容器狂占内存资源怎么办?
简介
Linux内存管理的机制与特点
OOM Killer
- OOM Killer 在 Linux 系统里如果内存不足时,会杀死一个正在运行的进程来释放一些内存。如果进程 是容器的entrypoint ,则容器退出。
docker inspect命令查看容器, 容器处于”exited”状态,并且”OOMKilled”是 true。出现OOM Killer的原因与解决方案 目前常见的出现OOM Killer的原因有以下几种:- cgroup内存使用达到上限
- 父cgroup内存使用达到上限
- 系统全局内存的使用率过高
- 内存节点(Node)的内存不足
- 内存碎片化时伙伴系统内存不足
- Linux 里的程序都是调用
malloc()来申请内存,如果内存不足,直接malloc()返回失败就可以,为什么还要去杀死正在运行的进程呢?Linux允许进程申请超过实际物理内存上限的内存。因为malloc()申请的是内存的虚拟地址,系统只是给了程序一个地址范围,由于没有写入数据,所以程序并没有得到真正的物理内存。物理内存只有程序真的往这个地址写入数据的时候,才会分配给程序。PS: 虚拟内存通过ps auxVSZ 查看;物理内存ps auxRES(也成为RSS) 查看 - 在发生 OOM 的时候,Linux 到底是根据什么标准来选择被杀的进程呢?这就要提到一个在 Linux 内核里有一个
oom_badness()函数,就是它定义了选择进程的标准。 - 我们怎样才能快速确定容器发生了 OOM 呢?这个可以通过查看内核日志及时地发现。使用用
journalctl -k命令,或者直接查看日志文件/var/log/message
Memory Cgroup
/sys/fs/cgroup/memory
- memory.limit_in_bytes,一个控制组里所有进程可使用内存的最大值
- memory.oom_control,当控制组中的进程内存使用达到上限值时,这个参数能够决定会不会触发 OOM Killer(默认是),当然只能杀死控制组内的进程。
echo 1 > memory.oom_control即使控制组里所有进程使用的内存达到 memory.limit_in_bytes 设置的上限值,控制组也不会杀掉里面的进程,但会影响到控制组中正在申请物理内存页面的进程。这些进程会处于一个停止状态,不能往下运行了。 - memory.usage_in_bytes,只读,是当前控制组里所有进程实际使用的内存总和。
Linux 内存类型
- 内核需要分配内存给页表,内核栈,还有 slab,也就是内核各种数据结构的 Cache Pool;
- 用户态进程内存
- RSS 内存包含了进程的代码段内存,栈内存,堆内存,共享库的内存
- 文件读写的 Page Cache。是一种为了提高磁盘文件读写性能而利用空闲物理内存的机制,因为系统调用 read() 和 write() 的缺省行为都会把读过或者写过的页面存放在 Page Cache 里。
- Linux 的内存管理有一种内存页面回收机制(page frame reclaim),会根据系统里空闲物理内存是否低于某个阈值(wartermark),来决定是否启动内存的回收。内存回收的算法会根据不同类型的内存以及内存的最近最少用原则,就是 LRU(Least Recently Used)算法决定哪些内存页面先被释放。因为 Page Cache 的内存页面只是起到 Cache 作用,自然是会被优先释放的。
