abtest 系统设计汇总
简介
- 第一个是数据中心的天级部署。
- 第二个数据,我们每天线上变更是两万次。
- 第三个数据是我们每天新增大约1500个A/B测试,说明我们有很多想法的时候可以快速验证,就会产生进化。我再举个例子,假设有两家公司,他们的方向一致,战略水平也差不多,如果一家公司每个星期能做10个A/B测试,验证10个想法,另一家公司每个星期只验证1个想法,可以想象经过半年之后,两家公司会拉开多大的差距。所以说当方向、战略差不多的情况下,敏捷就是决定竞争力的关键因素。
选择方案就好比找女朋友,经过初步分析和了解,比如说选定了样貌和学历两个条件,这时候两个对象都差不多,你选择了好追的(简单的)的对象去追求(实现方案)。事后才发现,追上的脾气大(踩坑了),看着差不多的其实差很多,这时候想回头就很尴尬了。这就是为什么看了这么多道理(方案设计),依然过不好这一生(系统实现有瑕疵)
本文主要是 阅读 ABTest 系统设计的各个方案,加上自身实践,列出设计abtest 系统 应考虑哪些点。
A/B 测试从 0 到 1 极客时间教程,涉及一些理论知识。
Google、Bing、抖音、淘宝等巨头如何做AB实验的? 未读。
AB 实验为何值得信赖? 未读
abtest 系统的边界
- 单纯的用户分流,根据uid等,单纯的对比AB方案
- A/B 与灰度发布,你没看错,跟发布搞在一起。蓝绿部署、A/B测试以及灰度发布
- 任意维度的A/B,比如地域、性别、新老用户等
先来一个完整案例
沪江ABTest测试平台实践 主要内容如下(内容很零碎,用来体现设计一个abtest 要考虑哪些问题):
实验的两个要素:
- 流量。其实就是selector,如何分流
- 参数。其实就是bucket/action ,分流后的动作
流量模型的几个基本概念
- 域,流量的一个划分,比如日语用户
- 层,不同实验层间进行独立的流量划分和独立的实验,互不影响。
- 实验,上文讲过了
不同终端采用不同的用户标识id来hash分流
- web端采用 cookieId
- app端采用设备id
- 小程序端采用 openID 作为唯一标识符
实现正交性的两种方式:
- 具体进行流量划分时,为了实现实验层之间流量划分的正交性,会将流量标识信息和实验层标识一起进行实验流量 bucket 划分, 实验层标识 salt 称为离散因子。
bucket id = hash(uid,salt) % 100 - 学习 ABTest 与灰度发布对于不同的测试,最好使用独立的各不相同的 hash 函数,以保持正交性
tips
- 为了便于内测等,我们也实现了白名单功能,运营或者产品可以通过后台配置某用户命中某个特定的实验参数。
-
在实际线上运行ab测试的时候,我们经常需要针对某个实验参数做流量的扩量或者缩量。
实验变量 A B C 切换前bucket区间 0-79 80-89 90-99 将C扩容10个百分比 0-74 75-79 80-99 切换之后实际上A,B和C覆盖的用户人群都发生了变化。其实更佳的扩缩量方案是:B流量不变,C从A切换 10% 流量过去,这样可以尽量减少对覆盖用户人群参与实验的变化。
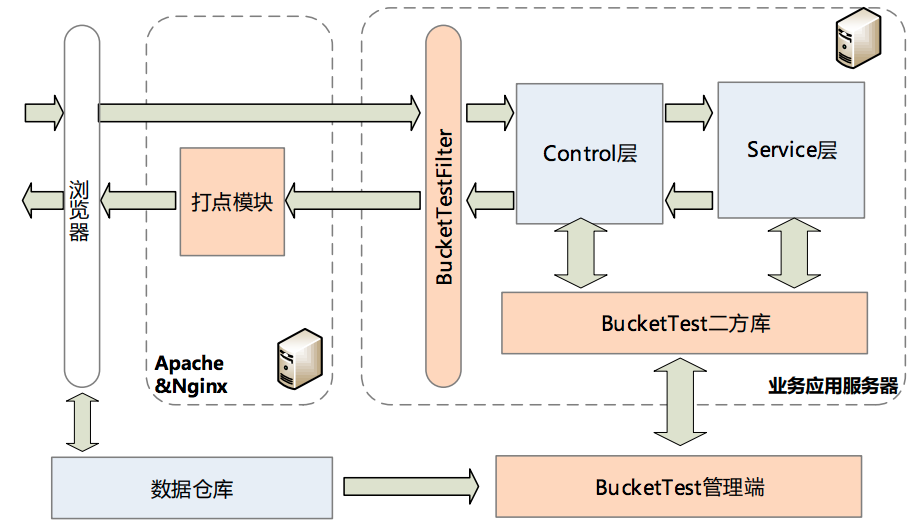
实验平台架构
- 实验管理,允许用户对实验进行配置和管理
- 流量管理,对实验参数分配流量配置
- 数据收集,客户端上报数据,最终落到BI部门Hadoop集群
- 数据分析,对上报的数据进行分析以及计算置信区间等,最后通过报表的形式进行展示。
从中可以猜到
- 沪江的实验管理和流量管理 是分开的。实验更多是参数的集合,作为流量划分、报表生成的单位存在
- 沪江的abtest 并没有向 客户端打tag,整个过程 大致都是服务端完成的。
理论层面
- A/B 测试目的在于通过科学的实验设计、采样样本代表性、流量分割与小流量测试等方式来获得具有代表性的实验结论,并确信该结论在推广到全部流量可信;
-
蓝绿部署的目的是安全稳定地发布新版本应用,并在必要时回滚。
- 精确的流量分发控制
- 监控系统的支撑
- 灵活的发布系统
twitter 的文章偏理论层面:
- Twitter的A/B测试实践(一):为什么要测试以及测试的意义
- 大部分实验只能带来个位数百分比的改进,或者甚至是分数百分比。大多数时候,不理想的 A/B测试结果让我们能够及早发现,看上去不错的想法其实可能不怎么样。因此我们更愿意尽可能快的获得坏消息
