maven/ant/gradle/make使用
简介
maven和ant之类的工具是做什么的?
我们对一个项目定义了一个生命周期:
- 编译,源文件到可执行文件(可能用到依赖的jar)
- 打包,如过你的项目是一个可重用的jar,那么把它打成jar
- 部署,对于war,部署即为将其放到tomcat的webapps目录下,或者将一个jar文件上传某个远程库。
对于maven和ant之类工具,我们编写一个配置文件(说清楚一些细节),即可通过命令一键完成或执行这些生命周期。
换句话说:maven和ant是一种支持项目构建,依赖管理和项目信息管理的工具。
2018.11.25补充:用长了之后,因为build 部分不用怎么动,反倒是觉得 maven 是做依赖管理的活儿了。
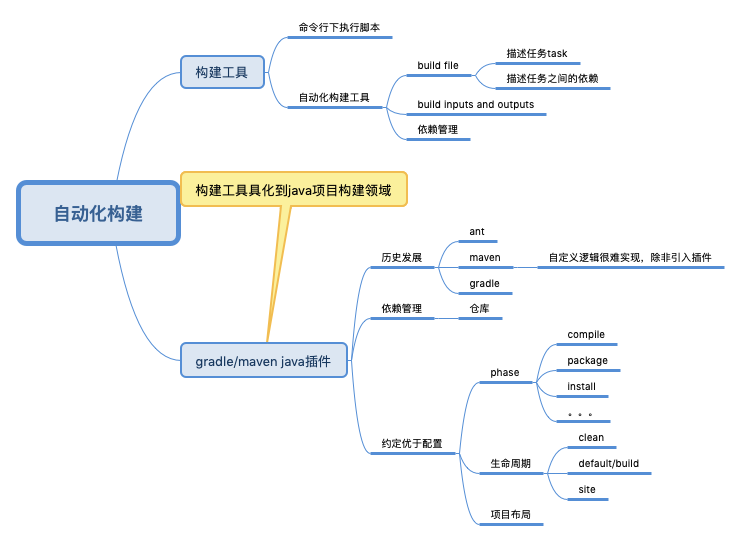
广义的构建工具
最原始的构建工具 就是一系列的 shell脚本,但shell脚本写多了,人们发现很多都是重复的,并且代码量也很大,模式比较固定。所以人们搞出了自动化构建工具,用写配置文件来代替写脚本。
自动化构建工具要干几件事:
- 描述任务 task
- 描述任务依赖,也就是执行顺序
- task 有时用到了外部文件,因此要做依赖管理
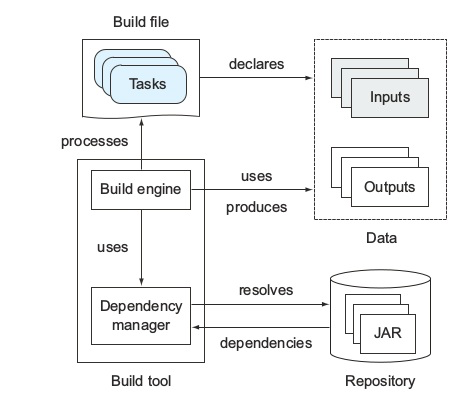
这几件事儿在java领域被具体化为:
- task 具化为 编译、打包、部署
- 编译的时候有依赖jar(jar 有个好处是还不怎么变),所以干脆搞了一个center repository,进而搞了依赖管理
- 为了task 之间协调方便,弄了一个“约定大于配置”,约定了项目目录结构/布局(定义了去哪里找项目的源代码、资源文件和测试代码),标准化构建生命周期(也就是对task 进行了划分)
- maven 项目构建的各阶段各任务都由插件实现,gradle 类似(提供了一些默认的task 实现给java 项目)
ant
最简单的例子
hello/build.xml 文件
<?xml version="1.0"?>
<project name="my">
<target name="sayHelloWorld">
<!--除了echo标签,你还可以使用javac、java、deploy-->
<echo message="Hello,Amigo"/>
</target>
</project>
执行ant命令ant <targtetName>
$ ant sayHelloWorld
Buildfile: e:\workspaces\java\my\build.xml
sayHelloWorld:
[echo] Hello,Amigo
BUILD SUCCESSFUL
Total time: 0 seconds
其中对于deploy标签,指定下:war文件地址,tomcat目录(和所在主机),即可将war包部署到tomcat上。
maven
maven构建提速 好文章
生命周期
生命周期(lifecycle)、阶段(phase)和插件(plugin)目标(goal)的关系
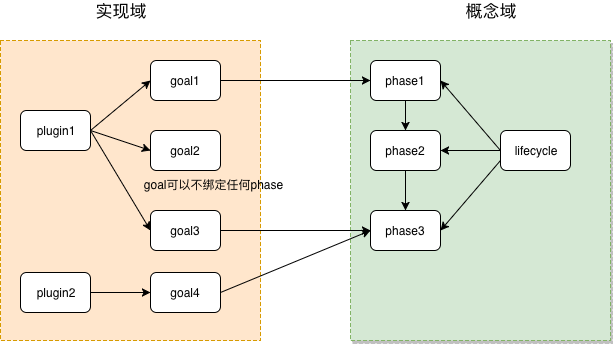
Maven 将构建过程定义为 default lifecycle,并将 default lifecycle 划分为一个个的阶段 phase,这一系列 phase 仅仅是规定执行顺序,至于每个阶段做什么工作?由谁来做?答案就在 插件(plugins) 中。 Maven 对工程的所有操作实实在在的都是由 插件 来完成的。一个插件可以支持多种功能,称之为目标(goal),例如:compiler 插件有两个目标:compile 和 testCompile,分别实现编译源代码 和 编译测试代码。 如何将插件与 Maven 的构建生命周期绑定在一起呢?通过将插件的目标(goal)与 build lifecycle 中 phase 绑定到一起,这样,当要执行某个 phase 时,就调用插件来完成绑定的目标。 比如 将插件 modello-maven-plugin 的 java 目标绑定到 generate-sources 阶段。
<plugin>
<groupId>org.codehaus.modello</groupId>
