向量数据库的一些考量
前言(未完成)
数据检索的挑战 —— 从结构化时代到非结构化时代。传统数据库存储的是标量数据,标量原来是物理上的概念,指只有大小而没有方向的物理量,在数据库这里用标量来表示一类数据类型,例如数字型、字符型、日期型、布尔型,针对该类数据类型可以使用精确匹配的方式进行查询,例如传统关系数据库的 SQL,该检索方式称为标量查询。全文检索是指在非结构化的文本数据中基于特定单词或者文本在全文范围内进行检索。常见的搜索引擎就是对全文检索技术的实现,例如 Lucene、Solr、ElasticSearch 等。标量查询和全文检索本质上是关于标量数据或关键字的精确匹配,其查找结果与输入目标之间是完全相同的关系。
全球数据量急剧增长,其中超过80%的数据都会是处理难度较大的非结构化数据,如文档、文本、图形、图像、音频、视频等,非结构化数据在大数据时代的重要地位已成为共识。现代 AI/ML 技术的发展提供了一种从非结构数据中提取语义信息的方式 —— embedding。区别于前面提到的标量类型,embedding 是一种向量类型 —— 由多个数值组成的数组,因此 embedding 又被称为向量或者矢量。
向量模型是指通过特定的嵌入(embedding)技术,将原始的非结构化数据转换成一个数值型的向量,在数学表示上,向量是一个由浮点数或者二值型数据组成的 n 维数组。embedding model 本质上是一种数据压缩技术,通过 AI/ML 技术对原始数据进行编码,使用比原始数据更少的比特位来表示数据。压缩后的数据就是原始数据的“隐空间表示”,压缩过程中,外部特征和非重要特性被去除,最重要的特征被保存下来,随着数据维度的降低,本质上越相似的原始数据,其隐空间表示也越相近。因此,隐空间是一个抽象的多维空间,外部对象被编码为该空间的内部表示,被编码对象在外部世界越相似,在隐空间中就越靠近彼此。基于以上理论基础,我们可以通过 embedding 之间的距离来衡量其相似程度。
技术
Lexical search is the kind of search that we’ve all been using for years in Elasticsearch. To summarize it very briefly, it doesn’t try to understand the real meaning of what is indexed and queried, instead, it makes a big effort to lexically match the literals of the words or variants of them(think stemming, synonyms, etc.) that the user types in a query with all the literals that have been previously indexed into the database using similarity algorithms, such as TF-IDF. If you search for the exact same terms but order them differently to produce a different meaning, e.g., “turn right” and “right turn,” it yields the exact same result. PS:词汇相似度,。如果你搜索完全相同的词,但顺序不同,从而产生不同的意思,它会产生完全相同的搜索结果。
