Kubernetes pod 组件
简介
- 简介
- What is a pod?
- 为什么需要pod?
- Pod Operations
- Pod 的运行
- kubectl drain 发生了什么
- 为什么pod中要有一个pause 容器?
- pod不只是一个概念
- 其它
Podman: Managing pods and containers in a local container runtimeMost people coming from the Docker world of running single containers do not envision the concept of running pods. 我们对pod的感觉不是很亲切一个原因是:它是k8s第一次引入的,从docker切到k8s本来就差异比较大,让人觉得pod和docker container是两个概念范畴。podman作为一个CRI 实现支持runnig pod locally
## 创建一个容器并将其 加入到demopod 中,实际还额外创建了一个类似k8s infra container
$ podman run -dt --pod demopod alpine:latest top
如果当年的学习路径是 docker container ==> podman pod ==> k8s pod,感觉就自然多了,碰到类似 docker run --link 之类的场景,就可以用local pod来实现。
“容器”镜像虽然好用,但是容器这样一个“沙盒”的概念,对于描述应用来说,还是太过简单了。Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段,将pod 单纯的理解为 多个容器 数字上的叠加 是不科学的。
What is a pod?
A pod models an application-specific “logical host(逻辑节点)” in a containerized environment. It may contain one or more containers which are relatively tightly coupled—in a pre-container world(在 pre-container 时代紧密联系的进程 ,在container 时代放在一个pod里), they would have executed on the same physical or virtual host.a pod has a single IP address. Multiple containers that run in a pod all share that common network name space。
Like running containers, pods are considered to be relatively ephemeral rather than durable entities. Pods are scheduled to nodes and remain there until termination (according to restart policy) or deletion. When a node dies, the pods scheduled to that node are deleted. Specific pods are never rescheduled to new nodes; instead, they must be replaced.
A pod is a relatively tightly coupled group of containers that are scheduled onto the same host.
- It models an application-specific(面向应用) “virtual host” in a containerized environment.
- Pods serve as units of scheduling, deployment, and horizontal scaling/replication.
- Pods share fate(命运), and share some resources, such as storage volumes and IP addresses.(网络通信和数据交互就非常方便且高效)
Pods can be used to host vertically integrated application stacks, but their primary motivation is to support co-located, co-managed (这两个形容词绝了)helper programs, such as:
- Content management systems, file and data loaders, local cache managers, etc.
- Log and checkpoint backup, compression, rotation, snapshotting, etc.
- Data-change watchers, log tailers, logging and monitoring adapters, event publishers, etc.
- Proxies, bridges, and adapters.
- Controllers, managers, configurators, and updaters.
Individual pods are not intended to run multiple instances of the same application, in general.
为什么需要pod?
本小节大部分来自对极客时间《深入剖析kubernetes》的学习
- 操作系统为什么要有进程组?原因之一是 Linux 操作系统只需要将信号,比如,SIGKILL 信号,发送给一个进程组,那么该进程组中的所有进程就都会收到这个信号而终止运行。
-
在 Borg 项目的开发和实践过程中,Google 公司的工程师们发现,他们部署的应用,往往都存在着类似于“进程和进程组”的关系。更具体地说,就是这些应用之间有着密切的协作关系,使得它们必须部署在同一台机器上。具有“超亲密关系”容器的典型特征包括但不限于:
- 互相之间会发生直接的文件交换
- 使用 localhost 或者 Socket文件进行本地通信
- 会发生非常频繁的远程调用
- 需要共享某些 Linux Namespace
- 亲密关系 ==> 亲密关系为什么不在调度层面解决掉?非得提出pod 的概念?容器设计模式
- Pod 这种“超亲密关系”容器的设计思想,实际上就是希望,当用户想在一个容器里跑多个功能并不相关的应用时,应该优先考虑它们是不是更应该被描述成一个 Pod 里的多个容器。你就可以把整个虚拟机想象成为一个 Pod,把这些进程分别做成分别做成容器镜像,把有顺序关系的容器,定义为 Init Container。 作者提到了tomcat 镜像和war 包(war包单独做一个镜像)的例子,非常精彩,好就好在 分别做镜像 肯定比 镜像做在一起要方便。重点不是pod 是什么,而是什么情况下, 我们要将多个容器放在pod 里。
- https://cloud.google.com/container-engine/docs Pods also simplify application deployment and management by providing a higher-level abstraction than the raw, low-level container interface. Pods serve as units of deployment and horizontal scaling/replication. Co-location, fate sharing, coordinated replication, resource sharing, and dependency management are handled automatically.
