为什么要有堆栈
简介
电影胶卷的一个胶片叫做一帧,电影的播放就是代码执行一个个函数一样,一帧一帧过去。
缘起:动态数据分配
追溯历史确实是理解概念的最好方法。不仅学计算机是这样,学其他学科也是这样。比如,很多人学物理,就是三板斧:背概念、记公式、做题目。但我一直认为,仅仅这样做是无法深刻理解物理概念的。学习一点物理史,了解概念、公式提出的背景,所要解决的问题,对于更深刻的理解物理图像,会更有帮助。计算机科学也不例外,人们提出这些概念,不是为了提出概念而提出概念,而是要解决当时面临的问题。最开始的时候,既没有栈,也没有堆。冯·诺依曼提出冯·诺依曼架构的时候,只是说要计算机要有“存储器”,并没有进一步划分为“堆”和“栈”。所以,早期( 1940s 到 1950s )实现的计算机,既没有栈的概念,有没有堆的概念。整个内存空间就是一张白纸,任你书写,任你驰骋。事实上,今天的一些设备,依然使用这种开发模式,比如,一些单片机的开发。既然”All our memory are belong to you”了,那按照今天的话说,就是整个地址空间,每个bit,都是全局变量。我们现在知道这样是不行的。当时人也不傻,时间长了也发现,这样真不行。这样写出的代码都是“面条代码”,难以理解,不可维护(写起来快,改起来累)。终于,到了1958年,一群欧洲和美国的计算机科学家提出了ALGOL 58语言,1960年又发展为ALGOL 60语言。ALGOL语言是里程碑式的,对后世语言影响很大。可以说目前所有主流语言都是这门语言的后代。ALGOL 革命性的提出了结构化编程的理念,用于解决面条代码的问题。结构化编程的意思就是代码要想不变成面条,一定要结构化,划分成块(if块、循环块、函数块),每块用begin…end包起来。begin…end中间,局部使用的变量也要本地化,不能再引用全局变量,避免变量耦合,代码变面条。那么,问题来了。如何实现变量的局部化呢?自然的想法就是进入每个块的时候,为这个块新开辟一块内存,由这个块独占。这里要注意,块是可以嵌套的(nested),A函数会调用B函数,B函数 又可能调用C函数… 。而且这个嵌套结构有个特点:程序执行时,最后执行的块(比如函数),一定会最先执行完。所以,后申请的块内存,一定会先释放。所以这一定是一种后进先出的数据结构。这就是“栈”。是结构化编程的一个自然结果。并不是科学家发明了“栈”这个概念,后来应用到了计算机语言中,而是在实现结构化编程时,发现必须使用一种LIFO的数据结构。1960s~1970s,ALGOL 的结构化编程思想逐渐为大家所接受。当然,这种模式会带来大量的push和pop操作。为了提高程序效率,DEC在1963年推出的PDP-6计算中,率先提供了PUSH, POP, PUSHJ, POPJ四个CPU指令。后继的几乎所有开发语言,以及CPU指令集,全部都遵循了这个范式,直到今天。
下面说堆,大家知道最早的高级语言叫FORTRAN,早期版本的FORTRAN除了基本类型外,使用DIMENSION定义一块内存,但这个DIMENSION必须在程序里写死维度和长度,按现在话说,内存必须在编译时静态分配好,不能在运行时分配。今天大家使用这样的语言编程,一定会疯掉。我在开发时候,就必须确定一个http返回包的大小并预先静态分配好内存?当时人当然也不爽。所以1960s初开发的BCPL语言首次引入了“堆”的概念,提供GETBLK(n)和FREEBLK(p)两个函数。这两个函数可以在运行时动态申请一块内存。BCPL语言发展到C语言,就是著名的malloc和free函数。这就是“堆”,为了能让你推迟到运行时再决定一块数据的大小,而不是在写代码时就必须决定。注意这一点和“栈”是不同的,绝大多数语言栈上数据的大小必须在编译期决定。