Memory Cgroup 里都不会对内核的内存做限制(比如页表,slab 等)。只限制用户态相关的两个内存类型,RSS(Resident Set Size) 和 Page Cache。当控制组里的进程需要申请新的物理内存,而且 memory.usage_in_bytes 里的值超过控制组里的内存上限值 memory.limit_in_bytes,这时我们前面说的 Linux 的内存回收(page frame reclaim)就会被调用起来。那么在这个控制组里的 page cache 的内存会根据新申请的内存大小释放一部分,这样我们还是能成功申请到新的物理内存,整个控制组里总的物理内存开销 memory.usage_in_bytes 还是不会超过上限值 memory.limit_in_bytes。PS:所以会出现 容器内存使用量总是在临界点 的现象。
在 Memory Cgroup 中有一个参数 memory.stat,可以显示在当前控制组里各种内存类型的实际的开销。我们不能用 Memory Cgroup 里的 memory.usage_in_bytes,而需要用 memory.stat 里的 rss 值。这个很像我们用 free 命令查看节点的可用内存,不能看”free”字段下的值,而要看除去 Page Cache 之后的”available”字段下的值。
swap
Swap 是一块磁盘空间,当内存写满的时候,就可以把内存中不常用的数据暂时写到这个 Swap 空间上。这样一来,内存空间就可以释放出来,用来满足新的内存申请的需求。
- 在宿主机节点上打开 Swap 空间,在容器中就是可以用到 Swap 的。
- 因为有了 Swap 空间,本来会被 OOM Kill 的容器,可以好好地运行了(RSS 没有超出)。如果一个容器中的程序发生了内存泄漏(Memory leak),那么本来 Memory Cgroup 可以及时杀死这个进程,让它不影响整个节点中的其他应用程序。结果现在这个内存泄漏的进程没被杀死,还会不断地读写 Swap 磁盘,反而影响了整个节点的性能。
- 在内存紧张的时候,Linux 系统怎么决定是先释放 Page Cache,还是先把匿名内存释放并写入到 Swap 空间里呢?如果系统先把 Page Cache 都释放了,那么一旦节点里有频繁的文件读写操作,系统的性能就会下降。如果 Linux 系统先把匿名内存都释放并写入到 Swap,那么一旦这些被释放的匿名内存马上需要使用,又需要从 Swap 空间读回到内存中,这样又会让 Swap(其实也是磁盘)的读写频繁,导致系统性能下降。
- 显然,我们在释放内存的时候,需要平衡 Page Cache 的释放和匿名内存的释放。Linux swappiness 参数值的作用是,在系统里有 Swap 空间之后,当系统需要回收内存的时候,是优先释放 Page Cache 中的内存,还是优先释放匿名内存(也就是写入 Swap)。
- 在每个 Memory Cgroup 控制组里也有一个 memory.swappiness。 不同就是每个 Memory Cgroup 控制组里的 swappiness 参数值为 0 的时候,就可以让控制组里的内存停止写入 Swap。
Linux内存管理的问题与解决
由于 Linux 内核的原则是尽可能使用内存而非不间断回收,因此当容器内进程申请内存时,内存用量往往会持续上升。当容器的内存用量接近 Limit 时,将触发容器级别的直接内存回收(direct reclaim),回收干净的文件页,这个过程发生在进程申请内存的上下文,因此会造成容器内应用的卡顿;如果内存的申请速率较高,还可能导致容器 OOM (Out of Memory) Killed,引发容器内应用的运行中断和重启。
当整机内存资源紧张时,内核将根据空闲内存(内核接口统计的 Free 部分)的水位触发回收:当水位达到 Low 水位线时,触发后台内存回收,回收过程由内核线程 kswapd 完成,不会阻塞应用进程运行,且支持对脏页的回收;而当空闲水位达到 Min 水位线时(Min < Low),会触发全局的直接内存回收,该过程发生在进程分配内存的上下文,且期间需要扫描更多页面,因此十分影响性能,节点上所有容器都可能被干扰。当整机的内存分配速率超出且回收速率时,则会触发更大范围的 OOM,导致资源可用性下降。
