计算机组成原理
简介
本文主要来自极客时间《深入浅出计算机组成原理》,相关书籍《编码:隐匿在计算机软硬件背后的语言》
从电路开始讲计算机底层实现原理 有几个gif非常贴切。
- 门电路——信号的关联
- 加法器——信号的计算
- 时钟——信号的震荡
- RAM——保存信号
- 程序——自动化。控制单元该怎么实现呢?只要给定输入信号,约定输出信号,任何组件都可以造出来。PS:信号的流动
入门
一些比较有意思的表述:
- 存放在内存里的程序和数据,需要被 CPU 读取,CPU 计算完之后,还要把数据写回到内存。然而 CPU 不能直接插到内存上,反之亦然。于是,就带来了最后一个大件——主板。主板的芯片组(Chipset)和总线(Bus)解决了 CPU 和内存之间如何通信的问题。芯片组控制了数据传输的流转,也就是数据从哪里到哪里的问题。总线则是实际数据传输的高速公路。因此,总线速度(Bus Speed)决定了数据能传输得多快。
- 手机里只有 SD 卡(Secure Digital Memory Card)这样类似硬盘功能的存储卡插槽,并没有内存插槽、CPU 插槽这些东西。没错,因为手机尺寸的原因,手机制造商们选择把 CPU、内存、网络通信,乃至摄像头芯片,都封装到一个芯片,然后再嵌入到手机主板上。这种方式叫 SoC,也就是 System on a Chip(系统芯片)。
- 冯·诺依曼体系结构(Von Neumann architecture),也叫存储程序计算机。
- 可编程。计算机是由各种门电路组合而成的,然后通过组装出一个固定的电路板,来完成一个特定的计算程序。一旦需要修改功能,就要重新组装电路。这样的话,计算机就是“不可编程”的。计算器的本质是一个不可编程的计算机