这就是“堆”和“栈”。这些概念的提出,都是为了解决一些问题的自然发展结果,没有任何高深之处。当你在函数中定义个一个变量的时候,你就在使用“栈”,当你malloc、new的时候,你就在使用堆。当然,在具体实现堆和栈的时候,会遇到很多细节问题,比如:栈的长度能不能无限大?堆里面要频繁申请释放,如何减少内存的窟窿,提高效率?进一步可能想到,每次malloc后一定要free,又麻烦又不安全,能不能由运行时自动free(GC,垃圾回收)。理解基本概念后,再理解这些实现细节也不会太难。
为什么需要 GC 内存分配一般有三种方式:静态存储区(根对象、静态变量、常量)、栈(函数中的临时局部变量)、堆(malloc、new等);
- 在计算机诞生初期,在程序运行过程中没有栈帧(stack frame)需要去维护,所以内存采取的是静态分配策略,这虽然比动态分配要快,但是其一明显的缺点是程序所需的数据结构大小必须在编译期确定,而且不具备运行时分配的能力,这在现在来看是不可思议的。
- 在 1958 年,Algol-58 语言首次提出了块结构(block-structured),块结构语言通过在内存中申请栈帧来实现按需分配的动态策略。在过程被调用时,帧(frame)会被压到栈的最上面,调用结束时弹出。PS:一个block 内的变量要么都可用 要么都回收,降低了管理成本。但是后进先出(Last-In-First-Out, LIFO)的栈限制了栈帧的生命周期不能超过其调用者,而且由于每个栈帧是固定大小,所以一个过程的返回值也必须在编译期确定。所以诞生了新的内存管理策略——堆(heap)管理。
- 堆分配运行程序员按任意顺序分配/释放程序所需的数据结构——动态分配的数据结构可以脱离其调用者生命周期的限制,这种便利性带来的问题是垃圾对象的回收管理。
应用程序的内存划分
操作系统把磁盘上的可执行文件加载到内存运行之前,会做很多工作,其中很重要的一件事情就是把可执行文件中的代码,数据放在内存中合适的位置,并分配和初始化程序运行过程中所必须的堆栈,所有准备工作完成后操作系统才会调度程序起来运行。PS:有点jvm类加载的感觉
来看一下程序运行时在内存(虚拟地址空间)中的布局图:
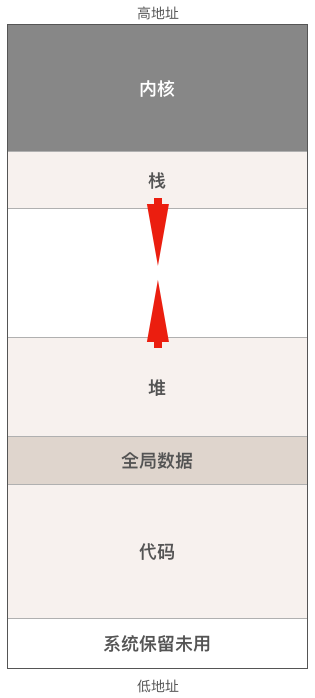
- 代码区,也被称为代码段,包括能被CPU执行的机器代码(指令)和只读数据比如字符串常量,这部分内存通常是只读的,以防止程序意外地修改其自身的指令。
- 数据区,包括程序的全局变量和静态变量(c语言有静态变量,而go没有),与代码区一样,程序加载完毕后数据区的大小也不会发生改变。
- 堆,堆是用于动态内存分配的区域,例如c语言的malloc函数和go语言的new函数就是在堆上分配内存。这部分内存由内存分配器负责管理,堆从低地址向高地址增长。该区域的大小会随着程序的运行而变化。传统的c/c++代码就必须小心处理内存的分配和释放,而在go语言中,有垃圾回收器帮助我们
- 栈内存是一个连续的内存区域,通常从高地址向低地址增长。每次函数调用都会在栈上分配一个新的栈帧,函数返回时栈帧会被释放。栈帧包含了函数调用的上下文信息,包括函数的参数、局部变量和返回地址。
AMD64 CPU中有3个与栈密切相关的寄存器:
- rsp寄存器 ,始终指向当前函数调用栈栈顶。
- rbp寄存器 ,一般用来指向当前函数栈帧的起始位置,即栈底。PS:rsp和rbp指向堆栈段。
- ip寄存器,保存着下一条将要执行的指令的内存地址。CPU在执行指令时,会根据IP寄存器的值从内存中获取指令从而执行,在大多数情况下,IP寄存器的值会按顺序递增,以指向下一条指令,这使得程序能够顺序执行。PS: 指向代码段。 PS:操作系统对线程的调度可以简单的理解为内核调度器对不同线程所使用的寄存器和栈的切换。可执行文件 ==> 进程内存区域构成 ==> 寄存器指向
