大模型训练和推理
简介
第一视角:深度学习框架这几年 作者深度参与了tf 等几个框架,对很多事情有独到的了解
什么是大模型
TensorFlow在推荐系统中的分布式训练优化实践随着美团业务的发展,推荐系统模型的规模和复杂度也在快速增长,具体表现如下:
- 训练数据:训练样本从到百亿增长到千亿,增长了近10倍。在内存中默认float32格式的1个参数占据4个字节,比如BLOOM或OPT-176B(有1760亿个参数),需要大概1.4TB的内存空间。
- 稀疏参数:个数从几百到几千,也增长了近10倍;总参数量(也就是tf.Variable)从几亿增长到百亿,增长了10~20倍。
- 模型复杂度:越来越复杂,模型单步计算时间增长10倍以上。 对于大流量业务,一次训练实验,从几个小时增长到了几天,而此场景一次实验保持在1天之内是基本的需求。
深度学习分布式训练的现状及未来大模型主要分为两类:
- 稀疏大模型:搜索、推荐、广告类任务,它的特点是海量样本及大规模稀疏参数(sparse embeddings),适合使用 CPU/GPU 参数服务器模式(PS);参数服务器模式从第一代 Alex Smola 在 2010 年提出的 LDA(文本挖掘领域的隐狄利克雷分配模型),到第二代 Jeff Dean 提出的 DistBelief,接着到第三代李沐提出的相对成熟的现代 Parameter Server 架构,再到后来的百花齐放:Uber 的 Horvod,阿里的 XDL、PAI,Meta 的 DLRM,字节的 BytePs、美团基于 Tensorlow 做的各种适配等等。参数服务器的功能日趋完善,性能也越来越强,有纯 CPU、纯 GPU,也有异构模式。
- 一般包含前面的稀疏特征的嵌入(embedding)和后面的稠密模型这两个部分。其中,稀疏特征的嵌入计算是稀疏大模型的关键,而稠密模型部分一般往往较小,可以放到一个GPU内,因此可以进行data并行以及all reduce通讯。
- 在训练中,在特征嵌入表(embedding table)上需要进行复杂的查找、排列等操作,然后生成张量再做稠密模型的计算。特征嵌入表往往会占用非常大的存储空间,需要很多台GPU服务器才能完整存放,这就是典型的tensor并行。在这样的场景下,就会导致典型的alltoall的通讯模式,而alltoall通讯会带来严重的incast通讯(多打一),进而带来网络拥塞,给网络架构、拥塞控制协议、负载均衡算法等都提出了很高的要求。
- 稠密大模型:CV、NLP 任务,它的特点是常规样本数据及大规模稠密参数,它适合用纯 GPU 集合通信模式(Collective)。基于纯 GPU 的集合通信模式的分布式训练框架,伴随着 Nvidia 的技术迭代,特别是 GPU 通信技术(GPU Direct RDMA)的进步,性能也变得愈来愈强。
- 由于模型参数非常多,远远超过了单个GPU显存所能容纳的空间(NVIDIA最新的A100也就是80GB显存),所以往往既需要对模型某一层的tensor并行,也需要不同层之间的pipeline并行,才能放得下整个大模型。
- 这里面的通讯,既有机内通讯,也有机间通讯,具体的通讯模式取决于模型的切分和放置方法。
- 为了加速训练过程,往往完整的大模型之间也会采用data并行,每一个完整的大模型会被投喂不同的训练数据,这就会导致大家熟悉的allreduce通信模式。 总结起来,稠密大模型和稀疏大模型在模型特征上有着明显的差异,对计算/存储/通信资源的需求也存在明显的不同。要达到GPU算力资源的最大化利用和最好的加速效果,需要结合模型特征和实现方式对GPU服务器架构、网络架构、训练数据存储和拉取、分布式训练框架进行全局的考量和设计。
广告推荐中大规模分布式模型 为啥一两百类的特征,我们却总是听说大规模特征?举个例子,用户 userid 这一维特征,比如系统中用户有1亿个,那么每个 id 实际上也可以当做一个独立的特征对待。这样一算,特征规模就上去了。这里就要重新理解 embedding 的概念了。对于模型而言,id 查了embedding表后得到向量,输入进来进行计算,是对数据进行抽特征。如果类比到图像分类,抽取 rgb 特征来分类 (一个值变成 3个255)
参数量卷到一百万亿!华人团队开源史上最大的推荐训练系统Persia 一般来说,推荐系统模型首先需要将不同的ID特征(如用户ID和session ID)映射到一个固定长度的低维向量,而系统中的用户ID、交叉特征数量都特别多,就需要更大规模的模型来捕获特征和映射。但更大规模的embedding layer也需要更大的内存来载入,不得不说大模型太费钱了!