- 存储。一个计算机程序,不可能只有一条指令,而是由成千上万条指令组成的。但是 CPU 里不能一直放着所有指令,所以计算机程序平时是存储在存储器中的。程序本身是存储在计算机的内存里,可以通过加载不同的程序来解决不同的问题。
任何一台计算机的任何一个部件都可以归到运算器、控制器、存储器、输入设备和输出设备中,而所有的现代计算机也都是基于这个基础架构来设计开发的。具体来说,学习组成原理,其实就是学习控制器、运算器、内存的工作原理。PS:这就叫框定了模型
电报是现代计算机的一个最简单的原型
制造一台电报机非常容易。电报机本质上就是一个“蜂鸣器 + 长长的电线 + 按钮开关”。蜂鸣器装在接收方手里,开关留在发送方手里。双方用长长的电线连在一起。当按钮开关按下的时候,电线的电路接通了,蜂鸣器就会响。短促地按下,就是一个短促的点信号;按的时间稍微长一些,就是一个稍长的划信号。有了电报机,只要铺设好电报线路,就可以传输我们需要的讯息了。
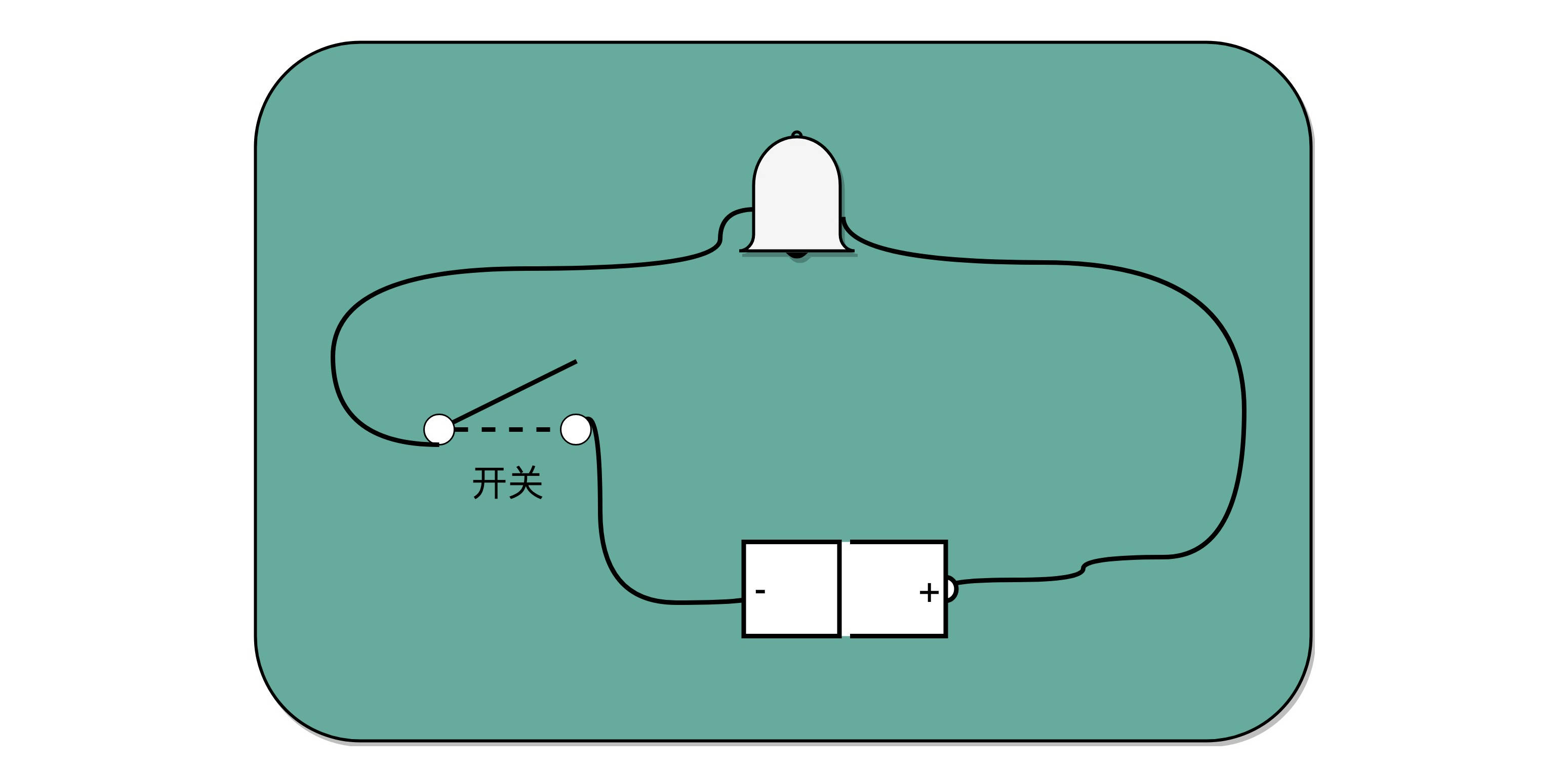
虽然一个按钮开关的电报机很“容易”操作,但是却不“方便”操作。因为电报员要熟记每一个字母对应的摩尔斯电码,并且需要快速按键来进行输入,一旦输错很难纠正。但是,因为电路之间可以通过与、或、非组合完成更复杂的功能,我们完全可以设计一个和打字机一样的电报机,每按下一个字母按钮,就会接通一部分电路,然后把这个字母的摩尔斯电码输出出去。
cpu 四大基本电路
CPU 也可以想象成我们熟悉的软件,一样能抽象成几大模块,然后再进行模块化开发。其实 CPU 其实就是一些简单的门电路像搭积木一样搭出来的。从最简单的门电路,搭建成半加器、全加器,然后再搭建成完整功能的 ALU。这些电路里呢,有完成各种实际计算功能的组合逻辑电路,也有用来控制数据访问,创建出寄存器和内存的时序逻辑电路。
- 组合逻辑电路。ALU 的功能就是在特定的输入下,没有状态的,根据组合电路的逻辑,生成特定的输出。
