log4j学习
前言
首先明确几个日志框架的基本关系:slf4j log4j logback关系详解和相关用法
文章基本要点:slf4j是一系列的日志接口(slf4j由二十多个类组成,大部分是interface),而log4j、logback是具体实现了的日志框架。logback是直接实现了slf4j的接口,是不消耗内存和计算开销的。而log4j不是对slf4j的原生实现,所以slf4j api在调用log4j时需要一个适配层,比如slf4j-log4j12。
源码分析参见:Log4j源码解析–框架流程+核心解析,几个基本概念理的比较清楚。
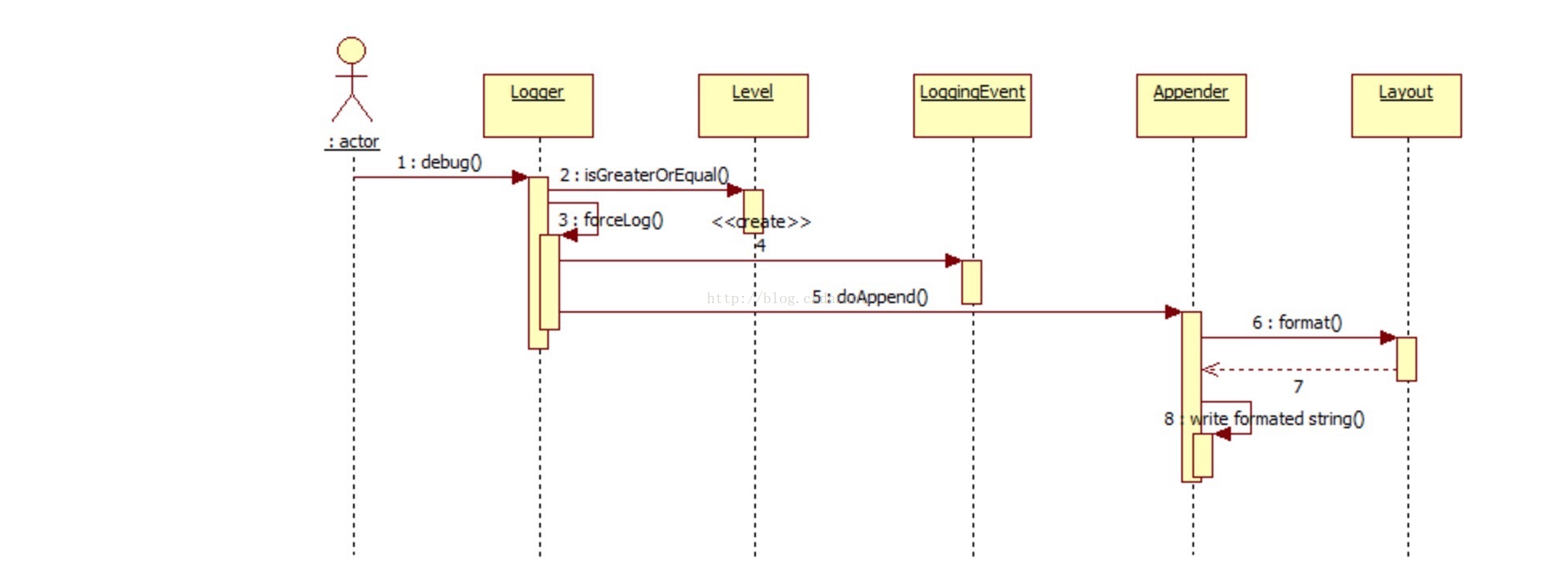
从中调整的几个误区
- LoggerRepository是Logger实例的容器,维护Logger name与Logger的映射关系。
- Logger 本身并不直接写日志到文件,Logger(准确的说是父类)聚合Appender实现类,Logger将日志信息弄成LogEvent,交给Appender写入。
打日志的哲学
2018.11.05 补充
技术攻关:从零到精通每个人都知道怎么打日志,但打一份好的日志,实际没有几个人能够做到的。一般来说,如果没有足够的重视,工程师打出来的日志,或者过于随意,或者逻辑缺失。一份好的日志其实要花很多精力来调整细节,把程序运行看成一个状态机,每一个关键的状态变化,都要在日志中记录。一份好的日志其实反映了一套好的程序逻辑。总之,打日志的目标是:如果线上发生奇怪的情况,拿过这份日志来就能分析出问题所在。这在客户端上分析线上问题的时候尤其有用。
系统日志规范及最佳实践 未读。
问题
The org.slf4j.Logger interface is the main user entry point of SLF4J API. slf4j 定好了Logger和LoggerFactory实现,最直观的感觉,为什么不是Logger.debug(),Logger.info()直接写到文件就好了呢?
