Flink学习
前言
Spark Streaming 是将实时数据流按时间分段后,当作小的批处理数据去计算。那么 Flink 则相反,一开始就是按照流处理计算去设计的。当把从文件系统(HDFS)中读入的数据也当做数据流看待,他就变成批处理系统了。
《大数据处理实战》spark RDD 是否就是完美无缺的呢?显然不是,它还是很底层,不方便开发者使用,而且用 RDD API 写的应用程序需要大量的人工调优来提高性能。Spark SQL 提供的 DataFrame/DataSet API 就解决了这个问题,它提供类似 SQL 的查询接口,把数据看成关系型数据库的表,提升了熟悉关系型数据库的开发者的工作效率。Spark 是怎样支持流处理的呢?Spark Streaming 和新的 Structured Streaming,其中 Structured Streaming 也可以使用 DataSet/DataFrame API,这就实现了 Spark 批流处理的统一。Spark 有什么缺点?流处理的实时性还不够,所以无法用在一些对实时性要求很高的流处理场景中。这是因为 Spark 的流处理是基于所谓微批处理(Micro-batch processing)的思想,即它把流处理看作是批处理的一种特殊形式,每次接收到一个时间间隔的数据才会去处理,所以天生很难在实时性上有所提升。想要在流处理的实时性上提升,就不能继续用微批处理的模式,而要想办法实现真正的流处理,即每当有一条数据输入就立刻处理,不做等待。
流式处理系统的演变
聊到现代流式数据处理, 谷歌大神 Tyler Akidau 在2015年8月关于流式计算写了两篇博客(Streaming 101: 批处理之上的世界(一), Streaming 102: 批处理之上的世界(二)(上), Streaming 102: 批处理之上的世界(二)(下), 【总结】批处理之上的世界(二)),后来写了《Streaming System》一书。它探索了四个问题:
- 【What】流式数据处理系统计算出什么结果?结果由pipeline的转换器决定。转换器好比MapReduce中的Mapper、Reducer函数,Spark中的transform算子。
- 【where】流式数据的结果在哪里计算?流式数据由事件构成,根据事件时间,流式数据可以切分成一个个窗口,把无界数据变成有界数据,计算在窗口中完成。
- 【when】计算结果何时输出?水位线或触发器触发输出。水位线表示属于某个窗口时间范围的事件全部到达,如果需要在水位线之前输出结果,或者水位线之后,还有迟到的事件需要计算,需要触发器的帮助。