- 锁存器和 D 触发器电路。我们需要有一个电路,能够存储到上一次的计算结果。这个计算结果并不一定要立刻拿到电路的下游去使用,但是可以在需要的时候拿出来用。这也是现代计算机体系结构中的“冯·诺伊曼”机的一个关键,就是程序需要可以“存储”,而不是靠固定的线路连接或者手工拨动开关,来实现计算机的可存储和可编程的功能。
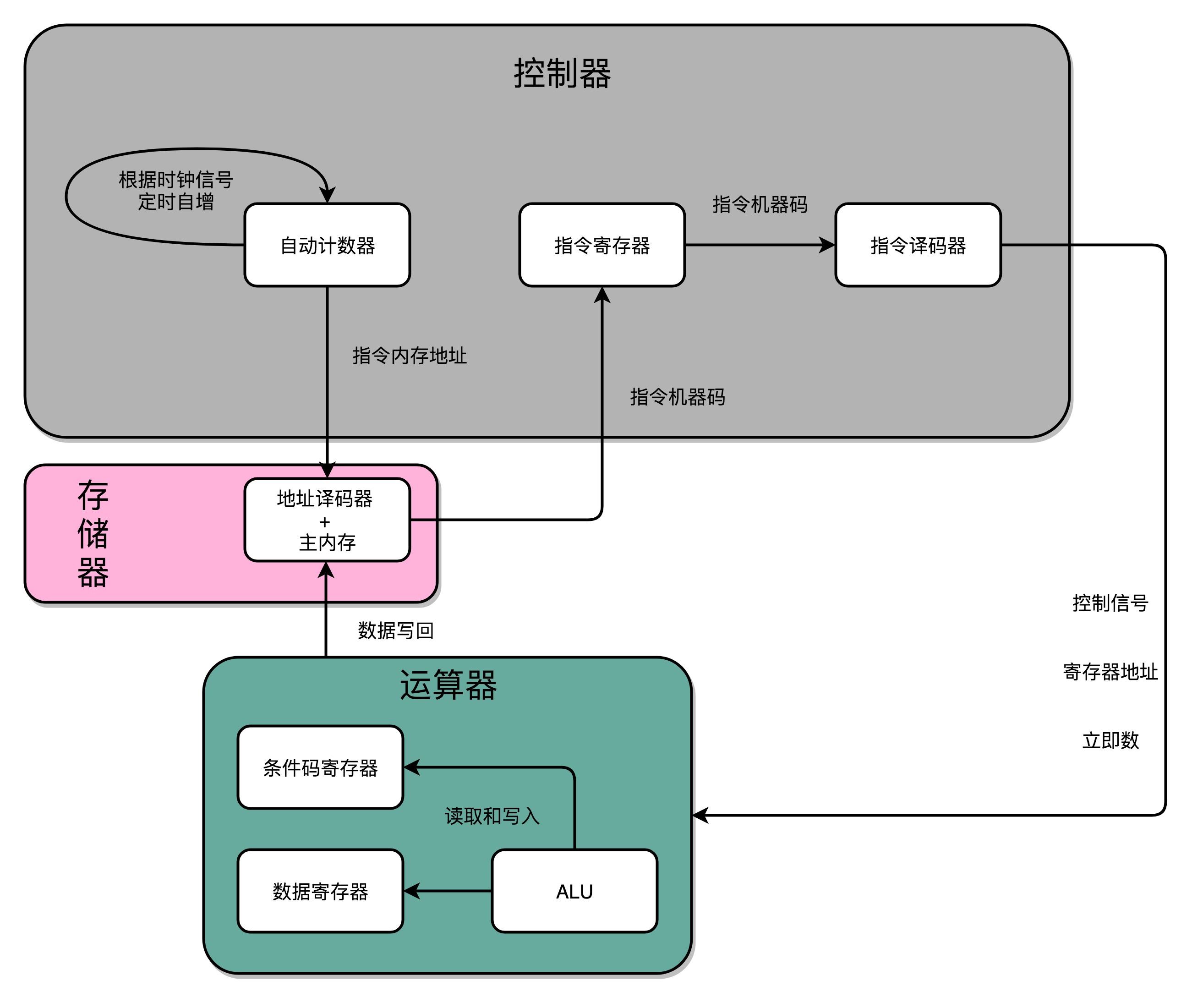
- 计数器电路。需要有一个“自动”的电路,按照固定的周期,不停地实现 PC 寄存器自增,自动地去执行“取指令 - 指令译码 - 执行指令“的步骤。我们的程序执行,并不是靠人去拨动开关来执行指令的。我们希望有一个“自动”的电路,不停地去一条条执行指令。
- 译码器电路。我们需要有一个“译码”的电路。无论是对于指令进行 decode,还是对于拿到的内存地址去获取对应的数据或者指令,我们都需要通过一个电路找到对应的数据。
把这四类电路,通过各种方式组合在一起,就能最终组成功能强大的 CPU 了。我们通过一个自动计数器的电路,来实现一个PC寄存器,不断生成下一条要执行的计算机指令的内存地址,然后通过地址译码器,从内存里读出对应的指令,写入到D触发器实现的指令寄存器中,再通过另外一个指令译码器,把它解析成我们需要执行的指令和操作数的地址,这些就是计算器中的控制器。我们把opcode和对应的操作数,发送给ALU进行计算,得到计算结果,再写回到寄存器以及内存里,这就是运算器。时钟信号,则提供了协调这样一条条指令的执行时间和先后顺序的机制。PS:每一个电路又都是几个基本电路的组合,比如 基本电路>门电路>全加器>加法器
