《网络是怎样连接的》笔记
简介
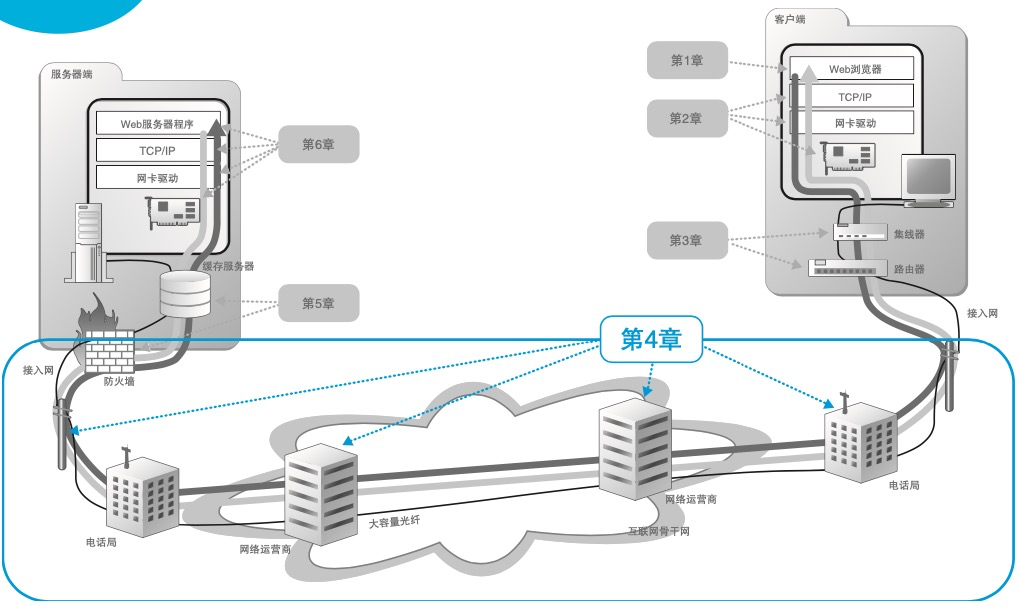
网络通信由操作系统中的网络控制软件,以及交换机、路由器等设备分工合作来实现的,它的基本思路是将数字信息分割成一个一个的小块,然后装入一些被称为“包”(Packet)的容器中来运送。包相当于信件或者包裹,而交换机和路由器则相当于邮 局或快递公司的分拣处理区。包的头部存有目的地等控制信息,通过许多 交换机和路由器的接力,就可以根据控制信息对这些包进行分拣,然后将 它们一步一步地搬运到目的地。无论是家庭和公司里的局域网,还是外面 的互联网,它们只是在规模上有所不同,基本的机制都是相同的。
客户端
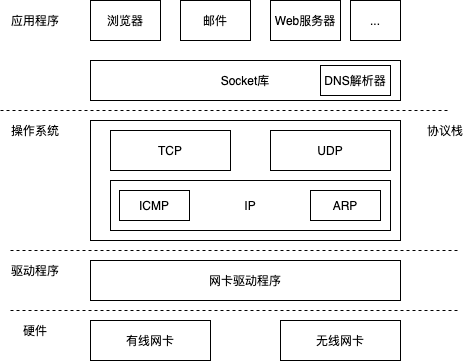
对于在数据收发中扮演关键角色的套接字,让我们来看一看它具体是个怎样的东西。在协议栈内部有一块用于存放控制信息的内存空间,这里记录了用于 控制通信操作的控制信息,例如通信对象的 IP 地址、端口号、通信操作的 进行状态等。本来套接字就只是一个概念而已,并不存在实体,如果一定 要赋予它一个实体,我们可以说这些控制信息就是套接字的实体,或者说 存放控制信息的内存空间就是套接字的实体。
协议栈在执行操作时需要参阅这些控制信息 。例如,在发送数据时, 需要看一看套接字中的通信对象 IP 地址和端口号,以便向指定的 IP 地址 和端口发送数据。在发送数据之后,协议栈需要等待对方返回收到数据的 响应信息,但数据也可能在中途丢失,永远也等不到对方的响应。在这样 的情况下,我们不能一直等下去,需要在等待一定时间之后重新发送丢失 的数据,这就需要协议栈能够知道执行发送数据操作后过了多长时间。为 此,套接字中必须要记录是否已经收到响应,以及发送数据后经过了多长时间,才能根据这些信息按照需要执行重发操作。套接字中记录了用于控制通信操作的各种控制信息,协议栈则需要根据这些信息判断下一步的行动,这就是套接 字的作用。
- 创建套接字。首先会分配用于存放一个套接字所需的内存空 间。用于记录套接字控制信息的内存空间并不是一开始就存在的,因此我们先要开辟出这样一块空间来 ,这相当于为控制信息准备一个容器。套接字刚刚创建时, 数据收发操作还没有开始,因此需要在套接字的内存空间中写入表示这一 初始状态的控制信息。
-
连接。以太网的网线都是 一直连接的状态,我们并不需要来回插拔网线,那么这里的“连接”到底 是什么意思呢?连接实际上是通信双方交换控制信息(比如IP和PORT),在套接字中记录这 些必要信息并准备数据收发的一连串操作。连接操作中所交换的控制信息是根据通信规则来确定的, 只要根据规则执行连接操作,双方就可以得到必要的信息从而完成数据收 发的准备。此外,当执行数据收发操作时,我们还需要一块用来临时存放 要收发的数据的内存空间,这块内存空间称为缓冲区,它也是在连接操作 的过程中分配的。通信操作中的控制信息分为两类
- 头部中记录的信息/客户端和服务端相互联络时交换的控制信息,这些内容在 TCP 协议的规格中进行了定义。比如发送方/接收方端口号、序号、ACK号、数据偏移量、控制位、窗口、校验和、紧急指针等
- 根据协议栈本身的实现方式不同而不同,通信对方是看不见的。例如,Windows 和 Linux 操作系统的内部结构不同,协议栈的实现方式不同,必要的控制信息也就不同。
