BFF
简介
GraphQL is a query language for APIs and a runtime for fulfilling those queries with your existing data. 为什么我使用 GraphQL 而放弃 REST API?
用搭积木的方式写业务 GraphQL及元数据驱动架构在后端BFF中的实践,bff 一般需要泛化rpc的支持。
聊聊我对 GraphQL 的一些认知 GraphQL 留给我的印象就停留在这些无法解决的问题上。曾经有人咨询我想用 GraphQL 去重构某个服务,被我比较激动的给打消了这个念头。
基于 GraphQL 平台化 BFF 构建及微服务治理 从理念到实现到落地比较成体系。
GraphQL
首先要先谈一下RESTful API,定义了一组设计约束和理念,他的核心思想是:一切都是资源(Resource),通过统一的接口来操作这些资源。并用 URL 来表示资源,用 HTTP 方法(GET/POST/PUT/DELETE)来定义操作。基于 REST 来构建的 API,我们称之为 RESTful API(PS: API=资源+操作)。REST 的设计哲学迎合了互联网应用的爆发需求:轻量、直观、跨语言、易扩展,搭配 Swagger (现称 OpenAPI Specification, OAS)的规范,成为互联网世界应用最广泛的的 API 形态,是 Web API 协议的事实标准。
在移动互联网和前端复杂化的背景下,客户端需要的数据结构和后端返回的 RESTful 响应会出现对不上号的情况。
- 数据获取过多:例如客户端只需要用户的头像和昵称,但 RESTful API /users/123 返回了整个用户对象(包含地址、订单、权限等一大堆信息)。这不仅浪费带宽,还增加了解析开销。
- 数据获取不足:例如移动端要展示用户信息 + 最近三条订单,但 RESTful 只能先调 /users/123,再调 /users/123/orders,最后还得筛选。一个页面可能要发出三四次请求,性能和延迟都受到影响。 这种不足在移动端、复杂单页应用、跨端应用尤为严重,因为客户端和网络环境资源有限。GraphQL 正是为了解决这个问题而出现的。它允许客户端“按需取数”,一次请求返回所需字段。GraphQL 是 Facebook 在 2015 年开源的一种 API 查询语言与执行引擎。它的核心理念是:客户端自己决定要什么数据,服务端只返回所需字段。和 RESTful 按资源划分不同,GraphQL 只有一个统一的入口(通常是 /graphql),客户端通过查询语句(Query)来精确指定数据结构,服务端不会多给一个字节。
需求
- 不知道大家有没有遇到过这样的一些场景,某个服务有几十个接口,更有甚者上百个也是有可能的。APP 或者其他下游要封装一个功能,需要调用 10 个接口左右,可能这些接口还涉及到不同的团队。不管开发,联调,测试,还是对于调用方,整个链条功能太多了。随着这些功能经过多个版本的迭代升级后,新+旧版本的接口谁也不敢大规模改动了,只能在原来的基础上做代码拼接,这基本就是祖传代码的由来。大部分同学基本的代码素养是有的,但是也只能任由这些祖传代码慢慢腐烂,原因为很简单,谁也不敢保证改动之后功能是不是有遗漏的地方。有没有这样一个功能,将这些接口做一下聚合,然后将结果的集合返回给前端呢?在目前比较流行微服务架构体系下,有一个专门的中间层专门来处理这个事情,这个中间层叫 BFF(Backend For Frontend)。
- 当用户打开这个页面的时候,按照目前比较流行的 REST 接口,需要 APP 至少发起下面这些请求:获取商品详情接口;获取商品价格、优惠相关的接口;获取评价接口;获取种草秀接口;获取问答接口。这些接口一般来说都比较重,里面有很多当前页面并不需要的字段,那有没有一种可能:APP 端发一次请求就能获取这个页面需要的所有字段,同时 APP 还能根据自己的需求只请求自己需要的字段呢?