在最简单的情况下,我们需要让每一条指令,从程序计数,到获取指令、执行指令,都在一个时钟周期内完成。如果 PC 寄存器自增地太快,程序就会出错。因为前一次的运算结果还没有写回到对应的寄存器里面的时候,后面一条指令已经开始读取里面的数据来做下一次计算了。这个时候,如果我们的指令使用同样的寄存器,前一条指令的计算就会没有效果,计算结果就错了。在这种设计下,我们需要在一个时钟周期里,确保执行完一条最复杂的 CPU 指令,也就是耗时最长的一条 CPU 指令。这样的 CPU 设计,我们称之为单指令周期处理器(Single Cycle Processor)。
基本电路的基本电路
开关 A,一开始是断开的,由我们手工控制;另外一个开关 B,一开始是合上的,磁性线圈对准一开始就合上的开关 B。于是,一旦我们合上开关 A,磁性线圈就会通电,产生磁性,开关 B 就会从合上变成断开。一旦这个开关断开了,电路就中断了,磁性线圈就失去了磁性。于是,开关 B 又会弹回到合上的状态。
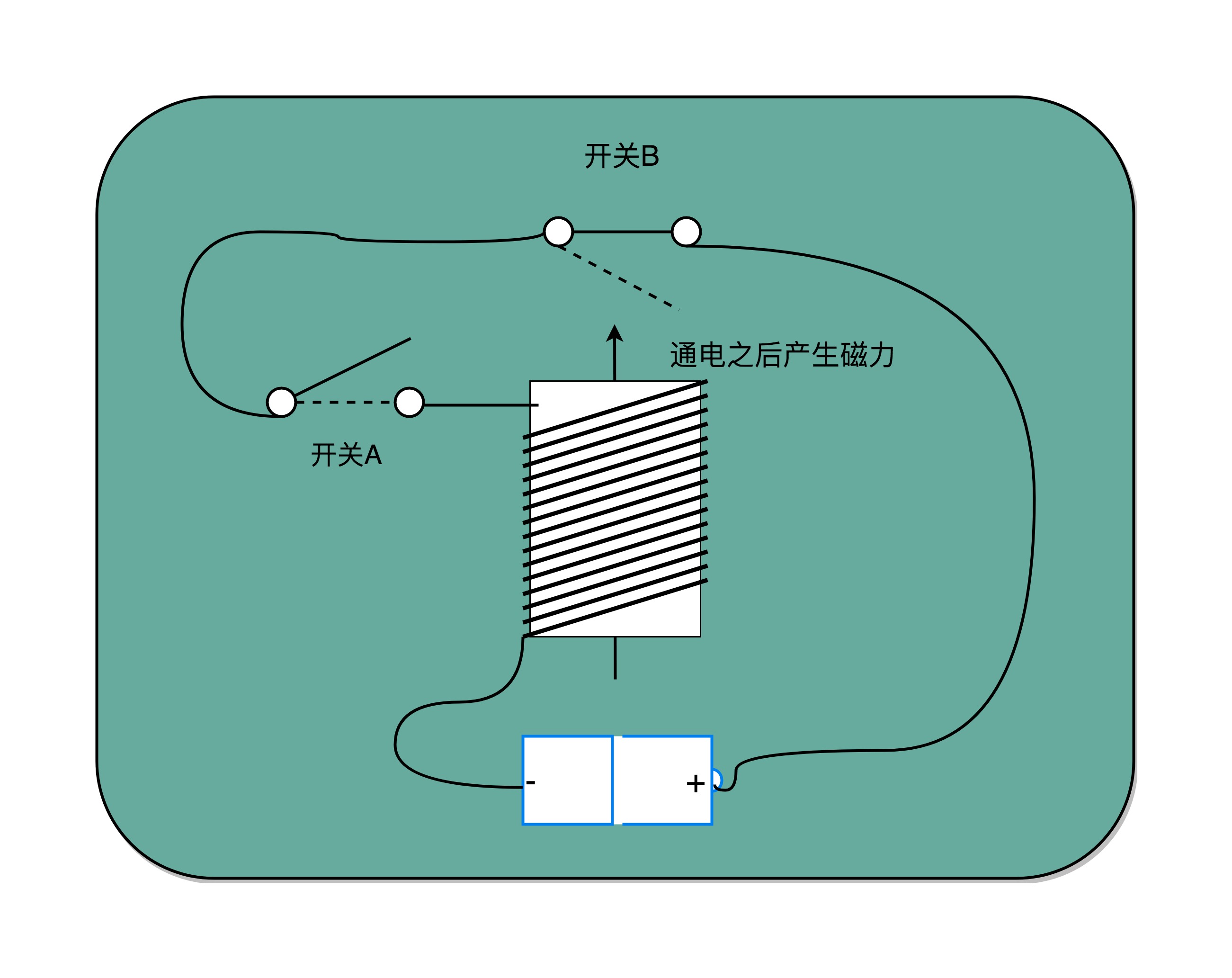
开关 A 闭合(也就是相当于接通电路之后),开关 B 就会不停地在开和关之间切换,这个不断切换的过程,对于下游电路来说,就是不断地产生新的 0 和 1 这样的信号。如果你在下游的电路上接上一个灯泡,就会发现这个灯泡在亮和暗之间不停切换。
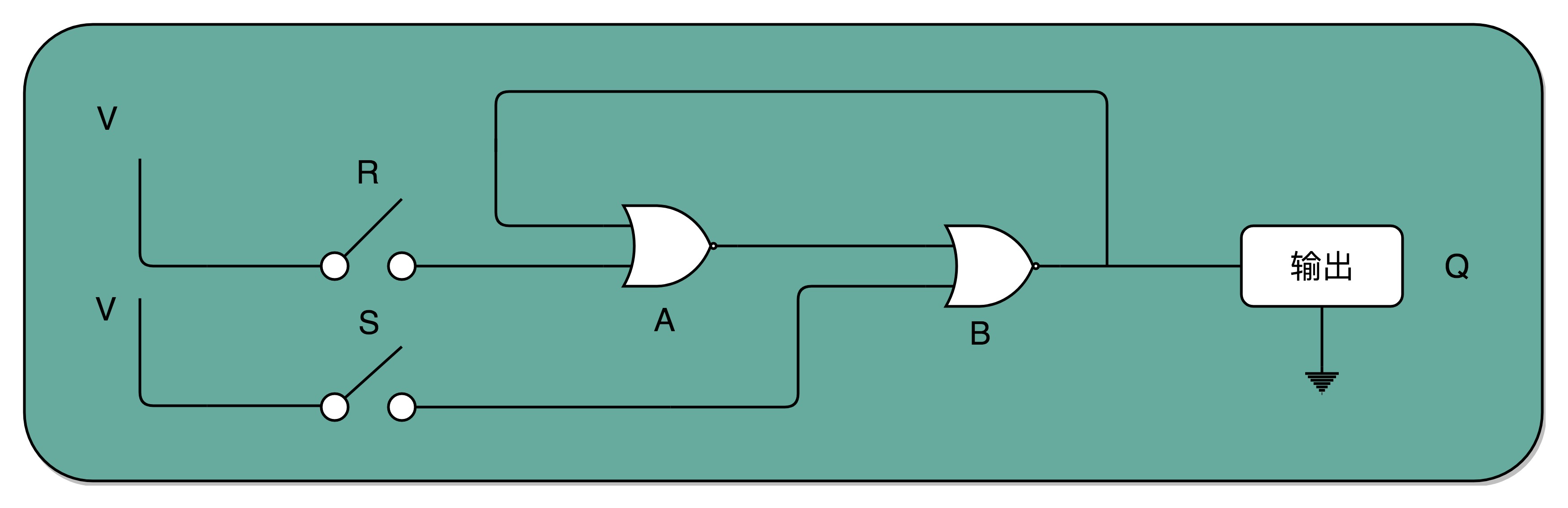
R-S 触发器
- 接通开关 R,输出变为 1,即使断开开关,输出还是 1 不变。
- 接通开关 S,输出变为 0,即使断开开关,输出也还是 0。 也就是,当两个开关都断开的时候,最终的输出结果,取决于之前动作的输出结果,这个也就是我们说的记忆功能。PS: 所谓记忆电路,就是电路会持续输出电路上一次改动的输出结果(毕竟输出重新作为了输入) CPU 的工作原理是什么?
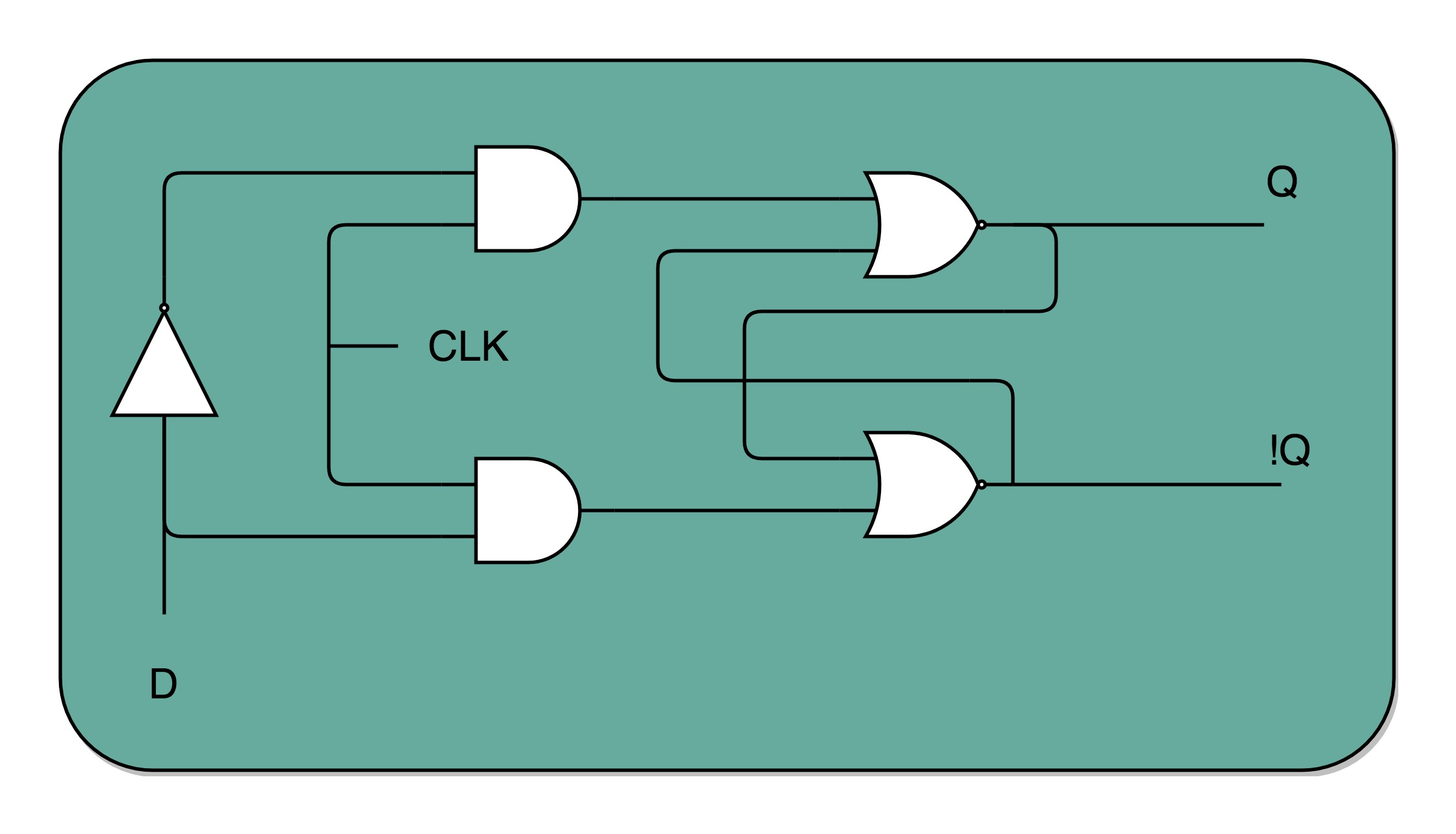
电路竟然具备存储信息的能力了。现在为保存信息你需要同时设置S端和R端,但你的输入是有一个(存储一个bit位嘛),当D为0时,整个电路保存的就是0,否则就是1。
