Spark Stream 学习
前言
借用前文 Spark 泛谈 的小结:java8 Stream 和 rdd 本质都是 Builder 模式。在build 模式中,调用setxxx 都是铺垫,最后build()(类似于spark rdd的行动操作)才是来真的。但Builder 模式 + 更高维度的抽象,加上函数式编程(setxxx 时可传入方法)的助力,便真让人眼前一亮了。
spark 全家桶
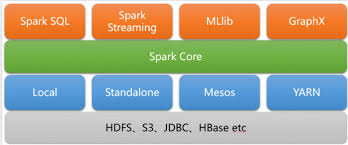
基于spark 通常从以下几个方向进行了扩展
- 支持更丰富的数据源,比如spark sql 支持半结构化/结构化的数据源,spark stream 支持流式数据
- 提供 针对性的 rdd 抽象
- 针对特定数据,提供相应的便捷接口
| context | rdd | |
|---|---|---|
| spark core | SparkContext | rdd |
| spark sql | HiveContext/SqlContext | SchemaRDD/DataFrame |
| spark stream | SreamingContext | DStream |
spark sql
spark 常规处理的是 非结构化文件,比如文本文件,RDD 的value 可以是任意类型。Spark SQL是一个支持结构化/半结构化数据处理的Spark模块。
多了结构化信息,带来以下不同:
-
spark sql 便推出了SchemaRDD/DataFrame抽象,提供更多的对外接口
df.filter(df['type'] == 'basic').select('name', 'type').show(),df 作为SchemaRDD/DataFrame, 拥有df['type'] == 'basic'、select 这些接口df.registerTempTable('courses'); coursesRDD = sqlContext.sql("SELECT name FROM courses WHERE length >= 5 and length <= 10")在连接查询等场景下,相对第一种方式,sql 查询表述起来更简洁
- 因为知道 每个列的类型信息,比如spark sql 使用 列式存储格式 在内存中缓存rdd数据。
- spark sql 背靠半结构化/结构化 文件 数据源,作为jdbc 服务器,对外提供sql 查询
spark stream
Spark 实战,第 1 部分 使用 Scala 语言开发 Spark 应用程序
相关概念
spark stream 是微批处理。
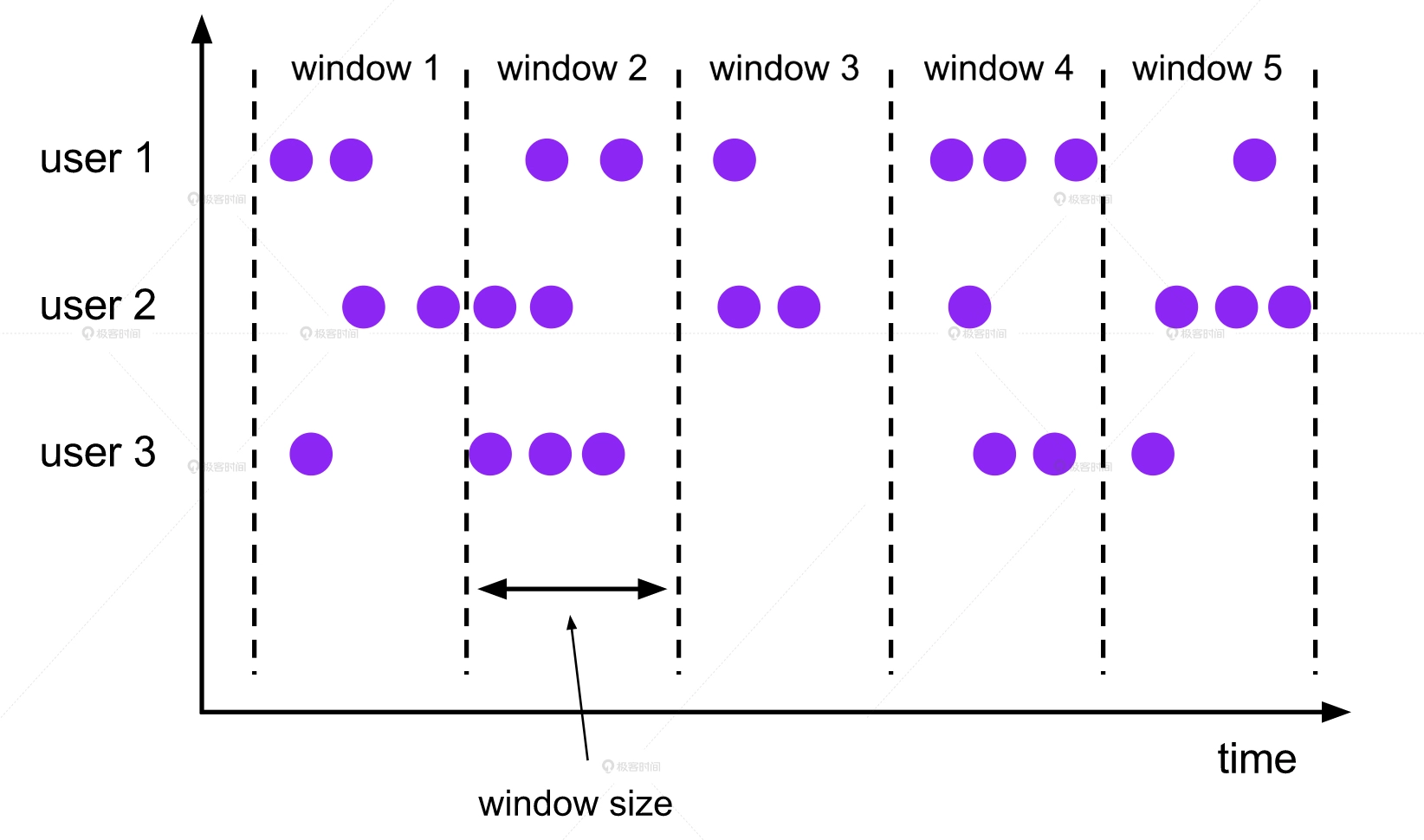