基于 GraphQL 平台化 BFF 构建及微服务治理从本质上来说是前端面向页面场景和后端面向业务领域之间的矛盾,由 BFF 这层来解决。但BFF 也只是为了解耦前端和后端间的依赖而增加的一层,BFF 内部还是存在的非常多的问题。
- 按需取数,比如在 App 端上,完整的获取数据可能需要 100 个字段,对应 10 个接口。而在 Mobile Web 上,这个页面可能只需要 50 个字段,对应 6 个接口。
- 页面差异化兼容,比如 Web 端需要完全平铺的字段结构,而 App 上可以接受结构化对象结构。
- 不同版本的差异化兼容,在原生的 APP 上,BFF 层需要针对不同的版本做不同的处理。因此我们引入了路由的能力来解决这个问题。不同的版本或者 iOS/Android 端映射到不同的 API 接口上,API 内处理 GraphQL 的调用和 JSON 模板映射
效果
query jdGoodsQuery {
goods {
detail {
id
pictures(first: 10) {
pic_id
thumb
}
spec {
name
size
weight
}
}
price {
price
origin_price
market_price
}
comment(first: 10) {
comment_id
topic_id
content
from_uid
}
self_show(first: 10) {
id
pic_id
}
}
}
对于上面京东商品详情的截图,类似这样的一个 Query 就可以把这个页面需要的所有的字段都获取到。
整体实现
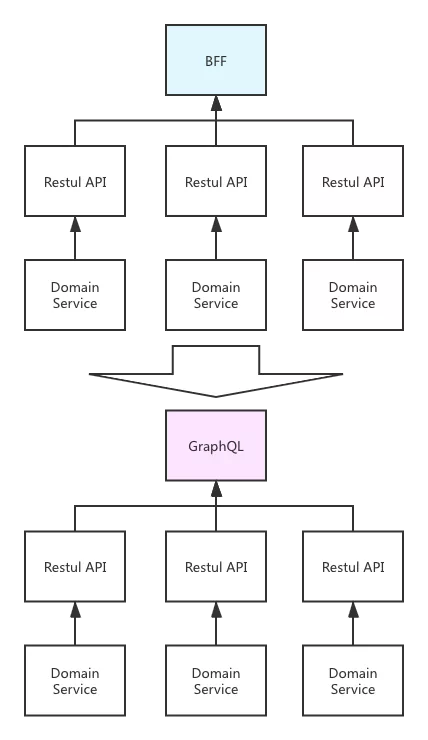
- 数据获取:多领域的按需取数和数据聚合 —— 引入 GraphQL
- 数据转换:一种 JSON 结构转换成另外一种 —— 引入 JSON 模板
- 请求映射:多版本兼容 —— 引入路由能力
GraphQL:从 GraphQL query 到json 响应
首先定义了一套类型系统/schema,这里 type 可以对应到 Java 语言中的 class
type Query {
me: User
}
type User {
id: ID
name: String
}
下面一段 GraphQL 的 query 语句,通过 Query 对象的入口,就可以开始对 GraphQL 对象进行查询了。
{
me {
name
}
}
很像db 支持sql 定义table(schema),然后用select 查询table 数据。
在 GraphQL 的实现里,是通过实现 DataFetcher 的接口来获取真正的数据的,例如调用 RESTful 接口或者调用 RPC 接口,都是封装在这里。DataFetcher 可以绑定在某个 type 的某个字段上,这样当访问到这个字段时, GraphQL 会自动调用这个 DataFetcher 来获取数据,没有使用到这个字段自然也不会请求。也是因为绑定到字段的原因,我们实现 DataFetcher 的时候可以聚焦在单一数据类型的获取上,而把多类型的数据关联交给 GraphQL 自己来完成。通过 GraphQL 这样的能力,我们即可以按需选择需要的数据字段,也可以让 GraphQL 自动帮助我们组装多个数据对象的数据。
在工程上
- 假设有一个rpc/rest api 接口,可以对应编写一个schema,针对这个schema 实现DataFetcher,在DataFetcher内可以使用restClient 访问rest api,之后,就可以以 GraphQL query 的方式来访问这个api 接口了
- 根据rpc/rest api 可以将上述 生成schema 和 DataFetcher 的逻辑自动化, 比如提交一个rpc api jar包,扫描rpc api jar 自动生成schema 注册到 GraphQL 网关中,生成 rpc DataFetcher jar 加载到GraphQL 网关中。
json 模板: 从json到 页面需要的json
前端页面所需的 JSON 字段的结构和 GraphQL 查询结果的 JSON 结构往往不相同,而且页面上也存在一些 format、if-else 的判断逻辑,这部分放在 GraphQL 里的话其实很难实现。我们采用 JSON 模板来对这两个不同的 JSON 结构进行映射。
//GraphQL 的结果,模板的输入 JSON
{
"data": [
{
"id": 10000,
"title": "房子 1",
"roomNum": 2,
"hallNum": 2,
"area": 90.12
}, {
"id": 10001,
"title": "房子 2",
"roomNum": 3,
"hallNum": 2,
"area": 99.34
},
...