在R-S 触发器电路里加两个与门和一个小小的时钟信号,我们就可以实现一个利用时钟信号来操作一个电路了。这个电路可以帮我们实现什么时候可以往 Q 里写入数据。当时钟信号 CLK 在低电平的时候,与门的输入里有一个 0,两个实际的 R 和 S 后的与门的输出必然是 0。也就是说,无论我们怎么按 R 和 S 的开关,根据 R-S 触发器的真值表,对应的 Q 的输出都不会发生变化。PS:时钟信号和你真正要写入的信号求与,可以让你的输入信号都是0。 时序电路。
一个 D 型触发器,只能控制 1 个比特的读写,但是如果我们同时拿出多个 D 型触发器并列在一起,并且把用同一个 CLK 信号控制作为所有 D 型触发器的开关,这就变成了一个 N 位的 D 型触发器,也就可以同时控制 N 位的读写。
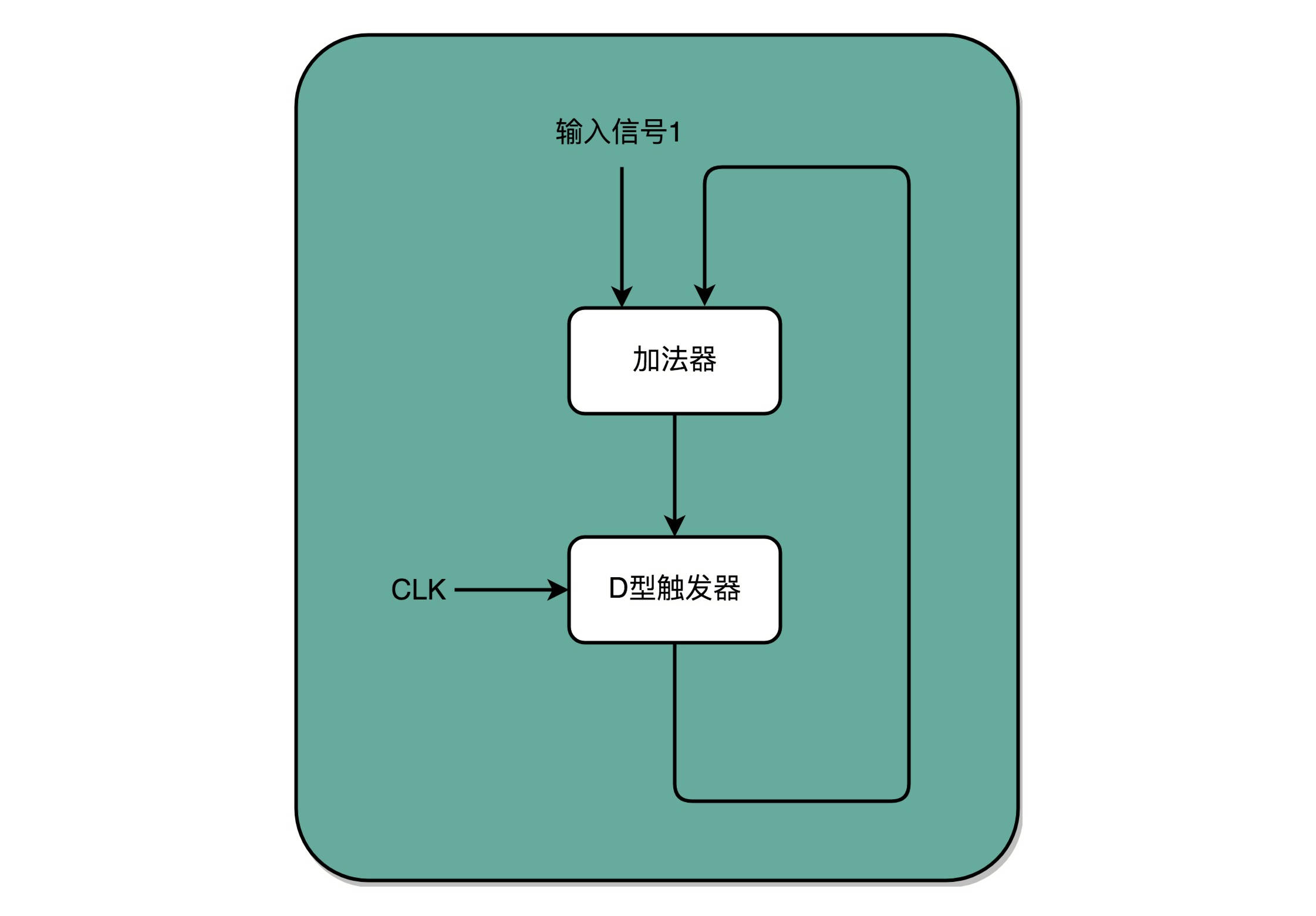
有了时钟信号,我们可以提供定时的输入;有了 D 型触发器,我们可以在时钟信号控制的时间点写入数据。加法器的两个输入,一个始终设置成 1,另外一个来自于一个 D 型触发器 A。我们把加法器的输出结果,写到这个 D 型触发器 A 里面。于是,D 型触发器里面的数据就会在固定的时钟信号为 1 的时候更新一次。这样,我们就有了一个每过一个时钟周期,就能固定自增 1 的自动计数器了。这个自动计数器,可以拿来当我们的 PC 寄存器。每次自增之后,我们可以去对应的 D 型触发器里面取值,这也是我们下一条需要运行指令的地址。
读写数据所需要的译码器:现在,我们的数据能够存储在 D 型触发器里了。如果我们把很多个 D 型触发器放在一起,就可以形成一块很大的存储空间,甚至可以当成一块内存来用。那我们怎么才能知道,写入和读取的数据,是在这么大的内存的哪几个比特呢?