- 有些特性不适合A/B,比如A版本的用户想给B版本的用户留言,而B版本的用户没有这个功能。
- Twitter的A/B测试实践(二):技术概述
- 应该跟踪哪些指标?可以在实验配置过程中创建或者从其它现有指标库中选取。
- Twitter的A/B测试实践(三):检测和避免 A/B Test中 bucket不平衡问题
- Twitter的A/B测试实践(四):A/B Test中使用多个控制的启示
生效机制
技术干货-AB测试和灰度发布探索及实践 要点如下
- 立即生效
- 热启生效,热启生效就是退出界面,重新进入生效
- 冷启生效,冷启生效就是杀死进程之后,重新进入生效
分流
- 分流在客户端做:客户端掌握完整 ab数据,自行根据 设备信息 选择 AB 方案的action,比如访问不同的url
- 分流在服务端做:同一个url,服务端 根据AB 配置 返回不同的数据。比如沪江方案
分流要确保 同一个用户 不同时间 返回方案的稳定性。
abtest 关闭之后
abtest 可以轻易关闭么?abtest 的最终目的还是要产生一个结论,这个结论如何广而告之 所有的客户端(通常不现实)?这是否意味着 abtest 在一个客户端版本周期内 不能关闭,最多就是将某个方案的 用户量设置为100%
工程层面
新浪新闻客户端的实践 AB测试和灰度发布探索及实践
适用场景
- 面向客户端,一般涉及到ui 变化,通常涉及到 客户端发版
- 面向服务端,不涉及 ui 变化,数据接口 返回值的schema 不变,只是更改了数据算法 或来源。比如一个专辑列表,返回的都是专辑数据,但有可能来自用户的订阅、推荐、收听历史等。
阿里巴巴的文章 还是面向 浏览器端 A/B测试:基本概念 A/B测试:实现方法
整体设计
- 基于配置中心做(一切皆配置), ab 的不同反应在 配置中心的不同配置值上,客户端无感知
-
客户端 有专门的 abtest sdk
- 服务端只是下发 ab 数据,由客户端自行 根据ab 数据选择动作
- 服务端 直接将策略(选A还是选B) 告诉客户端。也因此 客户端请求时 需要 携带 设备本身的大量信息。
代码实现
-
如何表示 一个abtest
- 页面上
- 数据存储上
-
如何表示一个abtest系统
- 代码组织上
- 系统运行上,哪些独立的运行进程,abtest 有哪些参与者,他们都会进行什么操作
- 系统结构上,访问层、存储层等
-
一个abtest 如何生效
- 服务端,对于接口
interface IHelloService{void hello();},实现类除实现hello方法外,提供helloA和helloB实现。运行时,拦截hello方法的执行,根据abtest 策略选择helloA/helloB 执行 - 客户端
- 基于配置中心做,同一个配置值,A/B用户对应的值不同。
- 客户端保有两份儿代码,abtest client sdk 根据本机的 设备信息 结合 下发的abtest 数据选择执行。阿里巴巴的方案 A/B测试:实现方法, 据猜测 新浪新闻客户端也应该是这个方案。
- 服务端,对于接口
数据统计
- 靠后台关联。ab 系统后台记录 打点日志,内容类似于 who when 拿到了 方案A/B 的响应,再与相关数据关联即可。
-
靠给设备 打tag。比如我根据 某个打点请求 来评估效果,那么假设该打点请求 总量是100个,打A标签的40个,打B标签的有60个,则说明B方案好。 tag(一些地方也叫bucketId)的来源有两种方式
- 客户端本地持有 用户画像数据,服务端返回AB 规则,客户端根据ab规则 + 画像数据 产生决策(用A还是用B),然后产生tag
- 由服务端决策 该客户端 使用A 还是B,除返回 A or B 策略数据外,一并返回 tag
- 客户端发送行为日志
用AB不靠AB
2018.10.22 补充
有一次跟产品闲聊,觉得他的思路挺好的。我以前想着,做了一个abtest, 然后有一个报表直接说这个abtest的情况。后来他说,其实应该是先有一个数据报表的基础设施,然后再有abtest,abtest 中的A B 只是给原有数据分析里加了一个维度。比如你原来就有一个请求的点击率报表,有了AB 之后,多了一个分析维度。而不是你为了ab,硬要做一个针对这个ab的报表。
abtest 对整个公司的基础设施依赖都很大,如果连数据可视化都做不到,效果对比就更无从谈起,ab系统做出来也难以让人信服。
同理心是地基,想象力是天空,中间是逻辑和工具。 我感觉这句话解决的是产品的发展方向如何判定的问题?