公平性问题
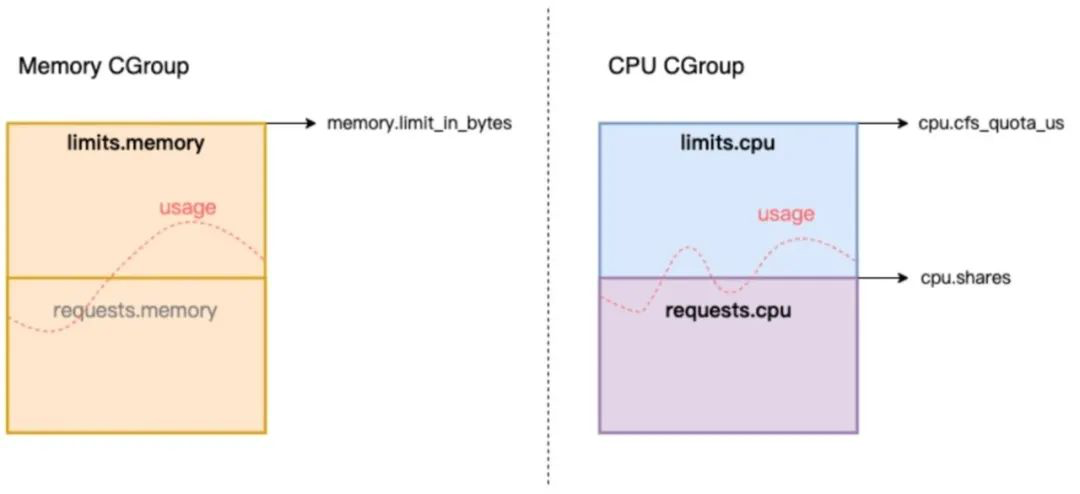
资源超用(Usage > Request)的容器可能和未超用的容器竞争内存资源:对于 Request 层面,Kubelet 依据 CPU Request 设置 cgroups 接口 cpu.shares,作为容器间竞争 CPU 资源的相对权重,当节点的 CPU 资源紧张时,容器间共享 CPU 时间的比例将参考 Request 比值进行划分,满足公平性;而 Memory Request 则默认未设置 cgroups 接口,主要用于调度和驱逐参考。在节点的内存资源紧张时,由于 Memory Request 未映射到 cgroups 接口,容器间的可用内存并不会像 CPU 一样按 Request 比例划分,因此缺少资源的公平性保障。
Kubelet 在 Kubernetes 1.22 以上版本提供了 MemoryQoS 特性,通过 Linux cgroups v2 提供的 memcg QoS 能力来进一步保障容器的内存资源质量,其中包括:
- 将容器的 Memory Request 设置到 cgroups v2 接口 memory.min,锁定请求的内存不被全局内存回收。
- 基于容器的 Memory Limit 设置 cgroups v2 接口 memory.high,当 Pod 发生内存超用时(Memory Usage > Request)优先触发限流,避免无限制超用内存导致的 OOM。
但从用户使用资源的视角来看,依然存在一些不足:
- 当 Pod 的内存声明 Request = Limit 时,容器内依然可能出现资源紧张,触发的 memcg 级别的直接内存回收可能影响到应用服务的 RT(响应时间)。
- 方案目前未考虑对 cgroups v1 的兼容,在 cgroups v1 上的内存资源公平性问题仍未得到解决。
内存回收时的内存使用量的保证(锁定)能力
在 Kubernetes 集群中,Pod 之间可能有保障优先级的需求。比如高优先级的 Pod 需要更好的资源稳定性,当整机资源紧张时,需要尽可能地避免对高优先级 Pod 的影响。然而在一些真实场景中,低优先级的 Pod 往往运行着资源消耗型任务,意味着它们更容易导致大范围的内存资源紧张,干扰到高优先级 Pod 的资源质量,是真正的“麻烦制造者”。对此 Kubernetes 目前主要通过 Kubelet 驱逐使用低优先级的 Pod,但响应时机可能发生在全局内存回收之后。
阿里云容器服务 ACK 基于 Alibaba Cloud Linux 2 的内存子系统增强,用户可以在 cgroups v1 上提前使用到更完整的容器 Memory QoS 功能,如下所示:
- 保障 Pod 间内存回收的公平性,当整机内存资源紧张时,优先从内存超用(Usage > Request)的 Pod 中回收内存(Memory QoS 支持为这类Pod设置主动内存回收的水位线,将内存使用限制在水位线附近),约束破坏者以避免整机资源质量的下降。
- 当 Pod 的内存用量接近 Limit 时,优先在后台异步回收一部分内存,缓解直接内存回收带来的性能影响。
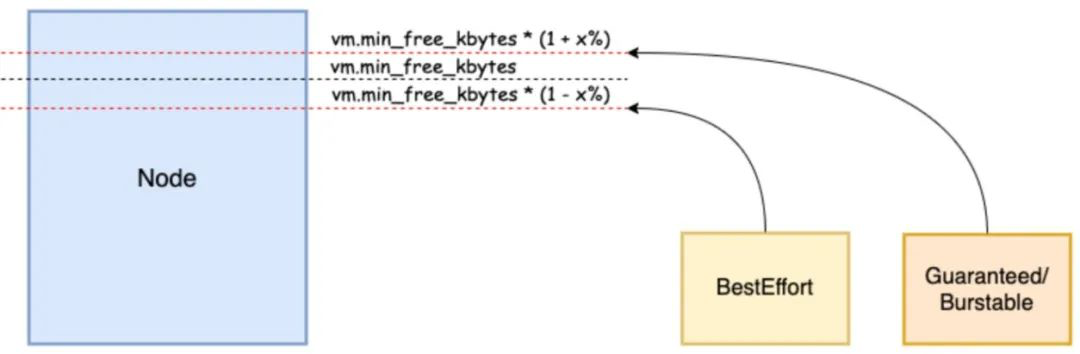
- 节点内存资源紧张时,优先保障 Guaranteed/Burstable Pod 的内存运行质量。Memory QoS 功能通过启用全局最低水位线分级和内核 memcg QoS,当整机内存资源紧张时,优先从 BE 容器中回收内存,降低全局内存回收对 LS 容器的影响;也支持优先回收超用的的内存资源,保障内存资源的公平性。
留下评论