比如图 4 中的数据流就被分割成了 5 个时间窗口,每个窗口的长度假设是 5 分钟,这意味着每积攒够 5 分钟的数据,就会把缓存在内存中的这 5 分钟数据进行一次批处理。除了上面例子中的固定窗口以外,Flink 还提供了多种不同的窗口类型,滑动窗口(Sliding Window)也是我们经常会用到的。滑动窗口的特点是在两个窗口之间留有重叠的部分,在移动窗口的时候,不是移动 window size 这个长度,而是移动 window slide 这个长度,window slide 的长度要小于 window size。因此,窗口内部的数据不仅包含了数据流中新进入的 window slide 长度的数据,还包含了上一个窗口的老数据,这部分数据的长度是 window size-window slide。那滑动窗口这种方式有什么用呢?它最典型的用处就是做一些数据的 JOIN 操作。比如我们往往需要通过 JOIN 连接一个物品的曝光数据和点击数据,以此来计算 CTR,但是你要知道,曝光数据肯定是在点击数据之前到达 的。
-
推出了DStream(discretized stream) 抽象. DStream 描述了
- 无状态操作:每个rdd 要做哪些转化
- 有状态操作:一批rdd(一个窗口) 要做哪些合并
- 其它:一个Dtream转化为另一个特定的DStream
-
驱动程序 按照 设定的时间间隔,从输入源收集数据并保存为rdd,按照DStream 设定的“执行计划” 读取、处理和输出
实现原理
流式处理 意味着项目 都是long-live,而spark 数据 大量缓存中内存中,因此spark stream 引入了checkpoint 机制。
Executor 中不仅运行 job 的task(计算rdd.map(f1).fitler(f2)),还可以运行“接收器”。是不是可以这样讲?在分布式部署模式下, 驱动器代码 负责调度 Schedule,一般不负责直接 参与到 job中(从各种数据源读取文件、处理、写数据到文件)
流处理平台是对数据流进行直接处理,它没有办法进行长时间段的历史数据的全量处理,这就让流处理平台无法应用在历史特征的提取,模型的训练样本生成这样非常重要的领域。比如,我们在流处理中可以很方便地计算出点击量、曝光量这类方便累计的指标,但如果遇到比较复杂的特征,像是用户过去一个月的平均访问时长,用户观看视频的进度百分比等等,这些指标就很难在流处理中计算得到了。这是因为计算这类特征所需的数据时间跨度大,计算复杂,流处理难以实现。
spark stream 和storm
JStorm概叙 & 应用场景 中有一句话:
- 从应用的角度,JStorm应用是一种遵守某种编程规范的分布式应用。
- 从系统角度, JStorm是一套类似MapReduce的调度系统。
- 从数据的角度,JStorm是一套基于流水线的消息处理机制。
如果用这个 描述结构 去描述spark 或 spark stream,以分布式应用系统的高度来归纳整理(分布式应用系统共同点、不同点、常见套路等),参见分布式系统小结, 或许会比较有感觉。
spark streaming 使用“微批次”的架构,把流式计算 当做一系列的小规模 批处理来对待。
- spark,数据流进来,根据时间分隔成一小段,一小段做处理1、处理2、处理3。每小段的处理 还是按 spark rdd 的套路来。
- storm,一个消息进来,一个消息做处理1、处理2、处理3