发送方的网络设备会负责创建包,创建包的过程就是生成含有 正确控制信息的头部,然后再附加上要发送的数据。接下来,包会被发往最近的网络转发设备。当到达最近的转发设备之后,转发设备会根据头部 中的信息判断接下来应该发往哪里。这个过程需要用到一张表,这张表里面记录了每一个地址对应的发送方向,也就是按照头部里记录的目的地址在表里进行查询,并根据查到的信息判断接下来应该发往哪个方向。这些对于各种通信方式都是适用的
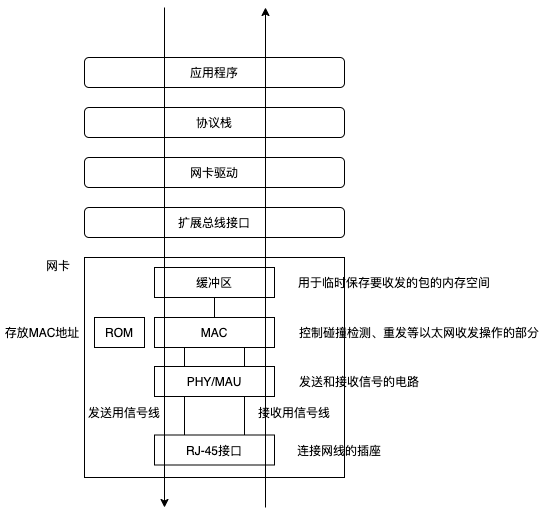
网卡并不是通上电之后就可以马上开始工作的,而是和其他硬件一样, 都需要进行初始化。也就是说,打开计算机启动操作系统的时候,网卡驱 动程序会对硬件进行初始化操作,然后硬件才进入可以使用的状态。这些 操作包括硬件错误检查、初始设置等步骤。
网卡驱动从 IP 模块获取包之后,会将其复制到网卡内的缓冲区中,然后向 MAC 模块发送发送包的命令。MAC 模块会将包从缓冲区中取出,并在开头加上报头和起始帧分界符,在末尾加上用于检测错误的帧校验序列。接下来,PHY(MAU)模块会将信号转换为可在网线上传输的格式, 并通过网线发送出去。PHY(MAU)还需要监控接收线路中有没有信号进来。在开始发送信号之前,需要先确认没有其他信号进来,这时才能开始发送。如果 有其他设备同时发送信号,这些信号就会通过接收线路传进来。在使用集线器的半双工模式中,一旦发生这种情况,两组信号就会相互叠加,无法彼此区分出来,这就是所谓的信号碰撞。这种情况下,继续发送信号是没有意义的,因此发送操作会终止。
接收数据包时,首 先,PHY (MAU)模块会将信号转换成通用格式并发送给 MAC 模块,MAC 模块再 从头开始将信号转换为数字信息,并存放到缓冲区中。当到达信号的末尾 时,还需要检查 FCS。如果 FCS 校验没有问题,接下来就要看一下 MAC 头部中接收方MAC 地址与网卡在初始化时分配给自己的 MAC 地址是否一致,以判断这 个包是不是发给自己的。我们没必要去接收发给别人的包,因此如果不是 自己的包就直接丢弃。如果接收方 MAC 地址和自己 MAC 地址一致,则将包放入缓冲区中 通知计算机收到了一个包。
通知计算机的操作会使用一个叫作中断的机制。在网卡执行接收包的 操作的过程中,计算机并不是一直监控着网卡的活动,而是去继续执行其 他的任务。因此,如果网卡不通知计算机,计算机是不知道包已经收到了 这件事的。网卡驱动也是在计算机中运行的一个程序,因此它也不知道包 到达的状态。在这种情况下,我们需要一种机制能够打断计算机正在执行 的任务,让计算机注意到网卡中发生的事情,这种机制就是中断。
具体来说,中断的工作过程是这样的。首先,网卡向扩展总线中的中断信号线发送信号,该信号线通过计算机中的中断控制器连接到 CPU。当产生中断信号时,CPU 会暂时挂起正在处理的任务,切换到操作系统中的 B中断处理程序 。然后,中断处理程序会调用网卡驱动,控制网卡执行相应 的接收操作。网卡驱动被中断处理程序调用后,会从网卡的缓冲区中取出收到的包, 并通过 MAC 头部中的以太类型字段判断协议的类型(除了TCP/IP之外还有 NetWare 的 IPX/SPX, Mac电脑中使用的 AppleTalk等)。如 0080(十六进制)代表IP 协议,网卡驱动就会把这样的包交给 TCP/IP 协议栈。PS:进程 ==> 设备 ==> 中断 ==> 进程,形成一个异步通信的机制