Pod Operations
Creating a pod
Pod,而不是容器,才是 Kubernetes 项目中的最小编排单位。将这个设计落实到 API 对象上,容器(Container)就成了 Pod 属性里的一个普通的字段。那么,一个很自然的问题就是:到底哪些属性属于 Pod 对象,而又有哪些属性属于 Container 呢?
Pod 扮演的是传统部署环境里“虚拟机”的角色。这样的设计,是为了使用户从传统环境(虚拟机环境)向 Kubernetes(容器环境)的迁移,更加平滑。而如果你能把 Pod 看成传统环境里的“机器”、把容器看作是运行在这个“机器”里的“用户程序”,那么很多关于 Pod 对象的设计就非常容易理解了。 比如,凡是调度、网络、存储,以及安全相关的属性,基本上是 Pod 级别的。这些属性的共同特征是,它们描述的是“机器”这个整体,而不是“机器”里的“用户程序”。
apiVersion: v1
kind: Pod...
spec:
nodeSelector:
hostAliases:
containers:
- name:
image:
lifecycle:
postStart:
exec:
command: ["/bin/sh","-c","echo hello world"]
preStop:
...
可以观察这些配置的位置,Pod的归Pod,容器的归容器。
Pod 的运行
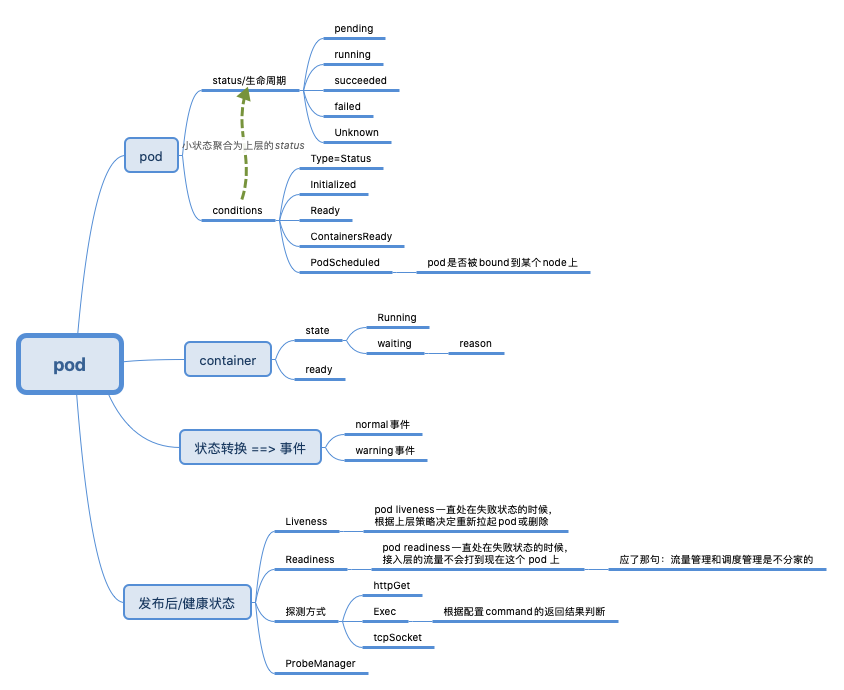
pod生命周期
pod的生命周期 Pod Lifecycle event.go
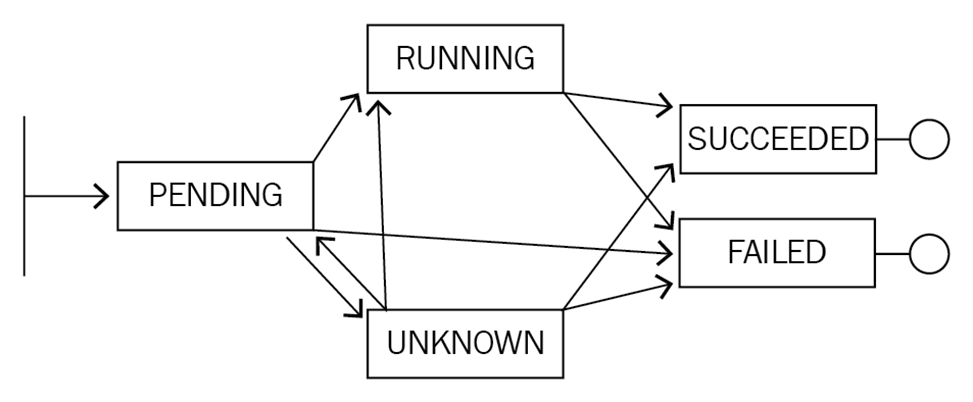
- Pending, API Server已经创建该Pod,且Pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程。
- Running, Pod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态。
- Succeeded, Pod内所有容器均成功执行退出,且不会重启。
- Failed, Pod内所有容器均已退出,但至少有一个容器退出为失败状态。
- Unknown, For some reason the state of the Pod could not be obtained, typically due to an error in communicating with the host of the Pod. 用户可以执行
kubectl delete pods <pod> --grace-period=0 --force强制删除 Pod
What the heck are Conditions in Kubernetes controllers? 值得细读。
- The conditions array is a set of types (Ready, PodScheduled…) with a status (True, False or Unknown) that make up the ‘computed state’ of a Pod at any time. the ‘conditions’ array is considered to be containing all the ‘ground truth’. The ‘phase’ just an abstraction of these conditions.