- 【How】如果修正计算结果?一个窗口的结果会被计算多次。每次计算结果可以独立地发送到下游,也可以更新之前计算的结果,还可以把之前的结果丢弃,再发送新的结果。
我们需要一个流式系统,能够达成三点目标:
- 数据的正确性,“正好一次”的数据处理机制,要做到这一点,我们需要在流式数据系统里,内置一个数据去重的机制。
- 系统的容错能力,把计算节点需要使用的“状态”信息持久化下来。这样,我们才能够做到真正的容错,而不是在系统出错的时候丢失一部分信息。而且,这个机制也有助于我们在线扩容。
- 对于时间窗口的正确处理,也就是能够准确地根据事件时间生成报表,而不是简单地使用进行处理的服务器的本地时间。并且,还需要能够考虑到分布式集群中,数据的传输可能会有延时的情况出现。把流式数据处理的时间窗口,以及触发机制内置到流式处理系统里面去。这样,我们就可以让我们的业务代码,专注于实现业务逻辑,而不是需要自己在应用代码里,搞一套时间窗口的维护和触发机制。
我们希望能有一个流式处理系统,帮助我们解决这些问题。我们并不希望,自己在写 Storm 的 Spout 代码的时候,写上一大堆代码,来解决正好一次的数据处理、Spout 中间状态的持久化,以及针对时间窗口的处理逻辑。因为这些问题,是流式数据处理的共性问题。
dataflow模型
2015 年,Google发表了一篇《The Dataflow Model》的论文。 Dataflow(三):一个统一的编程模型
Dataflow 的核心计算模型非常简单,它只有两个概念
- 一个叫做 ParDo,顾名思义,也就是并行处理的意思。地位相当于 MapReduce 里的 Map 阶段。所有的输入数据,都会被一个 DoFn,也就是处理函数处理。但是这些数据,不是在一台服务器上处理的,而是和 MapReduce 一样,会在很多台机器上被并行处理。只不过 MapReduce 里的数据处理,只有一个 Map 阶段和一个 Reduce 阶段。而在 Dataflow 里,Pardo 会和下面的 GroupByKey 组合起来,可以有很多层,就好像是很多个 MapReduce 串在一起一样。
- 另一个叫做 GroupByKey,也就是按照 Key 进行分组数据处理的问题。地位则是 MapReduce 里的 Shuffle 操作。在 Dataflow 里,所有的数据都被抽象成了 key-value 对。前面的 ParDo 的输入和 Map 函数一样,是一个 key-value 对,输出也是一系列的 key-value 对。而 GroupByKey,则是把相同的 Key 汇总到一起,然后再通过一个 ParDo 下的 DoFn 进行处理。