每个函数在执行过程中都需要使用一块栈内存用来保存上述这些值,我们称这块栈内存为某函数的栈帧(stack frame)。当发生函数调用时,因为调用者还没有执行完,其栈内存中保存的数据还有用,所以被调用函数不能覆盖调用者的栈帧,只能把被调用函数的栈帧“push”到栈上,等被调函数执行完成后再把其栈帧从栈上“pop”出去,这样,栈的大小就会随函数调用层级的增加而生长,随函数的返回而缩小。栈的生长和收缩都是自动的,由编译器插入的代码自动完成,因此位于栈内存中的函数局部变量所使用的内存随函数的调用而分配,随函数的返回而自动释放,所以程序员不管是使用有垃圾回收还是没有垃圾回收的高级编程语言都不需要自己释放局部变量所使用的内存,这一点与堆上分配的内存截然不同。
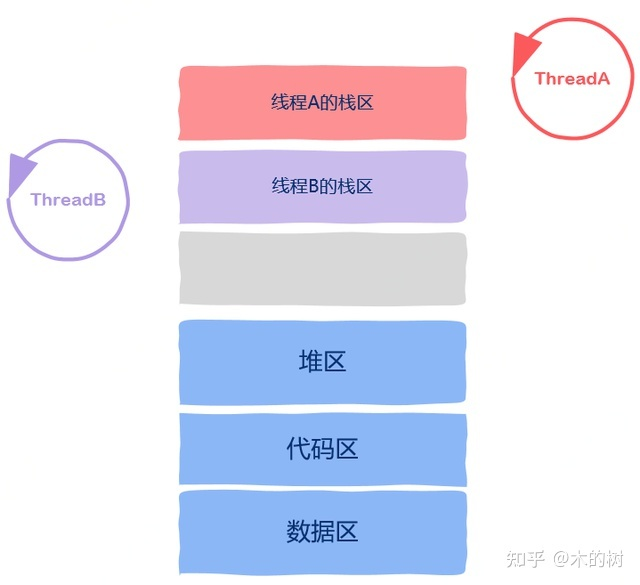
解密Go协程的栈内存管理堆和栈都是编程语言里的虚拟概念,并不是说在物理内存上有堆和栈之分,两者的主要区别是栈是每个线程或者协程独立拥有的,从栈上分配内存时不需要加锁。而整个程序在运行时只有一个堆,从堆中分配内存时需要加锁防止多个线程造成冲突,同时回收堆上的内存块时还需要运行可达性分析、引用计数等算法来决定内存块是否能被回收,所以从分配和回收内存的方面来看栈内存效率更高。
AMD64 Linux平台下,栈是从高地址向低地址方向生长的,为什么栈会采用这种看起来比较反常的生长方向呢,具体原因无从考究,不过根据前面那张进程的内存布局图可以猜测,当初这么设计的计算机科学家是希望尽量利用内存地址空间,才采用了堆和栈相向生长的方式,因为程序运行之前无法确定堆和栈谁会消耗更多的内存,如果栈也跟堆一样向高地址方向生长的话,栈底的位置不好确定,离堆太近则堆内存可能不够用,离堆太远栈又可能不够用,于是乎就采用了现在这种相向生长的方式。
为什么需要栈
栈是支持程序运行的基本数据结构,它跟计算机硬件(call、ret、push、pop 等指令),比如 CPU 的栈指针寄存器、操作系统息息相关,还跟编译器关系密切(我们在函数中定义的局部变量,就是放在栈中的,函数的调用和返回,也是依赖于栈)。《揭秘Java虚拟机》
- 函数内部会定义局部变量,变量要占内存,由于位于同一函数中,很自然的想法是将其内存空间放在一起,有利于整体申请和释放。所以栈帧首先是一个容器。
- 一个函数一帧,多个函数多个帧。如何组织呢? PS: 散列不行,所以选择了线性,队列不合适,选择了栈。
- 散列。一个函数的栈帧随意在内存中分配,栈帧地址与函数名建立关联关系 ==> 调用方与被调用方要保存对方的堆栈空间地址。
- 线性。又分为队列和栈两种结构。函数调用符合栈的特性,就用栈了。
- 操作系统明显的将程序空间区分为堆和栈,堆栈的增长方向不同(相向),为何呢?如果堆栈都从地址0开始分配,则栈空间和堆空间相互交错,则栈实际内存空间的连续性就被破坏了(堆没有这个要求)
- 系统每次保存栈顶和栈底地址比较麻烦, 因此硬件上使用SP 和BP 寄存器来加速这个过程。
sub $32,%sp开辟栈空间,add $32, $sp释放栈空间。 - 在操作系统环境下,操作系统会为一个进程/线程单独划分一个栈空间,还是会让所有进程/线程共同使用同一个栈空间呢?因为栈帧必须是连续的,所以只能是前者。
Memory Management/Stacks and Heaps
- The system stack, are used most often to provide frames. A frame is a way to localize information about subroutines(可以理解为函数).