- Although conditions are a good way to convey information to the user, they also serve as a way of communicating between components (e.g., between kube-scheduler and apiserver) but also to external components (e.g. a custom controller that wants to trigger something as soon as a pod becomes ‘Unschedulable’, and maybe order more VMs to the cloud provider and add it as a node.
- The status of a Pod is not updated by a single Sync loop: it is updated by multiple components: the kubelet, and the kube-scheduler. Here is a list of the condition types per component: |Possible condition types for a Pod| Component that updates this condition type| |—|—| |PodScheduled| scheduleOne (kube-scheduler)| |Unschedulable| scheduleOne (kube-scheduler)| |Initialized| syncPod (kubelet)| |ContainersReady| syncPod (kubelet)| |Ready| syncPod (kubelet)|
容器状态及其它状态
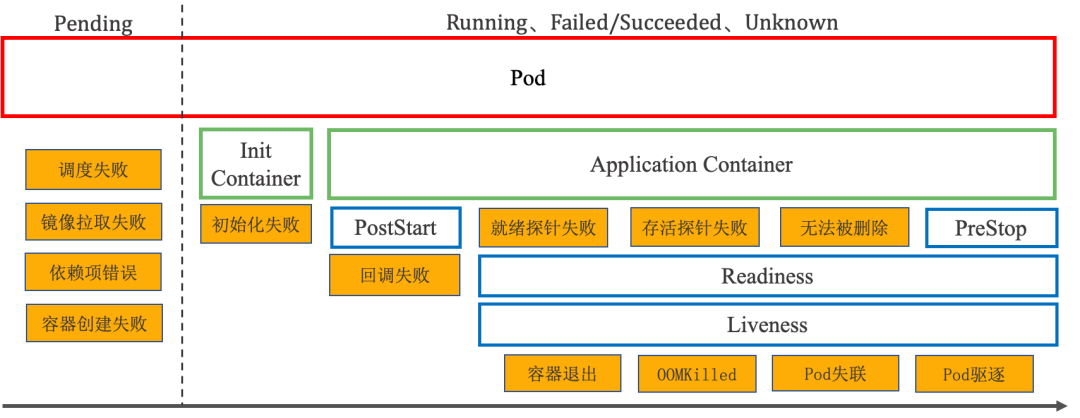
restartPolicy 和 Pod 里容器的状态,以及Pod 状态的对应关系(最终体现在kube get pod pod_name 时 status 的状态) 有一系列复杂的情况 ,可以概括为两条基本原则:
- 只要 Pod 的 restartPolicy 指定的策略允许重启异常的容器(比如:Always),那么这个 Pod 就会保持 Running 状态,并进行容器重启。否则,Pod 就会进入 Failed 状态 。
- 对于包含多个容器的 Pod,只有它里面所有的容器都进入异常状态后,Pod 才会进入 Failed 状态。在此之前,Pod都是 Running 状态。此时,Pod 的 READY 字段会显示正常容器的个数
Restart policyA PodSpec has a restartPolicy field with possible values Always, OnFailure, and Never. The default value is Always. restartPolicy applies to all Containers in the Pod. restartPolicy only refers to restarts of the Containers by the kubelet on the same node. Exited Containers that are restarted by the kubelet are restarted with an exponential back-off delay (10s, 20s, 40s …) capped at five minutes, and is reset after ten minutes of successful execution. 业务容器经常会因为内存不足发生oom,进而导致容器的重启,重启次数可以间接反映业务的健康状态。
// k8s.io/kubernetes/pkg/apis/core/types.go