比如,我们有一个不断输入的日志流,想要统计所有广告展示次数超过 100 万次的广告。那么,我们可以先通过一个 Pardo 解析日志,然后输出(广告 ID,1)这样的 key-value 对,通过 GroupByKey,把相同的广告 ID 的数据分组到一起。然后再通过一个 ParDo,并行统计每一个广告 ID 下的展示次数。最后再通过一个 ParDo,过滤掉所有展示次数少于 100 万次的广告就好了。
流批一体:在 MapReduce 的计算模型下,会有哪些输入数据,是在 MapReduce 的任务开始之前就确定的。这意味着数据从 Map 端被 Shuffle 到 Reduce 端,只依赖于我们的 CPU、网络这些硬件处理能力。而在 Dataflow 里,输入的数据集是无边界的,随着时间的推移,不断会有新的输入数据加入进来。如果从这个角度来思考,那么我们之前把大数据处理分成批处理和流式处理,其实并没有找到两种数据处理的核心差异。因为,对于一份预先确定、边界明确的数据,我们一样可以使用流式处理。比如,我们可以把一份固定大小日志,放到 Kakfa 里,重放一遍给一个 Storm 的 Topology 来处理,那也是流式处理,但这是处理的有边界的数据。而对于不断增长的实时数据,我们一样可以不断定时执行 MapReduce 这样的批处理任务,或者通过 Spark Streaming 这样看起来是流式处理,其实是微批(Mini-Batch)的处理方式。
在 Dataflow 的论文里,Google 把整个大数据的流式处理,抽象成了三个概念。
- 是对于乱序数据,能够按照事件发生时间计算时间窗口的模型。在 Dataflow 模型里,需要的不只是 GroupByKey,实际在统计数据的时候,往往需要的是 GroupByKeyAndWindow。统计一个不考虑任何时间窗口的数据,往往是没有意义的。每一个原始的事件,在我们的业务处理函数之前,其实都是(key, value, event_time)这样一个三元组。而 AssignWindows 要做的,就是把这个三元组,根据我们的处理逻辑,变成
(key, value, event_time, window)这样的四元组。需要注意,一个事件不只可以分配给一个时间窗口,而是可以分配给多个时间窗口。比如,我们有一个广告在 12:01 展示给了用户,但是我们统计的是“过去 2 分钟的广告展示”,那么这个事件,就会被分配给[12:00, 12:02) 和[12:01, 12:03) 两个时间窗口,我们原先一条的事件就可以变成多条记录。