]
}
//JSLT 模板
{
"dataList": [
for( .data) {
"id": .id,
"title": .title,
"label1": "户型",
"text1": .roomNum + "室" + .hallNum + "厅" ,
"label2": "面积",
"text2": .area +"㎡",
"link": URLRoute("HousePage", {"id": .id})
}
]
}
//输出JSON
{
"dataList": [
{
"id": 10000,
"title": "房子 1",
"label1": "户型",
"text1": "2室2厅",
"label2": "面积",
"text2": "90.12㎡",
"link": "https://anjuke.com/house.html?id=10000"
},
{
"id": 10001,
"title": "房子 2",
"label1": "户型",
"text1": "3室2厅",
"label2": "面积",
"text2": "100.34㎡",
"link": "https://anjuke.com/house.html?id=10001"
}
]
引入路由能力
路由这部分比较简单,主要就是根据不同的端、版本、iOS/Anroid 等参数,映射到对应的 GraphQL 请求和 JSON 模板上即可。
构建 BFF 平台
BFF 的开发工作其实比较模板化
- 数据获取:编写 GraphQL query,调用 GraphQL 服务获取数据
- 数据转换:编写 JSON 模板,转换成前端需要的 JSON 结构
- 请求映射:编写路由逻辑,映射到对应的 GraphQL 请求和 JSON 模板上
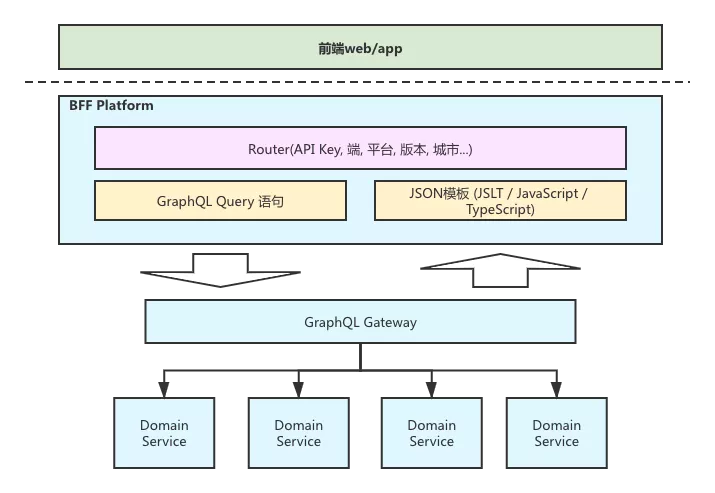
- 统一请求入口:BFF 平台负责对外部统一的 API 接口
- 请求映射:根据请求参数和内部配置的路由规则,把请求映射到不同的配置模板上
- 获取模板信息:单个配置模板里, 保存着 GraphQL 的 query 语句和 JSON 映射模板
- 数据获取:使用 GraphQL query 语句调用 GraphQL 网关,获取数据结果
