karmada支持crd
简介
背景
In the progress of propagating a resource from karmada-apiserver to member clusters, Karmada needs to know the resource definition. For Kubernetes native resources, Karmada knows how to parse them, but for custom resources defined by CRD, as lack of the knowledge of the resource structure, they can only be treated as normal resources. Therefore, the advanced scheduling algorithms cannot be used for them.The Resource Interpreter Frameworkis designed for interpreting resource structure.
karmada 从 karmada-apiserver 向多个cluster 分发crd的过程中,一边是用户创建的、存在于karmada-apiserver 的crd,一边是运行在各个cluster 的crd,对于两边的crd 需要进行各种操作和状态同步。
- 比如使用GetReplicas 获取crd的副本数,计算完cluster1 应负责的crd 的replica1 之后,向cluster1 创建 replica=replica1 的crd。
- 假如deployment有10个pod,两个cluster 分别运行2/8 个pod,用户创建的deployment 的status 等字段 也应该能感知到真实情况。
整体设计
Karmada 资源解释器资源解释器框架(Resource Interpreter Framework)是为解释资源结构而设计的,目前主要由下面 3 种解释器构成:
- 内置解释器 (Built-in Interpreter):用于解释常见的 Kubernetes 原生或知名扩展资源,由 Karmada 社区实现和维护,会内置到 Karmada 组件中。
- 自定义解释器(Customized Interpreter):用于解释自定义资源或覆盖内置解释器。需要用户实现和维护 Interpreter Webhook,并且注册到 Karmada 中。
- 可配置解释器(Configurable Interpreter):用于解释任意资源类型,并且支持用户通过编写 lua 脚本,来实现自定义资源对应的Interpreter Operations 方法或覆盖内置 Interpreter Operations 方法。
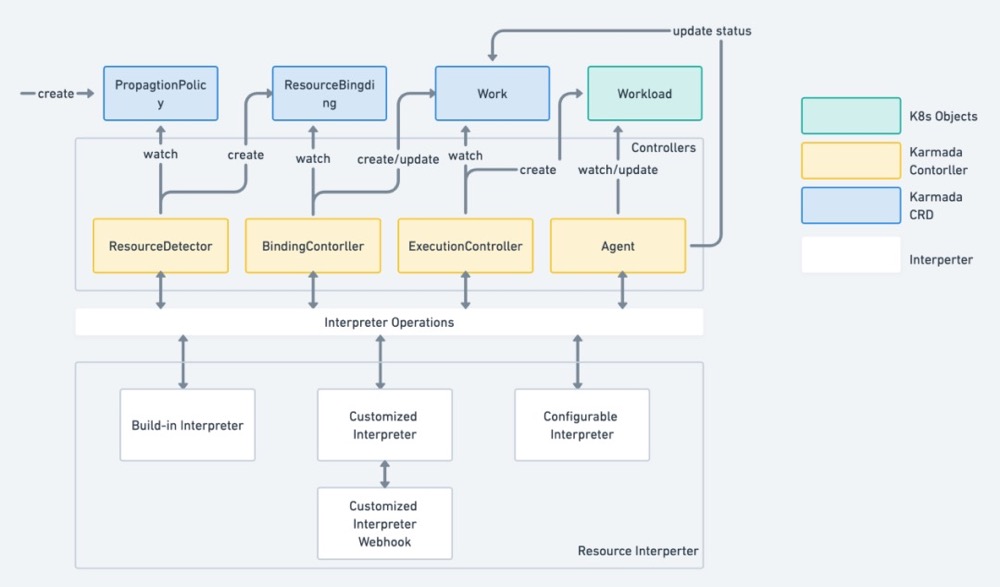
ResourceDetector 组件监听 用户创建的object,查找 object 匹配的 PropagationPolicy 并创建ResourceBinding。创建 ResourceBinding 时会执行 ResourceInterpreter.GetReplicas(object) 拿到crd 的副本数 为集群层的调度提供依据。
// ResourceDetector is a resource watcher which watches all resources and reconcile the events.
controllermanager.Run ==> ResourceDetector.Reconcile
object, err := d.GetUnstructuredObject(clusterWideKey)
propagationPolicy, err := d.LookForMatchedPolicy(object, clusterWideKey)
d.ApplyPolicy(object, clusterWideKey, propagationPolicy)
binding, err := d.BuildResourceBinding(object, objectKey, policyLabels, policy.Spec.PropagateDeps)
d.ResourceInterpreter.GetReplicas(object)
controllerutil.CreateOrUpdate(context.TODO(), d.Client, bindingCopy...)