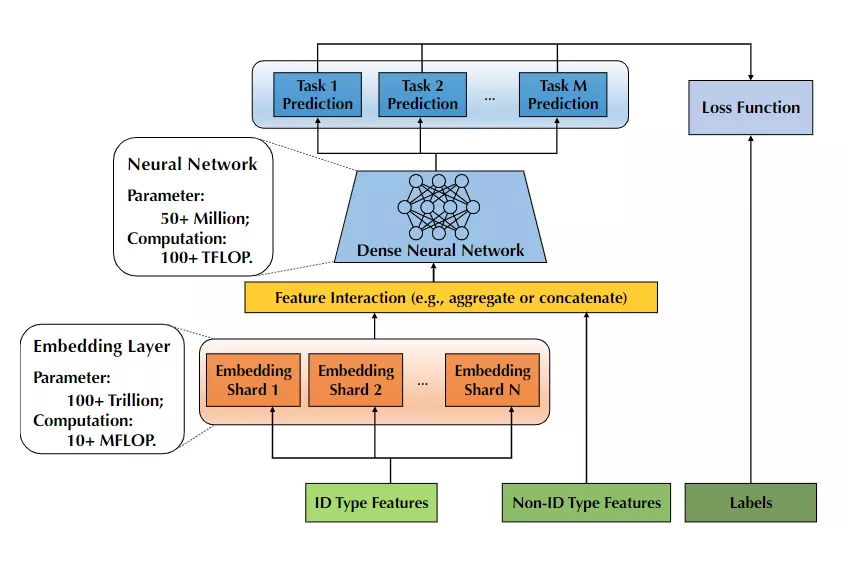
有了embedding后,剩下的工作就简单了,设计后续layer来适配不同的任务。通常只占据整个模型的0.1%,无需大内存,主要是一些计算密集型的工作。
在实现上
- 推理服务在运行时 也会访问ps (distributed inference),根据 ID feature 查询对应的 embedding 向量。当然,有的框架直接将 ps 组件的功能内嵌到各个worker 上了。
- 针对 大模型 包含 embedding layer的场景,input 层和 embedding 层之间不是全连接的,而是一个 embedding_lookup 的Op
- 常规的dense 模型,input是一个一维向量。 针对多个id feature,为了 确保与模型的input 层对齐,input 实际变成了一个
map<string,tensor>,key 为id feature 名字,value 为id feature 值对应的 tensor。
大了难在哪
大模型训练为什么用A100不用4090 重点,非常经典,讲清楚了Tensor、Pipeline、Data Parallelism三大并行的算力、算力和内存耗费,优缺点,是一次大模型理论知识与工程知识的完美结合。
预训练一个72b模型需要多久? 未细读
- 内存墙(GPU Memory Wall)。在计算过程中,神经网络模型每一层的卷积或者全连接计算,都会把权重W_m长期保存下来,用作网络的权重参数更新(静态内存)。另外针对诸如ADAM的优化器,会存储优化器的动量等信息,用于优化器计算(动态内存)。一块有16G显存的AI芯片,最大能塞满20+亿参数的模型,但是这时候已经没有额外空间,留给动态内存进行分配啦。静态内存和动态内存都可能造成内存墙的问题。PS:参数要用的显存就像程序运行时变量要申请的内存。
- 通讯墙。由于大模型训练&推理通常都不能在单卡进行,所以我们需要多算力卡构成集群,不可避免的就存在服务器机内和机间通信。大模型通过模型并行、流水线并行切分到AI集群后,通讯便成了主要的性能瓶颈。随着机器规模的扩大,基于同步的All Reduce通讯聚合方式,会因为大量的AI芯片和服务器之间频繁进行同步,出现水桶效应,也就是最慢的一路通讯,将会决定整个AI集群的通讯的高度。如果采用目前比较流行的Ring-AllReduce的通信聚合方式,当通讯的环越大,通讯的延长将会不断地被扩大。另外网络协议的多次握手的方式,诸如此类的开销会导致训练无法有效利用带宽。
- 性能墙。性能墙呢主要是指计算资源利用率的问题。随着大模型的提出,对算力需求更加迫切,理论上在4K的集群上每块卡快1分钟,总体就快了68个小时。大模型会增加对算力的需求,但是随着大模型引入各项分布式并行技术的同时,会降低计算资源的利用率。
- 算子层(Operator Level):小算子过多,可以通过算子融合进行优化;子实现不够高效,类似于卷积CONV算子针对2x2和3x3 Kernel大小的使用Winograd算法代替;内存局部性差,对算子和内存的开销进行分析,可以对计算时算子输出有相同的shape进行复用。
- 图层(Graph Level):如何搜索和切分处计算效率更高的子图,分配到不同的机器上进行计算;数据在通讯和内存之间如何增加overlay重叠部分,提高单卡整体的计算率。
- 任务层(Task Level):在任务层级,性能的瓶颈从计算转移到了通信,如何降低通信量,缩减通信域规模,尽可能把通信时延隐藏在计算中,是大规模训练的核心关注点。
- 调优墙。所以在数千节点的集群上,需要考虑到提升算法工程师分布式调试调优的效率,另外还要考虑降低工程师对大模型进行并行切分的难度。除了对人的考虑,还要对硬件集群的管理,需要保证计算的正确性、性能、可用性。要是有一台机器坏了,如何快速恢复训练中的参数。
CV和NLP场景
浅谈工业界分布式训练(一) 除了上述的数据量级大,不同场景下分布式训练的痛点 对CV和NLP场景
- CV和NLP场景模型复杂,单机性能要求高,比如卷积的计算时间在CPU上和 GPU上相差十倍到几十倍。 ==> 业界主要使用高性能的GPU进行计算,并采用All-reduce的通信拓扑进行参数的同步更新。
- 模型大(DenseNet部分),比如NLP领域,GPT-3这样的模型高达1750亿参数,显存占用高达3.5TB,至少需要44块80GB显存的GPU才能塞下一个模型副本。而Bert-Large虽然只有3.4亿参数规模,但由于各种内存占用,在16G V100上,训练也仅能使用batch Size=8。 ==> 当面对GPT-3这种DenseNet部分大的模型,Allreduce 单卡内存无法容纳,我们需要采用模型并行(model parallelism)的方式将计算图划分到不同的设备上构建有向无环图(DAG)进行分布式训练,其中Gpipe, Megatron, Oneflow和Whale都提出模型并行的相关解决方案。相比于数据并行每个worker只有一部分数据,模型并行下每个node使用所有数据.