rdd 采用函数式的方式 编写处理逻辑,spark scheduler 分发这个逻辑到各个节点。不准确的说,如果不涉及到分区操作的话,估计一个rdd 对应的工作(也就是数据的所有处理) 都是在一个节点完成的。
storm 其实更像 mapreduce(storm 作者讲述storm历史的时候,直接说storm 是 the hadoop of realtime),其提供的 topology= spout+ bolt,不准确的说,一个spout和 bolt 都对应一个节点,storm 负责将它们串联起来。 这也是storm 为什么 会用到 消息队列的 重要原因。 虽然spark 也涉及到 数据的序列化及节点间 传输
spark stream 和 flink(未完成)
小结
笔者最近为了一个系统的重构,连续粗略学习了spark、stream等,对分布式系统有以下几点感觉:
-
我们平时做的 http request ==> business server ==> rpc server ==> db/redis 等也是分布式系统,也实现了跨主机进程之间的协作,但是和spark/storm 等有所不同
- hadoop 和 spark 将分布式系统 抽出了 资源管理 + 计算调度 二维结构。一般业务开发用不上,或者说是高度耦合的。
- 写hadoop 程序,你得写mapper/reducer ,再写一个main 方法整合 mapper/reducer 。spark 提供了 rdd 抽象,所以main 方法的逻辑就是 读取输入为rdd,处理rdd,rdd 输出。
- 跨主机的数据交流,spark 直接跨主机内存到内存(所以spark 有数据序列化问题),mapreduce 是 hdfs(也就是跨主机磁盘到磁盘),业务系统是rpc/http/jdbc等
- 跨主机的进程协作,粗略的说,spark 和 mapreduce 的Scheduler 和 Executor 进程 通过zk 沟通,并不直接沟通。
http request ==> business server ==> rpc server ==> db/redis通过rpc 直接沟通 - 旁路系统,这个spark 和业务系统 都没有。当然,日志报警系统等算是一个旁路系统,只是我们在讲某一个业务架构时,通常不谈日志报警系统等。
- 容错。spark hadoop 都有Scheduler,对失败的任务进行重算等。业务系统就是某个节点挂了就挂了
- 部署方式,spark/hadoop 是直接部署main 程序,而
http request ==> business server ==> rpc server ==> db/redis则是各节点 分别启动
-
既然大家都是分布式系统,那么针对特定的业务,我们可以汲取spark 等设计的一些特点和经验,优化
http request ==> business server ==> rpc server ==> db/redis一撸到底的简单设计。但没有必要觉得spark/storm 有什么了不起,很多性能瓶颈,并不是spark/storm 能解决的。
学习知识要有体系,程序的生命力
留下评论