有了 Window 的信息之后,如果我们想要按照固定窗口或者滑动窗口统计数据,我们可以很容易地根据 Key+Window 进行聚合,完成相应的计算。窗口的分配和合并功能,就使得 Dataflow 可以处理乱序数据。相同的数据以不同的顺序到达我们的计算节点,计算的结果仍然是相同的。 - 根据数据处理的多维度特征,来决定计算结果什么时候输出的触发器模型。我们会遇到延时、容错等情况,所以我们还需要有一个机制告诉我们,在什么时候数据都已经到了,我们可以把计算结果向下游输出了。在 Dataflow 里,除了内置的基于水位信息的完成度触发器,它还能够支持基于处理时间、记录数等多个参数组合触发。而且用户可以实现自定义触发器,完全根据自己的需要来实现触发器逻辑。
- 能够把数据的更新和撤回,与前面的窗口模型和触发器模型集成的增量处理策略。
使用
public class KafkaExample {
public static void main(String[] args) throws Exception {
// parse input arguments
final ParameterTool parameterTool = ParameterTool.fromArgs(args);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000));
env.enableCheckpointing(5000); // create a checkpoint every 5 seconds
env.getConfig().setGlobalJobParameters(parameterTool); // make parameters available in the web interface
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<KafkaEvent> input = env .addSource(
new FlinkKafkaConsumer<>(
parameterTool.getRequired("input-topic"),
new KafkaEventSchema(),
parameterTool.getProperties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()))
.keyBy("word")
.map(new RollingAdditionMapper())
.shuffle();
input.addSink(
new FlinkKafkaProducer<>(