Resource Interpreter Webhook 代码分析
resourceinterpreter 相关的目录结构
karmada
/examples
/customresourceinterpreter # 示例一个名为workload的crd如何实现
/apis
/webhook
/app
/webhook.go
/workloadwebhook.go
/main.go
/pkg
/resourceinterpreter
/customizedInterpreter
/configmanager # 管理所有ResourceInterpreterWebhookConfiguration
/webhook # 对应 /pkg/webhook,提供了request 和 response
/customized.go # ResourceInterpreter 的 CustomizedInterpreter 实现
/defaultInterpreter
/interpreter.go
/webhook # 对自定义实现webhook 进行了简单的封装(比如请求的编解码等), 自定义webhook时只需要实现一个子类即可。
/interpreter
karmada 侧
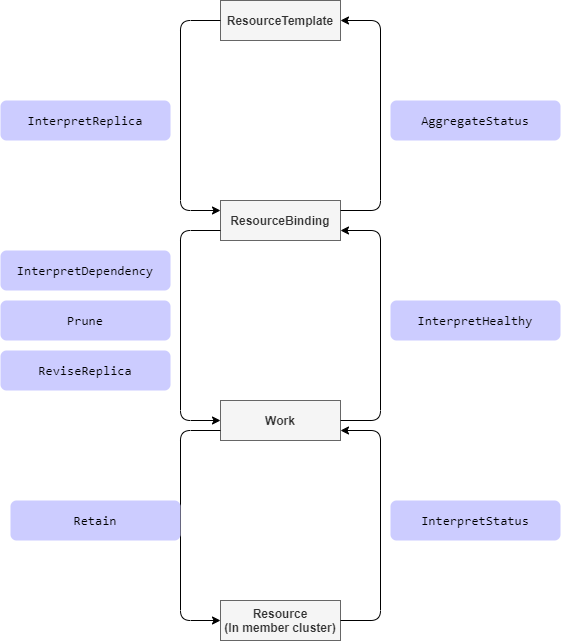
在解释资源时,我们经常会通过调用 Interpreter Operations,提取指定资源的多条信息。 Interpreter Operations 定义了解释器请求操作类型,资源解释器框架会为每个操作类型提供服务。
| ResourceInterpreter函数 | 功能 | 触发时机 | |
|---|---|---|---|
| HookEnabled | 检查是否有对应的 的ResourceInterpreterWebhookConfiguration | 进行下列操作之前 | |
| GetReplicas | 创建ResourceBinding 时获取karmada-apiserver crd的replica | ResourceDetector.Reconcile ==> ApplyPolicy ==> BuildResourceBinding | 仅对那些具有副本声明的资源类型是必需的,例如 Deployment 或类似的自定义资源。 |
| ReviseReplica | 分发到每个 cluster 时调整 cluster内crd的replica | ResourceBindingController.syncBinding ==> ensureWork | |
| GetDependencies | 比如对于 deployment 来说 configmap/secret/serviceaccount/pvc 即为 dependency | DependenciesDistributor.ReconcileResourceBinding | |
| Retain | Retain 表示 Karmada 请求 Webhook 保留想要的资源模板 | objectWatcherImpl.retainClusterFields | 例如一些资源被分发到成员集群以后,它们的模版将由其在成员集群中运行的控制器更新,那么对于这些类型的资源,Retain 是必须的 |
| ReflectStatus | 解析 各个cluster 下crd 的status 并汇总到所属work 的status下 | WorkStatusController.RunWorkQueue ==> syncWorkStatus | 仅对那些在特殊路径(不是.status)中定义其状态的资源类型是必需的。 |