向量的相似性度量基于距离函数,常见的距离函数有欧式距离、余弦距离、点积距离,实际应用中选择何种距离函数取决于具体的应用场景。
- 欧式距离(L2 distance)衡量两个向量在空间中的直线距离。欧式距离存在尺度敏感性的局限性,通过归一化等技术可以有效降低尺度敏感性对相似度的干扰。欧式距离适用于低维向量,在高维空间下会逐渐失效。
- 余弦距离(Cosine similarity)衡量两个向量之间夹角的余弦值。余弦距离存在数值敏感性的局限性,因为其只考虑了向量的方向,而没有考虑向量的长度。余弦距离适用于高维向量或者稀疏向量。
- 点积距离(Dot product similarity)通过将两个向量的对应分量相乘后再全部求和而进行相似度衡量,点积距离同时考虑了向量的长度和方向。点积距离存在尺度敏感性和零向量的局限性。
向量检索是一种基于距离函数的相似度检索,由于向量间的距离反映了向量的相似度,因此通过距离排序可以查找最相似的若干个向量。向量检索算法有 kNN 和 ANN 两种。PS:向量化 + 找临近向量
- kNN(k-Nearest Neighbors)是一种蛮力检索方式,当给定目标向量时,计算该向量与候选向量集中所有向量的相似度,并返回最相似的 K 条。当向量库中数据量很大时 kNN 会消耗很多计算资源,耗时也不理想。
- ANN ( Approximate Nearest Neighbor)是一种更为高效的检索方式,其基本思想是预先计算向量间的距离,并将距离相近的向量存储在一起,从而在检索时可以更高效。预先计算就是构建向量索引的过程,向量索引是一种将向量数据组织为能够高效检索的结构。向量索引大幅提升了检索速度,但返回的是近似结果,因此 ANN 检索会有少量的精度牺牲。常见的 ANN 索引类型有 IVF、HNSW(Hierarchical Navigable Small Worlds )、PQ、IVFPQ。PS:这些算法和技术可以基于树、图、聚类或哈希,其目标是快速缩小到多维空间的特定区域,以便找到最近邻。
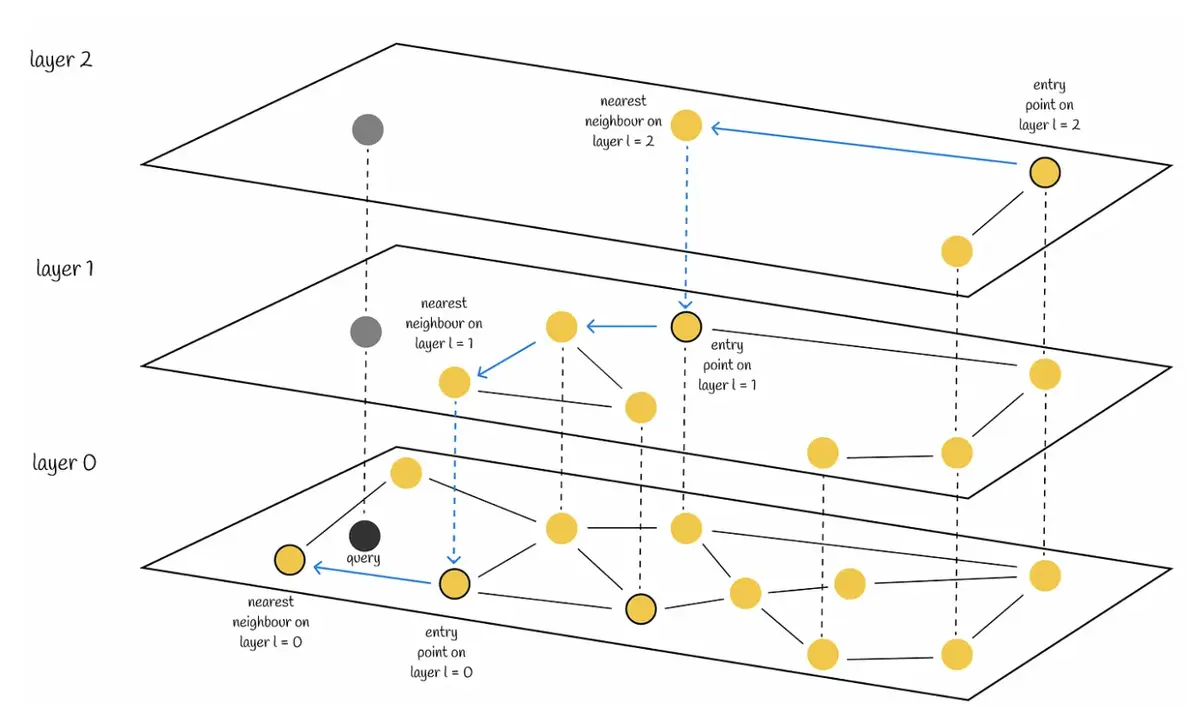
以HNS为例,HNSW是一种基于多层图的算法,在顶层,我们可以看到一个由极少向量构成的图,这些向量之间的连线最长,也就是说,这是一个由相似度最低的相连向量构成的图。我们越深入到较低层,发现的向量就越多,图也变得越密集,越来越多的向量彼此靠得更近。在最底层,我们可以找到所有的向量,其中相似度最高的向量彼此距离最近。在搜索时,该算法从顶层的任意入口点开始,找到与查询向量最接近的向量(由灰色点表示)。然后,它向下移动一层,并从上层离开的同一向量开始重复相同的过程,依此类推,逐层进行,直到到达最底层并找到查询向量的最近邻。PS:有点跳表的意思,分层跳表
混合检索