type PodStatus struct {
Phase PodPhase
Conditions []PodCondition
Message string
Reason string
NominatedNodeName string
HostIP string
PodIPs []PodIP
StartTime *metav1.Time
QOSClass PodQOSClass
InitContainerStatuses []ContainerStatus
ContainerStatuses []ContainerStatus
EphemeralContainerStatuses []ContainerStatus
}
kubectl drain 发生了什么
Pod 驱逐分为两种情况:
- 较安全驱逐 & 提高稳定性的良性驱逐
- API 发起驱逐,典型案例:kubectl drain
- Node Not Ready 时,Controller Manager 发起的驱逐
- 有风险的驱逐
- 节点压力驱逐:节点磁盘空间不足、内存不足 或 Pid 不足, kubelet 发起驱逐;节点内存不足,内核发起 OOM
- 节点打污点(NoExecute),导致 Pod 被驱逐,或者移除亲和性标签,导致 Pod 被驱逐, Controller Manager 发起的驱逐
- Pod 超过自身 Limit 限制, 内核用满,临时存储用满等
- 优先级抢占驱逐
kubectl drain 将以某种方式驱逐 Pod。drain 将向控制平面发出删除目标节点上的 Pod 的请求。通过 API 将 Pod 从集群中删除后,所有发生的事情就是该 Pod 在元数据服务器中被标记为要删除。这会向所有相关子系统发送一个 Pod 删除通知
- 目标节点上的 kubelet 开始关闭 Pod。
- 节点上的 kubelet 将调用 Pod 中的 preStop 勾子。
- 一旦 preStop 勾子完成,节点上的 kubelet 将向 Pod 容器中正在运行的应用程序发出 TERM 信号。
- 节点上的 kubelet 将等待最多宽限期(在 Pod 上指定,或从命令行传递;默认为 30 秒)以关闭容器,然后强行终止进程(使用 SIGKILL)。请注意,此宽限期包括执行 preStop 勾子的时间。
- 所有节点上运行的 kube-proxy 守护程序将从 iptables 中删除 pod 的 ip 地址。
- endpoint 控制器将从有效 endpoint 列表中删除该 Pod,然后从 Service 中删除该 Pod。
这里的重点涉及多个系统,这些系统可能在不同的节点上运行,并且这些序列并行发生。因此,将 Pod 从所有活动列表中删除之前,Pod 很有可能运行 preStop 钩子并接收到 TERM 信号。
为什么pod中要有一个pause 容器?
Kubernetes networking 101 – Pods
all containers within a single pod share the same network namespace. 那么现在假设一个pod定义了三个容器(container1, container2, container3),你如何实现共享网络的效果呢?直接的想法:启动一个容器(比如container1),然后container2、container3 挂在container1上,但这样做有几个问题:
- Pod 里的多个容器就不是对等关系,而是拓扑关系了
- 启动顺序无法保证,正常都是先拉到谁的镜像就先启动哪个
- 假设container1 挂了(比如业务代码问题),则就殃及container2, container3 。
- 尤其container3 还没有启动的时候,container1 挂了,那container3 怎么办呢?