parameterTool.getRequired("output-topic"),
new KeyedSerializationSchemaWrapper<>(new KafkaEventSchema()),
parameterTool.getProperties(),
FlinkKafkaProducer.Semantic.EXACTLY_ONCE));
env.execute("Modern Kafka Example");
}
}
理论基础来自谷歌论文 《The dataflow model:A pracitical approach to balancing correctness,latency, and cost in massive-scale,unbounded,out-of-order data processing》
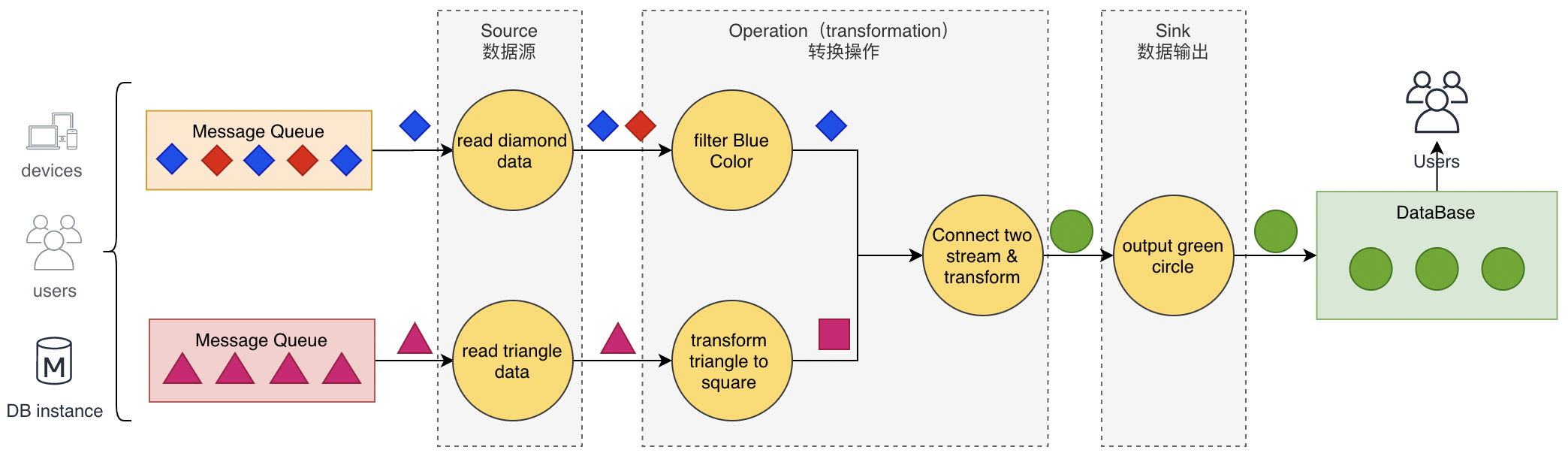
- 数据从上一个Operation节点直接Push到下一个Operation节点。
- 各节点可以分布在不同的Task线程中运行,数据在Operation之间传递。
- 具有Shuffle过程,数据从上游Operation push 到下游Operation,不像MapReduce模型,Reduce从Map端拉取数据。
- 实现框架有ApacheStorm和ApacheFlink以及ApacheBeam。
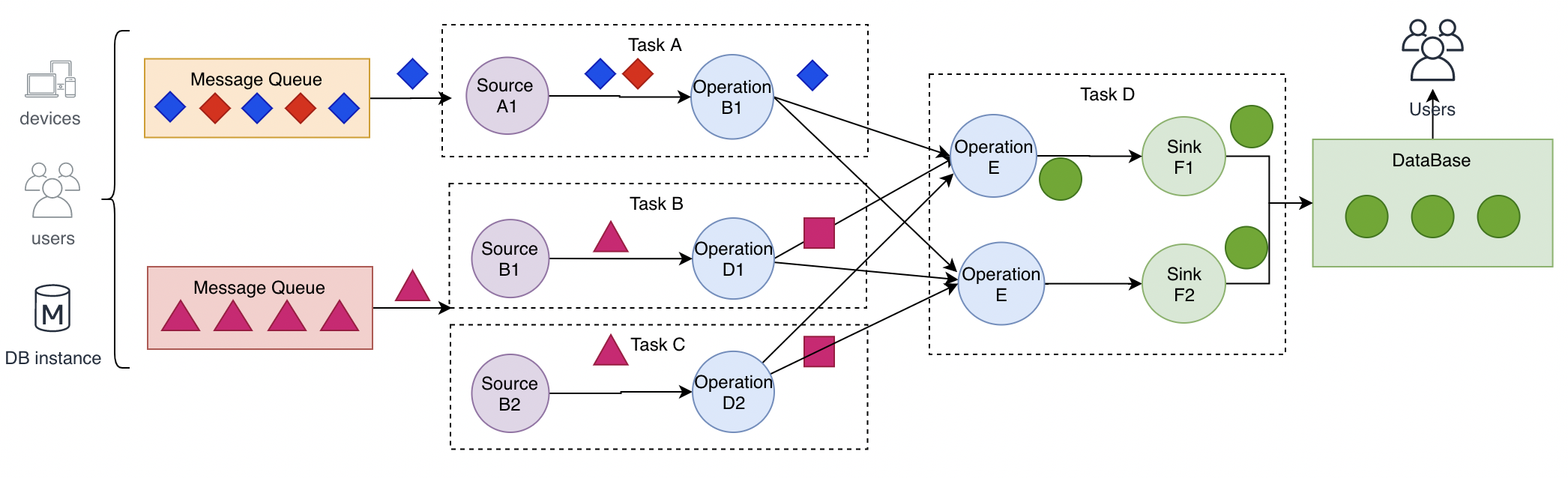
DataStream API
- source
- sink
- 转换操作
- 基于单条记录filter/map
- 基于窗口 window
- 多流合并 union join connect
- 单流切分 split
-
DataStream 之间的转换
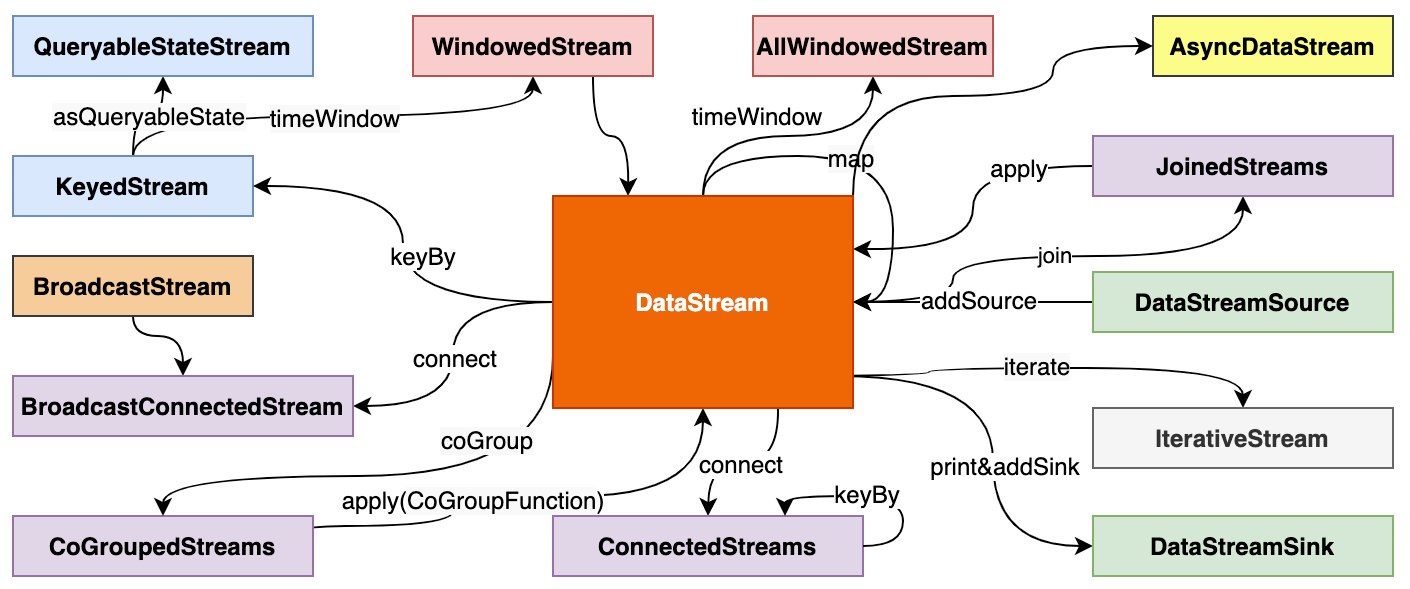
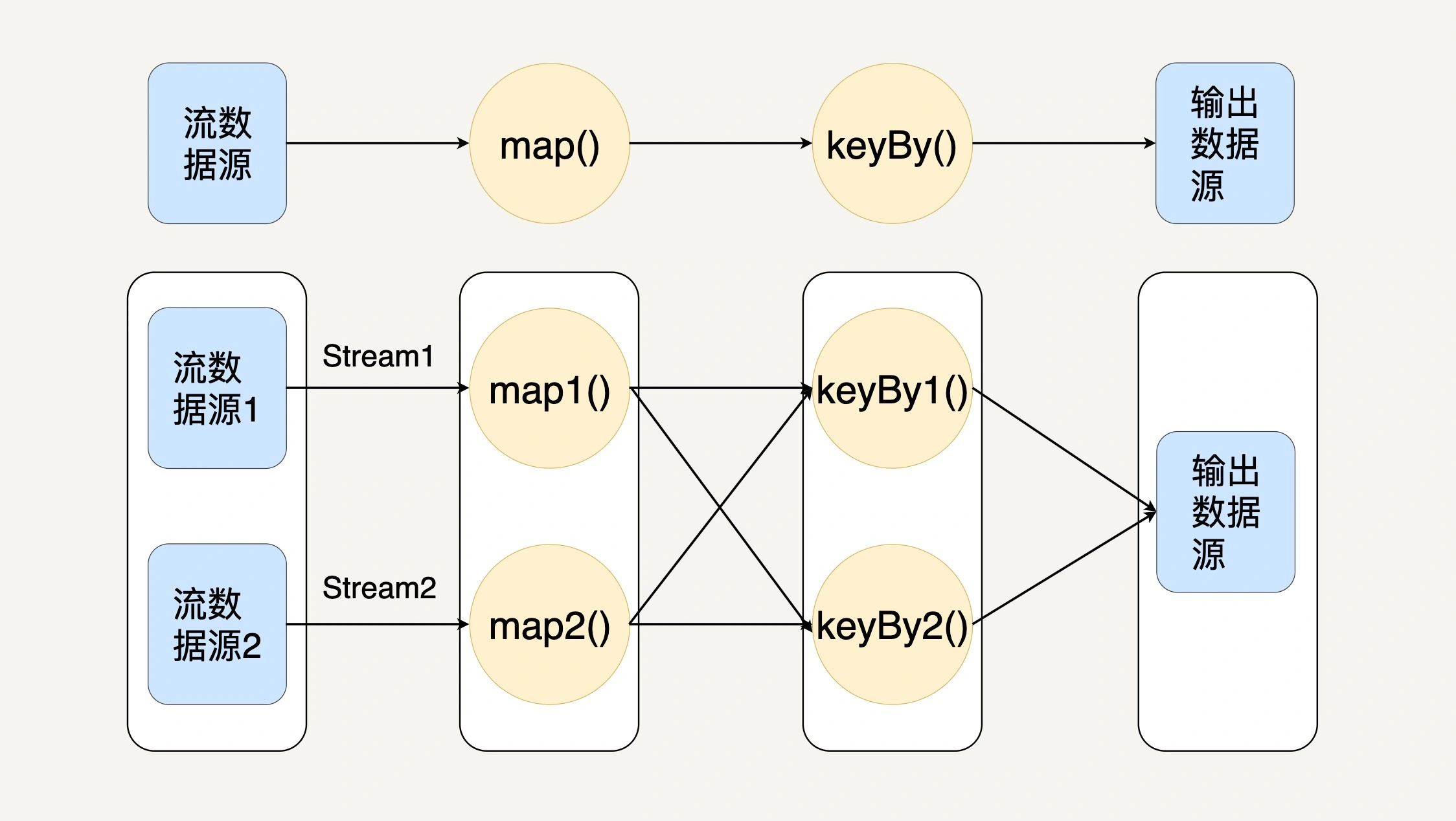
设计
Flink 中最核心的数据结构是 Stream,它代表一个运行在多个分区上的并行流。在 Stream 上同样可以进行各种转换操作(Transformation)。与 Spark 的 RDD 不同的是,Stream 代表一个数据流而不是静态数据的集合。所以,它包含的数据是随着时间增长而变化的。而且 Stream 上的转换操作都是逐条进行的,即每当有新的数据进来,整个流程都会被执行并更新结果。