传统检索技术( Lexical/词汇的 search)善于精确查询(结构化数据),但缺乏语义理解。而向量检索技术能够很好的识别用户意图,让非结构化数据具备可搜索性,但在精确检索方面召回率大概率不如传统检索技术,两种技术都不完美。对于特定的检索场景,两者结合能够提供更准确的检索结果。但混合检索提出了对多个结果集重新排序的难题。 运行混合搜索查询通常归结为发送至少一个词汇搜索查询和一个语义搜索查询的组合,然后合并两者的结果。词汇搜索结果由相似度算法(如 BM25 或 TF-IDF)进行评分,其评分范围通常是无界的,因为最高分数取决于倒排索引中存储的词项数量和频率。相比之下,语义搜索结果可以在一个封闭区间内进行评分,这取决于所使用的相似性函数(例如,余弦相似度的区间为 [0,2])。重新排序指将来自多种检索技术的有序结果集进行规范化合并,形成同一标准的单一有序结果集。单一有序结果集能够更好的供下游系统处理和分析。常见的重新排序算法有 RRF、RankNet、LambdaRank、LambdaMART 等。
- Convex Combination (CC) (也称为线性组合)旨在将词汇搜索结果和语义搜索结果的归一化分数与各自的权重相结合,可以看作是词汇和语义分数的加权平均值。
-
Reciprocal Rank Fusion (RRF),RRF不需要任何分数校准或归一化,只需根据文档在结果集中的排名对其进行打分,使用以下公式,其中k是一个任意常数,用于调整排名较低的文档的重要性。
\[score_{rr f}(doc) = \frac{1}{k + \text{rank}_{\text{lex}}(doc)} + \frac{1}{k + \text{rank}_{\text{sem}}(doc)}\]
产品
面向 RAG 应用开发者的实用指南和建议在 RAG 应用生产环境中有效部署向量数据库的关键技巧:
- 设计一个有效的 Schema:仔细考虑数据结构及其查询方式,创建一个可优化性能和提供可扩展性的 Schema。
- 动态 Schema vs. 固定 Schema。。动态 Schema 提供了灵活性,简化了数据插入和检索流程,无需进行大量的数据对齐或 ETL 过程。这种方法非常适合需要更改数据结构的应用。另一方面,固定 Schema 也十分重要,因为它们有着紧凑的存储格式,在性能效率和节约内存方面表现出色。
- 设置主键和 Partition key
- 选择 Embedding 向量类型。稠密向量 (Dense Embedding);稀疏向量(Sparse Embedding);二进制向量(Binary Embedding)
- 考虑可扩展性:考虑未来的数据规模增长,并充分设计架构以适应不断增长的数据量和用户流量。
- 选择最佳索引并优化性能:可以针对向量数据构建高效的索引结构,如倒排索引、树形结构(如 KD 树、Ball Tree)或近似最近邻搜索算法(如FAISS、HNSW),加速检索过程。
Elasticsearch
7.0可以使用 dense_vector 字段类型 存储向量,At that point, vectors were simply stored as binary doc values.在8.11版本之前,hnsw是Apache Lucene支持的唯一用于为密集向量建立索引的算法。8.12版本中新增的标量量化支持(比如int8_hnsw/int4_hnsw),只需定义并配置一个 dense_vector 字段就可以对向量数据建立索引。
"title_vector":{
"type":"dense_vector"
}
Elasticsearch支持两种不同的向量搜索模式使用 script_score 查询进行精确搜索;2)使用 knn 搜索选项或 knn 查询(8.12及更高版本)进行近似最近邻搜索。