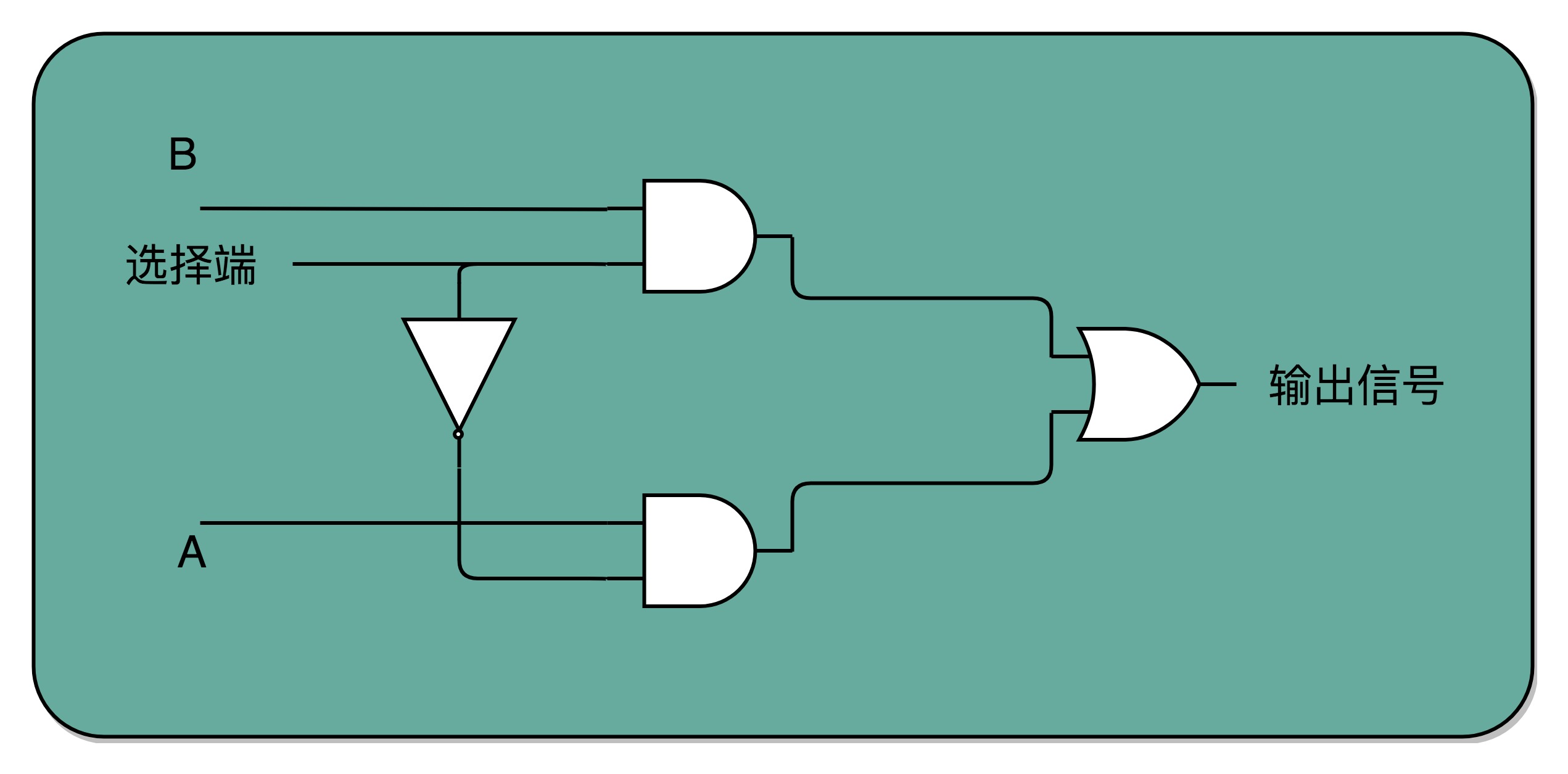
如果把“寻址”这件事情退化到最简单的情况,就是在两个地址中,去选择一个地址。我们通过一个反相器、两个与门和一个或门,就可以实现一个 2-1 选择器。通过控制反相器的输入是 0 还是 1,能够决定对应的输出信号,是和地址 A,还是地址 B 的输入信号一致。PS:这个2-1选择器打个比方就是,如果AB 两根线都通电/想数据输出,我可以通过“一根线” 决定让AB 哪根线出去。一个byte 8根线,则需要3根线即可决定谁“输出”。3根线是8根线的开关,它的值可以视为一个地址,而不是真的是一个“物理地址”。按地址取数据不是数据的搬运,是电流的组合的结果。
总结:
- 01输入经过门电路可以转换为输出,输出可以作为另一个门电路的输入
- 门电路的组合(与或非异或等) 有以下可能
- 输入 单纯的是 逻辑算术运算的 “因子”
- 时钟的01输入 与常规01输入求与 可以使得01输入有效或无效,或者说让输入有“节奏”
- 上一次输出原样作为电路的一部分输入,可以产生“记忆”的效果
- 某个输入可以让其它输入有效或无效,即起到选择作用
在我们的想象中,物理机机器内部似乎要维护一张大而全的指令集表,每次cpu 读入一个机器指令时,去扫描这张指令集表,从而识别机器码,并进一步判断该操作码后是否有操作数。而事实上,cpu 内置的“指令集” 是硬件结构/数字电路。只要向cpu 传递一个指令,cpu 便可以根据预先设定好的电路进行解码(高低电平),然后操作对应的寄存器或者某些电路 去读取该操作码后面的操作数。同时,另一些电路支持读取当前机器指令的下一条指令。 如此一来,cpu 便能完成取指 ==> 译码 ==> 执行 ==> 取指的循环了。PS:从内存中取数 可以认为是 让 所有的 存储电路有选择的输出,内存地址每一根线即开关。那么译码(地址+时钟)也可以认为 让所有电路有选择的 触发,指令代码的每一位即开关。
硬件描述语言
在芯片设计时,根据不同模块的功能特点,通常把它们分为数字电路模块和模拟电路模块。模拟电路还是像早期的半导体电路那样,处理的是连续变化的模拟信号,所以只能用传统的电路设计方法。而数字电路处理的是已经量化的数字信号,往往用来实现特定的逻辑功能,更容易被抽象化,所以就产生了专门用于设计数字电路的硬件描述语言。没错,芯片前端设计工程师写 Verilog 代码的目的,就是把一份电路用代码的形式表示出来,然后由计算机把代码转换为所对应的逻辑电路。
写软件代码和写硬件代码的最大区别是什么?Verilog 代码和 C 语言、Java 等这些计算机编程语言有本质的不同,在可综合(这里的“可综合”和代码“编译”的意思差不多)的 Verilog 代码里,基本所有写出来的东西都对应着实际的电路。所以,我们用 Verilog 的时候,必须理解每条语句实质上对应着什么电路,并且要从电路的角度来思考它为何要这样设计。而高级编程语言通常只要功能实现就行。在 Verilog 里举几个例子来说明:
- 声明变量的时候,如果指定是一个 reg,那么这个变量就有寄存数值的功能,可以综合出来一个实际的寄存器;
- 如果指定是一段 wire,那么它就只能传递数据,只是表示一条线。
- 写一个判断语句,可能就对应了一个 MUX(数据选择器)
- 写一个 for 可能就是把一段电路重复好几遍。
在开始一个大的芯片设计时,往往需要先从整个芯片系统做好规划,在写具体的 Verilog 代码之前,把系统划分成几个大的基本的功能模块。之后,每个功能模块再按一定的规则,划分出下一个层次的基本单元。Verilog 都是基于模块进行编写的,一个模块实现一个基本功能,大部分的 Verilog 逻辑语句都放在模块内部。