- In general, a subroutine must have in its frame the return address (where to jump back to when the subroutine completes), the function’s input parameters. When a subroutine is called, all this information is pushed onto the stack in a specific order. When the function returns, all these values on the stack are popped back off, reclaimed to the system for later use with a different function call. In addition, subroutines can also use the stack as storage for local variables.
Demystifying memory management in modern programming languagesThe stack is used for static memory allocation and as the name suggests it is a last in first out(LIFO) stack. the process of storing and retrieving data from the stack is very fast as there is no lookup required, you just store and retrieve data from the topmost block on it.
根据上文可以推断:为什么需要栈?为了支持函数。OS设计体现了对进程、线程的支持,直接提供系统调用创建进程、线程,但就进程/线程内部来说,os 认为代码段是一个指令序列,最多jump几下,指令操作的数据都是事先分配好的(数据段主要容纳全局变量,且是静态分配的),没有直接体现对函数的支持(只是硬件层面上提供了栈指针寄存器,编译器实现函数参数、返回值压栈、出栈)。没有函数,代码会重复,有了函数,才有局部变量一说,有了局部变量才有了数据的动态申请与分配一说。函数及其局部变量 是最早的 代码+数据的封装。
Go 垃圾回收(二)——垃圾回收是什么?GC 不负责回收栈中的内存,为什么呢?主要原因是栈是一块专用内存,专门为了函数执行而准备的,存储着函数中的局部变量以及调用栈。除此以外,栈中的数据都有一个特点——简单。比如局部变量就不能被函数外访问,所以这块内存用完就可以直接释放。正是因为这个特点,栈中的数据可以通过简单的编译器指令自动清理,也就不需要通过 GC 来回收了。
一文教你搞懂 Go 中栈操作In computer science, a call stack is a stack data structure that stores information about the active subroutines of a computer program. In computer programming, a subroutine is a sequence of program instructions that performs a specific task, packaged as a unit.A stack frame is a frame of data that gets pushed onto the stack. In the case of a call stack, a stack frame would represent a function call and its argument data.栈是一种栈数据结构,用于存储有关计算机程序的活动 subroutines 信息。栈帧stack frame又常被称为帧frame是在调用栈中储存的函数之间的调用关系,每一帧对应了函数调用以及它的参数数据。
