分如下:
public abstract class AbstractQueuedSynchronizer{
private transient volatile Node head;
private transient volatile Node tail;
Node {
int waitStatus;
Node prev;
Node next;
Node nextWaiter;
Thread thread;
}
// 在队列尾部插入节点,中间一些操作用到CAS以保证原子性
private Node addWaiter(Node mode){}
// 将一个Node的相关指向置为空,并不再让其它节点指向它,即可(GC)释放该节点
}
AQS实际上通过头尾指针来管理同步队列,实现包括获取锁失败的线程进行入队,释放锁时unpark 队首节点/线程等核心逻辑
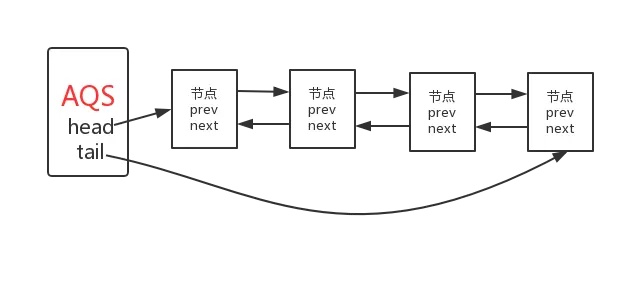
入队——AbstractQueuedSynchronizer.acquire
在排他模式下,线程执行一次acquire所需要经历的过程
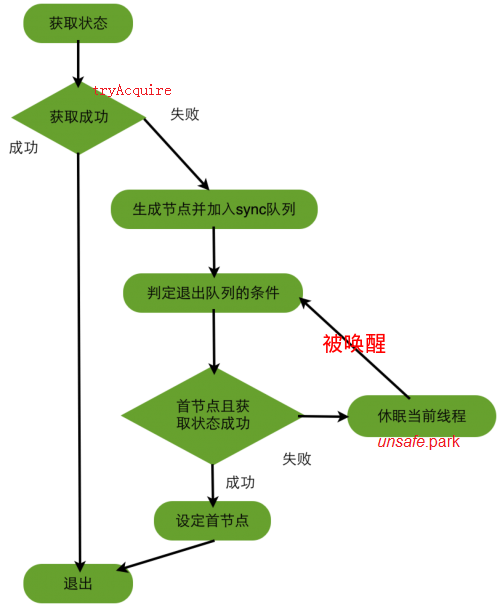
上图中的循环过程就是完成了自旋的过程,也正是有了这个循环,为支持超时和中断提供了条件。跳出当前循环的条件是当“前置节点是头结点,且当前线程获取锁成功”。为了防止因死循环导致CPU资源被浪费,我们会判断前置节点的状态来决定是否要将当前线程挂起.
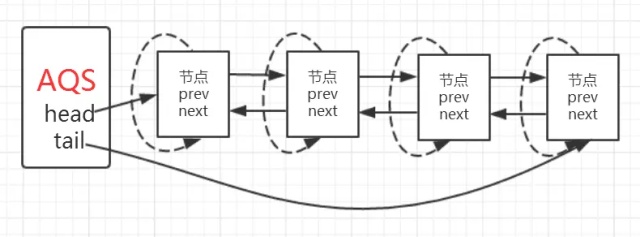
流程与代码相结合
出队
当前线程判断自己退出队列的条件
- 当前线程对应队列节点是首节点。如果是,说明轮到自己了。
- 获取“状态”是否成功。如果是,说明上一个首节点已经“忙完了”
将当前节点通过setHead()方法设置为队列的头结点,然后将之前的头结点的next域设置为null并且pre域也为null,即与队列断开,无任何引用方便GC时能够将内存进行回收。
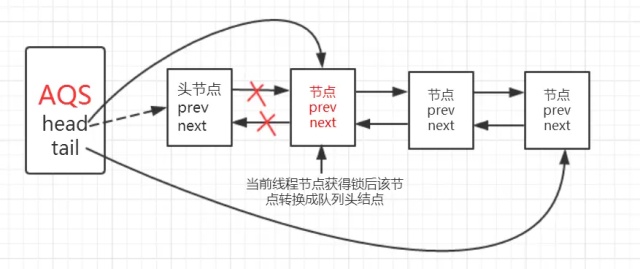
节点挂起后,何时被唤醒?
