负载均衡泛谈
简介
来自现代网络负载均衡与代理(上) 现代网络负载均衡与代理(下)
维基百科将负载均衡定义如下: 在计算中,负载均衡改进了跨多个计算资源(如计算机、计算机集群、网络连接、中央处理单 元或磁盘驱动器)的工作负载分布。负载均衡的目的是优化资源的使用,最大限度地提高吞 吐量,最大限度地减少响应时间,并避免任何单一资源的过载。使用具有负载均衡的多个组 件而不是单个组件,可以通过冗余提高可靠性和可用性。负载均衡通常涉及专用软件或硬件, 如多层交换机或域名系统服务器。
上述定义适用于计算的所有方面,而不仅仅是网络。操作系统使用负载均衡来跨cpu 调度任务,容器编排(如 Kubernetes)使用负载均衡来跨计算集群调度任务,网络负载均衡器 使用负载均衡来跨可用后端调度网络任务。
四层和七层负载均衡

客户端建立一个到负载均衡 器的 TCP 连接。负载均衡器终结该连接(即直接响应 SYN),然后选择一个后端,并与该后端建立一个新的 TCP 连接(即发送一个新的 SYN)。四层负载均衡器通常只在四层 TCP/UDP 连接/会话级别上运行。因此, 负载均衡器通过转发数据,并确保来自同一会话的字节在同一后端结束。四层负载均衡器 不知道它正在转发数据的任何应用程序细节。数据内容可以是 HTTP, Redis, MongoDB,或任 何应用协议。
四层负载均衡很简单,并且仍然被广泛使用。四层负载均衡有哪些缺点是七层(应用)负载均衡来解决的呢?以下几个四层案例:
两个 gRPC/HTTP2 客户端通过四层负载均衡器连接想要与一个后端通信。四层负载均衡器为每个入站 TCP 连接创建一个出站的 TCP 连接,从而产生两个入站和两个出站的连接(CA ==> loadbalancer ==> SA, CB ==> loadbalancer ==> SB)。假设,客户端 A 每分钟发送 1 个请求,而客户端 B 每秒发送 50 个请求,则SA 的负载是 SB的 50倍。所以四层负载均衡器问题随着时 间的推移变得越来越不均衡。
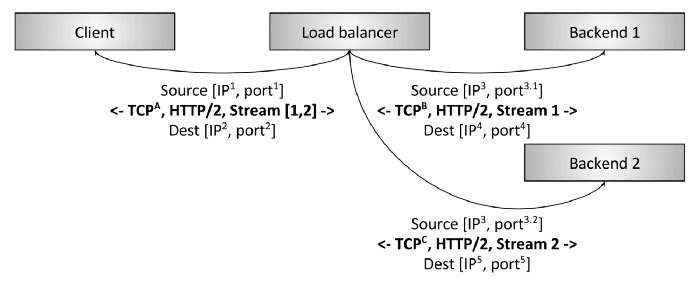
上图 显示了一个七层 HTTP/2 负载均衡器。在本例中,客户端创建一个到负载均衡器的HTTP/2 TCP 连接。负载均衡器创建连接到两个后端。当客户端向负载均衡器发送两个HTTP/2 流时,流 1 被发送到后端 1,流 2 被发送到后端 2。因此,即使请求负载有很大差 异的客户端也会在后端之间实现高效地分发。这就是为什么七层负载均衡对现代协议如此 重要的原因。
七层负载均衡器最终将会在服务对服务通信中完全取代四层负载均衡器,但四层负载均衡器仍然是非常重要的。一般在边缘部署中,将专用四层负载均衡器置于七层负载均衡器之前。
七层负载均衡的现状
- 协议支持。Envoy 明确支持七层协议解析和路由包括 HTTP/1, HTTP2, gRPC, Redis, MongoDB,和 DynamoDB。未来可能会添加更多协议,包括 MySQL 和 Kafka。
- 动态配置。分布式系统要求有可动态配置的功能来控制系统,Istio 就是这种系统的一个例子。
- 高级负载均衡。七层负载均衡器现在通常内置了很多高级负载均衡功能,例如超时、重试、速率限制、断路、Shadow、缓冲、基于内容的路由等。
- 可观察性。越来越动态的系统正在被部署,随之越来越 难以调试。
- 可扩展性。很多负载均衡器都支持脚本,比如 Lua。
- 容错
负载均衡器提供的高级功能
- 服务发现
- 静态配置文件。
- DNS。
- Zookeeper,Etcd,Consul 等
- Envoy 通用数据平面 API。
- 健康检查,确定后端是否可用来提供服务的过程。
- 主动方式:负载均衡器按固定的时间间隔 ping 后端(例如,向一个/healthcheck 端点发 送 HTTP 请求)将,来评估它的运行健康状况。
- 被动方式:负载均衡器从主要数据流来识别运行健康状况。例如,如果连续出现三个连 接错误,则四层负载均衡器可能会确定后端不可用。如果连续有三个 HTTP 503 响应代 码,则七层负载均衡器可能会确定后端不健康。