- 数据转换:调用模板引擎,进行 JSON 结构的转换,并将数据返回给调用方 通过上述几个步骤,我们的 BFF 平台可以支持非常快速的实现一个 API 来对外提供服务。BFF 平台由后端负责开发和维护,保证服务的性能和稳定性。前端主要的工作使用 BFF 平台写 query 和模板,完成页面的数据拼装。通过这样的方式,前端和后端都能够最大化的发挥自己的擅长的能力,优化团队研发效率。
京东
可视化服务编排在金融APP中的实践BFF(Backend For Frontend), 即服务于前端的后端,可看做是一个后端服务的代理层,它主要做接口聚合和响应数据裁剪。BFF层的核心职责是为前端(包括原生、小程序、H5等)适配不同的业务场景,降低客户端与业务端的耦合,前期通过硬编码的方式来实现BFF层的需求,是最简单最直接的方式。但随着BFF层承接业务需求的增多,通过编码的方式也逐渐暴露出一些问题,如编码效率低、编码细节难以规范、调试测试效率低和服务治理能力弱等。
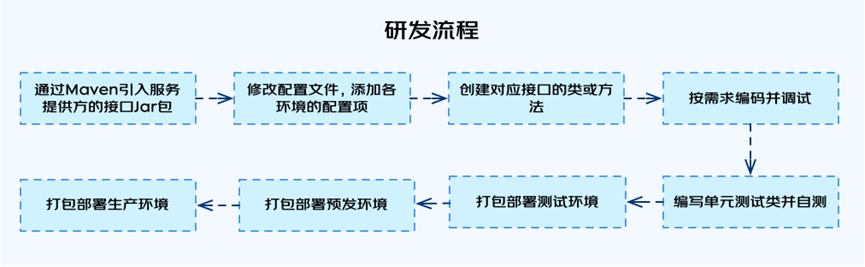
整个流程中,有太多需要人工处理及等待的步骤,这将会大大降低整个研发流程的效率,虽然现在有一些CI/CD的工具可以减少部分等待时间,但整体的编码体验及效率上的问题还是得不到根本的解决。可视化服务编排的提出,就是为了解决上面提到的问题。可视化服务编排的初衷是希望尽可能地抛弃代码,通过线上可视化拖拽的方式完成功能的开发、调试、测试和上线,我们不写代码或写少量代码就能完成业务需求的交付,没有代码就消除了前面提到的大多问题,这样极大提高研发的交付效率及编码幸福感。整个服务的编排效果如下图所示:
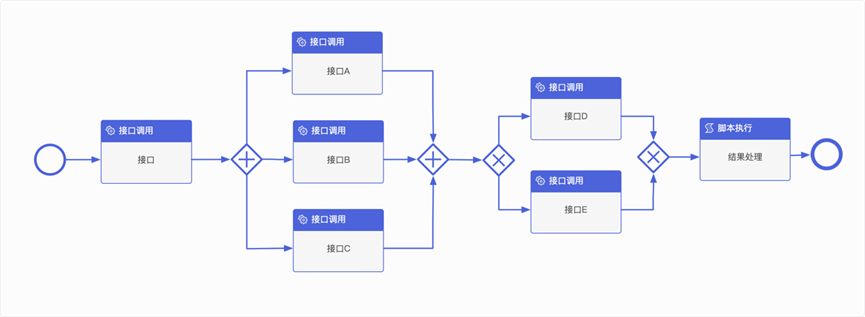
- 接口间调用关系可以抽象为:串行调用、并行调用、排他调用。排他调用就好比代码中的if…else,非A即B,这种场景主要用于根据条件判断调用接口A还是调用接口B,或是执行其他的业务逻辑。
- 参数处理:接口的入参主要有静态和动态两种形式,针对静态的入参,只需要在界面上提供输入框配置即可。针对动态的参数,值可能来自于其他接口的返回结果,也可能来自动态生成的,如随机数、UUID等,所以编排系统提供了通过表达式或脚本的方式来取值或生成值,以适配灵活的业务场景。