| AggregateStatus | 将分发到各个cluster 的object 的状态(从worker.status)汇总并更新到 karmada-apiserver crd status上 | ResourceBindingController.syncBinding ==> AggregateResourceBindingWorkStatus + updateResourceStatus | 只有那些需要将状态聚合到资源模板的资源类型是必须的。 |
| InterpretDependency | 指出特定对象的依赖关系 | 仅对那些具有依赖资源并期望传播依赖的资源类型是必需的,就像 Deployment 依赖于 ConfigMap/Secret | |
| Prune | 指出特定对象如何将其资源模板打包到 Work | ||
| InterpretHealth | 表示 Karmada 想要弄清楚特定对象的健康状态 | 仅对那些拥有并想要反映其健康状态的资源类型是必需的。 |
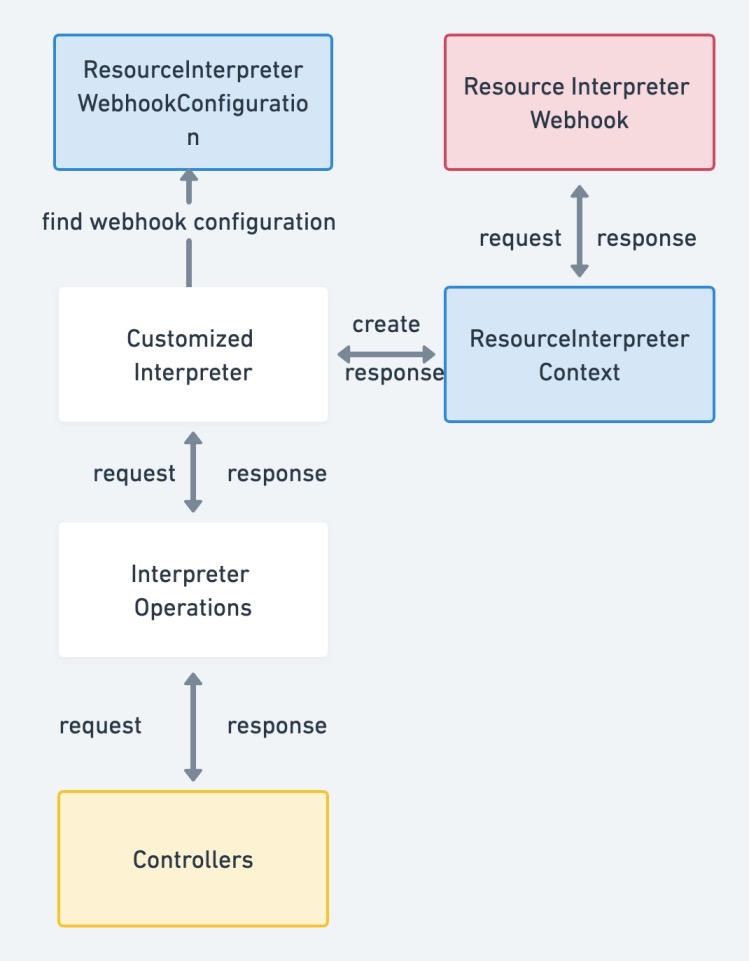
interpreter webhook 侧
受到 Kubernetes Admission Webhook 的启发,Karmada 引入了 Resource Interpreter Webhook 方案。
webhook 本质就是一个简单的 webserver,The webhook handles the ResourceInterpreterRequest request sent by the Karmada components (such as karmada-controller-manager), and sends back its decision as an ResourceInterpreterResponse.
// karmada/examples/customresourceinterpreter/webhook/app/webhook.go
func Run(ctx context.Context, opts *options.Options) error {
config, err := controllerruntime.GetConfig()
hookManager, err := controllerruntime.NewManager(config, controllerruntime.Options{
Logger: klog.Background(),
Host: opts.BindAddress,
Port: opts.SecurePort,
CertDir: opts.CertDir,
LeaderElection: false,
})
klog.Info("registering webhooks to the webhook server")
hookServer := hookManager.GetWebhookServer()
hookServer.Register("/interpreter-workload", interpreter.NewWebhook(&workloadInterpreter{}, interpreter.NewDecoder(gclient.NewSchema())))
hookServer.WebhookMux.Handle("/readyz/", http.StripPrefix("/readyz/", &healthz.Handler{}))
// blocks until the context is done.