- Exact search,本质上就是在整个向量空间中执行线性搜索或暴力搜索。基本上,查询向量会与每个存储的向量进行比对,以找到最近邻。在这种模式下,向量无需在HNSW图中建立索引,只需作为二进制文档值存储,相似度计算由自定义的Painless脚本运行。随着数据量的增长,搜索查询可能会很快变慢,因为添加的向量越多,遍历每个向量所需的时间就越长(即线性搜索的时间复杂度为O(n))。
POST my-index/_search { "_source": false, "fields": [ "price" ], "query": { # query 部分指定了一个过滤器(即 price >= 100),它限制了将针对其执行 script 的document set "script_score": { "query" : { "bool" : { "filter" : { "range" : { "price" : { "gte": 100 } } } } }, "script": { "source": "cosineSimilarity(params.queryVector, 'title_vector') + 1.0", "params": { "queryVector": [0.1, 3.2, 2.1] } } } } } - k-NN search
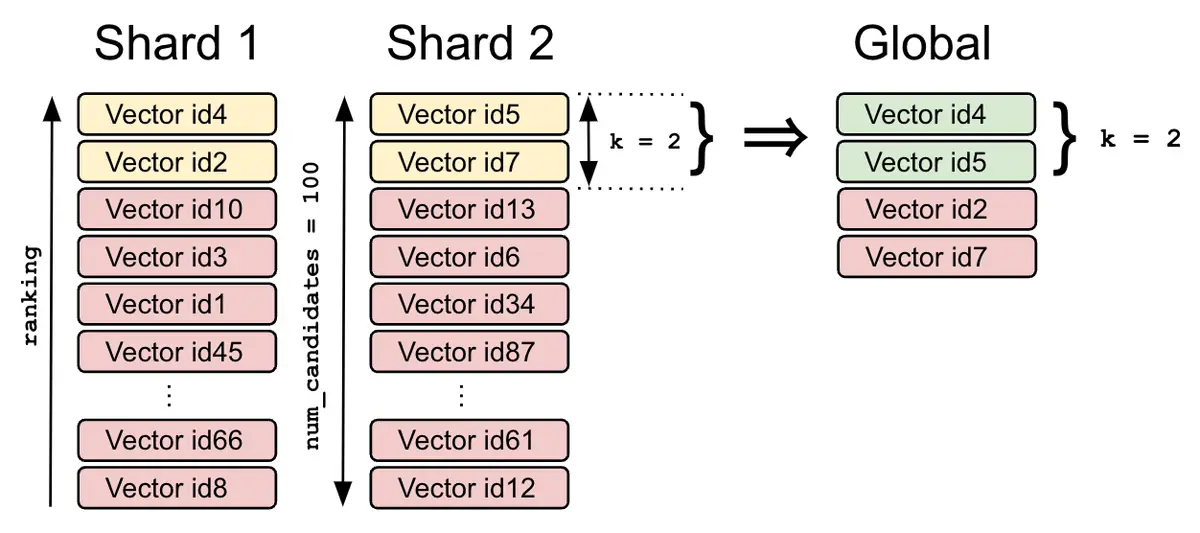
// Simple k-NN search POST my-index/_search { "_source": false, "fields": [ "price" ], "knn": { "field": "title_vector", "query_vector": [0.1, 3.2, 2.1], "k": 2, "num_candidates": 100 } } // 从8.12版本起,利用bool查询对k近邻搜索结果进行后置过滤 POST my-index/_search { "size": 3, "_source": false, "fields": [ "price" ], "query" : { "bool" : { "must" : { "knn": { "field": "title_vector", "query_vector": [0.1, 3.2, 2.1], "num_candidates": 100 // 每个shard上会考虑多达 num_candidates 个向量,排名前 k 的向量将被返回给coordinator node,coordinator node将合并所有分片本地的结果,并从全局结果中返回排名前 k 的向量. } }, "filter" : { "range" : { "price" : { "gte": 100 } } } } } }
向量id4和id2分别是第一个分片上的k个局部最近邻,id5和id7是第二个分片上的k个局部最近邻。在对它们进行合并和重新排序后,coordinator node返回id4和id5作为搜索查询的两个全局最近邻。
前过滤还是后过滤? Filtering data
milvus
Elasticsearch与milvus作为RAG向量库怎么选?