flink采用了基于操作符(Operator)的连续流模型,当一个 Flink 程序被执行的时候,它会被映射为 Streaming Dataflow,Streaming Dataflow 包括 Stream 和 Operator(操作符)。转换操作符把一个或多个 Stream 转换成多个 Stream。每个 Dataflow 都有一个输入数据源(Source)和输出数据源(Sink)。与 Spark 的 RDD 转换图类似,Streaming Dataflow 也会被组合成一个有向无环图去执行。在 Flink 中,程序天生是并行和分布式的。一个 Stream 可以包含多个分区(Stream Partitions),一个操作符可以被分成多个操作符子任务,每一个子任务是在不同的线程或者不同的机器节点中独立执行的。
实现
浓浓的tf 提交dag的味道,区别是flink 和spark 一样是集群先跑起来,再提交任务。中间设计到graph 拆分为task 、调度task 到具体TaskManager的过程。
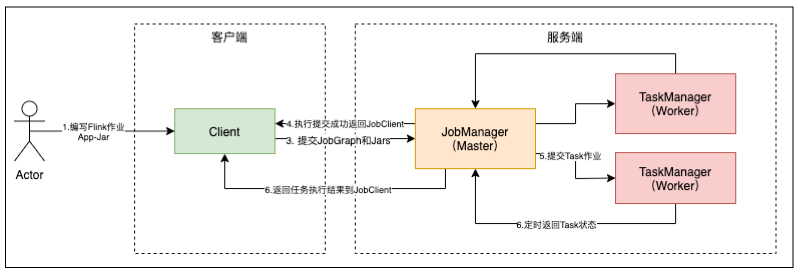
- JobManager 管理节点,每个集群至少一个,管理整个集群计算资源,Job管理与调度执行,以及 Checkpoint 协调。
- TaskManager :每个集群有多个TM ,负责计算资源提供。
- Client :本地执行应用 main() 方法解析JobGraph 对象,并最终将JobGraph 提交到 JobManager 运行,同时监控Job执行的状态。
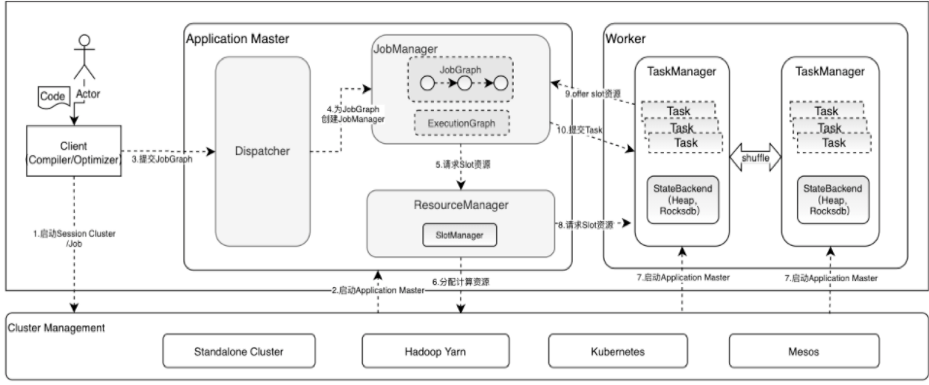
dispatcher 任务调度
- 一个jobGraph 对应一个 jobManager(JobMaster) 双层资源调度
- cluster -> job, slotManager 会给 jobGraph 对应的jobManager 分配多个slot (slotPool)
- job -> task, 单个slot 可以用于一个或多个task 执行; 但相同的task 不能在一个slot 中运行
Flink 四种 Graph 转换
- 第一层: Program -> StreamGraph。算子之间的拓扑关系。
- 第二层: StreamGraph -> JobGraph。 不涉及数据跨节点交换 的Operation 会组成 OperatorChain(最终在一个task 里运行)
- 第三层: JobGraph -> ExecutionGraph
- 第四层: Execution -> 物理执行计划
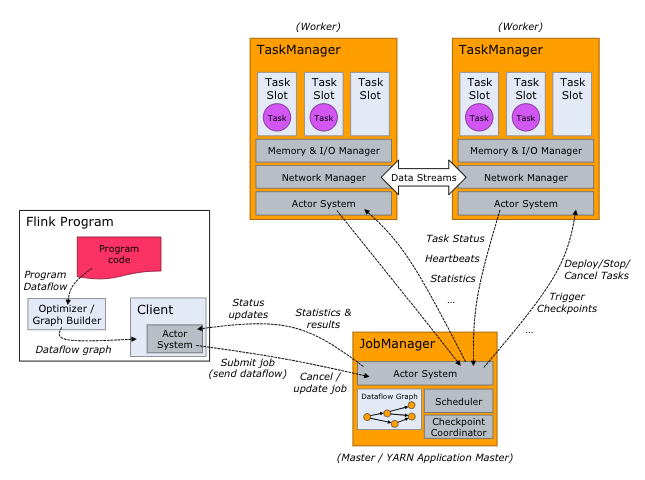
为什么 Flink 既可以流处理又可以批处理呢?