接下来就轮到 IP 模块先开始工作了,第 一步是检查 IP 头部,确认格式是否正确。如果格式没有问题,下一步就是 查看接收方 IP 地址。看包是不是发给自己的。当服务器启用类似路由器的包转发功能时,对于不是发给自己的包,会像路由器一样根据路由表对包进行转发。确认包是发给自己之后,检查包有没有被分片。 如果是分片的包,则将包暂时存放在内 存中,等所有分片全部到达之后将分片组装起来还原成原始包。 同一个包的所有分片都具有 相同的 ID。此外,IP 头部还有一个分片偏移量(fragment offset)字段,它 表示当前分片在整个包中所处的位置。根据这些信息,在所有分片全部收 到之后,就可以将它们还原成原始的包。如果没有 分片,则直接保留接收时的样子,不需要进行重组。到这里,我们就完成了包的接收。 接下来需要检查 IP 头部的协议号字段,并将包转交给相应的模块。例如,如果协议号为 06(十六进制),则将包转交给 TCP 模块;如果是 11(十 六进制),则转交给 UDP 模块。
TCP 模块会根据 IP 头部中的接收方和发送方 IP 地址,以及 TCP 头部中的接收方和发送方端口号来查找对应的套接字。找到对应的套接字之后,就可以 根据套接字中记录的通信状态,执行相应的操作了。例如,如果包的内容 是应用程序数据,则返回确认接收的包,并将数据放入缓冲区,等待应用 程序来读取;如果是建立或断开连接的控制包,则返回相应的响应控制包, 并告知应用程序建立和断开连接的操作状态。
严格来说,TCP 模块和 IP 模块有各自的责任范围,TCP 头部属于 TCP 的 责任范围,而 IP 头部属于 IP 模块的责任范围。应该对两者 进行明确的划分,IP 模块只向 TCP 模块传递 TCP 头部以及它后面的数据, 而对于 IP 头部中的重要信息,即接收方和发送方的 IP 地址,则由 IP 模块 以附加参数的形式告知 TCP 模块。然而,如果根据这种严格的划分来开发 程序的话,IP 模块和 TCP 模块之间的交互过程必然会产生成本,而且 IP 模块和 TCP 模块进行类似交互的场景其实非常多,总体的交互成本就会很 高,程序的运行效率就会下降。因此,就像之前提过的一样,不妨将责任 范围划分得宽松一些,将 TCP 和 IP 作为一个整体来看待,这样可以带来 更大的灵活性。
交换机
交换机的设计是将网络包原样 转发到目的地
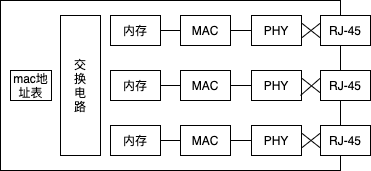
信号到达网线接口,并由 PHY(MAU)模块进行接收。它的接口和 PHY(MAU)模块也是以MDI-X传递给 MAC 模块。MAC 模块将信号转换为数字信息,然后通过包末尾的FCS校验错误,如果没有问题则存放到缓冲区中。网线接口 和后面的电路部分加在一起称为一个端口,也就是说交换机的一个端口就相当于计算机上的一块网卡。但交换机的工作方式和网卡有一点不同。网 卡本身具有 MAC 地址,并通过核对收到的包的接收方 MAC 地址判断是不是发给自己的,如果不是发给自己的则丢弃;相对地,交换机的端口不 核对接收方 MAC 地址,而是直接接收所有的包并存放到缓冲区中。因此,和网卡不同,交换机的端口不具有 MAC 地址。