<artifactId>modello-maven-plugin</artifactId>
<version>1.8.1</version>
<executions>
<execution>
...
<phase>generate-sources</phase>
<goals>
<goal>java</goal>
</goals>
</execution>
</executions>
</plugin>
在 pom.xml 文件中,packaging 类型支持 jar, war, ear, pom 等多种类型,不同的 packaging 类型会使得相同的 phase 绑定不同的 plugin goal。
命令执行
从上文可知 mvn phase 最终也是执行的 mvn goal,无论直接还是间接,最终都是为了执行plugin的goal 对应的代码。
~ mvn --help
usage: mvn [options] [<goal(s)>] [<phase(s)>]
Options:
-am,--also-make If project list is specified, also
build projects required by the
list
...
以mvn clean dependency:copy-dependencies package为例, clean 阶段将会被首先执行,然后 dependency:copy-dependencies 目标会被执行,最终 package 阶段被执行。
依赖管理
对于依赖jar的使用,使用maven后,一个很直接的感觉就是:
- 原先:将java工程需要的jar复制到工程目录的某个文件夹下,将该文件夹加入到classpath
- 现在:只要将需要的jar配置到pom.xml文件中即可
依赖管理中涉及到的问题比较多,比如依赖传递,scope设置,依赖调解等 Introduction to the Dependency Mechanism
pom文件
profile
在pom中,如果一个jar包的版本经常改变,我们可以将其版本提取到properties元素中:
<properties>
<xxx.version>0.0.1</xxx.version>
</properties>
假定pom.xml中有一个jar包,在不同的情境(开发、测试与上线)中所需的版本不同,那么可以:
<profiles>
<profile>
<!--开发版本-->
<id>dev</id>
<properties>
<xxx.version>0.0.1</xxx.version>
</properties>
</profile>
<profile>
<!--测试版本-->
<id>test</id>
<properties>
<xxx.version>0.0.2</xxx.version>
</properties>
</profile>
<profile>
<!--上线版本-->
<id>pro</id>
<properties>
<xxx.version>0.0.3</xxx.version>
</properties>
</profile>
</profiles>
编译该包时,只需mvn clean pacakge -P dev即可使“dev”下的<properties>生效。
最佳实践
pluginManagement和DependencyManagement
背景,
- 复杂的项目开发过程中,通常是一个父项目,包含多个子项目,依赖的jar在父项目中声明后,所有的子项目自动包含依赖的jar。
- plugin和jar都通过groupId和artifactId唯一标识
在父项目中通过pluginManagement和DependencyManagement引入build依赖的plugin和代码依赖的jar,这样,子项目在用到相关的jar和plugin时,需要再次声明(可以避免子项目依赖无关的jar),但无需声明版本号(所有子项目依赖的版本号可以集中设置)。
gradle
内部 DSL(基于一种动态语言)相比 XML 在构建脚本方面优势非常大。Gradle is modeled in a way that customizable and extensible in the most fundamental ways.