一个包含加、减、与、或、非等功能的简单 ALU 模块
module alu(a, b, cin, sel, y);
input [7:0] a, b;
input cin;
input [3:0] sel;
output [7:0] y;
reg [7:0] y;
reg [7:0] arithval;
reg [7:0] logicval;
// 算术执行单元
always @(a or b or cin or sel) begin
case (sel[2:0])
3'b000 : arithval = a;
3'b001 : arithval = a + 1;
3'b010 : arithval = a - 1;
3'b011 : arithval = b;
3'b100 : arithval = b + 1;
3'b101 : arithval = b - 1;
3'b110 : arithval = a + b;
default : arithval = a + b + cin;
endcase
end
// 逻辑处理单元
always @(a or b or sel) begin
case (sel[2:0])
3'b000 : logicval = ~a;
3'b001 : logicval = ~b;
3'b010 : logicval = a & b;
3'b011 : logicval = a | b;
3'b100 : logicval = ~((a & b));
3'b101 : logicval = ~((a | b));
3'b110 : logicval = a ^ b;
default : logicval = ~(a ^ b);
endcase
end
// 输出选择单元
always @(arithval or logicval or sel) begin
case (sel[3])
1'b0 : y = arithval;
default : y = logicval;
endcase
end
endmodule
通过逻辑综合,我们就能完成从 Verilog 代码到门级电路的转换。而逻辑综合的结果,就是把设计的 Verilog 代码,翻译成门级网表 Netlist。逻辑综合需要基于特定的综合库,不同的库中,门电路基本标准单元(Standard Cell)的面积、时序参数是不一样的。所以,选用的综合库不一样,综合出来的电路在时序、面积上也不同。因此,哪怕采用同样的设计,选用台湾的台积电(TSMC)工艺和上海的中芯国际(SMIC)的工艺,最后生产出来的芯片性能也是有差异的。通常,工业界使用的逻辑综合工具有 Synopsys 的 Design Compiler(DC),Cadence 的 RTL Compiler,Synplicity 的 Synplify 等。然而,这些 EDA 工具都被国外垄断了,且需要收取高昂的授权费用。学习用途 可以使用轻量级开源综合工具Yosys
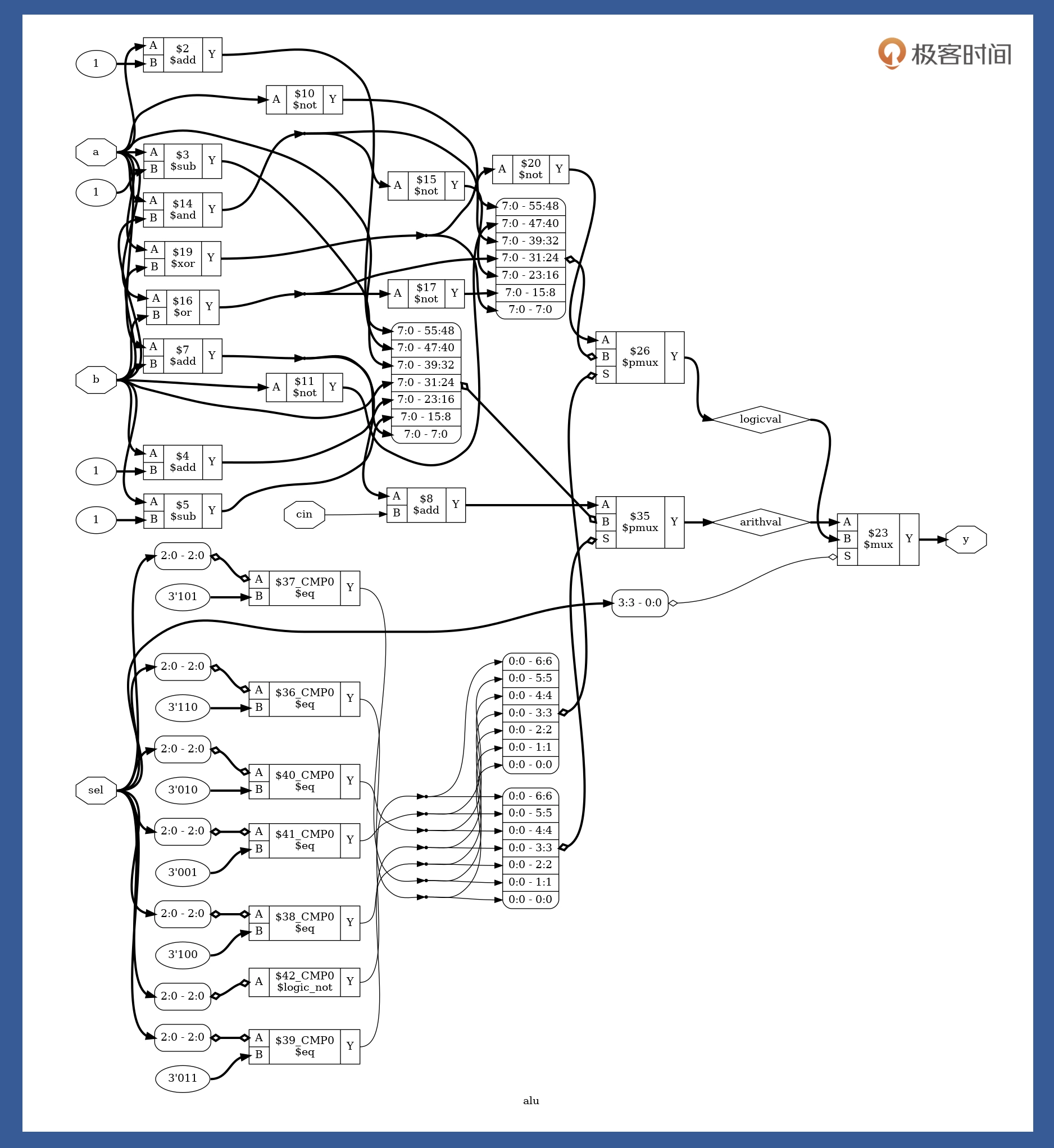
可以看到,这张图是由基本的 and、or、not、add、sub、cmp、mux 等电路单元组成。如果你还想进一步了解它们底层电路结构,可以自行查阅大学里学过的《数电》《模电》。
整体思路:cpu ==> 模块 == 硬件描述语言 ==> 基本电路单元 ==> 门电路
CPU怎么识别我们写的代码?