将包存入缓冲区后,接下来需要查询一下这个包的接收方 MAC 地址是否已经在 MAC 地址表中有记录了。MAC 地址表主要包含两个信息,一个是设备的 MAC 地址,另一个是该设备连接在交换机的哪个端口上。MAC 地址和端口是一一对应的,通过这张表就能够判断出收到的包应该转发到哪个端口。
当网络包通过交换电路到达发送端口时,端口中的 MAC 模块和 PHY (MAU)模块会执行发送操作,将信号发送到网线中,这部分和网卡发送信 号的过程是一样的。
MAC地址表的维护:收到包时,将发送方 MAC 地址以及其输入端口的号码写入 MAC 地址表中。由于收到包的那个端口就连接着发送这个包的设备,所以 只要将这个包的发送方 MAC 地址写入地址表,以后当收到发往这个地址 的包时,交换机就可以将它转发到正确的端口了。交换机每次收到包时都 会执行这个操作,因此只要某个设备发送过网络包,它的 MAC 地址就会 被记录到地址表中。
网络基本功之细说交换机补充到文档上。
- 交换机做出转发决定的时候,是基于进入端口以及消息的目的地址的。
- 一个交换机要知道使用哪一个端口传送帧,首先必须学习各端口有哪些设备。随着交换机学习到端口与设备的关系,它建立起一张 MAC 地址表,或内容可寻址寄存表(CAM)。交换机学习“源地址”,基于“目的地址”转发。
- MAC 地址表对于一个连接至其他交换机的端口记录多个 MAC 地址。
在我们常见的物理交换机中,有可以配置IP和不能配置IP两种,不能配置IP的交换机一般通过com口连上去做配置(更简单的交换机连com口的没有,不支持任何配置),而能配置IP的交换机可以在配置好IP之后,通过该IP远程连接上去做配置,从而更方便。
路由器
许式伟:路由器和交换机不太一样,交换机因为没有门牌号,通讯基本靠吼。好的一点是,圈子比较小,吼上一段时间后,路都记住了,闭着眼睛都不会走错。但广域网太大了,靠吼没几个人听得见。所以路由器工作在网络协议的第三层,也就是网络层。网络层看到的是 IP 协议,能够知道数据传输的源 IP 地址和目标 IP 地址。有了 IP 地址,就相当于有了门牌号,开启导航按图索骥就可以把东西带过去了。这也是路由器为什么叫路由器的原因,它有导航(路由)功能,知道哪些目标 IP 地址的数据包应该往哪条路走的。路由器可以拥有一部分交换机的能力,比如,如果发现请求是局域网内的话,也可以引入类似交换机那样的基于 MAC 地址的映射表实现高速通讯。但总体来说,路由器要考虑的问题复杂很多,因为涉及 “最佳路由路径” 的问题。路由器除了解决路由问题,它往往还要解决异构网络的封包转换问题。作为局域网的接入方,它可能走的是固网或 WiFi 网络。作为 Internet 的接入方,它可能走的是光纤宽带。所以它需要把局域网的数据链路层的封包解开并重组,以适应广域网数据链路协议的需求。
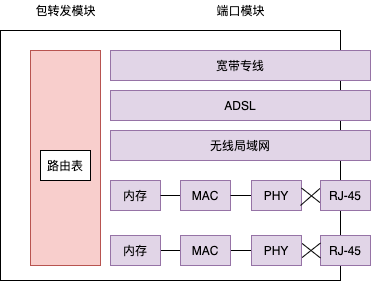
路由器包括转发模块和端口模块两部分,其中转发模块负责判断包的转发目的地,端口模块负责包的收发操作。路由器转发模 块和端口模块的关系,就相当于协议栈的 IP 模块和网卡之间的关系。
通过更换网卡,计算机不仅可以支持以太网,也可以支持无线局域网, 路由器也是一样。如果路由器的端口模块安装了支持无线局域网的硬件, 就可以支持无线局域网了。此外,计算机的网卡除了以太网和无线局域网 之外很少见到支持其他通信技术的品种,而路由器的端口模块则支持除局域网之外的多种通信技术,如 ADSL、FTTH(光纤接入网),以及各种宽带专线等,只要端口模块安装了支持这些技术的硬件即可。