- 以数据为中心,哪个数据好用哪个方案
- 有一套想法,打算创造一个什么价值,然后以用户最容易接受的方式落地
我印象最深的一句话:抖音也是如此,想象全屏的视频让手机变成一扇窗户,你透过这个窗户看到一个丰富的世界,抖音是这个五彩斑斓世界的投影,感觉非常奇妙。如果没有想象力,你可能只会做出一款对口型的热门应用或者搞笑视频软件,抖音也不可能从一款炫酷的音乐舞蹈小众软件,演化成包容美丽风光、戏曲艺术、感人故事、生活消费的大众平台。
做不做靠想象力、同理心,不是靠ab。而怎么做可以用ab来解决细节问题。
AB测试只是一个工具而已,是测不出用户需求的,同理心才是重要的基础。如果没有同理心,做出的产品肯定没有灵魂,不能满足用户需求。但是光有同理心还不够,这样只能做出有用的产品。想要做出彩的产品,想象力非常重要。
很多时候,ab只是帮助我们理解用户,而不是帮助我们决策
如何扩大客户端abtest 的应用范围
客户端abtest 通常涉及到ui的变化,对于AB用户,常常有以下需求
- 一个按钮/tab 的文案、颜色不同,可以将这些信息作为一个配置,由配置中心统一负责
- 界面的构成完全不同
- 跳转行为不同,一般由跳转系统负责
- 弹屏内容不同,一般由统一弹屏系统负责
可以看到,abtest的应用不只是 abtest 本身,是与其它系统一起相互作用的。而类似配置中心、弹屏系统等客户端实现方案一般为
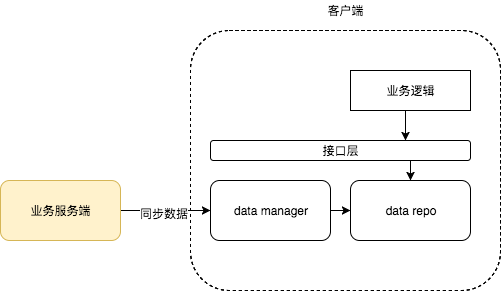
一般来说,既然业务系统数据 会以一定数据格式存在 客户端,此时,我们可以 更改 业务数据的 访问逻辑,先去abtest 中查询 特定 数据是否有abtest (持有了一份儿相同格式的业务数据),有则直接返回abtest 的数据,无则访问原业务数据。
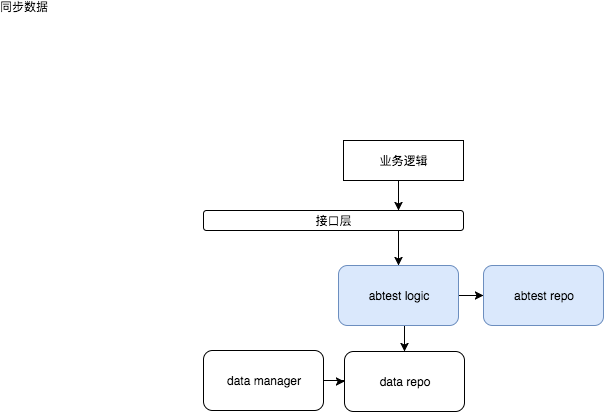
通过这种方式,我们可以将abtest 与客户端的各个业务系统 关联起来,实现不同的人有不同的ui、弹不同的屏、甚至运行不同的代码。
小结
从当下看,设计abtest 系统,其实最关键的 就是定义 abtest 系统的边界:是单纯的流量分割还是 夹带灰度下发,是单纯面向客户端还是 面向服务端,是全新开发还是依赖配置中心等组件来做。一个清晰地边界 非常重要。
精炼的说
- abtest 包括什么? 分流 + bucket/action
- 分流有哪些关键点?在客户端做还是服务端做
- bucket 有哪些关键点,在客户端做还是服务端做
留下评论