《现代C++实战30讲》本地变量所需的内存就在栈上,跟函数执行所需的其他数据(参数,下一行汇编指令的地址)在一起。
- 栈上的分配极为简单,移动一下栈指针而已。
- 栈上的释放也极为简单,函数执行结束时移动一下栈指针即可。
- 由于后进先出的执行过程,不可能出现内存碎片。
函数调用栈相关的指令和寄存器
函数运行时在内存中是什么样子?进程和线程的运行体现在函数执行上,函数的执行除了函数内部执行的顺序执行还有子函数调用的控制转移以及子函数执行完毕的返回。函数调用是一个First In Last Out 的顺序,天然适用于栈这种数据结构来处理。当函数在运行时每个函数也要有自己的一个“小盒子”,这个小盒子中保存了函数运行时的各种信息,这些小盒子通过栈这种结构组织起来,这个小盒子就被称为栈帧,stack frames,也有的称之为call stack。当函数A调用函数B的时候,控制从A转移到了B,所谓控制其实就是指CPU执行属于哪个函数的机器指令。当函数A调用函数B时,我们只要知道:函数A对于的机器指令执行到了哪里 (我从哪里来,返回 ret);函数B第一条机器指令所在的地址 (要到哪里去,跳转 call)。
- rsp 栈顶寄存器和rbp栈基址寄存器:这两个寄存器都跟函数调用栈有关,其中rsp寄存器一般用来存放函数调用栈的栈顶地址,而rbp寄存器通常用来存放函数的栈帧起始地址,编译器一般使用这两个寄存器加一定偏移的方式来访问函数局部变量或函数参数。比如:
mov 0x8(%rsp),%rdx call 目标地址指令执行函数调用。CPU执行call指令时首先会把rip寄存器中的值入栈,然后设置rip值为目标地址,又因为rip寄存器决定了下一条需要执行的指令,所以当CPU执行完当前call指令后就会跳转到目标地址去执行。一条call指令修改了3个地方的值:rip寄存器、rsp和栈。- ret指令从被调用函数返回调用函数,它的实现原理是把call指令入栈的返回地址弹出给rip寄存器。一条call指令修改了3个地方的值:rip寄存器、rsp和栈。
一些有意思的表述:
- 函数调用后的返回地址会保存到堆栈中。jmp跳过去就不知道怎么回来了,而通过call跳过去后,是可以通过ret指令直接回来的。call指令保存eip的地方叫做栈,在内存里,ret指令执行的时候是直接取出栈中保存的eip值 并恢复回去,达到返回的效果。PS: rsp 和 rsp 就好像一个全局变量,一经改变,call/ret/push/pop 这些指令的行为就都改变了。
- 函数的局部状态也可以保存到堆栈中。在汇编环境下,寄存器是全局可见的,不能用于充当局部变量。借鉴call指令保存返回地址的思路,如果,在每一层函数中都将当前比较关键的寄存器保存到堆栈中,然后才去调用下一层函数,并且,下层的函数返回的时候,再将寄存器从堆栈中恢复出来,这样也就能够保证下层的函数不会破坏掉上层函数的状了。
编译成机器码的函数有什么特点呢?在被调用者的函数体内,通常会分为三个部分。头尾两个部分叫做序曲(prelude)和尾声(epilogue),分别做一些初始化工作和收尾工作。在序曲里会保存原来的栈指针,以及把自己应该保护的寄存器存到栈里、设置新的栈指针等,接着执行函数的主体逻辑。最后,到尾声部分,要根据调用约定把返回值设置到寄存器或栈,恢复所保护的寄存器的值和栈顶指针,接着跳转到返回地址。
jump 和call 的区别是:jump 之后不用回来,而call(也就是函数调用是需要回来的)。有没有一个可以不跳转回到原来开始的地方,来实现函数的调用呢?