路由器在转发包时,首先会通过端口将发过来的包接收进来,这一步的工 作过程取决于端口对应的通信技术。对于以太网端口来说,就是按照以太 网规范进行工作,而无线局域网端口则按照无线局域网的规范工作,总之 就是委托端口的硬件将包接收进来。接下来,转发模块会根据接收到的包 的 IP 头部中记录的接收方 IP 地址,在路由表中进行查询,以此判断转发 目标。然后,转发模块将包转移到转发目标对应的端口,端口再按照硬件 的规则将包发送出去。
以以太网端口为例,路由器的端口具有 MAC地址,因此它就能够成为以太网的发送方和接收 。端口还具有 IP 地址,从这个意义上来说,它和计算机的网卡是一样的(端口是按照以太网规范接收包的,即当端口的 MAC 地址和包的接收方MAC 地址一致时,端口才接受这个包,否则就丢弃包)。这一点和交 换机是不同的,交换机只是将进来的包转发出去而已,它自己并不会成为 发送方或者接收方。
无论是路由器的路由表 还是计算机中的 路由表,它们的结构和功能都是相同的。
- 目标地址destination,记录的是接收方的信息
- 子网掩码,表示在匹配网络包目标地址时需要对比的比特数量。子网掩码 0.0.0.0 的意思是网络包接收方 IP 地址和路由表目标地址 的匹配中需要匹配的比特数为 0,换句话说,就是根本不需要匹配。
- 网关,表示网络包的转发目标
- 接口,表示网络包的转发目标
- 跃点数,表示距离目标 IP 地址的距离是远还是近
| 交换机 | 路由器 | |
| 查表判断转发目标 | MAC地址表 | 路由表 |
| 查表判断转发目标 | 通过 MAC 头部中的接收 方 MAC 地址 | 根据 IP 头部中的 IP 地址 |
| 查表判断转发目标 | 只匹配完全一致的记录 | 忽略主机号部分,只匹配网络 号部分 |
| 不具有 MAC 地址 | 端口具有MAC和IP地址 | |
| 维护方式 | 对 MAC 地址表的维护是包转发操作中的一个步骤 | 对路由表的维护是与包 转发操作相互独立的 |
| 如果无法找到匹配的记录 | 将包发送到所有的端口上 | 路由器会丢弃这个包,并通过 ICMP 消息告知发送方 通过默认路由发给默认网关 |
| 附加功能 | 地址转发 包过滤 |
从路由表中查找到转发目标之后,更新 IP 头部中的 TTL,TTL 字段表示包的有效期,包每经过一个路由器的 转发,这个值就会减 1,当这个值变成 0 时,就表示超过了有效期,这个包就会被丢弃(这个机制是为了防止包在一个地方陷入死循环)。路由器的端口并不只有以太网一种,也可以支持其他局域网或专线通信技术。不同的线路和局域网类型各自能传输的最大包长度也不同,因此 输出端口的最大包长度可能会小于输入端口,遇到这种情况,可以使用 IP 协议中定义的分片功能对包进行拆分,缩 短每个包的长度。