-
Intra-layer parallelism(Tensor Parallelism) 。主要是将一层Layer中的矩阵计算分别拆分到不同的机器上进行运算,比如简单的$Y_1=W_1*X_1$这一次矩阵乘法中,我们将模型参数$W_1$或者输入数据$X_1$,按某个维度分别拆分到不同设备上计算,比如1D Megatron。
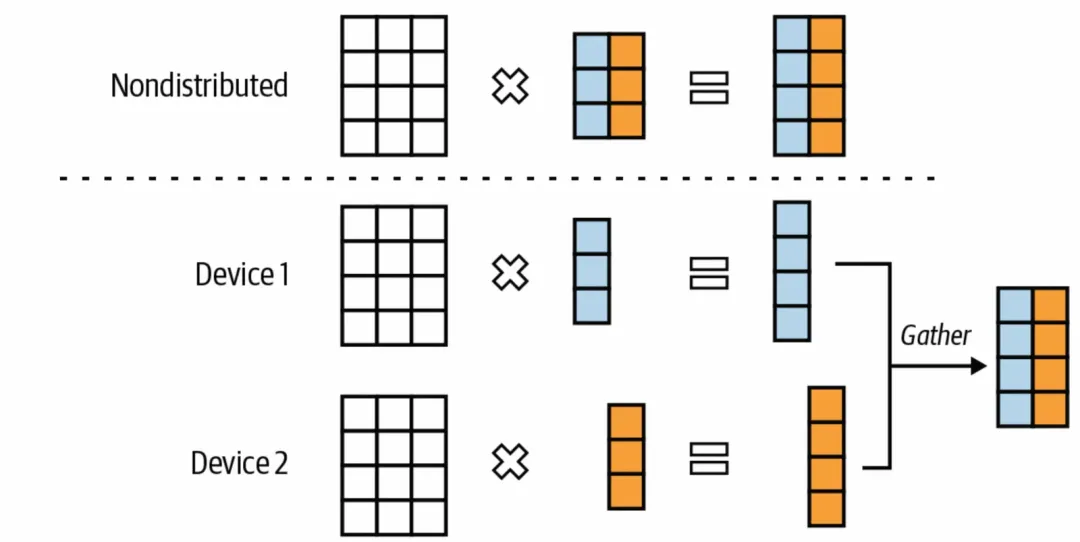
-
Inter-layer parallelism(Pipeline Parallelism)。而Inter-Layer Parallism会将模型的layers拆分到不同的机器上,则一次forward就需要跨过不同的机器串行地进行运算,而流行并行通过将batch size切分为更小的mirco batch,减少数据依赖,从而将整个计算过程异步起来,最大化资源利用率。举例来说,在一个简单的三层MLP中(的$Y_i = W_i X_i$, i=1,2,3)会存在三次矩阵乘法 $W_i X_i$,流水线并行会把$W_i X_i$分别分配到三台机器上进行运算。
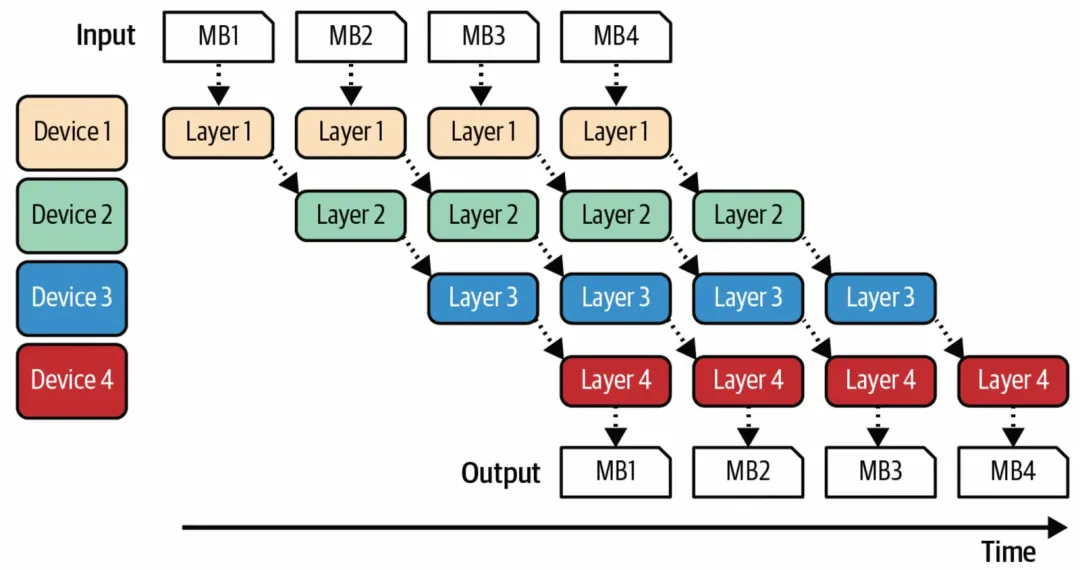
-
以Transformer结构为基础的大模型参数量、计算量、中间激活以及KV cache剖析
AI for Science的出现,让高性能计算与AI融合成为刚需, tensor parallelism、pipeline parallelism、data parallelism在模型的层内、模型的层间、训练数据三个维度上对 GPU 进行划分。三个并行度乘起来,就是这个训练任务总的 GPU 数量。
- 数据并行。数据集被分割成几个碎片,每个碎片被分配到一个设备上。假如整个模型设两个节点,一个模型节点0、另一个模型做的节点1,整个模型都做了数据并行,数据各一半要拿去训练学习,但并且在每个训练步骤结束时,通过某种形式的通信(如梯度平均或参数服务器)来同步模型参数。
- 限制是要求当模型可以放进单个 GPU 时才有效,当前 LLM 模型规模已经突破了这个限制,为了解决这个问题,微软提出了 ZeRO,还是数据并行,只是每个 GPU 没有都复制完整的模型参数、梯度和优化器状态,而是只存储其中的一部分。在之后的训练过程,当需要给定层的完整层参数时,所有 GPU 通过通信同步以相互提供它们缺失的部分。
- 数据并行(Data Parallelism)策略本身也经历了一系列的演进。例如,Zero Redundancy Optimizer (ZeRO) 和 Fully Sharded Data Parallel (FSDP,原理和deepspeed的ZeRO stage3一致,FSDP是pytorch的官方实现) 等概念的出现,它们的核心思想是在训练过程中将状态信息、梯度或模型参数分散存储,而计算过程仍然遵循数据并行的原则。但随着模型规模的增加,数据并行策略需要更高效的通信机制和更大的带宽来处理增加的同步负载。
- 模型并行。模型被分割并分布在一个设备阵列上。将整个模型切成一半,一半模型节点0,一半模型节点1,数据是整个拿去训练。训练完了以后出来的结果也不是最终结果,因为只训练了一半的模型,出来还有AII-Gather,也是做通信的。
- 流水线并行有多种说法