前置(首)节点的release操作会唤醒当前节点。共享模式下,前置节点的唤醒也会间接唤醒当前节点。
// java.util.concurrent.locks.AbstractQueuedSynchronizer
public final boolean release(int arg) {
// 上边自定义的tryRelease如果返回true,说明该锁没有被任何线程持有
if (tryRelease(arg)) {
// 获取头结点
Node h = head;
// 头结点不为空并且头结点的waitStatus不是初始化节点情况,解除线程挂起状态
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
AQS VS synchronized
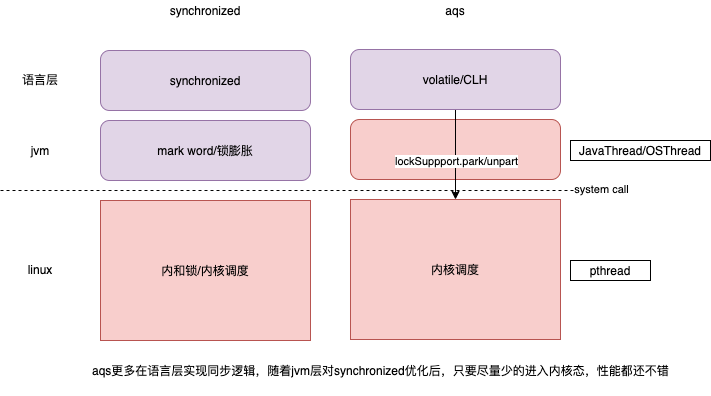
synchronized原理
JVM源码分析之synchronized实现synchronized的HotSpot实现依赖于对象头的Mark Word。JVM中创建对象时会在对象前面加上两个字大小的对象头mark word。Mark Word最后3bit是状态位,根据不同的状态位Mark Word中存放不同的内容。有时存储当前占用的线程id,有时存储某个线程monitor/lock record 的地址。
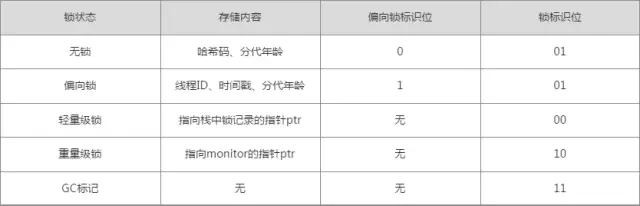
markOop中提供了大量方法用于查看当前对象头的状态,以及更新对象头的数据。比如 markOop->monitor() 里可以保存ObjectMonitor的对象。
class BasicObjectLock {
BasicLock _lock;
oop _obj; // object holds the lock;
}
class BasicLock {
volatile markOop _displaced_header; // 保存_obj指向Object对象的对象头数据;
}
// 每个对象有一个监视器锁(monitor), 每个锁对象拥有一个锁计数器和一个指向持有该锁的线程的指针。
ObjectMonitor::ObjectMonitor() {
_header = NULL; // markOop对象头
_count = 0;
_waiters = 0, // markOop对象头
_recursions = 0; // 重入次数
_object = NULL; // ObjectMonitor寄生的对象
_owner = NULL;
_WaitSet = NULL; // 处于wait状态的线程,会被加入到wait set;
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到entryset;
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
- synchronized 实现中,无锁、偏向锁、轻量级锁、重量级锁(使用操作系统锁)。中间两种锁不是“锁”,而是一种机制,减少获得锁和释放锁带来的性能消耗。
- Monitor是线程私有的数据结构,每一个线程都有一个可用monitor record列表,同时还有一个全局的可用列表。