接下来就会进入包的发送操作,这一步操作取决于输出端口的类型。如果是以太网端口,则按照以太 网的规则将包转换为电信号发送出去;如果是 ADSL 则按照 ADSL 的规则来转换,以此类推。如果输出端口是以太网,为了判断 MAC 头部中的 MAC 地址应该填写什么值,我们需 要根据路由表的网关列判断对方的地址。如果网关是一个 IP 地址,则这个IP 地址就是我们要转发到的目标地址;如果网关为空方 IP 地址就是要转发到的目标地址。知道对方的 IP 地址之后,接下来需 要通过 ARPD 根据 IP 地址查询 MAC 地址,并将查询的结果作为接收方MAC 地址。路由器也有 ARP 缓存,因此首先会在 ARP 缓存中查询,如果 找不到则发送 ARP 查询请求。接下来是发送方 MAC 地址字段,这里填写输出端口的 MAC 地址 还有一个以太类型字段,填写 0080(十六进制)。网络包完成后,接下来会将其转换成电信号并通过端口发送出去。这 一步的工作过程和计算机也是相同的。
这里讲的内容只适用于原原本 本实现 IP 和以太网机制的纯粹的路由器和交换机,实际的路由器有内置交 换机功能的,比如用于连接互联网的家用路由器就属于这一种。
接入互联网的设备数量快速增长,为解决地址不足的问题,考虑到两家公司的内网之 间不会有网络包流动,公司内部设备的地址可以和其他公司重复,从而大幅节省了 IP 地址。因此需要设置一定的规则,规定某些地址是用于内网的,内网中的设备不能和互联网直接收发网络包。
10.0.0.0 ~ 10.255.255.255
172.16.0.0 ~ 172.31.255.255
192.168.0.0 ~ 192.168.255.255
公司内网并不是完全独立的,而是需要通过互联网和其他很多公司相连接, 所以当内网和互联网之间需要传输包的时候,通过“地址转换”机制进行连接。地址转换的基本原理是在转发网络包时对 IP 头部中的 IP 地址和端口 号 进行改写。然后,改写前的私有地址 和端口号,以及改写后的公有地址和端口号,会作为一组相对应的记录保 存在地址转换设备内部的一张表中<公有地址|端口号|私有地址|端口号|>(在对外只能使用一个公有地址的情况下,可以用不同的端口号来区别内网中的 不同终端)。从互 联网一端来看,实际的通信对象是地址转换设备(这里指的是路由器)。PS:iptables 命令行方式看着就没有表格方式直接。
包过滤就是在对包进行转发时,根据 MAC 头部、IP 头部、TCP 头部的内容 事先设置好的规则决定是转发这个包,还是丢弃这个包。我们通常说的防火墙设备或软件,大多数都是利用这一机制来防止非法入侵的。
通过接入网进入互联网内部
互联网是一个遍布世界的巨大而复杂的系统,但其基本工作方式却出 奇地简单。和家庭、公司网络一样,互联网也是通过路由器来转发包的。
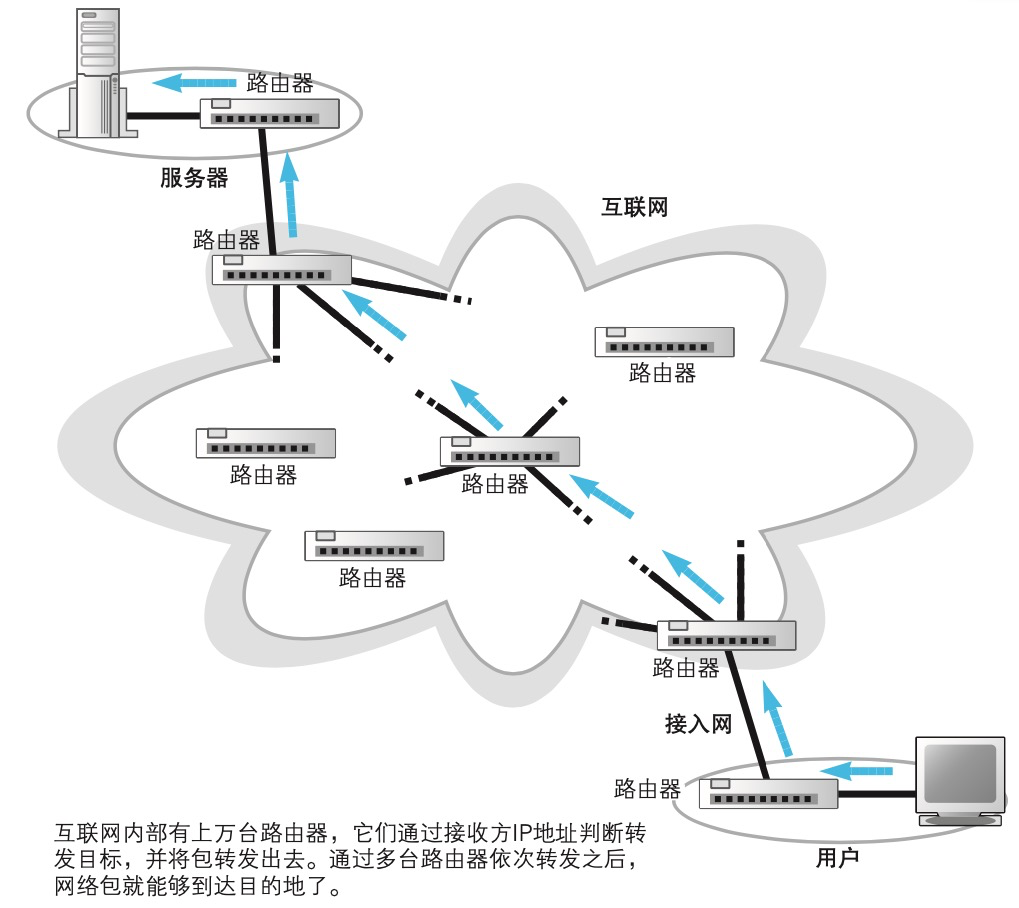
| 互联网 | 家庭、公司网络 | |
|---|---|---|
| 与转发设备间的距离 | 比如太平洋 | 几十米到几百米 |
| 路由表记录的维护方式 | 10w+的路由记录 BGP机制 运营商之间的路由交换是在特定路由器间一对 一进行的(方便控制和计费) |
在所 有路由器间平等交换的 |
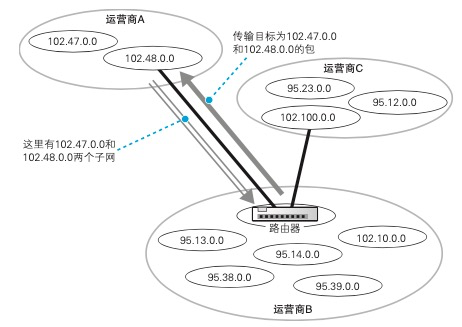
互联网的实体并不是由一个组织运营管理的单一网络,而是由多个运营商网络相互连接组成的。ADSL、FTTH 等接入网是与用户签约 的运营商设备相连的,这些设备称为POP ,互联网的入口就位于这里。
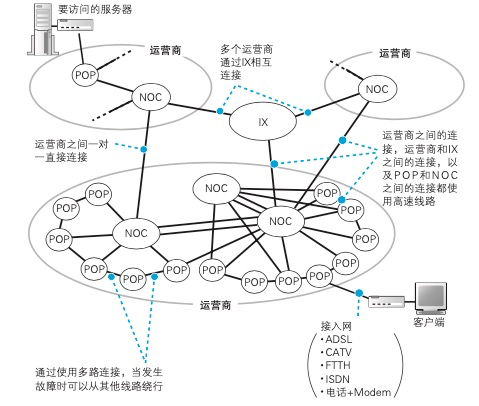