- 从架构方面,我就觉得milvus就逊于elasticsearch,最直观的感受就是太复杂,概念太多,组件太多,模块分层太多,也许你觉得这些描述过于感性,但复杂就会带来脆弱不稳定性以及维护难度大等问题,反观,这确实elasticsearch所擅长的,相对架构会简单很多,也不依赖外部组件,集群算法以及分布式文件存储都是自己多年沉淀出来的最佳实践。
- 功能与灵活性。为了提升最终召回的准确率,一般都会采用多路召回,再不济也会提供标准的混合检索实现,除了向量检索,还要求全文检索即相关性检索(当然,有些人也区别向量检索成为稀疏检索),不管变种怎么变化,核心一般还是围绕BM25,而elasticsearch天然支持全文检索,同时elasticsearch支持的script功能,还提供用户自定义算法,当然elasticsearch本身也提供了直接支持。除了这些,最坑的要数milvus不支持schema的修改,即collection一旦确定,不允许调整,尽管支持标量字段的json字段。而这对于elasticsearch号称的no schema或者schemaless特性,真的手拿把掐。
使用
当我们把通过模型或者 AI 应用处理好的数据喂给它之后(“一堆特征向量”),它会根据一些固定的套路,例如像传统数据库进行查询优化加速那样,为这些数据建立索引。避免我们进行数据查询的时候,需要笨拙的在海量数据中进行。
本地
faiss 原生使用
# 准备数据
model = SentenceTransformer('uer/sbert-base-chinese-nli')
sentences = ["住在四号普里怀特街的杜斯利先生及夫人非常骄傲地宣称自己是十分正常的人",
"杜斯利先生是一家叫作格朗宁斯的钻机工厂的老板", "哈利看着她茫然地低下头摸了摸额头上闪电形的伤疤",
"十九年来哈利的伤疤再也没有疼过"]
sentence_embeddings = model.encode(sentences)
# 建立索引
dimension = sentence_embeddings.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(sentence_embeddings)
# 检索
topK = 2
search = model.encode(["哈利波特猛然睡醒"]) # 将要搜索的内容“哈利波特猛然睡醒”编码为向量
D, I = index.search(search, topK) # D指的是“数据置信度/可信度” I 指的是我们之前数据准备时灌入的文本数据的具体行数。
print(I)
print([x for x in sentences if sentences.index(x) in I[0]])
faiss 与LangChain 集合,主要是与 LangChain 的 document和 Embeddings 结合。 faiss 本身只存储 文本向量化后的向量(index.faiss文件),但是vector db对外使用,一定是文本查文本,所以要记录 文本块与向量关系(index.pkl文件)。此外,需支持新增和删除文件(包含多个文本块),所以也要支持按文件删除 文本块对应的向量。
from langchain.document_loaders import TextLoader
# 录入documents 到faiss
loader = TextLoader("xx.txt") # 加载文件夹中的所有txt类型的文件
documents = loader.load() # 将数据转成 document 对象,每个文件会作为一个 document
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents) # 切割加载的 document
embeddings = OpenAIEmbeddings() # 初始化 openai 的 embeddings 对象
db = FAISS.from_documents(docs, embeddings) # 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 faiss 向量数据库,用于后续匹配查询
query = "What did the president say about Ketanji Brown Jackson"
docs = db.similarity_search(query)
print(docs[0].page_content)
简单的源码分析
# 根据文档内容构建 langchain.vectorstores.Faiss
vectorstore.base.from_documents(cls: Type[VST],documents: List[Document], embedding: Embeddings, **kwargs: Any,) -> VST:
"""Return VectorStore initialized from documents and embeddings."""
texts = [d.page_content for d in documents]
metadatas = [d.metadata for d in documents]
return cls.from_texts(texts, embedding, metadatas=metadatas, **kwargs)
# Embeds documents.
embeddings = embedding.embed_documents(texts)
cls.__from(texts,embeddings,embedding, metadatas=metadatas,ids=ids,**kwargs,)
# Initializes the FAISS database
faiss = dependable_faiss_import()
index = faiss.IndexFlatL2(len(embeddings[0]))
vector = np.array(embeddings, dtype=np.float32)
index.add(vector)
# 建立id 与text 的关联
documents = []
if ids is None:
ids = [str(uuid.uuid4()) for _ in texts]
for i, text in enumerate(texts):
metadata = metadatas[i] if metadatas else {}
documents.append(Document(page_content=text, metadata=metadata))
index_to_id = dict(enumerate(ids))
# Creates an in memory docstore
docstore = InMemoryDocstore(dict(zip(index_to_id.values(), documents)))
return cls(embedding.embed_query,index,docstore,index_to_id,normalize_L2=normalize_L2,**kwargs,)
save_local:
faiss = dependable_faiss_import()
faiss.write_index(self.index, str(path / "{index_name}.faiss".format(index_name=index_name)))
with open(path / "{index_name}.pkl".format(index_name=index_name), "wb") as f:
pickle.dump((self.docstore, self.index_to_docstore_id), f)
在线
Pinecone 是一个在线的向量数据库。所以,我可以第一步依旧是注册,然后拿到对应的 api key。
from langchain.vectorstores import Pinecone
# 从远程服务加载数据
docsearch = Pinecone.from_existing_index(index_name, embeddings)
# 录入documents 持久化数据到pinecone
# 初始化 pinecone
pinecone.init(api_key="你的api key",environment="你的Environment")
loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt')
documents = loader.load() # 将数据转成 document 对象,每个文件会作为一个 document
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
split_docs = text_splitter.split_documents(documents) # 切割加载的 document
docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name) # 持久化数据到pinecone
留下评论