- 将计算过程分成多个阶段,每个阶段分配到不同的GPU上进行计算。举一个例子,假设有一个深度学习模型需要进行训练,训练过程包括数据预处理、前向传播、反向传播、参数更新等多个阶段。在流水线并行中,可以将这个训练过程分成多个阶段,每个阶段分配到不同的GPU上进行计算。例如,可以将数据预处理分配到GPU1,前向传播分配到GPU2,反向传播分配到GPU3,参数更新分配到GPU4。这样每个GPU只需要计算自己负责的阶段,可以充分利用多个GPU的计算能力,提高训练效率和速度。在使用流水线并行时,需要进行复杂的调度和同步操作,以确保计算正确。例如,在上面的例子中,GPU2需要等待GPU1完成数据预处理后才能开始进行前向传播计算。
- 是不是把 pipeline 搞的越深越好,每个 GPU 只算一层?将模型的不同 layer 分配到多个 GPU 中,数据在不同层(也即是不同 GPU )之间移动。下图中 a 展示了流水线并行的计算方式,前向传播时,数据从 Device0 依次传递到 Device3;然后经历反向传播,计算梯度从 Device3 依次传递回 Device0。
- 因为每个 GPU 必须等待前一个 GPU 计算完成,从而导致不必要的气泡开销。比如流水线的第一级算出了正向传播的中间状态,如果有 N 个流水级,那就要正向流过后面的 N - 1 个流水级,再等反向传播 N - 1 个流水级,也就是 2N - 2 轮之后才能用到这个正向传播的中间状态。不要忘了每一轮都会产生这么多中间状态,因此一共是保存了 2N - 1 个中间状态。如果 N 比较大,这个存储容量是非常恐怖的。其次,pipeline 的相邻流水级(pipeline stage)之间是要通信的,级数越多,通信的总数据量和总时延就越高。因此,在内存容量足够的情况下,最好还是少划分一些流水级(pipeline stage)。单纯使用流水线并行和数据并行训练大模型的最大问题在于流水线并行级数过多,导致正向传播中间状态(activation)存储容量不足。
- 为了减少气泡开销,GPipe 和 PipeDream 提出如果同时进行多个迭代,每个节点在同一时刻负责不同迭代的计算,就可以避免数据依赖,不用在原地干等了。
- 张量并行:张量并行把全连接层的参数和计算分割到多个 GPU 上,与流水线不同,张量并行专注于分解模型的张量(参数矩阵),Megatron-LM 论文中关于这个问题有详细阐述。图解大模型之:张量模型并行,Megatron-LM 究竟用哪种并行方法呢?实际上这跟计算机结构有关。如果每台计算机之间通信都非常快,那么用数据并行就可以;如果你的通信比较慢,就要考虑模型并行。因此,这些模型如何跟数据、机器实际情况匹配?这就涉及到软硬件协同。
考虑到底层基础设施的能力,通常的分布策略是:
- 数据并行:多机组成一个单元,通信量是 GB 量级,单元间进行高效 AllReduce 通信,我们的三层 CLOS 网络架构是面向 AllReduce 优化。
- 流水线并行:多机一组,通信量在 MB 量级,机间同号卡进行 P2P 通信。
- 张量并行:考虑到通信量数百 GB,在单机内并行,借助单机内 NVLink 这样的高速互联通信能力。