hookManager.Start(ctx)
// never reach here
return nil
}
当收到 /interpreter-workload 请求,webhook.ServeHTTP ==> webhook.Handle ==> workloadInterpreter.Handle,之后根据请求的具体类型进行相应的处理。
func (e *workloadInterpreter) Handle(ctx context.Context, req interpreter.Request) interpreter.Response {
workload := &workloadv1alpha1.Workload{}
err := e.decoder.Decode(req, workload)
klog.Infof("Explore workload(%s/%s) for request: %s", workload.GetNamespace(), workload.GetName(), req.Operation)
switch req.Operation {
case configv1alpha1.InterpreterOperationInterpretReplica:
return e.responseWithExploreReplica(workload)
case configv1alpha1.InterpreterOperationReviseReplica:
return e.responseWithExploreReviseReplica(workload, req)
case configv1alpha1.InterpreterOperationRetain:
return e.responseWithExploreRetaining(workload, req)
case configv1alpha1.InterpreterOperationAggregateStatus:
return e.responseWithExploreAggregateStatus(workload, req)
case configv1alpha1.InterpreterOperationInterpretHealth:
return e.responseWithExploreInterpretHealth(workload)
case configv1alpha1.InterpreterOperationInterpretStatus:
return e.responseWithExploreInterpretStatus(workload)
default:
return interpreter.Errored(http.StatusBadRequest, fmt.Errorf("wrong request operation type: %s", req.Operation))
}
}
任何 访问这个 webhook 的 组件(在karmada 中主要是 controller )都需要 知道 webserver 提供服务的url 地址等信息,这些信息 可以作为 请求组件的启动参数传入,也可以写入到crd(即 ResourceInterpreterWebhookConfiguration),请求组件直接解析 ResourceInterpreterWebhookConfiguration 即可,karmada 选择后者。以下列配置为例,当karmada resourceInterpreter 需要 获取 Workload 的副本数时,便去 解析 名为 workloads.example.com 的ResourceInterpreterWebhookConfiguration 拿到 url,发出请求,访问用户自定义的crd 解析 replicas逻辑。
apiVersion: config.karmada.io/v1alpha1
kind: ResourceInterpreterWebhookConfiguration
metadata:
name: examples
webhooks:
- name: workloads.example.com
rules:
- operations: [ "InterpretReplica","ReviseReplica","Retain","AggregateStatus", "InterpretHealth", "InterpretStatus" ]
apiGroups: [ "workload.example.io" ]
apiVersions: [ "v1alpha1" ]
kinds: [ "Workload" ]
clientConfig:
url: https://:443/interpreter-workload
caBundle:
interpreterContextVersions: [ "v1alpha1" ]
timeoutSeconds: 3
可配置解释器
以 Retain/retention 为例: 在实际使用 Karmada 的过程中我们发现,Karmada 会一直在监听成员集群中传播的资源,以确保资源始终处于期望状态。在很多情况下,运行在成员集群中的控制器会对资源进行更改,例如:Kubernetes 将为类型为 ClusterIP 的 Service 分配一个 clusterIP。Kubernetes 会在调度阶段为 Pod 分配一个 NodeName。当 Karmada 用户对资源模板进行更改时,Karmada 将针对成员集群更新资源,但在更新之前,Karmada 应保留成员集群控制器所做的更改。
apiVersion: config.karmada.io/v1alpha1
kind: ResourceInterpreterCustomization
metadata:
name: examples
spec:
customizations:
retention:
luaScript: ``
target:
kind: Workload
apiVersion: v1alpha1
示例中我们为 v1alpha1 版本的 Workload 资源定义了一个 ResourceInterpreterCustomization 资源实例,并且通过自定义的 lua 脚本自定义了针对 Retention 请求的具体实现。当我们创建 PropagationPolicy 分发 v1alpha1 版本的 Workload 资源时,参与分发过程中的 Execution Controller 会发起 Retention 的 Interpreter Operations 请求,此时 Configurable Interpreter 根据我们创建的 ResourceInterpreterCustomization 找到与 Retention 请求对应的 lua 脚本,调用这些 lua 脚本从而实现对 Workload 资源的 Retention 请求的响应,当然 ResourceInterpreterCustomization 也支持自定义其他的 Interpreter Operations 请求的响应方法。PS:就像linux 支持ebpf 让我们进行一些简单的扩展一样,k8s 二次开发也开始设计一些机制 让用户通过脚本 来简单干预/扩展一下内部逻辑。
留下评论