- 异常处理:接口的异常通常由两个维度进行判定,一是接口是否调用成功,如果接口抛出异常或超时都可以认为是接口调用失败,另一种情况是接口返回数据是否符全预期,如果接口调用成功,但返回的数据不是预期的,如关键字段没有返回或返回的数据格式不正确,同样需要将接口调用判定为失败。接口调用失败的情况下,不同场景下的处理策略可能也会不一样,因为有的接口并不是业务强依赖的,即便此接口出现问题也不会影响整个服务的响应。但有些接口则是服务强依赖的,如果请求失败则要求返回兜底数据或直接返回错误。所以对接口的异常判定和异常的处理方式设计了针对性的功能,即“ 异常断言”、“异常处理策略”和“异常处理器”。
- 服务部署:通过编排实现的服务,整个上线过程都不需要重启应用,其核心部署工作就是刷新内存数据,只需要线上选择要部署的机器,即可在秒级内完成服务的部署。
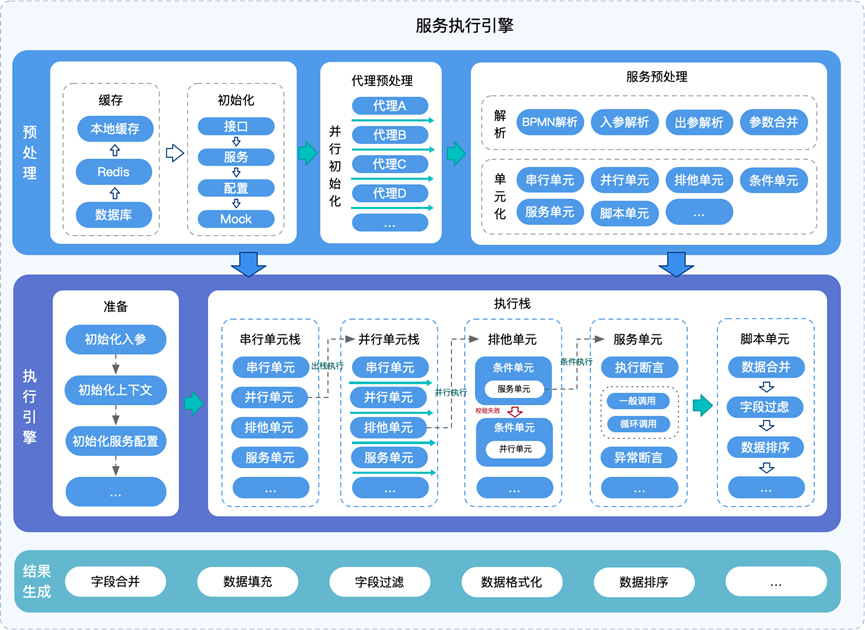
可视化服务编排系统的核心功能有两个,一个是前端编排画布,一个是后端服务执行引擎。
- 编排画布用于实现可视化操作部分,其核心功能是定义可操作的功能并根据用户的意图生成后端可解析执行的DSL。关于DSL的选择,方向主要有两个,一种是根据功能需求,定义一套全新的描述规范,另一种是基于已有的标准进行扩展。通过对前后端实现的复杂度及时间成本的考虑,最终决定基于BPMN规范进行裁剪和扩展,以实现编排整体的DSL规范定义。
- 执行引擎:
运行成效
- 交付效率,原来需要线下处理的流程全部转为线上操作,规避掉了大多编译构建及测试的等待时间。有些需求从原来的小时级提升为分钟级。
- 服务治理能力,通过编排实现业务需求后,可以由系统统一管理服务和接口,这样接口和服务的元数据天然就是结构化的,接口和服务的引用依赖关系可以做到一目了然。由系统管理接口和服务后,可以添加更多维度的标签,如接口归属的业务线、服务归属的页面等,可为日常的管理提供更多维度的统计数据。
- 基于服务编排实现的需求,天然具有流程图属性,和编码的方式相比,我们对服务的功能逻辑、接口前后依赖关系、调用关系都能一目了然,对我们日常的问题排查提供了有力帮助。
留下评论