- 把调用的函数指令,直接插入在调用函数的地方,替换掉对应的 call 指令,然后在编译器编译代码的时候,直接就把函数调用变成对应的指令替换掉。这个方法有些问题:如果函数 A 调用了函数 B,然后函数 B 再调用函数 A,我们就得面临在 A 里面插入 B 的指令,然后在 B 里面插入 A 的指令,这样就会产生无穷无尽地替换。PS:当然,内联函数完全可以这样做
- 把后面要跳回来执行的指令地址给记录下来。但是在多层函数调用里,简单只记录一个地址也是不够的。像我们一般使用的 Intel i7 CPU 只有 16 个 64 位寄存器,调用的层数一多就存不下了。最终,计算机科学家们想到了一个比单独记录跳转回来的地址更完善的办法。我们在内存里面开辟一段空间,用栈这个后进先出(LIFO,Last In First Out)的数据结构。
函数通过自身的指令遥控其对应的方法栈,可以往里面放入数值,从里面读取数据,也可以将数值移动到其它地方,从调用者的方法栈里取值。函数执行的切换,不只是切换pc,还有切换sp 和bp ,因为函数代码中有很多 指令引用了 sp 和bp。PS:就好比搬家不是换个住处,还有孩子的学校、户籍等等。
栈切换
go调度器源代码情景分析之九:操作系统线程及线程调度线程是什么?进程切换、线程切换、协程切换、函数切换,cpu 只有一个,寄存器也只有一批,想要并发,就得对硬件(cpu和寄存器)分时使用,分时就得save/load,切换时保留现场,返回时恢复现场。线程调度时操作系统需要保存和恢复的寄存器除了通用寄存器之外,还包括指令指针寄存器rip以及与栈相关的栈顶寄存器rsp和栈基址寄存器rbp,rip寄存器决定了线程下一条需要执行的指令,2个栈寄存器确定了线程执行时需要使用的栈内存。所以恢复CPU寄存器的值就相当于改变了CPU下一条需要执行的指令,同时也切换了函数调用栈,因此从调度器的角度来说,线程至少包含以下3个重要内容:
- 一组通用寄存器的值(切换时涉及到save和load)
- 将要执行的下一条指令的地址
- 栈
| 寄存器 | 栈等资源 | ||
|---|---|---|---|
| 函数调用 | PC和栈寄存器 | 如果有参数或返回值的话需要几次用户栈操作 | 不到1ns |
| 协程切换 | 少数几个寄存器 | 协程栈切换 | |
| 系统调用 | SS、ESP、EFLAGS、CS和EIP寄存器 | 同一进程用户态和内核态栈切换 | 1000条左右的cpu指令 200ns到10+us |
| 线程切换 | 寄存器 | 用户态和内核态栈切换到另一线程 | |
| 进程切换 | 几乎所有寄存器 | 用户态和内核态栈切换到另一线程,切换虚拟内存,全局变量等资源 |
系统调用:在内核栈的最高地址端,存放的是一个结构pt_regs,这个结构的作用是:当系统调用从用户态到内核态的时候,首先要做的第一件事情,就是将用户态运行过程中的CPU上下文也即各种寄存器保存在这个结构里。这里两个重要的两个寄存器SP和IP,SP里面是用户态程序运行到的栈顶位置,IP里面是用户态程序运行到的某行代码。
所以操作系统对线程的调度可以简单的理解为内核调度器对不同线程所使用的寄存器和栈的切换。最后,我们对操作系统线程下一个简单且不准确的定义:操作系统线程是由内核负责调度且拥有自己私有的一组寄存器值和栈的执行流。
为什么需要堆?