CPU怎么识别我们写的代码?啥叫半导体?半导体其实就是介于导体和绝缘体中间的一种东西。
假设你有8位加法器了,也有一个位移1位(乘2)的模块了。串起来你就能算(A+B)×2了。要是想算A×2+B呢?简单,你把加法器模块和位移模块的接线改一下就行了,改成输入A先过位移模块,再进加法器就可以了。改个程序还得重新接线?你以为呢?实际上,编程就是把线来回插啊。早期的计算机就是这样编程的,而且插线是个细致且需要耐心的工作,所以那个时候的程序员都是清一色的漂亮女孩子,穿制服的那种。
插线也是个累死人的工作。所以我们需要改进一下,让CPU可以根据指令来相加或者乘2。这里再引入两个模块
- flip-flop,简称FF,中文好像叫触发器,这个模块的作用是存储1bit数据。我们用FF来保存计算的中间数据(也可以是中间状态或者别的什么),1bit肯定是不够的,不过我们可以并联嘛,用4个或者8个来保存4位或者8位数据。这种我们称之为寄存器(Register)。
- MUX,中文叫选择器,input: sel,I0,I1。 sel=0 则输出I0,sel=1 则输出I1。当然选择器可以做的很长,比如四进一出。
有这个东西我们就可以给加法器和乘2模块(位移)设计一个激活针脚。这个激活针脚输入1则激活这个模块,输入0则不激活。这样我们就可以控制数据是流入加法器还是位移模块了。于是我们给CPU先设计8个输入针脚,4位指令,4位数据。我们再设计3个指令:
- 0100,数据读入寄存器
- 0001,数据与寄存器相加,结果保存到寄存器
- 0010,寄存器数据向左位移一位(乘2)
分别用指令输入的第二第三第四个针脚连接寄存器,加法器和位移器的激活针脚。这样我们输入0100这个指令的时候,寄存器输入被激活,其他模块都是0没有激活,数据就存入寄存器了。同理,如果我们输入0001这个指令,则加法器开始工作,我们就可以执行相加这个操作了。
这里就可以简单回答:CPU是为什么能看懂这些二级制的数呢?为什么CPU能看懂,因为CPU里面的线就是这么接的呗。你输入一个二进制数,就像开关一样激活CPU里面若干个指定的模块以及改变这些模块的连通方式,最终得出结果。
- CPU里面可能有成千上万个小模块,一个32位/64位的指令能控制那么多吗?我们举例子的CPU里面只有3个模块,就直接接了。真正的CPU里会有一个解码器(decoder),把指令翻译成需要的形式。
- 举例子的简单CPU,如果我输入指令0011会怎么样?当然是同时激活了加法器和位移器从而产生不可预料的后果,简单的说因为你使用了没有设计的指令,所以后果自负。在真正的CPU上这么干大概率就是崩溃,不过肯定会有各种保护性的设计。
- 你设计的指令【0001,数据与寄存器相加,结果保存到寄存器】这个一步做不出来吧?毕竟还有一个回写的过程,实际上确实是这样。我们设计的简易CPU执行一个指令差不多得三步,读取指令,执行指令,写寄存器。经典的RISC设计则是分5步:读取指令(IF),解码指令(ID),执行指令(EX),内存操作(MEM),写寄存器(WB)。我们平常用的x86的CPU有的指令可能要分将近20个步骤。那CPU怎么知道自己走到哪一步了呢?具体的设计涉及到FSM(finite-state machine),也就是有限状态机理论,以及怎么用FF实装。
现在我们有3个指令了。我们来试试算个(1+4)X2+3吧。
- 0100 0001 ;寄存器存入1
- 0001 0100 ;寄存器的数字加4
- 0010 0000 ;乘2
- 0001 0011 ;再加三
题外话:栈是一种数据结构,跟CPU无关。只不过栈这个数据结构实在太常用了,以至于CPU会针对性的进行优化。给CPU再加一个寄存器SP,并定义两个指令:一个PUSH,一个POP。动作分别是把数据写入SP的地址,然后SP=SP+1,POP的话反过来。这样有什么好处呢?好处在于PUSH/POP这样的指令消耗特别少,速度特别快。而栈这种数据结构在各种程序里用的又特别频繁,设计成专用的指令则可以很大程度上提升效率。
其它
- 晶体管可以实现 AND、OR、NOT
- 给定足够的AND、OR以及NOT门,就可以实现任何一个逻辑函数,{AND、OR、NOT}就是逻辑完备的
- 一个与门和一个异或门就可以实现二进制加法,有了加法任何算术运算就ok了
- 两个NAND门的组合可以实现记忆一个bit的效果(NAND由与或非门组合而成) ==> 电路有了记忆能力 ==> 寄存器和内存就出来了。
cpu空闲的时候在干嘛?内核设计者创建了一个叫做空闲任务的进程,在 Linux 下就是第 0号进程。当其它进程都处于不可运行状态时,调度器就从队列中取出空闲进程运行,显然,空闲进程永远处于就绪状态,且优先级最低,空闲进程是一个不断执行 halt 指令的循环。 这条指令会让部分CPU进入休眠状态,从而极大减少对电力的消耗,通常这条指令也被放到循环中执行。halt 指令是特权指令,也就是说只有在内核态下 CPU 才可以执行这条指令,程序员写的应用都运行在用户态,因此你没有办法在用户态让 CPU 去执行这条指令。
《编程高手必学的内存知识》
- 组合逻辑电路是指,输出仅由输入信号的状态决定的电路。而时序逻辑电路是指,电路的输出值同时依赖于电路过去的状态和现在的输入,所以时序逻辑电路中含有用于记忆电路状态的存储单元。
- 寄存器的存储单元:RS 锁存器 ==> D 锁存器 ==> D 触发器
- RAM 大体上分为两类:静态随机访问存储器(Static RAM, SRAM)和动态随机访问存储器(Dynamic RAM,DRAM)。
- SRAM 存储单元的特点是使用 6 个晶体管来实现。其中两个 P 型 MOS 管和两个 N 型 MOS 管组成两个反相器用于存储信息。还有两个用于控制存储单元是否选通。
- DRAM 的存储单元使用一个 MOS 管和一个电容实现。DRAM 因为有电容的存在,不再是单纯的逻辑电路。 DRAM电路相比 SRAM 更加简单,也就更容易大规模集成,成本也更低,但是它的读取速度比较慢。
- 存储器在存储数据时,一定要区分数据是要存在哪个地方的,也就是说,我们要想办法对存储器里的各个单元进行编码,并且能将地址总线的数据转换成相应存储单元的使能信号,然后进一步区分控制总线的读写信号。如果是读操作,存储控制器就要将存储单元内的值读入数据总线,如果是写操作,控制器就应该把数据总线的数据写入存储单元。现在的核心问题在于,控制器如何对地址信号进行转换,使得目标字节的字线变成高电压?这个工作需要译码器来完成。
留下评论