Flink 是一个面向有限流和无限流有状态计算的分布式计算框架,它能够支持流处理和批处理两种应用类型。在传统意义上,Flink 是一个无限的数据流。但如果我们用一个个的时间窗口把无限的数据流进行切分,我们就得到很多有限数据流,对 Flink 来说,批式数据只是流式数据的一种特例。无论是无限数据流还是有限处理流,Flink 都可以通过同一种 API、同一套代码进行处理之后,服务下游的数据。这样的流程也可以极大地减少工程师的学习和维护成本。可以说,Flink 无论是从上层的代码层面、SDK 层面、API 层面,还是下层的调度器层面,都是针对流批一体的整体架构来进行设计的,是可以从上至下完整地支持流批一体的数据处理引擎。
Flink 提供的两个核心 API 就是 DataSet API 和 DataStream API。你没看错,名字和 Spark 的 DataSet、DataFrame 非常相似。顾名思义,DataSet 代表有界的数据集,而 DataStream 代表流数据。Flink 这样基于流的模型是怎样支持批处理的?在内部,DataSet 其实也用 Stream 表示,静态的有界数据也可以被看作是特殊的流数据,而且 DataSet 与 DataStream 可以无缝切换。所以,Flink 的核心是 DataStream。
如果要进行流计算,Flink 会初始化一个流执行环境 StreamExecutionEnvironment,然后利用这个执行环境构建数据流 DataStream。
StreamExecutionEnvironment see = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<WikipediaEditEvent> edits = see.addSource(new WikipediaEditsSource());
如果要进行批处理计算,Flink 会初始化一个批处理执行环境 ExecutionEnvironment,然后利用这个环境构建数据集 DataSet。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet text = env.readTextFile("/path/to/file");
然后在 DataStream 或者 DataSet 上执行各种数据转换操作(transformation),这点很像 Spark。不管是流处理还是批处理,Flink 运行时的执行引擎是相同的,只是数据源不同而已。
演进——流批一体
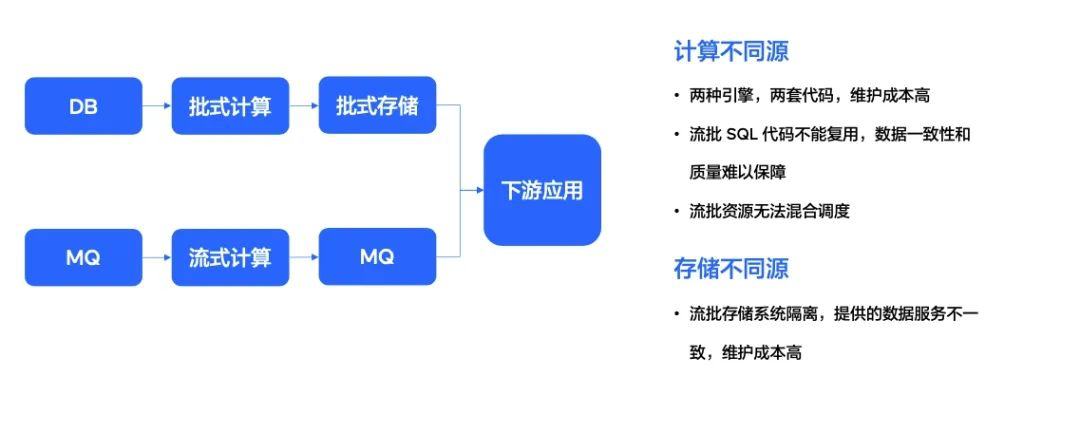
上图是一个非常典型,业界应用也很多的数据链路图。这个数据链路是典型的 Lamda 架构,整个数据链路分为批式计算链路和流式计算链路。在字节跳动内部,通常需要批式计算和流式计算两条链路共同服务于下游的应用。
- 在批式计算链路中,我们主要应用 Spark 引擎,通过 Spark 引擎在批式存储中拿到数据,经过 ETL 的计算后,存入下游的存储,从而服务下游的应用。
- 流式计算链路,也是我们整个实时推荐、实时信息流的核心链路。我们会通过消息中心件把实时数据进行缓存存入,然后运用 Flink 实时计算引擎进行处理,处理后经过消息中间件的缓存传输存入下游的存储,来服务下层的应用。
整个计算架构分成两条链路,带来了两个比较严重的问题:
- 计算不同源
- 维护成本高。批式计算主要使用 Spark 引擎,流式计算使用 Flink 引擎。维护两套引擎就意味着使用两套代码,工程师的维护成本和学习成本都非常高。
- 数据一致性和质量难以保障。两套代码之间不能相互复用,所以数据的一致性和数据的质量难以保障。
- 无法混合调度造成资源浪费。批式计算和流式计算的高峰期是不同的。对流式计算来说,用户的使用高峰期一般是白天或凌晨12点之前,那么这些时间段也就是流式计算的高峰,此时对计算资源的需求是非常高的。相对而言,批式计算对运算时间并没有严格的限制,比如可以在凌晨12点之后到早上6、7点之间进行大量运算。所以,如果流式计算和批式计算的资源无法进行混合调度,那么就无法对运算资源进行错峰使用,造成资源的巨大浪费。
- 存储不同源
- 数据不一致,维护成本高。如果两条链路同时服务于下游应用的话,那么两套存储系统也是分隔开的,依然存在数据不一致的问题。同时,维护流式、批式两套存储系统的成本也非常高。
那么,什么是流批一体呢?