Heap is used for dynamic memory allocation(data with dynamic size ) and unlike stack, the program needs to look up the data in heap using pointers. 堆其实是虚拟内存空间中一个段,由堆的开始地址和结束地址控制其大小,有一个堆指针指向未分配的第一个字节。所以,堆在本质上是指应用程序在运行过程中进行动态分配的内存区域,堆的管理通常在库函数中完成。
光有栈,对于面向过程的程序设计还远远不够,因为栈上的数据在函数返回的时候就会被释放掉,所以无法将数据传递至函数外部,只能通过不断拷贝的方式保持其“存活”。而全局变量、静态变量生存期虽然与整个程序保持一致,但没有办法在程序的运行过程中动态生成,只能在编译的时候定义,有很多情况下缺乏表现力,且完全暴露给所有程序代码使用,在这种情况下,堆(Heap)是一种唯一的选择。The heap is an area of dynamically-allocated memory that is managed automatically by the operating system or the memory manager library. Memory on the heap is allocated, deallocated, and resized regularly during program execution, and this can lead to a problem called fragmentation.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define N 5
int main(void) {
int arr[] = { 1, 2, 3, 4, 5 };
// 分配用于存放 N 个整数的堆内存;
int* p = (int*) malloc(sizeof(int) * N);
// 将数组 arr 中的元素复制到分配的堆内存中;
memcpy(p, arr, sizeof(int) * N);
for (int i = 0; i < N; ++i) {
// 通过指针遍历堆空间中的数据;
printf("%d\n", *(p + i));
}
// 释放先前分配的堆空间,让操作系统可以回收内存;
free(p);
return 0;
}
如果堆上有足够的空间的满足我们代码的内存申请,内存分配器可以完成内存申请无需内核参与,否则将通过操作系统调用(brk)进行扩展堆,通常是申请一大块内存。(对于 malloc 大默认指的是大于 MMAP_THRESHOLD 个字节 - 128KB)。
任何线程都可以在堆上申请空间(全局的),因此每次申请堆内存都必须进行同步处理,竞争十分激烈,必然会出现线程阻塞。在java 中,为每个线程在eden 区分配一块TLAB 空间,线程在各自的TLAB内存区域申请空间,无需加锁,这是一种典型的空间换时间的策略。
其它
让我们回到创世之初,回到计算机系统奠基时代。奠基者们发现,使用内存主要分两种形式, 大块的、偶而的分配/使用内存,和小块的、频繁的分配/使用内存。前者就像买房、买车,大笔的花费,但不会每天都买一套房、买一辆车。后者就像买瓶水、买包烟,频繁,且细碎。就像花零花钱一样。
- 前者主要交给了操作系统,使用“软”的方式进行管理。比如,你调用GNU函数malloc,就能得到一块内存。当然,这块内存也可能很小,小到一个字节。但如果你真的频繁调用malloc/free,分配、释放内存,碎不碎片的先不说,效率一定是不高的。这里“软”的方式,是指CPU中没有专门组件、模块或指令,对应malloc/free这样的内存管理函数。
- 相比前者纯“软”的方式,后者,花零花钱一样,频繁的分配、使用细碎的内存,纯软的方式性能不好。比如,你程序中要使用10个变量。变量完整的名称是内存变量,10个变量,其实就代表10次内存分配,花10次零花钱。花零花钱,是程序运行其间正常的行为,一个程序跑下来,几千、几万甚至更多变量被分配、释放。如何提高性能,走软、硬结合的方式。在CPU中,内置一部分集成电路,对外提供两条指令: push , pop,和两个寄存器,rbp, rsp,再进行一些“软”方面的约定,把“分配一个内存变量”,变成一个非常简单的操作。有了push/pop,和 rbp/rsp,CPU又不断在这个基础上进行优化。现在push/pop的执行只要一个周期(但涉及内存操作,完成时间仍需要看内存操作的完成速度,不过,相比普通的内存操作,CPU在这方面仍有优化),而且,程序的局部变量可以通过rbp寄存器进行,也简单了许多,并且方便CPU进行预取等优化。
主要区别,堆是纯软操作。栈是硬、软结合操作。有硬件加速成份在。栈,可以说是最早的硬件加速通用性操作的实践。
留下评论