POP 里面是什么样的呢? POP 的结构根据接入网类型以及运营 商的业务类型不同而不同,包括各 种类型的路由器,路由器的基本工作方式是相同的,但根据其角色分成了 不同的类型。
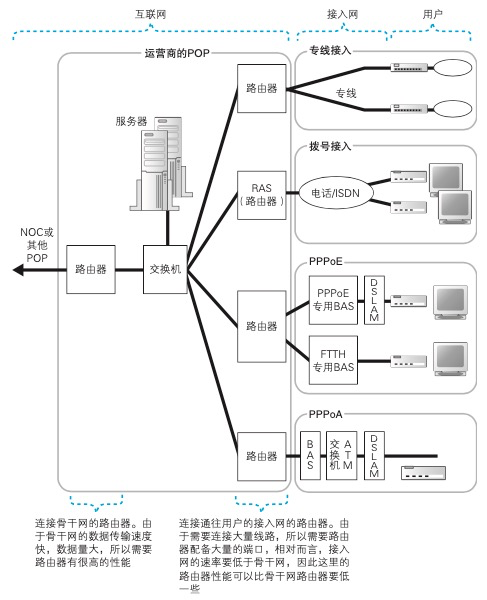
NOC是运营商的核心设备,从 POP 传来的网络包都会集中到这里, 并从这里被转发到离目的地更近的 POP,或者是转发到其他的运营商。面向运营商的高性能路由器中有些产品的数据吞吐量超过 1 Tbit/s,而一般 面向个人的路由器的数据吞吐量也就 100 Mbit/s 左右,两者相差 1 万多倍。
到达 POP 路由器之后,网络包是如何前往下一站的。首先,如果最终目的地 Web 服务器和客户端是连接在同一个运营商中的,那么 POP 路由器的路由表中应该有相应的转发目标。运营商的路由器可以和其他路由器交换路由信息,从而自动更新自己的路由表,通过这一功能,路由信息就实现了自动化管理 。于是,路由器根据 路由表中的信息判断转发目标,这个转发目标可能是 NOC,也可能是相邻 的 POP,无论如何,路由器都会把包转发出去,然后下一个路由器也同样 根据自己路由表中的信息继续转发。经过几次转发之后,网络包就到达了 Web 服务器所在的 POP 的路由器,然后从这里被继续转发到 Web 服务器。
如果服务器的运营商和客户端的运营商不同又会怎样呢?这种 情况下,网络包需要先发到服务器所在的运营商,这些信息也可以在路由 表中找到,这是因为运营商的路由器和其他运营商的路由器也在交换路由 信息(使用 BGP 机制)。
服务器端的局域网
Web 服 务器不仅可以部署在公司里,也可以放在网络运 营商等管理的数据中心里,或者直接租用运营商提供的服务器。数据中心是与运营商核心部分 NOC 直接连接的,或者是与运营商之 间的枢纽 IX 直接连接的。换句话说,数据中心通过高速线路直接连接到互联网的核心部分,因此将服务器部署在这里可以获得很高的访问速度。
服务端接收数据过程
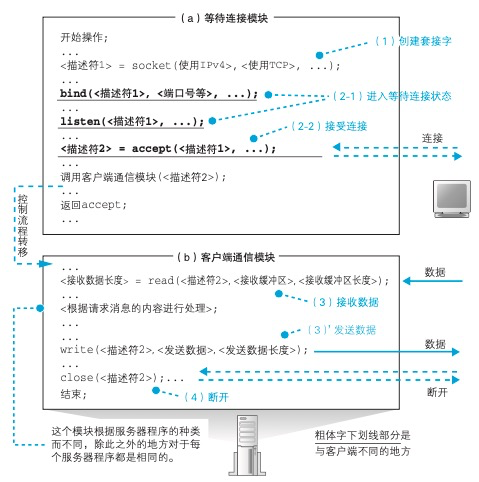
- 协议栈调用 socket 创建套接字,这一步和客户端是 相同的 。
- 接下来调用 bind 将端口号写入套接字中。在客户端发起连接的操作中,需要指定服务器端的端口号,这个端口号也就是在这一步 设置的。
- 设置好端口号之后,协议栈会调用 listen 向套接字写入等待连接状态 这一控制信息。这样一来,套接字就会开始等待来自客户端 的连接网络包。
- 然后,协议栈会调用 accept 来接受连接,一旦客户端的包到达,就会返回响应包 并开始接受连接操作。接下来,协议栈会给等待连接的套接字复制一个副 本,然后将连接对象等控制信息写入新的套接字中。到这里,我们就创建了一个新的套接字, 并和客户端套接字连接在一起了。原来那个处于等待连接状态的套接字会怎么样呢?其实 它还会以等待连接的状态继续存在,当再次调用 accept,客户端连接包到 达时,它又可以再次执行接受连接操作。如果不创建新副本,而是直接让客户端连接到等 待连接的套接字上,那么就没有套接字在等待连接了,这时如果有其他客 户端发起连接就会遇到问题。