- Projects 和 tasks 是gradle 最重要的 两个概念
- gradle 命令会从当前目录下寻找 build.gradle 文件来执行构建。我们称 build.gradle 文件为构建脚本,定义了一个 project 和一些默认的 task。
本来的样子
先不谈java
defaultTasks 'taskB'
task taskA << {
println "i am task A"
}
task taskB << {
println "i am task B,and i depend on " + taskA.name
}
taskB.dependOn taskA
$ gradle 就可以看到
i am task A
i am task B, and i depend on task A
task 是gradle 世界的第一公民
gradle vs maven
依赖管理、仓库、约定优于配置等概念 是maven的核心内容,这些概念本身没什么问题,gradle 对这些概念的实现 都更优于maven。
| 几个方面 | 优势 |
|---|---|
| 依赖管理 | 代码更简洁 |
| 项目布局 | 遵守maven的约定,但可自定义 |
| 生命周期 | 更灵活,可覆盖lifecycle的phase 或 跳过 |
总结下来,就是
- 简洁,groovy比xml表现力更强,当然了xml比groovy更容易推广
- 灵活
使用groovy 代替xml 来写代码 大大减少了 构建脚本的大小。maven pom.xml 的画风是
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>4.3.6.RELEASE</version>
</dependency>
</dependencies>
换成 build.gradle
dependencies {
compile('org.springframework:spring-core:4.3.6.RELEASE')
}
| gradle | maven | 备注 | |
|---|---|---|---|
| 命令执行 | gradle [option...] [task...] |
mvn [options] [<goal(s)>] [<phase(s)>]执行phase 本质也是执行goal |
都是执行一个具体的事情 |
| 源代码目录布局 | 两者一致 | ||
| 命令执行后的产出目录 | build | target |
build.gradle demo
group 'com.rotation.demo'
version '0.0.1-SNAPSHOT'
ext {
springVersion = '4.3.6.RELEASE'
slf4jVersion = '1.7.5'
}
apply plugin: 'java'
// war plugin 继承了 java plugin,所以不写java 也没影响
apply plugin: 'war'
sourceCompatibility = 1.8
repositories {
mavenCentral()
mavenLocal()
}
war {
archiveName = "gradle-demo.war"
}
dependencies {
testCompile group: 'junit', name: 'junit', version: '4.12'
compile group: 'org.slf4j',name: 'slf4j-api',version: slf4jVersion
compile group: 'org.slf4j',name: 'slf4j-log4j12',version: slf4jVersion
compile group: 'org.slf4j',name: 'jcl-over-slf4j',version: slf4jVersion
compile group: 'org.springframework', name: 'spring-web', version: springVersion
compile group: 'org.springframework', name: 'spring-webmvc', version: springVersion
compile group: 'org.springframework', name: 'spring-context', version: springVersion