不同的并行性技术会引入不同程度的通信开销和计算延迟。由于现实的互联所能实现的带宽延迟,并行度永远不可能无限扩展,一定会限制在一定尺度内,甚至非常有限的尺度内。在深度学习训练过程中,GPU需要大量的数据进行计算,但是如果数据没有及时传输到GPU就会导致GPU处于等待状态,浪费GPU的计算能力。因此,CPU卸载技术就应运而生,通过让CPU负责将数据传输到GPU,可以让GPU专心计算,提高训练速度。CPU卸载还可以帮助减少GPU内存的使用,降低训练过程中的内存压力。卸载分为多种类型,包括数据卸载、模型卸载、梯度卸载等。数据卸载是指将数据卸载到存储设备(例如硬盘)中,用的时候传输到GPU中,其他的类似。
Galvatron项目原作解读:大模型分布式训练神器,一键实现高效自动并行稠密大模型拥有着动辄数十亿、百亿甚至万亿规模的参数量,面临高昂的计算、存储、以及通信成本,为 AI 基础设施带来了巨大的挑战。人们研发了很多工具(如 Megatron、DeepSpeed、FairSeq 等)来实现如数据并行、张量模型并行、流水并行、分片数据并行等各种并行范式。但这种粗粒度的封装逐渐难以满足用户对系统效率和可用性的需要。如何通过系统化、自动化的方式实现大模型分布式训练,已经成为了当前 MLSys 领域最为重要的问题之一。最近已经有一些系统开始提及“自动并行”的概念,但它们大部分都还停留在对 API 和算子进行工程上的封装,仍然依赖用户人工反复尝试或系统专家经验才能完成部署,并没有从根本上解决自动并行难题。近日,北大河图团队提出了一套面向大模型的自动并行分布式训练系统 Galvatron,相比于现有工作在多样性、复杂性、实用性方面均具有显著优势,性能显著优于现有解决方案。
推广搜场景
大模型:id 化导致模型变大,模型变大需要更多的数据才能收敛。
- 模型小,词表大。模型中的DenseNet部分,不像BERT是模型巨大词表小,往往一台机器的内存就可以容纳,但是其特征量级可能高达成百上千亿,造成Sparsenet部分或者Embedding lookup table高达TB级别,使得单机无法容纳。
- 一个batch的embedding lookup量级大,造成查询耗时大。由于特征数量多,一个batch可能包含几十万个ID类特征,tf原生的embedding lookup查询耗时大,造成训练和inference性能低。尤其在线上inference的时候,无法在给定RT内完成服务响应。
- 数据具有大规模稀疏的特点。不同于CV和NLP场景,数据是稠密的图像和文本,搜广推的数据非常稀疏的,第一这来源于很多数据无法对所有用户和场景有效采集到,第二是因为建模使用的特征量级大造成的高维稀疏性。这会影响了数据的存储格式和计算效率。
TensorFlow在美团外卖推荐场景的GPU训练优化实践 推荐系统深度学习模型特点
- 读取样本量大:训练样本在几十TB~几百TB,而CV等场景通常在几百GB以内。
- 模型参数量大:同时有大规模稀疏参数和稠密参数,需要几百GB甚至上TB存储,而CV等场景模型主要是稠密参数,通常在几十GB以内。
- 模型计算复杂度相对低一些:推荐系统模型在GPU上单步执行只需要10~100ms,而CV模型在GPU上单步执行是100~500ms,NLP模型在GPU上单步执行是500ms~1s。 GPU服务器特点
- GPU卡算力很强,但显存仍有限:如果要充分发挥GPU算力,需要把GPU计算用到的各种数据提前放置到显存中。而从2016年~2020年,NVIDIA Tesla GPU卡计算能力提升了10倍以上,但显存大小只提升了3倍左右。