- 从计算层面来讲,就是用同一个引擎、同一套代码及同样的 API ,同时处理有限的数据流和无限的数据流,同时应对在线处理和离线处理(其中有限数据的处理对应离线处理,而无限数据的处理则对应在线处理),达到降本增效的目的。
- 在存储方面,流批一体即存储系统能够同时满足流式数据和批式数据的存储,并能够有效地进行协同以及元数据信息的更新。
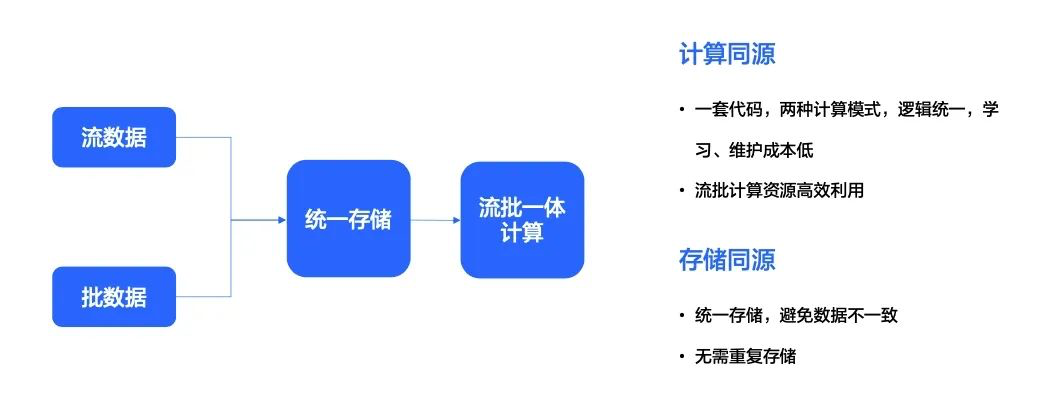
无论是流式数据还是批式数据,都可以直接或经过简单加工后存入统一存储中。而后,使用流批一体统一的计算引擎进行 ETL 计算,再服务下游的应用。由此,整个流批一体的架构实质上实现了计算同源和存储同源。
- 计算同源。用一套代码、一套逻辑去处理流式任务和批式任务,达到了降本增效的目的,同时也大幅提升了资源利用率。
- 存储同源。在存储方面统一存储,避免了存储资源的浪费,同时也在很大的程度上避免了数据不一致。
在字节跳动,我们使用 Flink 作为流批一体统一的计算引擎,Iceberg 作为流批一体统一的存储方式。
其它
流式处理,支持一条一条处理, 对于扩展operation,spark/flink client 会把main代码 和 jar 打包成一个package 上传到Master,jobGraph上附带job 相关的自定义jar信息, taskManager 执行task 前下载 相应的jar (然后由classloader)加载执行,而tf 因为其特殊性 就只能自定义op了。
蚂蚁实时计算团队的AntFlink提交攻坚之路 如何减少提交任务的耗时? Blink提交采用进程模型(包装flink info/run命令)进行作业执行计划的生成和作业的提交,这个基本是大数据计算引擎jstorm/spark/flink的共识,采用该方式的优点在于:
- 简单:
- 用户只需在自己的jar包中进行逻辑处理
- 引擎client负责以方法调用形式调用用户main方法,然后编译、提交
- 干净
- 进程模型用户包用完销毁,引擎版本包通过目录隔离,不用考虑多版本问题。
但这也带来了缺点,每次都得走一遍大量class 加载、校验等jvm启动全流程。同时,大多数作业的的执行计划生成耗时是在20秒以内,也就是说此时瓶颈不在编译阶段,此时jvm启动开销就成为了瓶颈。尤其当这些操作极其高频时,带来的开销不容小视。
留下评论