- 负载均衡,负载均衡器必须实现负载的均衡!从简单的算法(如随机选择和轮询),到考虑可变延迟和后端负载来判断更复杂的算法。
- 会话保持,在某些应用程序中,对于同一会话的请求到达同一的后端非常重要。会话的定义各不相同,可能包括 HTTP cookie、客户端连接的属性或其 他一些属性。
- TLS 终结
- 可观察性, 网络本质上是不可靠的,负载均衡 器通常负责导出统计信息,跟踪信息和日志,帮助管理员找出问题所在,以便他们解决问题。数据带来的好处远远超过了对性能影响。
- 安全性和 Dos 防范
- 配置和控制平面,通常,配置负载均衡 器的系统称为“控制平面”,其实现方式差异很大。
拓扑类型
- 中间代理
- 边缘代理,实际上只是中间代理拓扑的一种变体
- 嵌入式客户端库,为了避免中间代理拓扑固有的单点故障和扩展问题,更成熟的基础架构已朝着 通过将负载均衡嵌入到客户端库的方式来实现。
- Sidecar 代理,嵌入式客户端库负载均衡的一种变体。Sidecar 代理背后的思路是,以各进程间通信而导致的轻微延迟损失 为代价,无需任何编程语言锁定即可获得嵌入式库方法的各种优点。
代理的其它实现方式
通过 iptables实现proxy
深入理解 Kubernetes 网络模型 - 自己实现 kube-proxy 的功能用户空间代理程序的主要瓶颈来自内核-用户空间切换和数据复制。如果我们可以完全在内核空间中实现代理,它将在性能上大大提高,从而击败用户空间的代理。iptables 可用于实现这一目标。
通过ipvs 实现proxy
虽然基于 iptables 的代理在性能上优于基于用户空间的代理,但在集群服务过多的情况下也会导致性能严重下降。本质上,这是因为 iptables 判决是基于链的,它是一个复杂度为 O(n) 的线性算法。iptables 的一个好的替代方案是 IPVS——内核中的L4负载均衡器,它在底层使用 ipset(哈希实现),因此复杂度为 O(1)。
$ yum install -y ipvsadm
$ ipvsadm -ln
# 增加service
$ ipvsadm -A -t $CLUSTER_IP:$PORT -s rr
$ ipvsadm -a -t $CLUSTER_IP:$PORT -r $POD1_IP -m
$ ipvsadm -a -t $CLUSTER_IP:$PORT -r $POD2_IP -m
通过 bpf 实现 proxy
这也是一个 O(1) 代理,但是与IPVS相比具有更高的性能。如果你有足够的时间和兴趣来阅读eBPF/BPF,可以考虑阅读 Cilium: BPF and XDP Reference Guide
需要实现一段代码,编译并加载到内核中
使用 eBPF 在生产环境调试 Go 应用在功能上,eBPF 允许你在一些事件(如定时器、网络事件或函数调用)发生时运行受限的 C 代码,当触发一个函数调用时,我们把这些函数称为 probe,它们可以用来运行在内核内的函数调用上(kprobes),也可以运行在用户空间程序的函数调用上(uprobes)。eBPF 允许内核运行 BPF 字节码,通常都是 C 语言的限制子集,通常先用 Clang 将 C 代码编译成 BPF 字节码,然后对字节码进行验证以确保其安全执行。
eBPF 提供的是基本功能模块(building blocks)和程序附着点(attachment points)。我们可以编写 eBPF 程序来 attach 到这些 hook 点完成某些高级功能。BPF C 与普通 C 差异有多大?BPF 校验器可能最清楚地见证了近几年 BPF C 的发展历史。现在我们有了 BPF-to-BPF 函数调用、有限循环(bounded loops)、全局变量、静态 链接(static linking)、BTF(BPF Type Format,在 tracing 场景尤其有用;其 他方面也有用到,使内核成为可自描述的 self-descriptive)、 单个 BPF 程序的最大指令数(instructions/program)从原来的 4096 条放大到了 100 万条。
留下评论