- 其它维度资源并不是很充足:相比GPU算力的提升速度,单机的CPU、网络带宽的增长速度较慢,如果遇到这两类资源负载较重的模型,将无法充分发挥GPU的能力,GPU服务器相比CPU服务器的性价比不会太高。
外卖广告大规模深度学习模型工程实践在数据规模、模型规模增长的情况下,所对应的“时长”变得会越来越长。这个“时长”对应到离线层面,体现在效率上;对应到在线层面,就体现在Latency上。
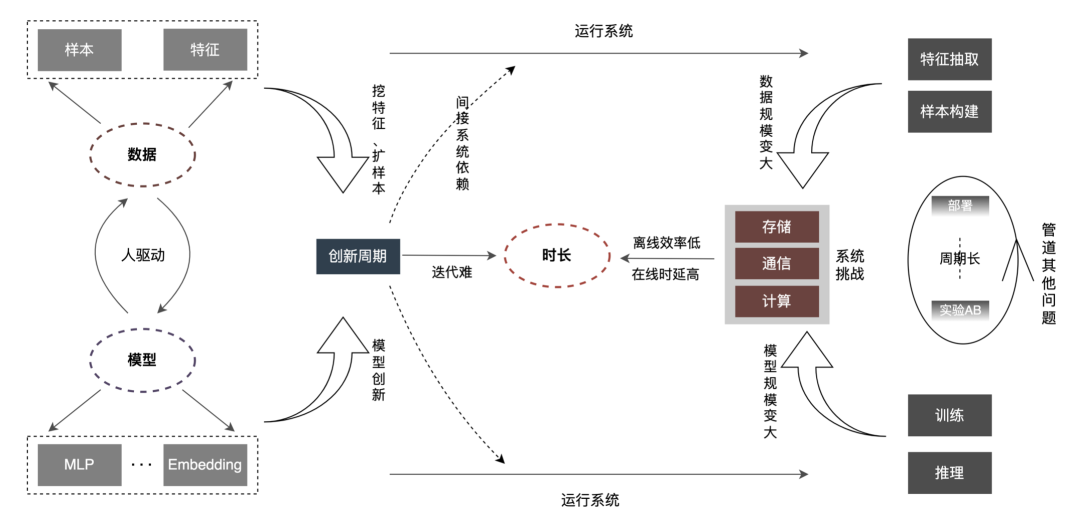 “时长”变长,主要会体现在以下几个方面:
“时长”变长,主要会体现在以下几个方面:
- 在线时延:特征层面,在线请求不变的情况下,特征量的增加,带来的IO、特征计算耗时增加等问题尤为突出,需要在特征算子解析编译、特征抽取内部任务调度、网络I/O传等方面重塑。在模型层面,模型历经百M/G到几百G的变化,在存储上带来了2个数量级的上升。此外,单模型的计算量也出现了数量级的上涨(FLOPs从百万到现在千万),单纯的靠CPU,解决不了巨大算力的需求,建设CPU+GPU+Hierarchical Cache推理架构来支撑大规模深度学习推理势在必行。
- 离线效率:随着样本、特征的数倍增加,样本构建,模型训练的时间会被大大拉长,甚至会变得不可接受。如何在有限的资源下,解决海量样本构建、模型训练是系统的首要问题。
- 在数据层面,业界一般从两个层面去解决,一方面不断优化批处理过程中掣肘的点,另一方面把数据“化批为流”,由集中式转到分摊式,极大提升数据的就绪时间。
- 在训练层面,通过硬件GPU并结合架构层面的优化,来达到加速目的。
- 其次,算法创新往往都是通过人来驱动,新数据如何快速匹配模型,新模型如何快速被其他业务应用,如果说将N个人放在N条业务线上独立地做同一个优化,演变成一个人在一个业务线的优化,同时广播适配到N个业务线,将会有N-1个人力释放出来做新的创新,这将会极大地缩短创新的周期,尤其是在整个模型规模变大后,不可避免地会增加人工迭代的成本,实现从“人找特征/模型” 到“特征/模型找人”的深度转换,减少“重复创新”,从而达到模型、数据智能化的匹配。
- Pipeline其他问题:机器学习Pipeline并不是在大规模深度学习模型链路里才有,但随着大模型的铺开,将会有新的挑战,比如:① 系统流程如何支持全量、增量上线部署;② 模型的回滚时长,把事情做正确的时长,以及事情做错后的恢复时长。简而言之,会在开发、测试、部署、监测、回滚等方面产生新的诉求。
大模型的参数主要分为两部分:Sparse参数和Dense参数。
- Sparse参数:参数量级很大,一般在亿级别,甚至十亿/百亿级别,这会导致存储空间占用较大,通常在百G级别,甚至T级别。其特点:
- 单机加载困难:在单机模式下,Sparse参数需全部加载到机器内存中,导致内存严重吃紧,影响稳定性和迭代效率;
- 读取稀疏:每次推理计算,只需读取部分参数,比如User全量参数在2亿级别,但每次推理请求只需读取1个User参数。
- Dense参数:参数规模不大,模型全连接一般在2~3层,参数量级在百万/千万级别。特点:
- 单机可加载:Dense参数占用在几十兆左右,单机内存可正常加载,比如:输入层为2000,全连接层为[1024, 512, 256],总参数为:2000 * 1024 + 1024 * 512 + 512 * 256 + 256 = 2703616,共270万个参数,内存占用在百兆内;
