对容器云平台的理解
简介
容器化实践在金融行业落地面临的问题和挑战分享了容器化的落地思路。
组成内容
一开始只是基于k8s api 做了个发布系统,在容器化落地过程中,单单一个发布系统是远远不够的,对要做的事情做了一个梳理。
- 基础组件改造/增强
- lxcfs 让容器内进程 感受到真实配给给容器的资源
- 镜像分发加速
- 发布系统
- 基于代码制作镜像
- 项目发布 四元组
- 无损发布 健康检查 与网关、mainstay 的对接==> 掌握的项目数据必须是准确的
- 发布历史、回滚、扩缩容、服务画像(优先级、基于标签的调度)
- 研发支持:日志采集、web shell、相关信息写入环境变量、隔离组、故障探测工具
- 资源管理中心:mysql、pika、redis、mq、kafka 等容器化
- 监控系统 态势感知,可观测性。
- 项目维度 cpu、内存使用情况、java 特殊性(jvm 感知cpu、内存大小、堆外内存限制)、事件流
- 集群维度 cpu 内存使用,事件中心,核心组件在线(k8s 几大组件、kubelet、docker、calico)
- 存储组件 mysql、redis、pika、mq 等
- 承载组件:prometheus ==> 出了事儿有必要的数据 辅助排查问题
- 报警
- 报什么警
- 常规报警,是否存在、cpu、内存等
- 运行状态报警,健康检查异常、cpu、内存紧张异常、rpc上下线异常
- 集群 资源异常、磁盘损坏异常、有多少反亲和的服务运行在同一个机器上
- 报警策略 报给谁、频度怎么样、对方不处理怎么办。如何不多报、不漏报、不迟报。
- 承载组件:一个 Doraemon + 基于模板的报警系统 能不能承载下来?报警组件本身的健壮性(prometheus 和 cadvisor 都是很费内存的)
- 报警平台,报警来源多种多样,统一汇总起来,报警数据统计,报警文案模板管理等。
- 报什么警
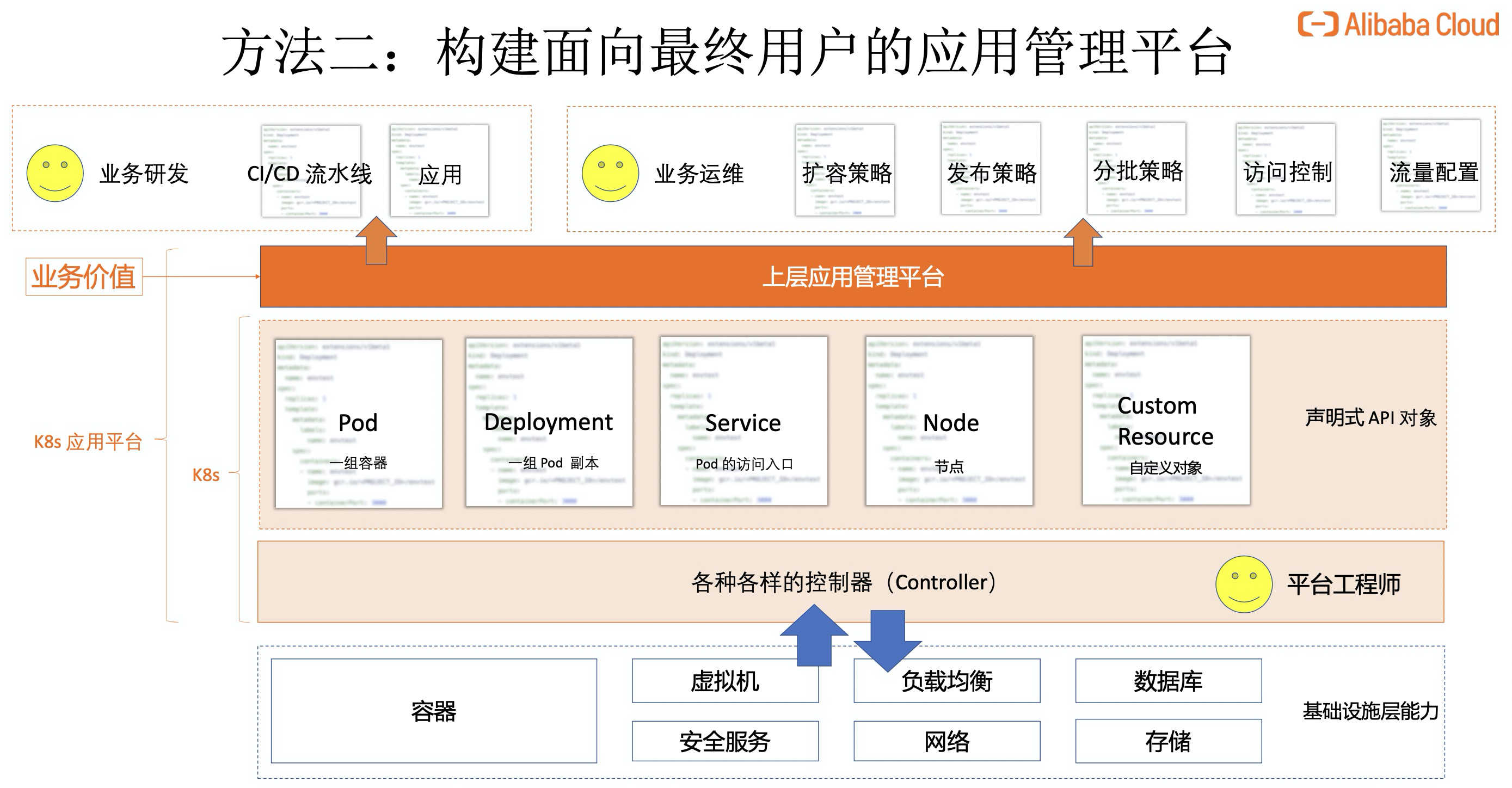
对平台的理解