为什么Logger需要一个name,为什么Logger要做成多例的?
Logger name是一个Logger日志输入目的地、日志级别及日志格式的描述,在一个系统中有多重配置。
从中可以学习到:那么类似的一个实例,通过配置文件读取,Logger、LoggerRepository(log4j中貌似功能有点弱化)、LoggerFactory、LoggerManager协同工作,达到Logger log = LoggerFactory.getLogger(name)效果。并根据配置文件变化,及时刷新。
配置文件理解
一个全套的logger配置如下
log4j.logger.logger_name = debug_level1,appender_name1,appender_name2
log4j.appender.appender_name1= appender_class_name
log4j.appender.appender_name1.layout= layout_class_name
...
log4j.logger.org.springframework=DEBUG单独出现便不算全套,这里org.springframework便表示logger name,其没有配置appender,便复用rootLogger的appender。
从中可以学习到如何用properties文件描述
- logger与level多对一关系
- logger与appender的一对多关系
- appender与layout的一对多关系
初始化过程
LogManager
static {
1. 若设置DEFAULT_INIT_OVERRIDE_KEY为true,则放弃默认的初始化过程
2. 按log4j.xml、log4j.properties和log4j.configuration 顺序尝试读取配置文件
3. 读取环境变量configuratorClassName设置的配置类,默认为PropertyConfigurator
4. configurator.doConfigure(url, hierarchy);
}
自定义初始化过程
通过初始化过程分析,那么自定义log4j的初始化过程的本质便是:自己触发执行doConfigure(Properties properties, LoggerRepository hierarchy),doConfigure多次执行,会覆盖先前的配置。
tomcat 日志
2018.4.25 补充
tomcat中的几种log 要点如下:
- catalina.out,catalina.out其实是tomcat的标准输出(stdout)和标准出错(stderr)。如果我们在应用里使用其他的日志框架,配置了向Console输出的,则也会在这里出现。
- catalina.{yyyy-MM-dd}.log是tomcat自己运行的一些日志,这些日志还会输出到catalina.out,但是应用向console输出的日志不会输出到catalina.{yyyy-MM-dd}.log。
- localhost.{yyyy-MM-dd}.log主要是应用初始化(listener, filter, servlet)未处理的异常最后被tomcat捕获而输出的日志,而这些未处理异常最终会导致应用无法启动。Spring的初始化我们往往是使用Spring提供的一个listener进行的,而如果Spring初始化时因为某个bean初始化失败,导致整个应用没有启动,这个时候的异常日志是输出到localhost中 ==> 初始化失败应该去查看下 localhost 日志。
日志系统使用规范
兼容性问题
slf4j兼容commons-logging,log4j,java.util.logging,支持log4j.xml和log4j.properties配置
如果你开发的是类库或者嵌入式组件,那么就应该考虑采用SLF4J,因为不可能影响最终用户选择哪种日志系统。
日志框架的性能问题
2017.12.23补充:有反馈称log4j2 性能更好,log4j在一定程度的负载下性能会急剧下降,成为瓶颈点。
2019.1.30补充:日志记录期间分配临时对象,如日志事件对象,字符串,字符数组,字节数组等,这会对垃圾收集器造成压力并增加GC暂停发生的频率。具体事例参见 java gc 中 log.debug(JSON.toJSONString(object)) 导致频繁fullgc 的例子
该让log4j退休了 - 论Java日志组件的选择log4j2实现了“无垃圾”和“低垃圾”模式。简单地说,log4j2在记录日志时,能够重用对象(如String等),尽可能避免实例化新的临时对象,减少因日志记录产生的垃圾对象,减少垃圾回收带来的性能下降
留下评论