- 全量读取:每次推理计算,需要读取全量参数。
因此,解决大模型参数规模增长的关键是将Sparse参数由单机存储改造为分布式存储,改造的方式包括两部分:
- 模型网络结构转换。业界对于分布式参数的获取方式大致分为两种:外部服务提前获取参数并传给预估服务;预估服务内部通过改造TF(TensorFlow)算子来从分布式存储获取参数。为了减少架构改造成本和降低对现有模型结构的侵入性,我们选择通过改造TF算子的方式来获取分布式参数。正常情况下,TF模型会使用原生算子进行Sparse参数的读取,其中核心算子是GatherV2算子。算子的作用是从Embedding表中读取ID列表索引对应的Embedding数据并返回,本质上是一个Hash查询的过程。遍历模型网络,将需要替换的GatherV2算子替换为自定义分布式算子MtGatherV2,同时修改上下游节点的Input/Output。MtGatherV2 算子:从本地Embedding表中查询,改造为从分布式KV中查询。
- Sparse参数导出。
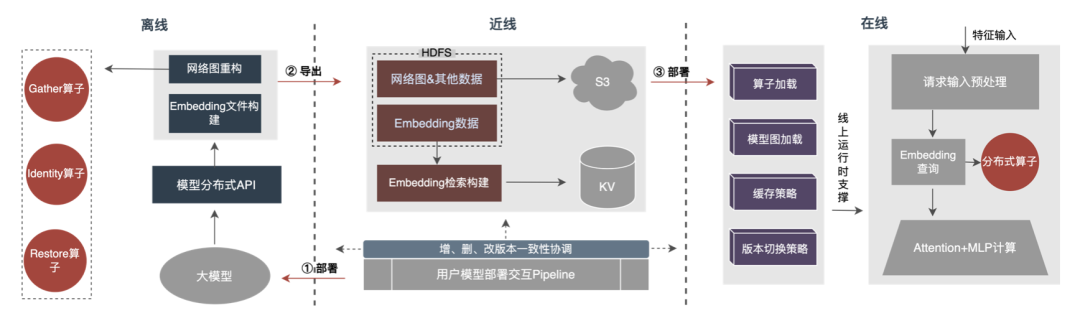
模型保存
- 在模型比较小的时候,比如100G以下,模型还有可能单机存储。这个时候的方案是tensorflow分布式训练+savedmodel,分布式训练可以用多个ps(tensorflow自带的),资源管理可以用yarn。用分布式是由于样本数大,同时多ps也能异步加速训练。saved_model一般由chief worker保存,但存下来以后,会抹掉ps的痕迹,保存的模型跟单机训练的一模一样。
- 当模型比较大的时候,这个时候要求的样本数也更大,训练完dump出来的模型会很大,一个单机放不下,尤其是embedding table。这个时候怎么办?一个自然的思路就是,把训练时候的ps拷贝同步一份给serving ps,线上由该ps做serving。注意后面谈到的serving ps,都是自己开发或者根据某个开源软件修改而成(比如ps-lite)。如果是天级模型,可以用tensorflow原生的worker和train ps,但依然用saved model方式把模型存放到hdfs,然后从hdfs读入另外一个serving ps。如果是实时训练,则serving ps还得跟训练ps进行实时的网络连接,在内存就解决掉weight同步的处理,这个时候就不能用tensorflow原生的ps了,因为原生的ps没有实现同步接口。ps变了,worker也得跟着变,worker大多数都是基于tensorflow的c++底层接口开发,底层用到tf的session接口。大模型分布式训练故障恢复的几点思考
解决思路
针对模型训练的加速,我们先看一下大模型训练的流程:加载 CheckPoint -> 加载数据 -> 前向计算 -> 反向计算 -> 梯度同步 -> 梯度更新 -> CheckPoint 保存。这里面每一个阶段都可以进行优化。
- CheckPoint 和 Data 的读写阶段,对读取的数据进行预读,对 CheckPoint 写入进行异步写入。
- 前向和反向计算阶段,可以采用跟推理阶段相同的计算优化方法,同时针对显存也有一些重计算和分组参数切片的方式来降低模型对显存容量的要求。
- 梯度同步阶段,可以通过降低通信频率,让计算和通信 Overlap 来进行通信优化。
怎么在大规模异构计算集群上做端到端的分布式并行训练?