the pause container servers as an anchoring point for the pod and make it easy to determine what network namespace the pod containers should join. pause container 被称为 infrastructure container,中文有的文章简称 Infra 容器。Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。这个镜像是一个用汇编语言编写的、永远处于“暂停”状态的容器,解压后的大小也只有 100~200 KB 左右。PS:代码里start/stopSandbox 就是在操作pause 容器
#include <signal.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
static void sigdown(int signo) {
psignal(signo, "Shutting down, got signal");
exit(0);
}
// 当子进程退出时,新的父进程(init)必须调用wait来获取它的退出码,否则它的进程表条目将永远保留下来,成为僵死进程。
// pause假定自己为PID 1的角色,当僵尸进程被其父进程孤立时,会被pause容器进行收养,通过调用wait来获取/释放僵尸进程。这样一来就不会在Kubernetes pod的PID命名空间中堆积僵尸进程了。
static void sigreap(int signo) {
while (waitpid(-1, NULL, WNOHANG) > 0);
}
int main() {
if (getpid() != 1)
/* Not an error because pause sees use outside of infra containers. */
fprintf(stderr, "Warning: pause should be the first process\n");
// sigaction 负责注册信号处理函数
if (sigaction(SIGINT, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 1;
if (sigaction(SIGTERM, &(struct sigaction){.sa_handler = sigdown}, NULL) < 0)
return 2;
if (sigaction(SIGCHLD, &(struct sigaction){.sa_handler = sigreap,.sa_flags = SA_NOCLDSTOP},NULL) < 0)
return 3;
// 不执行任何函数,本质上永远休眠
for (;;)
pause();
fprintf(stderr, "Error: infinite loop terminated\n");
return 42;
}
vivo AI计算平台在线业务落地实践k8s 给 pod 提供了一个 shareProcessNamespace 特性,可以在 pod 内开启共享 PID 名称空间,将 pod 中的 1 号进程变成了 /pause,并在 /pause 进程中实现了对容器内其他进程的管理,从而避免出现僵尸进程。pod 内其他容器默认情况下不会共享 pause PID Namespace,如果不共享 PID Namespace,那其他容器内的僵尸进程就无法将其父进程变成 pause,pause 自然也回收不了其他容器的僵尸进程。
Pod 最重要的一个事实是:它只是一个逻辑概念。有了Pod,我们可以说Network Namespace和Volume 不是container A 的,也不是Container B的,而是Pod 的。。kubectl 创建 Pod 背后到底发生了什么?pause 容器作为同一个 Pod 中所有其他容器的基础容器,它为 Pod 中的每个业务容器提供了大量的 Pod 级别资源,这些资源都是 Linux 命名空间(包括网络命名空间,IPC 命名空间和 PID 命名空间)。
pod不只是一个概念
容器与Pod到底有什么区别和联系?Pod 的 cgroups 是什么样的?systemd-cgls 可以很好地可视化 cgroups 层次结构:
$ sudo systemd-cgls
Control group /:
-.slice
├─kubepods
│ ├─burstable
│ │ ├─pod4a8d5c3e-3821-4727-9d20-965febbccfbb
│ │ │ ├─f0e87a93304666766ab139d52f10ff2b8d4a1e6060fc18f74f28e2cb000da8b2
│ │ │ │ └─4966 /pause
│ │ │ ├─dfb1cd29ab750064ae89613cb28963353c3360c2df913995af582aebcc4e85d8
│ │ │ │ ├─5001 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
│ │ │ │ └─5016 /usr/bin/python3 /usr/local/bin/gunicorn -b 0.0.0.0:80 httpbin:app -k gevent
│ │ │ └─097d4fe8a7002d69d6c78899dcf6731d313ce8067ae3f736f252f387582e55ad
│ │ │ └─5035 /bin/sleep 3650d
...
所以,Pod 本身有一个cgroup父节点(Node),每个容器也可以单独调整。Pod 不仅仅是一组容器。Pod 是一个自给自足的高级构造。所有 Pod 的容器都运行在同一台机器(集群节点)上,它们的生命周期是同步的,并且通过削弱隔离性来简化容器间的通信。
留下评论