此外,创建新套接字时端口号也是一个关键点,新创建的套接字副本必须和原来的等待连接 的套接字具有相同的端口号。如果是不同的端口号,那么,客户端本来想要连接 80 端口上的套接字,结果从另一个端口号返回了 包,这样一来客户端就无法判断这个包到底是要连接的那个对象返回的, 还是其他程序返回的。如 果一个端口号对应多个套接字,就无法通过端口号来定位到某一个套接字 了。因此,不仅使 用服务器端套接字对应的端口号,还同时使用客户端的端口号再加上 IP 地 址来进行判断。
服务器的接收操作
- 网卡将接收到的信号转换成数字信息
- IP 模块的接收操作
- TCP 模块如何处理连接包
- 当 TCP 头部中的控制位 SYN 为 1 时,表示这是一个发起连接的包。这时,TCP 模块会执行接受连接的操作,不过在此之前,需 要先检查包的接收方端口号,并确认在该端口上有没有与接收方端口号相同且正在处于等待连接状态的套接字。如果存在等待连接的套接字,则为这个套接字复制一个新的副本,并将发送方 IP 地址、端口号、序号初始值、窗口大小等必要的参数写入这个套接字中,同时分配用于发送缓冲区和接收缓冲区的内存空间。然后生成代表接收确认的 ACK 号,用于从服务器向客户端发送数据的序号初始值,表示接收缓冲区剩余容量的窗口大小,并用这些信息生成 TCP 头部,委托IP 模块发送给客户端。这个包到达客户端之后,客户端会返回表示接收确认的 ACK 号,当这个 ACK 号返回服务器后,连接操作就完成了。
- 进入数据收发阶段之后,TCP 模块会检查收到的包对应哪一个套接字。找到 4 种信息(
<发送方IP,发送方端口,接收方IP,接收方端口>)全部匹配的套接字之后,TCP 模块会对比该套接字中保存的数据收发状态和收到的包的 TCP 头部中的信息是否匹配,以确定数据收发操作是否正常。具体来说,就是根据套接字中保存的上一个序号和数据长度计算下一个序号,并检查与收到的包的 TCP 头部中的序号是否一致。果两者一致,就说明包正常到达了服务器,没有丢失。这时,TCP 模块会从包中提出数据,并存放到接收缓冲区中。之后,TCP 模块就会生成确认应答的 TCP头部,并根据接收包的序号和数据长度计算出 ACK 号,然后委托 IP 模块发送给客户端。收到的数据块进入接收缓冲区,意味着数据包接收的操作告一段落了。接下来,应用程序会调用 Socket 库的 read来获取收到的数据, 这时数据会被转交给应用程序。一般来说,应用程序会在数据到达之前调用 read 等待数据到达,在这种情况下,TCP 模块在完成接收操作的同时,就会执 行将数据转交给应用程序的操作。然后,控制流程会转移到服务器程序,对收到的数据进行处理 - 在 TCP 协议的规则中,断开操作可以由客户端或服务器任何一方发 起,具体的顺序是由应用层协议决定的。Web 中,这一顺序随 HTTP 协议 版本不同而不同,在 HTTP1.0 中,是服务器先发起断开操作。服务器程序会调用 Socket 库的 close,TCP 模块会生成一个控 制位 FIN 为 1 的 TCP 头部,并委托 IP 模块发送给客户端。当客户端收到这个包之后,会返回一个 ACK 号。接下来客户端调用 close,生成一个 FIN 为 1 的 TCP 头部发给服务器,服务器再返回 ACK 号,这时断开操作 就完成了。HTTP1.1 中,是客户端先发起断开操作,这种情况下只要将客 户端和服务器的操作颠倒一下就可以了。无论哪种情况,当断开操作完成后,套接字会在经过一段时间后被删除。
留下评论