- 启动任务之前,先根据模型的计算和通信 Cost Model,同时结合集群物理拓扑,生成最优任务放置策略。
- 任务进行 TP、PP、PP、分组参数切片 4D 混合并行。
- 遇到故障之后快速容错,重新训练。
网络架构
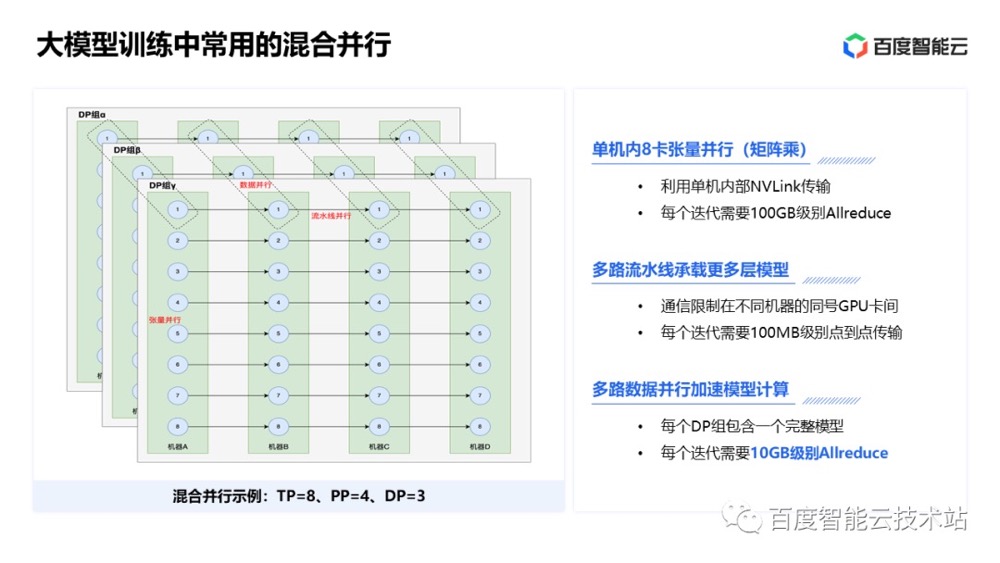
大规模 AI 高性能网络的设计与实践 并行训练策略 ==> 我们在训练大模型时,通常混合采用了三种并行策略。
- 首先在单机内部的多 GPU 卡间,我们采用张量并行,充分利用单机内部 NVLink 的高带宽特性。
- 其次,由于模型过大,单机 8 卡肯定还是放不下,因此在多机间继续采用流水线并行的策略,多路流水线并行构成一个模型训练的最小单元。
- 最后,为了进一步加速模型训练,我们再使用多路数据并行。注意这里数据并行的单元我们叫做一个 DP 组,每个 DP 组内部都是张量并行和流水线并行共存。数据并行中的 Allreduce 实际上是每个 DP 组的同号卡之间进行的。
比如这个图里,8 路张量并行,4 路流水线并行,3 路数据并行。在数据并行里,实际上有 32 个 Allreduce 组,每个组里有 3 张 GPU 做梯度同步。数据并行里每张 GPU 卡都需要对 10GB 级别的数据做 Allreduce,这个 Allreduce 是大模型训练对网络的主要需求。
正是由于大模型训练里这些需求,我们提出了 AI 高性能网络的三大目标:超大规模、超高带宽以及超长稳定。
- 首先,规模的大小直接决定了模型训练的快慢。这张图里可以看到,对于一个 1750 亿的模型,如果采用 2 千张 GPU,仍然需要训练 100 天以上。采用 8 千卡则可以把时间压缩到 30 天左右。这对于今天快速迭代的大模型而言是非常重要的。
- 其次,Allreduce 的带宽直接决定了大规模分布式下的整体效率。我们可以看下面这个图,平均单 GPU 的 Allreduce 带宽有 5GB/s 的时候,大规模分布式的整体加速比只有 70%。想要获得 90% 的加速比,单 GPU 的 AllReduce 带宽则需要做到 20GB/s,相当于单 GPU 跑满 400G 网卡。
- 最后是稳定的问题,由于训练时长至少是几个星期,长时间下的稳定性显得非常重要。假定单 GPU 的月可用性是 99.9%,那么在千卡规模下模型训练一月内遇到故障发生中断的概率是 60%,而如果采用 8 千卡中断概率就有 99%。即使 GPU 的可用性提升到 99.99%,8 千卡下的中断概率仍然在 50% 左右。
基于这样的目标,我们有针对性地设计了 AI 大底座里面的 AI 高性能网络—— AIPod。有约 400 台交换机、3000 张网卡、10000 根线缆和 20000 个光模块。其中仅线缆的总长度就相当于北京到青岛的距离。PS: 后面再具体的技术介绍就看不懂了。
AI 大模型狂飙的背后:高性能计算网络是如何“织”成的? 未读。
故障
相比 CPU, GPU 硬件故障率会高很多,另外网络规模大了之后端口和线缆也会有故障的可能。除了各种硬件故障之外还有一些软件故障,以及 Loss 尖峰进行回滚重算,这些都会导致计算任务终止。由于大模型训练中梯度需要同步,整个计算过程是同步的,任何一个故障都会造成整个集群不可用,因此提升整个 GPU 计算集群的有效运行时间成为大模型训练的关键。
任务无效训练时间 = 故障中断次数 * (任务故障恢复时长 + 任务故障重算时长) + 任务常态写 CheckPoint 总时长。 针对这些公式中的每一个部分进行逐层容错优化:
- 通过硬件层面的预检查,避免故障机器上线。提升硬件和网络的故障感知能力,再通过节点热维修或备机替换进行快速容错。
- 任务异常快速感知,进行重调度,并对任务恢复过程中的数据 I/O进行加速。
- 框架层优化 CheckPoint 加载、异步写入以及优化分布式写入。
其它
千卡级别的模型训练充满着挑战,经常会碰到训练不稳定导致模型崩溃的情况。而这种情况下的故障很可能来自多个方面,可能是硬件的故障、PyTorch 的死锁、甚至是其他方面的各种问题。除此之外,你还需要做好集群层面机器学习负载的灵活调度,在这方面,Anyscale 的 Ray和微软的 Singularity 也做了很多的工作。
留下评论