在容器云的落地构成中,三天两头各种小问题,业务方报过来很不满意。 一个组件A挂了,一会儿报警漏报了,或者天天很多简单的、无厘头的错误找你排查(重复性工作),这个时候就需要一个报警平台、异常探测平台等,这个平台不一定要cover住所有情况,但是当你发现一个新的问题,你可以加到这个平台上,沉淀下来,而不是解决完一个问题就结束了,什么也没留下(这样不管你解决的多少问题,都不能放心系统没有问题)。就好像我写博客,一开始有一个新的知识点就写一篇,写到了466篇,发现很多内容都重复了,后来开始将博客归类,发现新的知识点就填补到原来的博客上。
很有能力,很有想法,所有的技术都会,但就是没有办法输出成为一个平台(或者系统),发生的所有新的事情,都是在这个平台上找到或落地。平台是可以承接你理念、经验的东西。将能力沉淀在平台上,最终目的是降低对于大多数开发、测试的专业能力要求。
逃离职业倦怠期,我是这样做的如果你只是把自动化理解成实现一些几百行代码量的脚本,那么说明你并没有理解什么是真正的自动化,真正的自动化是给出一整套可以提升效率的平台,这个平台可以集成各式各样的改善效率的工具集合,而并非单独零散的脚本。当然这些工具也并非几天或几周就可以做完的,而是通过日常的工作中不断地发现问题、解决问题并总结而来的。以我们团队举例,将一些流程化比较固定的工作通过 RPA 来实现自动化,在出现故障时,为了能够第一时间快速响应故障,我们实现了故障自动拉群功能,这样可以减少故障过程中到处找人的问题。
云原生时代,应用架构将如何演进?对于业务而言,最关心的往往是交付速度。如果你和业务总监或者CTO去聊,他们就会问你,拥有这么多的技术对于业务有什么好处?可能会谈到成本的优势、管理的优势,但是对于几乎所有业务而言,最核心的是研发效率的提升。所以我们应该思考云原生技术如何才能帮助实现更快的交付。
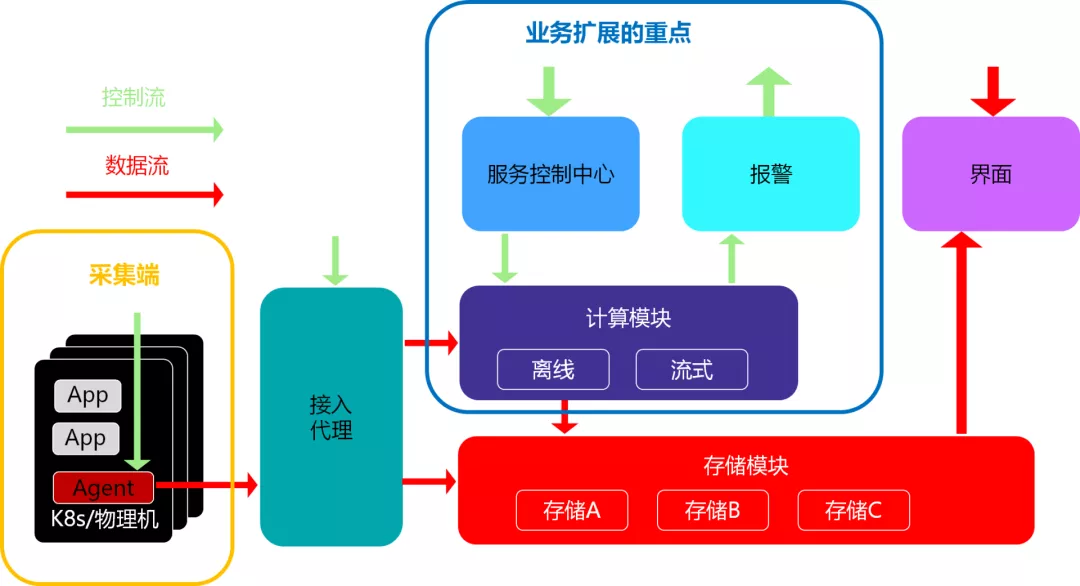
京东如何建设基于云原生架构的监控-日志系统?京东监控 - 日志系统本质上都是标准的 K8s 组件,与京东容器平台 JDOS 关系密切。
- 在 K8s 的视角,监控 - 日志系统是 DaemonSet、RS 的各个 Pod,并非改了系统。
- 在 JDOS 容器平台的视角,监控 - 日志系统可以视为 JDOS 容器平台的一个“插件“,并非强耦合。
- 从应用的视角来,监控 - 日志系统是一个“无需感知“的机制,例如上线无依赖。
留下评论