- 线程会根据自己获取锁的情况更改 mark word的状态位。mark word 状态位本质上反应了锁的竞争激烈程度。若一直是一个线程自嗨,mark word存一下线程id即可。严格意义上来讲偏向锁并不算一把真正的锁,因为只有一个线程去访问共享资源的时候才会有偏向锁这个情况,jdk15之后默认已经禁用了偏向锁。若是两个线程虽说都访问,但没发生争抢,或者自旋一下就拿到了,则哪个线程占用对象,mark word就指向哪个线程的monitor record。若是线程争抢的很厉害(10次自旋或等待cpu调度的线程数超过cpu核数的一半),则只好走操作系统锁流程了——重量级锁,会导致线程的状态切换,让出cpu。偏向锁通过对比Mark Word在没有多线程竞争的情况下,尽量减少不必要的轻量级锁执行路径,轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只依赖一次CAS原子指令置换ThreadID。而轻量级锁是通过用CAS操作和自旋来尽量避免重量级锁引起的性能消耗。重量级锁是将除了拥有锁的线程以外的线程都阻塞。谈谈JVM内部锁升级过程
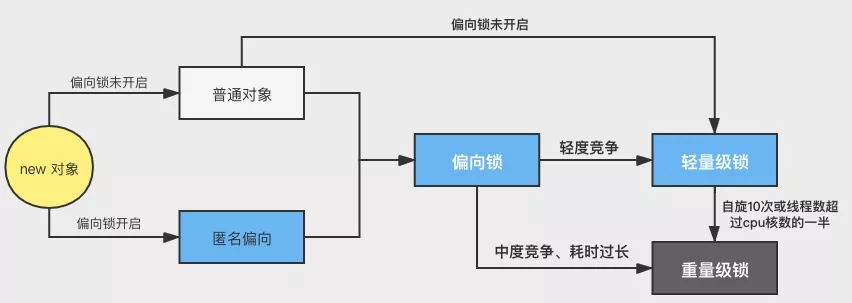
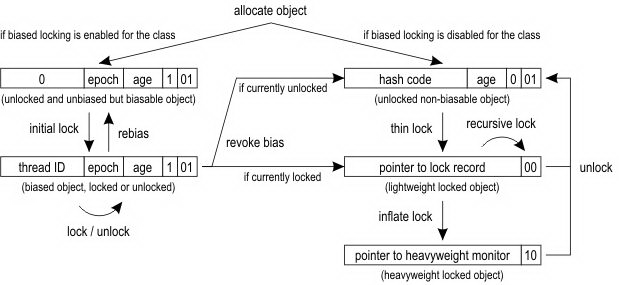
从底层原理来说,除了时间片中断外,所谓的阻塞都是线程自己让出了cpu(设置状态 + 执行内核调度函数scheduler),区别在于这些逻辑写在用户态还是内核态,由内核lock封装还是自己通过“park/unpark + 等待队列” 直接动手。
DK1.6 之后性能优势不大了,只剩下功能优势
由于Java的线程是映射到操作系统的原生线程之上的,如果要阻塞或唤醒一条线程,都需要操作系统来帮忙完成,这就需要从用户态转换到核心态中,因此状态转换需要耗费很多的处理器时间。所以synchronized是Java语言中的一个重量级操作。在JDK1.6中,虚拟机进行了一些优化,譬如在通知操作系统阻塞线程之前加入一段自旋等待过程,避免频繁地切入到核心态中,在用户态/jvm层完成锁操作。
synchronized与java.util.concurrent包中的ReentrantLock相比,由于JDK1.6中加入了针对锁的优化措施(见后面),使得synchronized与ReentrantLock的性能基本持平。ReentrantLock只是提供了synchronized更丰富的功能,而不一定有更优的性能,所以在synchronized能实现需求的情况下,优先考虑使用synchronized来进行同步。
惊群效应
AbstractQueuedSynchronizer与synchronized优缺对比及AQS 源码分析笔记
羊群效应,当有多个线程去竞争同一个锁的时候,假设锁被某个线程释放,那么如果有成千上万个线程在等待锁,有一种做法是同时唤醒这成千上万个线程去去竞争锁,这个时候就发生了羊群效应,海量的竞争必然造成资源的剧增和浪费(缓存同步开销,我们知道volatile 的工作原理,强制线程从内存读取数据 是有开销的。所有等待线程 突然去争抢一个锁(也就是检测锁变量),必然会所有等待线程强制去内存读取这个变量的值)。因为终究只能有一个线程竞争成功,其他线程还是要老老实实的回去等待。
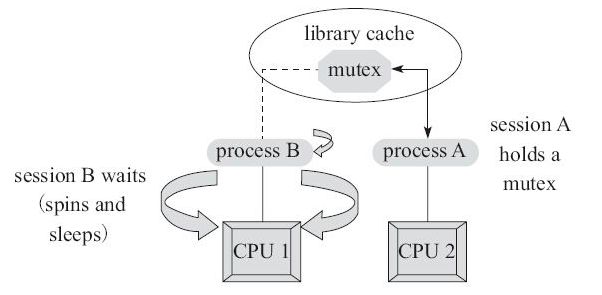
synchronized 较新实现/AQS的FIFO的等待队列给解决在锁竞争方面的羊群效应问题提供了一个思路:AQS使用了变种的CLH队列,因为队列里的线程只监视其前面节点线程的状态,根据前面节点来判断自己是继续争用锁,还是需要被阻塞; 线程唤醒也只唤醒队头等待线程。因为每个线程只会读写前一个线程的状态值,这个值只会被当前线程使用到,相比传统的所有线程都监视读写一个同步变量,CLH可以减少变量的变更带来的多处理器缓存同步的开销;
如果你的目标是让端到端的延迟只有 10毫秒,而其中花80纳秒去主存拿一些未命中数据的过程将占很重的一块。
沪江——写个AQS 是个系列,值得一读
留下评论