compile group: 'org.springframework', name: 'spring-context-support', version: springVersion
compile group: 'org.springframework', name: 'spring-beans', version: springVersion
}
目录结构
src // 与maven 惯例一致
main
java
resources
webapp
WEB-INF
web.xml
test
java
build
classes
libs
resources
tmp
.gradle
若是使用idea的话,可以查看 gradle 可以执行的task
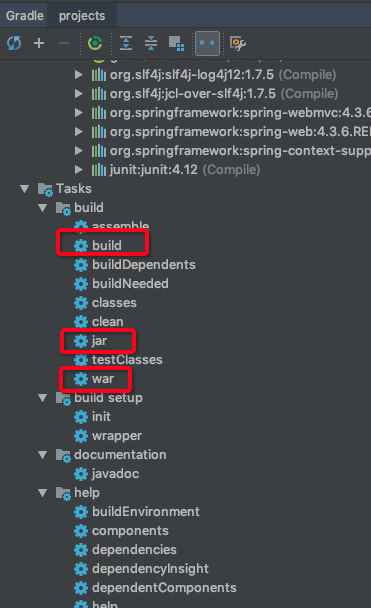
命令运行
gradle jar将代码编译成jargradle war将代码编译成war
gradle 貌似不像maven 一样,从assembly 顺序执行到 war,所以你直接运行gradle war 就是单纯的打war包,不会跑测试类。
gradle 包装器
包装器是gradle 的一个核心特性, 它会从中央仓库中自动下载gradle runtime,解压到你的文件系统,然后用来build。终极目标就是创建可靠地、可复用的、与操作系统、系统配置或Gradle版本无关的构建。
在build.gradle中
task wrapper(type:wrapper){
gradleVersion = '1.7'
}
然后执行
$ gradle wrapper
会生成目录结构
gradle
wrapper
gradle-wrapper.jar
gradle-wrapper.properteis
gradlew
gradlew.bat
这些文件都非常小,可以随代码一起提交,重点是提交后
- 你的同事本地没有装gradle,他可以使用
gradlew war来打war 包。gradlew 会自动下载 gradle runtime 并执行 - 你的同事已经装了gradle 并且直接运行
gradle war,则可能因为两人gradle runtime版本不一致带来问题。
gradle 构建组成
每个gradle构建都包括 三个基本的构建块:项目(project)、任务(task)和属性(properties),每个构建至少包括一个项目,项目包括一个或者多个任务,项目和任务都有很多属性来控制构建过程。
gradle运用了ddd来给自己的领域构建软件建模,因此gradle的项目和任务都在gradle 的API 中有一个直接的class 来表示
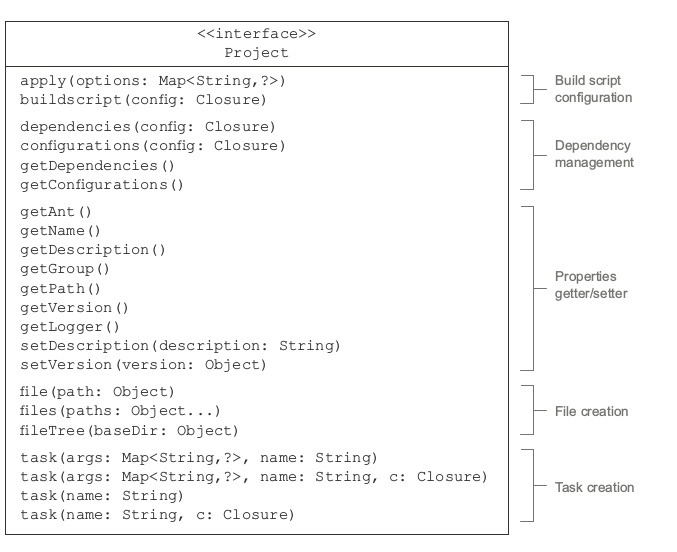
当开始构建过程后,Gradle基于你的配置实例化org.gradle.api.Project 类。这句话很重要,意味着build 时先初始化了一个org.gradle.api.Project类(估计内容是空的),然后执行 build.gradle 中的内容(反正也是groovy脚本)来为该实例赋值。在build.gradle 中,不需要显式的使用project 变量。
setDescription("myProject") // 实质是project.setDescription("myProject")
println "Description of project $name: " + project.Description
几个问题
- 再继续深入的话,要了解下groovy,是否适可而止?是否开始实践驱动而不是单纯的学习?
- build.gradle 可以随意定义task, 难道不需要像java 一样一个文件一个类?
- build.gradle 定义的类和默认的 gradle 类实例如何交互
- 定义的task 如何被加载,gradle 构建生命周期:初始化、配置和执行 又是怎么回
make
make是一个 构建工具,是 macOS 和 Linux 中自带的一个命令。Makefile是一个编译脚本,执行make命令的时候,它自动读取Makefile文件,从而决定自己要做什么事情。Makefile文件的格式如下:
# Makefile 的缩进只能使用 Tab 键,不能使用空格。
target1:prerequisites
command
target2:prerequisites
command
无论c/c++/Golang/Python 还是其他项目,使用 Makefile 来自动化执行一些繁琐重复的命令。
留下评论